

I. 서 론
II. 방 법
2.1 CRNN(Baseline)
2.2 다중 해상도 합성곱 모델
2.3 스킵 연결 기반 합성곱 모델
III. 제안된 누적 특징 추출 네트워크
3.1 누적 특징 추출 네트워크(AccNet)
3.2 모델 학습
3.3 모델 설계 변수
IV. 실험 및 결과
4.1 데이터베이스
4.2 성능 지표
4.3 모델별 성능 평가
4.4 음향 이벤트 종류별 성능 평가
4.5 Pooling 방법에 따른 모델 성능 비교
4.6 제안하는 방법의 성능에 관한 논의
V. 결 론
I. 서 론
음향 이벤트 검출(Sound Event Detection, SED)은 오디오 신호에 포함된 관심 음향의 종류와 시점과 끝점을 검출하는 기술로, 스마트 홈/도시에서 모니터링 시스템과 자율주행 자동차 등 IoT 분야에서 핵심 기술로 주목받고 있다.[1,2,3] 오디오 신호는 시간에 따른 주파수 변화를 보여주는 로그 멜 스펙트로그램으로 변환되어 음향모델에 입력된다. 이후, 모델의 결과에 임계값과 중간값 필터링을 순차적으로 적용하여 검출 결과가 도출된다.[4] 음향 신호 분석에 관한 국제 경연 대회(Detection and Classification of Acoustic Scenes and Events, DCASE)를 통해, 심층신경망 기반 음향 모델 설계, 데이터 증강, 모델 학습, 후처리 등 다양한 측면에서 성능 향상 방법이 소개되고 있다.[5,6,7,8] 이때, 검출성능 향상을 위해, 음향 특징을 효과적으로 구분하는 음향모델이 필요하다.
음향 이벤트 검출에 관한 DCASE 베이스라인(baseline)은 시간-주파수 영역에서 음향 특징을 추출하는 Convolutional Neural Network(CNN)와 시간에 따른 변화를 모델링하는 Gated Recurrent Units(GRUs)으로 구성된 CRNN을 음향모델로 활용한다. 하지만, 고정된 크기의 합성곱 필터를 사용하는 CNN은 제한된 수용 범위 내에서 지역적인 특징을 추출하기 때문에 시간에 따른 주파수 변화를 반영하는 데 한계가 있다. InceptionNet[9,10]에 기반한 음향모델은 여러 크기의 합성곱 필터를 병렬적으로 적용하여 다양한 크기의 수용영역에서 음향 특징을 효과적으로 추출한다. 다수의 합성곱 계층(convolution layer)과 풀링(Pooling) 계층으로 구성된 CNN은 시간에 따른 주파수 변화를 반영한 하위 레벨 특징(low-level feature)과 이들을 융합한 상위 레벨 특징(high-level feature)를 추출함으로써, 음향 이벤트 검출성능 향상을 기대할 수 있다. 하지만, 기울기 소실/폭발 문제로 인해, 모델 학습에 어려움이 있다. 이때, ResNet[11]은 이전 계층의 출력을 현재 계층의 출력과 연산하는 스킵 연결(skip connection)을 적용함으로써, 상위 레벨 특징을 효과적으로 추출하고 안정적인 모델 학습을 기대할 수 있다. 한편, 상위 계층으로 전달된 특징은 여러 연산을 통해, 시간-주파수 영역에서 관찰되는 지역적 특징이 희석될 수 있다. DenseNet[12,13]은 모든 상위 계층으로 스킵 연결된 밀집 연결(dense connection)을 적용하여, 안정적인 학습을 기대함과 동시에, 각 계층에서 추출된 특징을 상위 계층에 전달하여, 중간 계층에서의 정보 손실을 최소화할 수 있다.[12,13]
본 논문에서는 음향 이벤트 검출성능 향상을 위해 밀집 연결(dense-connection)에 기반한 음향 특징 추출 네트워크 AccNet을 제안한다. 제안하는 모델에서 하위 계층의 특징맵은 Dense 블록을 통해, 모든 상위 계층으로 전달됨으로써, 하위 계층에서 추출된 특징을 보존하면서 상위 레벨 특징을 추출함으로써 음향 이벤트 검출을 위해 효과적으로 특징을 추출할 수 있다. 이때, Dense 블록은 시간-주파수 영역에서 지역적인 음향 특징을 추출하고 채널 차원을 축소하기 위해, 3 × 3 합성곱과 점별 합성곱(point-wise convolution)으로 구성된다. DCASE 2023 Task4 테스트베드에 기반한 성능 평가에서 제안하는 모델의 F1 점수는 44.76 ± 0.51 %로 InceptionNet과 ResNet에 기반한 모델과 비교하여 각각 3.72 %, 3.68 % 향상된 결과를 보여준다.
이후 본 논문의 구성은 다음과 같다. II장에서는 실험에 사용된 CRNN, 다중 해상도 합성곱 모델, 잔차 경로 기반 모델, 제안하는 모델을 설명하고 III장에서는 database, 모델 학습 및 평가 지표, 실험 변수를 설명한다. IV장에서는 모델별 성능을 평가하고, 모델별 파라미터 수를 비교한다. 마지막으로 V장에서는 본 연구에 대한 결론을 도출한다.
II. 방 법
2.1 CRNN(Baseline)
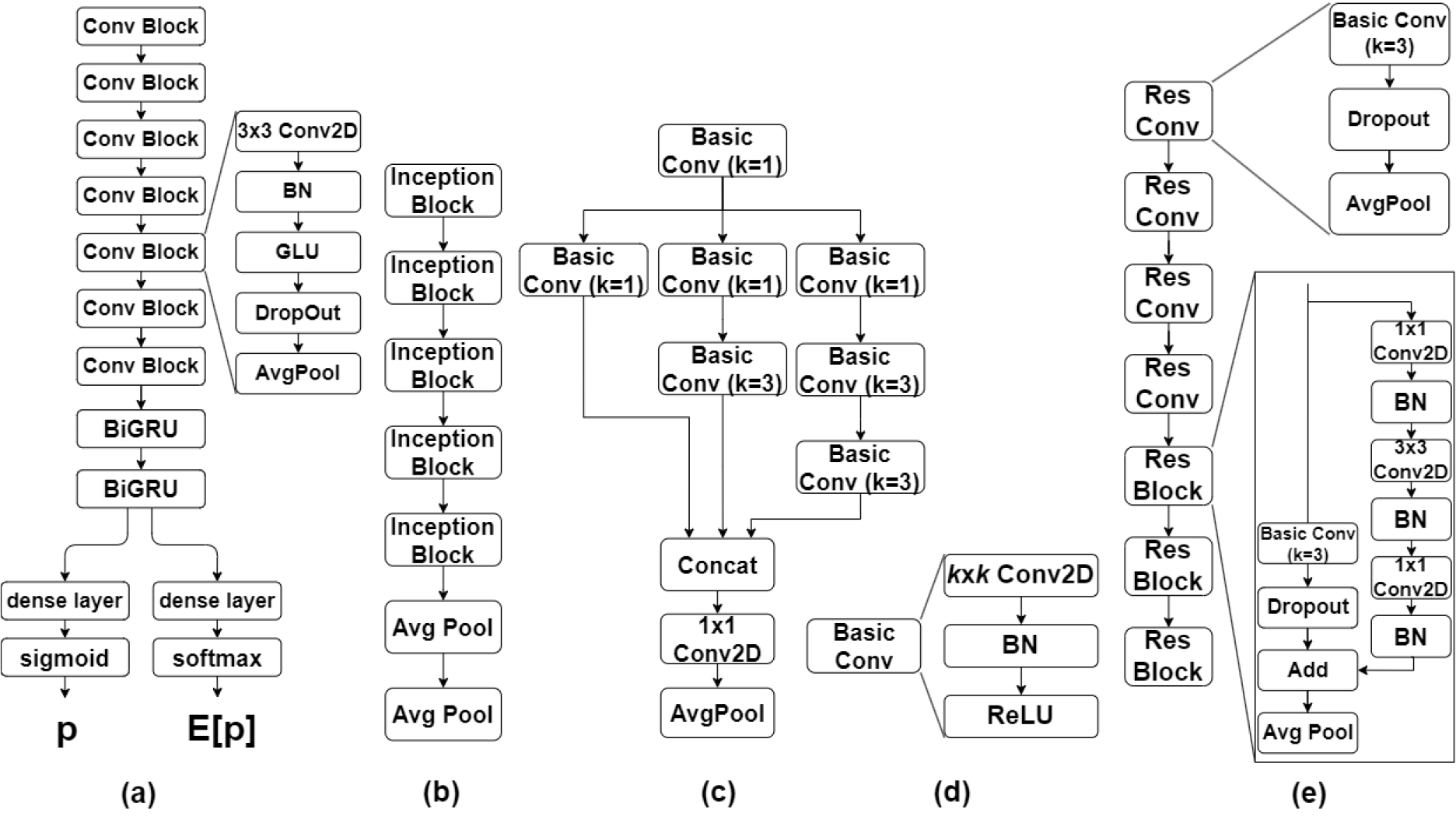
DCASE 2023의 Baseline에서 CRNN은 7개의 합성곱 블록과 2개의 양방향 GRU로 구성된다[Fig. 1(a)]. 합성곱 블록은 3 × 3 합성곱, 배치 정규화, GLU, 드롭아웃, Avg Pool 순서로 구성된다. 순환 신경망은 두 개의 양방향 GRU로 구성된다. 은닉 셀의 수는 128로 설정된다. CRNN의 결과는 완전 연결층(Fully connected Layer)을 통해, 10가지 음향 이벤트의 존재확률을 산출한다. 이때, 시간에 따른 음향 이벤트의 존재 확률(strong prediction)과 입력 오디오 신호에 포함된 음향 이벤트의 존재 확률(weak prediction)을 각각 sigmoid와 softmax를 통해 산출한다.
2.2 다중 해상도 합성곱 모델
InceptionNet[9,10]으로부터 영감을 받아, 시간-주파수 영역에서 여러 크기의 수용영역에 대한 음향 특징 추출을 위해, Inception 블록을 활용한 다중 해상도 합성곱 모델을 구축한다. 실험적으로 최고 성능을 기록한 다중 해상도 합성곱 모델(Inception-based)은 5개의 Inception 블록과 2개의 Avg Pool로 구성된다[Fig. 1(b)]. Inception 블록은 1 × 1, 3 × 3, 2개의 3 × 3 커널이 적용된 Basic 합성곱을 통해, 특징을 추출한 후, Point-wise 합성곱을 통해, 특징 맵의 채널 수를 축소한다[Fig. 1(c)]. 이때, Basic 합성곱은 (k × k) 합성곱, 배치 정규화(Batch Normalization, BN), ReLU 순서로 구성된다[Fig. 1(d)].
2.3 스킵 연결 기반 합성곱 모델
ResNet[11]으로부터 영감을 받아, 효율적인 상위 레벨 특징 추출과 안정적인 모델 학습을 위해, 스킵연결 기반 합성곱 모델을 구축한다. 다중 해상도 합성곱 모델과 마찬가지로, 실험적으로 최고 성능을 기록한 스킵연결 기반 합성곱 모델(Residual path based)은 4개의 ResConv와 3개의 Res블록으로 구성된다[Fig. 1(e)]. ResConv은 Basic 합성곱(k = 3), Dropout, Avg Pool 순서로 구성된다. Res블록은 Basic 합성곱(k = 3), Dropout을 수행한 후 스킵 연결을 추가하고 Avg Pool을 수행한다. 스킵 연결은 1 × 1 합성곱, BN, 3 × 3 합성곱, BN, 1 × 1 합성곱, BN으로 구성된다.
III. 제안된 누적 특징 추출 네트워크
3.1 누적 특징 추출 네트워크(AccNet)
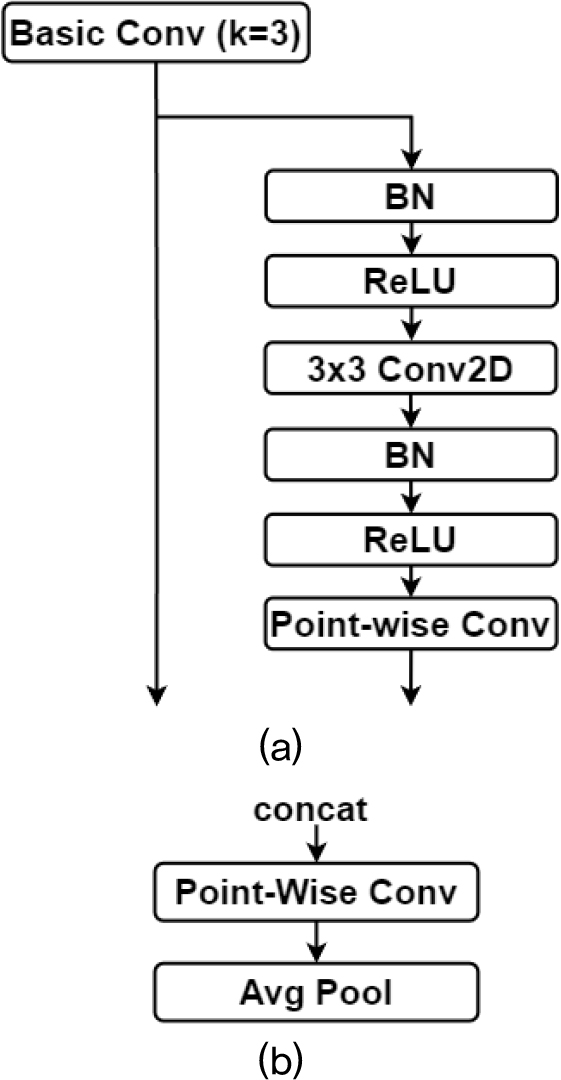
제안하는 모델은 7개의 Dense 블록과 7개의 Transition 블록으로 구성된다(Fig. 2). 먼저, Dense 블록은 Basic 합성곱(k = 3)과 Feature Extracting(FE) 블록으로 구성된다[Fig. 3(a)]. FE 블록은 BN, ReLU, 3 × 3 합성곱, BN, ReLU, point-wise 합성곱 순서로 구성되며 Basic 합성곱의 출력을 이용하여 생성된다. 하위 계층의 FE 블록은 3 × 3 합성곱을 통해 채널을 확장하고 특징 맵을 추출한 후, point-wise 합성곱으로 채널 차원을 압축하여, 특징 공간에서 중복된 정보를 제거한다. Transition블록은 concat, point-wise 합성곱, AvgPool 순서로 구성된다[Fig. 3(b)]. 이전 계층으로부터 전달된 모든 FE 블록은 AvgPool를 적용하여 현재 계층과 차원을 일치시킨 후, 현재 계층에서 Dense블록의 출력과 연결한다. 예를 들어, Transition 블록 4의 입력은 Dense 블록 4의 출력과 이전에 Dense 블록 1, 2, 3에서 생성된 FE 블록이다. 각 FE 블록은 모든 레이어를 거칠 때마다 AvgPool이 적용된다. 이는 각 Dense 블록에 반복함으로써, 하위 계층에서 추출된 시간-주파수 정보를 손실 없이 상위 계층의 특징 추출 과정에 반영할 수 있다. 제안하는 FE 블록은 기존 DenseNet[12,13]의 병목(bottleneck) 블록과 비교하여 3 × 3 합성곱을 선행함으로써, 각 계층에서 시간-주파수 영역에서 특징을 학습하고, 이후 1 × 1 합성곱을 통해, 채널을 축소하여 연산량을 줄인다.
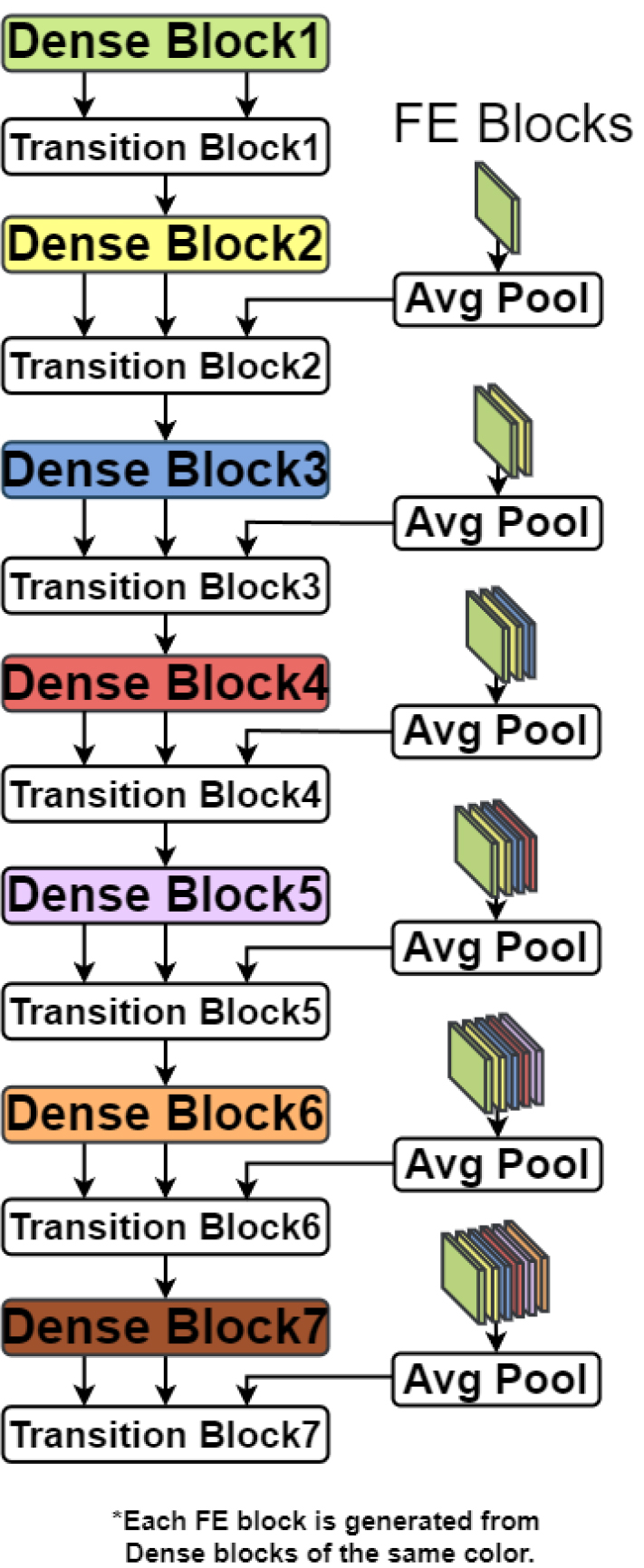
Dense블록으로 음향 모델을 구축함으로써, 시간-주파수 영역에서 관찰되는 음향 특징이 음향 모델 내 전파 과정에서 손실되는 정보를 최소화 함으로써, 효과적인 특징 추출을 기대할 수 있다. 또한, 스킵 연결과 동일하게, 학습과정에서 기울기 소실/폭발 문제를 완화함으로써, 안정적인 모델 학습을 기대할 수 있다.
3.2 모델 학습
성능 평가에서 각 모델은 평균 교사 모델에 기반하여 학습된다. 평균 교사 모델은 학생 모델과 교사 모델로 구성된다. 실험에서 사용한 평균-교사 모델은 다음 Eq. (1)과 같이 정의된다.
이때, 위 첨자 s, w, u는 각각 음향 데이터의 종류를 의미한다. BCE와 MSE는 Binary Cross Entropy와 Mean Squared Error를 나타낸다. ,는 각각 강한 레이블과 약한 레이블을 의미한다. n, m, k는 각각 강한 레이블, 약한 레이블, 레이블이 없는 데이터의 배치 크기를 나타낸다. ,는 각각 학생 모델과 교사 모델의 출력 값이고, 는 학생 모델의 출력값에 대한 시간에 대한 가중치 평균값이다. 각 모델은 DCASE2023 task4의 Testbed를 활용하여 학습된다.[14]
3.3 모델 설계 변수
CRNN은 DCASE2023 Baseline과 동일한 모델로 설정된다. 다중 해상도 합성곱 모델에서 Inception블록의 채널 수는 16, 32, 64, 128, 256 순서로 구성된다. Inception블록의 1 × 1 합성곱 필터는 입력 채널 수와 동일한 채널 수를 출력하고, 3 × 3 합성곱 필터의 1 × 1 합성곱 필터는 입력 채널수의 절반을 출력한다. 5 × 5 합성곱 필터의 1 × 1 합성곱 필터는 입력 채널수의 1/4을 출력한다. Point-Wise 합성곱은 다음 Inception 블록 입력 채널과 동일하게 설정한다. 잔차 경로 기반 모델은 ResConv의 채널 수는 순서대로 16, 32, 64으로 설정되고, Res블록의 채널 수는 모두 128로 설정된다. 스킵 연결의 3 × 3 합성곱의 채널 수는 모두 32로 설정된다. 제안하는 모델에서 채널 수는 계층 순서대로 16, 32, 48, 64, 80, 96, 112로 설정된다. 각 모델은 실험적으로 최고 성능을 보이는 구조로 설계되어, 성능평가에 고려한다.
IV. 실험 및 결과
4.1 데이터베이스
본 논문에서는 DCASE2023 task4에서 제공하는 DESED 데이터 셋을 사용한다. 학습데이터는 각각의 오디오 신호에 대해 음향 이벤트의 종류와 구간이 모두 명시된 strongly labeled set(S), 음향 종류만 명시된 weakly labeled set(W), 그리고 아무런 정보가 없는 unlabeled set(U)으로 구성되고, 검증데이터는 969개의 오디오 클립으로 구성된다. 모든 데이터는 10초 길이의 오디오를 샘플링 레이트 16 kHz로 재샘플링하고 2048포인트 Fast Fourier Transform(FFT)를 수행하여 스펙트로그램으로 변환한다. 이후 멜 필터를 적용하여 멜-스펙트로그램으로 변환한다.
4.2 성능 지표
성능 지표로 이벤트 기반 F1 점수(F1-score)와 PSDS를 활용한다. F1 점수는 정밀도와 재현율의 조화 평균으로 산출된다. PSDS는 이벤트 검출 시점이 정확할수록 높은 점수를 부여하는 PSDS1과 이벤트의 종류에 더 높은 점수를 부여하는 PSDS2를 사용한다. 각 지표의 산출방법은 DCASE 2023 task4에서 사용한 방법을 적용한다.[15] 모델 학습에서 발생하는 무작위성을 고려하여, 각 모델은 학습과 테스트를 세 번 반복하여, 평균을 통해 나타낸다.
4.3 모델별 성능 평가
Table 1은 각 모델의 성능과 모델 크기(변수 수)를 보여준다. 세 가지 성능지표에서 CRNN은 널리 알려진 성능과 유사함을 알 수 있다.[16] 본 실험에서 성능평가를 위한 검증데이터는 구축 과정에서 199개 오디오 샘플이 누락되었지만, 성능 평가 및 비교에 큰 차이가 없음을 확인할 수 있다. 다중 해상도 합성곱 모델과 잔차 경로 기반 모델은 CRNN과 비교하여 향상된 성능을 보여준다. 이때, 모델은 모든 지표에서 다른 방법과 비교하여 통계적으로 유의미한 성능 향상을 보여준다. 방법론적으로 스킵 연결과 Dense 연결은 서로 유사하지만, Table 1에서 제안하는 모델과 잔차 경로 기반 모델의 성능을 비교하면, Dense 연결이 스킵 연결 보다 음향 이벤트 검출에 효과적임을 확인할 수 있다.
Table 1.
Performance comparison of different models.
4.4 음향 이벤트 종류별 성능 평가
Fig. 4는 제안하는 모델과 잔차 경로 기반모델, CRNN 모델에서 관심 음향 이벤트 종류별 F1 점수를 보여준다. 제안하는 모델은 CRNN과 비교하여 Alarm을 제외한 모든 음향 이벤트에서 더 좋은 성능을 보여준다. 잔차 경로 기반 모델과 비교하여 제안하는 모델은 Blender와 Electric shaver를 제외한 모든 관심 음향에서 이벤트별 F1 점수가 향상된 결과를 보여준다. 특히 Dishes와 Dog 같은 임펄스 성 음향 이벤트에서 강한 성능을 확인할 수 있다. 이는 제안하는 모델이 하위 계층에서 추출한 특징이 상위 계층까지 전달되어 임펄스 성 음향 이벤트를 잘 검출한다는 것을 확인할 수 있다.

4.5 Pooling 방법에 따른 모델 성능 비교
Table 2는 제안하는 방법에 적용된 pooling 연산 종류에 따른 성능을 보여준다. AvgPool이 적용된 경우, F1점수와 PSDS1에서 유의미한 성능 향상을 확인할 수 있다. MaxPool의 경우, 추출된 하위 계층 특징이 상위 계층에서 추출된 특징값과 비교하여 작을 때, 더 이상 상위 계층으로 특징이 전달될 수 없다는 한계가 있다.
Table 2.
Performance comparison of maxpool and avgpool in the proposed model.
| Pooling | Class avg. F1-score | PSDS1 | PSDS2 |
| MaxPool | 43.59 ± 0.53 | 37.02 ± 0.54 | 58.49 ± 0.48 |
| AvgPool | 44.76 ± 0.51 | 38.98 ± 3.36 | 56.92 ± 1.31 |
4.6 제안하는 방법의 성능에 관한 논의
DCASE를 통해, 음향 이벤트 검출 성능에 관한 여러 연구가 소개된다. 최근, 주파수 별 가중치를 적용한 주파수 동적 합성곱 모델을 중심으로 음향 이벤트 검출 분야에서 최고 성능을 보여준다.[17,18] FDY[17]에서는 이벤트 기반 f1 점수에서 약 50 %의 정확도를 보여주고 있으나, 이는 데이터 증강, 후처리, 음향 모델 설계 등 성능 향상을 위한 다양한 방안이 고려된 결과이다. 반면, 본 논문에서는 음향 모델 설계를 제외한 방법은 고려되지 않았다. 제안하는 방법에서 성능 개선을 위해, 데이터 증강을 비롯하여 후처리 방안을 포함한 연구를 수행할 계획이다.
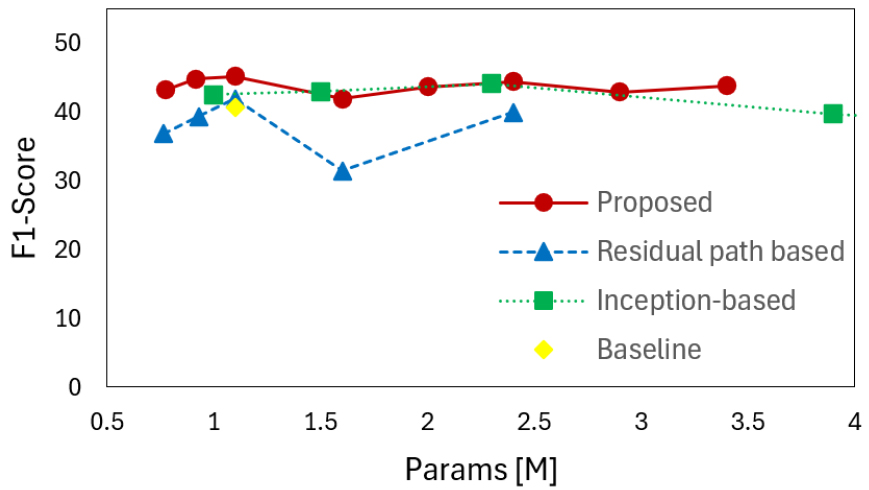
Fig. 5는 모델 크기 별 F1 점수를 보여준다. 각 모델의 크기가 클수록 F1 점수가 향상되는 것을 알 수 있다. 다만, 모델의 크기가 일정 수준을 넘어서면 모델의 성능이 향상되지 않는다. 이는 모델 학습에서 과적합이 발생한 것으로 생각된다. 또한, Fig. 5는 모델 크기 별 각 한번씩 실험한 결과로 모델 학습에서 발생하는 무작위성으로 인해 Table 1과 다른 결과를 보여준다.
V. 결 론
음향 이벤트 검출을 위해 CRNN 기반의 신경망들이 제안되었다. 본 논문은 음향 이벤트 검출에서 기존 밀집 신경망의 병목 구조의 하위 계층에서의 중요한 정보를 손실하는 문제점을 해결하기 위해 분리 밀집 신경망을 제안한다. 제안하는 모델의 FE 블록은 하위 계층에서 추출된 시간-주파수 정보를 손실 없이 상위 계층의 특징 추출 과정에 반영한다. 제안하는 모델은 DCASE 2023 Task4 테스트 베드에 기반한 성능평가에서 F1 점수 44.76 ± 0.51 %로 가장 우수한 성능을 보여주고, 모든 지표에서 유의미한 향상을 확인할 수 있다. 향후 연구 계획은 데이터 증강 기법을 적용하여 음향 이벤트 검출에서 모델의 성능을 더 높일 계획이다.
