

I. 서 론
최근 들어, 다양한 어플리케이션 (Home Theater, Movie, Game, etc.)에서 오디오 재생 시스템을 통해 보다 높은 공간감 및 현장감을 구현하기 위해 5.1채널 혹은 그 이상의 채널 스피커들이 사용되고 있다. 하지만 멀티채널 스피커 환경을 재생하기 위해서는 스피커 증가에 비례해서 데이터 전송률도 비례하여 함께 증가하기 때문에, 대역폭이 제한되는 방송 혹은 양방향 통신 환경에서는 구현하기 어렵다. 이러한 제한 요소를 극복하기 위해 사람의 청각적인 특성을 이용하는 “공간 오디오 부호화(Spatial Audio Coding)” 기술이 연구되었고, MPEG에서는 이 기술을 기초로 해서 “공간 오디오 객체 부호화(SAOC, Spatial Audio Object Coding)” 기술을 표준화하였다.[1] SAOC는 채널 기반이 아닌 오디오 객체 기반으로 처리되기 때문에, 수신단에서 사용자 목적에 따라 이득(gain) 이나 공간적 위치(spatial position) 등을 임의로 설정할 수 있는 렌더링(rendering) 정보가 사용된다. 이 정보를 통해 SAOC는 어떤 스피커 환경에도 적응적으로 신호를 재생할 수 있다.
SAOC는 입력 객체들을 모노(mono) 혹은 스테레오(stereo) 로 다운믹스(downmix) 하고, 각 객체의 특성을 파라미터(parameter)로 변환하여 전송하기 때문에, 수신단에서 입력된 객체의 파형(waveform)을 완벽하게 복원하기 어렵다.[1-2] 특히, Karaoke 모드와 같이 보컬(vocal) 객체를 완벽하게 제거 시켜야하는 환경에서는 다운 믹스된 신호로부터 여러 객체들이 완벽하게 분리되지 않는 한계 때문에, 합성된 신호에 보컬 특성이 함께 섞여서 출력된다. 이러한 약점을 극복하기 위해 SAOC 에서는 부호화단에서 파라미터 부호화를 통해 발생되는 오차 신호(error signal)를 추가로 전송하여, 합성된 신호로부터 발생할 수 있는 음질적 열화를 보상해주는 잔여 부호화(residual coding)방법을 사용 한다.[3] 잔여 부호화를 사용하지 않는 환경에서도 부호화단에서 보컬 객체의 기초 주파수(fundamental frequency) 정보를 추정하여 전송함으로써 복호화 과정에서 합성되는 하모닉(harmonics) 성분들을 제거하는 방법을 사용하여 복호화의 성능을 향상시킬 수 있다.[4] 하지만, 이 방법의 경우 DFT(Discrete Fourier Transform) 대역에서 연산이 이루어지기 때문에, 해당 알고리듬을 SAOC 표준 비트스트림(bitstream)에 직접적으로 적용할 수 없는 단점이 있다.
본 논문에서는 SAOC 표준 비트스트림을 이용한 환경에서 Karaoke 모드의 전체적인 음질을 향상시킬 수 있는 알고리듬을 제안하였다. 제안된 알고리듬의 주 목적은 부호화단에서 추가정보 없이 Karaoke 모드로 복호화된 뒤 남아 있는 보컬 성분들을 제거하여 전체적인 음질을 향상시키는 방법이다. 이는 Karaoke 모드로 복호화된 신호와 SAOC의 솔로(Solo) 모드로 추가로 복호화된 신호를 교차 예측(cross prediction)을 수행함으로써 Karaoke 신호에 남아있는 보컬 성분을 추정하여 제거 할 수 있다. 하지만, 교차 예측의 입력으로 사용되는 두 신호가 똑같은 다운 믹스 신호로부터 복호화되기 때문에 두 신호간의 상관성이 매우 높다. 이는 보컬 성분뿐만 아니라, 음악 성분(보컬이 아닌 성분)도 함께 예측을 하여 음악 신호의 음질 열화도 함께 초래한다. 이러한 문제를 보완하기 위해, 본 논문에서는 교차 예측 과정에서 예측을 억제하기 위해 심리 음향적 특성을 고려한 방해 신호(disturbance signal)을 적용하였으며, 이 방해 신호의 크기는 사람의 청각적인 특성을 적용하여 Karaoke 음질의 열화를 최소화하며 보컬 성분을 추정하도록 설정되었다. 그리고 객관적, 주관적인 실험 결과를 통해 제안된 알고리듬이 효과적이었음을 확인하였다.
본 논문은 2장에서는 SAOC의 기본 구조를 간단히 소개하고 Karaoke 모드에서의 문제점을 지적하였으며, 3장에서는 본 논문에서 제안하는 교차 예측을 기반으로 한 보컬 추정 알고리듬을 설명한다. 4장에서는 제안된 알고리듬의 성능을 평가하기 위해 객관적 및 주관적 실험 결과를 보여주고 마지막 5장에서 결론을 맺는다.
II. SAOC의 기본적인 구조와 Karaoke 모드에서의 문제
기본적인 SAOC의 부호화기와 복호화기의 구조는 Fig. 1 과 같다.
|
(a) |
|
(b) |
Fig. 1. Spatial Audio Object Coding (a) Encoder (b) Decoder. |
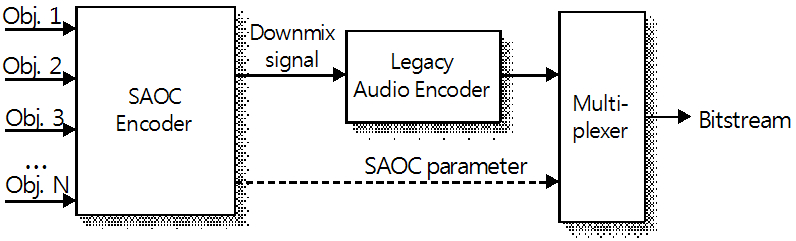
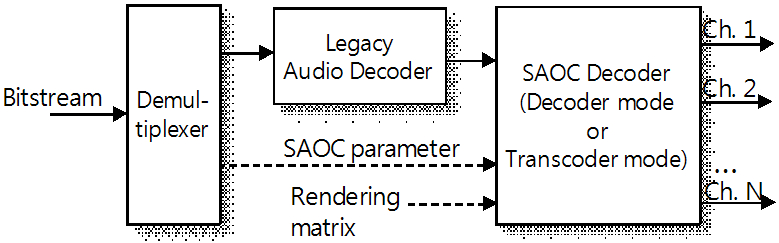
Fig. 1(a)의 부호화기에서 입력되는 오디오 객체들은 hybrid-QMF 필터뱅크(filterbank)를 통해 시간-주파수 신호로 변환된다. 다음, OLD(Objective Level Difference), IOC(Inter Object Correlation)와 DMG(DownMix Gain), 등과 같은 공간 객체 파라미터들을 각 주파수 밴드 단위로 추출한다. 입력 오디오 객체 신호들은 모노 혹은 스테레오 신호로 다운믹스 되고, 현존하는 오디오 부호화기(AAC, MP3 등)를 이용하여 부호화되어, 추출된 파라미터와 함께 비트스트림으로 전송된다.[5]
Fig. 1(b)의 SAOC 복호화기는 비트스트림으로부터 전송된 다운믹스 신호와 공간 객체 파라미터뿐만 아니라, 사용자 인터페이스 기반의 렌더링 매트릭스[5]도 함께 이용하여 출력 채널 환경에 맞는 공간 파라미터를 계산한다. 다음, 이 공간 파라미터를 다운 믹스 신호에 적용하여 원하는 채널 환경에 맞게 합성한다. 이 때, SAOC 복호화기의 연산량이 효율적으로 사용되도록 출력하고자하는 채널 수에 따라 디코더 모드(decoder mode)와 트랜스코더 모드(transcoder mode)로 구분된다. 예로, 모노, 스테레오, 바이노럴 스테레오(binaural stereo) 신호를 출력할 때는 디코더 모드가 동작하며, 그 이상의 채널(5.1 채널) 신호들을 출력할 때에는 트랜스코더 모드로 동작한다. 트랜스코더 모드에서는 먼저 입력 다운믹스 신호와 객체 파라미터들을 MPEG 서라운드(MPEG Surround(MPS))[6] 복호화기에 적합한 비트스트림으로 변환되고, 최종 멀티채널 신호는 MPS 복호화기를 통해 출력된다.
SAOC의 렌더링 매트릭스는 사용자에 의해 완전히 제어된다. 만약 N개의 객체가 입력으로 사용된다면, 임의의 주파수 밴드 ![]() 에서의 출력 신호의 파워는 다음과 같이 계산된다.
에서의 출력 신호의 파워는 다음과 같이 계산된다.
| (1) |
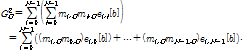
식에서 ![]() 는 주파수 밴드
는 주파수 밴드 ![]() 에서 입력 오디오 객체
에서 입력 오디오 객체 ![]() 와
와 ![]() 사이의 공분산(covariance)을 나타내며,
사이의 공분산(covariance)을 나타내며, ![]() 로 정의될 수 있다.식에서 IOC와 OLD 파라미터들은 각각
로 정의될 수 있다.식에서 IOC와 OLD 파라미터들은 각각 ![]()
![]() 와
와![]()
![]() 로 나타낼 수 있으며,
로 나타낼 수 있으며, ![]() 는 밴드
는 밴드 ![]() 에서 객체
에서 객체 ![]() 와 객체
와 객체 ![]() 와의 곱을 의미한다. 렌더링 매트릭스의 원소(element)
와의 곱을 의미한다. 렌더링 매트릭스의 원소(element) ![]() 는
는 ![]() 번째 객체를
번째 객체를 ![]() 번째 채널에 할당하는 게인 값을 나타낸다. 그러므로 입력 N개의 오디오 객체가 모두 서로 비상관(decorrelated) 되어 있고, N번째 객체가 보컬 객체라고 가정한다면, Karaoke 모드로 복호화 되는 식(1)은 아래 식으로 간략화될 수 있다.
번째 채널에 할당하는 게인 값을 나타낸다. 그러므로 입력 N개의 오디오 객체가 모두 서로 비상관(decorrelated) 되어 있고, N번째 객체가 보컬 객체라고 가정한다면, Karaoke 모드로 복호화 되는 식(1)은 아래 식으로 간략화될 수 있다.
| (2) |
다운 믹스 신호는 입력 오디오 객체들의 합으로 구성되기 때문에, 모든 오디오 객체들의 공간 단서(spatial cue)들은 다운 믹스 신호 내에 섞여있다. 이 때문에 음질의 왜곡 없이 특정 단서를 완전히 제거하기가 불가능하므로, Karaoke 환경과 같이 특정 객체만을 완전히 제거하는 분야에 사용하기에는 적합하지 않다. 그러므로, 본 논문에서는 후처리 연산을 통해 음질의 왜곡을 최소화하며 특정 객체의 영향을 줄여줄 수 있는 방법(본 논문에서는 Karaoke 모드에서 보컬 객체의 영향을 최소화)을 제안하였다.
III. SAOC에서의 보컬 추정 알고리듬
SAOC의 복호화가 잘 이루어질 수 있다면, 이상적으로는 Karaoke 모드에서 음악(보컬 객체만 제거된) 신호만을 복원할 수 있어야한다. 하지만, 실제로는 입력 객체들 간의 분리가 완벽하지 않기 때문에, Karaoke 모드에서 복원된 음악 신호에는 언제나 보컬 객체 성분이 섞여있다. 이러한 원치 않는 보컬 성분들은 예측 필터를 이용하여 제거할 수 있다. 기본적인 원리는 SAOC의 솔로 모드(보컬 객체만 합성)로부터 새로 합성된 신호를 Karaoke 모드 신호와 함께 예측 필터기의 입력으로 사용하여, Karaoke 신호 내에 존재하는 원치 않는 보컬 성분들을 추정하여, 그 성분을 제거하는 것이다. 하지만, 솔로 모드로부터 합성된 신호 역시 마찬가지로 완벽히 분리되지 않기 때문에 음악 객체 성분들이 보컬 신호에 섞여있게 된다. 그러므로 Karaoke모드와 솔로 모드를 통해 만들어진 두 신호는 전대역에 대해서 상당히 높은 상관성을 가지게 된다. 이러한 경우에 대해서 예측 필터를 이용한다면 음악 신호내의 보컬 성분뿐만 아니라, 음악 성분 신호도 함께 추정하게 되는 문제가 발생하기 때문에, 예측 필터를 그대로 사용할 수 없다. 본 논문에서는, 심리음향 모델의 마스킹 특성을 이용하여 음악 성분들에게는 청각적으로 변화를 주지 않는 예측 필터를 설계하여 음악 신호 내에 존재하는 보컬 성분을 추정하여 제거하는 알고리듬을 제안하였다.
아래부터는 설명의 편의성을 위해 입력되는 여러 객체들을 음악과 보컬 두 객체만으로 구분하였다. Fig. 2는 Karaoke 신호 내에 존재하는 잔여 보컬을 제거하기 위한 전체적인 블록도를 도시하였다. Fig. 2에서 점선 영역은 일반적인 SAOC 복호화 과정을, 파선 영역은 새로 제안된 알고리듬을 나타내었다. 그림에서 나타나 있듯이 잔여 보컬은 Karaoke 모드로 복호화된 신호 ![]() 와 솔로 모드로 복호화된 신호
와 솔로 모드로 복호화된 신호 ![]() 와의 교차 예측을 수행하여 추정하는데, 이 때 사용된 최적의 필터 계수
와의 교차 예측을 수행하여 추정하는데, 이 때 사용된 최적의 필터 계수 ![]() 는 최소 평균 제곱 에러(Minimum Mean Square Error) 척도를 이용하여 계산하였다. 그리고 음악 신호의 열화를 방지하게 위해 마스킹 특성이 반영된 예측 방해 신호
는 최소 평균 제곱 에러(Minimum Mean Square Error) 척도를 이용하여 계산하였다. 그리고 음악 신호의 열화를 방지하게 위해 마스킹 특성이 반영된 예측 방해 신호 ![]() 를 예측 과정에 추가하였다. 이에 대해서는 뒤에서 자세히 언급한다.
를 예측 과정에 추가하였다. 이에 대해서는 뒤에서 자세히 언급한다.
|
Fig. 2. Block diagram of the proposed vocla estimation. |
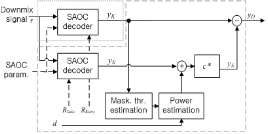
솔로 신호 ![]() 는 복호화 과정에서 새로 입력되는 렌더링 매트릭스
는 복호화 과정에서 새로 입력되는 렌더링 매트릭스 ![]() 를 통해 복호화 되는데, 이 매트릭스 내의 원소는 Karaoke 모드로 사용되는 렌더링 매트릭스
를 통해 복호화 되는데, 이 매트릭스 내의 원소는 Karaoke 모드로 사용되는 렌더링 매트릭스 ![]() 와 정 반대로 구성된다. 예로, 만약 입력으로 두 객체(첫 번째 객체는 음악 객체, 두 번째 객체는 보컬 객체)가 사용되었다고 가정하면, 두 렌더링 매트릭스
와 정 반대로 구성된다. 예로, 만약 입력으로 두 객체(첫 번째 객체는 음악 객체, 두 번째 객체는 보컬 객체)가 사용되었다고 가정하면, 두 렌더링 매트릭스 ![]() 와
와 ![]() 는 각각 다음과 같이 구성된다,
는 각각 다음과 같이 구성된다,![]() and
and ![]() .
.
입력으로 사용된 객체들은 복호화 과정에서 완벽히 분리되지 않기 때문에, Karaoke 신호 ![]() 와 솔로신호
와 솔로신호 ![]() 신호 내에는 각각 잔여 보컬 성분과 잔여 음악 성분이 입력 객체 파워의 크기에 따라 주파수 대역별로 서로 다른 레벨로 섞이게 되어, 두 신호는 전대역에 대해서 서로 높은 상관성을 가지게 된다. Fig. 3은 임의의 보컬과 음악 객체들로 구성된 신호에 대해서
신호 내에는 각각 잔여 보컬 성분과 잔여 음악 성분이 입력 객체 파워의 크기에 따라 주파수 대역별로 서로 다른 레벨로 섞이게 되어, 두 신호는 전대역에 대해서 서로 높은 상관성을 가지게 된다. Fig. 3은 임의의 보컬과 음악 객체들로 구성된 신호에 대해서 ![]() 와
와 ![]() 사이의 상관도를 나타낸 것이다.
사이의 상관도를 나타낸 것이다.
|
Fig. 3. Correlation between |
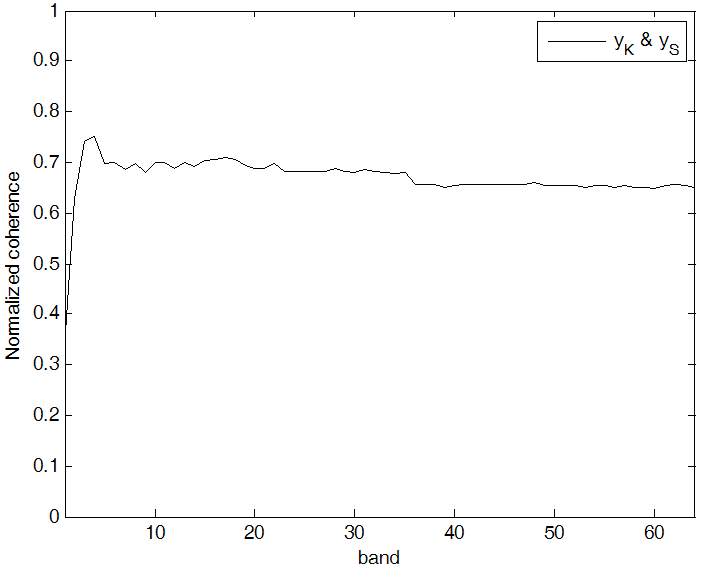
Fig. 3에서 가로 축은 주파수 밴드, 세로축은 아래와 같이 각 주파수 밴드단위로 정의되는 정규화된 상관 관계(normalized coherence)를 나타내었다.
| (3) |
식에서 ![]() 와
와 ![]() 는 각각
는 각각 ![]() 와
와 ![]() 의 파워를,
의 파워를, ![]() 와
와 ![]() 는 각각
는 각각 ![]() 와
와 ![]() 의 주파수 계수값을 의미한다. 그림에서 확인할 수 있듯이, 두 신호간의 상관 관계가 높아, 교차 예측기를 그대로 적용하면,
의 주파수 계수값을 의미한다. 그림에서 확인할 수 있듯이, 두 신호간의 상관 관계가 높아, 교차 예측기를 그대로 적용하면, ![]() 신호 내에 있는 보컬 성분뿐만 아니라, 음악 성분도 함께 추정되어 제거될 수 있다. 만약 예측 방해 신호
신호 내에 있는 보컬 성분뿐만 아니라, 음악 성분도 함께 추정되어 제거될 수 있다. 만약 예측 방해 신호 ![]() 를 적용하지 않고, 교차 예측을 수행하면 추정된 신호
를 적용하지 않고, 교차 예측을 수행하면 추정된 신호 ![]() 는 주파수 축에서 아래와 같이 나타낼 수 있다.
는 주파수 축에서 아래와 같이 나타낼 수 있다.
| (4) |
식에서 ![]() 는 예측 계수를, *은 복소 켤레를 의미한다. 최적의 예측 계수는 최소 평균 제곱 에러 척도를 이용하여 다음 식으로 계산된다.
는 예측 계수를, *은 복소 켤레를 의미한다. 최적의 예측 계수는 최소 평균 제곱 에러 척도를 이용하여 다음 식으로 계산된다.
| (5) |
식(5)에 식(3)을 적용하면, 아래 식으로 다시 표현될 수 있다.
| (6) |
이 결과를 이용하면 추정된 신호의 파워는 다음 식으로 계산된다.
| (7) |
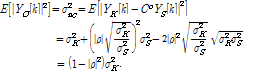
식(7)로부터 추정된 신호의 파워는 ![]() 의 인수 값으로 억제되는 것을 알 수 있다. 하지만, 솔로 신호
의 인수 값으로 억제되는 것을 알 수 있다. 하지만, 솔로 신호 ![]() 내에 존재하는 잔여 음악 신호로 인해, 직접적인 교차 예측 수행을 하게 되면 Karaoke 신호 내의 음악 성분도 함께 억제 시키는 문제가 발생한다. 예로, Fig. 3의 경우처럼
내에 존재하는 잔여 음악 신호로 인해, 직접적인 교차 예측 수행을 하게 되면 Karaoke 신호 내의 음악 성분도 함께 억제 시키는 문제가 발생한다. 예로, Fig. 3의 경우처럼 ![]() 일 경우, 오직 30%에 해당되는 음악 신호의 파워만이 추정된 신호에 남아있게 된다. 이러한 문제를 해결하기 위해, 본 논문에서는 Fig. 2에 나타낸 것처럼
일 경우, 오직 30%에 해당되는 음악 신호의 파워만이 추정된 신호에 남아있게 된다. 이러한 문제를 해결하기 위해, 본 논문에서는 Fig. 2에 나타낸 것처럼 ![]() 신호에 예측 방해 신호
신호에 예측 방해 신호 ![]() 를 추가하였다. 신호
를 추가하였다. 신호 ![]() 는 평균이 0, 분산이
는 평균이 0, 분산이 ![]() 인 가우시안(Gaussian) 특성을 갖는 랜덤 신호로 가정하였다. 이러한 환경에서 교차 예측을 통해 추정된 출력 신호는 다음과 같다.
인 가우시안(Gaussian) 특성을 갖는 랜덤 신호로 가정하였다. 이러한 환경에서 교차 예측을 통해 추정된 출력 신호는 다음과 같다.
| (8) |
식에서 ![]() 는 신호
는 신호 ![]() 의 주파수 계수값을 의미한다. 이 때, Karaoke 신호와 솔로 신호 사이의 정규화된 상관 관계와 최적의 예측 계수를 계산하면 다음과 같이 나타낼 수 있다.
의 주파수 계수값을 의미한다. 이 때, Karaoke 신호와 솔로 신호 사이의 정규화된 상관 관계와 최적의 예측 계수를 계산하면 다음과 같이 나타낼 수 있다.
| (9) |
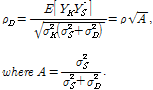
| (10) |
그러므로, 방해 신호가 추가된 환경에서의 추정된 신호의 파워는 아래와 같이 계산될 수 있다.
| (11) |
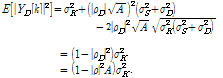
식(11)에서 확인할 수 있듯이, 추정된 신호는 ![]() 에 의해 영향을 받는다. 그러므로
에 의해 영향을 받는다. 그러므로 ![]() 의 크기는 추정된 신호 내의 음악 성분에 영향이 가지 않도록 조절되어야 한다.
의 크기는 추정된 신호 내의 음악 성분에 영향이 가지 않도록 조절되어야 한다.
비록 SAOC의 복호화기가 다운 믹스 신호 내에 섞여 있는 객체를 완벽하게 분리하지 못한 채 출력 신호로 합성하지만, 부호화단에 입력되는 두 객체는 서로 독립적인 특성을 가질 수 있다. 이러한 경우, 복호화단에서 Karaoke 신호와 솔로 신호는 식(1)을 통해 다음과 같이 나타낼 수 있다.
| (12) |
식에서 ![]() 과
과 ![]() 는 각각 주파수 밴드
는 각각 주파수 밴드 ![]() 에서의 음악 객체와 보컬 객체의 게인을,
에서의 음악 객체와 보컬 객체의 게인을, ![]() 는 다운 믹스 신호를 의미한다. SAOC 표준 부호화기는 QMF 도메인 기반으로 이루어지므로, 밴드 단위로 신호의 파워를 계산하면 아래와 같이 나타낼 수 있다.
는 다운 믹스 신호를 의미한다. SAOC 표준 부호화기는 QMF 도메인 기반으로 이루어지므로, 밴드 단위로 신호의 파워를 계산하면 아래와 같이 나타낼 수 있다.
| (13) |
에너지의 보존 법칙에 따라 두 신호 파워의 합은 다운믹스 파워의 합과 같아야 하므로 ,
| (14) |
식(14)와 ![]() 의 조건을 식(13)에 대입하여 전개하면 아래 식으로 나타낼 수 있다.
의 조건을 식(13)에 대입하여 전개하면 아래 식으로 나타낼 수 있다.
| (15) |
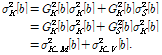
윗 식은 Karaoke 신호 내에 있는 각 객체의 파워를 나타낸 것으로 생각 될 수 있다. 비록, SAOC의 Karaoke 신호 내에 섞여 있는 보컬의 성분 및 특성을 정확하게 추출할 수는 없지만, 출력 신호 내에 있는 파워 크기에 대해서는 에너지 보존 법칙에 의해 식(15)에서처럼 분리시켜 생각할 수 있다. 식(15)에서는 Karaoke 신호 내에 있는 음악 성분의 파워를 ![]() , 보컬 성분의 파워를
, 보컬 성분의 파워를 ![]() 로 나타내었다. 이 결과를 식(11)에 적용하면 추정된 신호의 파워는 다음과 같이 나타낼 수 있다.
로 나타내었다. 이 결과를 식(11)에 적용하면 추정된 신호의 파워는 다음과 같이 나타낼 수 있다.
| (16) |
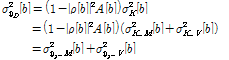
![]() 와
와 ![]() 는 각각 음악 성분과 보컬 성분의 파워를 의미한다. 식(16)에서 확인할 수 있듯이,
는 각각 음악 성분과 보컬 성분의 파워를 의미한다. 식(16)에서 확인할 수 있듯이, ![]() 에 존재하는 방해 신호의 파워
에 존재하는 방해 신호의 파워 ![]() ,
, ![]() 이라면
이라면 ![]() 는 0이 되고,
는 0이 되고, ![]() 인 경우에는 음악과 보컬 성분이 동시에 제거된다. 더욱이 식(15)의
인 경우에는 음악과 보컬 성분이 동시에 제거된다. 더욱이 식(15)의 ![]() 가
가 ![]() 보다 크고,
보다 크고, ![]() 이면 추정된 신호 내의 음악성분은 과도하게 제거된다. 그러므로 보컬을 추정하여 제거하는 과정에서
이면 추정된 신호 내의 음악성분은 과도하게 제거된다. 그러므로 보컬을 추정하여 제거하는 과정에서 ![]() 의 크기는 음악의 음질을 열화시키지 않도록 적절히 조절되어야한다. 본 논문에서는
의 크기는 음악의 음질을 열화시키지 않도록 적절히 조절되어야한다. 본 논문에서는 ![]() 를 계산하는 과정에서 사람의 청각적 마스킹 특성을 적용하였다. 즉, 음악 신호가 보컬 신호의 마스킹 임계치 아래에 존재하도록 추정 신호를 계산함으로써 음악의 청각적인 영향을 최소화시키는 것이다.
를 계산하는 과정에서 사람의 청각적 마스킹 특성을 적용하였다. 즉, 음악 신호가 보컬 신호의 마스킹 임계치 아래에 존재하도록 추정 신호를 계산함으로써 음악의 청각적인 영향을 최소화시키는 것이다.
일반적으로 마스킹 임계치는 사람의 청각 구조의 주파수 선택도와 마스킹 특성을 통해 모델링된다[7]. 그러나 오디오 코딩 분야에서와 같이 정교한 계산이 필요한 것과는 달리 각 주파수 대역 별로 대략적인 마스킹 레벨만 있어도 충분하다고 판단되므로 본 논문에서는 식(17)의 상대적 임계 오프셋(relative threshold offset)[7]만 고려하여 전체적인 마스킹 임계치로 간주하였다.
| (17) |
식에서 ![]() 는 토널리티(tonality) 인덱스를,
는 토널리티(tonality) 인덱스를, ![]() 는 바크(bark) 스케일 주파수 인덱스를 의미한다. 정확한 보컬과 음악 성분의 마스킹 임계치는 보컬과 음악 신호로부터 계산되어야 하지만, 복호화된 신호내의 각 성분들은 정확히 분리되기 힘들다. 그러므로 주파수 밴드 단위로 각 성분들의 파워를 나눠서 표현한 식(15)를 이용하여 마스킹 임계치를 계산하였다. 예로, 보컬 성분의 마스킹 임계치는 식(18)에 표현된 것 같이 식(17)을 식(15)의
는 바크(bark) 스케일 주파수 인덱스를 의미한다. 정확한 보컬과 음악 성분의 마스킹 임계치는 보컬과 음악 신호로부터 계산되어야 하지만, 복호화된 신호내의 각 성분들은 정확히 분리되기 힘들다. 그러므로 주파수 밴드 단위로 각 성분들의 파워를 나눠서 표현한 식(15)를 이용하여 마스킹 임계치를 계산하였다. 예로, 보컬 성분의 마스킹 임계치는 식(18)에 표현된 것 같이 식(17)을 식(15)의 ![]() 에 적용하여 얻을 수 있다.
에 적용하여 얻을 수 있다.
| (18) |
이처럼, 본 논문에서 계산된 각 성분별 마스킹 임계치는 각 대역별로 SAOC 복호화기에 전송되는 ![]() 과
과 ![]() 파라미터들을 통해서 계산된다. 만약 임의의 주파수 밴드
파라미터들을 통해서 계산된다. 만약 임의의 주파수 밴드 ![]() 에서 신호 내의 보컬 성분의 마스킹 임계치
에서 신호 내의 보컬 성분의 마스킹 임계치 ![]() 가 음악 성분의 파워
가 음악 성분의 파워 ![]() 보다 크다면 해당 주파수 대역에서는 보컬 신호에 의해 음악 신호가 마스킹 되어 들리지 않게 된다. 그러므로 방해 신호의 파워가 교차 예측을 수행한 뒤, 추정된 신호
보다 크다면 해당 주파수 대역에서는 보컬 신호에 의해 음악 신호가 마스킹 되어 들리지 않게 된다. 그러므로 방해 신호의 파워가 교차 예측을 수행한 뒤, 추정된 신호 ![]() 내의 보컬 성분의 마스킹 임계치
내의 보컬 성분의 마스킹 임계치 ![]() 가
가 ![]() 같도록 설정해준다면 추정 알고리듬이 수행된 뒤에도 적어도 청각적으로 음악 성분에 대해서는 영향을 끼치지 않을 수 있다. 이 조건을 만족하는
같도록 설정해준다면 추정 알고리듬이 수행된 뒤에도 적어도 청각적으로 음악 성분에 대해서는 영향을 끼치지 않을 수 있다. 이 조건을 만족하는 ![]() 를 계산하는 과정은 식(19)와 식(20)에 나타내었다. 나아가,
를 계산하는 과정은 식(19)와 식(20)에 나타내었다. 나아가, ![]() 가
가 ![]() 에 비해 두드러지게 높다면,
에 비해 두드러지게 높다면, ![]() 와
와 ![]() 의 차이도 커진다. 즉,
의 차이도 커진다. 즉, ![]() 라고 생각할 수 있다. 이는 교차 예측을 통해 억제 시킬 수 있는 보컬 성분의 양도 많아지므로, 제안된 알고리듬의 효과를 극대화 시킬 수 있다.
라고 생각할 수 있다. 이는 교차 예측을 통해 억제 시킬 수 있는 보컬 성분의 양도 많아지므로, 제안된 알고리듬의 효과를 극대화 시킬 수 있다.
| (19) |

| (20) |
식(20)은 식(9)를 참조하여 식(19)에서 계산 된 ![]() 값을 대입하여 구할 수 있다.
값을 대입하여 구할 수 있다.
Fig. 4는 SAOC 복호화된 신호의 파워 스펙트럼을 임의의 프레임에 대해서 제안된 보컬 추정 알고리듬을 사용하기 전과 후의 결과를 나타낸 것이다. SAOC 복호화할 때 사용된 다운믹스는 1.5 kHz, 2 kHz의 톤(tone) 신호와 노이즈 신호로 구성되어 있으며, 양자화를 수행하지 않았다. 실험 과정에서 톤 신호와 노이즈 신호는 각각 독립된 보컬과 음악 신호로 간주되었다.
|
Fig. 4. Comparison of the power spectra of (a) the SAOC output in Karaoke mode ( |
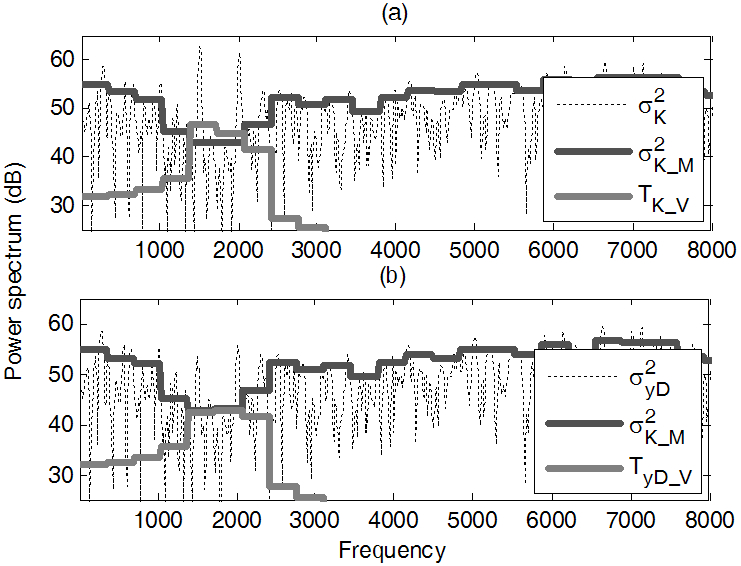
Fig. 4에서 결과는 8 kHz까지만 나타내었다. 보컬 추정 알고리즘은 톤 신호가 남아 있는 밴드에 대해서만 적용되었으며, 잔여 톤 신호들은 식(19)를 통해 제거되었다. Fig. 4의 (a)를 보면 몇몇 밴드에서 ![]() 가
가 ![]() 보다 높은데, 이는 해당 대역에 대해서 잔여 톤 신호의 파워가 상대적으로 커서 노이즈 신호가 마스킹 되었음을 의미한다. 이러한 대역에 대해서 제안된 알고리듬이 적용되어 보컬이 제거된 뒤, 출력 신호내의 보컬 성분의 마스킹 임계치
보다 높은데, 이는 해당 대역에 대해서 잔여 톤 신호의 파워가 상대적으로 커서 노이즈 신호가 마스킹 되었음을 의미한다. 이러한 대역에 대해서 제안된 알고리듬이 적용되어 보컬이 제거된 뒤, 출력 신호내의 보컬 성분의 마스킹 임계치 ![]() 를 확인하면, 해당 대역에 대해서 음악 성분의 파워 크기만큼 낮아졌음을 Fig. 4(b)를 통해 확인할 수 있다. 이는 추정된 신호내의 보컬 성분이 줄어들었음을 의미한다. 그러므로 Fig. 4를 통해서 비록 SAOC 복호화된 신호내의 보컬 성분은 완전히 제거되지 못했지만, 각 대역에 대해서 청각적으로 음악의 음질을 열화시키지 않았음을 알 수 있다.
를 확인하면, 해당 대역에 대해서 음악 성분의 파워 크기만큼 낮아졌음을 Fig. 4(b)를 통해 확인할 수 있다. 이는 추정된 신호내의 보컬 성분이 줄어들었음을 의미한다. 그러므로 Fig. 4를 통해서 비록 SAOC 복호화된 신호내의 보컬 성분은 완전히 제거되지 못했지만, 각 대역에 대해서 청각적으로 음악의 음질을 열화시키지 않았음을 알 수 있다.
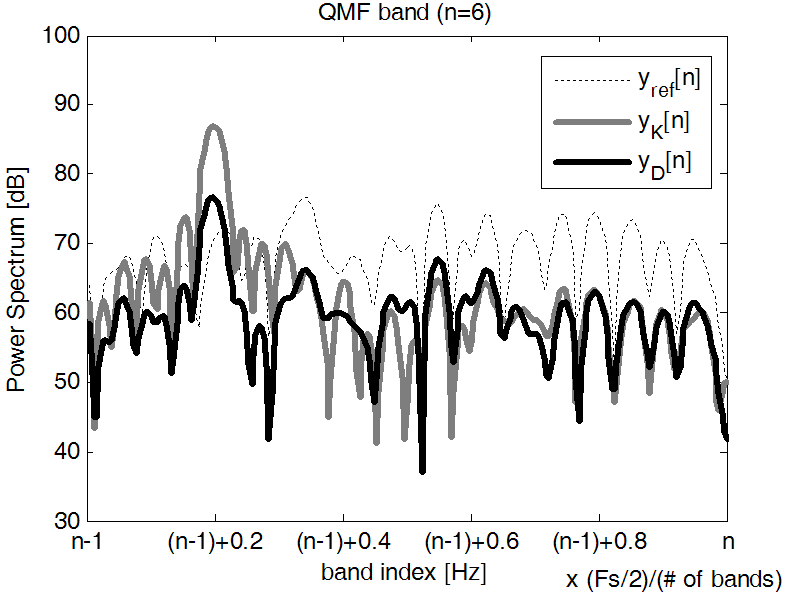
Fig. 5는 Fig. 4의 결과를 좀 더 자세히 관찰하기 위해, 보컬 추정 알고리듬이 수행되는 임의의 대역에 대해서 출력 신호의 스펙트럼을 관찰하였다. 그림에서 노이즈 신호 ![]() 를 Karaoke모드에서의 정답 신호로 간주하고, 톤과 노이즈 신호가 섞인 다운믹스 신호로부터 복호화된 신호를
를 Karaoke모드에서의 정답 신호로 간주하고, 톤과 노이즈 신호가 섞인 다운믹스 신호로부터 복호화된 신호를 ![]() , 제안된 알고리듬까지 적용된 결과를
, 제안된 알고리듬까지 적용된 결과를 ![]() 로 나타내었다.
로 나타내었다. ![]() 의 스펙트럼을 보면
의 스펙트럼을 보면 ![]() 에 남아 있는 톤 신호(x축에서 약 (n-1)+0.2에 위치함)가 보컬 추정 알고리듬을 통해 효과적으로 제거되었음을 알 수 있다. 나아가,
에 남아 있는 톤 신호(x축에서 약 (n-1)+0.2에 위치함)가 보컬 추정 알고리듬을 통해 효과적으로 제거되었음을 알 수 있다. 나아가, ![]() 스펙트럼을 보면 톤 성분이 추정된 위치로부터 멀어질수록 스펙트럼의 전체적인 변화가 작아져 톤이 위치한 곳에서만 음질의 변화가 발생하는 것을 확인할 수 있다.
스펙트럼을 보면 톤 성분이 추정된 위치로부터 멀어질수록 스펙트럼의 전체적인 변화가 작아져 톤이 위치한 곳에서만 음질의 변화가 발생하는 것을 확인할 수 있다.
|
Fig. 5. Comparison of the power spectrum of the output at an arbitrary band. |
IV. 실험 결과
제안된 알고리듬의 성능을 평가하기 위해, 객관적 및 주관적 음질 평가를 수행하였다. 제안된 알고리듬은 합성 QMF가 수행되기 전에 적용되었으며, 예측 계수는 4차로 설정하였다. 입력된 오디오 객체들은 부호화단을 통해 모노 신호로 다운믹스 하였다. SAOC 복호화를 진행할 때에는 양자화된 다운믹스 신호가 사용되지만, 제안된 알고리듬의 효과만을 확인하기 위해 양자화하지 않은 신호도 함께 실험에 포함하였다. 평가를 진행할 때에는 음악 객체만으로 구성된 ![]() 신호를 생성하여, Karaoke 신호
신호를 생성하여, Karaoke 신호 ![]() 와 보컬 추정 알고리듬이 적용된 신호
와 보컬 추정 알고리듬이 적용된 신호 ![]() 를 비교하며 평가하였다.
를 비교하며 평가하였다.
실험에 사용된 SAOC의 부호화기는 MPEG에서 제공되는 Reference model[8]을 개량하여 사용하였으며, 양자화된 다운믹스 신호는 HE-AAC를 이용하여 20kbps의 전송률로 부호화하여 사용되었다. 실험 샘플들은 Table 1에 나타내었다. “TN”을 제외한 샘플들은 MPEG 표준화 회의 때 공식 실험용으로 제안되었던 샘플들이며, 모두 44.1 kHz의 샘플링 레이트를 갖는다.
Table 1의 “Rock” 샘플의 경우, 다른 샘플들과는 달리 모든 악기들이 같은 공간에서 동시에 연주된 샘플이다. 즉, 5.1 채널 신호가 6개의 객체로 이루어져 있다고 생각할 수 있다. “TN”은 톤과 노이즈 신호를 이용한 인위적으로 구성된 샘플이다.
객관적인 실험는 세그멘탈 SNR(segmental SNR)로 평가 되었다.
| (21) |
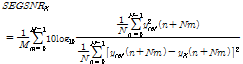
식에서 M과 N은 각각 프레임과 샘플 수를 의미한다. 아래 기입된 X는 출력 신호의 타입을 나타낸다. Table 2에 각 샘플에 대한 결과를 나타내었다.
표에서 Unquantized와 Quantized는 각각 다운믹스 신호의 양자화를 수행하지 않은 경우와 수행한 경우를 의미한다. 결과를 보면 ![]() 과
과 ![]() 의 차이는 크지 않는 것으로 나타났다. 하지만, 이는 전체 프레임에 대해서 평균을 낸 결과이며, 제안된 알고리듬은 각 주파수 밴드에 대해서 선택적으로 수행된다. Table 2의 가장 오른쪽 열에 임의의 주파수 밴드에 대해서 차이가 가장 컸던 결과를 함께 나타내었다. 실험 결과, 모든 신호에 대해서 대체로 큰 증가를 보이고 있는데, 이러한 증가는 제안된 알고리듬이 샘플 신호 곳곳에 적용된 구간들에 대해 음질 향상을 기대할 수 있는 결과로 생각될 수 있다.
의 차이는 크지 않는 것으로 나타났다. 하지만, 이는 전체 프레임에 대해서 평균을 낸 결과이며, 제안된 알고리듬은 각 주파수 밴드에 대해서 선택적으로 수행된다. Table 2의 가장 오른쪽 열에 임의의 주파수 밴드에 대해서 차이가 가장 컸던 결과를 함께 나타내었다. 실험 결과, 모든 신호에 대해서 대체로 큰 증가를 보이고 있는데, 이러한 증가는 제안된 알고리듬이 샘플 신호 곳곳에 적용된 구간들에 대해 음질 향상을 기대할 수 있는 결과로 생각될 수 있다.
SAOC는 제한된 전송률 및 파라메트릭 환경에서 부호화가 진행되어 복호화된 뒤에는 음질의 열화가 발생할 수 있다. SAOC의 Karaoke 모드는 여러 객체들 안에서 특정 객체를 추출하여 복원하는 것이므로, 음원 분리(source separation) 분야에서 추구하는 목적과 비슷하다. 그러므로 SAOC에서도 음원 분리할 때와 마찬가지로 음질의 왜곡, 간섭 및 뮤지컬 노이즈 등이 발생 할 수 있다.[9] 그러므로 본 논문에서는 제안된 알고리듬의 성능 향상을 확인하기 위하여 위에서 언급된 열화 및 전체적인 음질에 대해서 주관적 음질평가를 수행하였다. 총 8명의 숙련된 실험자가 참여하였으며, 모두 헤드폰을 착용하고 실험을 진행하였다. 각 청취자들에게 음질의 열화 및 전체적인 음질은 ITU-R BS.1284 권고안[10]에 따라 Table 3에 표시되어 있는 지표를 참조하도록 하였고, 음악 객체만으로 구성된 ![]() 신호를 기준으로 하여,
신호를 기준으로 하여, ![]() 와
와 ![]() 를 서로 비교하면서 평가하도록 하였다. 음질의 열화에 대해서 실험할 때에는 다른 부가적인 영향을 최소화하기 위해 양자화하지 않은 다운믹스 신호를 이용하였다. 실험 결과, 음악 음질의 왜곡 및 뮤지컬 노이즈의 경우 제안된 알고리듬을 적용하기 전과 후의 평가 결과가 크게 차이가 없어 영향을 덜 끼치는 요소들로 판단하여 본 논문에서는 제외하였고, 음질의 간섭 및 전체적인 음질에 대해서만 Fig. 6과 Fig. 7에 결과를 표시하였다.
를 서로 비교하면서 평가하도록 하였다. 음질의 열화에 대해서 실험할 때에는 다른 부가적인 영향을 최소화하기 위해 양자화하지 않은 다운믹스 신호를 이용하였다. 실험 결과, 음악 음질의 왜곡 및 뮤지컬 노이즈의 경우 제안된 알고리듬을 적용하기 전과 후의 평가 결과가 크게 차이가 없어 영향을 덜 끼치는 요소들로 판단하여 본 논문에서는 제외하였고, 음질의 간섭 및 전체적인 음질에 대해서만 Fig. 6과 Fig. 7에 결과를 표시하였다.
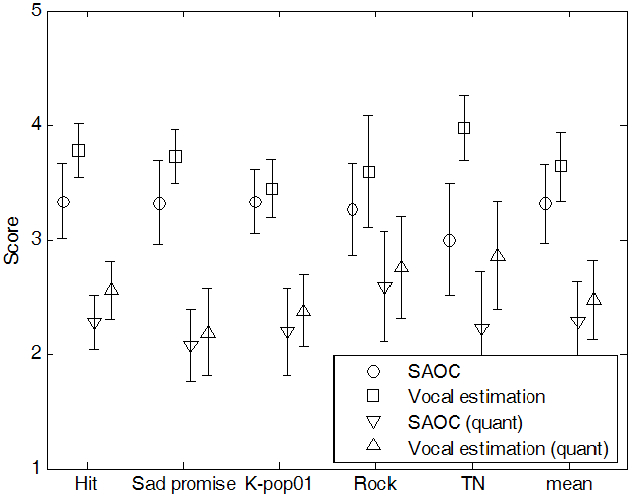
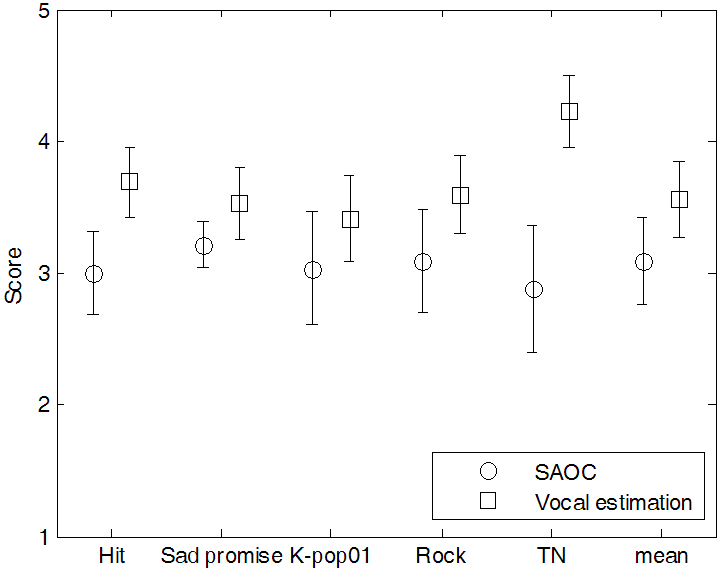
실험 결과의 평균을 계산할 때에는 인위적으로 만든 실험 샘플 “TN”을 포함시키지 않았다. 실험 결과를 보면 제안된 알고리듬을 이용하면 복호화된 신호 내에 존재하는 보컬 성분을 효과적으로 억제시킬 수 있음을 확인할 수 있다. 실험 샘플 “HIT”의 경우, 음악 성분에 비해서 보컬 성분의 에너지가 절대적으로 높은 구간들이 존재하여, SAOC의 Karaoke 모드로 복호화하여도 보컬성분의 에너지가 큰 구간들이 존재하지만, 이러한 경우에도 제안된 알고리듬을 이용하면 보컬 신호를 효과적으로 억제시켜 눈에 띄는 성능 향상을 확인할 수 있다.
제안된 알고리듬을 적용하기 위해서는 복호화단에서 파라메트릭 연산을 통해 추가로 보컬 신호(SAOC의 Solo 모드) 및 교차 예측을 수행하여야하며, 이로 인해 연산량이 증가된다. 그러나 파라메트릭스 스테레오(parametric stereo) 부호화의 연산량을 고려해보면, 파라메트릭 연산은 QMF의 연산과 비교하여 충분히 낮은 것을 알 수 있고,[11] 교차 예측의 차수 역시 높지 않기 때문에 제안된 알고리듬으로 인해 SAOC 복호화의 전체적인 연산량이 크게 증가되지 않는다고 판단된다.
V. 결 론
본 논문에서는 SAOC의 Karaoke 모드에서 복원된 신호 내에 존재하는 보컬 성분을 추정하여 억제시킴으로써 전체적인 음질을 향상시키는 알고리듬을 제안하였다. 잔여 보컬은 SAOC의 Karaoke 모드로 복원된 신호와 솔로 모드로 복원된 신호와의 교차 예측을 통해 추정이 가능하지만, 두 신호사이의 상관성이 매우 높아, 복원에 필요로 하는 음악성분까지도 함께 추정되어 제거될 수 있다. 이러한 열화를 방지하기 위해 보컬을 추정과정에서 예측을 억제하는 예측 방해 신호를 추가하였으며, 이 신호의 크기는 사람의 청각적인 마스킹 특성을 고려하여 음악적 음질의 열화가 최소화가 되도록 적응적으로 조절하였다. 객관적 및 주관적 음질 평가 결과 제안된 알고리듬은 Karaoke 신호 내에 남아있는 보컬 성분을 효과적으로 제거하여 음질을 향상시킬 수 있음을 확인하였다. 이러한 개선과정에서 제안된 알고리듬은 부호화단에서 어떤 추가 정보를 필요로 하지 않는 장점을 지닌다.
