

I. 서 론
II. 지진 이벤트 분류 모델
III. 정규화 기법을 적용한 CNN 구조
3.1 정규화 기법
3.2 정규화 기법을 적용한 CNN 구조
IV. 모의실험
4.1 데이터 구성
4.2 실험 환경
4.3 입력 정규화에 따른 성능 분석
4.4 은닉 레이어 정규화에 따른 성능 분석
4.5 기타 정규화 결과 분석
V. 결 론
I. 서 론
전 세계 각 지역에서 지진은 현재까지도 다양한 규모로 꾸준히 발생하고 있다. 한반도의 경우 2000년도 이후 지진 발생 규모 및 횟수가 급격히 증가하고 있으며 최근 경주와 포항에서 발생한 규모 5.0 이상의 강진으로 인해 국내에서도 지진에 대한 관심이 증가하고 있다.
지진 이벤트 분류 문제는 시계열 데이터 분류 문제로서 입력되는 지진 신호 혹은 변환 공간에서 특징 정보를 추출한 후 문턱치 혹은 학습기반 결정 규칙을 통해 지진 이벤트를 분류한다. 최근에는 심층 학습을 기반한 지진 이벤트 분류 연구들이 다양하게 등장하고 있다. Perol et al.[1]은 10 s의 3채널 지진파 데이터를 사용하여 1-D 합성곱(Convolutional Neural Networks(CNN))과 비선형 변환 Rectified Linear Unit (ReLU)을 가진 8개의 합성곱 레이어를 사용하였다. 그가 사용한 ConvNetQuake 모델은 적은 파라미터로 지진 이벤트 분류에 가장 널리 알려진 모델이다. Ku et al.[2]는 ConvNetQuake 모델을 기반으로 국내 지진 데이터를 사용하여 윈도우 슬라이딩 방식으로 데이터를 대량 확보한 뒤 각 은닉 레이어에 attention 모듈을 추가한 결과 기존 모델보다 향상된 성능을 보였다. Mousavi et al.[3]는 지진 이벤트 분류를 시계열 정보가 아닌 시공간을 반영한 스펙트로그램으로 변환하여 2-D CNN으로 특징을 추출한 후 순환신경망(Recurrent Neural Net, RNN)과 완전 연결 레이어(Fully Connected Layer, FCN)을 적용한 모델을 제시하였다. Kim et al.[4]는 기존의 단일 입력이 아닌 다양한 변환 입력(스펙트로그램, recurrent plot, S-trannsform, 1D 파형)을 결합한 모델을 제시하여 지진 분류 성능을 향상 시켰다. 또한 Kim et al.[5]는 단일 관측소 입력 정보들을 이용한 지진 이벤트 분류/탐지 문제를 다중 관측소로 확장된 모델을 제안하였으며 실제 환경에서 발생할 수 있는 다양한 false alarm 문제들을 효과적으로 해결하였다.
다층의 레이어로 구성된 딥러닝 네트워크를 학습시키는 과정에서 흔히 직면하는 문제는 경사 폭발과 경사 소실이다. 경사 폭발 및 경사 소실은 경사값의 차별성이 사라짐으로써 학습의 흐름을 방해하게 된다. 이러한 경사 폭발 및 경사 소실의 문제는 활성화 함수, 초기화 설정, 낮은 학습률 등을 통해 해결하려는 시도가 있었다. Ioffe et al.[6]은 간접적인 해결책 보다 근본적인 일괄정규화방법을 통해 이 문제에 접근하였다. 네트워크의 레이어마다 입력 분포 특성이 달라지는 내부 공변량 변화를 막기 위해 일괄정규화는 각 레이어의 평균과 표준편차를 미니배치 학습을 통해 정규화하는 방법을 제안하였다. 일괄정규화와 더불어 다양한 정규화 기법들이 제안되어 다양한 문제를 위한 딥러닝 네트워크에 적용되어 성능 향상을 이루어내고 있다.[7]
본 논문에서는 딥러닝을 이용한 지진 이벤트 분류에서 다양한 정규화 기법들이 미치는 영향력을 분석한 후 효과적인 지진 이벤트 분류 모델을 제안한다. 딥러닝 기반 지진 이벤트 분류 모델은 Fig. 1과 같은 ConvNetQuake 모델을 백본망으로 삼고 있으며 백본망 모델은 정규화 기법이 적용되지 않은 형태로 딥러닝 모델이 구성되어 있다. 본 논문에서는 지진 이벤트 분류 성능 향상을 위해 다양한 정규화 기법들을 입력값 및 은닉 레이어에 적용시켰다. 정규화 기법은 입력분포 혹은 은닉 계층 분포를 일정하게 함으로써 학습 속도가 향상되면 분류 정확도도 개선할 수 있게 된다. 본 논문에서는 다양한 정규화 기법의 적용 뿐만 아니라 적용되는 은닉 계층에 따라 지진 이벤트 분류 성능이 어떻게 변화하는지를 분석하였다. 분석 결과를 토대로 본 논문에서는 지진 이벤트 분류에 효과적인 모델을 제안하였다.
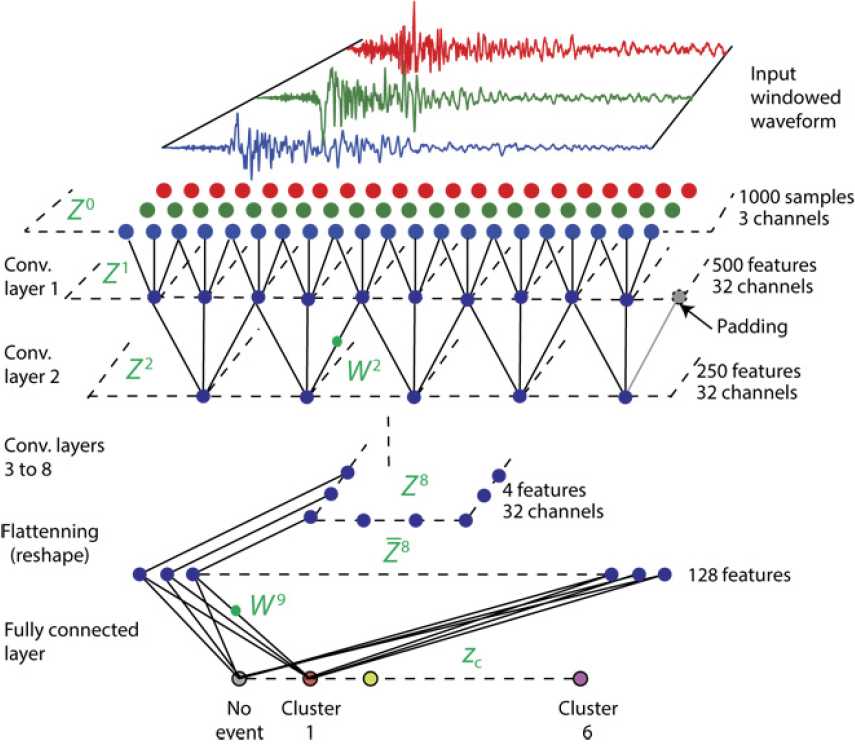
본 논문의 구성은 다음과 같다. 2장에서는 지진 이벤트 분류를 위한 백본망 네트워크 CNN 구조를 소개하였고 3장에서는 각각의 정규화 기법들에 관해 설명 및 정규화 기법을 적용한 CNN 구조를 설명하였다. 4장과 5장에서는 모의 실험결과 및 결론에 관해서 기술한다.
II. 지진 이벤트 분류 모델
본 논문에서는 Perol에 의해 제안된 ConvNet Quake를 백본망으로 이용한다. ConvNetQuake는 Fig. 1과 같이 CNN 기반의 네트워크로 구성되어 있다. 네트워크는 특징 추출 부분과 분류 부분으로 구성되어 있으며 특징 추출 부분에서 일반적인 딥러닝 모델에서 사용하는 일괄정규화와 같은 정규화 기법은 적용되지 않았다. 특징 추출 부분은 합성곱 레이어, 비선형 변환, 최대화 풀링 레이어의 연쇄 과정을 통해 이벤트 분류에 적합한 특징을 추출하고 있으며 추출된 특징은 완전연결층 및 소프트맥스 함수를 통해 지진 분류를 수행하고 있다. 입력은 미가공 3채널 1000샘플 데이터를 이용하고 있으며 합성곱 필터의 크기는 3 × 1, 개수는 32를 사용한다. 8개의 레이어를 통해 추출된 특징은 4 × 32의 특징이 추출되며 추출된 특징은 일렬화 변환 과정을 통해 128 차원 특징 벡터가 된다. 추출된 128 차원 특징 벡터는 완전 연결레이어와 소프트맥스 함수를 통해 지진 이벤트 발생 여부를 출력하게 된다. 백본망에서는 지진 이벤트 발생 클러스터를 5곳으로 설정하여 총출력 노드는 6개의 출력 노드를 가지고 있다.
III. 정규화 기법을 적용한 CNN 구조
3.1 정규화 기법
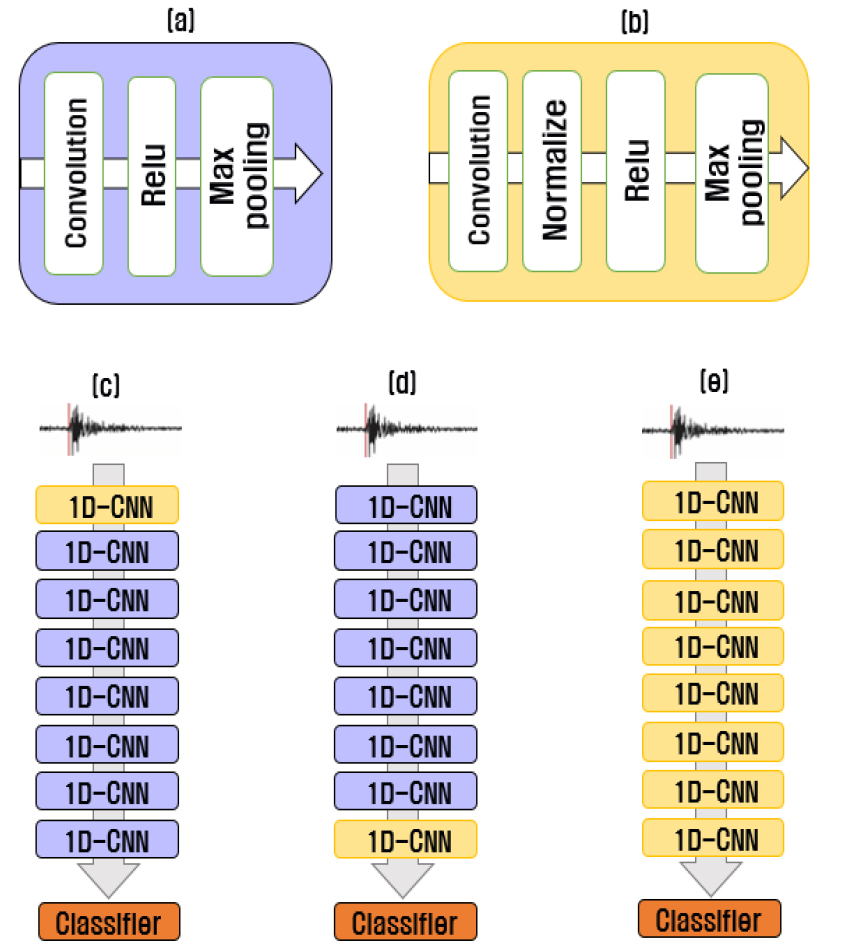
딥러닝 모델의 학습 및 성능 향상을 위해서는 일반적으로 입력데이터 값들을 정규화하는 과정과 딥러닝 은닉 레이어들 사이에서의 정규화 과정을 거치게 된다. Fig. 2와 같이 입력값을 정규화하지 않는 입력 데이터의 경우 학습에 많은 시간과 오차가 발생하게 된다. 그러나 입력 데이터를 정규화하게 되면 학습 속도 및 오차 감소의 효과를 얻게 된다. 여기서 은닉 레이어란 Fig. 3과 같이 신경망에서 입력에서 출력으로 가는 신경망의 가운데 레이어들을 의미한다. 본 연구에서는 입력 정규화는 Min-Max기법을 사용하여 전체 입력 데이터를 Eq. (1)과 같이 정규화하여 비교하였고 은닉 레이어들에 적용되는 정규화 기법은 Fig. 4와 같이 다양한 방식들이 제안되어 오고 있다. 회색 큐브는 미니배치의 탠서를 의미하며 파란색 부분은 각 정규화 기법이 적용되는 미니배치 데이터의 범위를 나타낸다.
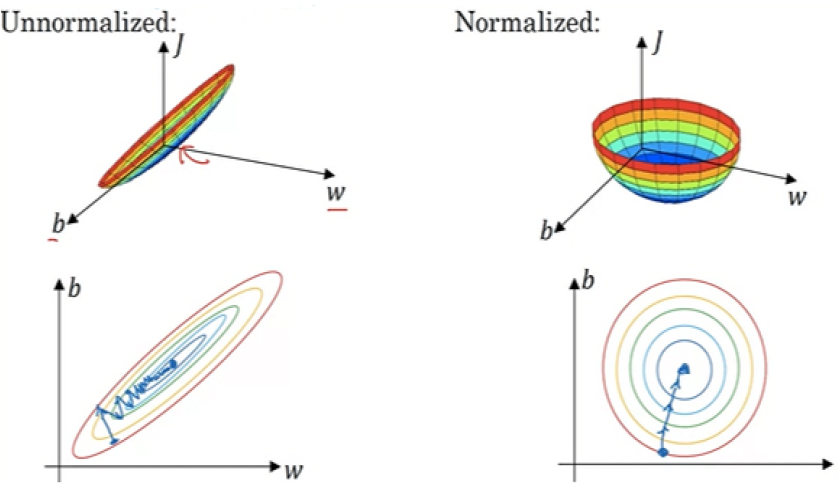
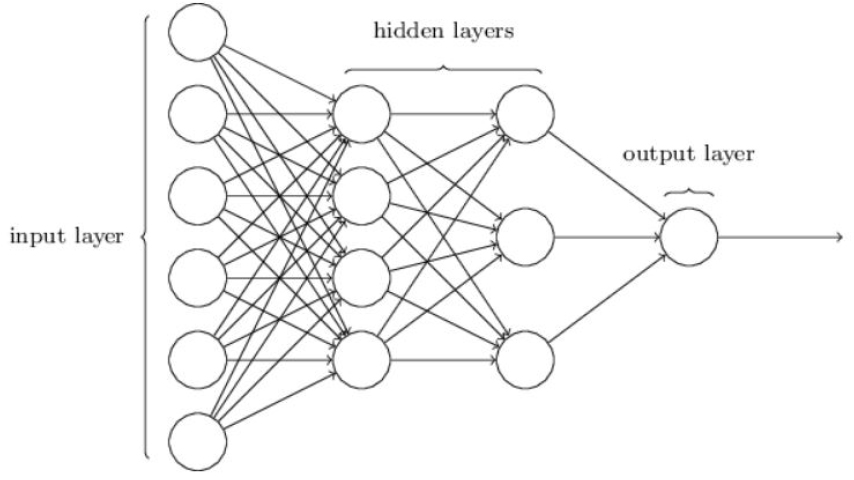

Fig. 4.
(Color available online) Normalization method (each subplot shows a feature map tensor with N batch, C channel, H*W spatial).[10]
1) 일괄 정규화(Batch Normalization)
일괄 정규화는 입력데이터 분포의 평균 및 분산을 정렬해주는 역할을 한다. 전체 입력데이터가 아닌 m개의 미니배치 집합 를 이용하여 데이터 분포의 평균 및 분산을 Eqs. (2), (3), (4)와 같이 정규화하게 된다.
이러한 단순 정규화 과정은 최적화와 무관하게 진행되기 때문에 특정 파라미터가 계속 커지는 상태로 정규화가 진행될 수 있다. 그래서 일괄정규화 과정에서는 신경망 안에 평균과 분산을 조정하는 과정을 포함해 학습하게 된다. Eq. (5)와 같이 벡터에 대한 크기과 방향을 감마(γ), 베타(β) 값을 통해 조정을 수행하게 된다.
여기서 이때 감마와 베타 값은 학습 가능한 변수이다. 이러한 일괄 정규화는 각 레이어마다 정규화하는 레이어를 두어 입력분포와 다른 분포가 나오지 않도록 유도한다.
2) 가중치 정규화(Weight Normlization)
Salimans et al.[8]은 기존의 일괄 정규화 기법은 미니배치 크기에 의존적인 성능을 나타내어 미니배치 크기가 작게 되면 분산의 영향을 받아 오히려 학습 결과가 저하되는 모습을 보이게 된다고 하였다. 가중치 정규화 기법은 이러한 문제를 해결하고자 제안된 기법으로 Eq. (6)과 같은 정규화 과정을 수행하며 구하고자 하는 가중치(w)를 다음과 같이 v와 g로 분리시킨다. 이때 v는 w벡터의 방향으로부터 norm을 분리시킨 후 g와 v를 경사하강법을 통하여 최적화한다.
Eq. (6)과 같이 이는 분산에 비해 평균은 큰 숫자일 가능성이 클 경우가 많다는 가설에서 비롯해 잡음을 최대한 줄이기 위하여 평균은 빼지만, 분산으로 나누지는 않는다. 또한, 가중치의 놈(norm)을 사용하여 기울기의 방향을 잡아줌으로써 데이터의 분포가 한쪽으로 치우치지 않게 도와준다.
3) 계층 정규화(Layer Normalization)
앞서 소개된 두 기법은 미니배치 크기만큼의 입력을 정규화하지만 Ba et al.[9]에서 소개된 계층 정규화의 특징은 동일한 은닉 계층의 뉴런 간의 입력을 정규화한다는 것이다. 따라서 Fig. 5와 같이 미니배치 간의 의존관계가 없이 미니배치의 크기를 뉴런 개수로 변경하여 입력 스케일이 다양한 데이터에 더욱 강건한 학습 능률을 보인다.
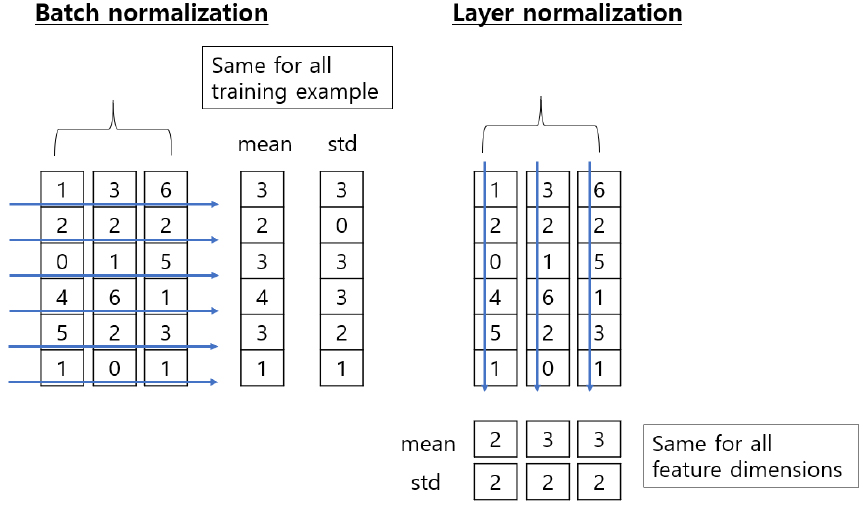
일괄 정규화는 배치 차원에서 각 입력 데이터들의 평균과 분산을 구해서 정규화한다고 하면 계층 정규화는 입력 특징 차원에서 평균과 분산을 구해 정규화하게 된다. Eq. (7)과 같이 번째 데이터의 j개의 특징들을 모아 정규화하게 된다. 이때 은 분모가 0인 경우를 막기 위하여 추가하는 상수이다. Eq. (4)과 달리 평균과 분산이 배치에서 계산하는 것이 아닌 각 계층에서 독립적으로 계산된다.
4) 그룹 정규화(Group Normalization)
Wu et al.[10]가 발표한 논문에서는 일괄 정규화에서 구하는 평균과 분산이 데이터셋 전체를 대표하지 못하는 문제를 제기하여 기존 계층 정규화와 가중치 정규화와 같은 미니배치 크기에 독립적인 모델들과 다른 그룹 정규화 모델을 제안했다. 일괄 정규화는 배치의 평균 및 표준편차를 계산하여 전체 계층의 가우시안 분포를 생성하지만, 그룹 정규화는 미니배치의 데이터 하나씩 계산하여 각각 개별 데이터의 분포를 사용하게 된다.
Eq. (8)처럼 C개의 채널에서 G개의 그룹으로 나누어 와 번째에 해당하는 데이터들이 동일한 공간에 배치된다. 이는 영상 처리에서 얻은 영감으로 각 색상(채널)에 따른 값들이 서로 다른 특성을 띠고 있다는 가정하에 각 은닉 계층을 여러개의 그룹으로 나누어 정규화하였다. 이때 G가 1이면 계층 정규화와 같고 G가 C일 때 인스턴스 정규화와 같아진다. 각 클래스의 레이블이 입력 이미지의 명암에 의존하지 않아야 하는 이미지 분류에 주로 사용되어 주로 영상 처리에서 많이 사용된다.
3.2 정규화 기법을 적용한 CNN 구조
ConvNetQuake 백본망을 기반으로 본 논문에서는 정규화 효과를 분석한다. 정규화 기법은 크게 입력 정규화와 은닉 레이어를 적용하게 된다. 은닉 레이어는 3.1절에서 설명한 다양한 정규화 기법을 적용하게 된다. 또한 은닉 레이어의 정규화 기법 적용은 어떠한 은닉 레이어에 정규화 기법을 적용하느냐에 따라서도 모델 성능이 변화하게 된다. 본 논문에서는 Fig. 6과 같이 8개의 1D-CNN 구조에서 활성화 함수 앞에 정규화 기법을 적용하고 있으며 은닉 레이어에 정규화 기법을 적용하는 구조는 크게 세 가지로 설정하였다. 첫 번째는 제1 은닉 레이어에만 정규화를 적용하는 구조이다. 다양한 관측소에서 발생하는 입력값들을 단순 min-max 입력 정규화와 더불어 은닉레이어단에서도 정규화 과정을 거치며 이를 통해 안정적인 학습을 유도하고자 하였다. 두 번째는 기존 백본망 네트워크를 따르며 최종적인 특징을 추출하는 마지막 레이어 단에서 정규화를 통해 특징을 정렬하는 구조를 채택하였다. 세 번째로는 모든 은닉레이어에 정규화를 적용하는 구조이다. 세 가지 제안된 모델은 최종적으로 128차원의 특징 벡터를 생성하며 fully-connected 레이어와 softmax 함수를 통해 3-class 분류를 수행한다.
IV. 모의실험
4.1 데이터 구성
본 실험에서는 STEAD[11] 데이터를 이용하여 모의실험 데이터를 구성하였다. STEAD는 1984년 1월부터 시작하여 2018년 8월까지 전 세계 지진관측소로부터 얻어진 지진과 잡음 데이터를 다양한 메타데이터에 따른 지진파 데이터를 정리한 데이터셋이다. Fig. 7과 같은 (E, N, Z) 채널의 지진파 데이터와 규모, 깊이, 경도, 위도, 거리 등 30개 이상의 다양한 속성의 메타데이터로 구성되어 있다. 지진 파형의 길이는 60 s, 100 Hz로 샘플링되어 있다. 수집된 지진파는 지진의 규모에 따라 크기가 천차만별이기에 이는 입력 데이터 정규화를 통해 적절한 범위 내의 값들로 변환 후 학습을 수행할 필요가 있다.
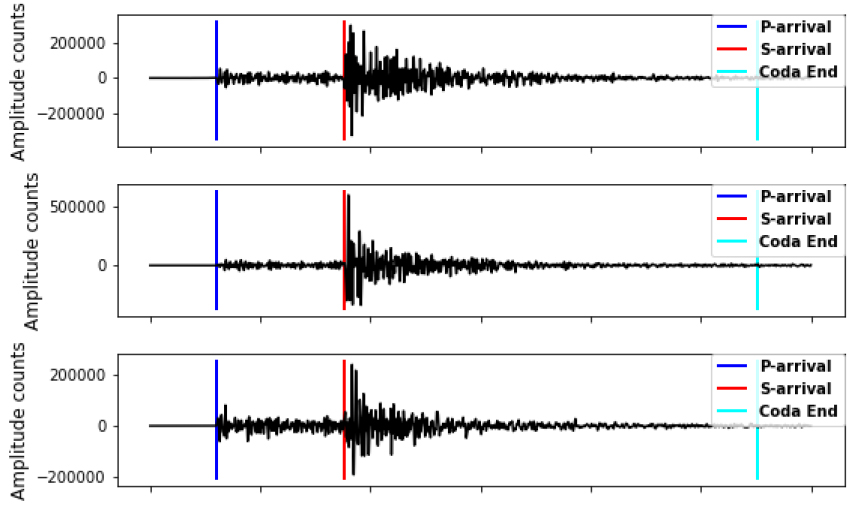
모의실험에서는 2017년 이전의 데이터는 모델 학습에 사용하였으며 2017년 이후의 데이터는 테스트에 사용하였다. 또한, 검증을 위해 학습 데이터의 20 %가량은 검증 데이터로 사용하였다. 이벤트 발생 시점을 기점으로 앞으로 0 s, 1 s, 2 s, 3 s 마진을 두어 총 10 s의 데이터를 추출하여 원래 데이터의 4배로 데이터 확장하였다. 학습 시 사용되는 라벨은 지진 규모 기준으로 강진(Macro, 규모 > 3.0), 미소지진(Micro, 규모 ≤ 3.0), 잡음(Noise)으로 구성하였다. 모델 학습 및 테스트에 이용되는 데이터셋 구성은 Table 1과 같다.
Table 1.
Dataset split.
| Dataset | Macro | Micro | Noise |
| Training | 32000 | 32000 | 32000 |
| validation | 8000 | 8000 | 8000 |
| test | 1999 | 2000 | 2000 |
4.2 실험 환경
모델 학습에 필요한 하이퍼파라메터는 Table 2와 같이 기존 ConvNetQuake 모델과 비교를 위하여 동일하게 사용하였다. 합성곱 레이어에서는 3 × 1 필터를 간격 1로 적용하였으며 필터의 입력 채널은 3, 출력 채널은 32로 설정하였다. 첫 번째 합성곱 레이어 이외에서도 필터 크기는 동일하지만 필터의 입력 및 출력 채널 수는 32로 설정하였다. 또한, 풀링의 크기는 2 × 1, 간격이 2인 최대 풀링을 사용하였다. 모델 최적화 기법은 ADAM 방법을 사용하며 미니배치 크기는 512로 설정하였다. 네트워크 학습은 300번의 에포크(Epoch)를 수행하였으며 제안된 모델의 성능 측정을 위하여 정확도와 confusion matrix를 성능 지표로 사용하였다.
여기서 TP는 true positive 개수, TN은 true negative 개수, FP는 false positive 개수, FN은 false negative 개수를 의미한다.
4.3 입력 정규화에 따른 성능 분석
본 실험에서는 백본망을 이용하여 입력값의 정규화 유무에 따라 학습한 모델의 성능을 분석하였다. Table 3과 같이 입력 정규화를 적용하지 않은 모델이 입력 정규화를 적용한 모델보다 우수한 성능을 보여 주고 있다. 실험에 사용된 입력 데이터는 다양한 크기의 지진 파형으로 전체 데이터를 정규화하게 될 경우 지진의 크기와 최댓값 특성들이 사라지게 되어 오히려 성능이 저하되는 현상이 나타났다.
Table 3.
Result of different input data.
| Normalized | Input | Normalized Input |
| Accuracy | 94.732 % | 93.722 % |
4.4 은닉 레이어 정규화에 따른 성능 분석
본 실험에서는 다양한 정규화 기법 및 적용된 은닉 레이어들의 구성에 따른 성능 분석을 알아보았다. Table 4는 입력 데이터는 정규화하지 않은 상태에서 은닉 레이어들을 정규화한 모델의 성능 결과를 나타낸다. Table 5는 입력 데이터 및 은닉 레이어들을 정규화한 모델의 성능 결과이다.
Table 4.
Result of the normalized hidden layer with input data normalization.
| layer | Batch | Layer | Weight | Group |
| 1 | 34.889 | 95.199 | 95.666 | 94.499 |
| 8 | 95.183 | 95.083 | 95.266 | 94.816 |
| all | 44.724 | 93.866 | 94.949 | 94.516 |
Table 5.
Result of the normalized hidden layer without input data normalization.
| layer | Batch | Layer | Weight | Group |
| 1 | 94.999 | 94.232 | 95.549 | 95.799 |
| 8 | 94.492 | 93.716 | 94.782 | 94.932 |
| all | 61.877 | 93.600 | 93.982 | 95.015 |
일괄 정규화는 지진 이벤트 분류에 사용할 경우 적용 은닉 레이어에 따라 과적합 현상이 일어나는 현상을 보였다. 모든 은닉 레이어에 일괄 정규화를 적용하게 되면 정규화 입력/비정규화 입력 모두에서 성능이 저하되는 현상을 보였다. 모든 은닉 레이어에 일괄정규화를 적용하게 되면 특징맵 값이 작은 범위내로 수렴하게 되는 모습을 보여 주었으며 이러한 현상의 결과로 테스트 성능이 저하되었다 . Tables 4와 5의 결과를 보면 일괄 정규화는 정규화된 입력값을 사용하는 모델에서 마지막 은닉 레이어에 적용될 때 기존 모델보다 성능 향상의 모습을 보여주었다.
계층 정규화는 비정규화 입력을 적용한 모델의 경우 모든 경우에서 성능 향상의 모습을 보여주지 못하였다. 그러나 입력 정규화 데이터에 적용할 경우 제1 은닉 레이어 및 마지막 레이어에 계층 정규화를 적용한 모델의 경우 기존 모델보다 향상된 성능 결과를 보여주고 있다. 모든 은닉 레이어에 계층 정규화를 적용할 경우 일괄 정규화와 같이 급격하게 성능 저하가 되는 모습은 보이지 않았다.
가중치 정규화와 그룹 정규화는 입력값의 정규화 여부 및 적용되는 은닉 레이어의 구성 여부와는 무관하게 안정적인 성능 향상의 모습을 보여주었다. 가중치 정규화는 정규화된 입력 데이터에서 더욱 우수한 모습을 보인 반면 그룹 정규화는 비정규화된 입력 데이터에서 더욱 우수한 결과를 나타내었다.
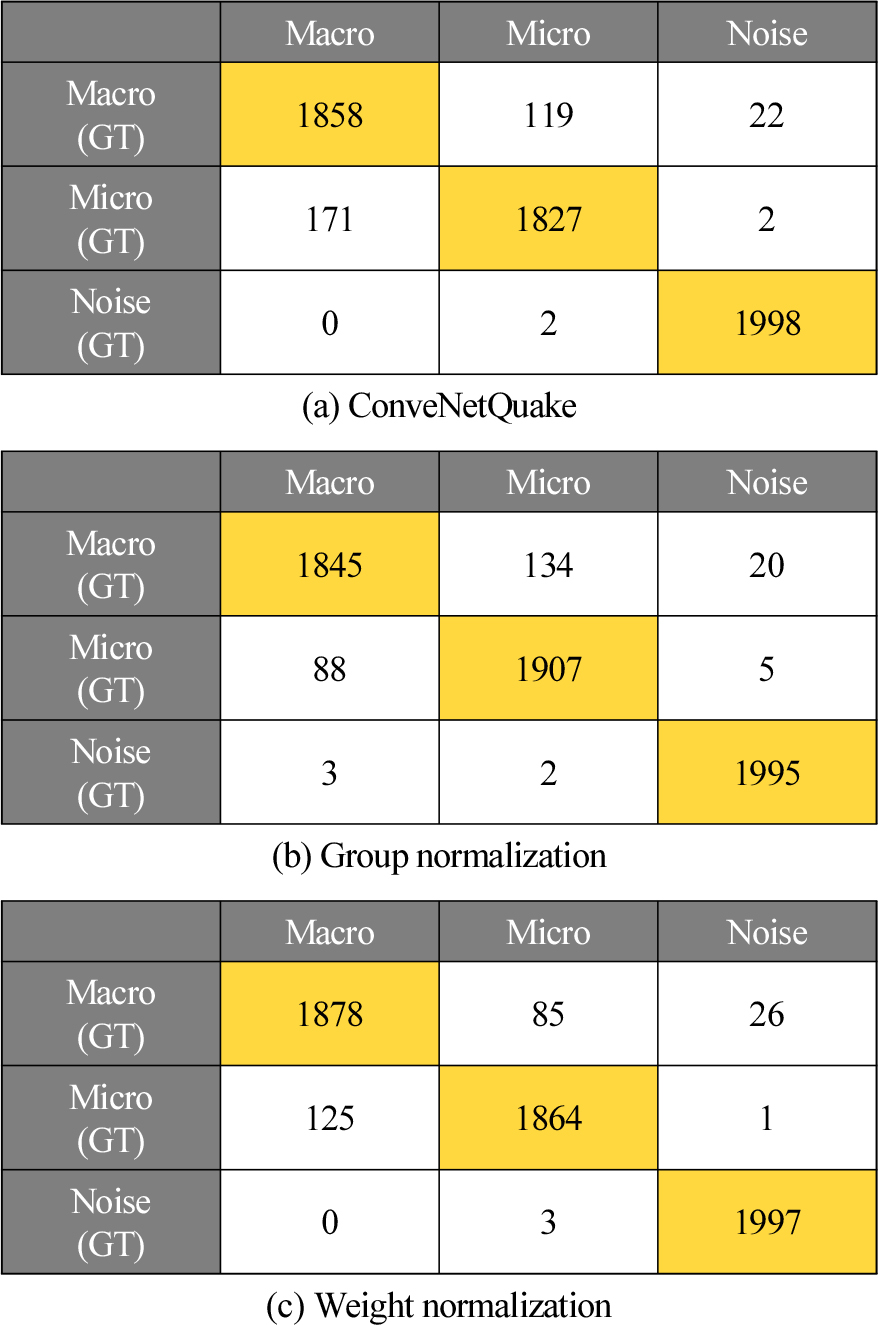
Fig. 8에서는 Tables 4와 5에서 성능이 가장 우수한 모델 confusion matrix를 나타낸다. 그룹 정규화 기법을 적용한 모델의 경우 백본 모델보다 미소지진의 TP(Truth Positive) 개수는 증가하였으나 강진의 TP 개수는 감소하였다. 가중치 정규화 기법을 적용한 모델의 경우 잡음의 경우 베이스라인과 유사한 성능을 보였으며 강진, 미소지진 이벤트에서는 베이스라인 모델보다 TP 개수가 전반적으로 증가하는 모습을 보였다. 정확도 및 confusion matrix를 살펴보면 다양한 정규화 기법 중 가중치 정규화 기법이 지진 이벤트 분류 성능 향상에 적합한 기법으로 판단된다. 또한 다양한 정규화 기법을 은닉 레이어에 적용할 경우 모든 은닉 레이어에 적용하기 보다는 특정 레이어에 정규화 기법을 적용하는 것이 효과적임을 알 수 있었다.
4.5 기타 정규화 결과 분석
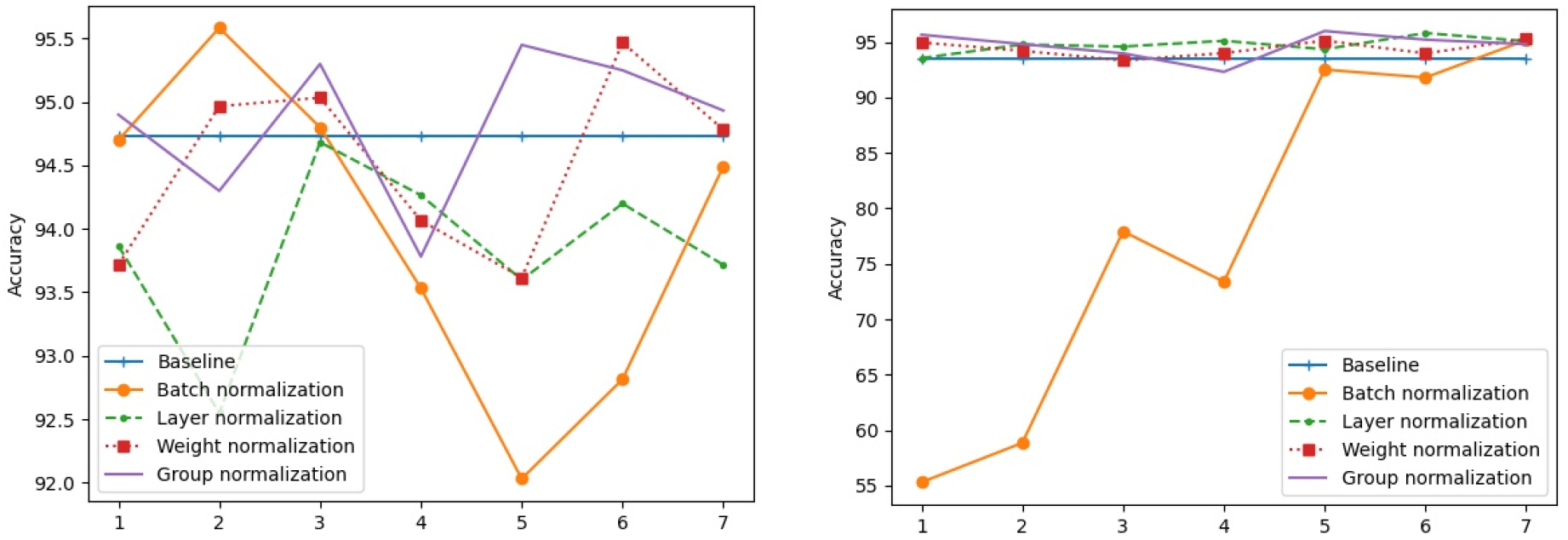
Figs. 9, 10에서는 입력 데이터를 정규화한 경우와 그러지 않은 경우에 대해 모든 계층에 관한 결과이다. 각 그림에서 빨간색은 기존의 ConvNetQuake 모델의 정확도이고 나머지 선들은 각각 다양한 정규화 기법을 적용한 결과이다. 실험결과 모든 은닉 레이어에 계층 정규화, 가중치 정규화, 그룹 정규화를 적용할 경우 일괄 정규화와 같이 급격하게 성능 저하게 되는 모습은 보이지 않았다.
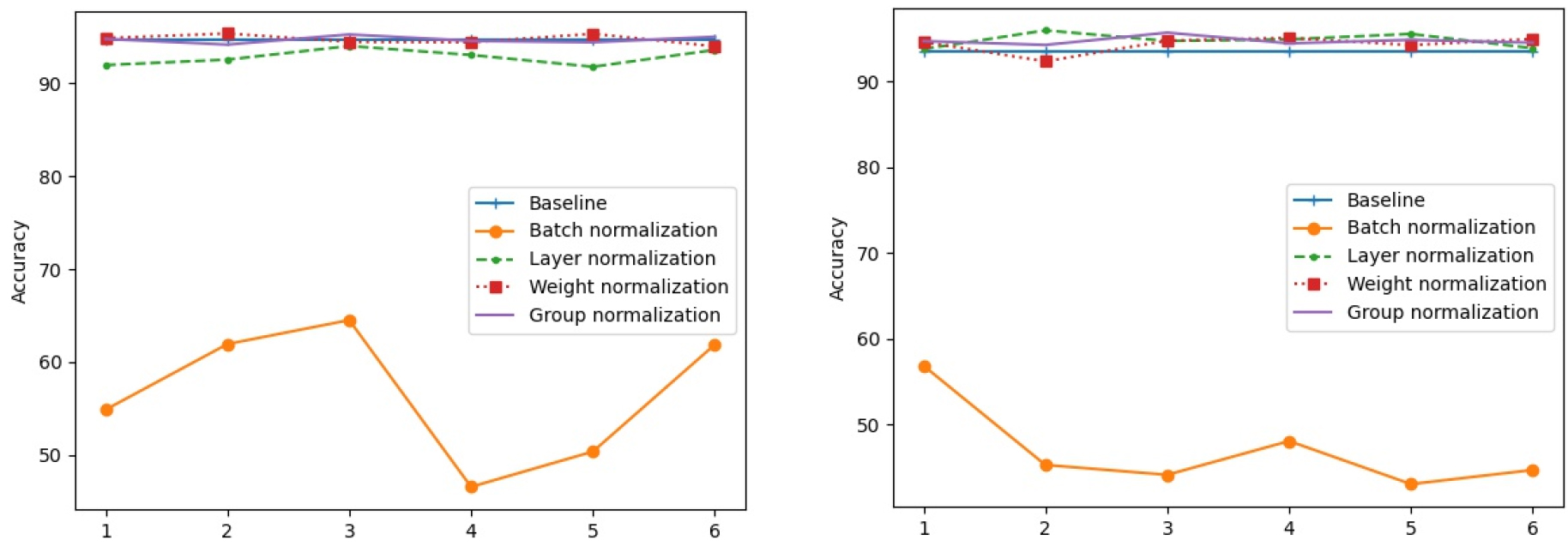
V. 결 론
본 논문에서는 다양한 정규화 기법이 딥러닝 기반 지진 이벤트 분류에 미치는 영향을 분석하였으며 효과적인 정규화 기법 및 네트워크를 제안하였다. 지진 이벤트 분류에 널리 알려진 ConvNetQuake를 백본 모델을 기반으로 적합한 정규화 기법 및 적용 구조를 실험을 통해 분석하였다. 실험결과 입력 데이터를 우선 정규화하고 제 1 은닉 레이어에 가중치 정규화 기법을 사용할 경우 기존 모델보다 약 1 %정도 성능 향상을 보였다. 본 연구에서 제시한 결과들은 딥러닝을 이용한 다양한 지진 분석 문제에 대한 해결책을 모색할 때 중요 판단 자료가 될 수 있다.
