

I. 서 론
음성인식이란 인간의 기본적인 의사 전달 수단인 음성을 매개로 하여 인간과 컴퓨터 사이를 이어 줄 수 있는 기술(human-computer interface)이다. 최근 들어 스마트폰을 위시한 많은 IT 제품들이 유저와 컴퓨터간의 편리한 인터페이스를 강조하며 출시되고 있는 만큼, 나날이 음성인식 기술에 대한 중요성은 증대 되고 있다. 음성인식 기술은 신호처리, 음향음성학, 패턴인식, 자연어 처리기술 등이 복합된 기술로 1950년대부터 연구를 시작하여 현재까지 상당히 많은 발전은 거처 진행되어 왔다. 그럼에도 불구하고, 아직까지는 사람들이 편리하게 사용할 만한 말하고 이해하는 음성인식 시스템이 구축되어 있지 않은 실정이기 때문에 다양한 방법으로 음성인식에 대한 연구가 진행되고 있다.
본 논문에서는 사람의 음성인지 과정과 음성의 발성학적인 특징을 기반으로 연구되고 있는 지식기반 음성인식 시스템의 한 부분으로서 비음 위치(nasal place) 검출에 관한 연구를 진행하려고 한다. 지식 기반의 음성인식 방법은 MIT 대학의 Stevens[1]에 의해서 제안된 방법으로서 음성신호로부터 발성학적인 연관성을 찾아 언어학 정보를 끄집어내는 방식으로 진행된다. 따라서 단편적인 특징 추출을 통한 성능의 평가보다는 음향음성학(Acoustic Phonetics)을 기반으로 하여 비음 위치의 의미 있는 특징들을 추출하여 성능을 평가하고 다각도로 분석하여 보았다.
영어의 비음 자음(/m/, /n/, /ng/)은 보통의 음소들처럼 발성이 될 때 구강을 통해 음성 발산 되는 것이 아니라, 구강 폐쇄를 통해 음성 발산의 경로가 비강으로 뻗어나가 만들어진다.[2-4] 이러한 비음의 발성학적인 특징은 다른 자음들과는 많은 차이를 나타내게 되는데, 크게 두 가지 특성이 두드러지게 나타난다. 첫 번째 특성으로는 폐쇄음(stops)에서 나타나는 특징과 같이 구강 폐쇄로 기인한 것이고, 다른 하나는 코인두 개방으로 인한 비음 구간(nasal murmur)이라는 음향음성학적인 특징이다.
비음의 특성을 연구하기 위해 Glass 와 Zue[5]는 음향음성학적인 특징들을 이용하여 비음과 다른 자음을 구분하는 실험을 진행하였는데, 에너지의 차이와 대역별 에너지의 변화를 특징으로 이용한 실험에서 80% 정도의 검출률을 나타내 주었다. 또한 그 이후 진행된 Chen[6]의 지식기반 음성인식 시스템의 구축을 위한 비음 검출 연구에서는, 비음 구간의 특성을 더 잘 나타내기 위해서 대역별 에너지를 좀 더 세분화하여 에너지의 차이와 변화를 관찰하였고, 또한 대역 에너지의 피크를 특징으로 하여 연구를 진행하였다. 가장 최근에는 Pruthi와 Espy-wilson[7]가 공명 자음(sonorant consonant)인 반모음과 비음 사이에서 SVM(support vector machine)을 이용하여 비음을 검출하는 실험을 하였는데, 대역 에너지의 onset/offset, 에너지의 비율, 그리고 스펙트럴 피크와 Hilbert 개형 (envelope)를 특징으로 한 실험에서 90% 정도의 검출률을 나타내 주었다.
본 논문에서는 앞선 연구자의 실험과 그 결과로부터 밝혀진 비음의 음향음성학적인 특징을 이용하여 비음 위치를 검출하는 것을 목표로 하고 있다. 비음 위치는 비음이 발생 시 폐쇄가 일어나는 위치에 따라 순음(labial), 치경음(alveolar) 그리고 연구개음(velar)로 나뉘게 되는데, 이는 영어에서 각각 /m/, /n/, 그리고 /ng/ 에 해당한다. 실험에는 에너지의 비율, 에너지의 차이, 포먼트 값 그리고 포먼트의 차이 값을 이용해서 비음 위치를 검출하였고, 가우시안 혼합 모델(Gaussian Mixture Model, GMM)[8]로 모델링하여 결과를 평가하였다.
이후의 장들은 다음과 같이 구성 되어있다. 먼저 2장에서는 실험에 사용된 비음의 음향음성학적 특징에 대한 설명과 특징을 추출한 방법에 대해서 설명한다. 3장에서는 실험 방법에 대해서 자세히 설명하고 , 4장에서는 실험 결과에 대한 분석과 나타난 의미에 대해서 토의 하고 마지막으로 5장에서는 전체적인 내용을 요약하고 결론을 맺는다.
II. 비음의 음향음성학적 파라미터
비음은 1장의 설명에서와 같이 구강 폐쇄와 함께, 이 구강 폐쇄가 유지되는 동안 비강을 통한 음성발산으로 이루어진다. 이러한 형태의 음성 발산은 비음 구간(nasal murmur)이라는 음향 특징을 만들게 된다. 그림 1의 ‘becalmed’라는 단어의 스펙트로그램은 비음 구간의 특성을 보여준다. 이 스펙트로그램에서 나타난 /m/의 비음 구간을 모음인 /aa/와 비교하여 살펴보면 두 가지의 특징을 알 수 있다. 그중 하나는 비음 구간은 모음의 포먼트가 나타나는 것과 비슷한 형태로 특정대역에서 에너지 집중이 나타난다는 점이고 다른 하나는 그 집중도가 모음과는 다른 양상으로 나타난다는 것이다. 이것은 이론상으로 포먼트만 가지고 있는 구강을 통한 전달함수와는 달리 포먼트와 안티 포먼트를 동시에 가지게 되는 비음의 특성으로 설명 될 수 있다. 다시 말해, 비음에서 나타나는 포먼트와 안티 포먼트의 상호작용은 조음기관의 변화를 통해 생성된 것이고 이것은 특정 대역의 상쇄 또는 비음 위치에 따라 특정한 스펙트럼의 결과가 나오게 되는 것이다.
|
그림 1.ʻbecalmedʼ 단어의 스펙트로그램. 모음인 /aa/ 와 비음인 /m/의 스펙트로그램을 비교 Fig. 1.Spectrogram of the word ʻbecalmedʼ. Compare vowel, such as the /aa/, with the nasal consonant, such as /m/. |
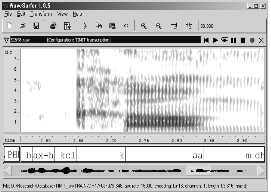
정리하면 비음은 보통 상위 포먼트와 구분되는 300 Hz 대역에서 제 1 포먼트가 나타나게 된다.[2] 또한 안티 포먼트의 존재로 인해 비음 위치에 따라 대역폭 별로 포먼트가 상쇄 되거나 안티 포먼트의 영향을 받은 스펙트럼의 형태가 나타나게 된다. 본 연구에서는 이러한 비음의 음향음성학적인 이론을 바탕으로 비음 위치 검출을 위한 특징을 제시하고 검출 실험에 사용하였다.
비음 위치를 검출하기 위해 최종적인 실험에서는 다음의 네 가지 성질을 사용하였다. (1) 대역별 에너지 비율(0 ~ 350/350 ~ 1000 Hz, 0 ~ 350/350~4000 Hz), (2) 제 1 포먼트 ~제 4 포먼트, (3) 비음 구간 중심과 비음 끝 지점(release)과의 대역별 에너지 차이(350 ~ 1000 Hz, 350 ~ 4000 Hz) 그리고 (4) 비음 구간 중심과 비음 끝 지점과의 포먼트 차이(제1포먼트 ~ 제4포먼트).
실험에서 사용한 에너지 비율은 비음 구간 중심에서 추출하였고, 음향음성학적 특징에 따라 비음의 첫 번째 포먼트가 나타나는 대역인 0 ~ 350 Hz의 에너지와 두 가지 고 대역 즉, 두 번째 포먼트의 영역인 350 ~ 1000 Hz 그리고 네 번째 포먼트까지의 영역인 350 ~ 4000 Hz의 에너지를 각각 구하여 특징으로 사용하였다. 포먼트는 동적 프로그램을 이용한 LPC (linear prediction coding) 방법으로 구현된 Snack 툴[9]을 사용하였고, 비음 구간의 중심에서 추출한 포먼트와 비음 끝 지점에서 구한 포먼트의 차이를 특징으로 사용하였다.
III. 실험 방법
본 연구에서는 TIMIT[10] 데이터베이스를 이용하여 실험을 진행하였다. TIMIT 데이터베이스는 음소비율을 고려한 10 문장을 630명의 미국인 화자가 발화한 것으로 총 6300개의 문장이 16 kHz로 녹음되었다. 학습 데이터에는 472명의 화자가 발화한 4720개의 문장을 사용하였고, 평가 데이터에는 162명의 화자가 발화한 1620개의 문장을 사용하여 실험을 진행하였다. 실험에서는 비음 플랩(nasal flap, /nx/)을 제외한 TIMIT 레이블 상의 모든 비음 자음(/m/, /em/, /n/, /en/, /ng/, /eng/) 을 /m/,/ n/, /ng/ 세 가지의 비음으로 나누어서 실험을 하였고, 비음 구간의 중심, 비음의 끝 지점과 주변부 음소의 정보는 레이블을 이용하여 실험하였다. 표 1 은 실험의 학습 데이터와 평가 데이터를 나타내고 있는데, 학습에 사용한 총 비음 자음의 개수는 13180개 그리고 평가에 사용한 모든 비음 의 개수는 4737개이다.
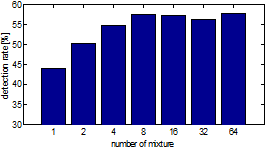
실험에 대한 성능 측정은 데이터베이스의 레이블된 음소 정보를 이용하여 평가하였다. 또한 비음 주변부에 나오는 모음의 영향에 대해서 알아보기 위하여 모음 직전(prevocalic), 모음 사이(intervocalic)에 그리고 모음 직후(postvocalic)에 대한 평가를 나누어서 진행하였다. 또한 그림 2에 나타난 결과처럼 mixture의 개수에 따라 비음 위치 검출률을 측정해 본 실험에서 8개의 mixture를 사용하였을 때, 최적의 결과가 나타났다. 따라서 이후의 실험은 8개의 가우시안 확률 밀도 함수로 모델링 하여 진행하였다.
IV. 실험 결과 및 토의
실험은 먼저 4가지의 음향음성학 파라미터를 이용하여 비음 위치를 검출하였는데, 그 결과는 그림 3의 인식률 그래프에 나타나있다. 비음 위치 전체의 성능은 57.5%의 인식률로 나타났다. 결과 중에는 연구개 비음(velar)인 /ng/가 가장 좋은 성능을 나타내었고, 순비음(labial)인 /m/이 전체의 성능보다는 8% 정도 떨어지는 결과를 나타내었다.
|
그림 3. 모음의 위치(모음 직전, 모음 사이, 모음 직후)에 따른 비음 위치 검출률 Fig. 3. Detection rates for nasal place according to the vowel positions (prevocalic, intervocalic, postvocalic). |
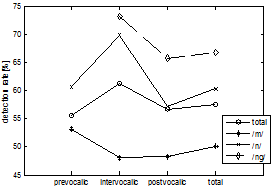
또한 그래프에서 모음 직전(prevocalic), 모음 사이(intervocalic), 그리고 모음 직후(postvocalic) 라고 표시 되어있는 결과는 비음 주변부에 나오는 모음의 영향을 고려한 평가이다. 비음이나 반모음과 같은 유성자음의 경우 주변 모음의 위치에 따라서 조음 효과(coarticulation effect)로 인해 에너지나 포먼트가 많은 영향을 받게 된다. 따라서 이 실험은 특징으로 사용한 파라미터들이 비음 위치를 검출하는데 있어 모음에 어떤 영향을 받는지를 알아보고자 하였다. 여기서 모음 직전(prevocalic)이라고 되어 있는 경우는 ‘next’ 라는 단어 와 같이 모음 바로 전에 비음이 나온 경우를 고려한 것이고, 모음 사이(intervocalic)이라고 되어 있는 경우는 모음 사이에 비음이 나온 경우 그리고 마지막으로 ‘becalmed’ 라는 단어와 같이 모음 뒤에 비음이 나온 경우를 모음 직후(postvocalic)이라고 지칭하여 실험을 진행하였다. 실험 결과는 모음 직전에 나타난 비음의 결과에서 55.6%의 검출 성능을 보여줬고, 전체적인 검출 결과에서 5% 내의 편차를 보이며 안정적인 성능을 나타내었다. 이러한 결과는 본 연구에서 사용한 특징의 대부분을 비음 구간의 중심부에서 추출하여 상대적으로 조음효과로 인한 성능 저하가 적었음을 의미한다.
전체적인 실험 결과는 기존에 진행되었던 비음 위치 검출 연구와 비교했을 때에도 의미 있는 결과라고 할 수 있다. 아직까지는 비음 위치 검출에 관한 연구보다는 비음 검출이나 특성 연구에 많은 초점이 맞추어져 있지만, Seitz et al.[11]의 연구와 De Mori et al.[12]의 연구 결과를 통해서 간접적인 비교를 할 수 있었다. 먼저 De mori et al.[12]의 연구에서는 다양한 음향음성학 특징과 신경망을 이용해서 자음들을 구분하는 실험을 진행하였는데, 주목할 만한 대목은 /m/ 과 /n/의 구분 실험으로 두 가지의 비음 위치 구분실험에서 80% 정도의 구분율을 나타내었다. 또한 Seitz et al.[11]가 진행한 실험에서는 목적과 결과가 본 연구와 가장 비슷한 연구로 여러 음성 스펙트럼 특징과 다양한 대역별 에너지를 이용하여 비음 위치를 검출하였다. 실험은 모음 직전(prevocalic)의 경우와 모음 직후(postvocalic)의 경우로 나누어 모델링하여 진행하였는데, 결과적으로 모음 직전의 경우 /ng/가 나타나지 않기 때문에 /m/과 /n/ 구분 실험이 되고 모음 직후의 경우는 /m/, /n/, /ng/ 세 가지 비음 위치 구분 실험이 된다. 실험 결과는 모음 직전에 나타난 비음 위치 검출 실험에서 77%의 검출률을 나타냈고, 모음 직후 나타난 비음 위치 검출 실험의 경우 51%의 검출률로 나타났다. 기존의 실험 결과들 모두 데이터베이스와 모델링의 개수 차이로 직접적인 비교는 어렵겠으나, 본 연구에서 진행한 실험에서 상대적으로 적은 특징들을 사용하여 의미 있는 결과를 얻었음을 알 수 있다. 또한 직접적인 비교가 가능한 Seitz et al.[11] 의 모음 직후 나타난 비음의 실험 결과와 본 연구의 결과를 비교하였을 때, 5% 이상 성능이 좋게 나타나는 것을 알 수 있었다.
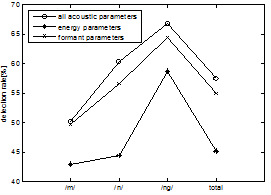
다음의 실험결과는 그림 4에서 나타난 것과 같이 특징에 따른 비음 위치 검출 결과이다. 이번 실험은 논문에서 사용한 특징들을 성질별로 묶어서 결과에 어떤 영향을 미치는지 알아보기 위한 실험으로 구성 하였다. 여기서는 논문에서 사용한 파라미터 중 대역별 에너지 비율과 대역별 에너지 차이를 에너지 파라미터(energy parameters)로 묶어서 평가하였고, 포먼트(제1포먼트 ~ 제4포먼트) 와 비음 구간 중심부와 끝 지점의 포먼트 차이를 포먼트 파라미터(formant parameters)로 묶어서 평가하였다. 실험 결과를 보면 포먼트 파라미터만을 사용한 결과가 에너지 파라미터만을 사용한 결과보다 모든 비음 위치와 전체적인 인식률에서 좋은 성능을 나타내었다. 특히 total(전체)의 결과를 보면 55.1%로 에너지만을 사용한 결과보다 9% 이상 좋은 성능을 나타내었다. 또한 비음 위치 중 순비음의 결과를 보면 에너지나 포먼트만을 사용한 결과 모두 좋지 않은 성능을 나타내었는데, 이것은 특징을 추출할 때 가정한 비음 위치에서의 안티 포먼트 영향이 다른 비음에 비해 덜 두드러지게 나타난다고 추론할 수 있고 반대로 연구개 비음에서는 그 영향이 잘 나타났음을 알 수 있다.
다음으로는 비음 위치 검출에서 나타나는 에러를 분석하기 위해 컨퓨전 행렬(confusion matrix)을 나타내었다. 표 2 는 음향음성학적 파라미터를 사용한 비음 검출 실험의 컨퓨전 행렬로, 표에서 나타난 결과를 보면 발성시 인접한 위치에서 나타난 비음들 사이에 에러가 많이 형성되고 있음을 알 수 있다. 특히나 순비음에서 나타나는 대부분의 에러는 연구개비음에서 나타나기 보다는(12.4%) 치경비음(37.5%) 에서 나타났고, 연구개비음 역시 에러의 대부분이 치경비음에서 나타난 것을 알 수 있다.
V. 결 론
본 논문에서는 그 동안 연구된 비음의 음향음성학 적인 특징을 사용해 비음 위치 검출을 위한 특징을 제시하였고 검출 실험을 통해 성능을 평가해 보았다. 음향음성학적 특징은 기존의 음성인식 분야에서 계속 연구되었던 스펙트럴(spectral) 파라미터와는 달리 발성적 특성을 중심으로 추출한 것으로 특징의 의미와 원리에 초점을 맞추어서 실험을 진행하였다. 실험의 결과는 논문에서 제시한 음향음성학적인 특징들이 비음 위치 검출에 적절하게 사용되었음을 증명해 주고 있다. 게다가 이전의 연구자들이 진행했던 제한된 화자가 발화한 고립단어 실험과는 다르게 연속된 음성(continuous speech)과 다양한 화자로 구성된 TIMIT 데이터베이스를 사용하여 비음에 대한 연구를 진행하였다. 실험 결과에서는 57.5%의 비음 위치 검출률을 나타내 주었고, 모음의 위치에 따른 결과에서는 큰 성능의 차이를 나타내지는 않았지만 모음 직전에 나타난 비음에서 위치 검출이 어려움을 밝혀낼 수 있었다.
검출시 사용했던 에너지 파라미터나 포먼트 파라미터의 경우 포먼트 파라미터가 비음 위치 검출에 더 효과적인 것을 알 수 있었지만, Chen[6]의 실험에서와 같이 대역폭이나 추출위치를 다양하게 실험 한다면 더 구체적인 특징을 찾아 낼 수 있을 것이다. 또한 에러를 분석해본 결과 인접한 비음 위치에서 에러가 많이 발생함을 알 수 있고, 특히 치경 비음인 /n/으로 에러가 많이 나타남을 알 수 있다.
이번 연구를 통해 알아본 결과 크게 두 가지 부분에서 향후 연구가 필요할 것으로 생각된다. 먼저 시간적인 파라미터의 추가이다. 비음은 앞서 설명한 발성 원리처럼 폐쇄에 이은 비음 구간의 존재가 순서대로 나타나기 때문에, 비음의 시작부터 끝까지 변화를 나타내주는 파라미터가 필요하게 된다. 또한 화자간의 차이를 보상해 줄 수 있는 화자 표준화 기법(speaker normalization)이 적용되면 좋은 효과를 가져올 수 있다. 특히, 본 논문에서 사용한 포먼트 값이나 포먼트 값의 차이의 경우 화자 표준화 기법으로 상당부분 화자 간 차이를 보상 할 수 있게 된다.
