
-
Research Article
-
Hull mounted passive sonar sensor based on accelerometers for improved low frequency detection
저주파 탐지 성능 개선을 위한 가속도계 기반 선체부착형 수동 소나센서
-
Hyeongmin Mun, Chang Hoon Lee, Woosuk Chang, Donghyeon Kim, Eunghwy Noh, Junho Hong, Seonghun Pyo, and Kyungseop Kim
문형민, 이창훈, 장우석, 김동현, 노응휘, 홍준호, 표성훈, 김경섭
- For hull-mounted passive sonar systems, insulating self noise and vibration generated from the hull structure is critical to the sonar detection performance. …
선체부착형 수동소나는 탐지 성능을 향상시키기 위해 후방에서 발생하는 함내 소음 및 진동을 효과적으로 차단하는 것이 중요하다. 이를 위해 최근 기존의 음향센서와 더불어 …
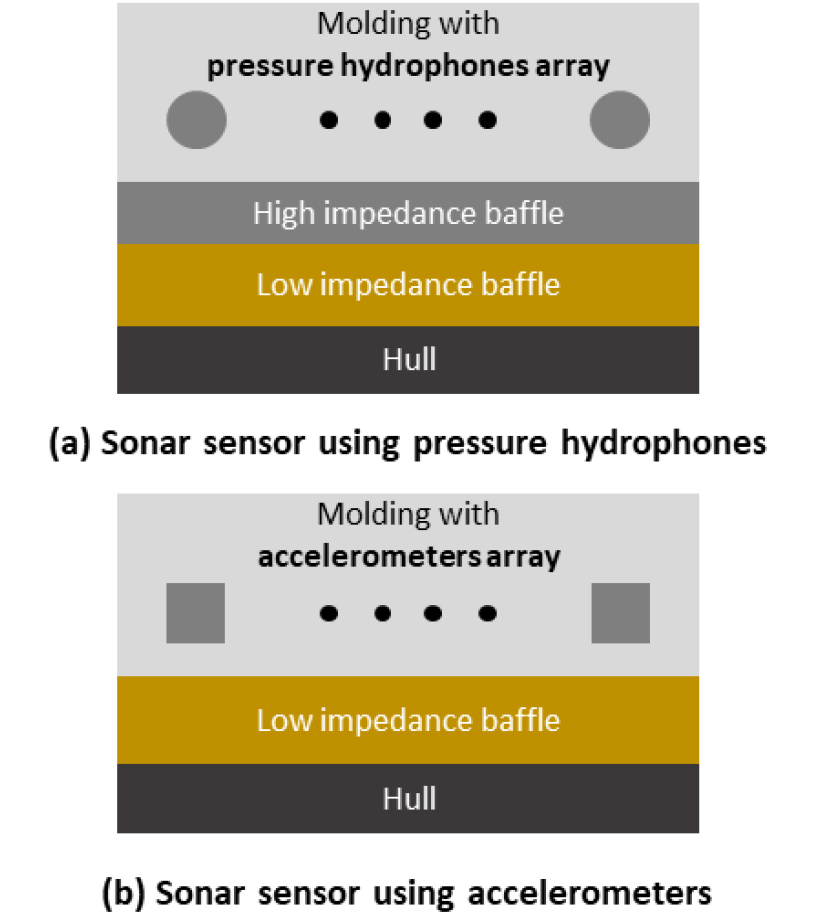
- For hull-mounted passive sonar systems, insulating self noise and vibration generated from the hull structure is critical to the sonar detection performance. To address this issue, recent researches have explored the integration of accelerometers alongside conventional acoustic sensors such as pressure hydrophones, in passive sonar applications. In this study, a hull-mounted passive sonar sensor utilizing accelerometers as acoustic sensors is developed, and its performance is evaluated in comparison with traditional passive sonar detecting acoustic pressure. The accelerometers are designed, fabricated and tested at the level of a single element, accelerometers array, and sonar sensor module including baffle structure, and their results are compared with predicted finite element analysis results. The proposed accelerometer-based sonar sensor demonstrates better performance than conventional pressure hydrophone-based sonar sensor, particularly when compared in terms of noise insulation which evaluated as difference between front and rear sensitivities. It also shows good possibility to minimize weight and thickness of the sonar module, which could be very important factor in ship design viewpoint.
- COLLAPSE
선체부착형 수동소나는 탐지 성능을 향상시키기 위해 후방에서 발생하는 함내 소음 및 진동을 효과적으로 차단하는 것이 중요하다. 이를 위해 최근 기존의 음향센서와 더불어 가속도계를 적용한 수동 소나에 대한 연구가 진행 중이다. 본 논문에서는 가속도계 기반의 선체부착형 수동 소나센서를 설계 및 제작하여 기존의 음압 감지식 하이드로폰을 사용한 소나센서와 비교하여 성능을 검증하였다. 개별 가속도계에서부터 가속도계 배열, 배플을 포함한 소나센서 모듈 단위까지 단계적으로 유한요소 해석을 통해 예측된 결과와 시험 결과와의 비교를 통해 가속도계 기반 소나센서의 수신 성능을 검증하였다. 또한 기존의 음압 하이드로폰 기반의 수동 소나센서와 비교하여 저주파 대역의 전후방 감도 차이에서 개선된 성능을 확인하였다. 이는 소나센서의 중량과 두께를 현저히 낮출 수 있기 때문에 함정 설계 측면에서도 상당한 이점이 된다.
-
Hull mounted passive sonar sensor based on accelerometers for improved low frequency detection
-
Research Article
-
Responses of passive sonar sensors to platform noise and vibration depending on sensed physical quantities
수동 소나센서의 감지 물리량에 따른 플랫폼 진동소음 수신 특성 비교
-
Eunghwy Noh, Woosuk Chang, Donghyeon Kim, Seonghun Pyo, and Kyungseop Kim
노응휘, 장우석, 김동현, 표성훈, 김경섭
- Platform noise is one of the major factors that degrade the detection performance of hull-mounted passive sonar sensors. The platform-side noise insulation …
플랫폼 소음은 선체부착형 수동 소나센서의 탐지성능을 저하시키는 주요 원인 중 하나이다. 현재까지의 소나센서는 대부분 수직입사 평면파 조건에서 후면소음 차단 성능을 평가해왔으나 실제 …
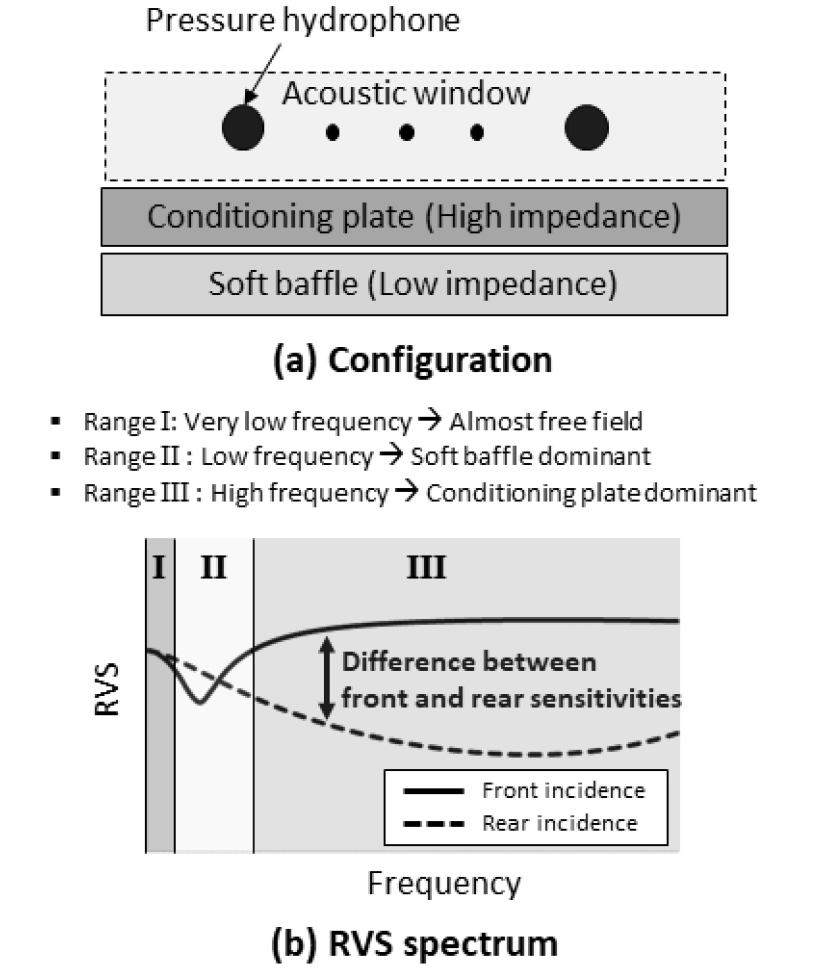
- Platform noise is one of the major factors that degrade the detection performance of hull-mounted passive sonar sensors. The platform-side noise insulation performance of most sonar sensors has been evaluated under normally incident plane wave conditions. However, vibration and noise in actual environments are generated in far more diverse and complex aspects, requiring further investigation. In this study, the sensitivities of two passive sonar sensors, one sensing acoustic pressure and the other sensing particle acceleration, are compared for different types of vibration and noise sources. First, the acoustic field induced by structural vibration is classified into progressive-wave and evanescent-wave regions according to its wavenumber. The differences in the relative magnitudes of the acoustic pressure and particle acceleration fields in these regions are verified through theoretical and finite element analyses. Subsequently, analyses using a model incorporating the platform structure confirm that the sensitivity of the sonar sensors to platform-side noise and vibration varies depending on the sensed physical quantities and the types of noise and vibration sources. The results show that, compared with the acoustic pressure sensing sonar sensor, the particle acceleration sensing sonar sensor exhibits lower sensitivity to normally incident plane waves with progressive field characteristics, but higher sensitivity to vibration-induced noise with evanescent field characteristics generated by structural excitation.
- COLLAPSE
플랫폼 소음은 선체부착형 수동 소나센서의 탐지성능을 저하시키는 주요 원인 중 하나이다. 현재까지의 소나센서는 대부분 수직입사 평면파 조건에서 후면소음 차단 성능을 평가해왔으나 실제 플랫폼 장착 환경에서의 소음은 훨씬 다양하고 복합적으로 발생하므로 이에 대한 추가적인 검토가 필요하다. 본 논문에서는 각각 음압과 입자가속도를 감지하는 두 종류의 수동 소나센서를 대상으로 진동소음의 유형에 따른 민감도를 비교하였다. 먼저 플랫폼 진동으로 인해 형성되는 음향장을 그 파수에 따라 진행파 영역과 소멸파 영역으로 구분하고, 각 영역에서 음압장과 입자가속도장의 상대적 크기가 다르게 나타남을 이론적 분석과 유한요소해석을 통해 검증하였다. 이후 플랫폼을 포함한 모델에 대해서도 소나센서의 후면 진동소음 민감도가 감지 물리량과 진동소음원의 유형에 따라 상이하게 나타남을 확인하였다. 결과적으로 음압 감지 방식의 소나센서에 비해 입자가속도 감지 방식의 소나센서가 진행파 특성을 가지는 수직입사 평면파에는 낮은 민감도를 보이는 반면, 구조 가진에 의해 생성되는 소멸파 특성의 진동 유기소음에 대해서는 높은 민감도를 나타내었다.
-
Responses of passive sonar sensors to platform noise and vibration depending on sensed physical quantities
-
Research Article

-
Quantitative evaluation of acoustic coupling characteristics and near field high echo artifacts in pad type ultrasound coupling materials
패드형 초음파 전달매질의 음향 결합 균질성과 근거리 경계면 허상 특성 평가
-
Ki-Seon Jeon
전기선
- This study quantitatively compared the ultrasound image quality and near field high echo artifact characteristics of four acoustic coupling materials — conventional …
본 연구는 일반 초음파 겔, HydroAid®, Aquaflex®, Bolx-II®의 네 가지 패드형 초음파 전달 매질의 초음파 영상 품질과 근거리 고에코 허상 특성을 정량적으로 …
- This study quantitatively compared the ultrasound image quality and near field high echo artifact characteristics of four acoustic coupling materials — conventional ultrasound gel, HydroAid®, Aquaflex®, and Bolx-II® — under identical imaging conditions. Three ex vivo tissue samples (beef rump, pork loin, pork tenderloin) were scanned under four coupling conditions: conventional ultrasound gel, HydroAid®, Aquaflex®, and Bolx-II®, all pad-type materials standardized to 1 cm stand off thickness, using a linear transducer at 12 MHz. Acoustic Coupling Homogeneity Index (ACHI), Contrast-to-Noise Ratio (CNR), and High-Echo Artifact Fraction (HEAF) were calculated from standardized regions of interest. Inter group differences were assessed using one way Analysis of Variance (ANOVA) or Kruskal–Wallis tests with post hoc correction. HydroAid® and Aquaflex® generally showed higher ACHI and CNR than Bolx-II® across all tissue samples (all p < 0.001). However, HydroAid® generated the highest HEAF in all samples (up to 42.55 % ± 6.77 %), while conventional gel and Bolx-II® remained near zero, indicating that coupling efficiency and near field artifact generation are independent material properties. Aquaflex® provided the most favorable balance between image quality and near field artifact suppression, suggesting its suitability as a pad-type coupling material for superficial ultrasound examinations.
- COLLAPSE
본 연구는 일반 초음파 겔, HydroAid®, Aquaflex®, Bolx-II®의 네 가지 패드형 초음파 전달 매질의 초음파 영상 품질과 근거리 고에코 허상 특성을 정량적으로 비교하고자 하였다. 소 우둔, 돼지 등심, 돼지 안심의 세 가지 ex vivo 생체 조직 시료를 대상으로, 일반 초음파 겔, HydroAid®, Aquaflex®, Bolx-II®의 네 가지 전달 매질 조건에서 B mode 초음파 영상을 획득하였으며, 패드형 전달 매질은 모두 1 cm 두께로 표준화하였다. 12 MHz 선형 탐촉자를 이용하여 영상을 획득하였으며, 표준화된 관심 영역에서 음향 결합 균질성 지수(Acoustic Coupling Homogeneity Index, ACHI), 대조도대잡음비(Contrast-to-Noise Ratio, CNR), 고에코 허상 비율(High-Echo Artifact Fraction, HEAF)을 산출하였다. 군 간 차이는 일원 분산분석(Analysis of Variance, ANOVA) 또는 크루스칼 왈리스 검정과 사후검정을 이용하여 분석하였다. HydroAid®와 Aquaflex®는 모든 조직 시료에서 Bolx-II®보다 유의하게 높은 ACHI 및 CNR 값을 보였다(p < 0.001). 그러나 HydroAid®는 모든 시료에서 가장 높은 HEAF를 나타냈으며, 최대값은 돼지 등심 시료에서 42.55 % ± 6.77 %였다. 반면 일반 초음파 겔과 Bolx-II®의 HEAF는 거의 0에 가까운 수준을 유지하였다. 이는 음향 결합 효율과 근거리 허상 발생이 서로 독립적인 재료 특성임을 시사한다. Aquaflex®는 영상 품질과 근거리 고에코 허상 억제 측면에서 가장 균형 잡힌 특성을 보여, 표재성 초음파 검사에서 활용 가능한 패드형 전달 매질로서의 유용성이 기대된다.
-
Quantitative evaluation of acoustic coupling characteristics and near field high echo artifacts in pad type ultrasound coupling materials
-
Research Article
-
Vibration and radiated noise estimation of an induction motor by using modal expansion method
모드 확장법을 이용한 유도 전동기의 진동 및 방사소음 예측
-
Changju Hwang, Wangki Seo, Kyungjun Song
황창주, 서왕기, 송경준
- This study proposes and validates a Modal Expansion Method (MEM) based prediction approach for estimating the vibration and radiated noise characteristics of …
본 연구에서는 운전 중인 유도 전동기의 진동 및 방사소음 특성을 규명하기 위해, 실험 데이터와 해석 모델을 결합한 모드 확장법(Modal Expansion Method, MEM) …
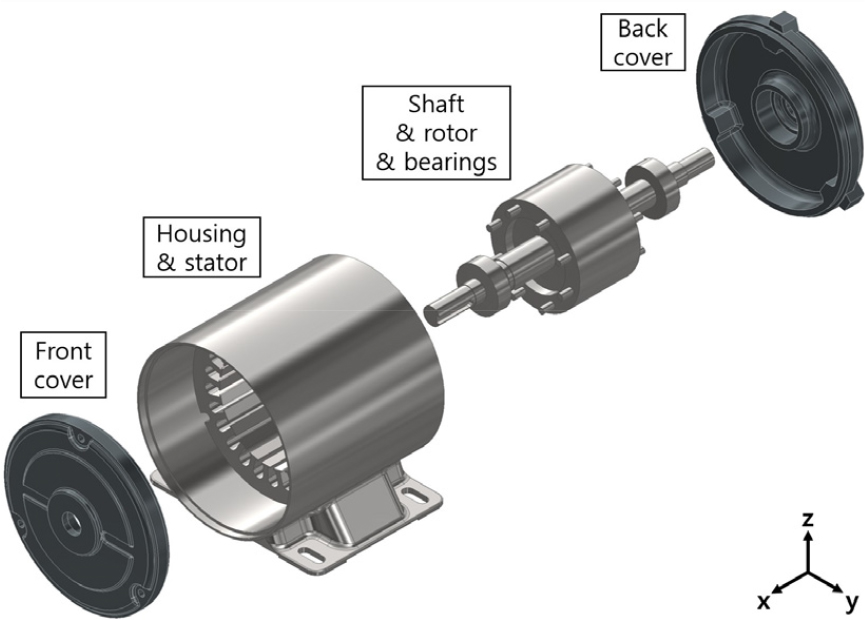
- This study proposes and validates a Modal Expansion Method (MEM) based prediction approach for estimating the vibration and radiated noise characteristics of an induction motor under operating conditions. The proposed method combines experimentally measured vibration responses with a finite element model. Experimental Modal Analysis (EMA) was first conducted to identify reliable structural modes, and the finite element model was validated by comparing experimental and numerical mode shapes using the Modal Assurance Criterion (MAC). The selected mode shapes and Operational Deflection Shape (ODS) data measured during motor operation were then used to estimate the Modal Participation Factor (MPF) from measured acceleration responses. Using the estimated modal contributions, the vibration response over the entire motor surface, including unmeasured regions, was reconstructed. The reconstructed surface vibration field was applied as an acoustic excitation source in a finite element–based structural·acoustic coupled analysis to predict the radiated noise. Finally, the predicted vibration and noise results were compared with experimental measurements to verify the accuracy of the proposed method. The results indicate that the MEM-based approach can effectively predict the vibration and radiated noise of an operating induction motor and can be used as a quantitative tool for low-vibration and low-noise motor design.
- COLLAPSE
본 연구에서는 운전 중인 유도 전동기의 진동 및 방사소음 특성을 규명하기 위해, 실험 데이터와 해석 모델을 결합한 모드 확장법(Modal Expansion Method, MEM) 기반의 예측 기법을 제안하고 그 유효성을 검증하였다. 먼저, 신뢰성 있는 모드 선정을 위해 실험 모드 해석을 수행하였으며, 실험과 해석 간의 모드 상관 계수(Modal Assurance Criterion, MAC) 비교를 통해 해석 모델의 타당성을 검토하였다. 이후, 선정된 모드 형상과 운전 변형 형상(Operational Deflection Shape, ODS)을 활용한 계측 가속도로부터 각 절점의 기여도를 산정하였고, 이를 바탕으로 미계측 지점을 포함한 전동기 표면 전체의 진동 거동을 예측하였다. 예측된 진동장을 음원으로 적용하여 유한요소법(Finite Element Method, FEM) 기반 구조·음향 연성 해석을 수행하였으며, 이를 통해 방사소음을 예측하였다. 최종적으로 예측과 실험 결과 간의 상관성 분석을 통해 제안한 기법의 정확성을 검증하였다. 본 연구 결과는 유도 전동기의 저진동·저소음 설계를 위한 정량적 설계 기반 자료로 활용될 수 있을 것으로 기대된다.
-
Vibration and radiated noise estimation of an induction motor by using modal expansion method
-
Research Article
-
Investigation of seasonal changes in the soundscape of Musimcheon in Cheongju
청주시 무심천의 계절별 음풍경 변화 조사
-
Tae-Hyung Lee and Chan-Hoon Haan
이태형, 한찬훈
- This study investigated seasonal changes in the soundscape of Musimcheon in Cheongju. Five frequently used sites with different spatial characteristics were selected …
본 연구는 청주시 무심천의 계절 변화에 따른 음풍경 변화를 조사하기 위하여 4계절 동안 조사를 수행하였다. 이를 위해 이용률이 높고 장소적 특성이 다른 …
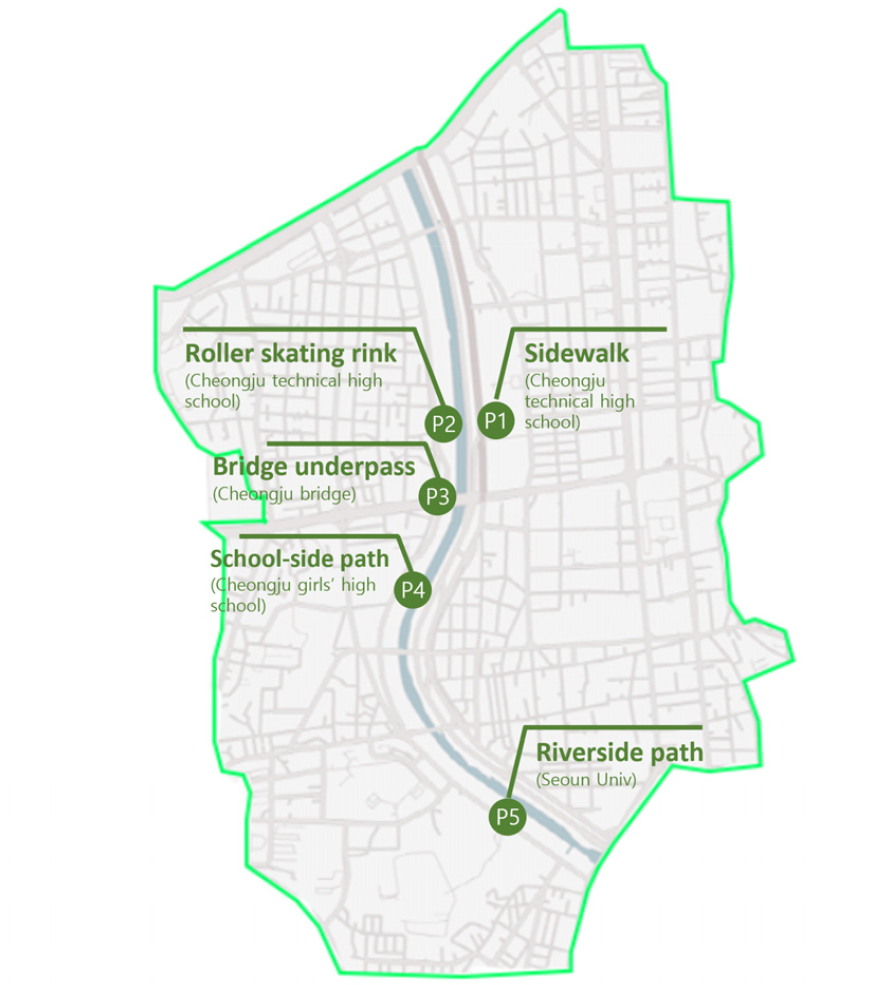
- This study investigated seasonal changes in the soundscape of Musimcheon in Cheongju. Five frequently used sites with different spatial characteristics were selected through a preliminary survey, and questionnaires were collected from participants aged 13 to 82, with 90 collected in spring, 180 in summer, 120 in autumn, and 90 in winter. Respondents rated perceived loudness and annoyance on a five point scale and selected up to three sounds for the loudest, most annoying, most preferred and place representative categories. Natural sounds were generally evaluated as more pleasant than mechanical sounds, with seasonal differences. In winter, the relationship between perceived loudness and annoyance for natural sounds was relatively weak, whereas mechanical sounds showed relatively high correlations across all seasons. Representative and preferred sounds varied with site characteristics and seasonal changes: traffic sounds at roadside sites, stream sounds at riverside sites, and birdsong, wind sounds, and insect sounds at reed dominated sites. Therefore, mechanical sound reduction and site specific soundscape management are considered necessary for improving the acoustic environment of the Musimcheon walking trail.
- COLLAPSE
본 연구는 청주시 무심천의 계절 변화에 따른 음풍경 변화를 조사하기 위하여 4계절 동안 조사를 수행하였다. 이를 위해 이용률이 높고 장소적 특성이 다른 5개 지점을 선정하였으며, 사전조사를 통해 각 지점의 장소적 특성을 파악하였다. 또한 방문객과 건축공학과 학부생을 포함하여 13세부터 82세까지 봄 90부, 여름 180부, 가을 120부, 겨울 90부의 설문을 수집하였다. 응답자는 소리의 크기와 불쾌감을 5점 척도로 평가하고, 계절별 소리 예시 항목에서 ‘가장 크게 들리는 소리’, ‘가장 불쾌하게 들리는 소리’, ‘가장 듣기 좋은 소리’, ‘이 장소를 대표하는 소리’를 최대 3순위까지 선택하도록 하여 지점, 계절별 소리 유형의 차이를 분석하였다. 소리의 크기와 불쾌감의 상관관계 분석 결과, 자연음은 전반적으로 기계음에 비해 쾌적하게 평가되었으며 계절에 따라 차이가 나타났다. 겨울에는 자연음의 소리의 크기와 불쾌감 간 관계가 비교적 약하게 나타났으며, 기계음은 전 계절에서 비교적 강한 상관관계를 보여 계절과 무관하게 우선 고려되어야 함을 확인하였다. 대표음과 선호음의 구성은 지점의 장소적 특성과 계절 변화에 따라 달라졌으며 도로변 지점에서는 자동차 운행 소리, 하천 지점에서는 하천 소리, 갈대 군락 지점에서는 새소리, 바람 소리, 곤충 소리가 주로 나타나 무심천의 장소적 특성이 계절별 음풍경 변화에 반영됨을 확인하였다. 이에 무심천의 계절별 음풍경 변화는 소리의 크기뿐 아니라 장소적 특성과 계절에 따른 자연음 구성 변화에 의해 형성되는 것으로 판단되며 무심천의 산책로 음환경 개선을 위해서는 기계음 저감과 지점별 특성을 고려한 음풍경 관리가 필요할 것으로 판단된다.
-
Investigation of seasonal changes in the soundscape of Musimcheon in Cheongju
-
Research Article
-
Development and application of the timbre interface for emotion modulation: Timbre exploration behavior and emotional change in university students
음색 기반 정서 조율 인터페이스의 개발과 적용: 대학생의 음색 탐색행동과 정서 변화를 중심으로
-
Minkyung Kwon and Eunju Jeong
권민경, 정은주
- The purpose of this study was to develop the Timbre Interface for Emotion Modulation (TIEM) and to examine whether timbre exploration behavior …
본 연구의 목적은 음색 기반 정서 조율 인터페이스(Timbre Interface for Emotion Modulation, TIEM)를 개발하고, 음색 탐색행동이 개인의 정서적 특성을 예측하는지, 그리고 음색 …
- The purpose of this study was to develop the Timbre Interface for Emotion Modulation (TIEM) and to examine whether timbre exploration behavior predicts individual emotion-related psychological characteristics, and whether emotional changes before and after improvisation differ between the timbre-modulated and original-timbre conditions. A crossover design was applied to 24 female undergraduate students (M = 21.58 years, SD = 1.61). All participants first explored timbre on the TIEM and then performed improvisation under both the timbre-modulated condition and the original-timbre condition. Hierarchical regression analyses showed that the Box-Cox-transformed variance reduction rate was significantly and negatively correlated with the Toronto Alexithymia Scale (TAS-20) score (r = –0.546, p = 0.006) and significantly predicted the TAS-20 score when entered alone in the model (R2 = 0.298, p = 0.006). For the Center for Epidemiologic Studies Depression Scale (CES-D), a model including both the dwell ratio and the Box-Cox-transformed variance reduction rate was significant (R2 = 0.258, p = 0.043), and a suppressor effect was obsered between the two predictors. A linear mixed-model analysis revealed that, after controlling for CES-D and TAS-20 as covariates, the timbre-modulated condition showed a 3.04-point greater reduction in negative affect than the original-timbre condition (B = –3.04, p = 0.004, Cohen’s d = 0.58, marginal R2 = 0.780), whereas no significant between-condition difference was found in positive affect change (p = 0.556). These findings indicate that the variance reduction rate and dwell ratio among timbre exploration behaviors may serve as behavioral data reflecting individual emotion-related psychological characteristics, and that timbre-modulated improvisation may be associated with greater reductions in negative affect than original-timbre improvisation.
- COLLAPSE
본 연구의 목적은 음색 기반 정서 조율 인터페이스(Timbre Interface for Emotion Modulation, TIEM)를 개발하고, 음색 탐색행동이 개인의 정서적 특성을 예측하는지, 그리고 음색 조정 조건과 원음색 조건에서의 즉흥연주 전후 정서 변화에 차이가 나타나는지를 탐색하는 데에 있다. 여성 대학생 24명(평균 = 21.58세, 표준편차 = 1.61)을 대상으로 교차설계를 적용하였으며, 모든 참여자는 TIEM에서 음색을 탐색한 후 음색 조정 조건과 원음색 조건에서 즉흥연주를 수행하였다. 위계적 회귀분석 결과, 변환된 분산감소율은 토론토 감정표현불능 척도(Toronto Alexithymia Scale, TAS-20)와 유의한 부적 상관을 보였으며(r = –0.546, p = 0.006), 단독 투입 모형에서 토론토 감정표현불능 척도를 유의하게 예측하였다(R2 = 0.298, p = 0.006). 역학연구센터 우울 척도(Center for Epidemiologic Studies Depression Scale, CES-D)에서는 머무름비율과 변환된 분산감소율을 함께 포함한 모형이 유의하였으며(R2 = 0.258, p = 0.043), 두 변인 간 억제변수 효과가 관찰되었다. 선형혼합모형 분석에서는 역학연구센터 우울 척도와 토론토 감정표현불능 척도를 공변량으로 통제한 이후에도 음색 조정 조건이 원음색 조건 대비 부적 정서를 평균 3.04점 더 감소하는 양상이 나타났다(B = –3.04, p = 0.004, Cohen’s d = 0.58, marginal R2 = 0.780). 반면 정적 정서 변화에서는 조건 간 유의한 차이가 나타나지 않았다(p = 0.556). 본 연구의 결과는 음색 탐색행동 중 분산감소율과 머무름비율이 감정 인식 및 표현의 어려움과 우울 수준을 반영하는 행동 자료로 활용될 수 있으며, 음색 조정 기반 즉흥연주가 원음색 기반 즉흥연주에 비해 부적 정서 감소와 관련될 수 있음을 의미한다.
-
Development and application of the timbre interface for emotion modulation: Timbre exploration behavior and emotional change in university students
-
Research Article
-
Approximation of a nonlinear constraint for active sonar reverberation suppression algorithm based on non-negative matrix factorization
비음수 행렬 분해 기반의 능동소나 잔향 제거 알고리즘에 대한 비선형 제약 조건의 근사 기법
-
Seokjin Lee
이석진
- In this paper, a study is conducted to improve computational complexity in order to enhance the applicability of a Non-negative Matrix Factorization …
본 논문에서는 능동소나 시스템을 위한 비음수 행렬 분해(Non-negative Matrix Factorization, NMF) 기반의 잔향 제거 기법의 활용도를 높이기 위해 연산 복잡도를 개선하는 연구를 …
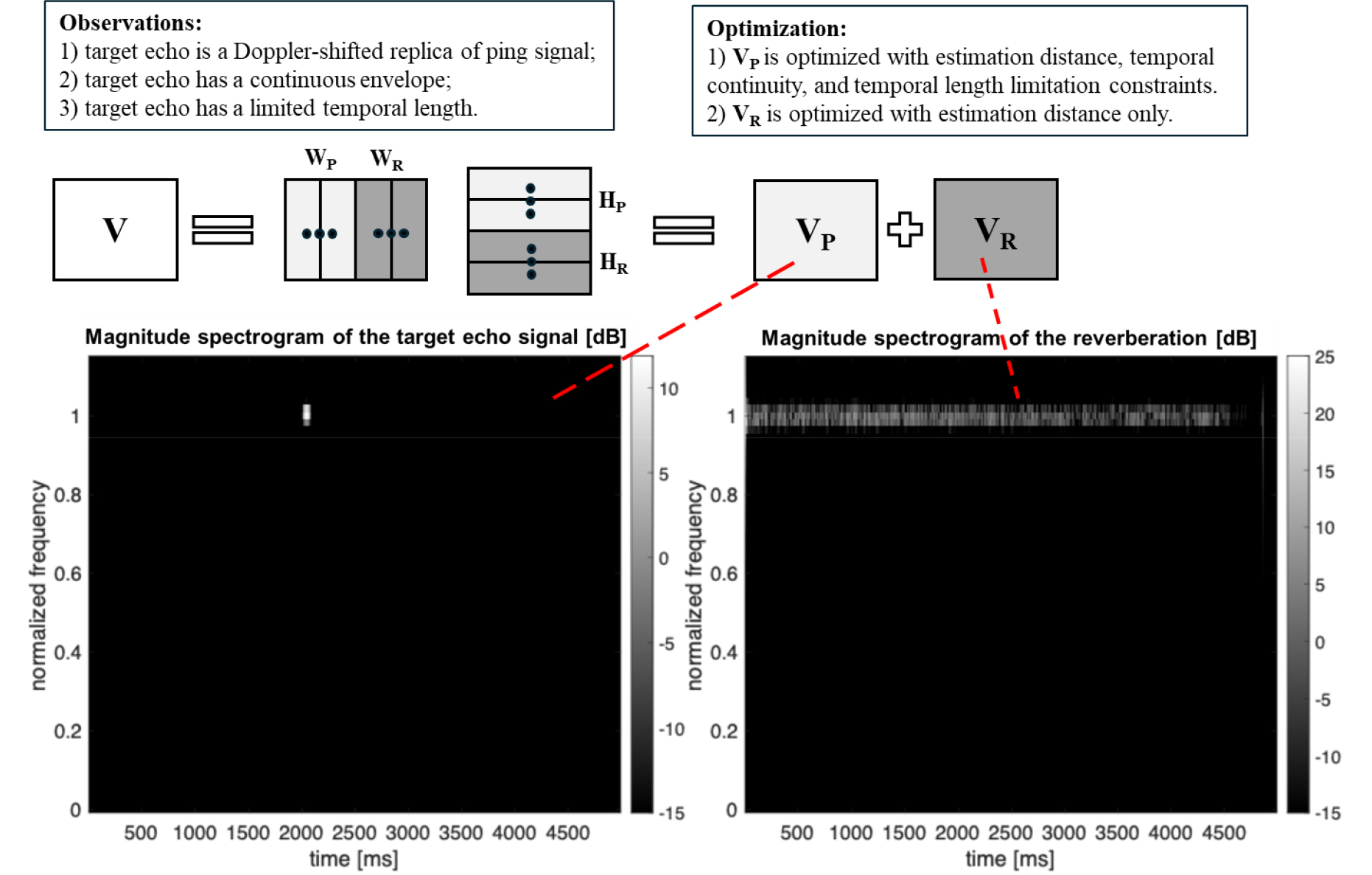
- In this paper, a study is conducted to improve computational complexity in order to enhance the applicability of a Non-negative Matrix Factorization (NMF)-based reverberation suppression method for the active sonar system. To deploy such methods on real hardware, computational complexity must be low; however, conventional NMF-based approaches involve exponential operations in their computational process. Since nonlinear operations such as exponential functions require relatively high computational or memory complexity when implemented on hardware, it is desirable that deployable algorithms be composed only of linear operations such as multiplication and addition. To address this issue, a new constraint formulation is derived by applying a Maclaurin approximation to the exponential function in the time-length constraint operation, and an additional method is proposed to satisfy the approximation condition by exploiting the scale ambiguity of NMF. Simulation results confirm that the proposed approximation-based method achieves performance comparable to the conventional approach, while requiring significantly reduced computation time (approximately 54.8 ms) compared to the time-length constraint using a standard exponential implementation (approximately 216.5 ms).
- COLLAPSE
본 논문에서는 능동소나 시스템을 위한 비음수 행렬 분해(Non-negative Matrix Factorization, NMF) 기반의 잔향 제거 기법의 활용도를 높이기 위해 연산 복잡도를 개선하는 연구를 진행하였다. 능동소나 잔향 제거 기법을 실제 장비에 탑재하려면 연산 복잡도가 크지 않아야 하는데, 기존의 비음수 행렬 분해에 기초한 능동소나 잔향 제거 기법은 그 연산 과정이 지수함수 연산을 포함하고 있다는 문제가 있다. 지수함수와 같은 비선형 연산은 장비에 탑재할 때 상대적으로 높은 연산 복잡도 혹은 메모리 복잡도를 요구하기 때문에, 대부분의 장비 탑재 알고리즘은 가능한 곱셈 및 덧셈과 같은 선형 연산으로만 구성되는 것이 바람직하다. 본 논문에서는 이를 해결하기 위하여 시간 길이 제한 제약 조건 연산 과정의 지수함수에 매클로린 근사를 적용하여 새로운 제약 조건 연산식을 도출하였으며, 비음수 행렬 분해의 스케일 모호성을 활용하여 근사 조건을 만족시키는 방법을 추가로 도출하였다. 시뮬레이션을 통하여 제안하는 근사가 적용된 기법이 기존의 기법과 성능이 유사함을 확인하였으며, 일반적인 지수함수 구현 방법을 활용한 시간 길이 제한 제약 조건(약 216.5 ms) 대비 유의미하게 감소된 연산시간(약 54.8 ms) 이 소요됨을 확인하였다.
-
Approximation of a nonlinear constraint for active sonar reverberation suppression algorithm based on non-negative matrix factorization
-
Research Article

-
Rotor unbalance diagnosis method using vision based orbit and phase analyses
비전 기반 궤도 및 위상 분석을 이용한 회전체 불균형 진단
-
Eunjin Jo and Sung-Hwan Shin
조은진, 신성환
- This paper proposes a practical non-contact unbalance diagnosis method for rotating machinery using a single camera to overcome the limitations of conventional …
본 논문은 기존 멀티 센서 시스템의 제약을 극복하기 위해, 단일 카메라를 활용한 실용적인 비접촉식 회전체 불균형 진단 기법을 제안한다. 불균형 진단 알고리즘을 …
- This paper proposes a practical non-contact unbalance diagnosis method for rotating machinery using a single camera to overcome the limitations of conventional multi-sensor systems. An unbalance diagnosis algorithm was developed to extract two-dimensional shaft orbits at a sub-pixel level through autonomous Region of Interest (ROI) tracking and centroid calculation. Principal Component Analysis (PCA) and Fast Fourier Transform (FFT) were utilized to identify the principal vibration axis and frequency characteristics. The magnitude of the unbalance mass was inversely estimated by correlating the Root Mean Square (RMS) of the displacement response with the static stiffness model of the system. Furthermore, the physical radial direction of the unbalance mass on a shaft was identified without additional sensors by synchronizing the major axis direction of the orbit with the image phase information. Experimental results at 240 r/min demonstrated that the system could capture a minute displacement increase of 0.11 mm, estimating a micro-unbalance mass, which represents only 0.84 % of the total rotor assembly mass, with an error of less than 9 %. This study demonstrates that the magnitude and direction of unbalance can be accurately estimated without complex multi-sensor systems, providing a practical alternative for efficient on-site balancing and predictive maintenance through vision-based measurement.
- COLLAPSE
본 논문은 기존 멀티 센서 시스템의 제약을 극복하기 위해, 단일 카메라를 활용한 실용적인 비접촉식 회전체 불균형 진단 기법을 제안한다. 불균형 진단 알고리즘을 개발하여 관심영역(Region of Interest, ROI) 자동 추적 및 무게중심 산출법으로 2차원 축심 궤도를 서브 픽셀 단위로 추출하고, 주성분 분석(Principal Component Analysis, PCA)과 고속 푸리에 변환(Fast Fourier Transform, FFT) 분석을 통해 진동의 주축 방향과 주파수 특성을 규명하였다. 변위 응답의 실효치(Root Mean Square, RMS)를 시스템의 정적 강성 모델과 연계하여 불균형 질량의 크기를 역산하였으며, 궤도의 장축 방향과 이미지 위상 정보를 동기화하여 별도의 추가 센서 없이 불균형 질량의 물리적 방향을 식별하였다. 240 r/min 조건의 실험 결과, 0.11 mm의 미세 변위 증가를 포착하여 전체 회전부 질량 대비 단 0.84 %에 불과한 미소 불균형 질량을 9 % 이내의 오차로 추정하고, 그 방향을 정확히 식별하였다. 본 연구는 별도의 멀티 센서 시스템 없이도 불균형 질량의 크기와 방향 추정이 가능함을 입증하였으며, 비전 기반 계측을 활용한 효율적인 현장 밸런싱 및 예지 보전의 실용적 대안을 제시하였다.
-
Rotor unbalance diagnosis method using vision based orbit and phase analyses
-
Research Article
-
Neural network based office noise classification via sub frame division and majority voting
서브 프레임 분할과 다수결 투표를 활용한 신경망 기반 사무실 소음 분류
-
Sanghyeok Park, Minhan Kim, Seunghyeon Shin, Naheun Song, and Seokjin Lee
박상혁, 김민한, 신승현, 송나흔, 이석진
- Accurate noise classification is essential for the effective operation of sound masking systems. However, noise signals recorded in real office environments are …
사운드 마스킹 시스템의 효과적인 운용을 위해서는 환경 소음을 정확하게 분류하는 기술이 요구된다. 그러나 실제 사무실 환경에서 획득한 소음 신호는 잔향, 배경 소음, …
- Accurate noise classification is essential for the effective operation of sound masking systems. However, noise signals recorded in real office environments are easily distorted by reverberation, background noise, and overlapping acoustic events, which can degrade the performance of conventional whole clip classification methods. In addition, office noise often contains temporally correlated or repetitive patterns rather than isolated events, indicating that both local acoustic cues and global temporal context should be considered. To address these issues, this study proposes an office noise classification framework that combines a Conformer based classifier for modeling temporal dependency with sub frame segmentation and majority voting based post processing to alleviate the influence of distortions in real world recordings. Experimental results show that the proposed method provides more accurate and stable classification performance than both a Convolutional Neural Network (CNN) based baseline model and a single clip Conformer model. These results indicate that the Conformer effectively captures temporal relations in office noise signals, while the sub frame based inference strategy mitigates the influence of distortion in real world data.
- COLLAPSE
사운드 마스킹 시스템의 효과적인 운용을 위해서는 환경 소음을 정확하게 분류하는 기술이 요구된다. 그러나 실제 사무실 환경에서 획득한 소음 신호는 잔향, 배경 소음, 중첩된 음향 이벤트 등의 영향으로 왜곡되기 쉬우며, 이러한 특성은 기존의 전체 클립 단위 분류 방식에서 성능 저하를 유발할 수 있다. 또한 실제 사무실 소음은 단발적인 사건만으로 구성되기보다 시간상으로 연관되거나 반복되는 패턴을 포함하므로, 국소적 특징뿐 아니라 시간 축 전반의 문맥 정보도 함께 반영할 필요가 있다. 본 연구에서는 이러한 점을 고려하여, 시간적 연관성을 반영할 수 있는 Conformer 기반 분류기와 실 환경 데이터의 왜곡 영향을 완화하기 위한 서브 프레임 분할 및 다수결 후처리 전략을 결합한 사무실 소음 분류 프레임워크를 제안하였다. 실험 결과, 제안한 방법은 기존 합성곱 신경망(Convolutional Neural Network, CNN) 기반 모델 및 단일 클립 기반 Conformer 모델보다 더 높은 정확도와 안정적인 분류 성능을 나타냈다. 이는 Conformer가 소음 신호의 시간적 연관성을 효과적으로 반영하고, 서브 프레임 기반 추론이 실 환경 데이터의 왜곡 영향을 완화하는 데 유효함을 보여준다.
-
Neural network based office noise classification via sub frame division and majority voting
-
Research Article
-
Performance comparison of four DFT interpolation techniques for accurate fundamental frequency analysis of harmonic signals
배음 신호의 정밀한 기본주파수 분석을 위한 네 가지 DFT 보간 기법의 성능 비교
-
Hee-Suk Pang
방희석
- When analyzing the fundamental frequency of a harmonic signal based on the Discrete Fourier Transform (DFT), a fine frequency estimation method should …
배음 신호의 기본주파수를 이산 푸리에 변환(Discrete Fourier Transform, DFT)에 기반해서 분석할 경우, 추정 에러를 최소화하기 위해서 정밀한 주파수 추정 방법을 사용해야 한다. …
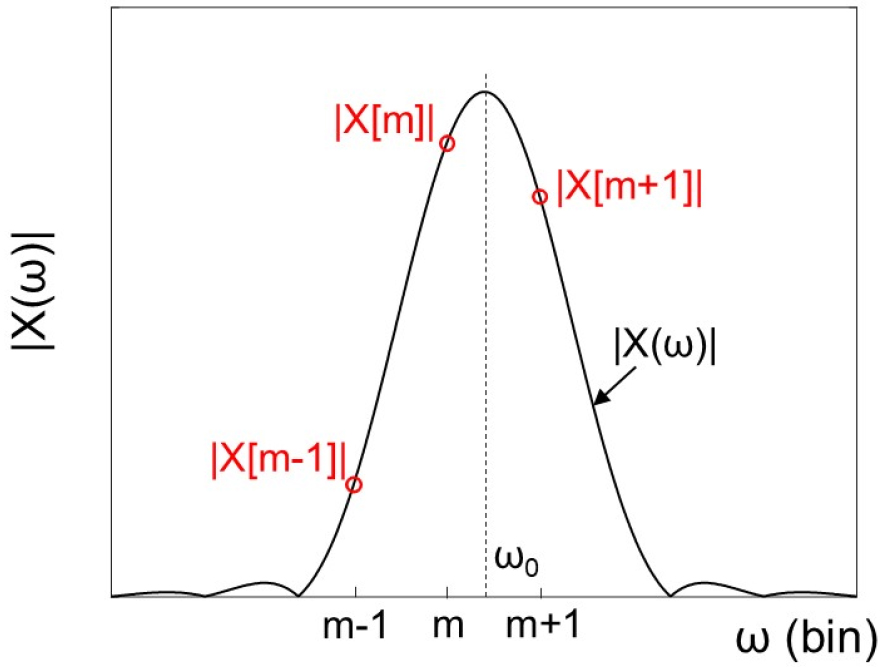
- When analyzing the fundamental frequency of a harmonic signal based on the Discrete Fourier Transform (DFT), a fine frequency estimation method should be applied to minimize the estimation error. For this purpose, we qualitatively analyzed the characteristics of the estimation errors for DFT interpolation techniques such as Quadratic Fit (QF), Interpolated Fast Fourier Transform (IFFT), Weighted Multipoint Interpolated DFT (WMIDFT), and Corrected Quadratically Interpolated FFT (CQIFFT), and compared the performance of each method using simulation experiments and recorded flute sound. The results showed that the optimal method varied depending on the fundamental frequency, Signal to Noise Ratio (SNR), and number of harmonics. CQIFFT required an additional computational load compared to the other techniques, but performed well either at low SNR or when the SNR is high and the influence of harmonics was weak, such as when the fundamental frequency was high or the signal consisted of a single sinusoid. WMIDFT was effective when the fundamental frequency was low at high SNR, and IFFT outperformed WMIDFT at low SNR. The results are expected to be helpful in selecting a DFT interpolation technique for fundamental frequency estimation.
- COLLAPSE
배음 신호의 기본주파수를 이산 푸리에 변환(Discrete Fourier Transform, DFT)에 기반해서 분석할 경우, 추정 에러를 최소화하기 위해서 정밀한 주파수 추정 방법을 사용해야 한다. 이를 위해서 DFT 보간 기법인 2차 피팅(Quadratic Fit, QF), Interpolated Fast Fourier Transform(IFFT), Weighted Multipoint Interpolated DFT(WMIDFT), Corrected Quadratically Interpolated FFT(CQIFFT)에 대해 주파수 추정 에러의 특성을 정성적으로 분석하고, 모의 실험 및 녹음된 플루트음을 이용해 각 보간 기법의 성능을 비교하였다. 그 결과 각 보간 기법들은 기본주파수, 신호대잡음비(Signal to Noise Ratio, SNR), 배음의 수 등에 따라서 최적의 방법이 달라지는 것으로 나타났다. CQIFFT는 다른 방법들에 비해 연산량이 더 많으며, 신호대잡음비가 낮은 경우 혹은 신호대잡음비가 높고 기본주파수가 상대적으로 높거나 단일 정현파로 구성되는 등 배음의 영향이 작은 경우 성능이 좋았다. WMIDFT는 신호대잡음비가 높고 기본주파수가 낮은 경우 성능이 좋았으며, IFFT는 신호대잡음비가 낮은 경우 WMIDFT보다 좋은 성능을 보였다. 이상의 결과는 배음 신호의 기본주파수를 추정하기 위해 DFT 보간 기법을 선택하는 데 도움이 될 것으로 기대한다.
-
Performance comparison of four DFT interpolation techniques for accurate fundamental frequency analysis of harmonic signals

Journal Informaiton
 The Journal of the Acoustical Society of Korea
The Journal of the Acoustical Society of Korea
The Journal of the Acoustical Society of Korea










한국음향학회
Room 1619, 280, Gwangpyeong-ro, Gangnam-gu, Seoul 06367 Republic of Korea
Tel: +82-2-565-1625, +82-2-556-3513 / Fax: +82-2-569-9717 / E-mail: nonmun@ask.or.kr Copyright© The Acoustical Society of Korea. Powered by APUB
Tel: +82-2-565-1625, +82-2-556-3513 / Fax: +82-2-569-9717 / E-mail: nonmun@ask.or.kr Copyright© The Acoustical Society of Korea. Powered by APUB

한국음향학회지는 KCI, ESCI, Scopus
등재저널입니다.



CLOSE

한국음향학회지는 KCI, ESCI, Scopus
등재저널입니다.
CLOSE