

I. 서 론
II. 기존 연구
2.1 자동 음성 인식
2.2 오디오 태깅
2.3 위급 상황 탐지
2.4 실시간 처리
III. 제안한 모델
3.1 개선된 Whisper-AT
3.2 Whisper-MLP
3.3 Whisper-ESD
IV. 실험 방법
4.1 데이터셋 구축
4.2 실험 방법
V. 실험 결과
5.1 실험 1: Whisper-AT와 Whisper-ESD의 성능 비교
5.2 실험 2: Whisper 모델 동시 학습 여부에 따른 성능 비교
5.3 실험 3: 모델 구조 변화에 따른 성능 비교
5.4 Whisper-ESD(𝜆=1)의 결과 시각화
5.5 Whisper-ESD(𝜆=1)의 분류 정확도
5.6 실험 4: 저지연 처리가 가능한 Whisper-ESD 모델의 성능 확인
VI. 결 론
I. 서 론
최근 1인 가구와 노인 가구의 증가로 인해 위급 상황에 취약한 계층이 급증하고 있다. 특히 1인 가구에서 낙상 사고와 같은 위급 상황이 발생할 경우, 의식을 잃는 사고가 생기면 즉각적으로 대처하기 어려워 생명에 위협을 받을 수 있다. 이러한 문제를 해결하기 위해, 가정 내에서 위급 상황을 신속하게 감지하고 대응할 수 있는 시스템 구축의 필요성이 커지고 있다.
Whisper[1]는 OpenAI에서 개발한 자동 음성 인식 모델로, 현재 가장 우수한 성능을 보이는 모델 중 하나이다. Whisper Audio Tagging(Whisper-AT)[2]은 Whisper 모델의 각 레이어에 새로운 구조를 추가해서 자동 음성 인식과 오디오 태깅 작업을 동시에 수행할 수 있도록 설계된 모델이다. Whisper-AT 모델은 오디오 태깅의 종류를 분류하는 작업에 특화되어 있으나, 오디오 태깅의 특정 시점을 예측하는 데에는 한계가 있다. 그러나 위급 상황을 감지하는 시스템에서는 위급 상황이 발생한 정확한 시점의 파악이 매우 중요하다. 이에 따라 본 연구에서는 Whisper-AT의 구조를 수정하여 위급 상황을 분류하는 동시에 발생 시점을 보다 정밀하게 예측할 수 있는 모델로 개선하였다.
위급 상황으로 분류된 후, 해당 상황을 가족 또는 응급 구조 센터로 전송하는 시나리오에서는 자동 음성 인식 결과로 생성된 텍스트가 중요한 역할을 할 수 있다. 그리고 Whisper-AT에서는 Whisper가 높은 음성 인식 성능을 보이는 이유로 배경 음향을 풍부하게 학습한 점을 언급하고 있다.[2] 이러한 점들을 고려하여, 이 연구에서는 기존의 Whisper-AT 학습 방법과는 달리 위급 상황에서의 텍스트를 추가로 학습할 수 있도록 Whisper와 분류 모델을 동시에 미세 조정한다. 이를 통해 기존 Whisper가 학습하지 못했던 위급 상황에서의 배경 음향을 학습하고, 이 정보를 텍스트 예측에 활용할 수 있도록 한다. 본 연구는 Whisper를 단순히 미세 조정하는 것보다, 배경 음향 분류를 병행하여 미세 조정할 때 자동 음성 인식 성능 향상에 더욱 효과적임을 보여준다.
가정 내의 위급 상황을 신속하게 인식하기 위해서는 오디오를 실시간 또는 저지연으로 처리할 수 있는 모델을 설계할 필요가 있다. 그러나 Whisper 모델은 기본적으로 실시간 처리를 수행하지 못한다. 기존의 Whisper 모델은 30 s 길이의 오디오를 입력으로 받으므로 최소 30 s의 녹음 지연 시간이 발생하며, 여기에 오디오 전처리 및 모델 추론 시간을 포함하면 전체 지연 시간은 더욱 길어진다. 이러한 지연은 위급 상황에서 신속한 대응을 어렵게 만들 수 있다. 따라서 본 연구에서는 기존에 존재하는 알고리즘을 연구 목적에 알맞게 수정하여 적용함으로써, 약 4 s 내외의 지연 시간으로도 높은 정확도의 위급 상황 분류가 가능함을 입증한다.
II. 기존 연구
2.1 자동 음성 인식
자동 음성 인식은 사람의 음성을 인식하여 텍스트로 변환하는 기술로, 딥러닝 기술의 발전과 함께 지속적으로 새로운 모델이 개발되고 있다. Facebook AI에서 발표한 wav2vec 2.0[3]과 HuBERT[4]는 자기 지도 학습 기반의 자동 음성 인식 모델로서, 대규모 비지도 음성 데이터를 활용해 음성의 언어적 특징을 효과적으로 학습하여 높은 성능을 보였다. 반면, OpenAI의 Whisper[1]는 지도 학습 또는 자기 지도 학습을 사용하여 수십만 시간의 다국어 음성-텍스트 데이터를 학습하였다. Whisper는 Transformer 구조로 설계되었으며, 한국어를 포함한 다양한 언어에서 우수한 인식 성능을 보여준다. 또한 Whisper는 잡음환경에서도 높은 강인성을 보이며, 여러 상황에서의 일반화 능력이 뛰어난 것으로 평가된다.
2.2 오디오 태깅
오디오 태깅은 오디오 신호에서 특정 음향을 식별하여 해당 소리가 무엇인지 분류하는 기술이다. Hershey et al.[5]은 log-mel spectrogram을 입력으로 사용하고 Convolutional Neural Network(CNN) 구조를 이용하여 오디오 태깅을 수행하는 모델을 제안하였다. 또한, Audio Spectrogram Transformer(AST)[6]는 Vision Transformer(ViT) 구조를 채택하여 오디오 태깅 작업에 Transformer를 성공적으로 적용한 모델이다. Audio-MAE[7]는 Masked Autoencoder를 오디오 태깅에 적용하여 뛰어난 성능을 보였다.
Whisper-AT[2]는 OpenAI의 Whisper 모델을 기반으로, 기존 자동 음성 인식 기능을 유지하면서 동시에 오디오 태깅 작업을 수행할 수 있도록 확장된 모델이다. Whisper 모델이 잡음 환경에서 강인성을 갖는 이유는 흔히 중간 표현이 소음에 불변하는 특성을 가졌기 때문으로 설명되지만, Whisper-AT 논문에서는 이와 다르게 Whisper가 소음의 변화를 효과적으로 감지하여 음성을 인식한다고 보고하고 있다. 즉, Whisper는 배경 소음을 잘 인식하는 특성 덕분에 오디오 태깅 작업에도 적합하다. 이를 바탕으로 Whisper-AT는 Whisper의 중간 표현들을 추출하여 오디오 태깅 모델의 입력으로 활용함으로써, 다양한 음향 이벤트를 정밀하게 분류할 수 있도록 설계되었다. 그 결과, Whisper-AT는 앞서 소개된 다양한 오디오 태깅 모델들보다 더 높은 성능을 보였다.
2.3 위급 상황 탐지
위급 상황을 탐지하는 작업은 사람의 생명을 구하는 데 중요한 역할을 한다. Kim et al.,[8] Sharma et al.,[9] 그리고 Jung et al.[10]은 위급 상황을 탐지하기 위한 모델을 개발하였으며, 이는 본 연구의 목적과 유사하다. 그러나 기존 연구들은 주로 CNN 및 Long Short-Term Memory(LSTM)와 같은 전통적인 딥러닝 기법에 의존하고 있어 정확도 향상에 한계가 존재한다.[8,10] 또한, 높은 정확도를 보인 연구는 이진 분류에만 초점을 맞추고 있어 다양한 위급 상황을 세분화하여 분류하는 데 한계가 있다.[9] 특히, 실제 위급 상황 탐지 모델이 작동할 때는 위급 상황과 비위급 상황이 혼합된 오디오 입력이 제공되기 때문에, 입력 신호 중에서 위급 상황이 발생하는 정확한 지점을 식별할 필요가 있다. 본 논문에서는 Whisper와 같은 자동 음성 인식 모델을 활용하여 위급 상황을 효과적으로 분류하고, Whisper-AT 모델을 적절히 변형하여 발생 지점을 탐지할 수 있도록 함으로써 분류 정확도를 향상시켰다.
2.4 실시간 처리
Whisper 모델은 원래 실시간 처리를 지원하지 않는다. Macháček et al.[11]은 Whisper 모델을 실시간 음성 인식에 적용하기 위해 Whisper-Streaming 시스템을 제안하였다. Whisper-Streaming은 Whisper 모델에 LocalAgreement[12] 알고리즘을 도입한 것으로, 해당 알고리즘은 다음과 같이 동작한다.
1. 개의 연속된 입력 청크에 대한 모델의 출력으로부터 가장 긴 공통 접두사를 확정된 출력으로 결정한다.
2. 개 미만의 입력 청크에 대해서는 빈 부분을 출력한다.
여기에서 청크란 입력 오디오를 짧은 구간으로 분할한 단위이며, 모델의 출력은 이러한 청크들을 순차적으로 전사한 텍스트이다. 또한 가장 긴 공통 접두사란 여러 문자열이 처음부터 동일하게 시작하는 부분 중에서 가장 긴 문자열을 의미한다. 예를 들어, 첫 번째 문자열이 “안녕하세요, 방가”이고 두 번째 문자열이 “안녕하세요, 반갑습니다.”인 경우, 두 문자열의 가장 긴 공통 접두사는 “안녕하세요,”가 된다. 한 번 확정된 출력은 이후 모델의 출력에 변화가 있더라도 수정되지 않는다. Whisper-Streaming에서는 =2인 LocalAgreement-2를 채택하였다. 이와 같은 알고리즘의 도입으로 지연 시간을 단축하는 동시에 모델 출력의 불안정성을 효과적으로 감소시킬 수 있으며, 본 논문에서는 이를 응용하여 위급 상황 분류의 저지연 처리를 구현하였다.
III. 제안한 모델
실험 방법을 설명하기에 앞서, 본 연구에서 사용하는 세 가지 모델 구조인 Whisper-AT, Whisper Multi-Layer Perceptron(Whisper-MLP), Whisper Emergency Situation Detection(Whisper-ESD)을 소개한다.
3.1 개선된 Whisper-AT
Whisper-AT 논문[2]에서 제안된 모델 구조를 기반으로 하되, 컴퓨팅 자원의 한계로 Whisper-base를 사용하여 중간 표현의 차원을 조정하였다. 또한, 분류할 클래스 수가 무음을 포함하여 17가지(4.1절 참고)이므로 기존 모델의 linear classifier 출력 차원도 이에 맞춰 수정하였다. 본 연구에서 사용한 모델의 구조는 Fig. 1과 같다. 이 그림에서 temporal transformer는 입력 오디오의 시간 축에 따른 정보를 학습하고, layer transformer는 Whisper encoder의 각 층에서 추출된 표현을 종합하여 학습한다. temporal transformer와 layer transformer는 모두 Transformer 논문[13]에서 제안된 모델의 encoder layer와 동일한 구조를 따른다.
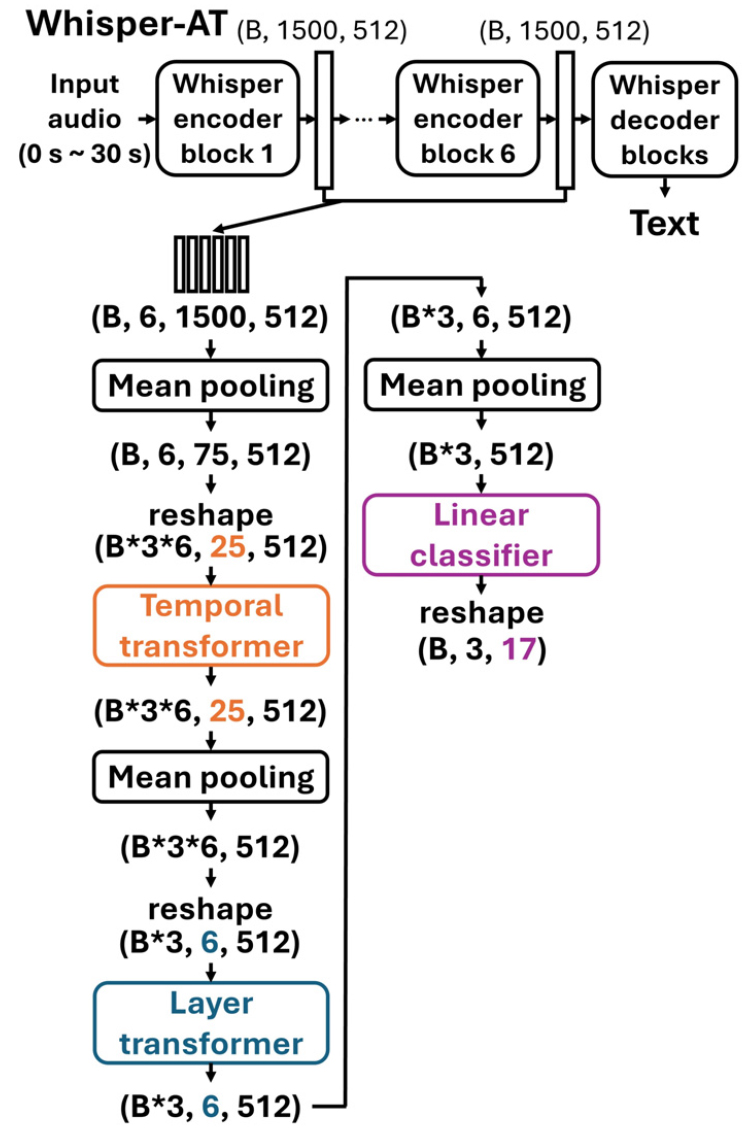
Whisper-AT는 형상이 (B, 1500, 512)인 Whisper encoder의 각 층에서 추출된 표현 6개를 합쳐서 형상이 (B, 6, 1500, 512)인 데이터를 입력으로 이용한다. 여기서 B는 배치 크기, 6은 Whisper encoder의 레이어 수, 1500은 시간 축의 토큰 수, 512는 각 토큰의 임베딩 차원을 의미한다. 여기에 평균 풀링을 적용하면 시간 축의 토큰 수를 1500에서 75로 축소시킬 수 있다.
Whisper-AT에서는 형상 (B, 6, 75, 512)의 데이터를 (B*3*6, 25, 512)로 재형상하여 temporal transformer에서 임베딩 차원이 512인 25개의 시간 축의 토큰을 갖는 B*3*6개의 오디오 샘플을 처리할 수 있다. 75개의 시간 축 토큰을 갖는 30 s의 오디오 샘플을 25개의 시간 축 토큰을 갖는 3개의 샘플로 나누어 주었기 때문에, 각 샘플은 30/3 = 10 s의 정보를 포함한다. 이후 평균 풀링을 통해 시간 축 토큰을 하나로 통합하여 형상 (B*3*6, 512)를 만든다. 그리고 다시 (B*3, 6, 512)로 재형상하여 layer transformer에서 임베딩 차원이 512인 6개의 레이어 축의 토큰을 갖는 B*3개의 오디오 샘플을 처리한다. 이후 평균 풀링을 통해 레이어 축 토큰을 하나로 통합하여 형상 (B*3, 512)를 만든다. 마지막으로 linear classifier로 B*3개의 샘플을 분류하면 하나의 30 s 오디오에 대해 3개의 태깅 결과를 확보할 수 있으므로 10 s 단위로 오디오 태깅을 수행했다고 볼 수 있다.
Whisper-AT는 기본적으로 10 s 단위로 오디오 태깅을 수행하나, temporal transformer의 입력 토큰 수를 25에서 1로 줄임으로써 최대 0.4 s 단위로 세밀한 오디오 태깅이 가능하다. 만약 기존의 형상 (B, 6, 75, 512)의 데이터를 (B*3*6, 25, 512)가 아닌 (B*75*6, 1, 512)로 재형상하면 temporal transformer에서 임베딩 차원이 512인 1개의 시간 축의 토큰을 갖는 B*75*6개의 오디오 샘플을 처리할 수 있다. 이는 75개의 시간 축 토큰을 갖는 30 s 오디오 샘플을 1개의 시간 축 토큰을 갖는 75개의 샘플로 나눈 것이므로, 각 샘플은 30/75 = 0.4 s의 정보를 포함한다. 이렇게 수정하면 layer transformer의 입력 데이터 형상은 (B*75, 6, 512)가 되고, linear classifier의 입력 데이터 형상은 (B*75, 512)가 되어 하나의 30 s 오디오에 대해 75개의 태깅 결과를 확보할 수 있다. 이는 곧 0.4 s 단위로 오디오 태깅을 수행한 것이다.
Whisper-AT는 10 s 단위로 학습을 진행하고, 추론 시에는 위와 같은 재형상 조정 과정을 통해 최대 0.4 s 해상도로 오디오 태깅을 수행하도록 변경할 수 있다. 이러한 추론 방식에서의 데이터 형상은 학습 단계에서 사용한 형상과 달라지며, 이로 인해 모델의 오디오 태깅 성능이 저하된다. 따라서 Whisper-AT의 오디오 태깅 해상도를 조정하는 방법과 이에 따른 성능 변화를 개선할 필요가 있다. 본 논문에서는 오디오 태깅 수행 간격을 시간 해상도라 칭한다.
3.2 Whisper-MLP
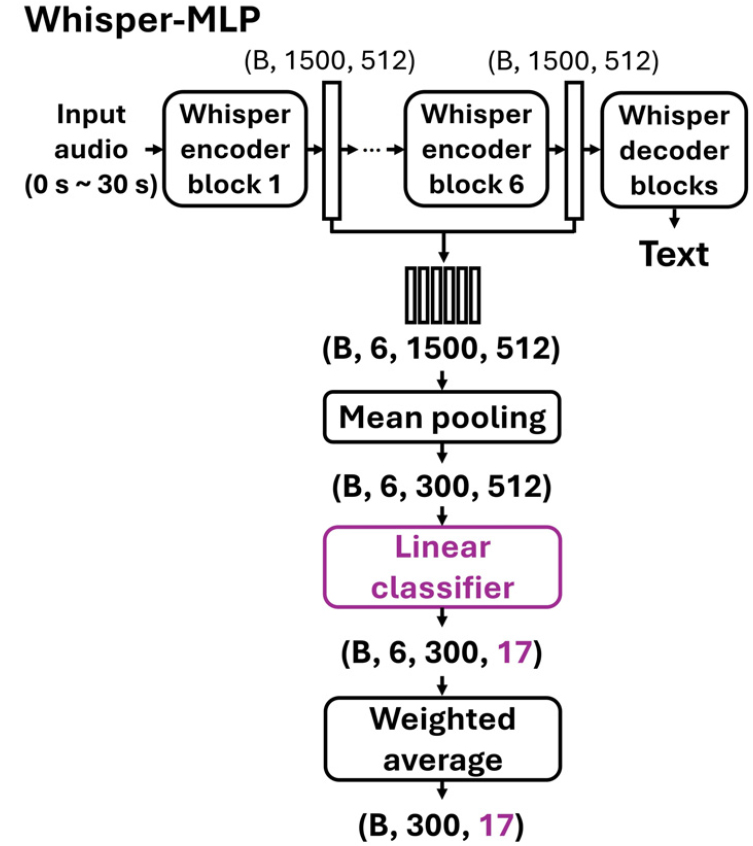
Whisper-MLP는 Whisper-AT 논문[2]에서 제안된 Weighted Average MLP(WA-MLP) 구조와 유사하게 설계되었으며, 그 구조는 Fig. 2에 제시되어 있다. Whisper-AT는 낮은 시간 해상도 때문에 위급 상황의 발생 시점을 파악하기 어렵고, 시간 해상도를 0.4 s로 높이면 성능이 떨어진다는 한계가 있다. Whisper-MLP는 이러한 문제를 해결하기 위해 학습 시부터 시간 해상도를 0.1 s로 설정하여 성능 저하 없이 위급 상황을 탐지할 수 있도록 설계하였다. Whisper encoder의 각 표현을 시간 축에 대해 평균 풀링, 시각별로 linear layer, 그리고 레이어 축에 대해 가중 평균을 적용하는 방식으로 시간 정보를 보존하며 위급 상황을 예측하도록 한다.
3.3 Whisper-ESD
Whisper-ESD는 Whisper-AT 구조를 변형하여 Whisper-MLP와 동일하게 시간 해상도를 0.1 s로 높인 모델이다. 해당 구조는 Fig. 3에 나타나 있다. Whisper-AT에서는 시간 해상도를 0.4 s로 높이는 경우, temporal transformer에 입력되는 토큰 수가 1개로 감소하며 Transformer 구조의 장점이 상실되는 문제가 발생한다. 이는 Transformer가 다수의 입력 토큰 간 상호작용을 통해 학습하는 구조적 특성을 가지기 때문이다. Whisper-ESD는 이러한 성능 저하를 방지하기 위해 temporal transformer의 입력 토큰 수를 300으로 고정하였으며, 이를 통해 Transformer 구조의 이점을 유지하였다.
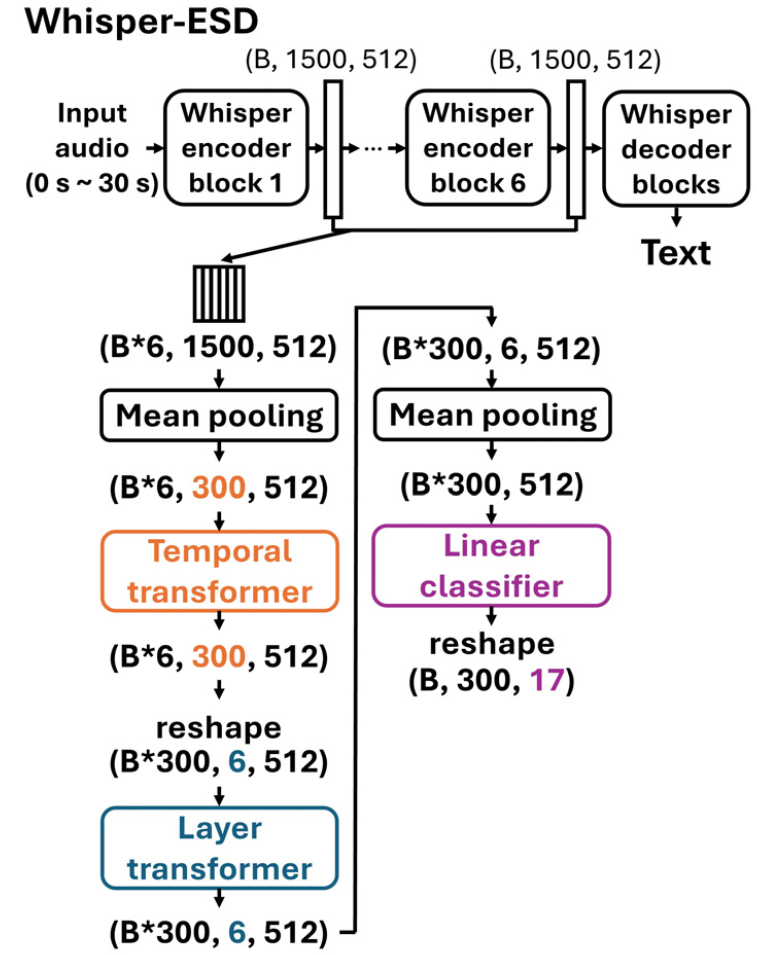
Whisper-AT에서는 temporal transformer에 입력되는 토큰 수를 25에서 1로 줄여 시간 해상도를 0.4 s로 개선하였다. 반면 Whisper-ESD는 입력 토큰 수를 300으로 증가시켰기 때문에, 단순히 입력 토큰 수만으로는 시간 해상도가 개선되지 않는 것처럼 보일 수 있다. 이를 해결하기 위해 Whisper-ESD는 temporal transformer 이후 단계에 적용되던 평균 풀링을 제거하여 시간 축 토큰을 하나로 합치는 과정을 생략하였다. 이러한 설계는 입력 토큰 수가 증가하더라도 시간 축의 차원을 유지하도록 하여, 시간 해상도를 효과적으로 개선하는 결과를 얻을 수 있게 한다.
Whisper-ESD의 시간 해상도가 0.1 s로 개선되는 과정을 자세히 설명하면 다음과 같다. 먼저, Whisper encoder로부터 추출된 6개의 표현을 결합하여 형상이 (B*6, 1500, 512)인 데이터를 입력으로 사용한다. 이후 평균 풀링을 적용하여 시간 축 토큰 수를 1500에서 300으로 줄이고, 형상이 (B*6, 300, 512)인 데이터를 temporal transformer에 입력한다. 이 단계에서 시간 축 토큰이 300개인 B*6개의 오디오 샘플을 처리하게 된다. 다시 출력을 재형상하여 데이터의 형상을 (B*300, 6, 512)로 변환한 후, layer transformer에 입력하여 레이어 축 토큰이 6개인 B*300개의 오디오 샘플을 처리한다. 마지막으로 평균 풀링을 통해 레이어 축 토큰을 하나로 축소한 뒤 linear classifier를 통과시키면 B*300개의 태깅 결과를 얻는다. 결과적으로, 하나의 30 s 오디오에 대해 300개의 태깅 결과를 얻어내며, 이는 30/300 = 0.1 s의 시간 해상도를 제공한다. 이러한 설계를 통해 Whisper-ESD가 위급 상황 탐지를 높은 시간 해상도로 수행할 수 있도록 하였다.
Whisper-ESD 모델은 시간 해상도를 0.1× s(단, 은 300의 양의 약수)로 조정할 수 있으며, 이를 위한 알고리즘은 다음과 같다. 이 알고리즘은 Whisper-AT 모델과 Whisper-ESD 모델의 성능을 직접 비교하기 위해 사용된다.
1. 30 s 길이의 오디오에 대해 300개의 예측값을 생성하고, 개씩 묶는다.
2. 묶인 개의 예측이 모두 동일하다면 해당 예측값으로 반환한다.
3. 위의 조건을 만족하지 않고, 개 중 개 이상 위급 상황(label 1 ~ 14)으로 예측된다면 위급 상황으로 반환하며, 이 경우 label 번호가 낮은 것이 우선한다.
4. 3번 조건을 만족하지 않고, 개 중 개 이상 음성이 포함된 비위급 상황으로 예측되면 음성(label 16)으로 반환한다.
5. 위의 모든 조건을 만족하지 않으면 비위급 상황 중 음향(label 15)으로 반환한다.
IV. 실험 방법
4.1 데이터셋 구축
실제 가정 내 위급 상황을 포함한 음성/음향 데이터는 수집이 어려울 뿐만 아니라 개인 정보 보호 문제와도 연관되어 데이터셋 구축이 쉽지 않다. 이에 본 연구에서는 AI Hub에서 전문가들이 구축한 가상의 위급 상황 음성/음향 데이터셋을 사용하였다(출처: https://aihub.or.kr). 여기에서 사용한 데이터셋은 총 2개로, ‘소음 환경 음성인식 데이터’와 ‘위급상황 음성/음향 데이터’로 구성된다.
위급상황 음성/음향 데이터셋에는 강제추행, 화재, 낙상 등 14개의 위급 상황과 2개의 정상 상황(실내, 실외)이 포함되어 있으며, 소음 환경 음성인식 데이터셋에는 가전 소음, 교통수단 소음 등 11개의 소음 상황이 포함되어 있다. 본 연구에서는 가정 환경에 적합한 가전 소음만을 소음 환경 음성인식 데이터에서 추출하여 사용하며, 다음과 같은 17가지의 클래스로 분류하여 실험을 설계하였다.
- 무음(label 0)
- 위급 상황 14종(label 1 ~ 14)
- 실내/실외 음향(label 15)
- 가전 소음 및 음성(label 16)
위급 상황은 일반적으로 위급하지 않은 상황(이하 비위급 상황) 중에 발생하는 경우가 많으나, ‘위급상황 음성/음향 데이터’에는 위급 상황만 포함되어 있다. 그러나 가정 내에서의 실제 위급 상황을 효과적으로 탐지하기 위해서는 비위급 상황과 위급 상황이 동시에 포함된 오디오 데이터에서 위급 상황을 탐지할 수 있어야 한다. 이에 따라, 실제 발생 가능한 위급 상황 오디오 데이터를 시뮬레이션하기 위해 다음 2가지 데이터 증강 방법(오버랩, 크로스페이드)을 적용하였다. Figs. 4와 5는 비위급 상황 오디오(파란색)에 위급 상황 오디오(빨간색)를 각각 오버랩하거나 크로스페이드하여 생성된 가상 오디오(검은색)를 시각적으로 나타낸 것이다.
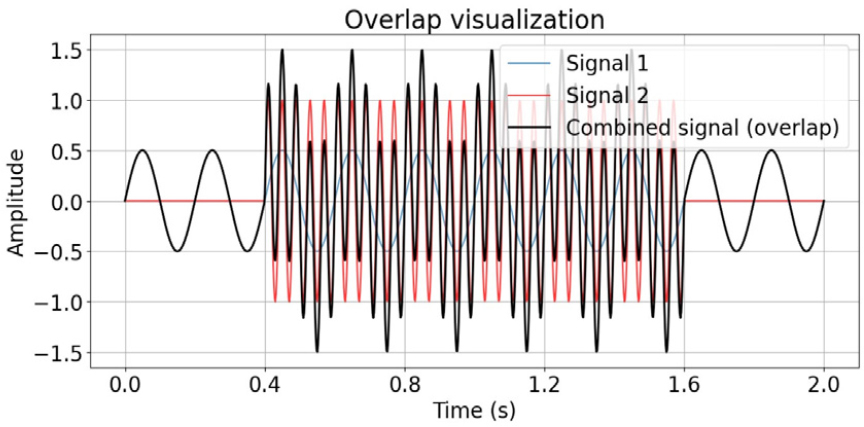
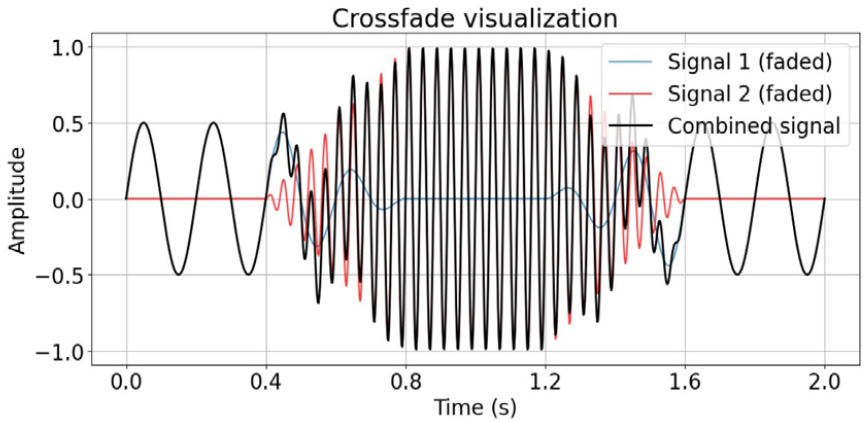
- 오버랩: 두 오디오가 일정 구간에서 겹치도록 만드는 방식
- 크로스페이드: 두 오디오의 음량을 조절하여 자연스럽게 전환되도록 만드는 방식
모든 데이터 증강은 실내/실외 음향 위에 위급상황 또는 가전 소음 음성을 오버랩 또는 크로스페이드 방식으로 추가하여 구현하였다. 실내/실외 음향의 음량은 10 %에서 100 % 사이에서 균등하게 랜덤으로 선택하였으며, 오버랩과 크로스페이드는 각각 50 % 확률로 선택되도록 설정하였다. 위급 상황 또는 가전 소음 음성이 시작되는 시점 역시 랜덤하게 설정하였으며, 크로스페이드 시간은 0 s에서 1 s 사이의 랜덤 값으로 설정하였다. 각 오디오 데이터가 중간에 잘리지 않도록 하여 자연스러운 데이터 증강을 구현하였다.
구축된 데이터셋은 다음과 같은 분포를 가진다. 훈련, 검증 및 테스트 데이터셋은 중복되는 음원 및 배경이 없도록 철저히 검수하여 구축하였다.
- 훈련 데이터셋
∙위급 상황 14종: 원본 각 2,000개, 증강 데이터 각 2,000개(총 56,000개)
∙실내/실외: 원본 각 1,000개(총 2,000개)
∙가정 소음 3종: 원본 각 6,000개, 증강 데이터 각 6,000개(총 36,000개)
- 검증 및 테스트 데이터셋
∙위급 상황 14종: 원본 각 200개, 증강 데이터 각 200개(총 5,600개)
∙실내/실외: 원본 각 100개(총 200개)
∙가정 소음 3종: 원본 각 600개, 증강 데이터 각 600개(총 3,600개)
4.2 실험 방법
본 연구에서는 Whisper-AT 모델과 비교하여 제안하는 Whisper-ESD 모델이 위급 상황 탐지에 더욱 적합함을 보이기 위해, 다음의 4가지 실험을 수행한다.
4.2.1 Whisper-AT와 Whisper-ESD의 성능 비교
이 실험에서는 Whisper-AT와 Whisper-ESD 모델의 성능을 직접 비교한다. 먼저, Whisper-base 모델을 미세 조정한 후 Whisper 모델의 파라미터를 고정하고 Whisper-AT 또는 Whisper-ESD 모델을 학습시킨다. 이 논문에서 Whisper-AT 모델은 Fine-tuned, Frozen Whisper with Whisper-AT(FT-FW-AT)로, Whisper-ESD 모델은 Fine-tuned, Frozen Whisper with Whisper-ESD (FT-FW-ESD)로 칭한다. 두 모델 모두 시간 해상도는 0.4 s로 설정하였다. 시간 해상도를 조절하기 위해 3.3절에서 소개한 알고리즘(=4, =1)을 이용한다.
4.2.2 Whisper 모델 동시 학습 여부에 따른 성능 비교
실험 1에서는 Whisper-AT 논문의 제안에 따라 Whisper 모델의 파라미터를 고정하여 학습시켰다. 이 실험에서는 Whisper를 고정한 상태로 학습하는 것이 위급 상황 탐지에 유리한지, 아니면 Whisper와 Whisper-ESD를 동시에 학습시키는 것이 더 나은지 비교한다. 여기에서부터 Whisper-ESD라 함은 Whisper와 함께 학습시키는 모델을 의미한다. 두 모델 모두 시간 해상도는 0.1 s로 설정하였다.
4.2.3 모델 구조 변화에 따른 성능 비교
Whisper와 함께 학습하는 모델들인 Whisper-AT, Whisper-MLP, Whisper-ESD의 성능을 비교한다. 각 모델은 텍스트 예측 손실 함수() 와 위급 상황 탐지를 위한 손실 함수()에 대해 모두 cross-entropy를 사용하며, 최종 손실 함수는 아래와 같이 정의된다:
여기서 𝜆(MLP ratio)는 하이퍼파라미터로, 𝜆값을 0.1, 1.0, 10.0으로 설정하여 성능 변화를 살펴본다. 참고로 실험 2에서는 𝜆=1로 고정하였다. Whisper-AT는 구조상 시간 해상도를 0.4 s로 설정하고 평가하며, 나머지 모델들은 모두 시간 해상도를 0.1 s로 맞추어 평가하였다.
4.2.4 저지연 처리가 가능한 Whisper-ESD의 성능 확인
Whisper-ESD 모델의 저지연 처리를 가능하게 하기 위해 LocalAgreement-2 알고리즘을 변형하여 위급 상황 탐지에 적용하였다. 저지연 처리에서 발생하는 지연 시간은 다음 4가지 요소로 구성된다.
1. 오디오 녹음 시간
2. 오디오 전처리 시간
3. 모델의 추론 시간
4. LocalAgreement-2의 확정된 출력과 입력 사이의 지연 시간
이 실험에서는 먼저 Whisper-AT, Whisper-MLP, Whisper-ESD 모델이 모두 짧은 추론 시간을 가지므로 저지연 처리가 가능함을 검증한다. 또한, LocalAgreement-2 알고리즘의 하이퍼파라미터인 청크의 최소 크기(Minimum Chunk Size, MCS)를 조절하며 Whisper-ESD의 4가지 지연 시간과 성능을 비교한다. MCS의 단위는 초(s)이며, Whisper-ESD의 시간 해상도는 0.1 s이므로 MCS가 1 s이면 한 입력 청크당 10개의 태깅 결과를 출력할 수 있음을 나타낸다. Whisper-ESD에 적용할 변형된 LocalAgreement-2 알고리즘은 다음과 같으며, 이 알고리즘의 예시는 Fig. 6에서 보여준다.
1. confirmed_output(확정된 출력)을 빈 리스트로 설정하고, prev_output(이전 출력)은 첫 번째 입력 청크에 대한 Whisper-ESD의 출력으로 초기화한다(예: confirmed_output = [ ], prev_output = [1, 1, 1]).
2. 다음 입력 청크에 대한 Whisper-ESD의 출력을 new_ output(새로운 출력)으로 할당한다.
3. prev_output과 new_output의 가장 긴 공통 접두사를 찾아 confirmed_output에 추가한다. 만약 confirmed_ output이 비어 있지 않다면, confirmed_output에 있는 부분을 제외한 나머지 부분에서 가장 긴 공통 접두사를 찾아 추가한다.
4. new_output을 prev_output에 할당한다.
5. 과정 2 ~ 4를 반복하여 confirmed_output을 지속적으로 갱신한다.
6. 마지막 입력 청크에 대한 Whisper-ESD의 출력으로 confirmed_output의 남은 부분을 채운다.

Fig. 6.
(Color available online) Examples of the update process for confirmed_output in the LocalAgreement-2 algorithm applied to Whisper-ESD. Each element in the list represents one of the 17 classes presented in section 4.1, where 0 denotes silence, 1 indicates emergency situations, and 15 corresponds to indoor/outdoor acoustics.
V. 실험 결과
5.1 실험 1: Whisper-AT와 Whisper-ESD의 성능 비교
Whisper-base를 learning rate 5e-5로 미세 조정한 뒤 FT-FW-AT와 FT-FW-ESD를 learning rate 1e-4로 학습시킨 결과는 Table 1과 같다. Whisper-base를 미세 조정하여 CER을 53.18에서 12.03까지 감소시킬 수 있었다. 17가지 위급/비위급 상황 탐지에 대한 FT-FW-AT와 FT-FW-ESD의 정확도는 각각 94.14 %와 98.92 %로, Whisper-ESD 모델이 Whisper-AT보다 위급 상황 탐지에 더 적합함을 확인할 수 있었다.
Table 1.
Comparison of emergency situation detection accuracy and Character Error Rate (CER) between Fine-Tuned, Frozen Whisper with Whisper-AT (FT-FW-AT) and Fine-Tuned Frozen Whisper with Whisper-ESD (FT-FW-ESD).
| Model (time resolution) | Accuracy | CER |
|
Whisper base (no fine-tuning) | - | 53.18 |
| FT-FW-AT (0.4 s) | 94.14 % | 12.03 |
| FT-FW-ESD (0.4 s) | 98.92 % |
5.2 실험 2: Whisper 모델 동시 학습 여부에 따른 성능 비교
Whisper, Whisper-ESD를 따로 학습시킨 실험 1의 FT-FW-ESD와 동시에 학습시킨 Combined Whisper and ESD simultaneous training(CW-ESD)의 성능을 비교한 결과는 Table 2에 제시되어 있다. FT-FW-ESD와 CWS-ESD의 위급 상황 탐지 정확도와 CER은 각각 98.99 %/12.03, 99.40 %/10.11로 나타났으며, Whisper를 동시에 학습한 모델이 정확도와 CER 모두 더 우수한 성능을 보였다. 이 실험에서 가장 중요한 점은 위급 상황 분류기가 분류 정확도뿐만 아니라 Whisper의 텍스트 예측 성능을 향상시켰다는 것이다. 이는 Whisper-AT[2] 논문에서 언급한 바와 같이, 위급 상황에 대한 배경 음향을 풍부하게 학습하여 텍스트 예측에 활용했기 때문이라고 추론할 수 있다.
Table 2.
Comparison of performance with and without simultaneous training of the Whisper Model (CW-ESD stands for Combined Whisper and ESD simultaneous training).
| Model (time resolution) | Accuracy | CER |
| FT-FW-ESD (0.1 s) | 98.99 % | 12.03 |
| CW-ESD (0.1 s) | 99.40 % | 10.11 |
5.3 실험 3: 모델 구조 변화에 따른 성능 비교
Table 3은 Whisper-AT, Whisper-MLP, Whisper-ESD의 성능을 비교한 결과이다. 위급 상황 분류 정확도와 CER에서 Whisper-ESD가 가장 우수한 성능을 보임을 확인할 수 있다. 여기에서 𝜆는 텍스트 예측 대비 위급 상황 탐지에 대한 학습의 가중치로, 𝜆값을 증가시킬수록 분류 정확도는 향상되지만, 텍스트 예측 성능은 감소하는 경향을 보인다. 본 연구에서는 분류 정확도와 CER을 모두 고려한 결과, 𝜆=1일 때 가장 최적의 성능을 보인다고 판단하여 최종 모델로 Whisper-ESD(𝜆=1)를 선택하였다.
Table 3.
Comparison of performance according to changes in model structure (Acc: accuracy).
5.4 Whisper-ESD(𝜆=1)의 결과 시각화
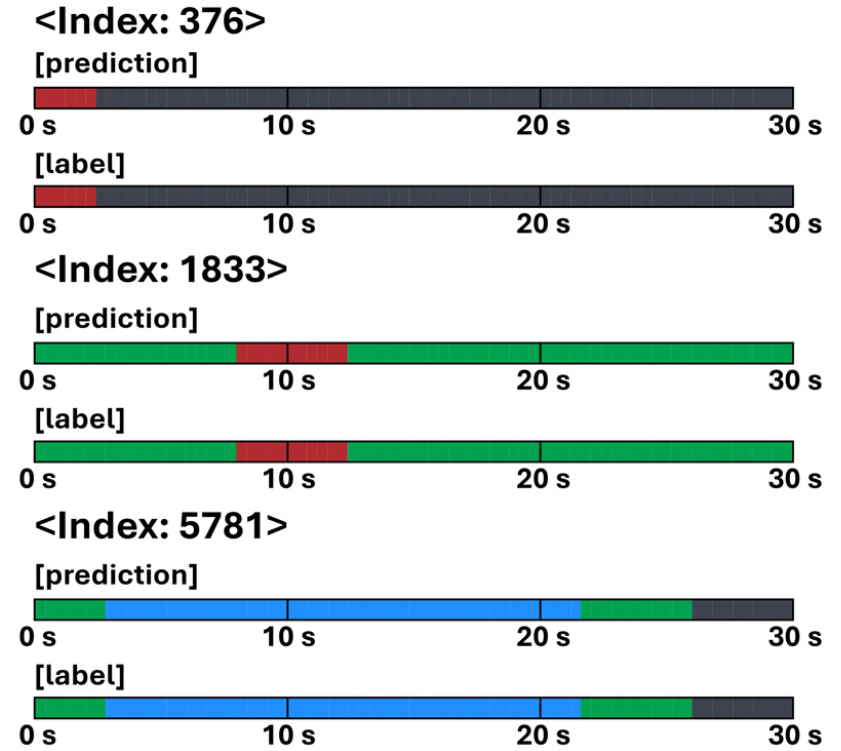
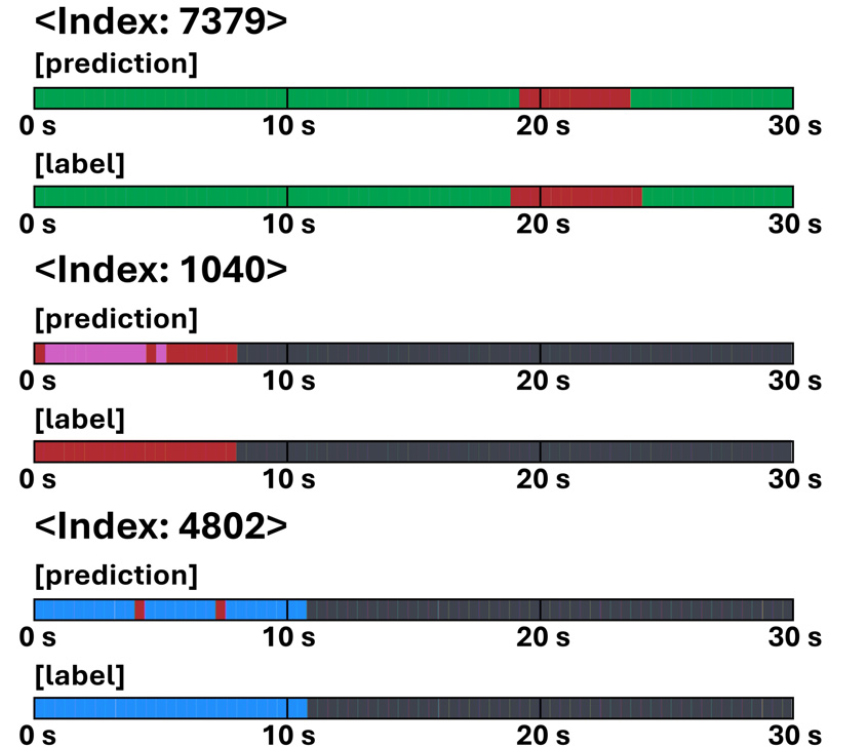
Whisper-ESD(𝜆=1) 모델의 위급 상황 탐지 결과를 시각화한 그림은 Figs. 7과 8에 제시되어 있다. 모든 추론 결과는 하나의 막대로 표현되며, 검은색은 label 0에 해당하는 무음을, 빨간색은 label 1 ~ 14에 해당하는 위급 상황을, 초록색은 label 15에 해당하는 실내/실외 음향을, 파란색은 label 16에 해당하는 가전 소음 및 음성을, 보라색은 정답과 다르게 예측된 위급 상황을 나타낸다. Fig. 7은 위급/비위급 상황을 모두 정확하게 탐지한 경우를 나타내며, Fig. 8은 일부 예측 오류가 발생한 경우를 보여준다.
5.5 Whisper-ESD(𝜆=1)의 분류 정확도
기존 실험에서는 시간 해상도 0.1 s를 기준으로 30 s 길이의 오디오 데이터를 300개의 구간으로 분할하여 각 구간에서 위급 상황을 분류하는 정확도를 평가하였다. 본 실험은 동일한 30 s 오디오를 단 하나의 구간으로 통합하여 무음을 제외한 16가지 위급 및 비위급 상황 중 하나로 분류하는 것을 목표로 하며, 이를 위해 시간 해상도를 0.1 s에서 30.0 s로 변경하여 평가를 진행한다. 시간 해상도를 변경하는 과정에는 3.3절에서 소개한 알고리즘(n = 300, k = 4)을 활용하였다. 그 결과, Table 4에 나타난 바와 같이 16가지 위급/비위급 상황을 분류하는 정확도는 97.70 %에 달했으며, 위급과 비위급을 이진 분류하는 정확도는 99.67 %를 달성하였다.
Table 4.
16 class classification accuracy and binary classification accuracy.
| Classification | Accuracy |
| 16 classes | 97.70 % |
| Binary | 99.67 % |
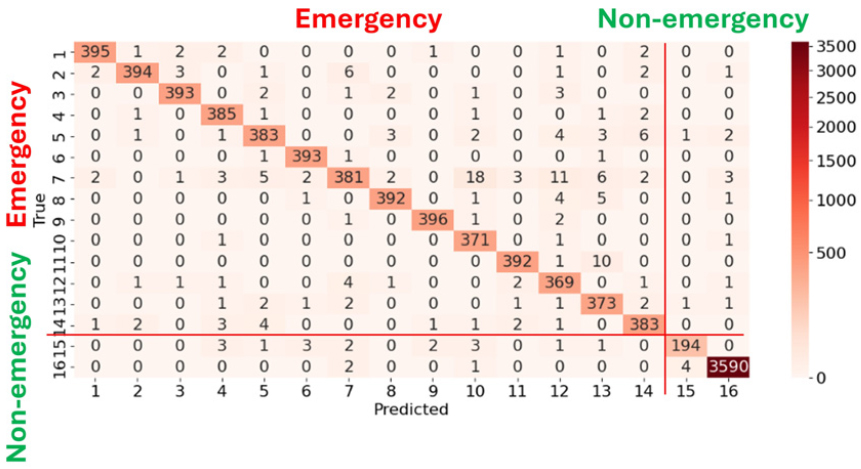
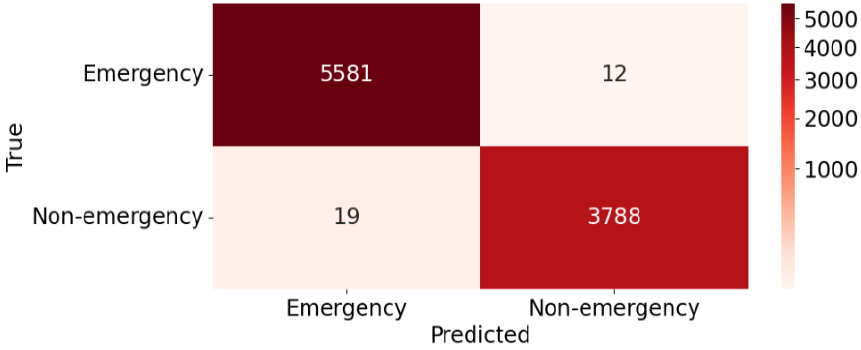
16가지 위급/비위급 상황 분류의 혼동 행렬은 Fig. 9와 같다. 대부분 올바르게 분류했음을 확인할 수 있다.
이진 분류의 혼동 행렬은 Fig. 10과 같다. 위급 상황을 비위급 상황으로 잘못 분류하는 경우와 비위급 상황을 위급 상황으로 잘못 분류하는 경우 중, 전자가 훨씬 더 위험하다. 이 모델에서는 위급 상황을 비위급 상황으로 분류하는 경우는 12회였고, 비위급 상황을 위급 상황으로 분류한 경우는 19회였다. 이러한 결과를 바탕으로, 모델은 상대적으로 더 큰 위험을 초래할 수 있는 전자의 경우가 비교적 적게 발생하여, 위험성 측면에서 비교적 안전하다고 평가할 수 있다. precision은 0.9950, recall은 0.9968, f1-score는 0.9959이다.
5.6 실험 4: 저지연 처리가 가능한 Whisper-ESD 모델의 성능 확인
Whisper-ESD 모델이 신속한 위급 상황 탐지에 효과적으로 활용될 수 있음을 평가하기 전에, 해당 모델이 저지연 처리에 적합한지 먼저 검증하고자 한다. 이를 위해 Whisper-AT, Whisper-MLP, Whisper-ESD 모델의 추론 시간을 Graphics Processig Unit(GPU)와 Central Processing Unit(CPU) 환경에서 비교하였으며, 그 결과는 Table 5에 제시되어 있다. 이때 사용한 GPU는 NVIDIA RTX 4090 1개이다.
Table 5.
Comparison of inference time according to changes in model structure. We used a single NVIDIA RTX 4090 GPU.
| Model | Inference time | |
| GPU | CPU | |
| Whisper-AT | 0.020 s | 0.373 s |
| Whisper-MLP | 0.017 s | 0.361 s |
| Whisper-ESD | 0.019 s | 0.433 s |
세 모델은 모두 GPU 환경에서 0.02 s 내외, CPU 환경에서 0.4 s 내외의 매우 짧은 추론 시간을 보였으며, 특히 제안한 Whisper-ESD 모델은 기존 Whisper-AT 및 Whisper-MLP 모델과 유사한 추론 속도를 유지함으로써 저지연 처리에 적합함을 확인할 수 있었다. 이는 Whisper 모델 중 경량화된 모델인 Whisper-base를 사용한 결과로 해석된다.
4.2절에 제시한 변형된 LocalAgreement-2 알고리즘을 적용하여 저지연 처리가 가능한 Whisper-ESD 모델을 구현하였다. Table 6은 LocalAgreement-2의 하이퍼파라미터인 MCS를 조절하여 이 모델의 4가지 지연 시간(4.2절 참고)과 위급 상황 분류 정확도를 평가한 결과를 제시한다.
Table 6.
Comparison of latency and accuracy in low latency processing of Whisper-ESD according to Minimum Chunk Size (MCS). In latency, (1) refers to the audio recording time, (2) the audio preprocessing time, (3) the model inference time, and (4) the delay between the input and confirmed output of LocalAgreement-2.
실험 결과, MCS가 증가함에 따라 (1) 오디오 녹음 시간과 (4) LocalAgreement 알고리즘의 지연 시간이 증가하여 전체 지연 시간이 길어지는 반면, 위급 상황 분류 정확도는 향상되는 경향을 보였다. 이러한 결과는 적절한 MCS 설정이 저지연 처리에서 지연 시간과 분류 성능 간의 균형을 결정하는 요소임을 보여준다. 본 연구에서는 MCS를 2 s로 설정하는 것이 최적이라고 판단하였으며, 이 경우 전체 지연 시간은 약 4.2 s, 분류 정확도는 95.91 %를 달성한다. 비록 이 정확도가 기존 Whisper-ESD 모델의 99.40 %에 미치지 못하지만, 기존 모델은 오디오 녹음 시간만 30 s를 필요로 하여 전체 지연 시간이 30 s 이상이 되므로, 저지연 처리 측면에서는 제안한 접근법이 보다 적합하다고 볼 수 있다. 또한, 초기 오디오 정보가 부족한 경우 부정확한 추론이 발생하는 경향이 있으므로, 실제 응용 환경에서는 모델 실행 직후를 제외하고 항상 30 s의 누적된 오디오 정보를 반영하도록 설정할 경우 정확도가 크게 개선될 것으로 기대된다.
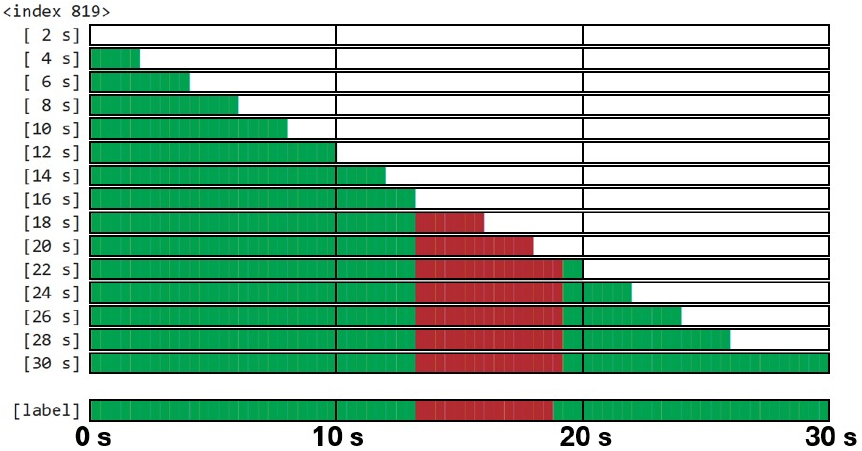
마지막으로, Fig. 11은 MCS가 2 s로 설정된 Whisper-ESD 모델이 저지연으로 위급 상황 탐지 결과를 출력하는 과정을 보여준다. 모델은 사용자에게 항상 확정된 출력만을 제공하며, 이 출력은 2 s 간격으로 갱신되지만 반드시 2 s 분량의 새로운 정보가 추가하는 것은 아니다. 이는 LocalAgreement-2 알고리즘을 적용하여 모델의 부정확성을 보완하고자 한 의도를 반영한다.
VI. 결 론
본 연구에서는 위급 상황 탐지를 0.1 s 간격으로 수행하기 위해 Whisper-AT 모델을 개선한 Whisper-ESD 모델을 설계하였다. 이 모델이 기존 모델에 비해 위급 상황 탐지에서 탁월한 성능을 보임을 여러 실험을 통해 입증하였다. 또한, Whisper와 동시에 학습을 수행함으로써 위급 상황 분류 정확도를 향상시키는 동시에 Whisper가 예측하는 텍스트의 CER을 낮추는 결과를 얻었다. 이를 통해 Whisper의 텍스트 예측 성능을 향상시키기 위해서는 배경 음향을 같이 학습시키는 것이 도움이 된다는 결론을 얻었다. 최종적으로 제안하는 모델인 Whisper-ESD(𝜆=1)는 위급 상황 탐지 정확도 99.40 %, CER 10.11을 달성하였으며, 16가지 위급/비위급 상황 분류에서는 97.70 %, 위급과 비위급의 이진 분류에서는 99.67 %라는 성능을 기록하였다. LocalAgreement-2 알고리즘을 적용하여 저지연 처리가 가능하도록 설계된 Whisper-ESD 모델은 전체 지연 시간 4.2 s에 위급 상황 탐지 정확도 95.91 %를 달성하였다.
그러나 본 연구는 실제 위급 상황 데이터가 아닌 전문가가 인위적으로 생성한 가상의 위급 상황 데이터를 학습에 사용했다는 점에서 한계가 있다. 이러한 한계를 극복하기 위해 데이터 증강 과정에서 오버랩과 크로스페이드를 도입하여 실제 상황과 유사성을 높이고자 하였으나, 여전히 인위적인 데이터 조정이 이루어졌다는 점은 연구의 제한점으로 남아 있다. 향후 연구에서는 데이터의 한계점을 보완하고 다양한 실제 데이터를 바탕으로 배경 음향 분류 작업을 수행함으로써, 분류 성능뿐만 아니라 자동 음성 인식 성능 역시 더욱 향상된 모델을 개발할 수 있을 것으로 기대된다.
