

I. 서 론
II. 중첩음향이벤트 검출 시스템
2.1 음향사전 훈련 방법
2.1.1 비음수 행렬 분해
2.1.2 Spherical K-Means (SKM)
2.1.3 비음수 K-SVD
2.2 신호분리 및 최종 검출 방법
III. 실험 결과
IV. 결 론
I. 서 론
최근 주성분 분석 sparse coding, 비음수 행렬 분해 등 행렬 분해 기법을 이용한 사전 훈련에 관한 많은 연구가 진행되고 있다.[1] 이러한 방식을 이용하여 입력 행렬데이터로부터 사전(dictionary)과 크기(gain)로 분해한다. 특히, 이 중 비음수 행렬 분해 기법은 음향사전과 크기의 곱을 통해 재구성된 신호와 원신호의 평균자승오차(Mean Squared Error, MSE)가 작고 구현과 해석의 용이성으로 중첩음향이벤트 검출에 널리 이용되고 있다.[2,3]
비음수 행렬 분해는 비음수 제약조건을 이용하여 주어진 비음수 데이터 행렬을 두 개의 기저행렬과 부호화 행렬의 곱으로 근사화 하는 방법이다.[4] 비음수 행렬 분해 기반의 중첩음향검출은 각 단일음향을 비음수 행렬 분해 기법을 이용하여 사전을 구하고, 이를 이용하여 중첩음향을 단일음향으로 분리한다.[5] 하지만 비음수 행렬 분해 기반의 사전 획득은 비음수 행렬 분해의 고유한 특성인 부분기반표현(part-based representation)으로 인해 하나의 음향 이벤트를 구성하는 기저벡터의 파편화 현상이 발생하는 문제가 발생한다.
본 논문에서는 기저벡터의 파편화 현상 문제를 해결하기 위하여 전체기반 표현인 SKM(Spherical K- Means)와 K-SVD를 이용하여 음향사전을 훈련하고, 기존의 비음수 행렬 분해 기법을 이용하여 크기를 획득하는 방식을 이용한 중첩음향이벤트 검출을 다룬다.[6,7]
본 논문은 II장에서 중첩음향이벤트 검출을 위한 시스템을 제안하고, 기존방법인 비음수 행렬 분해와 SKM, 그리고 K-Means를 일반화 시킨 K-SVD를 이용하여 사전을 생성하는 방법을 설명한다. 또한, 생성된 사전을 이용하여 신호분리 및 최종 검출방법을 설명한다. III장에서는 실험 데이터와 실험 결과에 대한 분석 및 고찰을 다루며, 마지막으로 IV장에서는 결론으로 구성하였다.
II. 중첩음향이벤트 검출 시스템
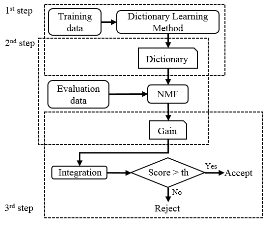
Fig. 1은 본 논문에서 제안하는 중첩음향이벤트 검출 시스템의 순서도를 나타내며 총 3단계의 과정으로 구성되어 있다. 1단계는 음향사전 훈련 과정으로 기존의 중첩음향이벤트 검출을 위해 많이 활용되는 비음수 행렬 분해 및 본 논문에서 제안하는 전체기반 표현기법인 SKM과 K-SVD을 적용하여 음향사전을 획득한다. 음향사전을 구성하는 각 기저벡터의 합산값이 1이 되도록 하는 정규화 과정을 거쳐, 기저벡터는 데이터의 형태성분만을 반영하도록 한다. 2단계는 입력신호에서 각 음향이벤트 구성성분을 계산하는 과정으로, 1단계에서 획득한 사전을 고정시키고 비음수 행렬 분해를 이용하여 크기성분만 업데이트 한다. 3단계에서는 각 음향이벤트 발생구간을 최종 검출하는 과정으로 각 이벤트 기저벡터별 크기성분의 합산값이 임계값 이상의 값을 보이는 구간을 음향이벤트가 검출된 것으로 판단한다. 아래에서는 각 단계별 과정을 구체적으로 기술한다.
2.1 음향사전 훈련 방법
행렬 분해기법에 의한 사전 훈련은 행렬형태로 주어진 데이터에 내포된 구조적인 특성을 비교사 방식(unsupervised learning)으로 표현하는 방법이며, 일반적으로 Eq.(1)과 같이 나타낼 수 있다.
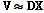 , (1)
, (1)
여기에서 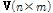 는 데이터 행렬,
는 데이터 행렬, 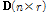 는 기저벡터의 집합으로 구성된 사전,
는 기저벡터의 집합으로 구성된 사전, 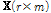 는 각 기저벡터의 크기성분을 나타낸다. 음향신호의 경우 Short Time Fourier Transform(STFT) 통해 스펙트로그램을 생성하며,
는 각 기저벡터의 크기성분을 나타낸다. 음향신호의 경우 Short Time Fourier Transform(STFT) 통해 스펙트로그램을 생성하며, 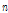 은 FFT bin 개수,
은 FFT bin 개수, 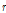 은 기저 개수,
은 기저 개수, 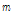 은 프레임 개수를 나타낸다. 사전 훈련 방법은
은 프레임 개수를 나타낸다. 사전 훈련 방법은 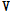 와 이를 재구성하는
와 이를 재구성하는 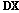 로 정의되는 목적함수를 최소화 하는 방식으로 이루어진다. 이때 각 사전 훈련 기법의 목적함수 및 제약조건의 차이로 인해 다른 형태의 사전을 획득하게 된다. 본 논문에서는 아래와 같이 3가지 사전훈련 방식을 고려한다.
로 정의되는 목적함수를 최소화 하는 방식으로 이루어진다. 이때 각 사전 훈련 기법의 목적함수 및 제약조건의 차이로 인해 다른 형태의 사전을 획득하게 된다. 본 논문에서는 아래와 같이 3가지 사전훈련 방식을 고려한다.
2.1.1 비음수 행렬 분해
비음수 행렬 분해 기법은 주어진 데이터 행렬 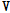 와 분해되는 두 개의 행렬
와 분해되는 두 개의 행렬 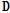 ,
, 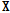 의 구성성분이 모두 비음수라는 제약조건을 가진다. 목적함수는 일반적으로 유클리디안 거리 또는 generalized Kullback–Leibler divergence를 사용하며 후자 목적함수를 사용하는 경우 목적함수는 Eq.(2)와 같이 정의된다.
의 구성성분이 모두 비음수라는 제약조건을 가진다. 목적함수는 일반적으로 유클리디안 거리 또는 generalized Kullback–Leibler divergence를 사용하며 후자 목적함수를 사용하는 경우 목적함수는 Eq.(2)와 같이 정의된다.
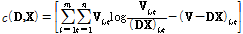 . (2)
. (2)
상기 목적함수를 최소화하기 위해 Eqs.(3)과 (4)와 같이 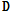 와
와 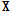 를 번갈아 가며 업데이트를 적용하고, 각각의
를 번갈아 가며 업데이트를 적용하고, 각각의 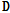 와
와 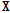 가 수렴할 때까지 반복한다.
가 수렴할 때까지 반복한다.
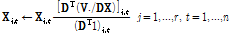 , (3)
, (3)
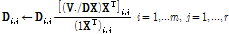 , (4)
, (4)
수렴한 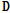 와
와 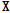 를 곱하면 Eq.(1)을 만족하고, 여기서 수렴한
를 곱하면 Eq.(1)을 만족하고, 여기서 수렴한 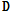 를 음향사전으로 이용하게 된다.
를 음향사전으로 이용하게 된다.
2.1.2 Spherical K-Means (SKM)
K-means 기법은 유사한 특성을 갖는 데이터가 서로 근접하여 위치한다는 가정에 근거하여, 모든 데이터를 K개의 대표 값으로 근사화 하는 방식으로 주어진 데이터의 군집화 작업에 주로 사용된다. 각 입력데이터는 사전 정의된 거리척도에 의해 가장 가까운 코드벡터로 표현된다. 각 입력데이터 마다 평균자승오차를 최소화하고 이를 수식으로 표현하면 Eq.(5)와 같다.
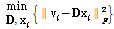 subject to
subject to 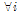 ,
,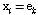 for some
for some  ,
,여기서 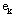 는
는  번째 열백터를 제외한 모든 성분이 0을 갖는 단위벡터를 의미한다. 입력데이터
번째 열백터를 제외한 모든 성분이 0을 갖는 단위벡터를 의미한다. 입력데이터 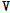 에 대하여 임의의 사전
에 대하여 임의의 사전 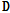 가 주어졌을 때 최근접 이웃 방식에 의하여 대표벡터
가 주어졌을 때 최근접 이웃 방식에 의하여 대표벡터 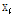 를 구하고, 이 대표벡터
를 구하고, 이 대표벡터 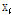 를 통하여 각 입력데이터 벡터
를 통하여 각 입력데이터 벡터 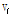 에 더욱 적합한 사전
에 더욱 적합한 사전 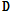 로 업데이트를 반복한다.
로 업데이트를 반복한다.
이때 두 데이터 샘플간의 거리척도가 코사인 유사도로 주어지는 경우 SKM이 된다. SKM의 특징은 각 데이터 샘플의 크기를 단위벡터로 표현(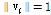 )하고 벡터의 방향을 중요시 한다. 예를 들어, 스펙트로그램으로 표현한 입력데이터에 SKM을 적용하였을 때 각 프레임에서의 에너지는 반영되지 않고 스펙트럼의 형태정보만 나타난다. 각 음향의 크기를 일반화 해줌으로써 음향의 크기는 반영되지 않고 스펙트럼의 형태정보만 나타내는 전체기반 표현으로 사전을 생성할 수 있다.
)하고 벡터의 방향을 중요시 한다. 예를 들어, 스펙트로그램으로 표현한 입력데이터에 SKM을 적용하였을 때 각 프레임에서의 에너지는 반영되지 않고 스펙트럼의 형태정보만 나타난다. 각 음향의 크기를 일반화 해줌으로써 음향의 크기는 반영되지 않고 스펙트럼의 형태정보만 나타내는 전체기반 표현으로 사전을 생성할 수 있다.
2.1.3 비음수 K-SVD
K-means가 주어진 샘플값을 하나의 기저벡터로 대체하여 표현하는 반면, K-SVD는 기저벡터들의 선형결합으로 표현한다는 점에서 K-Means를 일반화 시킨 알고리즘으로 볼 수 있다.
비음수 행렬 분해와 K-means 방식과 마찬가지로 K-SVD 또한 사전 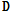 와 크기
와 크기 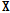 를 번갈아가며 업데이트 한다. 각 반복단계는 sparse coding으로 표현 벡터
를 번갈아가며 업데이트 한다. 각 반복단계는 sparse coding으로 표현 벡터 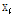 를 구하는 단계와 사전
를 구하는 단계와 사전 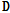 를 업데이트하는 두 단계로 나누어 반복적으로 진행된다.
를 업데이트하는 두 단계로 나누어 반복적으로 진행된다.
Sparse coding 단계에서는 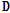 가 고정되었다고 가정하고, pursuit 알고리즘을 이용하여 표현벡터
가 고정되었다고 가정하고, pursuit 알고리즘을 이용하여 표현벡터 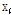 를 구한다. 이를 수식으로 표현하면
를 구한다. 이를 수식으로 표현하면
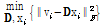 subject to
subject to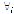 ,
,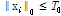 , (6)
, (6)
여기서 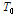 는 sparsity를 의미하며 주어진 데이터를 구성하기 위해 사용될 수 있는 기저벡터의 개수를 제한하는 역할을 한다.
는 sparsity를 의미하며 주어진 데이터를 구성하기 위해 사용될 수 있는 기저벡터의 개수를 제한하는 역할을 한다.
사전 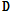 의 업데이트 단계에서는
의 업데이트 단계에서는 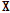 와
와 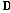 가 고정되었다고 가정하고, 오차를 최소화하기 위하여 목적함수를 아래 수식으로 다시 표현한다.
가 고정되었다고 가정하고, 오차를 최소화하기 위하여 목적함수를 아래 수식으로 다시 표현한다.
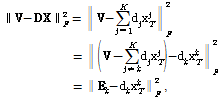
여기서 K는 기저 개수이고, 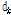 는 사전
는 사전 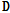 의 k번째 열벡터를 뜻하며,
의 k번째 열벡터를 뜻하며, 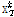 는
는 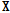 의 행벡터를 의미한다. 또한,
의 행벡터를 의미한다. 또한, 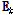 는 k번째를 제외한 입력데이터와 재구성한
는 k번째를 제외한 입력데이터와 재구성한 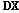 의 오차를 나타낸다. 파생된
의 오차를 나타낸다. 파생된 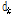 와
와 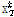 는 SVD를 이용하여
는 SVD를 이용하여 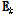 를 근사화한다. 비음수 K-SVD에서는 오차행렬
를 근사화한다. 비음수 K-SVD에서는 오차행렬 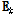 의 음수값을 0으로 설정하고, SVD를 적용하면 업데이트 된 모든 요소들은 양수의 값을 갖게 된다. 본 논문에서는 sparsity
의 음수값을 0으로 설정하고, SVD를 적용하면 업데이트 된 모든 요소들은 양수의 값을 갖게 된다. 본 논문에서는 sparsity 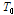 를 1로 설정함으로써 기저행렬이 전체기반 표현으로 나타난다. 이는 사전과 크기로 재구성한 행렬이 입력된 데이터 행렬과 비교했을 때 SKM보다 더욱 정확한 결과로 나타나는 shape- gain VQ의 결과를 의미한다.[8] 예를 들어, 음향신호에서 SKM은 방향정보만 나타내기 때문에 묵음도 방향정보를 갖는 사전으로 표현되지만, shape-gain VQ는 묵음이 적게 표현되거나 표현되지 않는다.
를 1로 설정함으로써 기저행렬이 전체기반 표현으로 나타난다. 이는 사전과 크기로 재구성한 행렬이 입력된 데이터 행렬과 비교했을 때 SKM보다 더욱 정확한 결과로 나타나는 shape- gain VQ의 결과를 의미한다.[8] 예를 들어, 음향신호에서 SKM은 방향정보만 나타내기 때문에 묵음도 방향정보를 갖는 사전으로 표현되지만, shape-gain VQ는 묵음이 적게 표현되거나 표현되지 않는다.
2.2 신호분리 및 최종 검출 방법
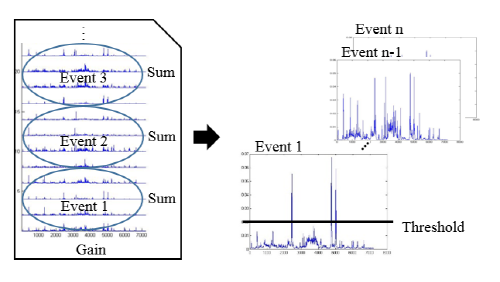
각각의 이벤트에 해당하는 단일음향인 훈련데이터로부터 앞에서 언급한 방법으로 음향사전을 획득하고 이를 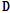 로 고정시킨 뒤, 테스트 데이터인 중첩음향으로부터 비음수 행렬 분해를 이용하여 각 이벤트마다 크기성분을 계산한다. Fig. 2는 크기로부터 음향이벤트 검출 방법을 나타내고 있다. 크기는 이이벤트별로 사전에 해당하는 열벡터 개수만큼 생성되고, 이를 합산한 값을 최종검출에 이용한다. 이는 시간경과에 따라 프레임에서 해당 이벤트가 발생한 경우 높은 값을 나타내고 있다. 각 이벤트에서 구한 크기가 실험을 통해 설정한 임계값을 넘으면 이벤트가 검출된 것으로 간주한다.
로 고정시킨 뒤, 테스트 데이터인 중첩음향으로부터 비음수 행렬 분해를 이용하여 각 이벤트마다 크기성분을 계산한다. Fig. 2는 크기로부터 음향이벤트 검출 방법을 나타내고 있다. 크기는 이이벤트별로 사전에 해당하는 열벡터 개수만큼 생성되고, 이를 합산한 값을 최종검출에 이용한다. 이는 시간경과에 따라 프레임에서 해당 이벤트가 발생한 경우 높은 값을 나타내고 있다. 각 이벤트에서 구한 크기가 실험을 통해 설정한 임계값을 넘으면 이벤트가 검출된 것으로 간주한다.
III. 실험 결과
중첩음향검출 실험에 사용한 DB는 Audio and Acoustic Signal Processing(AASP) Challenges에서 제공되는 DB를 사용하였다.[9] 실내에서 발생하는 16가지 음향이벤트로 구성되어 있으며 종류는 Table 1과 같다.
훈련용 DB는 16종류의 단일 음향이벤트로 구성되어 있으며, 각 음향이벤트 당 20개의 샘플로 구성되어 있다. 테스트 DB는 16종류의 단일음향이 여러 시간대에 발생하여 중첩이 발생하는 음향이며, 3가지 SNR (-6, 0, 6 dB)의 배경잡음이 혼합되어 있다. 모든 DB의 샘플링레이트는 16 kHz, 16 bit, 모노채널 포맷이다. 검출결과는 DB에서 제공된 이벤트가 발생한 시간과 제안한 방법을 통해 구한 결과를 비교하였다. 각 성능결과는 precision과 recall의 조화평균인 F-score를 이용하여 나타내었다.
훈련용 DB와 테스트 DB는 25 ms 윈도우 크기의 STFT으로 사용하고, 윈도우 크기의 50 %씩 중첩하며 진행하여 스펙트럼을 생성한다. 훈련용 DB는 16종류의 단일 음향이벤트에 대하여 기저개수를 20개로 선정하고 비음수 행렬 분해, SKM, K-SVD을 이용하여 사전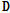 를 구성하였다. 이
를 구성하였다. 이 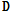 를 고정시키고 비음수 행렬 분해를 이용하여 부호화 행렬의
를 고정시키고 비음수 행렬 분해를 이용하여 부호화 행렬의 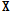 값을 구한 후, 실험을 통해 선정한 임계값을 넘으면 이벤트가 검출된 것으로 간주하였다.
값을 구한 후, 실험을 통해 선정한 임계값을 넘으면 이벤트가 검출된 것으로 간주하였다.
Table 1. Sixteen classes of acoustic event. | |||
alert | clear throat | cough | door slam |
drawer | keyboard | keys | knock |
laughter | mouse | page turn | pen drop |
phone | printer | speech | switch |
실험은 단일음향이벤트 훈련데이터에 기본 비음수 행렬 분해와 SKM, K-SVD를 적용하여 획득한 사전 차이에 따른 중첩이벤트검출에 대한 성능비교를 수행하였다. 또한, SNR 차이에 따른 실험도 진행하였다. 실험 결과는 Table 2에 제시된 바와 같이 K-SVD, SKM, 비음수 행렬 분해 방식 순으로 높은 성능이 나오는 것을 확인할 수 있다.
비음수 행렬 분해 방식이 가장 낮은 성능을 나타내는 이유는 비음수 행렬 분해의 고유한 특성인 부분기반표현(part-based representation)으로 인해 하나의 음향 이벤트를 구성 하는 사전(dictionary)의 파편화 현상이 발생하고, 다른 음향이벤트와 공유하는 사전으로 인하여 결과적으로 분리, 검출 성능의 저하 문제가 발생하기 때문이다.
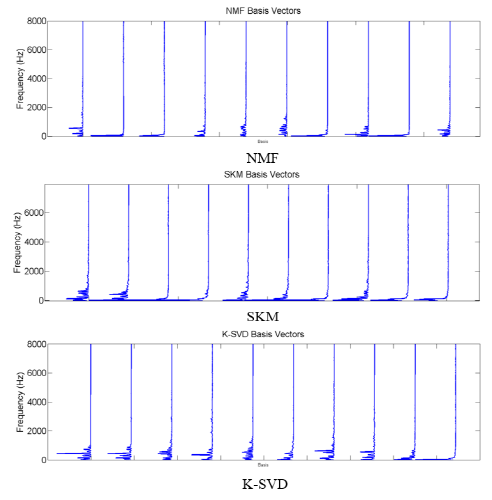
Fig. 3은 각 알고리즘을 적용하여 획득한 음향사전을 나타낸다. 테스트 샘플은 훈련용 DB 중 speech를 사용하였으며, 모든 알고리즘에 대하여 음향사전을 구성하는 기저개수는 10개로 설정하였다. 획득한 음향사전에 대하여 Fig. 2의 2단계 방법을 적용하여 음성 기저벡터의 크기성분의 합산값을 구하고 내림차순으로 왼쪽에서 오른쪽으로 나타내었다. 즉, 에너지가 크고 발생빈도가 높아 입력 데이터를 구성하는 기여도가 높은 순으로 배열된 결과이다.
Fig. 3에 보듯이 K-SVD 방법으로 획득한 음향사전의 경우 2번 기저벡터는 주어진 프레임에 대한 음성의 하모닉스를 온전히 표현하고 있는 반면 비음수 행렬 분해 음향사전의 경우 하모닉스를 표현하고 있는 스펙트럼이 1번, 5번 기저벡터로 파편화 되는 현상을 확인할 수 있다.
전체기반 표현인 SKM 방식의 경우 부분기반표현 기법인 비음수 행렬 분해에 비하여 높은 성능을 보이지만 몇 가지 한계점을 보인다. 에너지가 가장 높은 첫 번째 기저벡터의 경우 하모닉스 구조가 많이 뭉개진 것을 확인할 수 있다. 즉 하나의 군집에 서로 다른 형태의 데이터가 다수 포함된 것으로 해석할 수 있다. 입력값의 크기에 따른 의존성을 제거하기 위해 코사인 유사도를 사용하는 과정에서 모든 데이터샘플을 단위구(unit sphere)에 투영시키는 변환이 포함되며, 변환된 영역에서 군집화가 수행된다. 이로 인해 이상점(outlier)에 취약한 특성을 보이며 재구성 오차가 비교적 크게 나타난다. 또한 비음수 행렬 분해와 K-SVD 방식에서는 생성되지 않았던 무성음과 마이크 잡음만 존재하는 묵음구간이 Fig. 3의 SKM에서 2번째 기저벡터로 나타남을 확인할 수 있다. 이러한 한계점에도 불구하고 전체기반 표현 방식이 부분기반표현의 한계를 만회한 것으로 해석할 수 있다.
K-SVD의 경우 원신호 영역에서 수행되므로 변환된 영역에 따른 문제가 발생하지 않는다. 하지만 이러한 방식을 적용하기 위해 비음수 행렬 분해, SKM 방식보다 복잡하고 많은 연산량을 필요로 한다.
IV. 결 론
본 논문에서는 사전 획득 과정에서 부분기반표현으로 나타내는 비음수 행렬 분해와 전체기반표현으로 나타내는 SKM과 K-SVD를 이용하여 중첩음향이벤트 검출성능을 비교하였다. 비음수 행렬 분해를 이용하여 사전을 생성한 경우보다 SKM과 K-SVD를 이용한 경우가 SNR변화에 관계없이 향상된 성능을 보였으며, 이는 단일음향이벤트에 대한 사전 생성시 부분기반표현보다 전체기반표현인 경우가 음향의 특징을 더욱 잘 반영함을 확인할 수 있었다. 또한, sparse coding을 적용한 K-SVD를 이용하여 SKM의 사전에서 불필요한 성분을 줄여줌으로써 성능향상에 효과가 있음을 확인하였다.
