

I. 서 론
II. 제안된 음악분류 시스템
2.1 프레임수준의 주의집중 기반 BGRU 인코더
2.2 세그먼트수준의 주의집중 기반 BGRU 인코더
2.3 회귀를 통한 EEG 특징의 자동생성
2.4 음악 신호로부터 음악적 특징 추출
III. 실험 및 결과
IV. 결 론
I. 서 론
시공간의 제약 없이 음악을 청취할 수 있는 모바일 디지털 환경이 조성됨에 따라 음악 검색 및 추천 시스템[1]에 대한 필요성이 급증하였다. 이에 따라 가수, 가사, 앨범명 등의 적절한 검색어, 사용자의 음악 선택 경향의 학습, 음악 곡들로부터 추출된 특징 패턴의 유사성 등을 반영하는 기술[2]이 개발되어 적용되고 있다 . 그러나 대부분의 음악 검색 및 추천 시스템은 사용자 중심의 시스템이 아닌 시스템 중심의 관점에서 개발되어 왔으며, 음악을 듣는 사용자의 감정이나 표현에 대한 연구는 여전히 부족하다.
감정 분석을 위한 선행 연구는 음성 인식과 표정 인식[3]을 사용하여 처음 도입되었다. 최근에는 생체센서를 통해 자율신경계에서 발생하는 근전도와 심전도, 뇌파와 같은 생체 신호를 인식[4]하여 감정을 분석하는 방법들이 주목받고 있는 추세이다.
최근 인공지능 분야에서 주목을 받는 딥러닝 기법을 활용하여 음악 청취 시 자연스럽게 발생하는 사용자의 생체신호를 음악 분류 및 추천 시스템에 적용한다면 다양한 상황에서 음악을 듣는 사용자의 만족도를 극대화할 수 있다. 그러나 사용자가 추천이 필요할 때마다 웨어러블 생체센서 및 기기를 통해 생체 신호를 측정하는 것은 번거롭고 불편하기 때문에 이를 대체할 수 있는 방법이 필요하다.
Chen et al.[5]은 Electroencephalogram(EEG) 신호의 시간축 신호에 계층적 주의집중 방식을 적용하여 EEG 신호를 감정별로 분류하는 방식을 소개했다. 이 방식을 개선하여 본 논문에서는 EEG 신호를 스펙트럼 신호로 변환하여 계층적 내적 주의집중 방식을 통해 추출한 EEG 특징과 음악신호로부터 추출한 음악특징과의 상관적 관계를 회귀 학습한다. 이러한 학습된 능력을 기반으로 실제 적용에서는 음악신호로부터 EEG 특징을 예측하여 음악을 자동으로 분류한다.
II. 제안된 음악분류 시스템
Fig. 1은 제안된 감정기반 음악 분류 시스템의 프로세스 흐름을 보여 주며, 뇌파 센서를 적용하는 경우와 적용하지 않는 두 가지 부분으로 구성된다. 사람은 소리를 들을 때 세부적인 부분보다는 특정한 부분을 주의 깊게 듣는 경향이 있다. 이러한 개념을 기반으로 제안된 시스템에서는 계층적 내부 주의집중 기반의 양방향 순환 게이트 유닛(Hierarchical Inner- Attention-Based Bidirectional Gated Recurrent Unit, HIA- BGRU) 을 적용한다.
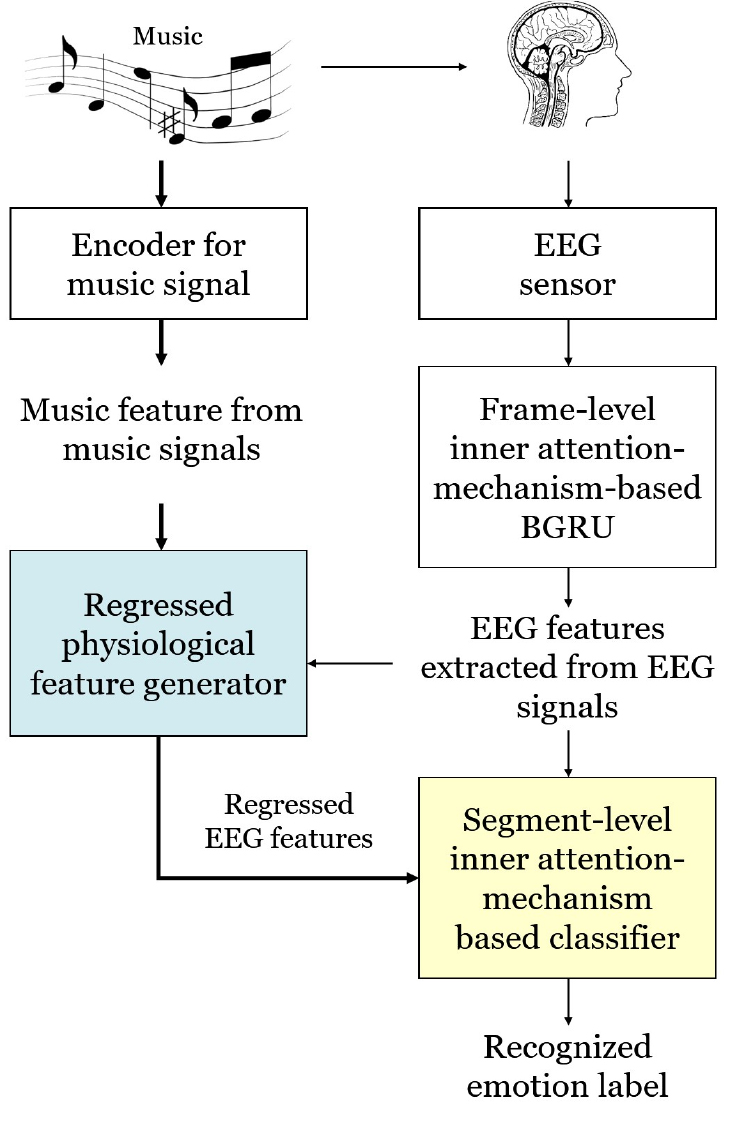
뇌파(EEG) 센서를 적용하는 경우는, 음악을 듣는 동안 사용자가 착용한 EEG 센서를 통해 획득된 신호를 주파수영역으로 변환한 후에 프레임수준의 내부-주의집중(Frame Inner-Attention, FIA) 기반 Bidirectional Gated Recurrent Unit(BGRU)(FIA-BGRU) 인코더를 통해 사용자의 감정 특징을 추출하고, 세그먼트수준의 내부-주의집중(Segment Inner-Attention, SIA) 기반 BGRU(SIA-BGRU)에 적용하여 음악을 감정별로 학습한다. 그리고 FIA- BGRU 인코더로 부터 추출된 EEG 특징과 음악 특징 간의 상관적 모델을 다층 퍼셉트론(Multi-Layer Perceptron, MLP)의 회귀학습을 통해 생성한다. 실제 적용에 있어서는, 학습된 모델 가중치는 MLP 회귀기와 SIA-BGRU에 각각 반영됨으로써, 입력되는 음악에서 추출된 음악특징이 MLP 기반 회귀기에 입력되어 EEG 센서가 필요 없이 음악특징에 상응하는 EEG 감정 특징이 자동으로 생성되고, 이를 훈련된 SIA-BGRU에 입력하여 자동화된 음악 분류를 수행한다.
2.1 프레임수준의 주의집중 기반 BGRU 인코더
제안된 FIA-BGRU 인코더의 구조는 Fig. 2와 같다. 전처리 과정에서 수집된 EEG 신호는 30 % 중첩되어 0.5 s 단위의 세그먼트로 분할 된 후에, 푸리에 변환에 의해 이차원 스펙트로그램으로 변환되고 FIA-BGRU 인코더로 입력된다. 인코더는 EEG 세그먼트에서 스펙트로그램의 주파수 성분 간의 상관관계를 학습하여 특징을 추출하는 역할을 한다. BGRU는 각 은닉층을 두 개의 층으로 분할하여 단방향 BGRU 신경망을 확장한다. Eqs. (1)과 (2)와 같이 하나의 계층은 순방향 GRU 로서 시간적 순서(xi1에서 xiJ 까지)로 시퀀스를 처리하고, 다른 계층은 역방향 GRU를 통해 반대 시간 순서로 시퀀스를 처리한다.
여기서 xij는 j 번째의 세그먼트(총 128개 세그먼트) 에서 i 번째의 주파수 성분(128차원) 을 나타낸다. 이를 통해 BGRU 인코더는 시계열 EEG 특징 벡터에서 과거 및 미래의 맥락에 대한 강력한 표현을 로 요약하여 추출한다.
다음 단계로, BGRU에 의해 출력된 특징에 프레임 레벨 내부 주의집중 메커니즘이 적용된다.
여기서 Ws와 Wm은 단일 층의 가중치 행렬, 그리고 uJ 은 J 샘플의 1로 구성된 벡터, Pmean는 각 세그먼트의 BGRU 은닉층에서 추출된 모든 출력 벡터의 평균 벡터이다. , , 는 각각 내부 주의집중 메커니즘에서 출력된 맥락 벡터, BGRU 은닉 층의 출력 벡터, 내부 주의집중 가중치를 각각 나타낸다.
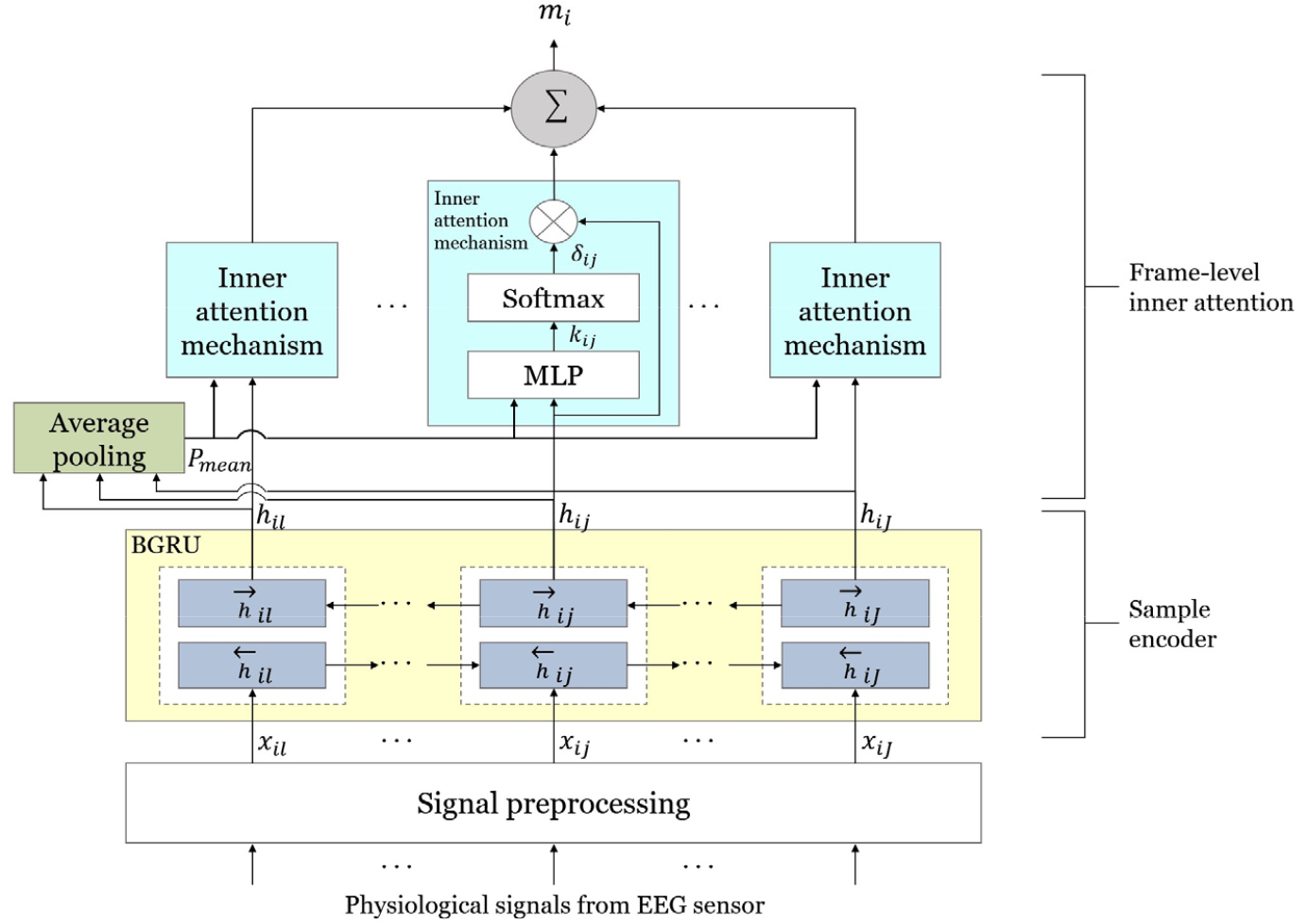
프레임수준의 내부 주의집중 메커니즘 에서는 은닉층의 출력벡터 hij 와 스펙트로그램 주석의 가중치 의 합을 적용하여 세그먼트의 맥락 벡터 표현 mi를 계산한다. 세그먼트 샘플 xij의 중요성을 나타내는 정규화 된 주의가중치 를 계산하기 위해서는 먼저 Eq. (6)과 같이 BGRU 은닉층의 출력 벡터 hi를 단일 층 MLP에 입력하여 kij 를 출력한 후에, Eq. (7)과 같이 softmax 함수를 통해 kij와 ks의 유사도를 정규화하여 를 계산한다. ks는 샘플 간의 맥락 벡터이며, 모델 학습 시 초기화하여 갱신되는 매개변수이다. 유사도가 높으면 내부 주의집중 가중치가 높아진다.
2.2 세그먼트수준의 주의집중 기반 BGRU 인코더
EEG 시퀀스의 감정을 예측하기 위해 FIA-BGRU 인코더에서 추출된 세그먼트 벡터 mi는 SIA-BGRU에 입력된다. SIA-BGRU는 BGRU 기반의 세그먼트 인코더, 세그먼트수준의 내부 주의집중, 심층 특징을 입력으로 하는 softmax 층으로 구성된다. Fig. 3은 제안된 SIA-BGRU 분류기의 구조도를 보여준다.
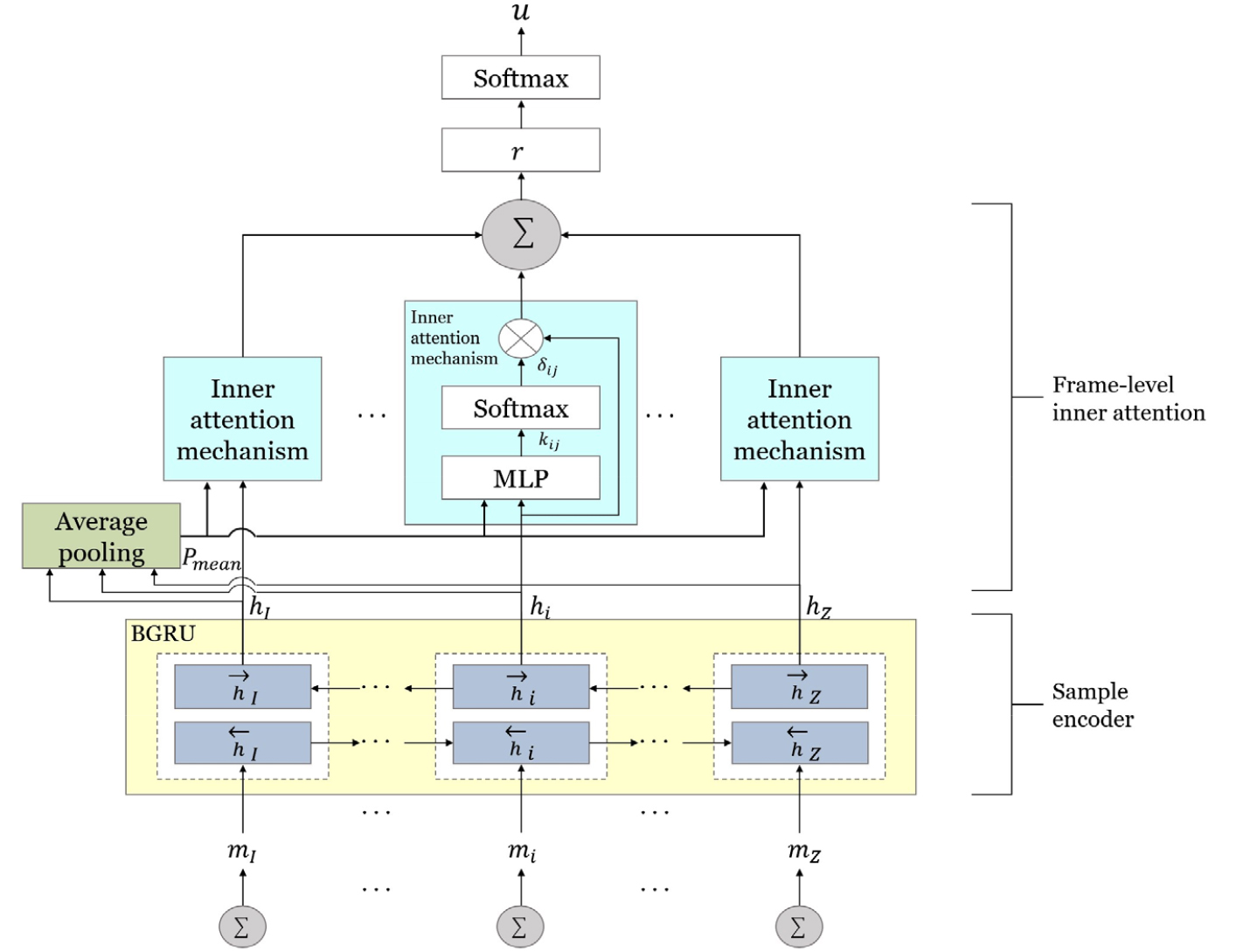
Eqs. (9)와 (10)과 같이, 세그먼트 벡터 mi는 BGRU 기반 세그먼트 인코더에 입력되어 순방향 및 역방향을 고려하여 주석 벡터 hi를 계산한다. 인코더 과정은 세그먼트 i 주변의 인접한 문맥 정보가 (5)와 유사한 방식으로 주석 벡터 hi 에 병합된다.
여기서 L은 각 시퀀스의 세그먼트 수이며 은닉 유닛의 수를 의미한다.
그 후, 내부 주의집중 메커니즘은 다시 128 차원의 세그먼트 간의 문맥 정보를 추출하는 데 사용된다.
여기서 L은 각 시퀀스의 세그먼트 수이며 은닉 유닛의 수를 의미한다.
세그먼트 시퀀스 벡터 r은 감정 분류에 중요한 역할을 하는 EEG 시퀀스의 전반적인 정보를 포함하는 높은 수준의 특징벡터로서 Eq. (13)에서와 같이 SIA 가중치 와 세그먼트 인코더의 각 세그먼트 주석 벡터 hi 의 가중치 합에 의해 계산된다.
최종적으로, 세그먼트 시퀀스 벡터 r은 다음과 같이 softmax 층에 적용되어 확률 분포 u를 예측한다.
여기서 Wc와 bc는 softmax 층의 매개변수이다.
학습 과정에서 세그먼트의 중요성을 계산하기 위해 적용된 매개변수들은 미세 조정된다. 따라서 주의집중 출력을 입력받아 가장 중요한 부분의 가중치가 학습에 반영되어 더욱 정확한 결과를 얻을 수 있다. 최적화 함수로 사용된 Adam optimizer는 모든 세그먼트에 대해 예측 레이블과 실제 레이블 사이의 cross-entropy 오류를 최소화한다. 이러한 과정을 반복하여 신경망이 가장 높은 정확도에 도달할 수 있게 된다.
2.3 회귀를 통한 EEG 특징의 자동생성
음악 청취 시 나타나는 감정 변화는 뇌가 활성화될 때 발생하는 뇌파를 통해서도 파악이 가능하다. 이러한 뇌파에는 사용자의 고유한 경험과 관련된 특징 정보가 포함된다. 역으로 이러한 현상을 적용하면 기계가 음악을 청취할 때 인간으로부터 생성되는 뇌파의 특징을 학습한 후에 음악에 해당하는 뇌파의 특징을 자동으로 생성할 수 있다. 이를 위해, 제안된 방식에서는 추출된 뇌파 특징과 음악 신호에서 추출한 음악적 특징사이의 상관관계를 학습하여 감정 분류에 적용한다. 즉, 입력 변수인 음악 신호의 특징에서 출력 변수인 뇌파 특징으로 매핑하는 회귀 방식[6]을 적용한다. 회귀 학습을 위해 1개의 은닉층으로 구성된 간단한 구조의 MLP를 최적화하여 사용하였다.
2.4 음악 신호로부터 음악적 특징 추출
음악적 특징 추출을 위한 인코더는 신호 분할, 푸리에 변환을 사용한 멜스펙트로그램 분석, 이미지 데이터를 통해 사전 학습된 VGG19 합성곱 신경망[7]으로 구성된다. 먼저 입력되는 음악 신호는 0.5초 단위의 세그먼트로 분할되고, 세그먼트 간의 30 % 중첩이 사용된다. 각 음악 세그먼트의 스펙트럼에 64개의 멜-필터뱅크를 적용하여 멜스펙트로그램으로 변환하고 전이 학습을 통해 사전 학습된 VGG19 합성곱 신경망에 입력하여 저차원의 청각적 특징을 추출한다. 적용된 VGG19 합성곱 신경망은 19개의 층(즉, 16개의 합성곱 층, 3개의 fully-connected층, 5개의 max-pooling 층, 1개의 softmax 층)으로 구성되어 있으며, 입력으로 원본 이미지 데이터를 필요로 하기 때문에 멜스펙트로그램 세그먼트로부터 정적 특징과 함께 첫 번째와 두 번째 동적 특징[8] 등의 3개의 채널을 입력으로 사용하여 512개의 저차원 음악적 특징을 추출한다.
III. 실험 및 결과
제안된 방법의 성능을 평가하기 위해 우리는 10명의 대학생을 선발하여 각 피험자가 음악을 듣는 동안 단일 채널 EEG 센서를 통해 128 Hz의 샘플링 주파수로 EEG 데이터를 수집하여 데이터세트를 구성하였다. 데이터 세트는 10개 장르에서 80 곡의 노래를 선택하였으며 그 중 20곡은 High Arousal과 High Valence(HAHV), 18곡은 High Arousal과 Low Valence (HALV), 22곡은 Low Arousal과 High Valence(LAHV), 20곡은 Low Arousal과 Low Valence(LALV) 등의 4개의 감정 클래스로 선정하였다. 각 노래의 길이는 3분 미만이며, 모든 노래는 44.1 kHz 및 128 kbps의 스테레오 표준 MP3 오디오 파일로 인코딩되어 저장되었다. 제안된 방법의 성능 측정을 위해 진행한 실험은 K- Fold 교차 검증방식(k = 4)을 통해 수행되었다.
첫 번째 실험은 피험자의 음악 청취 시에 착용한 웨어러블 EEG 센서로부터 발생하는 신호만을 사용하여 감정 클래스를 분류하였다. EEG 센서를 적용한 실험결과를 나타내는 Table 1에서는 제안된 방식인 ESP(EEG 신호의 스펙트럼) + HIA-BGRU가 가장 우수한 결과를 보여준다. ESP + convolutional BGRU (CBGRU)의 분류 정확도는 제안된 방식보다 조금 낮았지만 다른 3가지 방식보다 우수한 성능을 제시하였다. 실험 결과를 통해 내부 주의집중 메커니즘을 사용하는 방식이 사용하지 않는 방식보다 더 우수한 성능을 보임을 알 수 있다.
Table 1.
Emotion classification results based on EEG signals (%).
| Features + Methods | Recognition accuracy |
| M-HEPS | |
| RAW-BF + RF | 70.35 |
| ESP + CNN | 76.27 |
| ESP + BGRU | 80.36 |
| ESP + CBGRU | 85.46 |
| ESP + HIA-BGRU | 91.23 |
두 번째 실험에서는 음악신호만을 심층신경망에 직접 적용하는 경우, 음악 특징과 EEG 특징을 함께 심층신경망에 적용하는 경우, 그리고 입력된 음악신호로부터 추출된 청각적 특징에 적합한 EEG 특징을 MLP 회귀모델을 통해 생성하여 음악분류에 적용하는 실험을 진행하여 성능을 측정하였다.
⦁ MSP + CNN: 음악신호를 스펙트럼으로 변환(MSP)하여 합성곱 신경망(CNN) 분류기에 적용한다.
⦁ MSP + BGRU: CNN 대신에 BGRU를 적용한다.
⦁ MSP + CBGRU: BGRU 대신에 CBGRU를 적용한다.
⦁ MSP + SIA-BGRU: MSP를 CBGRU 대신에 SIA-BGRU에 적용한다.
⦁ MSP-ESP + SIA-BGRU: MSP 대신에 음악특징과 EEG 특징을 함께 SIA-BGRU 방식에 적용한다.
⦁ MSP + MLP + CNN: MLP 기반 회귀를 사용하여 음악신호의 멜스펙트럼에 VGG19를 적용하여 추출한 음악특징 MSP와 FIA-BGRU 인코더에서 추출한 EEG 특징 간의 관계를 학습한다. 학습된 회귀 모델을 기반으로 입력 음악에서 추출한 MSP에 대한 EEG 특징이 자동으로 생성되어 CNN 분류기에 적용된다.
⦁ MSP + MLP + BGRU: 회귀방식을 적용하여 생성된 EEG 특징을 CNN 대신에 BGRU 분류기를 적용한다.
⦁ MSP + MLP + CBGRU: BGRU 대신에 CNN과 BGRU가 결합된 CBGRU 분류기가 적용된다.
⦁ MSP + MLP + SIA-BGRU: CBGRU 대신에 SIA-BGRU 분류기가 적용되며, 우리가 제안하는 방법이다.
Table 2는 두 번째 실험의 결과를 나타낸다. 각 감정과 연관된 EEG 신호에서 특징 벡터를 선택하기 위해 두 가지 다른 접근법을 사용하여 평가했다.
Table 2.
Music classification results using regression model (%).
첫 번째는 회귀 학습을 위해 개인별 EEG 신호에서 추출한 특징 벡터를 개별적으로 적용한 개별 접근법이다. 두 번째는 각 감정 클래스의 모든 참가자의 EEG 신호를 학습하여 추출한 특징 벡터를 적용하는 일반적인 접근 방식이다. 일반적인 접근 방식의 경우에서는 참가자의 일부 데이터가 학습에 적용되었다. 실험결과는 제안하는 방식인 MSP + MLP + SIA-BGRU가 개인별 측정과 일반적 측정 모두에서 MSP + MLP + CBGRU, MSP + MLP + BGRU, MSP + MLP + CNN 보다 우수한 성능의 교차 분류 정확도를 보여주었다. 그리고 EEG를 적용한 감정분류 결과가 MSP만을 적용한 경우보다는 월등히 우수하였고, MSP와 ESP를 결합한 방식 보다 개별 접근법에서 약간 우수하였고, 일반적인 접근 방식에서는 약간 낮은 결과를 보여주었다.
