

I. Introduction
II. ivectors for speaker verification
III. ivector extraction based on HMM-UBM
IV. Scoring
4.1 Scoring using dominant state information
4.2 Feature level fusion
4.3 Score-level fusion
V. Experiments
5.1 Experimental condition
5.2 Experimental result
VI. Conclusion
I. Introduction
Recently, accuracy of text-independent speaker verifica-tion has been significantly improved by the i-vector extraction paradigm with probabilistic linear discriminant analysis.[1,2] The i-vector approach in total variability space first introduced in[1] It has been considered as the state of the art in speaker verification systems. It is originated in JFA framework that consists of defining two distinct spaces: a speaker and a channel space.
A fundamental assumption of the approach is that the high dimensional GMM supervector of speech utterance can be represented by a speaker and a channel subspace based Universal Background Model (UBM). Therefore, obtaining a UBM is the first step of text-independent speaker verification. The modeling technique of UBM is based on GMM that is widely used in numerous areas of acoustic and speech processing. Although HMM is the method of choice for speech recognition,[3] for text-independent speaker verification, the model should embrace a wide range of phonetic variation rather than modeling temporal patterns of speech. Underscoring this fact, Reynolds[4] stated that there is no advantage in text-independent task using a more complex likelihood function, e.g. HMM, than GMM.
However, there have been some research efforts using more complex likelihood function like HMM. Using HMM in speaker verification was first introduced by Poritz.[5] Text-independent speaker recognition based on HMM was done by Naftali et al.[6] and Tomoko.[7] They used an ergodic HMM for speaker recognition and evaluated the performance with other algorithms. Recently, BenZeghiba[8] proposed User Customized Password Speaker Verification (UCP-SV) using multiple reference and background models. Because his or her own password is chosen by customer without any lexical constraints, the UCP-SV has similar freedom of input speech utterance with text-independent speaker recognition. BenZeghiba’s team used a combined HMM/GMM approach with background HMM models and has shown better performance than that of the GMM-UBM baseline. R. Gajsek et al.[9] proposed a speaker state recognition system using a HMM-UBM based method. It shows superior results than the standard scheme of adapting GMM-UBM in both the emotion recognition task and the alcohol detection task.
By recognizing the effectiveness of capturing various characteristics of an individual speaker by the HMM-UBM, we propose to apply the HMM-UBM based i-vector feature for text-independent speaker verification system. Ergodic HMM is used for estimating UBM so that the individual speaker’s characteristic is fully represented. Since an HMM has more than 1 state, several i-vectors can be extracted from GMM supervectors corresponding to each state. Using the dominant state information of test speech utterances with HMM-UBM, the score can be measured by distance between target and test i-vectors. The performance is evaluated with the i-vector baseline and other fusion rules for integrating i-vectors.
The outline of the paper is as follows. First, we describe the baseline i-vector for speaker verification briefly at section II. Section III and IV show the proposed i-vectors based text-independent speaker verification system and the scoring method. Section V presents experimental results and section 6 concludes this paper.
II. i─vectors for speaker verification
In classical Joint Factor Analysis (JFA)[10] a speaker utterance is represented by a supervector that consists of additive components from a speaker and a channel/session subspace. But in total variability perspective, a speaker utterance can be defined by both speaker and channel variability in a single space, i.e total variability space[1] as Eq.(1).
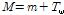 , (1)
, (1)
where supervector M represents the speaker utterance, m denotes the speaker and channel independent supervector, i.e UBM supervector, T is a total variability matrix that is rectangular matrix of low rank and ω is total variability factor. We refer this factor as i-vector.
Consider a feature sequence of L frames y = {y1,y2,…yL}. The GMM-UBM model λ = {wc, mc, Σc}, c = 1,...,C consists of C mixture components in a feature dimension F. For estimating the i-vector, the first step is extracting the zeroth and centered first order Baum-Welch statistics using the UBM as
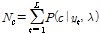 , (2)
, (2)
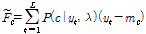 , (3)
, (3)
where c = 1,…,C Gaussian component index, P(c|yt,λ) is the posteriori probability of mixture component c generating the vector yt on UBM λ. mc is the mean of the UBM mixture component c. Using these statistics and total variability matrix T, we can get the i-vector as follows
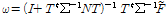 , (4)
, (4)
where N is a diagonal matrix of dimension CF × CF whose diagonal block is NcI, c = 1,...,C and Σ is a diagonal covariance matrix of dimesion CF×CF estimated during a factor analysis training.[11]
III. i─vector extraction based on HMM-UBM
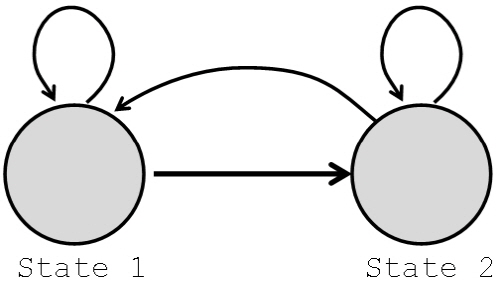
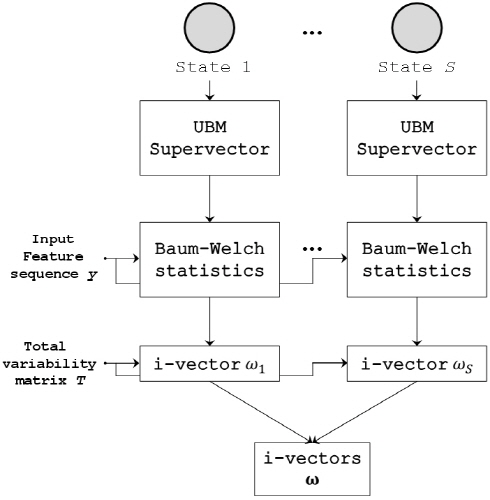
The speaker and channel independent supervector m is estimated by GMM-UBM essentially by means of i-vector extraction. We propose to change “GMM-UBM” to “HMM- UBM” for speaker and channel independent supervector. An ergodic HMM model is employed such that all possible transitions between states are allowed for estimating the UBM as in Fig. 1 shown below as an example when there are two states. An ergodic HMM automatically forms broad phonetic classes corresponding to each state.[5,7] Hence, speech segment can be classified into one of the broad phonetic categories corresponding to the HMM states.
Consider S states in an ergodic HMM. For each state, there is a GMM λs , s = 1,…S that represents the automatically classified phonetic categories as follows.
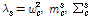 . (5)
. (5)
Hence, Eq.(1) can be expressed as follows:
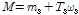 , (6)
, (6)
where ms represents speaker and channel independent and phonetic category dependent supervectors. Ts is the total variability matrix for phonetic category s, and ωs is the i-vector for phonetic category s. Then, we can have i-vectors ω for each state as described below.
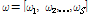 . (7)
. (7)
For each state, there is UBM supervector for calculating the Baum-Welch statistics with input feature sequence y. Next, from Eq.(4) we can get the phonetic category dependent i-vector ωs corresponding each state, i.e phonetic category.
IV. Scoring
This section describes scoring method for text-independent speaker recognizer using i-vectors. We proposed cosine distance scoring of i-vectors using dominant state informa-tion. In addition, we present general fusion rules for comparing performance with a baseline and the proposed scoring method.
4.1 Scoring using dominant state information
HMM-UBM essentially contains state transition probabilities unlike the GMM-UBM that has no state transition probability. Consider a state sequence of L frames q = {q1, q2,…, qL}. To find the most likely state sequence Q, it is needed to define the best score function along the path q at time t as
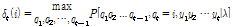 . (8)
. (8)
Using this best score function δt, we can find the most likely state sequence Q of input speech utterance based on Viterbi algorithm and HMM-UBM parameters.[12] In other words, the phonetic category of input speech utterance can be estimated frame by frame. Using this state sequence information, the dominant phonetic category of an input speech utterance can be determined by counting category index frame by frame. Then, the state index that appeared most is set as the dominant state information D. Finally, using this dominant state information D, the score of input utterance can be calculated as Eq.(9).
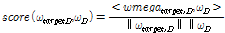 , (9)
, (9)
where ω target, D is target i-vector from state D.
4.2 Feature level fusion
In feature level fusion, the normalized i-vectors for each state is simply concatenated into a vector as follows.
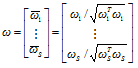 , (10)
, (10)
where ωs is i-vector from the HMM state S as Fig. 2. Both i-vector of a target and a test speech utterances should be done with Eq.(10). Using this concatenated ω, we calculate the Cosine Distance Score (CDS).
4.3 Score-level fusion
In score-level fusion, test speech utterance is scored with each phonetic category. In this paper, each i-vector calculated CDS using UBMs of each state s. So each of the i-vector extraction system acts as an independent speaker recognizer. Finally, scores were summed.
V. Experiments
5.1 Experimental condition
Experiments were conducted on the core task of NIST 2008 Speaker Recognition Evaluation (SRE), namely short2-short3, with common condition 7 (telephone-telephone- English) for female only. Both GMM-UBM and HMM- UBM was trained on telephone utterances selected from NIST2005 and 2006 SRE database with female gender dependent 1024 Gaussian mixture and diagonal-covariance matrices. For HMM-UBM, we use ergodic HMM that consist of 2 states. Our experiment operated on 13-dimensional MFCC feature extracted using 25-ms Hamming window. We apply feature warping to 13 dimensional feature vector on 3 seconds length sliding window.[13] Then delta and acceleration coefficients were appended to produce total 39-dimentioanl feature vectors. i-vector was extracted using 400 dimensional subspace matrix T that was trained with same database as UBM. All i-vector are normalized by whitening and scaling the length of each i-vector to a unit length.[14] The dimensionality of i-vectors is further reduced to 250 by Linear Discriminant Anlysis (LDA). LDA transform matrix were estimated using same data bases as training UBM for each states s of HMM-UBM.
5.2 Experimental result
The result of the baseline, proposed and other fusion rule method are shown as table 1. The three indices, Equal Error Rate (EER), Detection Cost Function (DCF) 08 and DCF10, of performance were measured. The DCF008 and DCF10 are defined in the NIST SRE plan of 2008 and 2010. The baseline system evaluated with GMM-UBM based i-vector extraction scheme. All three proposed, DSI, feature fusion and score fusion system evaluated with HMM-UBM based i-vector extraction scheme via three scoring ways as described at chapter 4. DSI means system scoring using dominant state information.
From the result, it is apparent that the proposed systems shows the better performance than baseline. In other words, speech segment can be classified into one of the broad phonetic categories corresponding to the HMM states and shows better performance than using only one phonetic category such as GMM-UBM based baseline system. Especially, the proposed system with DSI shows best performance than other system. It shows improved perfor-mance in all three evaluation metrics than other systems.
VI. Conclusion
In this paper, we proposed i-vectors extraction based on dominant state information of HMM-UBM. For validating the performance of proposed algorithms, the experiments were conducted using NIST 2008 SRE database. Through the experimental evaluation, we found the performance improvement in EER and DCF when using proposed i-vectors extraction. Scoring methods were used in three ways. Among them, using dominant state information of HMM-UBM shows best performance in speaker verification. From this result, we developed more robust speaker verification system with utilizing HMM-UBM and its dominant state information.
