

I. 서 론
II. 심층 신경망 기반 음성 향상 성능 평가를 위한 비교군
2.1 실수 네트워크와 복소 네트워크
2.2 스펙트럼 사상과 T-F 마스킹
III. 베이스라인 네트워크 및 실험 구성
3.1 베이스라인 네트워크
3.2 실험 데이터 구성
IV. 실험 결과 및 평가
V. 결 론
I. 서 론
음성 향상은 잡음이 있는 음성 신호의 명료도와 품질을 향상시키는 기법으로 음성 통신, 보청기, 자동음성인식과 같이 소음 억제와 음성 특징 유지가 필수적인 분야에서 다양한 활용이 가능하다. 최근에는 심층 신경망(Deep Neural Network, DNN) 기반의 음성 향상 기법이 활발하게 연구되고 있으며, 기존의 확률 기반 기법과 비교하여 우수한 성능을 보이고 있다.[1,2,3]
심층 신경망 기반 음성 향상은 음성의 특징을 보다 효과적으로 학습하기 위하여 주로 시간 영역의 신호를 Short- Time Fourier Transform(STFT) 영역으로 변환하여 사용한다.[2,3] 이러한 주파수 영역 심층 신경망 기반 음성 향상을 설계하기 위한 학습 기법은 학습 대상과 네트워크 구조에 따라 크게 두 가지로 나눌 수 있다.
먼저, 심층 신경망 학습 대상에 따라 학습 기법은 스펙트럼 사상과 Time- Frequency(T-F) 마스킹 기법으로 나뉘는데, 스펙트럼 사상 기법은 잡음이 있는 음성으로부터 대상(깨끗한) 음성을 직접 추정하는 반면 T-F 마스킹 기법은 음성 고유의 특성을 유지하고 추정된 마스크를 잡음이 있는 음성에 곱하여 잡음을 억제한다. 이때, 스펙트럼 사상과 T-F 마스킹은 각각 음질과 명료도 개선에 좋은 성능을 보이는 것으로 알려져 있기 때문에 목적에 따라 적절한 학습 기법을 선정하는 것이 중요하다.[4]
두 번째로, 심층 신경망 네트워크 구조를 실수 네트워크로 할 것인지 복소 네트워크로 할 것인지에 따라 학습 기법을 나눌 수 있다. 초기의 주파수 영역 심층 신경망 기반 음성 향상 기법은 위상 정보 추정의 어려움으로 인해 크기 추정에 중점을 두었다.[1,2] 그리고 이렇게 추정한 크기 정보에 잡음이 포함된 입력 음성의 위상 정보를 결합하는 방법으로 최종 결과를 생성하였다. 그러나 이 경우, 특히 낮은 신호대잡음비(Signal-to-Noise Ratio, SNR) 상황에서 왜곡이 발생할 수 있다.[3,5] 이러한 왜곡의 발생을 막기 위해 위상 정보를 함께 추정할 수 있는 복소 스펙트럼 사상법[6]이나 다양한 복소 마스크를 추정하여 이용하는 방법이 사용되고 이를 위하여 기존의 실수 네트워크를 확장하여 복소수 스펙트럼이나 복소수 마스크의 실수부와 허수부를 모두 추정하는 복소 네트워크가[3,7] 제안되었다.
본 논문에서는 실수 네트워크와 복소 네트워크를 사용하여 스펙트럼 사상 기법과 T-F 마스킹 기법의 성능을 다양한 규모의 데이터 셋에서 비교 평가하고, 이를 통해 심층 신경망 기반 음성 향상에 효과적인 네트워크 구조와 데이터 셋 규모를 모색해 보았다.
II. 심층 신경망 기반 음성 향상 성능 평가를 위한 비교군
2.1 실수 네트워크와 복소 네트워크
시간 영역에서 잡음이 섞인 음성 신호를 라고 할 때, 는 깨끗한 음성 신호 와 잡음 신호 의 합으로 표현 가능하다. 또한, 는 STFT을 통해 T-F 영역의 신호 로 변환할 수 있다. 이때, 는 다음과 같이 표현할 수 있다.
이때, 와 는 각 성분의 크기와 위상, 허수 단위를 의미하며, 편의를 위하여 시간-주파수 첨자 를 생략하였다.
초기 연구[1,2]에서는 신호 또는 T-F 마스크의 크기만을 추정하는 실수 네트워크를 사용하였다. 이때, 향상된 음성 을 합성할 때 잡음이 섞인 위상을 그대로 사용하였는데 이러한 접근법은 성능 향상에 한계를 가지고 있다[3,5]. 최근 다양한 연구에서 이러한 문제를 해결하기 위해 복소 네트워크를 제안하였으며[3,7] 실수 네트워크와 비교하여 우수한 성능을 보였다. 복소 네트워크는 신호를 실수 부분 과 허수 부분 를 모두 추정하므로, 이들을 이용하여 신호의 크기와 위상을 다음과 같이 얻을 수 있다.
본 논문은 실수 네트워크와 복소 네트워크를 다양한 환경에서 직접 비교하기 위하여, 최근 우수한 성능을 보인 복소 네트워크인 Deep Complex Convol- utional Recurrent Network(DCCRN)와 DCCRN의 실수 네트워크(CRN) 간의 성능을 두 종류의 데이터 셋을 세 가지 규모로 나누어 비교 평가하였다.
2.2 스펙트럼 사상과 T-F 마스킹
T-F 영역에서 심층 신경망을 이용하여 음성 향상을 할 때는 주로 스펙트럼 사상과 T-F 마스킹 기법을 사용하여 최종 신호를 얻는다.[4] 이때, 각각 실수 네트워크를 사용하는지 복소 네트워크를 사용하는지에 따라 얻을 수 있는 최종 신호가 달라지는데, 실수 네트워크에서 스펙트럼 사상 기법을 사용하여 주파수 영역의 의 크기 를 의 크기 로 직접 사상하면 향상된 음성의 크기 를 구할 수 있다. 그러나 이 경우 2.1절에서 언급했듯이 로 인한 왜곡이 발생한다.
Tan과 Wang[6] 등은 이러한 문제를 방지하기 위하여 과 로부터 과 을 직접 사상하는 복소 스펙트럼 사상을 제안하였다.
T-F 마스킹 기법은 음성을 직접 사상하는 스펙트럼 사상 기법과 달리 로부터 를 합성하기 위한 마스크 을 추정한다. 그리고 추정된 은 와 곱하여 을 만든다. 초기의 T-F 마스킹 기법은 스펙트럼 사상과 마찬가지로, 로부터 를 추정하여 를 구하고 와 결합하여 를 합성하였다.
그러나, 이 경우에도 로 인하여 원하지 않은 왜곡이 발생한다. 최근에는 이를 해결하기 위하여 복소 마스크나 복소 마스크를 효과적으로 계산할 수 있는 복소 네트워크가 제안되었는데, 대표적인 복소 마스크는 complex Ideal Ratio Mask(cIRM)[7]로 수식은 다음과 같다.
이를 통해 는 다음과 같이 구할 수 있다.
이때, *는 복소 곱을 의미하며, 과 는 각각 Eq. (4)을 통해 얻어진 마스크의 실수 부분과 허수 부분이다. 복소 네트워크는 과 또는 과 을 효과적으로 계산할 수 있게 설계된 네트워크이다.[3,7]
스펙트럼 사상과 T-F 마스킹 기법 모두 네트워크를 통해 구해진 는 최종적으로 Inverse STFT(ISTFT)을 통하여 시간 영역의 음성 신호 로 표현된다.
본 논문에서는 실수 네트워크를 위해 실수 스펙트럼 사상을 사용하였고 복소 네트워크를 위해 복소 스펙트럼 사상과 cIRM을 사용하였다.
III. 베이스라인 네트워크 및 실험 구성
3.1 베이스라인 네트워크
실험에 사용한 베이스라인 네트워크는 Fig. 1과 같다. 먼저, 복소 네트워크로는 DCCRN[Fig. 1(a)]을 사용하였으며, 실수 네트워크로는 CRN[Fig. 1(b)]을 사용하였다.
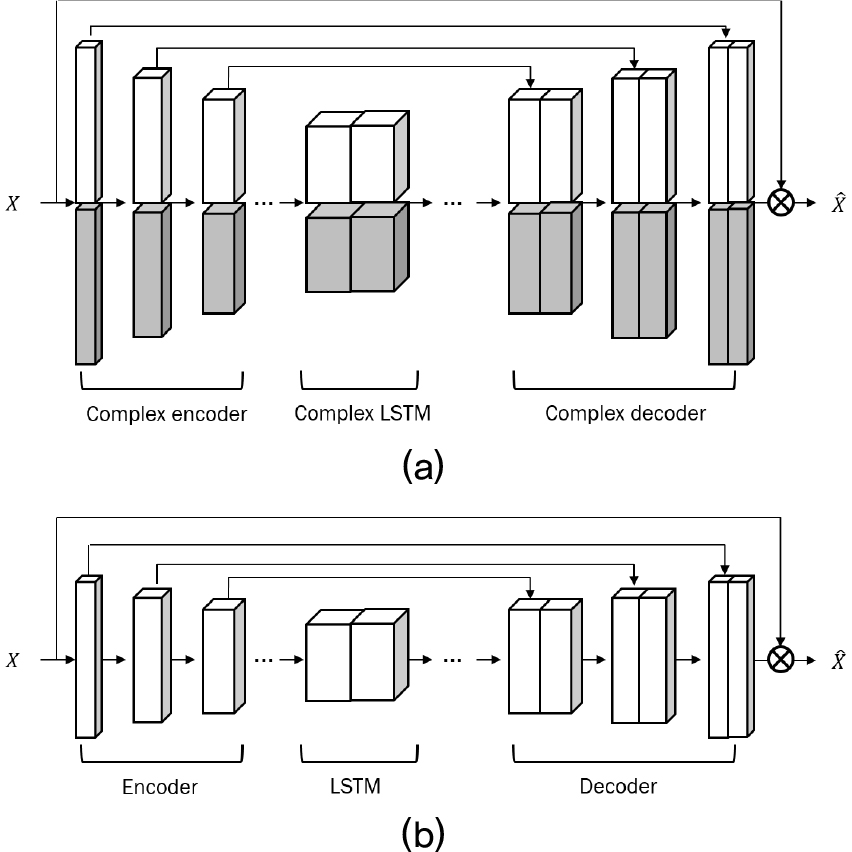
Fig. 1.
The architecture of baseline network. (a) is complex network,[7] and (b) is real network of (a).
DCCRN은 합성곱 계층으로 이루어진 인코더와 디코더 사이에 Long Short-Term Memory(LSTM) 계층을 갖는 네트워크이다. 이때, 각 계층은 입력의 실수 부분과 허수 부분을 위한 가중치를 별도로 갖으며[Fig. 2(a)], 합성곱 계층에서는 복소 모듈[3]을 통하여 두 가중치를 복소 연산한다. CRN은 DCCRN에서 복소 연산을 구성하던 허수부 가중치와 복소 합성곱 모듈을 제거하여 사용하였다. DCCRN의 자세한 구조는 Reference [7]을 따랐으며 CRN 구조는 Table 1과 같다. Table 1에서 입출력 크기는 각각 [채널 수, 주파수 빈 수, 프레임 개수]를 나타낸 것이며, 파라미터는 Conv2d와 ConvTrans2d의 경우(커널 높이, 커널 폭)과 커널의 개수를 나타낸 것이고 LSTM의 경우 유닛의 개수를 나타낸 것이다.
Table 1.
CRN architecture. Here F denotes the number of frequency bins, and T denotes the number of time frames.
윈도우 길이, 홉 길이, FFT는 각각 25 ms(T), 6.25 ms, 512 샘플(F)을 사용하였으며 DCCRN과 CRN의 총 파라미터 수는 각각 3.7 M,와 1.8 M이며 모델 최적화를 위해 Adam optimizer를 사용하였다. 손실함수로는 Mean Square Error(MSE)를 사용하였으며 학습률은 0.001로 정하였다.
3.2 실험 데이터 구성
실험에는 두 종류의 데이터 셋을 사용하였다. 먼저, 16 kHz로 샘플링된 TIMIT 음성 데이터 셋[10]을 사용하였으며, 잡음 데이터 셋은 NoiseX-92,[11] CHIME-2,[12] CHIME-3[13]를 혼합하여 사용하였다(dataset-1). 이때, 훈련 데이터 셋은 음성 데이터 셋 규모에 따라 세 가지로 나누었는데, TIMIT 음성 1,000개, 2,000개, 3,696개를 각각 랜덤으로 선택한 잡음 음성과 SNR 0 dB에서 20 dB까지 5 dB 간격으로 섞어 총 5,000개, 10,000개, 18,480개 세 가지 규모의 데이터 셋을 생성하였다. 테스트 데이터 셋은 훈련에 사용되지 않은 음성 462개를 훈련 데이터와 같은 방식으로 생성하였다.
또한, 데이터 셋에 따른 규칙성을 확인하기 위해 dataset-1보다 상대적으로 큰 규모인 DNS challenge 데이터 셋[9]의 일부를 사용하여 추가적인 실험을 진행하였다(dataset-2). dataset-2는 dataset-1과 동일한 방법으로 총 5,000개, 50,000개, 100,000개 세 가지 규모로 데이터 셋을 생성하였으며 462개의 테스트 데이터를 사용하였다. 이때, dataset-1과 dataset-2의 발화 길이는 동일하게 3초로 맞추어주었으며 dataset-1의 음성은 구어체와 문어체가 섞여있고 dataset-2는 책을 읽는 음성이다.
IV. 실험 결과 및 평가
모델 성능 평가는 각각 음질과 음성의 명료도 평가를 위해 가장 많이 사용되는 객관적 평가지표인 Perceptual Evaluation of Speech Quality(PESQ)[14]와 Short-Time Objective Intelligibility(STOI)[15]를 사용하였으며 실험 결과는 Tables 2, 3, 4, 5와 같다. 각 테스트 별로 DCCRN과 CRN의 성능을 비교하여 더 높은 PESQ와 STOI 값을 굵은 글씨로 나타내었다.
Table 2.
Performance evaluation of various network types using spectral mapping method on dataset-1.
Table 3.
Performance evaluation of various network types using spectral mapping method on dataset-2.
Table 4.
Performance evaluation of various network types using T-F masking method on dataset-1.
Table 5.
Performance evaluation of various network types using T-F masking method on dataset-2.
먼저, Tables 2와 3은 데이터 셋 규모에 따른 스펙트럼 사상의 각 SNR 별 성능을 DCCRN과 CRN에서 평가한 결과이다. dataset-1의 경우(Table 2) 모든 SNR에서 DCCRN이 CRN보다 높은 STOI 값을 보였으며 10,000개 데이터를 사용했을 때를 제외하고 SNR 10 dB 이상일 때 DCCRN이 CRN보다 높은 PESQ 값을 보였다. 반면, dataset-2는(Table 3) 규모에 따라 성능 양상이 다르게 나타났는데, 5,000개 데이터를 사용했을 때 SNR 5 dB 이하인 경우 DCCRN의 PESQ와 STOI 값이 CRN보다 더 높았으며 10 dB 이상인 경우 CRN이 더 높은 값을 보였다. 50,000개 데이터를 사용했을 때는 모든 SNR에서 PESQ 값은 DCCRN이 더 높았고 STOI 값은 CRN이 더 높았다. 그리고 100,000개 데이터를 사용했을 때는 SNR 10 dB를 제외하고 DCCRN의 PESQ와 STOI 값이 CRN보다 더 높았다.
Tables 4, 5는 데이터 셋 규모에 따른 T-F 마스킹의 각 SNR 별 성능을 DCCRN과 CRN에서 평가한 결과이다. dataset-1은(Table 4)의 경우 Table 2와 마찬가지로 모든 SNR에서 DCCRN이 CRN보다 높은 STOI 값을 가지며, 10,000개 데이터를 사용할 때 DCCRN이 모든 SNR에서 CRN보다 높은 PESQ 값을 갖는다. 반면, 5,000개 데이터를 사용할 때 SNR 10 dB 이하인 경우나 18,480개 데이터를 사용할 때 SNR 20 dB를 제외한 경우에는 CRN이 DCCRN보다 높은 PESQ 값을 갖는다. dataset-2의 경우(Table 5) Table 3과 유사한 경향성을 보이는데 10,000개 데이터를 사용했을 때 스펙트럼 사상의 경우 모든 SNR에서 DCCRN의 PESQ가 높았던 반면, T-F 마스킹의 경우 CRN이 높은 PESQ 값을 갖는다. 또한, dataset-2는 dataset-1과 비교하여 상대적으로 낮은 성능을 보였는데, 이는 dataset-2의 음성 대비 잡음 데이터비율이 상대적으로 더 높고 발화 길이를 맞춰주는 과정에서 묵음 구간이 많아져 모델 학습에 어려움을 겪었을 것으로 예상한다.
Tables 2, 3, 4, 5를 볼 때, PESQ 값이 STOI 값에 비해 더 분명한 차이를 보였기 때문에 각 실험 결과에 따른 평균 PESQ를 데이터 셋 별로 Figs. 3과 4에 정리하였다. 이때, Figs. 2와 3은 각각 0.05와 0.12 길이로 스케일링하였다.
Figs. 2와 3을 보면 DCCRN은 학습 기법에 따른 차이 없이 dataset-1과 dataset-2 모두 데이터 셋의 규모가 커질수록 PESQ 값이 향상되었다. 반면, CRN은 dataset-2에서는 DCCRN과 유사한 양상을 보였지만, dataset-1에서는 스펙트럼 사상을 사용한 경우 중간 규모의 데이터 셋이 가장 높은 PESQ 값을 보였고 T-F 마스킹을 사용한 경우 가장 낮은 PESQ 값을 보였다.
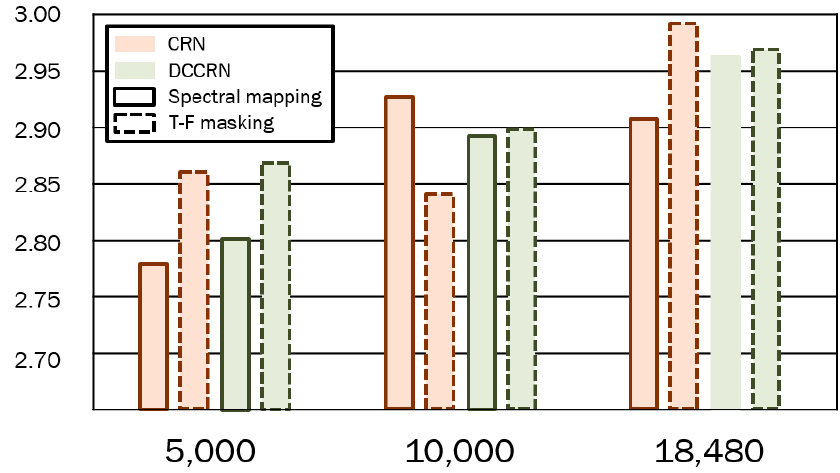
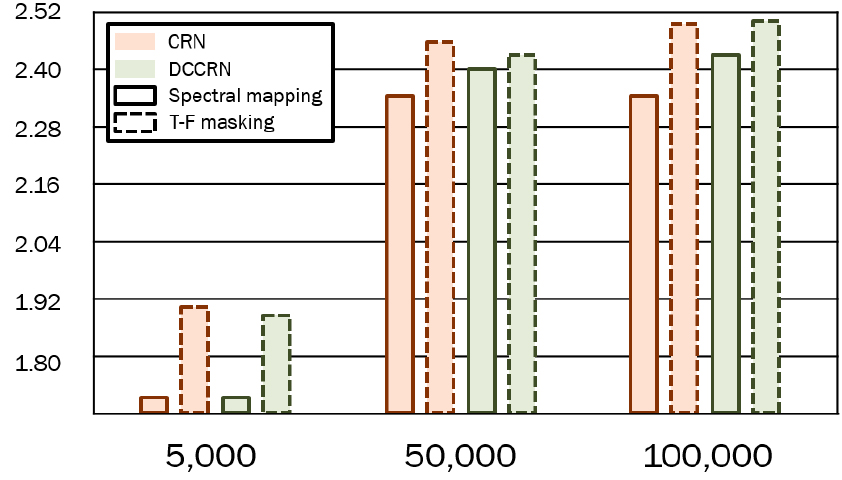
결과적으로 DCCRN과 CRN 사이에서 큰 성능 차이는 없었지만, dataset-1에서는 5,000개 데이터를 사용했을 때 T-F 마스킹을 사용하는 DCCRN의 성능이 가장 좋았으며, 10,000개와 18,480개 데이터를 사용했을 때 각각 스펙트럼 사상과 T-F 마스킹을 사용하는 CRN이 가장 좋은 성능을 보였다. dataset-2의 경우 5,000개와 50,000개 데이터를 사용했을 때 T-F 마스킹을 사용하는 CRN의 성능이 가장 좋았으며, 100,000개 데이터를 사용했을 때 T-F 마스킹을 사용하는 DCCRN의 가장 좋은 성능을 보였다.
한편, CRN은 DCCRN과 비교하여 사용하는 총 파라미터 수가 약 2배 가까이 적기 때문에 특정 상황에서는 CRN을 사용하는 것이 효율적일 수 있다.
V. 결 론
본 논문은 실수 네트워크와 복소 네트워크를 사용하여 스펙트럼 사상과 T-F 마스킹을 사용하였을 때 세 가지 규모의 데이터 셋 크기에 따른 성능 차이를 PESQ 와 STOI 관점에서 살펴보았다. 복소 네트워크의 경우 데이터 크기가 클수록 전체적인 성능이 개선되었지만, 실수 네트워크는 특히 높은 SNR 상황에서 중간 규모의 데이터 크기로 스펙트럼 사상을 사용하였을 때 더 좋은 성능을 보였다. 또한, 데이터 크기와 학습 기법에 따라 복소 네트워크 보다 실수 네트워크를 사용하는 것이 더 높은 성능을 보이기도 하였다. 따라서 총 파라미터의 수를 고려한다면 경우에 따라, 실수 네트워크를 사용하는 것이 보다 현실적인 해결책일 수 있다는 것을 확인하였다.
