

I. 서 론
Ⅱ. 제안 모델
2.1 멀티 서브밴드 분할 구조
2.2 시계열 합성곱 네트워크(TCN)
2.3 학습 손실 함수 및 옵티마이저
Ⅲ. 실험 방법
3.1 데이터셋(datasets) 구성
3.2 학습 파이프라인
3.3 성능 지표
IV. 실험 결과
V. 결 론
I. 서 론
오디오 이펙트의 모델링은 전자악기 및 오디오 소프트웨어 분야에서 원음에 특수한 음색과 왜곡을 추가하여 앰프 혹은 페달을 사용하지 않아도 해당 회로 구성을 사용할 수 있도록 한다. 기존의 오디오 이펙트 모델링 방식은 주로 물리적 회로 분석 및 시스템 식별 기법을 통해 특정 이펙트 유닛의 수학적 모델을 정립하는 방식으로 수행되었다. 하지만 이러한 기존 방식은 이펙트 장치 내의 복잡한 비선형 요소 및 시변적 특성을 정확히 구현하기 어려우며, 특정 이펙트 회로에 지나치게 최적화되어 있어 일반화가 어렵다는 단점이 있다.[1]
최근 딥러닝 기술의 급속한 발전에 따라 이러한 오디오 이펙트 모델링에 신경망 기반 접근법이 도입되기 시작했다. Ramírez et al.[2]은 원신호-비선형 신호를 1 대 1로 매칭시켜 학습하는 블랙박스 방식의 오디오 이펙트 모델링을 위해 합성곱 신경망(Convolutional Neural Network, CNN), 순환 신경망(Recurrent Neural Network, RNN) 및 WaveNet[3] 구조를 활용한 다양한 딥러닝 모델을 연구하였으며, 이를 통해 비선형 신호인 진공관 앰프, 트랜지스터 기반 리미터 등 다양한 오디오 이펙트를 효과적으로 모델링 할 수 있음을 보였다. 또한 Wright et al.[4]은 블랙박스 방식으로 기타 앰프의 비선형 특성을 WaveNet 및 순환 신경망 모델을 이용하여 효과적으로 구현하고 실시간으로 동작 가능함을 입증하였다. 또한 Engel et al.[5]은 미분 가능한 디지털 신호 처리를 이용하여 해석적이고 해석 가능한 신경망 기반의 음성합성 방식을 제안하였으며, 이는 전통적인 신경망 구조 대비 적은 연산량과 우수한 표현력을 동시에 달성하였다.
그러나 기존 신경망 기반의 오디오 이펙트 모델링 접근법은 대부분 입력 오디오 신호를 하나의 주파수 대역에서 처리하며, 다양한 주파수 대역에서 나타나는 복잡한 비선형 특성을 충분히 표현하지 못한다는 한계를 지니고 있다.[2,4,5] 특히, 기타 앰프 등 비선형 오디오 장치에서 각 주파수 대역에서 발생하는 왜곡 특성의 차이를 세밀하게 반영하지 못한다. 비선형 오디오 이펙트에서 고음역대는 클리핑으로 인해 하모닉이 강하게 생성되고 동시에 저역에서는 드라이브 증가에 따른 에너지 왜곡이 두드러지게 나타난다. 이를 단일 모델로 표현하는 것은 어려움이 있다.
본 연구에서는 이러한 문제를 극복하기 위해 입력 오디오 신호를 여러 개의 주파수 서브밴드로 나누어 각 서브밴드에서 독립적인 비선형 모델링을 수행한 후, 이를 다시 합성하여 최종 출력을 생성하는 다중 서브밴드 기반의 접근법을 제안한다. 이 접근법은 주파수 서브밴드별로 독립적인 신경망 구조를 사용하여 각 밴드의 특성에 최적화된 비선형 특성을 학습할 수 있으며, 다중 서브밴드를 이용한 시계열 합성곱 네트워크(Temporal Convolutional Network, TCN)[6] 구조는 주파수 대역별로 서로 다른 특성을 가진 복잡한 이펙트 장치의 효과적인 모델링을 가능케 하고, 이를 통해 음향적 표현력을 대폭 개선할 수 있다. 이를 통해 다양한 실제 오디오 이펙트 장치들의 복잡한 비선형 특성을 보다 효율적이고 정확하게 표현하며, 모델의 일반화 성능을 향상시키는 것을 목표로 한다.
Ⅱ. 제안 모델
2.1 멀티 서브밴드 분할 구조
본 연구에서 입력 오디오 신호에 여러 개의 대역 통과 필터를 순차적으로 적용하며, 전체 주파수 범위를 서브밴드 형태로 세분화하였다.
여기서 는 각 밴드의 저역 및 고역 경계 주파수이며, 는 샘플레이트(sample rate)이고, 은 서브밴드의 개수이다. Eq. (1)을 기반으로 각 밴드 에 대해 중심 주파수를 갖는 대역 통과 필터 를 구성한다.
시간 영역 임펄스 응답 로 표현되는 필터를 오디오 신호 에 적용하면, 서브밴드 신호 는 Eq. (2)로 정의될 수 있다.
다중 서브밴드의 분할 구조는 Fig. 1(a)와 같다. 입력된 오디오 신호 는 {}로 분해되며, 다중 서브밴드 구조는 전체 주파수 범위를 등분하여 각각의 대역에서 신호를 추출한 형태로 볼 수 있다. 분해한 각 서브밴드 신호를 로 표기했을 때, Eq. (3)와 같은 텐서 구조를 얻는다.
여기서 는 서브밴드 텐서(subband tensor)이며, 는 배치 크기(batch size), 는 시간축 샘플 길이(framesize)에 해당한다. 즉 하나의 신호 가 N개의 대역 필터로 나뉘고, 각 서브밴드는 특정 주파수 구간의 성분만을 주로 포함한다. 이 서브밴드 구조는 비선형 오디오 이펙트에서 많이 발생하는 고역 하모닉이나 저역 공진현상을 세밀하게 처리할 수 있다.
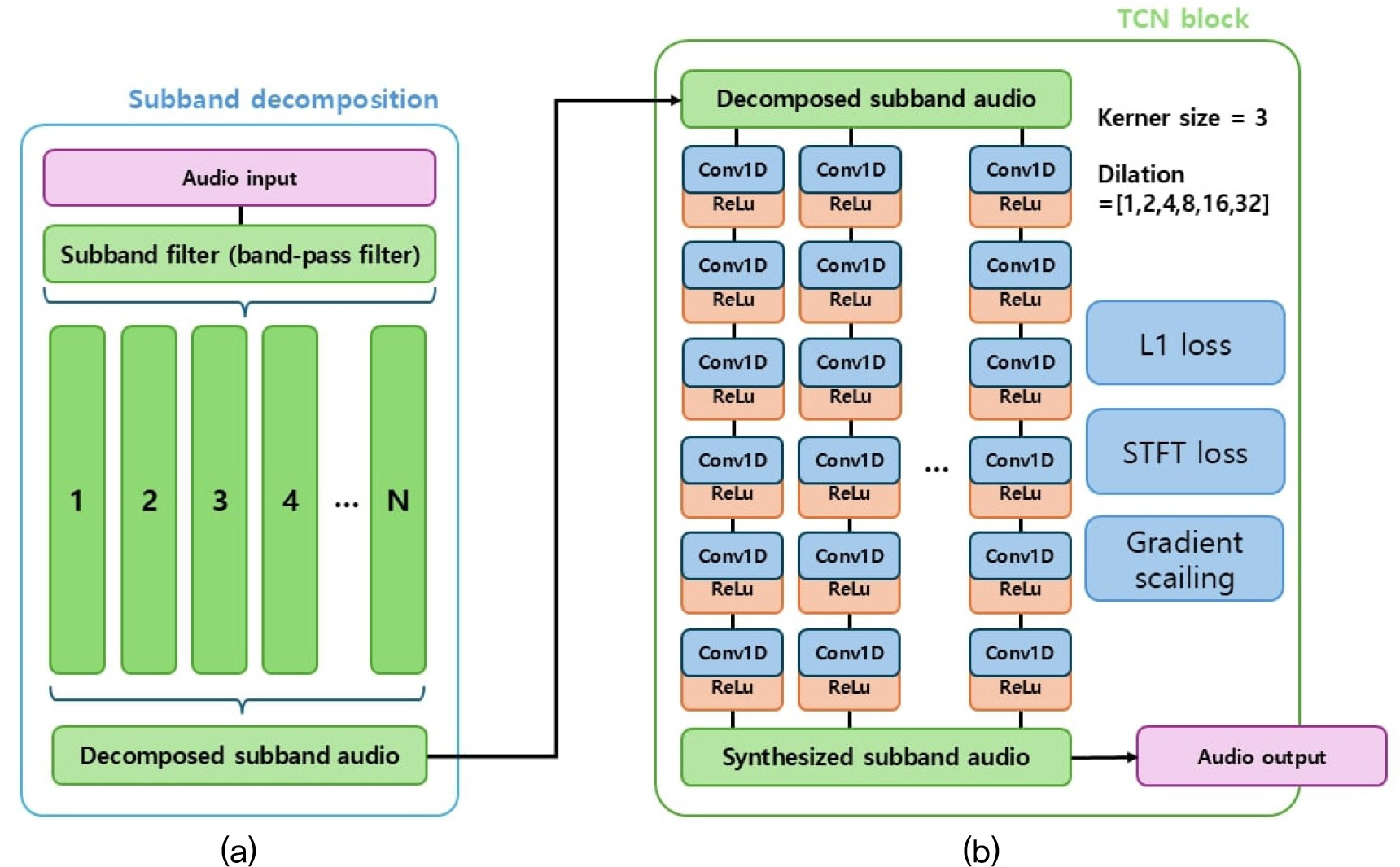
2.2 시계열 합성곱 네트워크(TCN)
다중 서브밴드로 분할된 오디오 신호를 처리하기 위해 TCN 구조를 적용한다. 제안 모델인 서브밴드 TCN(sTCN)은 각 레이어에서 1D 컨볼루션에 딜레이션(dilation)을 증가시키며 넓은 시계열 정보를 학습한다. 입력 는 Eq. (3)의 형태로 주어지며, TCN의 최종출력도 가 되어, 서브밴드마다 비선형 처리된 결과를 제공한다.
TCN의 핵심은 Conv1D에 딜레이션 를 적용하는 것이다. 딜레이션이 없는 일반적인 1D 컨볼루션에서, 출력 는 Eq. (4)로 표현된다.
여기서 는 커널 크기, 은 입력채널이다. 딜레이션 가 적용될 경우는 Eq. (5)과 같다.
이를 통해 각 레이어가 훨씬 넓은 리셉티브 필드(receptive field)를 갖게 되며, 긴 시간 범위에 걸친 비선형 의존성을 학습할 수 있게 된다.
TCN은 여러 개의 1차원 컨볼루션 레이어를 딜레이션 값과 함께 스택(stack) 형태로 쌓아 올린다. 각 레이어 에서 출력 는 Eq. (6)로 정의된다.
여기서 는 -번째 레이어 입력, 는 해당 레이어의 학습 가중치, 는 딜레이션 계수, 는 커널(필터)의 길이, 는 활성화 함수를 의미한다. 따라서, -번째 레이어는 커널 크기 와 딜레이션 로 구성된 1차원 컨볼루션을 수행한 뒤, 비선형 활성화 𝜙를 적용함으로써 긴 시계열 의존성을 효율적으로 학습하게 된다. 마지막으로, Conv1D의 채널 차원을 다시 서브밴드 개수 ()로 맵핑한다.
즉, 최종 출력 는 Eq. (7)로 표현되며, 입력과 동일한 (배치, 서브밴드, 시간) 형태를 가지게 된다. Fig. 1(b)에서 본 연구에서 적용한 sTCN의 전체 구조를 확인 가능하다.
2.3 학습 손실 함수 및 옵티마이저
이라 표기하는 파형 L1 손실은, 출력 파형 과 정답 파형 간의 샘플 단위 절댓값 오차를 평균하여 구한다. 단일 채널 파형에 대한 식은 Eq. (8)과 같다.
이를 배치 차원 B로 확장하면 Eq. (9)와 같다.
본 연구에서 기타 앰프, 디스토션 페달과 같은 비선형 오디오 이펙트를 모델링할 때, 파형의 과도 응답까지 직접적으로 맞추는 데 효과적인 L1 손실을 채택한다. 그러나, 파형만으로는 고역 하모닉 분포나 음색상의 차이를 충분히 잡아내기 어렵기 때문에, Short Time Fourier Transform(STFT) 기반 손실()도 병행하여 채택한다. STFT 손실은 복소 스펙트럼 STFT()에서 진폭을 추출해 Eq. (10)으로 정의한다.
여기서 M은 STFT 프레임의 총 개수, 은 -번째 프레임에 해당하는 복소 스펙트럼을 의미하며, 은 주파수축의 L1 노름을 나타낸다. 해당 STFT 손실 구조는 진폭(magnitude) 스펙트럼 간 차이만을 비교하며, 위상(phases)의 부정합(mismatch)으로 인해 발생한 예측 손실 값의 과도한 증가를 방지한다. 이후, 두 손실()을 결합해 최종 학습손실 을 구성한다. 최종 학습손실은 Eq. (11)로 정의된다.
여기서, 𝛼, 𝛽는 가중치이다. 본 연구에서 두 손실을 동등하게 반영하기 위해 두 가중치를 𝛼 = 0.5, 𝛽 = 0.5로 설정했다.
최종손실 을 최소화하기 위해, AdamW 옵티마이저를 사용했다. 일반적인 Adam 알고리즘과 유사하나, weight_dacay항을 별도로 적용함으로서 L2정규화와는 다른 형태로 과적합 억제와 학습 안정성을 도모한다. 옵티마이저의 업데이트 식은 Eq. (12)와 같다.
여기서 𝜂는 학습률 는 AdamW 로 추정된 파라미터𝜃의 기울기이다. 학습 과정은 먼저 미니배치 ()를 모델에 입력한 뒤, 을 계산한다. 다음으로 역전파(backprop)를 통해 를 추정하고 AdamW의 파라미터 𝜃를 갱신한다. 해당 에폭(epoch)을 반복하여 수렴시키면 비선형 오디오 이펙트의 복잡성을 안정적으로 학습할 수 있다.
Ⅲ. 실험 방법
3.1 데이터셋(datasets) 구성
본 연구에서 사용한 데이터셋은 EGDB dataset[7]이다. 해당 데이터셋에는 240곡의 전자기타 악보를 기반으로 20 s ~ 30 s가량의 기타 연주를 녹음한 오디오 데이터셋이며, 총 1,600곡가량의 오디오 파일이 존재한다. Table 1에서 본 연구에서 사용한 데이터셋을 구성을 확인할 수 있다. 데이터셋의 입력 데이터인 Direct Input(DI)과 출력데이터인 기타 앰프, 디스토션 페달등 비선형 오디오 이펙트의 페어(pair) 데이터를 약 900곡의 쌍을 구성하여 샘플 단위로 정렬된 상태에서 학습을 진행한다. 이를 위해 해당 오디오 파일들을 다음과 같은 절차로 전처리를 진행했다.
Table 1.
Configuration of data used.
| The name of the data | Number of audios |
| audio_DI | 240 |
| audio_Marshall | 240 |
| audio_Mesa | 240 |
| audio_Plexi | 240 |
| audio_Ftwin | 240 |
먼저, 신호를 앰프를 통과시켜 얻은 출력에는, 장비 내부 또는 인터페이스 지연에 의해 몇 샘플에서 수백 샘플 단위의 오프셋(offset)이 발생할 수 있다. 이 오프셋이 존재하면, 모델이 두 신호가 동시간대에 대응한다는 사실을 정확히 학습하기 어렵다. 따라서 오프셋을 방지하기 위해, 페어 데이터 한 쌍마다 최대 길이를 기준으로 패딩(padding)하거나, 상호상관(cross-correlations)을 이용해 샘플 단위로 정렬을 수행했다.
따라서, 정렬된 신호 와 는 정확히 같은 시간축 {1,2,...,}에 대응하게 된다. 이는 모델 학습 시 Eq. (13)의 형태로 1 대 1 매칭이 이루어짐을 의미한다.
이후 샘플레이트를 44.1 kHz로 리샘플링(re-sampling)을 한다. 리샘플링 과정에서 샘플 정렬이 깨질 수 있으므로, 통일된 샘플레이트를 사용하는 편이 학습 안정성과 데이터 관리 면에서 유리하다. 리샘플링이 완료된 오디오 신호는 실제 모델에 입력하기 전 일정 프레임 단위(65536샘플)로 슬라이싱을 한다. 이는 2가지 목적을 지닌다. 먼저, 슬라이싱으로 프레임 단위 학습을 수행함으로서 연산량을 제한해 미니배치 학습이 가능하며, 프레임 시작점을 무작위로 고정하여 전체 오디오 구간 중에서 무음(silence) 혹은 단조로운 연주 구간만 반복학습 하는 것을 방지한다. 최종적으로 오디오 데이터는 (1, 65536)의 샘플 구조를 가지는 약 12,000개의 페어-데이터로 변환되어 데이터셋을 구성하게 된다. 이후, 구성한 전체 데이터셋을 랜덤하게 학습(train), 검증(vaildation), 테스트(test) 7:1.5:1.5의 비율로 분할해 학습을 진행했다.
3.2 학습 파이프라인
다중 서브밴드 TCN 모델을 학습시키기 위한 학습 파이프라인을 구성했다. sTCN의 가중치는 He 초기화를 사용해 무작위로 설정하였다. 또한, 별도의 배치 정규화 계층 없이 학습을 진행하였다. Table 2에서 하이퍼 파라미터를 확인할 수 있다.
Table 2.
Hyperparameters used for learning subband TCNs.
| Batch size | 4 |
| Epoch | 20 |
| LR schedule | 1 × 10-3 |
| Optimizer | AdamW |
3.3 성능 지표
본 연구에서 오디오 출력 와 정답 출력 간의 유사도를 평가하기 위해 Root Mean Square Error(RMSE),[1] Mean Absolute Error(MAE),[1,2] STFT error[10] 3가지 지표를 사용했다.
여기서 T는 파형의 길이를 나타낸다.
IV. 실험 결과
본 연구에서 비선형 오디오 이펙트 모델링을 학습하기 위해 다중 서브밴드 TCN 모델 sTCN을 제안했다. 실험에서 서브밴드의 개수를 2개 ~ 32개로 증가시키며 모델 학습을 진행했다. Fig. 2는 서브밴드 개수를 각각 단일, 2개 ~ 32개로 설정했을 때, 에폭별 학습 손실과 검증 손실 변화를 보여준다. Figs. 2(a) ~ (e)는 손실이 완만하게 감소하는 양상을 보여 학습이 적절히 이뤄지고 있음을 확인할 수 있다. 반면에, Fig. 2(f)에서 서브밴드 개수가 32개일 때, 학습 손실과 검증 손실이 교차하며 큰 변동 폭을 보이는 것을 확인할 수 있다. 이는 밴드 수가 과도하게 커져 모델 파라미터가 늘어나면서 학습 난이도가 올라갔음을 시사한다.
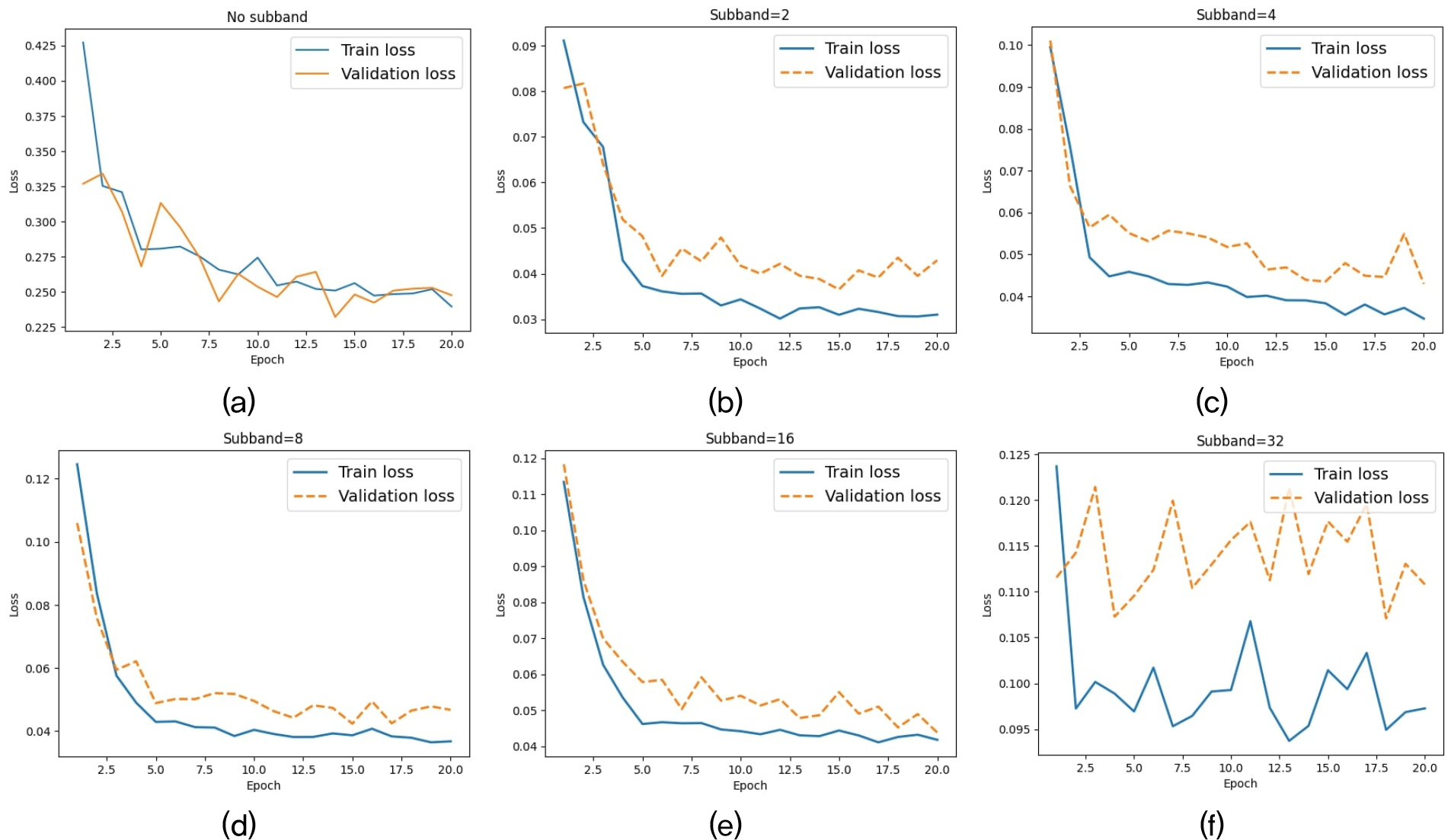
Table 3는 다중 서브밴드의 개수를 변화시키며 학습한 TCN 모델의 평가 지표를 정리한 것이다. 서브밴드의 개수가 늘어날수록 RMSE, MAE, STFT error 모두 전반적으로 감소하는 추세를 보인다. 이는 고역과 저역을 분리하여 모델링함으로써, 대역 특유의 비선형 왜곡을 더 정밀하게 학습할 수 있기 때문으로 보인다. 하지만 서브밴드 개수가 32개일 때 STFT error가 큰 폭으로 증가하는 것을 확인할 수 있으며, 너무 세분화된 대역 분할은 위상 오류와 과적합을 일으키는 것을 확인할 수 있다. Fig. 2와 Table 2를 종합했을 때, 서브밴드가 16개일 때, 단일 밴드 TCN에 비해 RMSE가 약 60 % MAE와 STFT error가 약 45 %의 성능개선을 확인하여 학습에서의 손실과 성능지표를 종합했을 때 가장 안정적이고 우수한 결과를 보인다.
Table 3.
Average performance indicators by number of subbands.
| Subbands | RMSE | MAE | STFT error |
| No subbands | 0.3958 | 0.2852 | 0.9606 |
| 2 | 0.2275 | 0.1758 | 1.2553 |
| 4 | 0.2274 | 0.1798 | 0.9264 |
| 8 | 0.1998 | 0.1613 | 0.5722 |
| 16 | 0.1519 | 0.1577 | 0.5243 |
| 32 | 0.1882 | 0.1488 | 1.1710 |
Fig. 3은 타깃 오디오(ground truth)와 출력 오디오(synthesized output)를 시간축에서 비교하기 위한 파형을 시각화한 것이다. 신호의 변화와 에너지 분포를 확인하기 위해 샘플 오디오를 동일한 시간축(3.00 s ~ 3.40 s)을 설정했다. Fig. 3(a)는 단일 밴드 TCN으로 학습했을 때 타깃 오디오와 모델 출력의 비교이다. 모델 출력의 진폭이 –0.25 ~ 0.25로 타깃 오디오에 비해 출력이 약한 것을 확인할 수 있다. Fig. 3(b)는 서브밴드가 16개일 때 타깃 오디오와 모델 출력의 비교이다. 두 파형을 비교했을 때 세부적인 진폭과 위상이 차이가 나는 것을 확인할 수 있다. 이는 모델이 위상 정보를 완벽히 복원하지 못했기 때문으로 보인다. 반면에, 모델 출력의 진폭이 –0.5 ~ 0.5 사이로 타깃 오디오와 유사한 진폭을 가지는 것을 확인 할 수 있다. 단일 밴드 TCN과 sTCN은 전체 시간 구간에서 타깃 오디오와 유사한 감쇠패턴을 가지는 것을 확인할 수 있다. 특히 sTCN에서 유사한 진폭과 감쇠패턴을 가지는 것을 확인할 수 있는데, 이는 모델이 이펙트의 주기성과 패턴을 적절히 학습한 것으로 보인다.
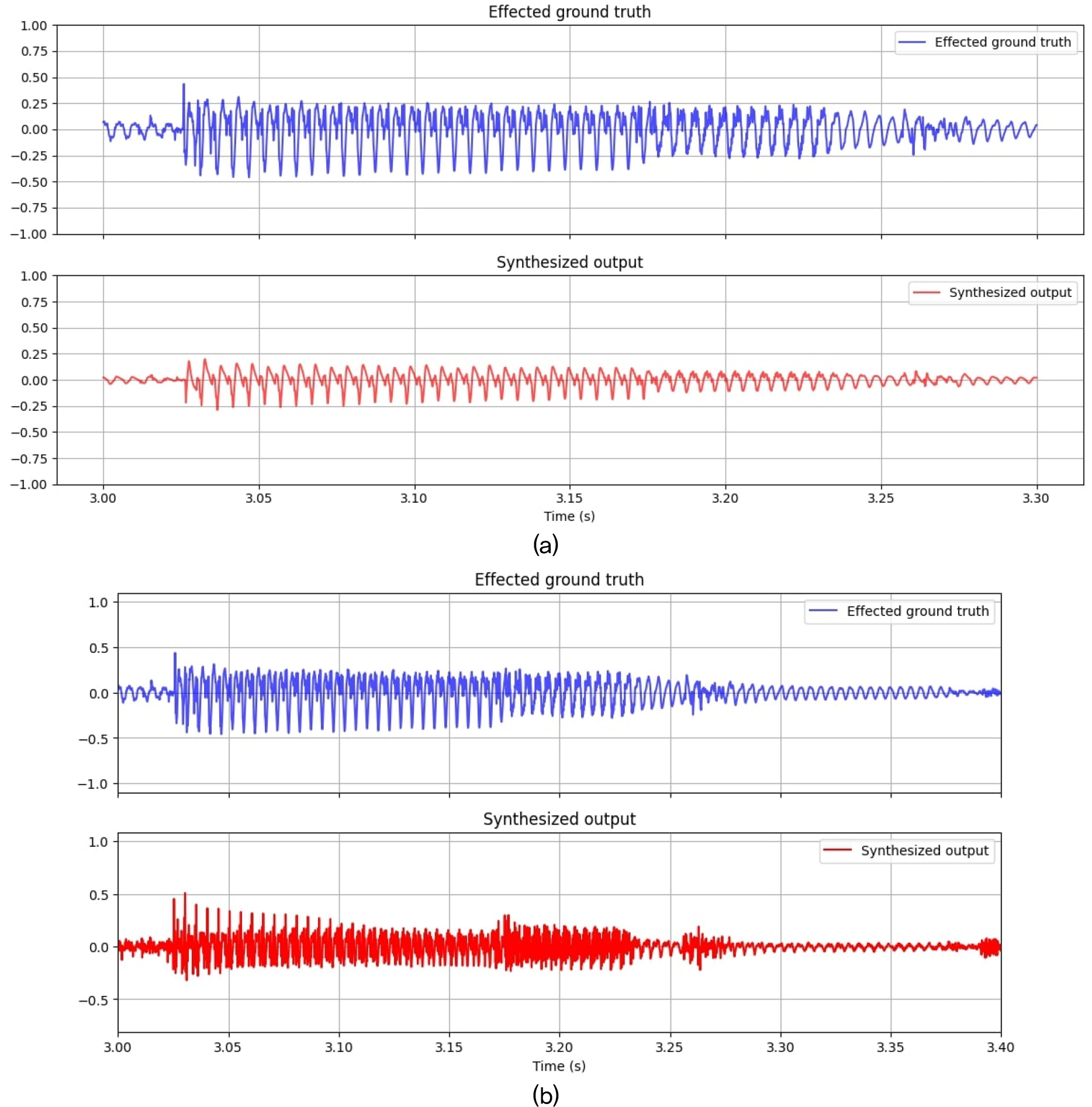
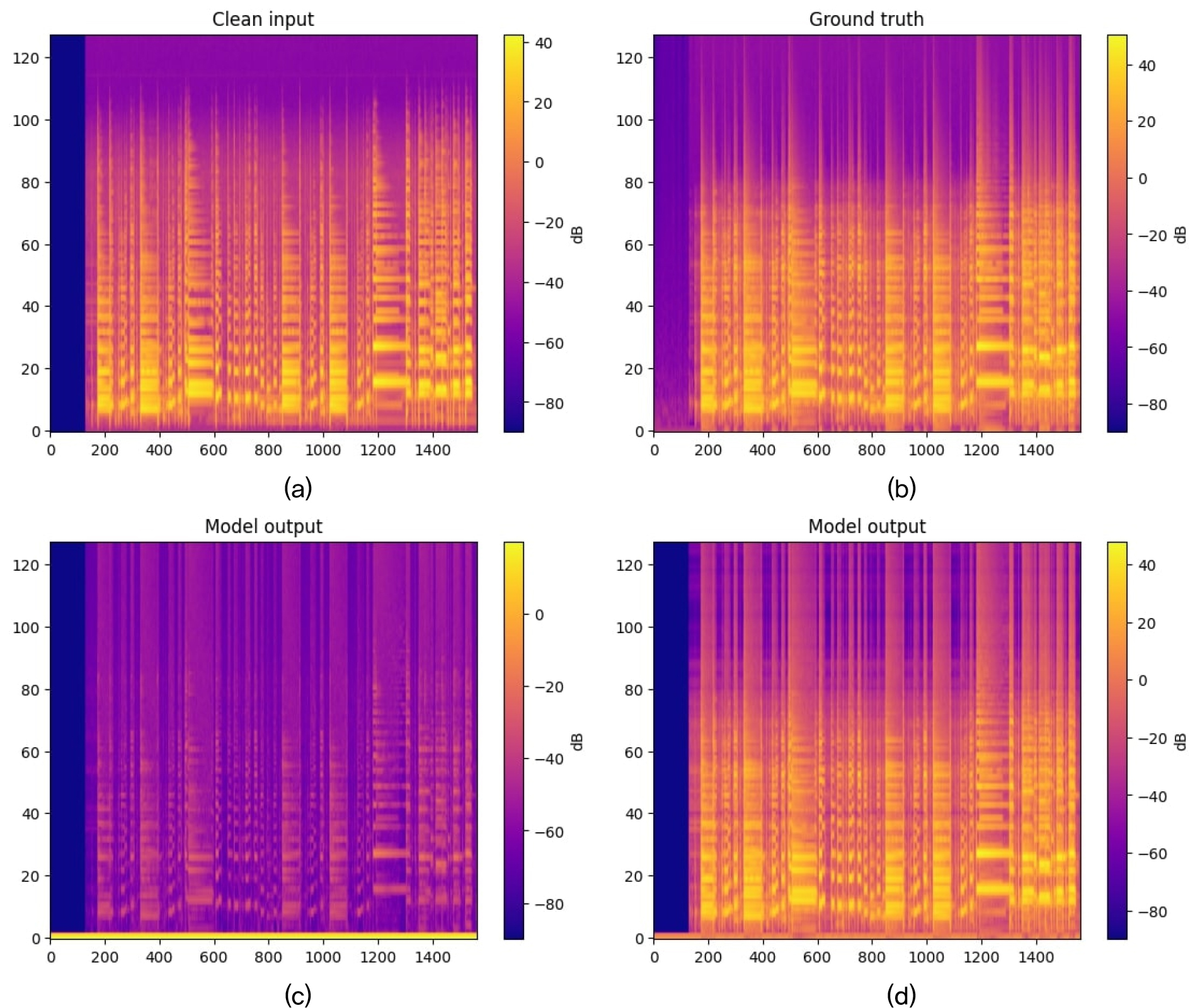
Fig. 4는 입력 오디오(clean input)와 타깃 오디오, 단일 밴드 TCN 출력, 16개의 sTCN의 출력을 멜 스펙트로그램(Mel spectrogram)으로 시각화한 것이다. 각 세로축은 주파수 축을 의미하며, 가로축은 시간 프레임이고, 밝기는 dB 스케일 에너지이다. Fig. 4(b)는 타깃 오디오로 Fig. 4(a)의 오디오 인풋에 오디오 이펙트가 적용된 음원의 스펙트로그램이다. Fig. 4(a)에 비해 중 저역(20구간 ~ 80구간) 에너지는 부스팅된 반면, 고역(100 ~ 120) 구간은 상대적으로 에너지가 줄어든 것을 확인할 수 있다. Fig. 4(c)는 단일 밴드 TCN의 출력이다. 대체적으로 타깃 오디오에 근접한 대역 에너지 분포를 띄며, 원본과 유사한 하모닉 구조를 재현함을 확인 가능하다. 하지만 전반적인 구간에서 에너지 분포가 과소 추정된 모습을 확인할 수 있다. Fig. 4(d)는 서브밴드가 16개일 때 출력이다. Fig. 4(b)와 유사한 대역 분포를 가지며, 시간 흐름에 따른 진폭 변동 또한 전반적으로 유사한 패턴을 가지는 것을 볼 수 있다. 따라서, 타깃 오디오가 보여주는 저-중역 부스트와 고역 억제의 모델링을 유사하게 재현했으며, 제안 모델인 sTCN은 비선형 오디오 이펙트의 모델링을 성공적으로 진행했음을 시사한다. 다만, 부분적으로 Fig. 4(b)에 비해 과한 배음(400 ~ 600)이 관찰되는데 이를 해결하기 위해 더 다양한 학습 데이터의 추가, 개선된 구성의 서브밴드를 고려할 수 있다.
V. 결 론
본 논문에서 기타 앰프 및 디스토션 페달과 같은 비선형 오디오 이펙트를 모델링하기 위해 다중 서브밴드 분할과 TCN을 결합한 모델을 제안했다. 실험 결과, 서브밴드 개수(2, 4, 8, 16, 32)를 증가시키며 단일 밴드 TCN과 비교했을 때, 서브밴드가 16개일 때 시간 영역 및 주파수 영역 지표에서 가장 일관된 성능을 보였으며, 특히 성능 지표에서 평균 RMSE가 약 60 %, 평균 MAE와 STFT error가 약 45 % 개선됨을 확인했다. 또한, 서브밴드가 32개일 때 전체적인 지표가 감소함을 확인할 수 있었다. 이는 다중 서브밴드 접근이 오디오 이펙트 모델링에서 효과적이나, 서브밴드의 수가 지나치게 많으면 오히려 과적합, 위상 불일치를 일으켜 학습 안정성을 저해할 수 있음을 시사한다. 향후 sTCN의 성능 개선 및 비선형 오디오 이펙트의 실시간 구현을 위한 연구를 수행할 계획이다.
