

I. 서 론
II. 데이터셋과 사운드 분류 체계
III. 실험 방법
3.1 CNN 계열 모델
3.2 트리 계열 모델
3.3 실험 환경과 평가지표
IV. 실험 결과 및 분석
4.1 분류 체계에 따른 모델 성능
4.2 클래스별 인식률 분석
4.3 정확도-효율성 트레이드오프 분석
V. 결 론
I. 서 론
사운드스케이프란 특정 장소의 소리 환경, 그리고 그 소리가 인간에 의해 지각·경험되는 방식까지 포함하는 총체적 개념이다.[1] 국제 표준 ISO 12913[2]에서는 사운드스케이프를 ‘컨텍스트 안에서 사람 또는 집단이 인지, 경험하고 이해하는 음환경’으로 정의하고 있으며, 이는 단순한 물리적 소음 측정을 넘어서 음 환경에 대해 인간 중심의 접근을 강조하고 있다. 이에 따라 사운드스케이프 분석은 건축 및 환경 음향 분야에서 음향 환경을 평가하고 개선하는 핵심 도구로 자리 잡고 있으며, 나아가 도시 주거지역, 공원 등의 소음을 저감하고 쾌적한 음향 환경을 조성하기 위한 주요 지표로 발전하고 있다.[3,4]
이러한 사운드스케이프 분석을 위해서는 실시간으로 자연음과 인공음을 효과적으로 구분하는 방법이 필요하다. 특히 스마트폰, 웨어러블 기기와 같은 엣지 디바이스(Edge device)의 활용이 늘어나면서, 이러한 기기들에서 실시간으로 주변 소리를 인지하고 분류하는 기술에 대한 수요가 점차 증가하고 있다.[5] 그러나 엣지 디바이스는 대체로 연산 성능과 메모리 등의 자원이 제한적이기 때문에, 고성능 심층신경망 모델을 직접 탑재하여 구동하기에는 하드웨어의 한계가 따른다. 이러한 제약을 극복하기 위해 최근에는 적은 컴퓨팅 자원에서도 준수한 성능을 내는 경량(Lightweight) 머신러닝 및 딥러닝 모델에 관한 관심이 높아지고 있다.[6]
본 논문에서는 엣지 컴퓨팅 환경에서 효율적인 사운드스케이프 음원 분류를 위해 다양한 경량 머신러닝 모델의 성능을 종합적으로 비교 분석하였다. 이를 위해 환경음 인식에서 자주 사용되는 ESC-50 데이터셋[7]에 포함된 소리를 5가지 소리 분류 체계(Taxonomy)를 기준으로 재구성한 후, 경량 머신러닝 모델을 이용하여 분류 성능을 시험하였다. 사용한 머신러닝 모델은 CNN계열과 트리 계열 각 3종이며, CNN 계열은 MobileNetV3-Small,[8] MobileNetV2,[9] 그리고 EfficientNet-Lite0[10]를 사용하였으며, 트리 계열 모델로는 LightGBM,[11] XGBoost,[12] 그리고 Random Forest[13]를 사용하였다. 입력 특징으로는 CNN 계열은 로그 멜 스펙트로그램, 그리고 트리 계열 모델은 저차원 6종 스펙트럼 특징과 YAMNet 임베딩[14]을 사용하였다.
또한 이 모델들의 엣지 디바이스 구동 가능성을 분석하기 위해, 라즈베리파이 5의 성능 지표를 바탕으로 연산량과 지연 시간을 추정하였다. 이를 토대로 정확도와 효율성을 고려한 최적 조합을 도출하고, 실시간 응용 가능성을 제시하였다. 본 논문의 구성은 2장은 데이터셋과 사운드 분류 체계, 3장은 실험 방법, 4장은 실험 결과 및 분석, 그리고 5장 결론으로 이루어져있다.
II. 데이터셋과 사운드 분류 체계
본 논문에서는 환경음 분류 연구에서 널리 사용되고 있는 ESC-50 데이터셋을 이용하여, 사운드 분류 체계에 따른 음원 인식 실험을 수행하였다. ESC-50은 50종의 소리 클래스로 구성된 오디오 데이터셋으로서, 동물 소리, 자연환경 및 물소리, 인간 활동음, 실내 소리, 도시 소음 등의 폭넓은 소리 종류로 구성되어 있다. 오디오 클립 수는 각 클래스 당 40개씩, 총 2,000개이며, 각각은 WAV형식의 5 s 길이, 44.1 kHz, 모노 채널로 녹음되어 있다. 또한 ESC-50은 5-fold 교차 검증을 위한 폴드 구성이 제공되어 있어, 일관성 있는 성능 비교를 할 수 있다. 본 논문에서는 원 데이터셋의 50 클래스의 소리를 5가지 사운드스케이프 음원 분류 방식으로 재구성하여 사용하였다. 사용한 방식은 다음과 같다.
① ESC Top5: ESC-50 데이터셋의 공식 상위 5 분류로서 동물음(Animal sounds), 자연음(Natural sounds), 인간 비음성(Human non-speech), 실내음(Interior/ domestic), 그리고 실외음(Exterior/urban)으로 구성되어 있다. 각 분류에는 10종의 소리가 균일하게 들어있다.
② ISO L1: ISO 12913-2[15] 사운드스케이프 음원 분류를 참고하여 인간 활동외의 자연음(Nature), 인간 활동음(Human), 그리고 기타(Other) 3개 클래스로 분류하였다.
③ ISO L2: ISO L1 분류를 생물음(Natural Biophony), 지구음(Natural Geophony), 음성(Human Voice), 활동음(Human Activity), 기계음(Human Mechanical), 그리고 기타 음악이나 사회 문화적 소리(Other- Music & culture) 6 클래스로 세분화하였다.
④ Krause: Krause[16,17]가 제안한 사운드스케이프 생태학(Soundscape Ecology) 기반의 3가지 소리 출처 분류법을 기준으로 생물음(Biophony), 지구음(Geophony), 그리고 인공음(Anthropophony) 3종으로 구분하였다.
⑤ Krause Extended: Krause 3 분류에서 인공음을 인간 소리(Human)와 기계 소리(Mechanical)로 세분화하여 4 클래스로 분류하였다.
이상의 기준으로 ESC-50 데이터의 소리 클래스 매핑 결과를 Table 1에 요약하였다. 표에서 보듯 각 분류 체계별로 클래스 수가 균일하지 않다. 특히 Krause 3분류 체계에서 인공음에 해당하는 Anthropophony 클래스가 62 %로 높은 비중을 차지하며, ISO L1에서도 Human 클래스가 54 %를 차지한다. 이러한 불균형은 모델 성능에 영향을 미칠 수 있으나, 실제 환경에서의 소리 분포를 반영하는 측면이 있어 별도의 데이터 개수 조정은 하지 않았다.
Table 1.
Soundscape taxonomies and ESC-50 class distribution.
III. 실험 방법
엣지 디바이스에서 사용 가능한 사운드스케이프 음원 분류용 머신 러닝 모델 성능을 비교하기 위하여 CNN 계열 경량 모델 3종과 트리 계열 3종의 모델을 사용하여 분류 성능을 평가하였다.
3.1 CNN 계열 모델
경량 합성곱 신경망(CNN) 계열에서 파라미터 수 5 M 이하의 경량 모델 중 준수한 성능을 보이는 MobileNetV3-Small, MobileNetV2, 그리고 EfficientNet- Lite0을 3종을 선택하여 실험에 사용하였다. 모델 분류기 헤드의 구성은 MobileNetV3-Small과 MobileNetV2는 ‘백본 → Global Average Pooling → Batch Normalization → Dropout → Dense layer’로 구성되며, EfficientNet-lite0는 성능 향상을 위해 여기에 BN → Dropout이 더 추가된 구성으로 되어 있다. 학습은 ImageNet에서 사전 훈련된 백본을 활용한 전이학습을 이용하였다. 학습은 분류기 헤드만 학습하는 첫 번째 warm-up 과정 후, 다음 단계에서 백본의 일부 레이어를 해제하여 낮은 학습률과 가중치 감쇠를 적용하는 미세 조정 과정으로 구성되어 있다. 이 단계에서 MobileNetV3-Small은 백본의 마지막 65개 레이어, MobileNetV2는 마지막 30개 레이어, 그리고 EfficientNet-Lite0는 전체 백본 네트워크를 해제하여 미세 조정하였다.
ESC-50 데이터셋은 총 2,000개의 샘플로 구성되어 있어 학습 데이터만으로는 일반화 성능 확보가 어렵다. 이를 보완하기 위해 원본 오디오를 8배 증강하고 로그-멜 스펙트로그램(log-mel spectrogram)을 추출하였다. 증강 방법은 (i) 약한 잡음 혼합(0.05 – 0.10), (ii) 강한 잡음 혼합(0.10 – 0.20), (iii) 시간 이동(±0.5 s), (iv) 피치 변환(±2 반음), (v) 시간 스트레칭(0.8배 – 1.2배), (vi) 볼륨 조절(0.7배 – 1.3배), (vii) 피치 변환 + 잡음 조합을 사용하였다. 잡음은 fold별 소음 샘플 중에서 선택하거나 핑크 노이즈를 사용하였다. 모든 오디오는 44.1 kHz, 5 s로 정규화되었으며, 2048 FFT, 512 홉, 128 Mel 필터로 산출된 로그-멜 스펙트로그램(128 × 432 프레임)을 최종 특징으로 사용하였다. 전체 데이터는 원본 포함 16,000개(2,000 × 8)이다.
3.2 트리 계열 모델
트리 계열 모델은 가장 일반적으로 널리 사용되는 LightGBM, XGBoost, 그리고 Random Forest를 사용하였다. 학습 시 Optuna 베이지안 최적화[18]를 통해 각 모델의 핵심 변수를 미세 조정하였다. 트리 모델의 입력은 다음 2가지를 사용하였다.
① 데이터 2배 증강 및 음향 특성 파라미터 추출(84 차원 벡터)
② 증강없이 원 YAMNet 특징 벡터 추출(1024차원 벡터)
첫 번째 방식은 각 오디오 샘플에서 총 6종의 저차원 특징(20차원 MFCC, Spectral Centroid, Spectral Contrast, Chroma STFT, RMS Energy, Zero-Crossing Rate)을 추출하고, 각 특징에 대해 프레임 단위 평균과 표준편차를 계산하여 최종적으로 84차원 특징 벡터를 생성하였다. 이때 데이터 증강은 각 오디오 샘플별로 무작위로 (i) 백색 잡음 추가, (ii) 피치 이동(±2반음), (iii) 시간 이동(±0.2초), (iv) 음량 조절(0.7배 – 1.3배) 중 1개 – 2개의 기법을 선택하여 적용하였다. 증강은 CNN 대비 단순화된 2배 증강만 적용하였으며, 이는 트리 모델이 데이터 중복에 민감하고 과적합에 취약하다는 점을 고려한 것이다.
두 번째 방식은 대규모 오디오 이벤트 데이터셋인 AudioSet으로 사전학습된 YAMNet 모델을 활용하여 소리의 임베딩 특징을 추출한 것이다. 각 오디오 샘플은 데이터 증강없이 16 kHz 모노 신호로 변환한 뒤 5 s 길이에 맞추어 패딩 또는 절단을 수행하였다. 이후 TensorFlow Hub에서 제공되는 YAMNet을 통해 1024차원 임베딩 시퀀스를 산출하고, 시간 축 평균 풀링을 적용하여 벡터로 변환하였다.
3.3 실험 환경과 평가지표
실험은 Google Colab에서 수행했으며, 사용한 소프트웨어 스택은 Python 3.12.11, TensorFlow 2.19.0이다. 성능 평가는 ESC-50의 공식 fold를 그대로 사용한 5-fold 교차 검증으로 평가지표를 구했으며, 이때 데이터 증강은 학습 fold에만 적용하였다. 성능 평가지표는 정확도(Accuracy)와 함께 클래스 불균형을 고려하여 매크로-F1(Macro-F1)과 균형 정확도(Balanced accuracy) 3가지를 사용했다. 매크로-F1은 각 클래스에 대한 F1-score를 산출한 후 평균한 값이며, 균형 정확도는 클래스별 재현율(Recall)의 평균이다.
IV. 실험 결과 및 분석
4.1 분류 체계에 따른 모델 성능
사운드스케이프 음원 분류 체계에 따른 모델 실험 결과를 Fig. 1에 나타내었다. 모델별 성능은 세 가지 평가지표(정확도, 매크로-F1, 균형 정확도) 모두에서 YAMNet 특징을 사용한 트리 모델이 분류 체계와 무관하게 가장 우수한 성능을 보였고, 다음으로는 CNN 계열의 경량 모델, 그리고 전통적 특징 기반 트리 모델이 가장 낮은 성능을 보였다.
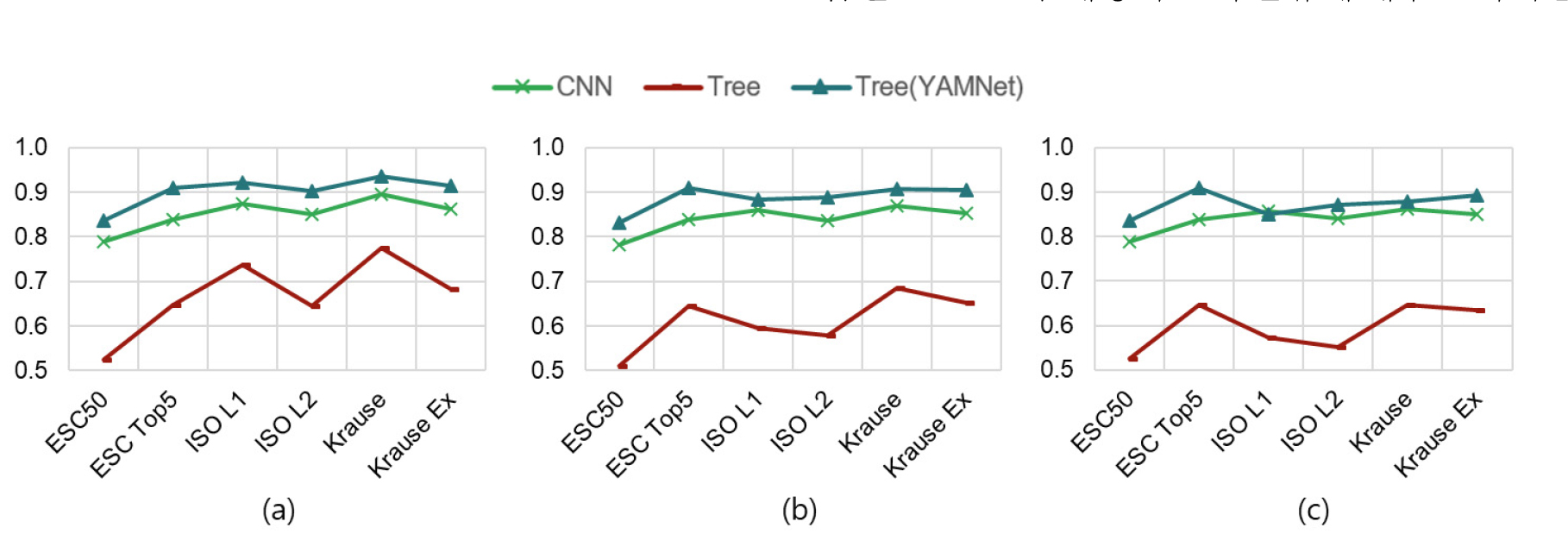
세부적으로 Table 2에 제시한 정확도를 보면, YAMNet 특징을 사용한 트리 모델은 ESC50 분류에서도 평균 83.2 % ~ 84.2 %로 CNN 모델과 비슷하거나 약간 더 높은 성능을 보였으며, Krause 분류에서는 91.7 % ~ 94.7 %, ISO L1 분류에서는 90.1 % ~ 93.6 %에 달하는 높은 정확도를 달성하였다. 이는 사전 학습된 YAMNet 임베딩이 소리 분류에 매우 효과적인 특징을 제공하며, 이를 활용하면 간단한 트리 모델만으로도 우수한 성능을 얻을 수 있음을 시사한다. 트리 모델간에는 XGBoost와 LightGBM이 Random Forest보다 전반적으로 약간 더 나은 성능을 보였다. 반면 전통적 저차원 특징을 사용한 트리 모델 그룹은 ESC50 분류에서 평균 50.6 % ~ 53.9 %의 낮은 정확도를 기록했으며, 가장 단순한 Krause 분류에서도 평균 74.6 % ~ 77.5 %에 머물러 복잡한 환경음 분류에는 한계가 있음을 보여주었다. 이는 저차원 특징만으로는 다양한 소리 클래스를 충분히 표현하기 어렵기 때문으로 분석된다. CNN 모델은 YAMNet 특징을 사용한 트리 모델보다는 성능이 약간 낮았으나 저차원 특징을 사용한 트리모델보다는 우수했다. 각 CNN 모델의 성능은 대체로 비슷했으나, 전반적으로 EfficientNet-Lite0이 약간 더 우수한 결과를 나타내었다.
Table 2.
Accuracy across taxonomies and model families.
Table 3의 매크로- F1과 Table 4의 균형 정확도 결과 역시 정확도 지표와 매우 유사한 경향을 보인다. 이 두 지표는 클래스 불균형에 더 강건한 평가지표임에도 불구하고, 모델 그룹 간의 성능 순위와 분류 체계 단순화에 따른 성능 향상 추세는 동일하게 유지되었다. 특징적으로 전통적 특징 기반 트리 모델의 경우, 이 두 지표에서 정확도보다 더 낮은 점수를 기록하는 경우가 많아 소수 클래스 분류 성능이 더욱 취약함을 알 수 있다.
Table 3.
Macro-F1 across taxonomies and model families.
Table 4.
Balanced accuracy across taxonomies and model families.
분류 클래스 개수의 영향을 살펴보면 클래스 수가 적은 Krause(3개)나 ISO L1(3개) 분류로 갈수록 모든 모델 그룹의 성능이 전반적으로 향상되는 경향을 보였다. 이는 분류 체계가 단순화될수록 모델이 각 클래스를 더 명확하게 구분할 수 있음을 시사한다. 세부적으로 살펴보면, Table 2의 Accuracy에서 CNN 모델 그룹은 ESC50 원 분류에서는 평균 77.8 % ~ 80.2 %의 정확도를 보였으나, 클래스 수가 3개로 줄어드는 Krause 분류에서는 89.1 % ~ 90.2 %까지 성능이 향상되었다.
결론적으로, 분류 체계의 복잡도(클래스 수)는 모든 모델의 성능에 영향을 미치지만, YAMNet과 같은 고품질 사전 학습 임베딩을 활용하면 경량 트리 모델만으로도 복잡한 CNN 모델을 능가하는 우수한 분류 성능과 더불어 클래스 불균형에도 강건한 결과를 얻을 수 있음을 확인하였다.
4.2 클래스별 인식률 분석
Table 5는 가장 좋은 성능을 보인 XGBoost + YAMNet 모델의 예측 결과 혼동 행렬이며, 이를 통해 소리 클래스별로 인식률의 차이를 알 수 있다. 대부분의 분류 체계에서 인간음, 동물음, 기계음과 관련된 소리는 대체로 높은 인식률을 보였다. 그 이유는 첫째, 인간이나 동물이 내는 소리는 대체로 ‘바람’이나 ‘물소리’ 등과는 달리, 비교적 명확한 스펙트럼 패턴과 배음 구조를 가지므로 모델이 비교적 쉽게 구분할 수 있기 때문으로 분석된다. 둘째, YAMNet의 사전 학습 특성이다. YAMNet은 ‘Speech’, ‘Animal’, ‘Vehicle’ 등의 소리를 포함하는 AudioSet으로 사전 학습되었다. 이는 본 논문에서 사용된 ‘Human Voice’, ‘Biophony’, ‘Mechanical’ 클래스들과 직접적으로 대응된다. 따라서 YAMNet 임베딩 자체가 이미 이들 클래스를 구별하기 위한 특징을 효과적으로 추출했고, XGBoost 모델은 이를 기반으로 높은 분류 성능을 달성한 것으로 판단된다.
Table 5.
Confusion matrices of 5-fold accuracy (%) of the XGBoost + YAMNet model for each of the five soundscape taxonomies (Rows: true labels, Columns: predicted labels).
반면, 특정 클래스 간에는 명확한 오인식 경향이 나타났다. 가장 주목할 만한 오인식 경향은 ‘자연 잡음’과 ‘인공 잡음’ 간의 혼동이다. Table 5(d)의 Krause 분류에서 ‘Geophony’의 인식률은 78.9 %에 그쳤으며, 20.0 %의 샘플이 ‘Anthropophony’로 오인식되었다. 또한 Table 5(e)의 Krause Extended에서 ‘Geophony’는 ‘Mechanical’ 클래스로 15.0 % 오인식되었으며, Table 5(c)의 ISO L2에서도 ‘Natural Geophony’(NG)는 ‘Human Mechanical’(HM) 클래스로 11.8 % 오인식되었다. 이는 Geophony에 속하는 ‘바람(wind)’, ‘비(rain)’, ‘불타는 소리(crackling_fire)’ 등의 음원이 Mechanical에 속하는 ‘엔진(engine)’, ‘비행기(airplane)’, ‘전기톱(chainsaw)’ 등의 소리와 유사한 광대역잡음 스펙트럼 특성을 갖기 때문이며, 이에 따라 두 클래스 간의 혼동이 있는 것으로 분석된다.
또 다른 오인식의 원인은 소수 클래스로 인한 것이다. Table 5(b)의 ISO L1 ‘Other’ 클래스는 76.9 %의 가장 낮은 인식률을 보였으며, 다수 클래스인 ‘Human’으로 16.9 % 오인식되었다. 분류를 세분화한 Table 5(c)의 ISO L2 분류의 OT 역시 79.4 %의 인식률을 보이며, 10 %가 HM(Human)으로 오인식되었다. 이는 Other 클래스가 전체 데이터의 8 %(Table 1 참조)에 불과한 극소수 클래스라는 점에 기인한다. 이와 같은 심각한 데이터 불균형으로 인해 모델이 소수 클래스의 특징을 충분히 학습하지 못하고, 데이터의 과반을 차지하는 HM 클래스로 예측하는 결과를 가져온 것으로 보인다.
이상에서 알 수 있듯 분류 성능을 높이기 위해서는 다른 인공지능 문제와 같이 특징 추출 방법과 학습 데이터의 균일성이 중요하며, 더불어 인공음과 스펙트럼이 유사한 자연음을 효과적으로 분류하는 방법이 고려되어야 할 것으로 생각된다.
4.3 정확도-효율성 트레이드오프 분석
각 모델의 엣지 디바이스에서 효율성을 검증하기 위해 라즈베리파이 5에서 사용하는 ARM Cortex- A76(2.4 GHz) 성능을 기준으로, 각 모델의 총 연산 시간을 계산하였다. 제시된 시간값은 실측치가 아니라 FLOPs 계산과 라즈베리파이5의 이론적 처리량을 기반으로 도출한 추정치이다. 따라서, 실제 하드웨어에 탑재하여 구동 시에는 최적화 수준과 I/O 오버헤드 등에 따라 차이가 발생할 수 있으나, 제시된 값을 이용하여 각 모델 간의 효율성을 이론적으로 상대 비교하는 용도로는 충분한 타당성을 갖는다.
라즈베리파이5의 CPU 연산 성능은 오픈소스 벤치마크(OpenBLAS) 기반 측정에서 약 31.4 GFLOPS로 보고된 바 있으나,[19] 이는 4코어 전체를 최적 조건에서 활용했을 때의 이론적 성능에 해당한다. 실제 응용에서는 메모리 대역폭, 최적화 정도에 따라 연산량이 감소한다. 따라서 본 논문에서는 보수적인 가정을 적용하여 4코어 합산 약 2-4 GFLOPS의 실효 연산 성능을 기준으로 삼았다. 모든 계산은 5 s 길이의 단일 채널 오디오(44.1 kHz, FFT 크기 2048, 홉 크기 512, 멜 필터 128)를 입력으로 가정하였으며, FLOPs는 행렬 곱셈 및 FFT 복잡도(O(N log N))를 반영하여 추정하였다.
Tables 6과 7, 그리고 Fig. 2에 모델별 연산 복잡도와 라즈베리파이 5에서의 처리 지연 시간 예측값을 보였다. CNN 모델은 약 2.3 M – 7.5 M 파라미터와 0.06 GMACs – 0.8 GMACs의 연산량을 요구하며, CPU(FP32) 환경에서 15 ms – 400 ms, TFLite INT8 최적화 시 5 ms – 100 ms의 추론 시간이 소요되는 것으로 추정된다. 로그멜 스펙트로그램 특징 추출 시간(~35 ms – 70 ms)을 포함할 경우 전체 처리 시간은 약 50 ms – 470 ms 범위이며, TFLite INT8 환경에서는 최대 170 ms의 처리 시간이 예측된다.
Table 6.
CNN model complexity and latency on Raspberry Pi 5.
Table 7.
Tree-based model complexity and latency on Raspberry Pi 5 (Num. classes = 5).
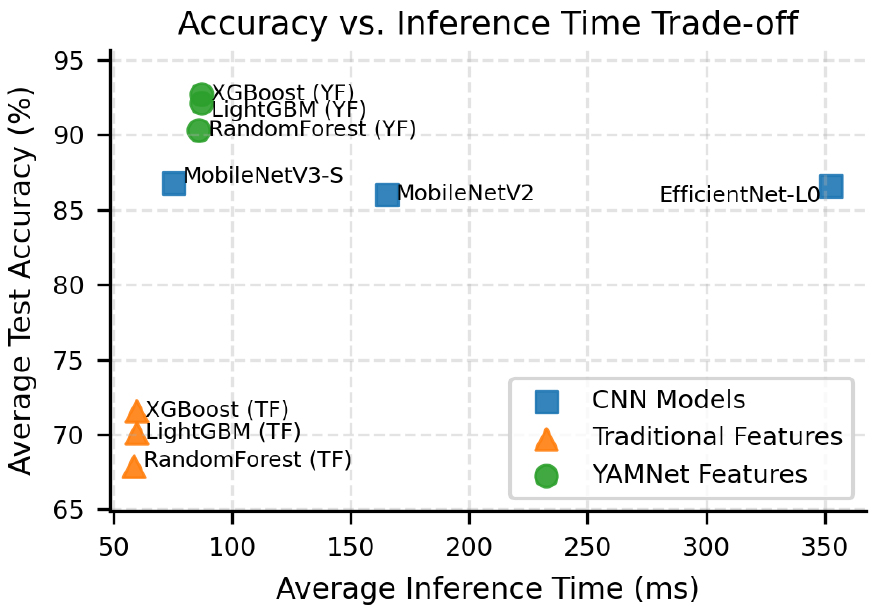
트리 기반 모델의 경우, 추론 자체의 연산량은 매우 작아(0.05 MFLOPs – 0.3 MFLOPs, 0.5 ms – 3 ms) 전체 지연은 사실상 특징 추출 단계에 의해 결정된다. 5개 클래스 분류를 기준으로 했을때, 전통적 저차원 특징(84차원)을 사용하면 약 30 ms – 85 ms, YAMNet 임베딩(1024차원)을 사용하면 약 45 ms – 125 ms의 특징 추출 시간이 소요되어, 최종 처리 시간은 각각 31 ms – 88 ms, 그리고 46 ms – 128 ms 수준으로 추정된다.
이러한 결과는 상대적으로 연산 비용이 높은 CNN 모델 대비, 트리 모델의 연산 효율성이 매우 좋다는 것을 보여준다. 특히, Fig. 2에서 명확히 드러나듯 YAMNet 임베딩과 트리 분류기의 조합은 가장 낮은 연산 부담으로 CNN 모델들을 능가하는 최고 수준의 정확도를 달성하여 가장 효율적인 트레이드오프를 보였다.
V. 결 론
엣지 컴퓨팅 환경에서 실시간 사운드스케이프 음원 분류를 위한 경량 머신러닝 모델들의 성능을 비교 분석하였다. 주요 결과는 다음과 같다. 첫째, YAMNet 임베딩을 사용한 트리 모델이 모든 분류 체계에서 우수한 정확도를 보였다. 이는 적절한 사전훈련 모델의 전이학습 효과가 뛰어남을 나타낸다. 둘째, 연산 속도 측면에서는 트리 모델이 경량 CNN 보다 빠른 추론 속도를 보여 엣지 디바이스 환경에 더 적합할 것으로 보인다. 셋째, 분류 체계가 단순할수록 모든 모델의 성능이 향상되었다. 따라서 사운드스케이프 실시간 분류 시 적절한 분류 체계와 카테고리 수 설정이 필요하다. 이상의 결과는 엣지 디바이스 실시간 사운드스케이프 모니터링에 YAMNet과 같은 사전학습 모델의 임베딩을 경량 트리 모델과 결합하는 방식이 효율적인 방안이 될 수 있음을 보여준다. 다만, 본 연구에서 제시한 효율성 지표는 실제 측정이 아닌 추정치라는 한계가 있어 상대적인 비교에만 의미가 있다. 향후 연구에서는 실제 엣지 디바이스에서의 추론 시간 및 인식 성능 평가, 다양한 환경에서의 강건성 검증, 그리고 온디바이스 학습 기능 구현 등을 수행할 예정이다.
