

I. 서 론
II. 기존 방법
2.1 주파수 분할 다중화
2.2 주파수 편이 변조
III. 제안한 방법
3.1 오토인코더
3.2 오토인코더 기반 소노부이 신호 변․복조 기법
IV. 실험 환경 및 결과
4.1 모의실험 데이터
4.2 실험 환경
4.3 실험 결과
V. 결 론
I. 서 론
소노부이는 소나(sonar)와 부이(buoy)의 합성어로 음파를 통해 수중정보를 수집하는 장치를 말한다. 소노부이는 일회성 장치로서 주로 해상초계기에서 관심지역으로 투하하여 운용되는데 수중에 전개된 센서 배열을 이용하여 수집한 수중신호를 부이를 통해 무선 통신으로 신호처리가 가능한 해상초계기로 전송하고 임무를 마치면 해저로 가라앉도록 설계되어 있다. 소노부이는 탐지하는 방식에 따라 수동형 과 능동형으로 나뉘며 제품 모델마다 탐지 범위, 작동 시간, 사용 수명 등이 매우 다양하다.[1] 그 중 신호의 전송 비트율은 적게는 초당 수 백 킬로비트(Kilobits per second, Kbps)에서 수십 메가비트(Megabits per second, Mbps)까지 사용된다.[2]
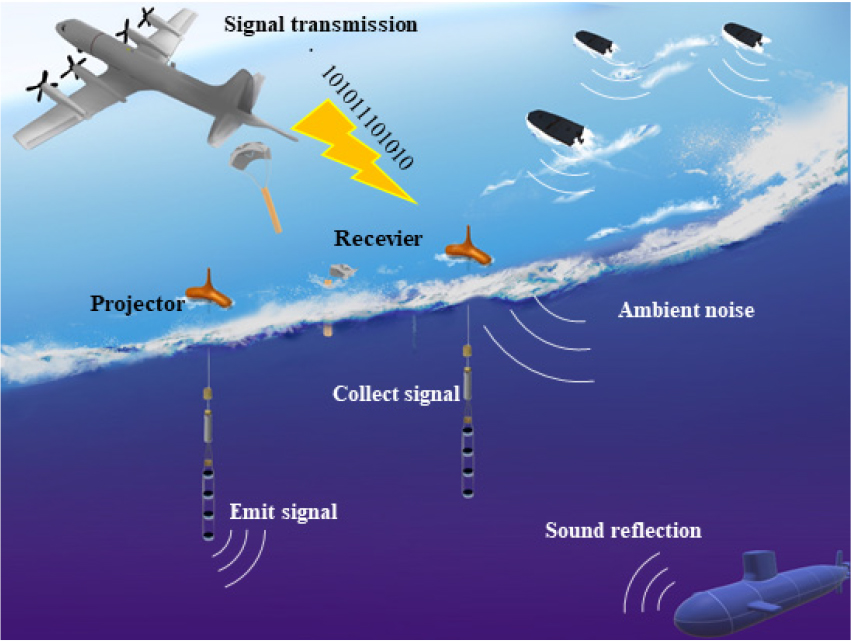
소노부이는 능동형 소노부이인 Command Activated Sonobuoy System(CASS) 또는 Directional CASS(DCASS)를 단독으로 사용할 경우 단상태로 운용될 수 있고, 폭발성 음원 또는 능동형 소노부이와 수동형 소노부이의 조합으로 양상태 및 다중상태로 운용될 수 있다.[3] 일반적으로 양상태 탐지는 송신기와 수신기의 위치가 다르므로 단상태 탐지에 비해 탐지 영역이 넓고 은밀성을 보장하는 장점을 가진다.[4] Fig. 1은 대잠전에서 능동형 소노부이와 수동형 소노부이를 이용한 양상태 표적 탐지 환경을 도식화한 연구개념도이다. 소노부이는 일회성의 장치로 탑재된 전자부의 시스템이 복잡한 신호처리를 수행할 수 없기 때문에 필연적으로 수집한 센서신호를 무선통신을 통해 해상초계기 또는 모함으로 송신한다. 기존에 무선통신에서 사용되는 신호 변․복조 방식은 주파수 분할 다중화[5]와 주파수 편이 변조[6] 등이 있다. 이러한 신호 변․복조 방식은 송신해야 하는 정보가 단채널화 된 신호 전체이기 때문에 전송해야할 정보의 양이 많아 높은 비트율이 요구되는 단점이 있다. 또한, 변조된 신호의 주파수 대역을 쉽게 분석 가능하기 때문에 변조 방식을 비교적 쉽게 예측할 수 있고 복조해 낼 수 있는 가능성이 크므로 보안성이 낮다. 따라서, 본 연구에서는 오토인코더를 이용하여 송신 신호를 저차원의 잠재 벡터로 변조하여 잠재 벡터를 항공기 또는 함정으로 전송하고 수신한 잠재벡터를 복조하여 전송정보량을 감소시키고 신호의 보안성을 향상시킬 수 있는 방법을 제안하였다.
II. 기존 방법
2.1 주파수 분할 다중화
주파수 분할 다중화는 다채널 신호를 단채널으로 전송하기 위해 사용하는 방식으로 다채널 신호는 다중화기 내부에서 서로 다른 주파수 대역으로 옮겨진다. 변조된 신호들은 단순한 덧셈을 통해 단채널 신호로 합쳐진 뒤 전송된다. 수동 소노부이 중 Directional Frequency Analysis and Recording(DIFAR) 소노부이는 주파수 분할 다중화를 사용하며 전체적인 구조는 Fig. 2과 같다. DIFAR는 단채널로 합쳐진 신호 전체를 전송하기 때문에 비트율이 높은 편이며 전송된 신호가 주파수 축에서 쉽게 구분 가능하기 때문에 보안성이 떨어진다.
2.2 주파수 편이 변조
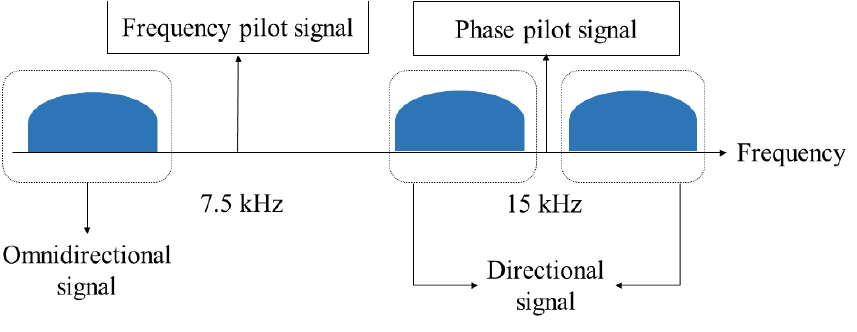
주파수 편이 변조는 사인파와 같은 반송파 신호의 주파수 변화로 정보를 전송한다. 가장 단순한 이진 주파수 변이 변조의 경우 0과 1의 이진수 정보를 전송하기 위해 다른 주파수의 두 신호를 사용한다. 이밖에도 주파수 변환시 가우시안 필터를 사용하는 방식은 가우시안 주파수 편이 변조라 하는데 다양한 소노부이 모델에서 사용하는 신호 전송 방식이다.
III. 제안한 방법
3.1 오토인코더
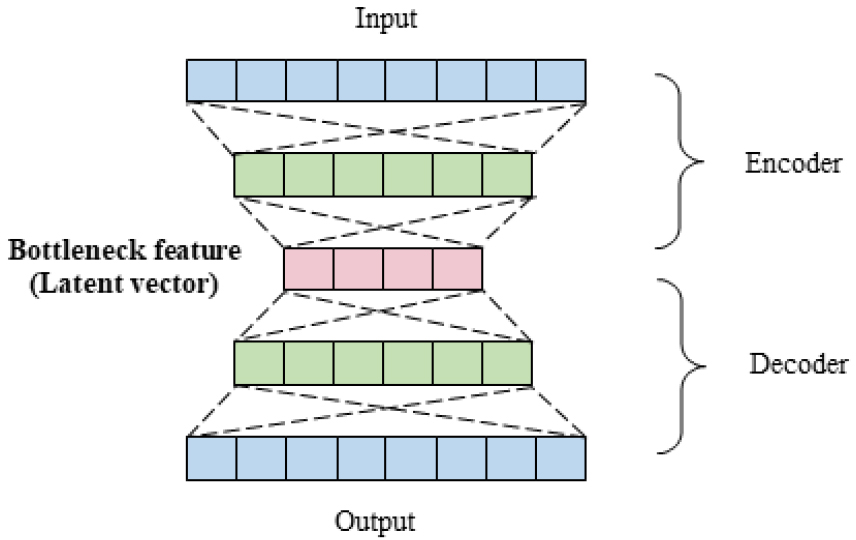
오토인코더는 딥러닝 분야에서 널리 쓰이는 구조로 모델의 출력값이 입력값과 동일하도록 훈련하며 대칭적인 구조가 특징이다. 해당 구조는 크게 변조기, 복조기, 그리고 그 사이에 보틀넥 구간으로 나뉜다. 인코더 부분을 통과하여 추출된 보틀넥 구간의 잠재 벡터는 일반적으로 입력 특징 벡터의 차원보다 매우 낮으며 데이터의 함축적인 특징을 반영하고 있다. 그렇기 때문에 오토인코더는 하나의 모델로서 어떤 전체적인 역할을 수행하기 보다는 다른 모델 가중치의 초기값을 얻기 위해 사용하거나 잠재 벡터의 특성을 이용한 특징 추출기의 역할을 주로 수행한다.[7] 이 때 변조기와 복조기가 여러층으로 이루어진 경우를 적층 오토인코더(stacked autoencoder)라 하고 전체적인 구조는 Fig. 3과 같다.
3.2 오토인코더 기반 소노부이 신호 변․복조 기법
본 논문에서는 오토인코더 구조를 이용해 소노부이내에서는 내장된 변조기를 통해 잠재 벡터를 전송하고, 해상초계기에서는 복조기를 이용해 수신한 잠재 벡터를 다시 원본 신호로 복조할 수 있도록 한다. 제안한 방법의 전체 과정은 Fig. 4와 같다.
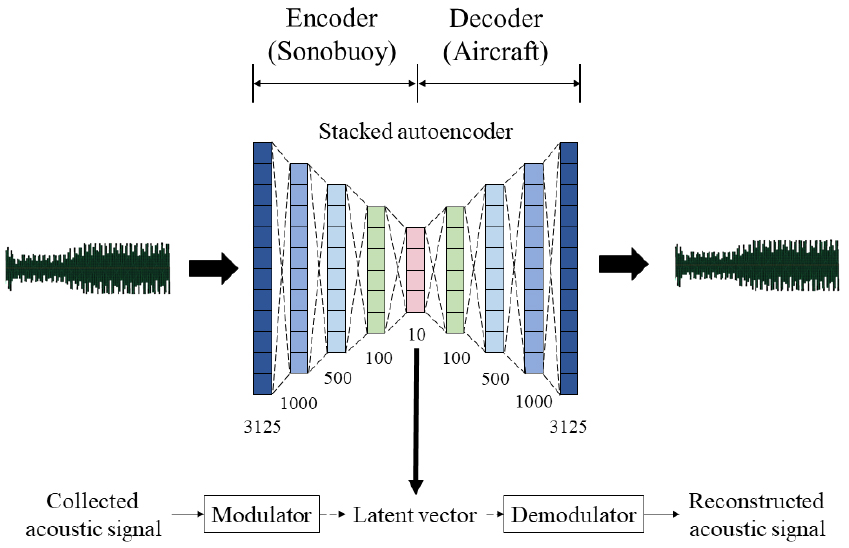
해당 연구의 목적은 소노부이 신호를 전송할 때 기존의 방식보다 적은 비트를 사용하여 신호의 보안성까지 확보하는 것으로 오토인코더는 이 두 가지 목적을 모두 만족하는 적합한 모델로 판단하였다. 오토인코더는 입력값과 출력값을 같게 훈련하므로 전송 신호를 다시 복조하는 개념과 부합한다. 또한 보틀넥 구간의 잠재 벡터는 원본 신호로 복원할 수 있는 정보를 가지고 있기 때문에 전체 신호를 전송하지 않더라도 잠재 벡터와 훈련된 복조기만 있다면 원본 신호로 복조할 수 있다. 이를 이용하면 기존의 소노부이 신호 전송 기법에 비해 매우 낮은 비트율을 만족할 수 있게 된다. 게다가, 이 모든 송․수신 과정은 기본적으로 훈련된 오토인코더 모델을 보유하고 있어야 복조가 가능하기 때문에 제3자는 송신하는 잠재 벡터를 취득하더라도 원본 신호로 복조할 수가 없다.
IV. 실험 환경 및 결과
4.1 모의실험 데이터
본 논문에서는 제안한 방법을 검증하기 위해 수중 환경에서의 양상태 모의실험 데이터를 생성하였다. 송신기에서 발생하는 신호는 연속파(Continuos Wave, CW)와 선형 주파수 변조(Linear Frequency Modulation, LFM) 두 가지 형태로 데이터를 생성하였다. 송신기와 수신기의 위치는 고정하였고 표적과 소노부이의 최대 거리는 9 km로 제한하였다. 표적 기동 범위는 50 m에서 150 m 사이로 설정하였다. 기타 상세한 모의실험 데이터 생성 환경은 Table 1에 정리하였다.
Table 1.
Simulation environmental setup.
| CW | LFM | |
| Center frequency | 3500 Hz, 3600 Hz, 3700 Hz, 3800 Hz | |
| Bandwidth | - | 400 Hz |
| Pulse duration | 0.1 s, 0.5 s, 1 s | |
| Sampling frequency | 31250 Hz | |
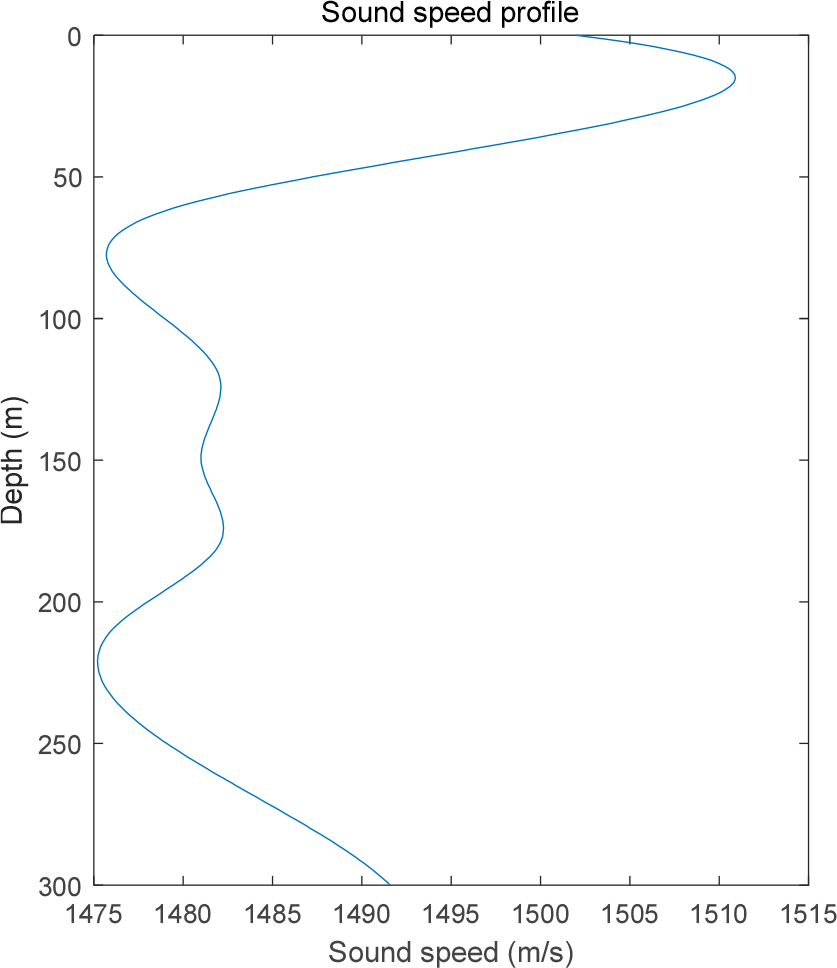
임의의 표적에서 반사되는 펄스 신호를 수신하는 시나리오로 데이터를 생성하였다. 표적의 위치가 무작위로 설정된 시나리오는 약 10 s 분량의 파일로 저장된다. 총 훈련데이터는 약 50 h의 분량으로 훈련의 수렴여부를 평가하기 위한 데이터는 훈련 데이터와 별개로 약 3 h 분량의 데이터를 생성하여 사용하였다. 모든 데이터는 Fig. 5와 같이 음선추적기법[8]을 적용하여 생성하였으며 음선추적에 사용된 음속 구조는 Fig. 6과 같다.

4.2 실험 환경
단순한 단층의 오토인코더 구조로는 소노부이 신호를 모델링 할 수 없기 때문에 본 실험에서는 적층 오토인코더를 활용하여 훈련을 진행한다. 실험에 사용한 모델의 파라미터 세팅은 Table 2와 같다. 해당 파라미터는 경험적으로 설정한 것으로 연구 데이터의 특성상 손실 값만으로는 결과를 확인할 수 없기 때문에 직접 복원된 샘플을 통해 판단해야 한다. 훈련 레이어의 넓이와 깊이는 최적의 변수는 아니지만 레이어의 깊이가 너무 낮은 경우에는 복잡한 입력 신호의 분포를 모델링하지 못하였다.
Table 2.
Configuration of the baseline autoencoder model.
일반적인 오디오 신호들과는 달리 수중 음향 신호의 경 주파수 축에서 매우 드물기 때문에 본 연구에서는 주파수 축의 특징 벡터를 입력으로 사용하지 않고 시간 축에서의 음향 신호를 그대로 입력으로 사용한다. 그렇기 때문에 제안한 방법은 일종의 단대단 접근방식에 속한다. 입력 신호는 파일마다 –1 ~ 1 범위로 정규화 하였고 모델의 입력 크기는 너무 작을 경우에는 한 주기의 펄스를 제대로 반영하지 못해 불연속성이 생길 수 있기 때문에 0.1 s(3125 샘플) 단위로 모델에 넣어주었다. 선형 층 사이에는 Rectified Linear Unit(ReLU)을 활성화 함수로 사용하여 입력 신호의 비선형성을 반영하도록 하였고 복조기의 마지막 층에서는 쌍곡탄젠트를 활성화 함수로 사용하여 –1 ~ 1 범위로 다시 신호를 복원하였다. 손실 함수로는 평균 제곱 오차(Mean Square Error, MSE)를 이용해 입력신호와 출력신호의 차이를 샘플마다 계산하였고 학습률이 0.001인 아담(Adam) 최적화 방식[9]을 사용하였다.
4.3 실험 결과
오토인코더의 원본 신호 복원 성능을 평가하기 위해 원본 스펙트로그램과 복원된 스펙트로그램의 크기 평균 제곱 오차(Mean Square Error, MSE)를 측정하였다. 평가에 사용한 신호는 모델 훈련에 사용하지 않은 60 s 분량의 데이터를 생성하였고 주파수 축에서 평균 에너지는 0.0074였다. Table 2의 모델(Autoencoder3)보다 레이어 수가 적은 2개의 오토 인코더 모델(Autoencoder1, Autoencoder2)의 성능을 측정하여 Table 3에 정리하였다. 실험 결과, 원본 신호와의 차이를 나타내는 MSE가 원본 신호의 에너지 평균에 비해 Autoencoder1, Autoencoder2, Autoencoder3이 각각 4.08 %, 3.88 %, 3.22 %로 전반적으로 원본신호와 차이가 크지 않았으며 8개의 선형 층으로 구성된 모델의 성능이 가장 우수하였다.
Table 3.
Comparison of autoencoder models in MSE. Autoencoder3 refers to the model in Table 2.
| Model | MSE | # of parameters |
|
Autoencoder1 (4 layers) | 0.000302 | 6.27 M |
|
Autoencoder2 (6 layers) | 0.000287 | 6.66 M |
|
Autoencoder3 (8 layers) | 0.000238 | 7.36 M |
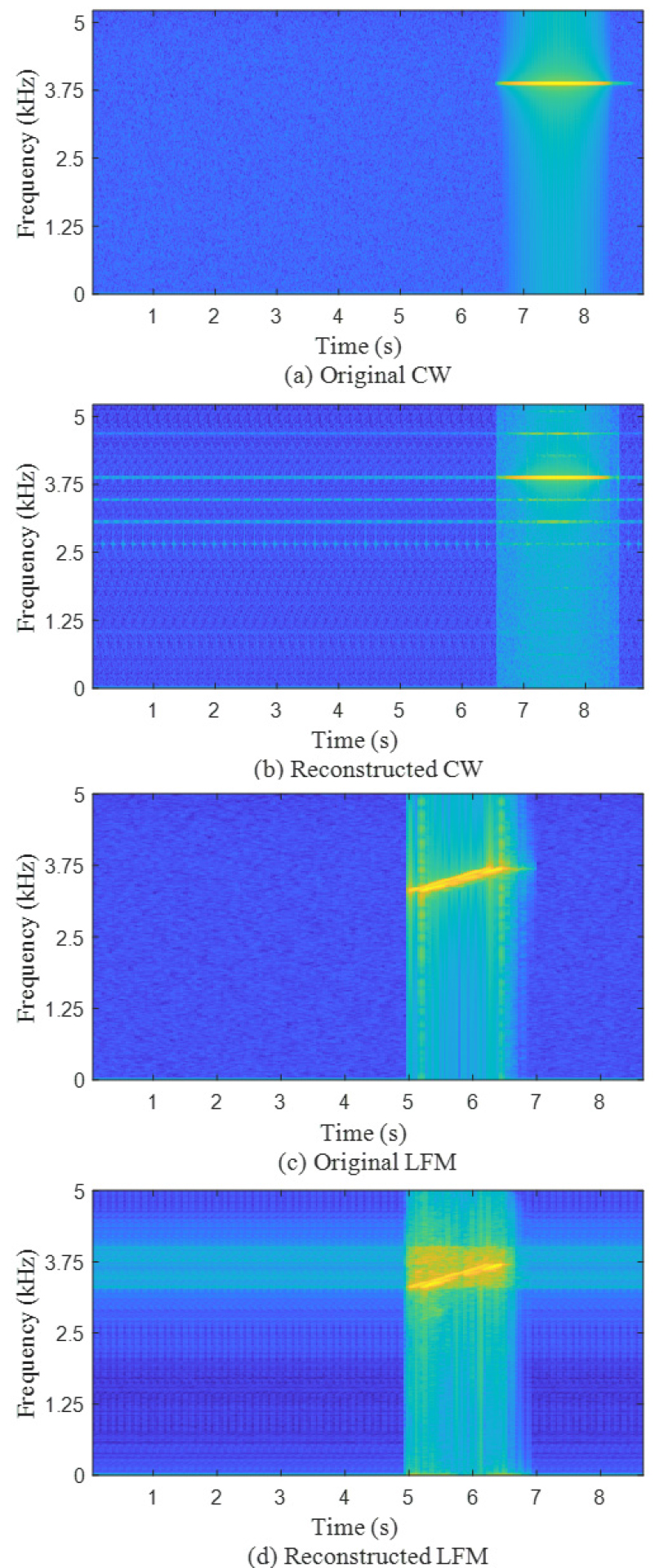
Fig. 7의 실제로 복원된 샘플의 스펙트로그램을 살펴보면 저차원의 잠재 벡터로 원본 신호를 대체로 복원할 수 있음을 확인할 수 있다. 실제 반사 신호가 존재하는 주파수 대역외에도 고조파와 같은 형태의 신호가 보이거나 묵음 구간에도 잡음같은 신호가 존재하는 것을 볼 수 있다. 묵음 구간의 경우에는 실제 원본신호의 묵음구간의 데이터의 크기가 너무 작아서 오토인코더 모델의 편향값에 의해 반사 신호가 존재하는 대역폭에 잡음과 같은 신호가 발생하는 것으로 추정된다. 또한 제안한 방법은 별도의 특징 벡터 추출 과정 없이 훈련을 진행하기 때문에 손실 함수 값이 감소하더라도 시간 축에서의 작은 값 차이가 고주파 대역에서의 잡음으로 나타날 수 있다. 그럼에도 불구하고 두 가지 형태의 신호 모두 반사 신호가 존재 하는 주파수 대역은 매우 유사하게 복원하였고 묵음 구간에 생성된 잡음과 같은 신호는 사용자의 관심 표적의 에너지에 비하면 매우 낮은 수준이다.
원본 신호의 복조를 위해서는 잠재 벡터 이외에도 정규화에 사용한 2개의 값까지 전송해야 한다. 따라서 10차원의 잠재벡터와 정규화에 사용한 크기 값을 각각 4비트로 양자화할 경우 제안한 방법의 정보량은 약 1.5 kbps로 기존의 소노부이 송․수신에 사용된 정보량[2]보다 약 100배 가량의 정보량 저감 효과를 기대할 수 있다. 또한 훈련된 변조기에서 추출된 잠재벡터의 경우 제3자가 신호를 취득하더라도 훈련된 복조기가 없다면 복조가 불가능하므로 높은 신호 보안성까지 얻을 수 있다.
V. 결 론
본 논문에서는 오토인코더를 활용한 소노부이 신호 송․수신 전송 방법을 제안하였다. 제안한 방법의 유효성을 입증하기 위해 양상태 수중 음향 환경을 모사하여 데이터를 생성하였다. 실험 결과 기존의 소노부이 전송 방식[2]과 비교하였을 때 전송해야하는 정보량이 약 100배 감소하였고 전송 신호의 보안성까지 확보하였다. 하지만 원본 신호와 비교하였을 때 고조파같은 아티팩트가 발생하였다. 후속 연구로는 해당 아티팩트를 줄이기 위해 오토인코더 모델을 고도화하고 주파수 축 특징벡터를 임베딩 벡터의 형태로 함께 사용하는 소노부이 신호 전송 방법을 연구할 계획이다.
