

I. 서 론
디지털 기술의 발달로 점점 다양하게 생성되고 있는 디지털 콘텐츠들을 사람들은 일상 속에서 자연스럽게 경험하고 있다. 그러나 현재 대부분의 디지털 콘텐츠들은 인간의 오감 중 시각과 청각의 두 가지 자극을 이용한 단방향 소통 방식으로 구성되어 있으며, 이는 사용자에게 충분한 현실감과 몰입감을 제공하지 못한다는 단점이 있다. 이를 해결하기 위해 촉각 자극을 적용한 인간과 기계 간 햅틱 인터페이스 방식이 지속적인 관심을 받고 있다.
햅틱은 입력 장치를 조작하는 동안 사용자가 힘, 진동, 그리고 움직임 등을 느끼게 하는 감각 재현 기술이다. 지속적으로 발전하고 있는 햅틱 기술을 통해 사람은 물체에 작용하는 힘, 무게, 크기 등의 기하학적 특성뿐만 아니라 물체의 질감, 온감 등의 표면 특성 정보를 제공받아 재현된 운동감각 및 피부감각을 지각할 수 있다. 이중 질감은 특히 사람과 물체 간 상호작용 시 현실감 있는 촉각 구현에 매우 중요한 역할을 한다.
인간은 물체의 질감을 인지할 때 눈으로 재료의 표면을 관찰하거나, 맨손 또는 도구를 통해 물체 표면과 상호작용한다. 이것은 인간의 자연스러운 물체 인지 과정이다. 예를 들어, TV를 통해 홈쇼핑을 시청하는 동안 사람들은 판매하는 제품에 관해서 보고, 듣는 것뿐만 아니라 그 제품을 직접 만지며 느끼고 싶어 한다. 특히, 의류의 경우 사용된 소재의 질감을 만지고, 느끼는 것은 구매 결정에 큰 영향을 미친다. 이처럼 현실감 있는 환경을 제공받길 원하는 사용자에게 햅틱 기술을 통해 화면 너머로 물체의 질감 정보를 전달한다면 사용자의 만족도를 크게 높일 수 있다. 이러한 질감 정보 전달을 위한 햅틱 기술은 쇼핑뿐만 아니라 가상현실 및 다양한 디지털 콘텐츠 분야에서도 유용하게 적용될 수 있다.
최근에는 사용자가 햅틱 스타일러스 펜과 같은 도구를 물체 표면과 접촉하고 이를 통해 발생하는 진동 가속도 및 충격음 등을 통해 물체 표면의 질감 정보를 획득할 수 있다. 특히, 표면 재료로 인해 발생하는 가속도 신호는 오디오 신호와 높은 유사성이 있기 때문에[1] 오디오 신호 분석에 적용되는 기계 학습 기술을 접목하여 현재 햅틱 질감 인식 분야에 널리 사용되고 있다.[2]
본 연구에서는 60개의 질감 클래스별로 10개의 햅틱 가속도 데이터로 구성된 Lehrstuhl für Medientechnik (LMT) 햅틱 질감 데이터 세트[3]에 최근 음성 및 오디오 인식분야에서 뛰어난 성능을 나타내는 Conformer 모델을 적용함으로써 기존 연구와 비교하여 개선된 햅틱 질감 인식 정확도를 달성하였다.
II. 제안된 햅틱 질감 인식 시스템
Fig. 1은 제안한 햅틱 질감 인식 시스템의 구조도를 나타낸다. 제안한 방식에서는 사람이 스타일러스 도구로 60가지의 서로 다른 질감을 가진 물체의 표면과 상호작용하는 동안 표면 특성에 의해 발생한 접촉 진동신호를 3축 가속도 센서를 통해 10 kHz의 샘플링 레이트로 수집한다. 수집된 3축 가속도 데이터는 전처리 과정을 통해 1차원 신호로 결합되며, 오디오 신호와의 유사성을 반영하여 로그 멜-스펙트로그램(Logarithmic Mel-Spectrogram, LMS)으로 변환된다. 그리고 변환된 LMS로부터 질감 인식에 중요한 주파수 정보를 나타내는 지역적 및 전역적인 특징을 추출하기 위해 Conformer 모델을 적용한다. 최종적으로, 얻어진 햅틱 가속도 신호의 지역적 및 전역적인 주파수 특징은 두 개의 완전 연결 계층으로 구성된 분류기를 통해 60개의 질감 클래스에 대한 분류 결과를 출력한다.
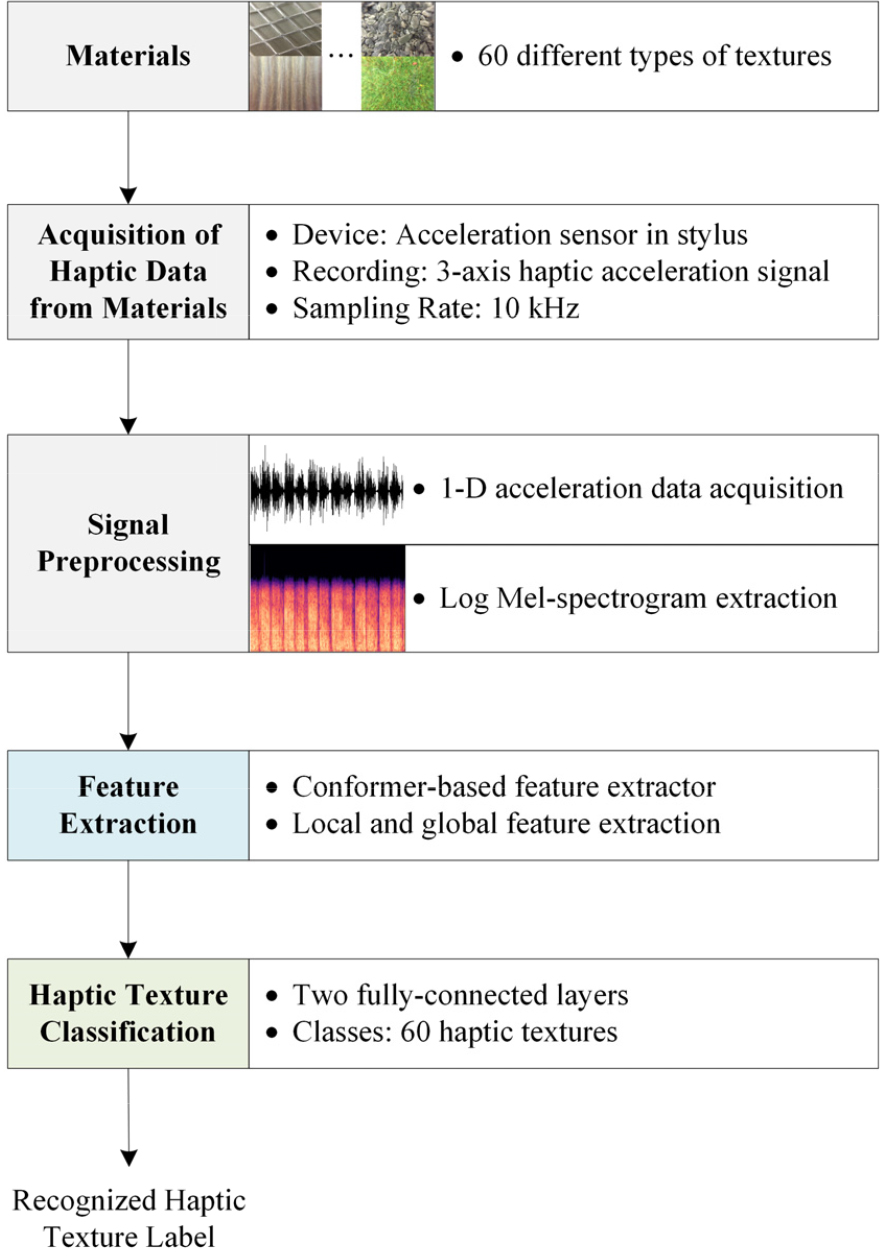
2.1 전처리
스타일러스가 물체 표면에 맞닿은 상태로 움직이는 동안 발생하는 접촉 진동은 도구 내 설치된 3축 가속도 센서에 의해 10 kHz의 샘플링 주파수로 기록되고, DFT321 알고리즘[4]을 통해 하나의 신호로 결합된다. 이 후에 결합된 1차원 원시 가속도 신호는 오디오 신호와의 높은 유사성을 고려하여 LMS로 변환된다.
LMS는 고주파보다 저주파의 경우 더 민감하게 반응하는 인간의 소리 지각 원리를 반영한 것이며, 로그 연산을 이용하여 서로 곱해져 있는 성분들을 분리하여 추출할 수 있다. 즉, 질감의 거칠기에 따른 저주파 진동 정보를 포함하는 가속도 신호의 멜-스펙트럼으로부터 스펙트럼의 포락선을 포착하고, 로그 연산을 통해 성분을 분리하여 신호로부터 차별적인 특징을 효과적으로 검출하는 데 적용된다.
먼저, 1차원 가속도 신호를 50 ms 길이의 해밍 윈도우와 10 ms의 홉 길이를 가진 단구간 푸리에 변환을 통해 각 단구간 프레임 내 신호의 주파수 신호 성분을 계산한다. 각각의 프레임에 대해 얻어낸 주파수 성분들을 사람 달팽이관 특성을 고려한 멜-스케일(mel-scale)로 변환하기 위해 20개 멜 필터 뱅크를 일정한 간격으로 적용한다. 각 멜 필터 내의 스펙트럼 성분들을 합산하여 출력하고, 이에 로그 변환을 취하여 LMS를 추출한다. 추출된 가속도 신호의 LMS는 합성곱 신경망과 트랜스포머를 결합한 Conformer에 입력되어 대상 물체들의 표면 질감을 식별하는 특징을 학습한다.
2.2 Conformer
Conformer[5]는 합성곱 신경망과 트랜스포머를 결합한 구조로, 전역적인 정보를 잘 표현하지만 지역 정보를 표현하는 데는 부족한 단점을 갖는 트랜스포머[6] 방식에 합성곱 신경망 기능을 보강함으로 지역 및 전역적인 특성을 모두 모델링 할 수 있는 장점을 갖고 있다.
Fig. 2는 Conformer 기반 특징 추출기의 구조를 나타낸다. Conformer 기반 특징 추출기는 합성곱 서브샘플링 계층, 선형 계층, 드롭아웃 계층, 그리고 Conformer 블록으로 구성된다. 여기서 합성곱 서브샘플링 계층 및 선형 계층은 입력 데이터의 중요한 특징은 유지하면서 시퀀스의 길이를 줄이는 기능을 한다. 그리고 Conformer 블록은 트랜스포머와 달리 멀티헤드 자기 주의 모듈 뒤에 보강된 합성곱 모듈이 위치하고, 절반으로 나뉜 순방향 신경망이 두 모듈을 감싸는 구조를 갖는다. 전통적인 트랜스포머와 같이 멀티헤드 자기 주의 모듈 다음에 단일 순방향 신경망을 연결하는 것보다 순방향 모듈을 절반으로 나누어 멀티헤드 자기 주의 모듈을 감싸는 구조가 성능을 향상시킬 수 있다.[7] Conformer 블록 내 각 모듈은 층 정규화 단계로 시작하며, 입력을 출력에 더하는 잔여 연결이 적용되었다. Conformer 블록에 대한 입력과 출력이 각각 와 라 할 때, Conformer 블록은 다음 Eqs. (1), (2), (3), (4)과 같이 표현할 수 있다.
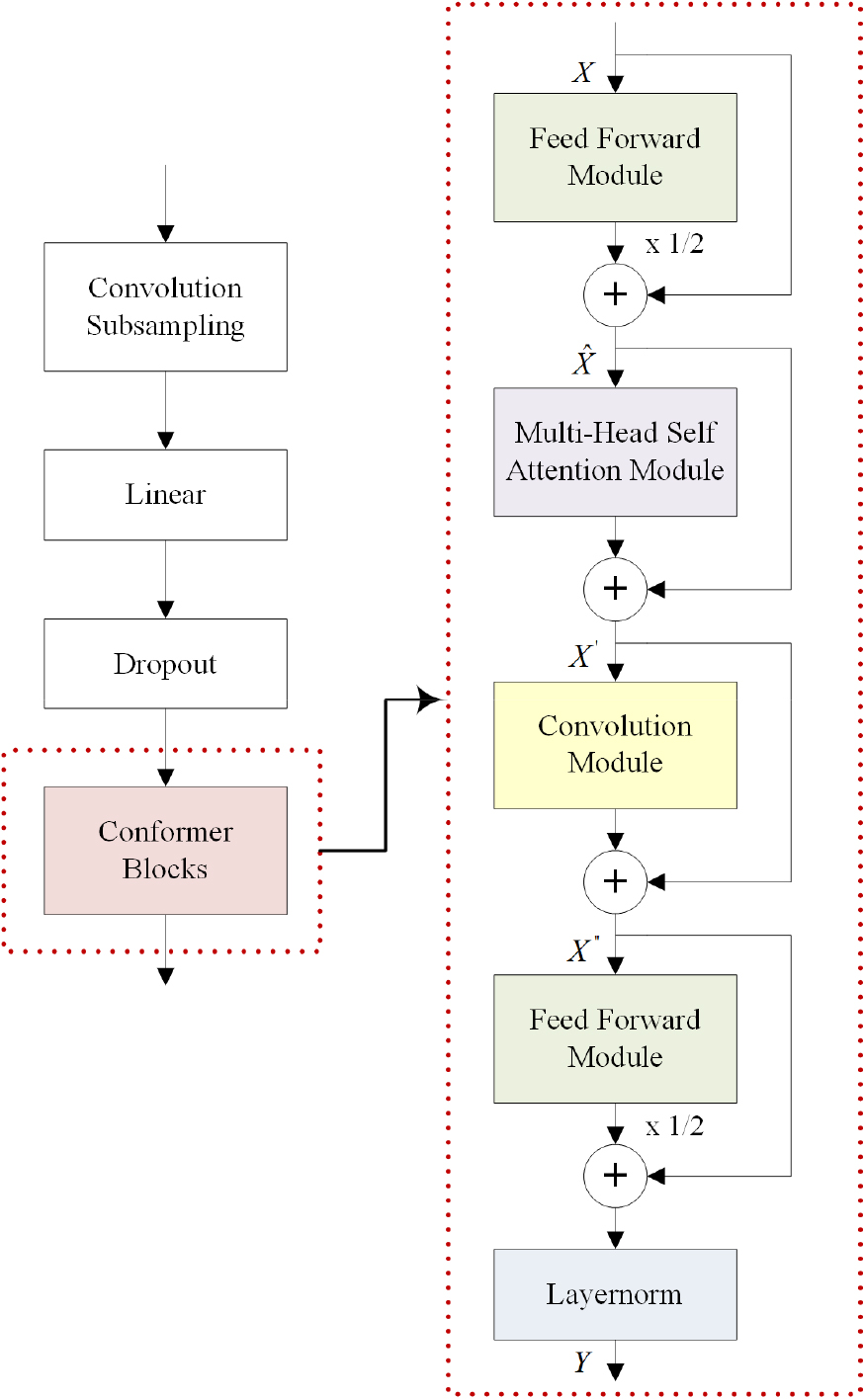
여기서 , , , 그리고 는 각각 순방향 신경망(Feed forwad network) 모듈, 멀티헤드 자기 주의(Multi-headed self-attention) 모듈, 합성곱 모듈, 그리고 층 정규화 모듈을 의미하며, , , 그리고 는 멀티헤드 자기 주의 모듈의 입력, 합성곱 모듈의 입력, 그리고 두 번째 순방향 신경망의 입력을 나타낸다.
순방향 신경망 모듈은 정규화 계층, Swish 활성화 함수가 있는 선형 계층, 드롭아웃, 두 번째 선형 계층, 그리고 두 번째 드롭아웃으로 구성된다. 첫 번째 선형계층은 입력의 차원을 4배 확장하는 반면, 두 번째 선형계층은 원래 입력 차원으로 다시 투영한다. 그리고 Swish 활성화 함수는 깊은 층을 학습시킬 때 정류 선형 유닛(Rectified Linear Unit, ReLU)보다 뛰어난 성능을 제공하고,[8] 드롭아웃은 학습 시 과적합 현상을 방지하는 장점을 제공한다.
멀티헤드 자기 주의 모듈은 층 정규화, 상대적 위치 임베딩이 결합된 멀티헤드 자기 주의, 그리고 드롭아웃 계층으로 구성된다. 상대적 위치 임베딩 방식은 입력 시퀀스의 길이가 가변적이어도 성능을 유지할 수 있고, 층 정규화는 심층적인 모델 학습 성능을 향상시키는 장점을 갖는다. 멀티헤드 자기 주의 모듈에 대한 동작 과정은 다음과 같다. 먼저, 멀티헤드 자기 주의 모듈의 입력은 층 정규화 단계가 수행된 후 선형 투영되어 쿼리(Query), 키(Key), 값(Value)으로 변환되며, 이는 Eqs. (5), (6), (7), (8)과 같다.
여기서 는 층 정규화의 출력을 나타내며, 이를 선형 투영한 i번째 헤드의 쿼리, 키, 그리고 값을 각각 , , 라 한다. 그리고 , , 는 학습 가능한 매개변수 행렬, d는 입력 벡터의 차원, 및 는 각각 헤드의 키 및 값의 차원, 그리고 h는 주의 헤드의 수를 나타낸다. 이후 획득된 쿼리 와 값 의 행렬 곱은 의 제곱근으로 축소된 후, 소프트맥스 함수 연산을 통해 유사도에 대한 가중치가 구해지며, 이는 에 행렬 곱 연산을 통해 반영된다. 가중치가 반영된 를 라 할 때 이는 Eqs. (9), (10)와 같이 나타낼 수 있다.
본 과정은 h개의 헤드에 병렬적으로 수행되며, 구해진 모든 값은 concat 연산을 통해 연결된 후 다시 선형 투영되어 Eq. (11)과 같이 최종 값을 출력한다.
여기서 는 연결된 특징 벡터에 적용된 최종적인 매개변수 행렬이며, 는 연결 연산을 나타낸다.
마지막으로, 합성곱 모듈의 구조는 층 정규화, 점별 합성곱, 게이트 선형 유닛(Gated Linear Units, GLU) 활성화 함수, 1차원 깊이별 합성곱, 배치 정규화, Swish 활성화 함수, 두 번째 점별 합성곱, 그리고 드롭아웃 계층으로 구성된다. 여기서 점별 합성곱과 게이트 선형 유닛을 통해 게이팅 메커니즘이 적용되었으며, 순방향 신경망 모듈과 동일하게 활성화 함수로는 ReLU 함수 대신 Swish 함수를 사용하였다.
III. 실험 및 결과
제안된 방식의 성능을 평가하기 위해 LMT 햅틱 질감 데이터세트를 적용하였다. LMT 햅틱 질감 데이터세트는 공개 데이터베이스로 본 논문에서는 60가지의 서로 다른 다양한 질감을 적용하였다. 적용된 재료 표면의 종류는 메시(meshes), 돌(stones), 유광 표면(glossy surface), 목재 표면(wooden surface), 고무(rubbers), 섬유(fibers), 폼(foams), 포일/종이(foils/papers)의 일상적인 범주이다.[3]
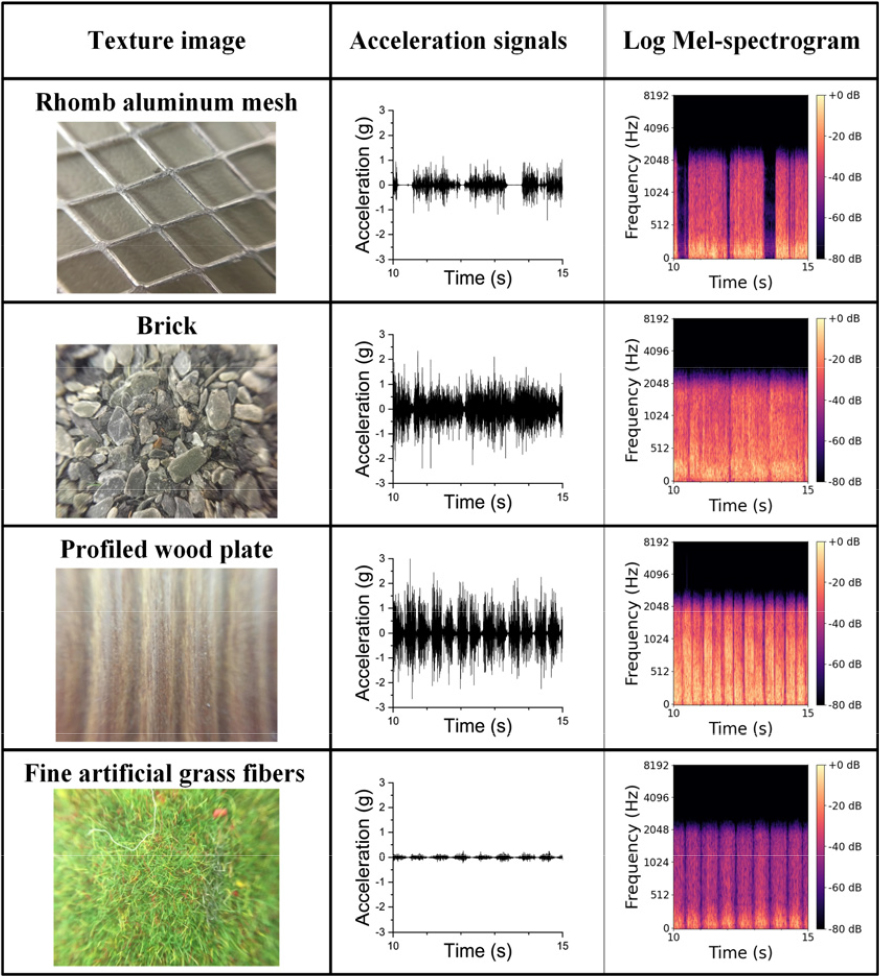
햅틱 질감 신호는 단단한 팁이 달린 스타일러스 도구로 60개의 각 재료의 표면을 자유롭게 접촉하는 동안 10 kHz의 샘플링 주파수로 기록되었으며, 가속도, 소리, 그리고 마찰력 신호를 제공한다.[3] Fig. 3은 LMT 햅틱 질감 데이터세트에서 제공하는 60개의 재료 중 네 가지 물체 표면에 대한 예시 이미지와 이에 해당하는 가속도 신호 및 LMS를 나타내며, 기록 중 스타일러스 도구 팁이 재료 표면에 닿아 충격이 생기는 신호의 시작 부분을 제외하고 표면의 특성이 잘 드러나는 10 s에서 15 s 부분을 보여준다.
우리는 제안한 햅틱 질감 인식 방식의 성능을 평가하기 위해 60개의 질감 클래스별로 존재하는 10개의 샘플링된 햅틱 가속도 신호 데이터를 적용하였으며, 모든 실험은 10겹 교차 검증 평가로 수행되었다. 즉 데이터의 90 %는 각 네트워크의 훈련을 위해 사용되었으며, 나머지 10 %는 훈련된 각 네트워크의 성능을 평가하는데 적용되었다. 이와 같은 과정을 거쳐 획득된 10번의 인식률 성능 결과는 최종적으로 평균화되었다.
본 논문에서 제안한 햅틱 질감 인식 방식의 성능을 비교하기 위하여 적용된 방식들은 다음과 같다.
⦁MFCC + Gaussian Mixture Model(GMM): 햅틱 진동신호로부터 추출한 15차원의 Mel-Frequency Cepstral Coefficient(MFCC)를 특징값으로 추출하여 GMM 모델에 적용하였다. GMM 모델에서는 K-평균 군집화로 초기값을 입력한 후 예측과 최대화 훈련을 11번 반복하여 추정된 최적의 모델 파라미터가 실험에 적용되었다.
⦁LMS + Convolutional Neural Network(CNN): 4개의 3x3 합성곱 커널을 갖는 합성곱 계층, 2x2 풀링 커널을 갖는 최대 풀링 계층, 하나의 드롭아웃 계층, 2개의 완전 연결 계층, 그리고 마지막으로 소프트맥스 계층으로 구성된 CNN이 입력된 LMS에 적용되어 햅틱 질감을 인식한다.
⦁LMS + Bidirectional Gated Recurrent Unit(BGRU): BGRU 계층, 드롭아웃 계층, 128개의 은닉 유닛으로 구성된 완전 연결 계층, 그리고 소프트맥스 계층으로 구성된 BGRU가 햅틱 질감 분류를 위해 적용되었다. 여기서, BGRU 계층은 64개의 은닉 유닛으로 이루어진 순방향 GRU 및 역방향 GRU의 출력을 결합한다.
⦁LMS + Convolutional BGRU(CBGRU): 2개의 합성곱 계층, 하나의 서브샘플링 계층, 2개의 완전 연결 순환 계층, 그리고 마지막으로 하나의 출력 계층으로 구성된 CBGRU가 적용되었다. 이는 CNN과 BGRU를 결합한 하이브리드 신경망 구조를 나타낸다.
⦁LMS + Pre Layer-Norm Transformer(PLNT): 햅틱 진동신호의 시간적 종속성을 학습하기 위해 멀티헤드 주의집중 메커니즘을 적용하기 전에 층 정규화를 사용하고, 이어서 잔여연결을 적용한 후에 다시 층 정규화, 순방향 신경망, 잔여연결을 순차적으로 수행한다.
⦁LMS + Gated Transformer(GTR): 위 PLNT 방식에서 잔여 연결 대신 게이팅 메커니즘을 적용하여 훈련 과정을 안정화하였다.
⦁LMS + Conformer: 본 논문에서 제안한 방식이다.
Table 1은 다양한 신경망 구조를 적용한 방식들과 제안한 방식의 햅틱 질감 인식 성능 결과를 비교한다. 실험결과, 제안한 Conformer 방식이 93.4 %로 가장 높은 분류 정확도를 나타냄을 알 수 있다. 이는 Conformer 방식이 트랜스포머 모델의 자기 주의 모듈에 합성곱층을 추가함으로써 지역적인 요소 및 전역적인 특성을 효과적으로 모델링함을 제시한다. 멀티헤드 주의집중 메커니즘을 포함하는 GTR 및 PLNT 방식은 제안한 방식보다는 인식 정확도가 낮았지만 다른 네 가지 방식보다는 우수한 성능을 제공하였다. 그리고 주의집중 메커니즘이 없이 CNN과 BGRU가 결합된 CBGRU 방식은 GTR 및 PLNT의 인식성능 보다는 다소 낮았지만, CNN 또는 BGRU만 적용한 방식보다 더 높은 인식 성능을 나타내었다. 마지막으로, 가장 낮은 질감인식 정확도는 MFCC 특징에 GMM을 적용한 경우였다.
IV. 결 론
본 논문에서는 물체 표면으로부터 스타일러스에 의해 획득된 햅틱 가속도 신호를 LMS로 변환한 후 Conformer를 이용하여 지역적 및 전역적인 햅틱 질감 특징을 효과적으로 추출함으로써 60개 클래스에 대해 높은 정확도로 햅틱 질감을 인식하는 시스템을 제안하였다.
LMT 햅틱 질감 데이터세트에 대한 실험은 제안된 방식이 기존의 방식보다 햅틱 질감을 높은 정확도로 인식할 수 있음을 입증하였다. 향후 연구에서는 본 논문에서 제안된 Conformer 모델을 다채널 뇌파 신호의 감정 맥락 정보 검출에 적용하여 사람의 긍정 및 부정감정, 그리고 스트레스 상태를 인식하고, 이를 기반으로 긍정적으로 감정 변화를 유도하여 사람의 감성을 증강시키는 연구에 적용할 예정이다.
