

I. 서 론
II. 전이학습
2.1 깊은 신경망을 이용한 전이학습
2.2 음성 및 음악으로부터의 전이학습
III. 성능 평가
3.1 데이터베이스
3.2 기준 실험
3.3 전이학습 실험
IV. 결 론
I. 서 론
최근 딥러닝 분야의 발전은 음성인식[1-3]이나 화자인식[4,5]과 같은 응용분야에서 놀랄만한 성능 향상을 가져왔다. 깊은 신경망은 딥러닝 분야의 대표적인 모델로써, 많은 양의 데이터를 바탕으로 훈련된 깊은 신경망을 이용한 모델링 방법은 데이터의 특성을 효과적으로 표현할 수 있는 방법으로 주목받고 있다. 하지만, 깊은 신경망을 훈련하기 위해서는 충분한 양의 데이터가 필요하기 때문에, 많은 양의 데이터가 확보되지 않는 상황에서는 과적합문제가 발생할 수 있다. 전이학습(transfer learning)[6,7]은 위와 같은 문제를 해결하기 위한 방법으로, 데이터의 양이 충분한 도메인으로부터 훈련된 모델을 이용하여 데이터가 적은 도메인에 대한 모델을 훈련한다.
최근에는 교차-언어 음성 인식(cross-lingual automatic speech recognition)[8,9]과 같이 깊은 신경망을 활용한 전이학습에 대한 연구가 활발하게 진행되고 있다. Das와 Hasegawa-Johnson[8]은 영어로 훈련된 깊은 신경망을 이용하여 터키어에 대한 깊은 신경망을 훈련하는 전이학습에 대한 연구를 수행하였다. 또한, Huang et al.[9]은 몇 가지의 언어를 함께 이용하여 다중-언어 깊은 신경망(multi-lingual deep neural network)을 훈련하여 타겟 언어에 대한 초기 모델로 활용하였다. 이들은 모두 많은 양의 데이터에 대한 초기 깊은 신경망을 비교사 사전훈련 과정으로부터 훈련한 뒤 교사 미세조정 과정을 거쳐 적은 양의 데이터에 대한 깊은 신경망을 훈련하는 공통점을 보인다. 여기서 비교사 사전훈련 과정은 레이블정보를 필요로 하지 않기 때문에 비슷한 특성을 갖는 다른 도메인의 데이터를 활용하는데 용이하다는 장점이 있다.
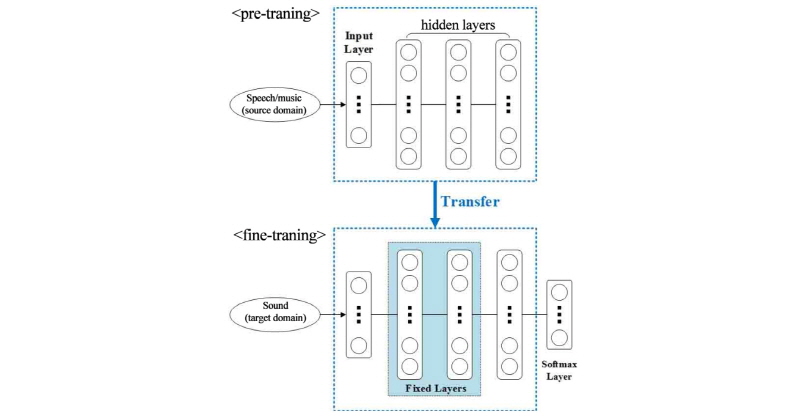
사운드 이벤트 분류 분야에도 standard deep neural network,[10] CNN(Convolutional Neural Network)[11]과 같은 딥러닝 기술을 이용한 방법이 최근 활발하게 연구되고 있다. 하지만, 사운드 이벤트는 음성이나 음악에 비해 길이가 짧은 특성을 갖고 있고, 적은 양의 데이터베이스가 대다수이기 때문에 제한적인 수의 은닉 계층(hidden layer) 또는 은닉 노드(hidden node)로 이루어진 소규모의 깊은 신경망을 사용하고 있는 실정이다. 이러한 한계를 극복하기 위해 본 논문에서는 Fig. 1에서와 같은 음성 및 음악으로부터 사운드로의 전이학습 방법을 제안한다. 제안하는 방법은 레이블 정보가 없는 음성 및 음악 데이터를 이용하여 훈련된 초기 깊은 신경망 모델을 사운드 이벤트 데이터를 이용하여 훈련하는 과정으로 이루어진다. 제안하는 방법에 대한 효과성을 입증하기 위해 사운드 이벤트 분류 실험을 수행하였으며, 음성 및 음악으로부터의 전이학습으로 훈련된 사운드 이벤트에 대한 음향 모델과 사운드 이벤트 데이터만으로 훈련된 음향 모델 사이의 성능을 비교하였다.
II. 전이학습
2.1 깊은 신경망을 이용한 전이학습
깊은 신경망은 입력 계층과 출력 계층, 그리고 두 개 이상의 은닉 계층들로 이루어진 다층퍼셉트론이다. 일반적으로 출력 계층은 데이터의 클래스 수에 맞게 설정된다. 입력 계층의 경우 데이터로부터 추출된 특징을 사용하여 구성하며, 특히 음성이나 음향과 같은 연속적인 데이터에 대해서는 시간적인 변화 패턴을 처리하기 위해서 몇 개의 연속적인 프레임에 대한 특징벡터로 구성된 입력을 사용한다. 이러한 깊은 신경망의 계층들은 시그모이드 혹은 하이퍼볼릭 탄젠트와 같은 비선형 함수를 통해 연결되는데, 이를 통해 깊은 신경망은 입력 데이터에 대한 효과적인 특징을 추출할 수 있게 된다.
일반적으로 깊은 신경망의 훈련은 두 단계로 이루어진다. 먼저, 계층 단위의 비교사 사전훈련을 통해 초기 모델을 생성하고, 오류역전사 방식을 통한 교사 미세조정을 수행한다. 사전훈련 과정을 통해 훈련된 깊은 신경망은 랜덤하게 초기화된 깊은 신경망에 비해 더 나은 초기 값을 제공하며, 효과적인 미세조정을 가능하게 한다. 서로 다른 도메인의 데이터를 활용하는 전이학습은 위와 같은 깊은 신경망의 훈련 과정에 쉽게 적용할 수 있다. 먼저 데이터의 양이 풍부한 소스 도메인으로부터 깊은 신경망을 사전훈련한 뒤 이를 전이시켜 적은 양의 타겟 도메인의 데이터를 이용한 미세조정을 수행한다. 특히 사전훈련 과정은 레이블 정보가 필요하지 않기 때문에, 레이블 사이의 변환과정 없이 유사한 도메인의 데이터를 쉽게 활용할 수 있다는 장점이 있으며, 음성 및 음악으로부터 사운드로의 전이학습을 용이하게 한다.
2.2 음성 및 음악으로부터의 전이학습
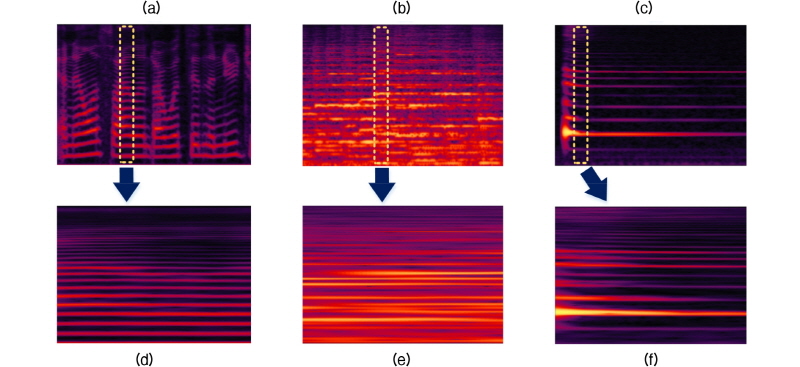
사운드 이벤트 분류를 위한 음향 모델을 깊은 신경망 방식으로 훈련하기 위해서는 많은 양의 사운드 이벤트 데이터가 필요하지만, 사운드 이벤트의 특성상 데이터베이스의 크기가 제한적인 경우가 많다. 하지만, 음성인식 혹은 음악 정보검색에서 일반적으로 사용되는 음성이나 음악 데이터베이스는 대규모의 깊은 신경망을 훈련하기에 적합한 크기를 갖고 있다. Fig. 2의 (a)-(c)는 음성(영어 낭독), 음악(관현악), 그리고 사운드(현의 진동)의 스펙트로그램을 나타낸다. Fig. 2의 (d)-(f)는 위 스펙트로그램을 100 ms 단위로 확대한 모습으로, 모두 수평 방향의 유사한 패턴을 보이고 있다. 여기서, 100 ms는 음성이나 음악에 대한 깊은 신경망에서 통상적으로 사용하는 입력의 길이로, 사운드와 음성 혹은 사운드와 음악은 깊은 신경망의 입력관점에서 서로 비슷한 음향 특성을 갖는다는 것을 의미한다. 따라서 음성 및 음악 데이터를 이용한 깊은 신경망 기반의 전이학습을 통해 사운드 이벤트에 대한 음향 모델을 효과적으로 학습할 수 있다.
III. 성능 평가
3.1 데이터베이스
본 논문에서 제안하는 깊은 신경망 기반의 전이학습의 성능 평가를 위해 RWCP(Real World Computing Partnership)[12] 사운드 이벤트 데이터베이스를 사용하였다. 총 100개의 사운드 이벤트 클래스로 구성된 이 데이터베이스는 두 물체 사이의 충돌, 기체의 분사, 종이 찢는 소리, 악기 소리, 전화벨 소리 등과 같은 다양한 종류의 사운드 소스와 그들 사이의 상호 작용으로 구성되어 있으며, 본 논문에서는 이들 중 50개의 사운드 이벤트를 사용하였다. 각 클래스는 100개의 사운드 클립으로 구성되었으며, 실험에서는 훈련과 테스트에 각각 70개와 30개의 사운드 클립을 사용하였다. 총 1시간 정도의 분량을 갖는 데이터베이스의 사운드들은 평균 1 s 정도의 짧은 길이로 이루어져 있다.
전이학습을 위한 음성 데이터베이스로는 영어 낭독체로 구성된 DARPA(Defense Advanced Research Projects Agency) RM(Resource Management)[13]의 SI- training 데이터베이스를 사용하였다. 또한 음악 데이터베이스로는 블루스, 클래식, 컨츄리, 디스코, 힙합, 재즈, 메탈, 팝, 레게, 락의 총 10개 장르로 구성된 GTZAN[14]데이터베이스를 사용하였으며, Table 1에는 앞서 언급한 세 종류의 데이터베이스의 구성을 정리하였다.
Table 1. Configuration of three databases. | ||
Database | # clips | Total durations |
RWCP | 5,000 | 1 hour |
RM (SI-training) | 4,000 | 4.4 hours |
GTZAN | 1,000 | 8.3 hours |
3.2 기준 실험
전이학습의 효과를 비교하기 위한 기준 실험으로 RWCP 데이터베이스만을 이용하여 훈련된 깊은 신경망의 사운드 이벤트 분류 성능을 측정하였다.
먼저 계층 단위의 RBM(Restricted Boltzmann Machine)을 훈련하여 깊은 신경망에 대한 초기 모델인 DBN (Deep Belief Network)을 생성하였다. DBN의 첫 번째 계층은 실수 값의 입력을 위해 일반적으로 사용되는 GBRBM(Gaussian-Bernoulli RBM)을 사용하였으며, 나머지 계층은 BBRBM(Bernoulli-Bernoulli RBM)을 사용하였다. 입력으로는 13개의 연속적인 프레임에 대한 520차의 Mel-filterbank 로그 에너지를 사용하였으며(프레임당 40차), 10 ms의 프레임 크기(50 % overlap)를 사용하였다. 이렇게 훈련된 DBN의 최상위 계층에 소프트맥스 계층을 덧붙인 다음 오류 역전사 방법을 이용하여 미세조정을 수행하였다. 실험에 사용된 학습율 미니배치의 크기와 같은 모수(parameter)는[15]에서 사용한 기본 값을 사용하였다. Table 2는 은닉 계층의 수와 은닉 노드의 수의 변화에 따른 깊은 신경망에 대한 사운드 이벤트 분류 실험 결과를 나타내었다. 전반적으로 은닉 노드 수의 증가는 오류율의 감소를 가져왔다. 하지만, 은닉 계층의 수의 증가는 오히려 오류율을 증가시키는 효과를 가져왔으며, 심지어 은닉 계층의 수를 가장 적게 사용했을 때 가장 좋은 성능(3.81 %)을 얻을 수 있었다. 이처럼 RWCP와 같은 작은 규모의 데이터베이스를 이용하여 큰 규모의 깊은 신경망을 훈련하는 경우, 앞서 언급한 바와 같이 과적합 문제가 발생하여 오히려 작은 규모의 깊은 신경망에 비해 성능이 감소하게 된다.
3.3 전이학습 실험
전이학습에 대한 성능을 평가하기 위해, 3.1절에서 언급했던 음성 및 음악 데이터베이스로 훈련된 DBN을 이용하여 사운드 이벤트에 대한 깊은 신경망을 훈련하였다. 모든 실험에서는 6개의 은닉 계층을 갖는 깊은 신경망을 사용했으며, 은닉 노드의 수는 512개에서 부터 2,048개 까지 증가시켰다.
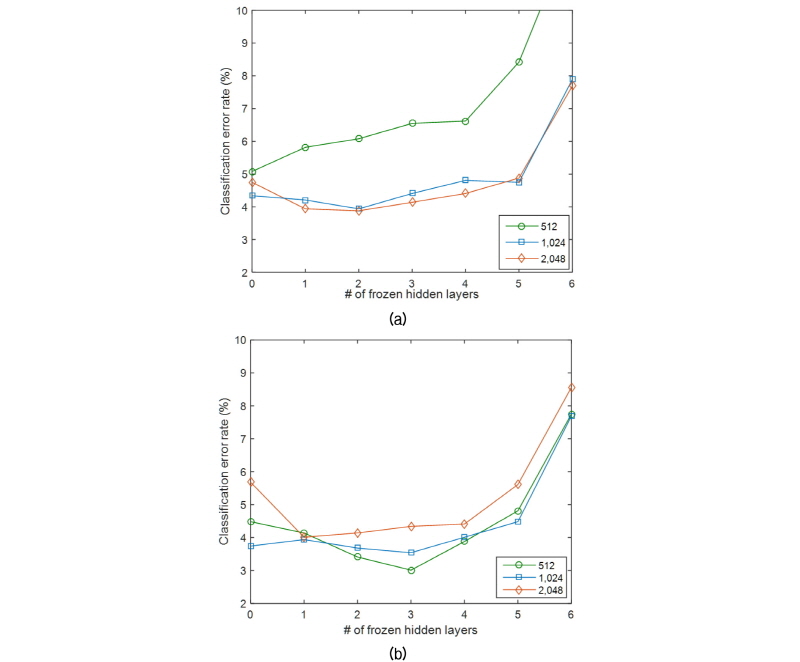
일반적인 교차-언어 전이학습에서는 미세조정 과정에서 나머지 계층들은 그대로 둔 채(frozen)[16] 랜덤하게 초기화 된 소프트맥스 계층만을 훈련한다. 이는 모든 계층을 미세조정 할 경우 타겟 데이터베이스의 크기가 작아서 과적합 문제가 발생할 수 있기 때문이다. Fig. 3에는 frozen 계층의 수에 따른 전이학습의 성능을 나타내었는데, 여기서 frozen 계층의 수가 0개라는 것은 통상적인 깊은 신경망에서와 같이 모든 은닉 계층을 미세조정 과정에서 훈련한 것을 의미한다. 결과에서 보듯이 frozen 계층의 수를 감소시킬수록 분류 오류율이 감소하는 모습을 보였으며, 2개 혹은 3개의 frozen 계층을 사용하였을 때 가장 좋은 성능을 보였다. 즉, 미세조정 과정에서 보다 많은 은닉 계층을 같이 훈련할수록 좋은 성능을 보이고 있는데, 이는 전이학습과 관련된 기존의 연구들[9,17]과는 반대되는 경향성을 나타낸다. 이와 같은 결과는 전이학습에 사용된 소스 데이터와 타겟 데이터 사이의 유사도에서 그 이유를 찾을 수 있다. 음성 및 음악과 사운드 사이의 유사도는 교차-언어 전이학습에서 사용되는 서로 다른 나라의 음성들 사이의 유사도에 비해 낮다. 그렇기 때문에 음성 및 음악으로부터 훈련된 모델을 전이하는 과정에서 하위 계층들도 함께 훈련하여 사운드의 특성을 좀 더 반영할 때 보다 좋은 성능을 나타낸 것으로 해석된다.
음성과 음악을 결합한 데이터베이스를 이용하여 사전훈련을 수행할 때 데이터베이스의 크기와 훈련 데이터의 다양성의 증가로 추가적인 성능 향상을 기대할 수 있다. Fig. 4는 음성과 음악을 함께 이용하여 사전훈련 했을 때의 실험 결과를 나타낸다. 전체적인 경향성은 앞선 실험에서와 마찬가지로 미세조정 과정에서 소프트맥스 계층만을 훈련하는 것보다 하위의 은닉 계층을 함께 훈련하는 것이 더 좋은 성능을 보였지만, 기대와는 다르게 성능은 오히려 감소하는 모습을 보였다. 이러한 결과는 유사도가 높지 않은 음성과 음악 데이터를 함께 이용했기 때문이라고 생각할 수 있으며, 데이터베이스를 함께 사용하여 훈련을 할 때에는[8,9]의 경우와 같이 유사도가 높은 데이터를 선정하는 것이 중요하다는 사실을 의미한다.
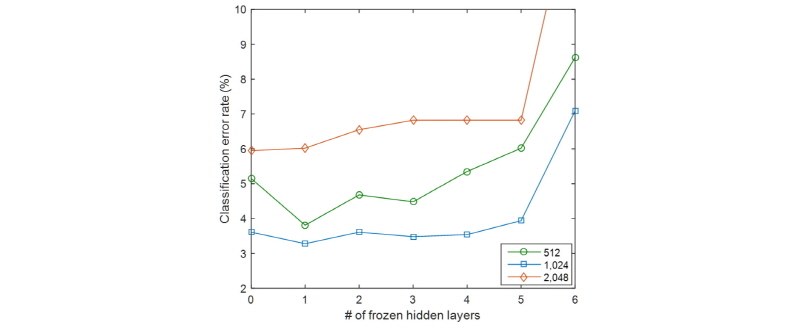
마지막으로 기준 실험과 전이학습의 성능 및 오류 감소율을 Table 3에 정리하였다. 기준 실험에 대한 성능은 Table 2의 결과 중 6개의 은닉 계층을 사용한 실험 결과를 의미하며, RM과 GTZAN을 이용한 전이학습은 Fig. 3의 각 그래프에서 가장 낮은 오류율을 갖는 결과를 의미한다. RM의 경우 은닉 노드의 수를 증가시켰을 때 성능이 향상되는 모습을 보였으나, GTZAN의 경우에는 반대의 양상을 보였다. 대부분의 경우 기준 실험에 비해 향상된 성능을 보였으며, GTZAN을 사용한 실험에서 512개의 은닉 노드로 구성된 깊은 신경망이 3.01 %의 가장 낮은 오류율을 보였다. 또한, 기준 실험에서의 가장 좋은 성능인 3.81 %의 오류율에 비해 21 % 정도의 성능 향상을 보였다. 결과적으로 많은 양의 음성 또는 음악을 이용한 전이학습은 데이터의 양이 부족한 사운드 이벤트를 위한 깊은 신경망을 훈련할 수 있도록 하며, 이를 통해 사운드 이벤트의 특성을 잘 표현할 수 있는 음향 모델을 얻을 수 있다.
IV. 결 론
본 논문에서는 적은 양의 사운드 이벤트의 음향 모델 훈련을 위한 방법으로 음성을 이용한 깊은 신경망 기반의 전이학습을 제안하였다. 음성과 사운드의 유사점을 바탕으로 음성으로부터 훈련된 깊은 신경망을 초기 모델로 하여 사운드 이벤트에 대한 음향모델을 훈련하였다. 제안하는 방법에 대한 성능 평가를 위해 사운드 이벤트 분류 실험에서의 오류율을 측정하였으며, 제안하는 방법은 기준 실험인 사운드 이벤트 데이터만으로 훈련된 깊은 신경망에 비해 20 % 이상의 상대적인 오류율 감소를 보였다. 본 연구는 오디오를 이용한 보안 감시와 같이 제한적인 양의 데이터베이스를 이용한 분야에서 효과적으로 활용될 수 있을 것으로 기대된다.
