

I. 서 론
II. 제안하는 방법
2.1 Bag of words 기반 히스토그램 특징[6]
2.2 재발량 분석을 이용한 시간 변화 특징
2.2.1 재발 도표(Recurrence Plot:RP)
2.2.2 재발량 분석
2.3 서포트 벡터 머신
III. 실 험
3.1 실험 database
3.2 실험 설정
3.2.1 기존 방법 1: MFCC-GMM
3.2.2 기존 방법 2: BOW 기반 음향 상황 인지
3.2.3 제안하는 방법
3.3 실험 결과 및 분석
3.3.1 기존 방법 1: MFCC-GMM
3.3.2 기존 방법 2: BOW 기반 음향 상황 인지
3.3.3 제안하는 방법
IV. 결 론
I. 서 론
음향은 장소와 사람의 유무 및 행동 등 다양한 정보를 포함하며, 그 중 장소를 판단할 수 있는 음향 상황 인지(acoustic scene classification)는 다양한 분야에서 사용된다. 스마트폰,[1] 로봇 내비게이션,[2] 시계, 안경과 같이 착용할 수 있는 장치(wearable device)[3]와 같이 이동 가능한 장치에서 현재 장소 판단 및 상황 대처를 위해 상황 인지 기술이 적용되고, 음성 인식 또는 음향 이벤트 인식/검출 성능 향상을 위해 현재 장소를 판단하는데 사용된다.[4] 현재까지 음향 상황 인지를 위한 많은 연구들이 진행됐고, 최근, 도전과제로 Detection and Classification of Acoustic Scenes and Events(DCASE)가 개최됐다. Reference [5]에서는 DCASE에 투고된 11가지 방법들의 특징 추출, 인식기, 인식 전략 등으로 설명 하고 있다.
이러한 음향 상황 인지는 동일한 장소에서 매우 다양한 음향이 발생하고, 서로 다른 장소에서도 유사한 음향이 발생하기 때문에 인식이 어렵다. 이때, 코드북을 이용하여 발생한 음향들의 분포를 히스토그램으로 나타내는 BOW 기반 특징 추출 방법을 사용하면 문제를 극복할 수 있다. 지난 연구에서 BOW 기반 음향 상황 인지는 코드북의 표현력에 따라 성능이 다르며, 코드북의 표현력을 향상하기 위한 특징을 제안했다.[6]
한편, 서로 다른 장소에서 동일한 음향이 발생하더라도 시간에 따른 변화에는 차이가 있을 수 있다. 특히 특정 음향의 주기성과 지속성은 음향 상황을 판단하는데 중요한 정보가 된다. 기존 특징들은 대부분 프레임 기반 특징으로 시간 변화에 대한 특징을 반영할 수 없었다. 몇몇 특징은 1차, 2차 미분 성분으로 시간 변화에 대한 정보를 반영했지만[1,4] 이러한 특징은 인근 프레임들만 고려된 부분적인 시간 정보로서 주기성과 지속성 같은 전반적인 시간 정보는 표현할 수 없다. BOW 기반 히스토그램 특징도 일정 시간동안 발생한 음향 특징의 분포만 반영할 뿐, 특징이 발생한 순차적인 정보는 무시해 버리기 때문에 동일한 문제점을 갖는다.
본 논문에서는 이러한 단점을 보완하기 위해 재발량 분석(Recurrence Quantification Analysis: RQA) 특징을 사용했다.[7] 재발량분석 특징은 일정 시간동안 발생한 음향 의 주기성과 지속성을 수치화하여 표현한다. 제안하는 방법에서는 재발량 분석 특징과 BOW 기반 히스토그램 특징을 이용함으로써 실험을 통해 기존 방법들 보다 향상된 성능을 확인했다. 본 논문은 II장 제안하는 방법, III장 기존 방법들과 제안하는 방법을 이용한 실험 내용, IV장 결론으로 구성된다.
II. 제안하는 방법
본 논문에서는 음향 상황 인지를 위해 BOW 기반 히스토그램 특징과 재발량 분석을 이용한 시간 특징을 사용했다. Fig. 1은 제안하는 음향 상황 인지 알고리즘의 구조도이다.
2.1 Bag of words 기반 히스토그램 특징[6]
BOW 기반 히스토그램 특징은 일정 시간동안 발생한 음향 특징의 분포를 이용하여 특징 벡터를 구성한다. 입력 데이터는 프레임 단위로 분할된 뒤, 매 프레임에서 Mel Frequency Cepstral Coefficients (MFCCs) 특징이 추출된다. 추출된 특징은 사전에 훈련된 코드북의 요소들과 유사도를 측정하여 최종적으로 히스토그램 특징으로 변환된다.
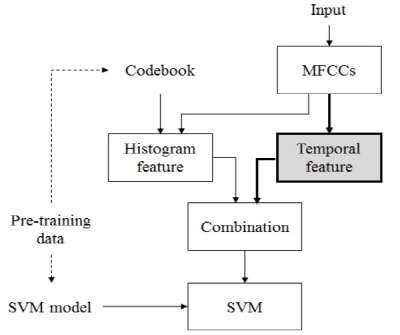 |
Fig. 1. Proposed structure for acoustic scene classifica-tion. |
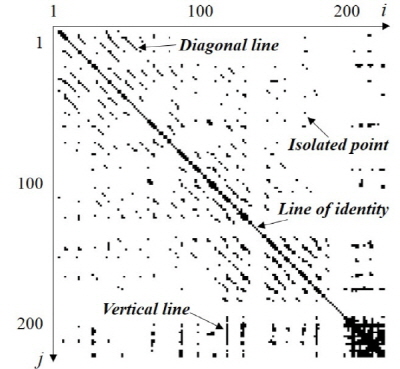 |
Fig. 2. Recurrence pattern in recurrence plot. |
2.2 재발량 분석을 이용한 시간 변화 특징
Fig. 2는 택시안 상황에서 생성된 재발 도표와 재발 패턴을 보여준다. 재발 도표에 나타나는 재발 패턴을 수치화하여 시간 변화에 대한 특징을 추출했다.
2.2.1 재발 도표(Recurrence Plot:RP)
MFCC 특징은 1차, 2차 미분 성분을 이용하여 시간 변화에 대한 정보를 추출할 수 있다. 하지만 위 요소들은 인근 프레임 사이 발생하는 변화만 반영하기 때문에 주기성, 지속성을 표현할 수 없다. 위 단점을 보완하기 위해, 매 프레임에서 추출된 MFCC 특징 사이의 연관성을 나타내는 재발 도표를 생성했다.
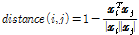 . (1)
. (1)
Eq.(1)은 두 벡터 사이의 코사인 유사도(cosine similarity)를 의미하며, 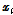 는 i번째 프레임에 대한 MFCC 특징을 의미한다. 입력 데이터에 대해 총 N개의 프레임이 추출된 경우, Eq.(1)의 결과 N차 정사각행렬이 생성되며, (i,j) 번째 요소는 i번째 MFCC와 j번째 MFCC의 유사도를 의미한다. 다음 Eq.(2)를 이용하여 유사도가 높은 요소들을 선별한다.
는 i번째 프레임에 대한 MFCC 특징을 의미한다. 입력 데이터에 대해 총 N개의 프레임이 추출된 경우, Eq.(1)의 결과 N차 정사각행렬이 생성되며, (i,j) 번째 요소는 i번째 MFCC와 j번째 MFCC의 유사도를 의미한다. 다음 Eq.(2)를 이용하여 유사도가 높은 요소들을 선별한다.
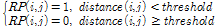 . (2)
. (2)
Eq.(2)에서 문턱값(threshold)은 재발 빈도를 결정하는 값으로 결과에 중요한 영향을 준다. Reference [7]에서는 재발량 분석을 적용하기 위한 매개 변수를 선정하는 문제에 대해 논의하고 있으며, 위 내용을 참고하여 본 논문에서는 재발량 분석을 위해 재발 빈도를 10 %로 설정하여 문턱값을 결정했다.
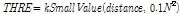
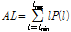
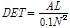
 )
) = max[DiagonalLines(RP)]
= max[DiagonalLines(RP)]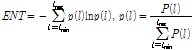
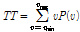
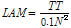
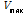 )
)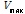 = max [VerticalLines (RP)]
= max [VerticalLines (RP)]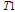 = mean [Diff_Time (RP)]
= mean [Diff_Time (RP)]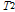 = mean [Acce_Time (RP)]
= mean [Acce_Time (RP)]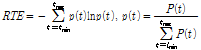
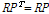 .
.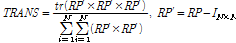
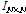 : N by N identity matrix, i, j: matrix row, column index respectively
: N by N identity matrix, i, j: matrix row, column index respectively /
/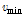 : the minimum length of diagonal/vertical line
: the minimum length of diagonal/vertical line2.2.2 재발량 분석
재발 도표에서 재발 패턴을 이용하여 입력 데이터의 주기성과 지속성을 확인할 수 있다. Fig. 2의 예시에서, 재발 도표의 상,하삼각행렬에 나타나는 대각선은 동일한 음향이 반복되는 주기성을 나타낸다. 반복되는 패턴이 길수록 대각선의 길이가 길어지며, 주기가 길수록 중심 대각선에서 멀어진다. 재발 도표 의 수직선은 지속성을 나타내며, 오랜시간 지속될수록 수직선의 길이가 길어진다. 2차원 평면에서 표현된 대각선과 수직선 특징을 수치화 하기 위해 재발량 분석을 수행한다. 본 논문에서는 재발점(recurrence point)이 연속적으로 2개 이상 발생한 경우를 선으로 정의하여 재발량 분석을 수행했다. 그 결과 총 12가지 특징이 추출되며, Table 1은 본 논문에서 사용된 특징들을 설명한다.
2.3 서포트 벡터 머신
각 단계에서 추출된 히스토그램 특징과 시간 변화 특징을 연결하여 인식 단계로 넘어간다. 코드북 기반 히스토그램 특징은 0인 요소들을 포함하고 있기 때문에 서포트 벡터 머신이 인식에 효율적이다. 서포트 벡터 머신 기반 인식 실험은 libSVM을 이용하여 수행하였다.[9] 실험에서는 다양한 커널함수를 이용하여 성능을 측정했다.
III. 실 험
3.1 실험 database
실험 database는 녹음기를 이용하여 일상에서 자주 접하는 교통수단과 실내, 실외에 대해 총 11가지 장소에서 수집했다. 먼저, 교통수단으로 버스(Bus), 택시(Car), 지하철(Metro), 지하철 환승 통로(Gate)가 고려되었고, 카페(Cafe), 잡화점(Department Store), 가정집(Home), 마트(Mart)가 실내 상황으로, 마을 버스가 다니는 골목길(Alley), 버스 중앙차로가 설치된 대도로변(Street), 차량 통행이 없는 길거리(Way)가 실외 상황으로 고려되었다. 수집된 데이터는 16 kHz, 단일 채널, 16 bit resolution으로 변환하고, 4 s 단위로 분할하여 실험했다. Table 2는 본 논문에서 정의한 음향 상황과 각 상황에서 수집된 database 분량을 보여준다.
3.2 실험 설정
본 논문에서는 성능 평가를 위해 5-fold cross validation 실험을 진행했으며, 훈련 데이터와 테스트 데이터 비율은 1:4로 설정했다. 다섯 번 반복 실험을 통해 평균 인식률과 표준 편차를 산출했으며, 기존 방법과 제안하는 방법의 성능을 비교했다.
3.2.1 기존 방법 1: MFCC-GMM
MFCC 특징 벡터의 분포를 GMM으로 훈련하여 Maximum Likelihood(ML) 기준에 근거한 인식 구조는 이미 널리 알려진 방법으로, DCASE에서도 기존 방법으로 사용되고 있다.[5] 본 논문에서 첫 번째 기존 방법으로 프레임 길이는 64 ms로 설정하고, 50 % 중첩하여 총 22차원의 MFCC와 1차 미분을 추출했다. 인식 실험은 GMM의 mixture 수에 따라 진행했다.
3.2.2 기존 방법 2: BOW 기반 음향 상황 인지
Reference [8]에서는 비정상 상황을 인지하기 위해 BOW 기반 특징이 사용되었고, Reference [6]에서는 버스와 지하철 상황을 구분하기 위해 표현력이 향상된 특징을 적용하여 BOW 기반 특징을 사용했다. 위 두 연구 결과를 바탕으로 Table 2의 11가지 상황에 대한 인식 성능을 평가했다. 실험은 코드북 크기와 SVM 커널 함수에 따라 수행했다.
3.2.3 제안하는 방법
제안하는 방법에서는 MFCC 특징에 시간 흐름에 대한 정보를 반영하기 위해 Table 1에 정리된 재발량 분석 특징을 추가했다. MFCC 특징은 기존 방법 1 실험과 동일하게 추출했으며, 4 s 길이의 데이터에서 추출된 MFCC를 바탕으로 히스토그램 특징을 추출하고 재발량 분석을 수행했다. 인식 단계에서는 기존 방법 2 실험과 동일한 조건에서 실험했다.
3.3 실험 결과 및 분석
3.3.1 기존 방법 1: MFCC-GMM
첫 번째 기존 방법에 대한 인식 실험 결과를 Table 3에 정리했다. Mixture 수가 많을수록 인식률이 높아지는 것을 확인할 수 있다. 64 mixture 모델을 사용한 경우, 11개 음향 상황에 대해 평균 89.90 %의 인식률을 보인다. MFCC는 프레임 기반 특징으로 주파수에 따른 에너지 분포를 이용하여 추출된다. 1차 미분 성분을 이용하여 부분적인 시간 변화를 반영할 수 있지만, 상황 인지에 필요한 주기성과 지속성은 반영할 수 없다. 또한 훈련 데이터에 포함되지 않은 상황을 표현하는데 한계가 있기 때문에 훈련 데이터가 상대적으로 적은 상황에서는 인식률을 보장할 수 없다.
Table 3. MFCC-GMM experiment results. | |||||||
# of mix. | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
Recog. Rate (%) | 74.66 | 81.18 | 83.70 | 85.57 | 87.49 | 88.82 | 89.90 |
Std. | 0.22 | 0.27 | 0.25 | 0.31 | 0.18 | 0.26 | 0.23 |
3.3.2 기존 방법 2: BOW 기반 음향 상황 인지
두 번째 기존 방법에 대한 인식 실험 결과를 Table 4에 정리했다. Table 4에 정리된 숫자는 5-fold corss validation의 평균 인식률을 의미하며 괄호 안에 있는 값은 표준편차를 의미한다. Reference [8]에 소개된 방법을 이용한 경우, 코드북 크기가 440이고 2차 커널함수를 사용했을 때, 81.32 %로 가장 높은 인식률을 보이고 있다. 주파수 특징을 이용하여 코드북을 구성한 경우, 음향 상황을 표현하는데 한계가 있다. Reference [6]에서는 코드북의 표현력을 향상하기 위해 캡스트럴 특징과 주파수 특징을 사용했다. 그 결과, 같은 조건에서 84.69 %로 약 3 % 향상된 결과를 확인할 수 있고, 같은 커널 함수에서 코드북의 크기가 550일 때, 85.12 %로 가장 높은 인식률을 확인할 수 있었다. 하지만 이 결과는 기존 방법 1 결과와 비교하여 약 4 % 하락한 성능을 보이고 있다. 실험 결과에서는 자동차 엔진 소리가 주로 발생하는 버스와 택시 상황, 노래 소리가 빈번히 발생하는 길거리와 잡화점 상황, 조용한 배경에 간헐적인 음향이 발생하는 가정과 카페 상황에서 오인식이 많았다. BOW 기반 히스토그램 특징은 일정 시간 동안 발생한 특징들의 분포를 사용하기 때문에 유사한 음향 분포가 발생하는 상황에서는 한계가 있다.
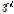 polynomial
polynomial3.3.3 제안하는 방법
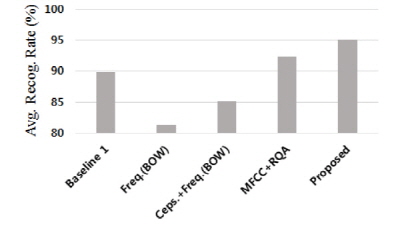
특징 벡터의 시간에 따른 변화도를 추출하기 위해 재발량 분석을 이용하여 특징을 추가했다. 먼저, 기존 MFCC 특징과 그들의 재발량 분석 결과를 이용한 실험에서 2차 커널함수를 사용한 경우 92.28 %로 첫 번째 기존 방법 보다 약 2.3 % 향상된 것을 확인할 수 있었다. BOW 기반 음향 상황 인지에 재발량 분석을 통해 추출한 특징을 적용한 경우 코드북 크기가 550이고 선형 커널함수에서 95.02 %로 가장 높은 인식률을 확인할 수 있었다. 제안하는 방법에서는 BOW 기반 음향 상황 인지를 이용하여 훈련에 반영되지 않은 상황에 강인하게 대처할 수 있고, RQA 특징을 이용하여 시간 변화에 따른 특징을 반영함으로써 효과적인 음향 상황인지를 수행할 수 있었다. Fig. 3은 각 실험에서 최상의 성능을 보여준다. 재발량 분석을 통해 전반적인 시간 정보를 반영한 경우, 기존 방법들 보다 높은 성능을 보이며, 제안하는 방법에서 가장 높은 성능을 확인할 수 있다.
IV. 결 론
음향 특징의 주기성과 지속성은 음향 상황 인지를 위한 중요한 특징이 될 수 있다. 기존 연구에서 많이 사용되는 MFCC 특징은 1차 미분 성분을 이용하여 시간에 따른 RQA 특징을 반영하지만, 이는 부분적인 시간 변화만 반영할 뿐, 전반적으로 발생되는 주기성과 지속성을 반영할 수 없다. 본 논문에서는 시간에 따른 음향 특징을 반영하기 위해 재발량 분석을 사용했다. 인식 실험 결과 BOW 기반 음향 상황 인지에 재발량 분석을 통해 추출한 특징을 적용한 결과 11개 음향 상황을 인식하는데 평균 95.02 %의 인식률을 확인했다.
