

I. Introduction
II. Related Works
III. Proposed Method
3.1 Overall Architecture
3.2 Multi-Route Res2Block (MRBlock)
3.3 Classifier
IV. Experiment
4.1 Dataset
4.2 Experiment setting
4.3 Results
V. Conclusions
I. Introduction
The explosive growth of the digital music industry over the past decade has led to the release of vast amounts of new music every year.[1] This surge has driven significant interest in technologies that can automatically analyze and organize large-scale music collections.[2] One such field is Music Information Retrieval (MIR), which aims to extract high-level semantic information from audio signals, including genre, artist identity, tempo, and mood. These extracted representations serve as the foundation for various downstream tasks such as classification, recommendation, and music generation.[3,4]
Deep Neural Networks (DNNs) have shown remarkable success across many domains due to their strong capacity for data-driven feature learning. In MIR, DNNs have become increasingly dominant, with Convolutional Neural Networks (CNNs) in particular proving to be well-suited for learning from raw or spectrogram-based audio inputs.[5,6,7,8] This suitability arises from the hierarchical nature of music: short-term features like pitch, rhythm, and timbre accumulate over time to form higher-level patterns such as melody, emotional tone, or structure.[9] CNNs inherently exploit this compositionality by progressively aggregating local features into global representations through stacked convolutional layers.
Motivated by these characteristics, many prior works have designed CNN-based MIR models that capture either local or global musical traits. However, recent findings suggest that effective music representations are not confined to deep layers alone. Previous works demonstrated that shallow-layer features can also carry rich musical information, highlighting the importance of incorporating multiple levels of abstraction in MIR models.[10,11] Building on these insights, we identify two key considerations for designing an effective MIR system: (i) the ability to capture features across a wide range of time scales, and (ii) the ability to utilize representations from different processing depths.
To address both, we propose the Multi-Route Neural Network (MRNet), a CNN-based architecture specifically designed to extract music representations at various temporal resolutions and abstraction levels. MRNet is constructed by stacking Res2Blocks[12] with varying dilation rates along the time axis, allowing each block to specialize in a different temporal context. We further introduce the multi-route Res2Block (MRBlock), an enhanced module that splits the feature extraction path into three branches. Each branch is processed at a different depth, enabling parallel extraction of low-, mid-, and high-level features from a shared input.
We conduct evaluations of MRNet using four widely used datasets: GTZAN ,[13] FMA Small, FMA Large[14] and Melon Playlist,[15] with an emphasis on music classification tasks such as genre prediction. Through these experiments, we demonstrate that MRNet outperforms conventional CNN-based architectures and effectively learns hierarchical, multi-scale representations suitable for MIR.
II. Related Works
CNNs have been widely adopted in MIR due to their ability to model hierarchical patterns in time–frequency representations.[5,11] Many prior studies have explored CNN-based architectures tailored to various MIR tasks. For example, CNNs have been applied to timbre classification,[8] music tagging,[7] and genre classification across multiple datasets.[6,10,16] CNN-based models have also shown promise in music recommendation systems by learning user preference aligned representations from audio content.[9]
A key reason for CNNs’ popularity in MIR is their effectiveness in capturing both local and global acoustic features through progressive convolutional layers.[5] This aligns well with the hierarchical nature of music, where short-term elements such as pitch or rhythm combine over time to form long-term patterns like melody and mood.[2,4] However, many existing CNN architectures treat deep- layer features as the primary source of semantic information, often overlooking the potential of shallow- layer representations.
Recent work by Liu et al.[10] challenged this assumption by showing that shallow features can also carry discriminative information in MIR tasks. Their findings highlight the need for architectures that integrate multi- level processing and adapt to varying temporal resolutions.
III. Proposed Method
Our goal is to design a neural architecture capable of learning music representations across both diverse temporal ranges and multiple abstraction levels. To this end, we propose the Multi-Route Neural Network (MRNet), a CNN-based framework that captures features from low, mid, and high processing depths while also modeling temporal information at multiple resolutions.
3.1 Overall Architecture
Fig. 1 presents the overall structure of MRNet. MRNet comprises three MRBlocks, five Convolutional layers, and a classifier. A detailed description of MRBlock, a variant of the Res2Block, is provided in Fig. 2 and the following subsection. To capture temporal structures of varying durations, the MRBlocks are stacked with increasing dilation rates (2, 3, and 4), allowing each block to specialize in a different temporal context. We explored various configurations and numbers of stacked blocks and found that this design consistently yielded the best performance across our experiments.
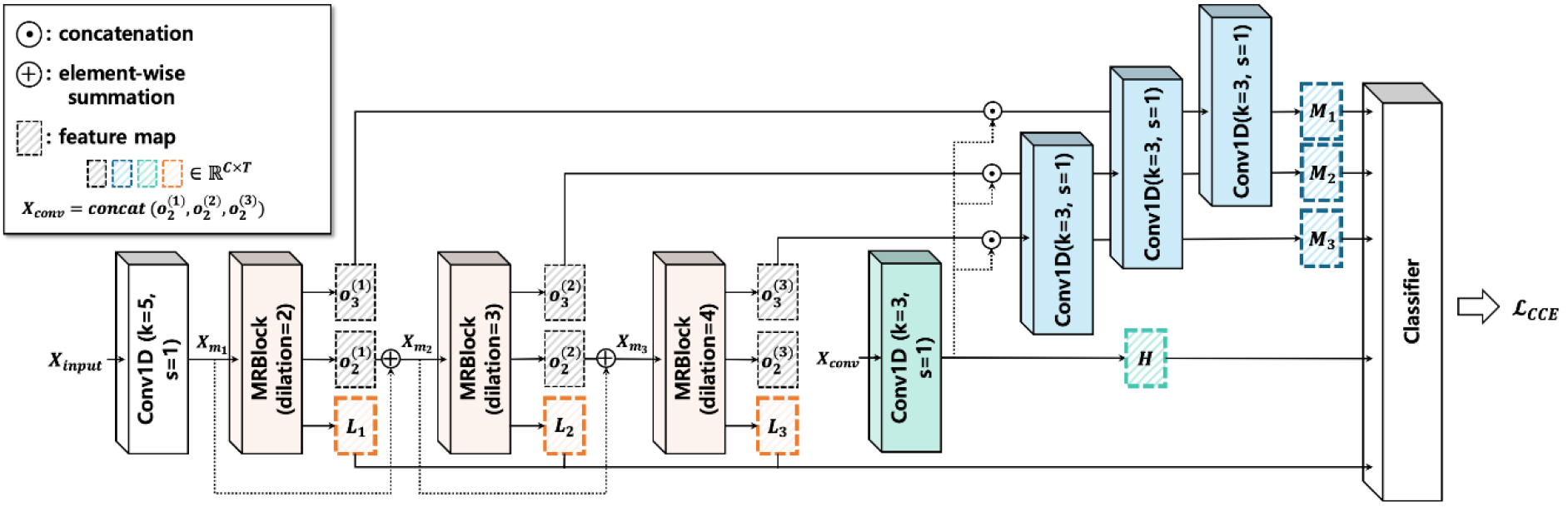
Given an input feature map, the first convolutional layer produces the input to the first MRBlock. For each MRBlock, the input is either the initial convolution output (when =1) or the element-wise sum of the previous MRBlock’s second output and its own input:
Each MRBlock produces three outputs , , . These are generated from three independent SE layers without hierarchical dependency, and the indices are assigned sequentially for notational clarity. The input of MRBlock, , is split into segment , where each is processed with residual convolution to produce . The resulting features are further transformed into and passed through SE modules to generate the final outputs , , . These outputs are used to extract representations at different depths: Low-level features (, , in Fig. 1) are directly taken from without further processing. High-level feature () is computed by concatenating , , and applying an additional convolution layer as:
Mid-level features (, , ) are generated by adding the global context to each , , and passing the result through a separate convolution:
This architectural design allows MRNet to extract low-, mid-, and high-level features in parallel, offering diverse representations for downstream classification.
3.2 Multi-Route Res2Block (MRBlock)
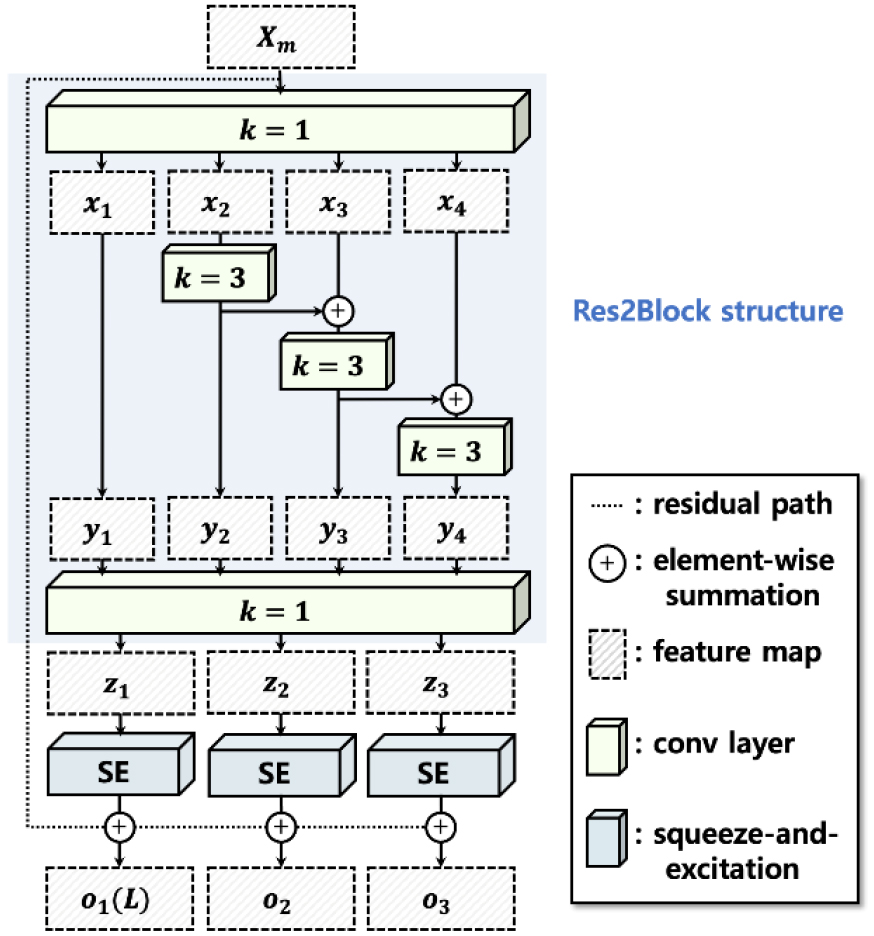
MRBlock is the core component that enables MRNet to extract multi-depth features. Inspired by findings that shallow-layer features can be effective in MIR tasks, MRBlock explicitly separates feature processing into three branches.
As illustrated in Fig. 2, the input feature map is first passed through a convolution layer and split into four segments (, ... , ) along the channel axis. Each segment is processed independently and then recombined. The output is subsequently divided into three segments corresponding to , and , and each is individually refined using a Squeeze-and-Excitation (SE) mechanism. This split-aggregate-refine process allows each output to emphasize a different level of representation while sharing the same temporal scope.
3.3 Classifier
MIR tasks vary in nature, and different target types (e.g., genre, mood) may rely more heavily on features from specific abstraction levels. To accommodate this, MRNet includes a classifier that adaptively weights and integrates the extracted features (, ... , , , ... , , ).
As shown in Table 1, each of the seven features is first passed through an Attentive Statistics Pooling (ASP) layer, which summarizes the temporal sequence into a fixed-length vector using attention-weighted mean and standard deviation. These vectors are then scaled by a learnable weight vector , and passed through a linear classifier. This design enables the network to learn task-dependent importance across multiple feature depths.
Table 1.
Detailed structure of the classifier. ASP denotes Attentive Statistics Pooling, which is applied for global pooling along the temporal axis. BN refers to 1D batch normalization.
IV. Experiment
4.1 Dataset
We evaluated MRNet on four publicly available music datasets commonly used in music information retrieval tasks. GTZAN[13] contains 1,000 audio tracks categorized into 10 distinct genres. Each track has a fixed duration of 30 seconds. It is widely used as a benchmark for genre classification. We also used both the small and large subsets of the Free Music Archive (FMA)[14] dataset. The small subset consists of 8,000 samples evenly distributed across 8 genre categories. The large subset contains 106,574 tracks labeled with 161 genre categories, with highly imbalanced class distributions. Melon Playlist[15] dataset includes 649,091 songs accompanied by metadata such as artist, album, and genre. For our experiments, we clustered tracks based on their genre annotations to create a genre classification task. Note that only spectrograms were available in this dataset; raw audio waveforms were not provided. For dataset splits, we followed the official training and evaluation protocols provided with the FMA datasets. For GTZAN and Melon dataset, we applied 10-fold cross validation following common practice in prior research. To facilitate reproducibility, we have also released the implementation of our K-fold splitting procedure on GitHub.1)
4.2 Experiment setting
We used classification accuracy as the primary evaluation metric across all datasets. For the FMA Large and Melon datasets, which contain highly imbalanced genre distributions, we additionally report the macro- averaged F1-score to better reflect performance across classes.
To obtain input features, we employed WavLM[17] as a pretrained feature extractor for the GTZAN and FMA datasets. WavLM has demonstrated strong performance in various audio-related tasks, outperforming traditional hand-crafted features. Each input waveform was transformed into frame-level embeddings using the base version of WavLM.
For the Melon dataset, since raw waveforms were unavailable, we extracted 48-dimensional Mel-spectrograms directly from the provided data. WavLM was not used for this dataset. In training process, we used the AdamW optimizer with a weight decay of 10–4. The learning rate was initialized at 10–3 and decayed to 5 × 10–4 following a cosine annealing schedule. Models were trained for 1000 epochs with a mini-batch size of 48. All experiments were conducted on two NVIDIA A5000 GPUs. The full experimental code is available on GitHub.
4.3 Results
Comparison with Previous Works. To assess the competitiveness of the proposed MRNet, we conducted music genre classification experiments across four benchmark datasets. The results are summarized in Table 2. In addition to accuracy, we report macro F1-scores for the FMA Large and Melon datasets, which exhibit significant class imbalance. MRNet achieved top performance on all four datasets, recording classification accuracies of 94.5 %, 56.6 %, 63.2 %, and 71.3 % on GTZAN, FMA Small, FMA Large, and Melon, respectively. Notably, the gains on FMA Large and Melon are particularly significant, suggesting that MRNet is well-suited for handling datasets with large-scale, fine-grained class structures. These results demonstrate MRNet’s superior generalization capability and robust clustering of musical characteristics, even in complex and diverse music collections.
Table 2.
Experimental results across various datasets. Macro F1-scores are reported only for unbalanced datasets to complement the accuracy metric.
| Models | Dataset | Samples | Accuracy (%) | Macro-f1 |
| MoER[18] | GTZAN | 1,000 | 86.4 | N/A |
| BBNN[10] | 93.9 | N/A | ||
| Siddiquee et al.[19] | 90.0 | N/A | ||
| MRNet (ours) | 94.5 | N/A | ||
| MoER[18] |
FMA (Small) | 8,000 | 55.9 | N/A |
| BBNN[10]* | 54.8 | N/A | ||
| LFCNet[16] | 55.1 | N/A | ||
| MRNet (ours) | 56.6 | N/A | ||
| BBNN[10]* |
FMA (Large) | 106,574 | 53.9 | 0.34 |
| LFCNet[16]* | 52.7 | 0.35 | ||
| MRNet | 63.2 | 0.38 | ||
| ResNet34 | Melon | 649,091 | 63.6 | 0.36 |
| SE-ResNet34 | 64.1 | 0.38 | ||
| BBNN[10]* | 60.2 | 0.36 | ||
| LFCNet[16]* | 64.7 | 0.41 | ||
| MRNet (ours) | 71.3 | 0.55 |
Ablation Study. To validate the contribution of the multi-route architecture, we conducted a route ablation study using the FMA Small dataset. Table 3 shows the performance degradation when individual routes were disabled.
Table 3.
Experiment results of route ablation experiments on the FMA-Small dataset.
| L1 | L2 | L3 | M1 | M2 | M3 | H | Acc (%) |
| 56.6 | |||||||
| × | 53.9 | ||||||
| × | 51.9 | ||||||
| × | 54.5 | ||||||
| × | 54.8 | ||||||
| × | 54.6 | ||||||
| × | 53.0 | ||||||
| × | 53.0 |
The second row in the table presents the baseline performance of the full MRNet model, which utilizes all seven feature paths. Rows 3 to 9 depict the results when one of the feature branches (e.g., , , , etc.) was removed during training and evaluation. In all configurations, performance dropped below the original 56.6 % accuracy of the full model. These findings confirm that each route contributes meaningfully to the model’s discriminative power and that the full multi-path design is essential for optimal performance.
Feature utilization by task. MRNet extracts seven feature representations: three from low-level (, ... , ), three from mid-level (, ... , ), and one from high-level () branches. Depending on the task, the importance of each feature type may vary. For example, mood classification may rely more on long-term global features, while genre classification might benefit from short-term local patterns.
To explore this, we examined the learned weights of the feature scaling vector , introduced in Section 3.3, Fig. 3 illustrates the distribution of W values after training MRNet for both genre and mood classification tasks.

The analysis shows that low-level features, especially and , were most influential in genre classification, supporting prior findings that shallow features are highly effective for this task. In contrast, mood classification placed more weight on , , and features, which have deeper and broader temporal receptive fields. These results confirm that MRNet dynamically adjusts its feature emphasis according to the target MIR objective, enhancing task-specific performance.
Although the contribution of , , and appeared relatively weak in the FMA Small dataset, Table 3 shows that removing mid-level features consistently degraded performance, indicating that these branches are not redundant and do contribute to the overall effectiveness of MRNet.
V. Conclusions
In this paper, we introduced MRNet, a novel convolutional architecture tailored for MIR. MRNet is designed to capture musical representations across multiple time scales and processing depths by employing distinct feature extraction routes. Leveraging a stack of dilated Res2Blocks and the proposed multi-route Res2Block (MRBlock), MRNet effectively extracts low-, mid-, and high-level features in parallel.
Through extensive evaluations on four benchmark datasets including GTZAN, FMA Small, FMA Large, and Melon Playlist, we demonstrated that MRNet consistently outperforms previous CNN-based approaches in genre classification tasks. In addition, our analysis of the learned feature scaling weights revealed that MRNet can dynamically prioritize different types of features depending on the specific MIR objective, such as genre or mood classification.
These results highlight MRNet’s ability to learn robust, hierarchical representations that are both flexible and task adaptive. As part of future work, we plan to extend MRNet to other MIR tasks beyond classification, including playlist recommendation, emotion prediction, and music generation, to further explore its generalization and compositional capabilities. Furthermore, we intend to analyze the differences between misclassified and correctly classified tracks to better understand the limitations of MRNet.
