

I. 서 론
II. 제안 모델
2.1 듀얼 컨디셔닝 구조
2.2 생성기 구조
2.3 학습 손실 함수
III. 실험 방법
3.1 데이터셋 구성(datasets)
3.2 학습 설정(Training configuration)
3.3 비교 조건
3.4 평가함수
IV. 실험 결과
V. 결 론
I. 서 론
오디오 이펙트 모델링은 기타 앰프와 페달 등의 하드웨어를 신디사이저 혹은 가상악기와 같은 소프트웨어로 대체하여 연주자에게 유연한 제작환경을 제공하는 것을 목표로 한다. 전통적인 디지털 오디오 이펙트 모델링은 주로 하드웨어 회로의 물리적 동작을 수학적으로 등가화하거나 물리적 동작을 수치해석적으로 모사하는 방식으로 이루어져 왔다. 이러한 접근은 특정 앰프나 이펙트의 동작을 정밀하게 재현할 수 있다는 장점이 있지만, 회로 내의 복잡한 비선형 소자나 시변적 특성을 충분히 반영하기 어렵고, 개별 장치마다 별도의 모델을 구축해야 하므로 새로운 장치에 대한 일반화가 제한적이다.[1]
최근에는 이러한 문제를 해결하기 위해 딥러닝 기반 접근법이 연구되고 있다. Ramírez et al.[2]은 합성곱 기반 딥러닝 모델인 CAFx 모델에 순환신경망(Recurrent Neural Network, RNN) 및 WaveNet을 적용해 다양한 오디오 이펙트를 입출력 신호 데이터 만으로 특성을 높은 정확도로 재현 할 수 있음을 입증하였다. Wright et al.[3]은 기타 앰프 및 디스토션 페달과 같은 아날로그 왜곡 회로의 비선형 특성을 순환 신경망 및 WaveNet-style 합성곱 신경망(Convolutional Neural Network, CNN)에 적용시켜 비선형 오디오 이펙트의 실시간 적용 가능성을 검증하였다. 또한, Engel et al.[4]은 생성적 적대 신경망(Generative Adversarial Network, GAN)을 이용해 WaveNet보다 빠르고 다양성이 높은 악기 음색 합성의 가능성을 보였다.
Chen et al.[5]은 기존의 연구들이 특정 장비 혹은 제한된 범위의 이펙트를 대상으로 개별적으로 모델링을 수행한 것과 달리, 톤 임베딩 을 활용한 통합적 모델링 기법을 제안하여 하나의 신경망으로 여러 앰프 톤을 재현할 수 있음을 보였다. 또한 학습이 되지 않은 앰프에 관해서도 참조 오디오로부터 임베딩을 추출해 제로샷 오디오 이펙트 전이가 가능함을 입증함으로써, 오디오 이펙트 모델링의 범용성과 확장 가능성을 진전시켰다. 그러나 해당 연구는 앰프에 국한되어 있으며, 실제 연주환경에서 빈번히 사용되는 페달 이펙트 나 앰프-이펙트 체인을 포괄하지 못하는 한계를 지닌다. 또한 톤 임베딩만을 조건으로 활용하는 방식은 특정 디바이스의 정체성을 안정적으로 보장하는데 제약이 있다.
본 연구에서는 Chen et al.[5]이 제안한 톤 임베딩 기반 모델이 앰프에 국한되고 디바이스 정체성 보장에 한계가 있다는 점을 극복하기 위해, 라벨 임베딩과 톤 임베딩을 동시에 활용하는 듀얼 컨디셔닝 접근법을 제안한다. 이를 통해 특정 오디오 이펙트의 특성을 보장하면서도, 참조 음색을 활용하여 학습되지 않은 장치의 음색 특성을 재현할 수 있다. FiLM (Feature wise Linear Modulation)기반[5]의 시계열 합성곱 네트워크(Temporal Convolutional Network, TCN)과 WaveNet[6] 구조에 이 접근을 적용해 실시간성이 요구되는 경량 모델과 고품질 합성을 지향하는 고용량 모델을 비교 분석한다. 이를 통해 기존의 개별적 이펙트 모델링 혹은 앰프 중심 모델링을 넘어, 실제 음악 제작환경에서 요구되는 앰프와 이펙트를 통합한 모델링과 제로샷 일반화 가능성을 제시한다. 본 연구에서 제로샷 모델링은 학습되지 않은 장치의 음색 특성을 추가 학습 없이 참조 오디오 임베딩만으로 재현하는 일반화 방식을 의미한다. 즉, 학습은 일부 디바이스(앰프·이펙트)로 수행되지만, 테스트 시 미학습 장치의 톤 임베딩을 입력함으로써 새로운 음색을 생성할 수 있다.
II. 제안 모델
2.1 듀얼 컨디셔닝 구조
디바이스 라벨 은 임베딩 테이블을 통해 저차원 벡터 공간으로 사상된다. 이는 특정 앰프 또는 이펙트의 정체성을 나타내는 라벨 임베딩으로, Eq. (1)과 같이 정의 된다.[5]
여기서 는 학습 가능한 벡터, 는 디바이스 라벨을 연속벡터로 바꿔주는 임베딩 함수이며, 은 차원이다. 라벨 임베딩은 각 장치(앰프 또는 이펙트)의 식별자를 학습 가능한 임베딩 테이블을 통해 저차원 연속 벡터로 변환한 것이다. 이 벡터는 모델 학습 과정에서 각 디바이스의 정체성과 주파수 응답 특성을 내포하도록 최적화되며. 결과적으로 기기별 음색적 정체성을 인코딩하는 학습 가능한 파라미터로 기능한다.
참조 오디오는 학습되지 않은 장치의 음색 특성을 추출하기 위한 기준 신호로서, 원시 파형 을 로그 멜 스펙트로그램 변환 후 2차원 합성곱 신경망 기반 톤 인코더를 통과하여 저차원 임베딩 벡터로 표현된다. 이 과정을 통해 얻어진 벡터는 참조 오디오의 전반적인 음색 정보를 포함하며, 식은 Eq. (2)와 같다. 톤 인코더는 유사한 톤의 오디오가 임베딩 공간에서 가깝게 위치하도록 대조적 자기지도 학습으로 학습되었다.
여기서 는 톤 인코더 함수이며, 은 위 과정을 통해 얻은 톤 임베딩 벡터로, 해당 참조 오디오가 가진 음색적 특성을 함축적으로 표현한다.
최종적으로 두 임베딩은 연결 후 선형 변환 및 정규화를 거쳐 하나의 통합 조건 벡터로 변환시키면 Eq. (3)과 같다. 해당 조건 벡터의 구조는 Fig. 1과 같다.
여기서 은 확장된 입력 차원을 다시 고정된 차원 로 압축한다.
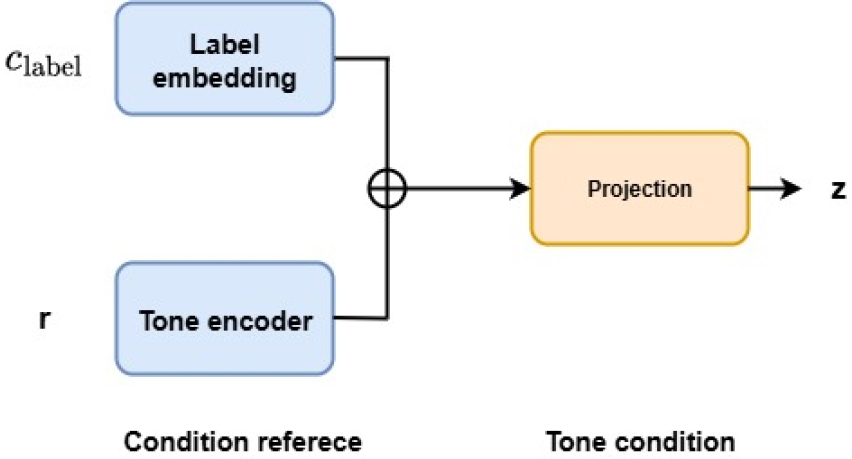
이렇게 얻어진 조건 벡터 는 FiLM 계층과 WaveNet 블록의 게이트 분기에 주입되어 각 층의 활성화를 조절함으로써 출력 신호의 톤을 제어한다. 이와 같이 구성된 듀얼 컨디셔닝 구조를 통해, 학습에 포함되지 않은 장치의 임베딩을 참조 오디오로 대체함으로서 제로샷 환경에서도 음색을 일반화 할 수 있도록 설계하였다.
2.2 생성기 구조
본 연구의 생성기 구조는 기존의 FiLM-TCN, WaveNet을 기반으로 하되, 듀얼 컨디셔닝 벡터 를 각 불록에 주입하는 점에서 차이점을 둔다.
Feature-wise Linear Modulation(FiLM)은 피처맵의 각 채널에 스케일과 시프트를 주입하여 조건 정보를 직접 반영하는 방식으로, 오디오 신호의 조건부 제어에 사용된다.[5] 또한 WaveNet은 잔차 및 스킵 연결을 갖는 딜레이티드 합성곱 구조로, 신호의 장기적 시간 의존성을 효과적으로 학습하는 생성 모델이다.[6]
먼저, FiLM-TCN의 경우 각 합성곱 블록의 출력을 라고 할 때, 듀얼 컨디셔닝 벡터 를 통해 산출된 스케일 와 시프트 를 적용하여 Eq. (4)와 같이 변조한다.
여기서 ⊙는 원소별 곱을 의미한다. 와 는 듀얼 컨디셔닝 벡터 를 입력으로 하는 선형 변환층을 통해 각각 생성된 스케일 및 시프트 파라미터이다. FiLM 계층은 이 두 파라미터를 각 합성곱 블록의 출력 에 곱·덧셈 형태로 적용하여, 조건 정보가 채널 단위로 직접 반영되어 다양한 디바이스, 톤 특성을 블록 수준에서 조정할 수 있도록 한다.
WaveNet 구조에서는 각 딜레이티드 합성곱 블록의 게이트 연산에 조건이 주입된다. 입력 에 대한 필터 경로 와 게이트 경로 에 각각 선형 변환된 조건 를 더해, 다음과 같이 출력 를 계산한다.
여기서 𝜎는 시그모이드 함수이며, 두 경로의 출력을 곱한 뒤 잔차 연결과 스킵 연결을 통해 상위 블록으로 전달한다. 와 는 각각 필터 경로와 게이트 경로에 조건을 투사하기 위한 학습가능한 가중치 행렬로, 듀얼 컨디셔닝 벡터 z가 각 경로의 활성화 정도를 제어하도록 한다. 해당 구조를 통해 라벨 및 톤 임베딩 정보가 딜레이티드 합성곱의 게이트 연산에 직접 반영되어, 학습되지 않은 장치의 음색 특성또한 유연하게 표현할 수 있다.
결과적으로, 제안하는 생성기 구조는 기존 TCN 및 WaveNet을 계승하면서도, 듀얼 컨디셔닝 벡터 를 FiLM 또는 게이트 분기에 통합하여, 앰프와 이펙트에 대한 통합 모델링과 제로샷 일반화를 동시에 달성할 수 있도록 설계하였다.
2.3 학습 손실 함수
제안하는 모델은 파형의 시간 영역과 주파수 영역 모두에서 정합성을 확보하기 위해 복합적인 손실 함수를 사용하였다. 먼저 시간 영역에서 예측 파형 과 목표 파형 간의 차이를 최소화하기 위해 평균 절대 오차(Mean Absolute Error, MAE)를 적용하였다. 평균 절대 오차는 Eq. (6)과 같이 정의한다.[2]
그러나 L1 손실만으로 왜곡된 하모닉 구조 혹은 주파수 대역별 에너지 불균형과 같은 음향적 특성을 충분히 반영하기 어렵기 때문에, 본 연구에서 다중 스케일 단기 푸리에 변환(Multi-Scale Short-Time Fourier Transform, MS-STFT) 손실을 함께 사용하였다. MS-STFT 손실은 서로 다른 FFT 크기, 윈도우 길이, 홉 길이에서 계산된 STFT 손실을 통합적으로 산출하여, 시간 해상도와 주파수 해상도 간의 균형을 유지하도록 한다.[7]
여기서 와 는 각각 예측 신호와 목표 신호의 STFT 스펙트럼을 의미하며, 는 서로 다른 스케일의 개수를 나타낸다. 최종 손실 함수는 두 항의 가중합으로 정의되며 Eq. (8)과 같다. 본 연구에서는 두 가중치의 동등한 반영을 위해 으로 설정하였다.
III. 실험 방법
3.1 데이터셋 구성(datasets)
본 연구에서 EGDB[8](앰프 5종), EGFxSET[9](이펙트 12종) 데이터셋을 사용하였다. 두 데이터셋의 구성은 Table 1에서 확인할 수 있으며, 모든 오디오는 44.1 kHz로 리샘플링 한 후 RMS –18 dBFS로 정규화하였다.[5] 이펙트나 앰프가 적용되지 않은 원신호인 클린 신호(EGDB-Audio_DI, EGFxSET-Clean)와 각 장치의 출력이 적용된 디바이스 출력을 쌍(pair)으로 구성했으며, 학습에는 약 25,000개의 샘플을 사용하였다. 데이터셋은 학습 : 검증: 테스트= 8 : 1 : 1로 분할했으며, 제로샷 실험을 위해 일부 디바이스를 학습 집합에서 제외하였다.
Table 1.
Configuration of data used.
3.2 학습 설정(Training configuration)
본 연구에서 사용한 모델 구조는 FiLM-TCN과 WaveNet 두 가지로 설정하였다. 각 모델의 세부설정은 Table 2에 제시하였다. 또한, 훈련 과정에서 사용한 하이퍼파라미터는 Table 3에서 확인할 수 있다.
Table 2.
Training configuration.
Table 3.
Common hyperparameters.
| Optimizer | AdamW |
| Learning rate | 2 × 10–4 |
| Momentum parameters | 𝛽1 = 0.8, 𝛽2 = 0.99 |
| Weight decay | 0.01 |
| Batch size | 4 |
| Epoch | 20 |
3.3 비교 조건
제안한 모델의 성능을 검증하기 위해 조건 주입 방식(Label-only / Dual conditioning)과 모델 구조(FiLM TCN / WaveNet)을 조합한 총 네 가지 경우로 설정하였다. 해당 조건으로 조건 설계와 모델 구조가 성능에 미치는 영향을 분석하였다.
3.4 평가함수
본 연구에서 모델 성능을 검증하기 위해 시간 영역과 주파수 영역에서 각각 세 가지 평가지표(MAE,[2] RMSE,[10] MS-STFT[7])를 사용하였다.
예측 파형 와 목표 파형 가 주어졌을 때 MAE는 Eq. (9)와 같고, RMSE는 Eq. (10)과 같다.
예측 신호 와 목표 신호 의 스펙트럼 유사도의 오차를 통합적으로 나타내는 MS-STFT Error는 Eq. (11)로 나타낸다.
여기서 는 스펙트럼의 에너지 차이를 나타내는 스펙트럼 수렴도 로서, 전체 스펙트럼의 정합도를 평가하는 항이다. 는 주파수 대역별 세부 차이를 반영하는 로그 스펙트럼 차이를 의미하는 항으로, 각 대역의 세밀한 스펙트럼 오차를 보완한다. 와 의 결합을 통해 시간-주파수 영역 양쪽에서 정확도를 동시에 평가할 수 있다.
IV. 실험 결과
본 연구에서 라벨 임베딩과 톤 임베딩을 동시에 수행하는 듀얼 임베딩을 제안하였다. Table 4는 FiLM- TCN과 WaveNet 구조에서 조건 주입방식에 따른 성능을 비교한 결과이다. 실험 결과 라벨 컨디셔닝 대비 듀얼 컨디셔닝 방식은 일관적인 성능 향상이 있었다. FiLM-TCN의 경우 MAE는 0.1276에서 0.0746으로, RMSE는 0.1731에서 0.0832로, MS-STFT는 1.3386에서 1.1724로 감소하였다. WaveNet에서 MAE는 0.0830에서 0.0376으로, RMSE는 0.1211에서 0.0461으로, MS- STFT는 0.4786에서 0.4238로 감소하였다.
Table 4.
Comparison of model performance based on evaluation metrics.
| Model | MAE | RMSE | MS-STFT |
|
TCN-FiLM (label only) | 0.1276 | 0.1731 | 1.3386 |
|
TCN-FiLM (dual) | 0.0746 | 0.0832 | 1.1724 |
|
WaveNet (label only) | 0.0830 | 0.1211 | 0.4786 |
|
WaveNet (dual) | 0.0376 | 0.0461 | 0.4238 |
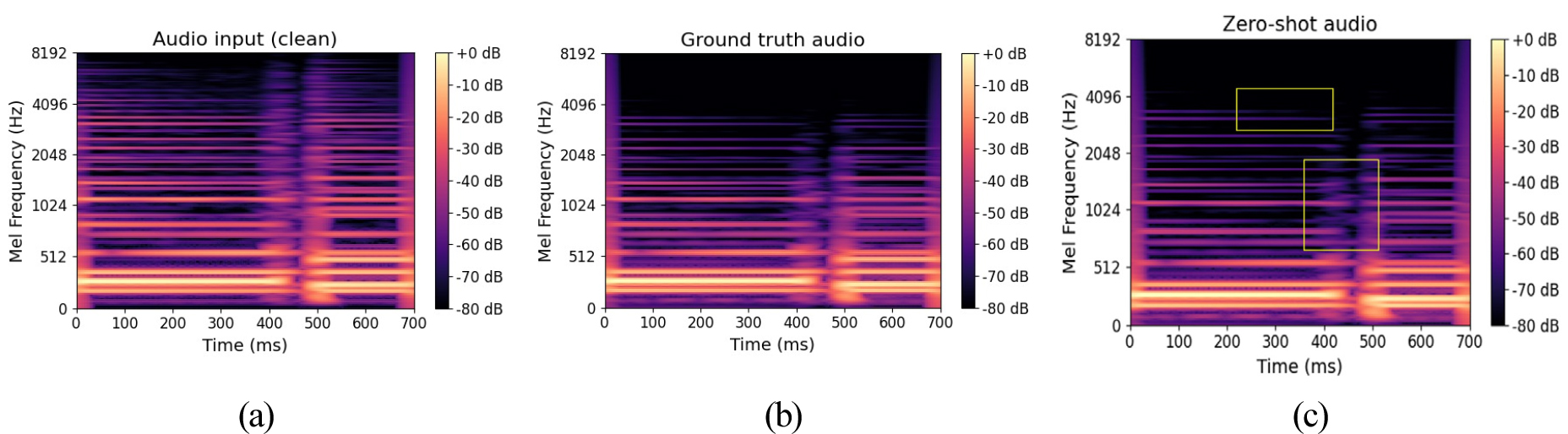
Fig. 2는 제안 모델의 제로샷 추론 결과를 스펙트로그램으로 비교한 것이다. Fig. 2(a)는 클린 입력신호, Fig. 2(b)는 목표 신호, Fig. 2(c)는 제로샷 조건에서 생성된 출력 신호를 나타낸다. 제안 모델은 학습시 사용되지 않은 디바이스에 대해서도 목표 신호와 유사한 스펙트럼 구조를 재현하였음을 확인 할 수 있다. 다만, 일부 제로샷 생성에서 노란색 박스 영역과 같이 고주파 하모닉이 다소 불규칙하게 분포하고, 중저역 배음이 희미하게 나타났다. 결과적으로 제안한 듀얼 컨디셔닝 접근법이 새로운 장치에 대해서도 일반화가 가능함을 확인할 수 있었다.
V. 결 론
본 연구에서 오디오 이펙트 모델링을 위해 라벨 임베딩과 톤 임베딩을 동시에 활용하는 듀얼 컨디셔닝 방식을 제안하고, 이를 FiLM-TCN 및 WaveNet 구조에 적용하였다. FiLM-TCN의 경우 MAE가 약 41.5 %, RMSE가 약 52 % 감소했으며, MS-STFT 오차는 12.4 %의 개선이 있었다. WaveNet 구조에서 MAE와 RMSE는 각 54.7 %, 61.9 % 감소했으며, MS-STFT 오차는 11.5 % 감소하였다. 이는 제안한 듀얼 컨디셔닝 방식이 WaveNet 구조에서 더 효과적인 것으로 보인다. 다만, 일부 이펙트에서 잔여 왜곡을 확인했으며, 향후 연구에서 이를 개선하기 위해 확장 모델링을 진행할 예정이다.
