

I. 서 론
II. 온라인 비정상 탐지 알고리즘
III. 실험 및 결과
3.1 실험구성
3.2 정상 특징 변화에 대한 온라인 학습
3.3 새로운 정상 특징에 대한 온라인 학습
IV. 결 론
I. 서 론
비정상 탐지는 일반적인 통계적 특징 범주를 벗어나는 이상치 검출 문제로 정의되며, 제조, 의료, 보안 등 다양한 분야에서 활용된다.[1] 일반적으로 비정상 탐지 연구는 대부분의 데이터를 정상으로 가정하는 비지도 학습 방법으로 접근한다. 이러한 접근은 주로 정상 특징 학습에 기반하여 단일 클래스 분류를 수행한다. One Class Support Vector Machine(OC-SVM) [2]과 Support Vector Data Description(SVDD)[3]는 대표적인 단일 클래스 분류 기법으로 정상 데이터가 밀집된 특징 공간의 탐색 방법이다. 최근에는 얕은 학습의 고차원 데이터에 대한 한계를 극복하고자 심층 신경망에 기반한 연구가 수행되고 있다.[4,5,6,7] 대표적으로 Deep SVDD[4]는 심층 신경망에 의해 형성된 잠재 공간에서 정상 데이터를 포함하는 최소 크기의 구 경계를 탐색하는 방법이다. 이와 같은 비정상 탐지 모델은 대부분 배치 학습을 기초로 하여 시간에 따른 정상 특징의 변화에 성능 저하를 나타낸다.
최근 분류 모델에서 새로운 클래스가 추가되는 경우를 고려하기 위한 지식 증류 기법 기반의 온라인 학습 모델이 제안된 바 있다.[8,9] 또한 Seo et al.[10]는 시간에 따른 데이터의 특징 변화에 적응할 수 있는 선생-학생 모델 기반의 온라인 학습 알고리즘을 제안하였다. 하지만 이러한 연구들은 다중 클래스 분류 문제에 기초하여 희소 사건에 대한 비정상 탐지 문제에는 한계를 나타낸다. 이러한 이유로 시간에 따른 정상 특징의 변화에 적응하기 위한 단일 클래스 분류 모델 기반의 온라인 학습 알고리즘이 요구된다.
본 논문에서는 정상 데이터의 점진적 특징 변화를 고려할 수 있는 온라인 비정상 탐지 알고리즘을 제안한다. 제안하는 알고리즘은 대표적인 단일 클래스 분류 모델인 Deep SVDD에 기반하며 오프라인 및 온라인 학습 과정을 포함한다. 오프라인 단계에서 기존에 확보된 데이터가 잠재 공간의 중심에 밀집되도록 학습한다. 이후 온라인 단계에서 점진적 중심 연산을 통해 새로운 데이터에 의한 잠재 공간의 중심을 갱신한다. 단일 클래스 분류 모델은 새로운 데이터 입력에 대해 갱신된 중심을 기준으로 학습을 반복한다. 비정상 탐지 모델의 장시간 운용이 요구되는 수중 음향 환경 실험을 통해 제안하는 온라인 비정상 탐지 알고리즘을 평가한다.
본 논문의 구성은 다음과 같다. 2장에서는 제안하는 Deep SVDD 기반 온라인 비정상 탐지 알고리즘에 대해 설명한다. 3장에서는 수중 음향 데이터를 이용하여 제안하는 알고리즘을 평가한다. 끝으로 4장에서 결론을 기술한다.
II. 온라인 비정상 탐지 알고리즘
본 논문에서는 단일 클래스 분류를 위한 Deep SVDD 기반의 온라인 탐지 알고리즘을 제안한다. 제안하는 알고리즘은 Fig. 1과 같이 오프라인 및 온라인 학습 단계를 포함한다. 단일 클래스 분류 모델은 Fig. 1의 (a)와 같이 사전 확보된 데이터 를 이용한 오프라인 학습을 수행한다. 오프라인 학습 단계에서 데이터 임베딩을 통한 잠재 공간 형성을 위해 오토인코더를 사전 학습한다. 오토인코더는 입력 데이터를 복원하기 위한 학습을 수행하여 차원이 축소된 잠재 공간에서 데이터의 주요한 특징을 표현할 수 있다.[4] 이후 오토인코더의 잠재 공간에 대한 중심을 계산하고 인코더의 학습을 통해 잠재벡터를 중심에 밀집한다. 개의 오프라인 학습 데이터에 대한 잠재 공간에서 중심 는 Eq. (1)과 같이 계산된다.
여기서 는 입력 데이터 에 대한 인코더 네트워크 의 출력으로 생성된 잠재벡터를 나타낸다. 오프라인 학습 단계에서 의 학습을 위한 목적함수는 Eq. (2)와 같이 나타낸다.
여기서 는 를 구성하는 층 의 가중치를 나타내며 는 프로베니우스 노름을 의미한다. Eq. (2)의 목적 함수는 학습 과정에서 과대 적합을 방지하기 위해 초 매개변수 를 곱하여 에 대한 가중치 감소 정규화를 구성한다. Eq. (2)에 기반하여 는 잠재 공간에서 모든 데이터를 에 근접하도록 학습한다. 단, 가중치가 0이 되지 않도록 바이어스는 학습하지 않는다.
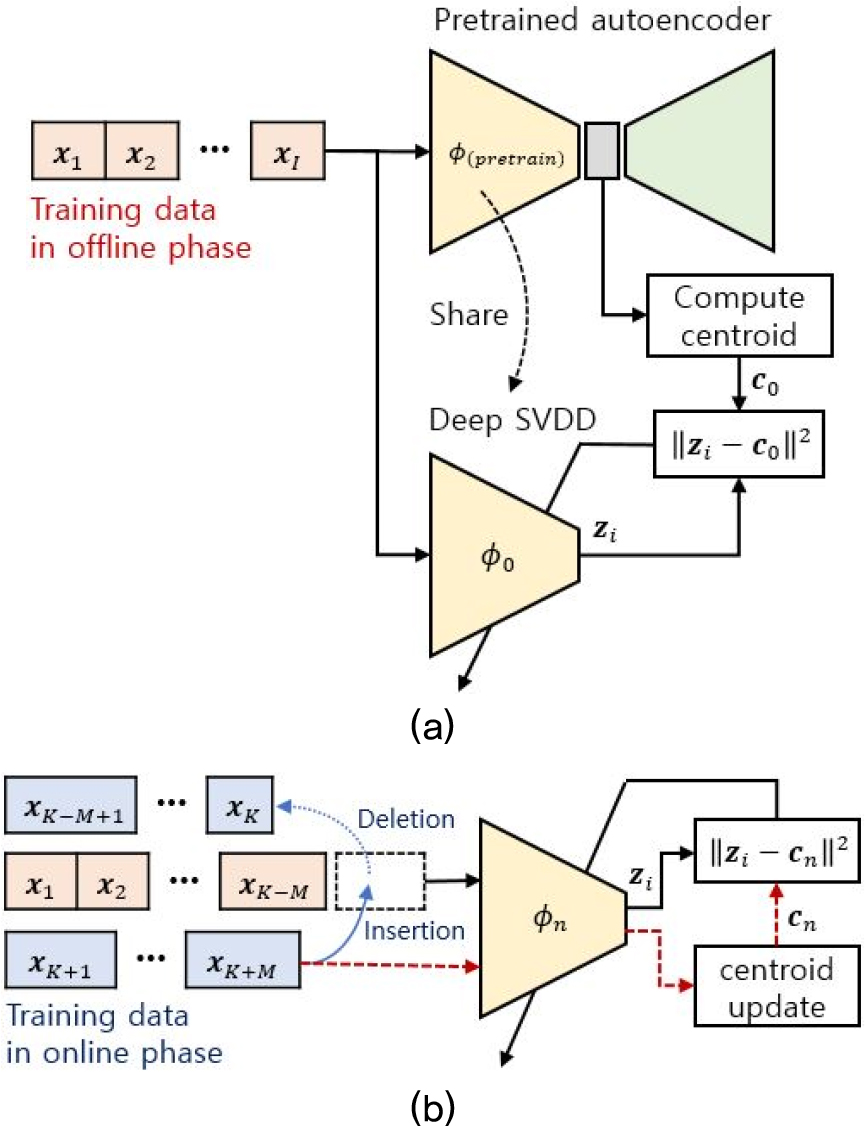
기존의 Deep SVDD 기반의 비정상 탐지 알고리즘은 오프라인 학습 이후 새로운 입력 데이터에 대한 비정상 탐지를 수행한다. 이러한 기존의 방법은 시간에 따른 정상 데이터의 특징 변화를 인식하지 못하여 성능 저하를 유발할 수 있다. 따라서 제안하는 알고리즘은 Fig. 1의 (b)와 같이 단일 클래스 분류 모델에 대한 온라인 학습 과정을 포함한다. 우선 개의 오프라인 학습 데이터에서 개의 데이터를 선택하여 초기 데이터 세트 를 생성한다. 이후 번째 데이터 세트 은 번째 입력된 개의 데이터를 번째 새로 입력된 데이터로 교체하여 구성된다. 매 학습에서 에 대한 잠재 공간의 중심 은 Eq. (3)과 같이 개의 새로운 입력 데이터에 대한 점진적 중심 연산을 통해 갱신될 수 있다.
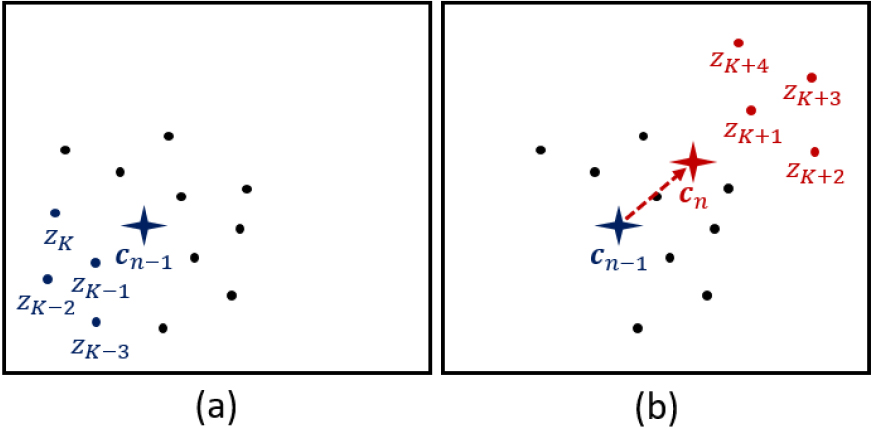
Eq. (3)에서 은 번째 계산된 잠재 공간의 중심 에서 전체 개의 데이터 중 단지 개의 새로운 입력 데이터와 삭제되는 데이터에 대한 적은 연산으로 갱신된다. 제안하는 단일 클래스 분류 모델은 신규 데이터 입력에 따라 갱신되는 을 기준으로 에 대한 학습을 수행한다. Fig. 2는 =4개의 신규 데이터 입력에 대한 잠재 공간에서 중심 및 데이터 갱신 방법을 보여준다.
제안하는 온라인 비정상 탐지 알고리즘은 신규 데이터 입력에 따라 갱신된 잠재 공간의 중심 및 데이터 세트를 이용하여 를 반복적으로 학습한다. 온라인 학습을 위한 목적함수는 Eq. (4)와 같다.
온라인 학습 단계에서 단일 클래스 분류 모델은 Eq. (4)와 같이 잠재 공간에서 개의 데이터가 에 밀집하도록 학습한다. Eqs. (3)과 (4)에서 이 작을수록 새로운 데이터의 특징 변화를 보다 빠르게 반영하지만 시간에 따른 네트워크의 학습 반복 횟수가 증가한다. 또한 가 클수록 다양한 특징의 오프라인 학습 데이터를 보존하여 학습할 수 있지만 매 학습에서 더욱 많은 연산이 요구된다. 따라서 온라인 학습 환경에 따른 학습 효율을 고려한 과 의 설정이 요구된다.
오프라인 및 온라인 학습 단계를 포함하는 단일 클래스 분류 모델의 전체 학습 과정은 Table 1과 같다. 오프라인 학습 단계에서 초기 주어진 개의 데이터를 이용하여 네트워크 를 학습한다. 온라인 학습 단계에서 개의 오프라인 학습 데이터 중 개의 데이터를 선택하여 를 구성한다. 이후 번째 새로운 데이터에 대한 을 갱신하고, 번째 입력된 개의 데이터를 번째 새로운 개의 데이터로 교체하여 을 구성한다. 끝으로, 갱신된 을 기준으로 에 대한 네트워크 을 학습한다.
Table 1.
Learning procedure of the proposed algorithm.
비정상 탐지를 위한 비정상 점수 는 와 의 절대 오차의 제곱으로 Eq. (5)와 같이 계산된다.
Eq. (5)에서 계산되는 는 입력 데이터의 비정상 정도를 나타내며 0에 근접할수록 정상으로 판정된다. 비정상 점수는 학습 데이터에 의존적으로 나타나므로 별도의 평가 데이터를 통한 Receiver Operating Characteristic(ROC) curve를 기준으로 판정을 위한 임계값을 설정할 수 있다.[6]
III. 실험 및 결과
3.1 실험구성
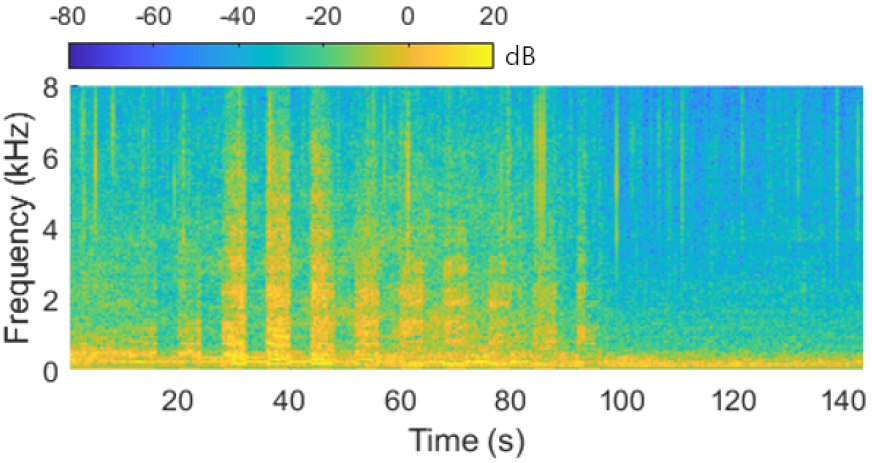
제안하는 온라인 비정상 탐지 알고리즘의 평가를 위해 수중 음향 신호에 대한 실험을 수행한다. 수중의 음향 환경은 파도와 같은 자연적 현상에 의한 잡음 외에 저주파 대역의 선박 엔진음이 큰 비중을 차지한다.[11,12] 따라서 본 논문에서는 ShipEar database[13]의 다양한 선종에 따른 선박 엔진음을 정상 데이터로 사용한다. 또한, DOSITS audio gallery[14]에 전시된 어뢰, 능동 소나, 해저 지진, 얼음 균열에 의한 수중 음향 데이터를 비정상 데이터로 사용한다. Fig. 3은 실험에 사용되는 정상 및 비정상 데이터에 대한 스펙트로그램을 나타낸다. 실험에 사용되는 정상 데이터와 비정상 데이터는 총 900 s, 68 s로 Table 2와 같이 구성된다. 각각의 데이터는 시간에 따라 연속적으로 측정된 데이터로 점진적인 특징 변화를 나타낸다. Fig. 4는 144 s의 예인선 엔진음 데이터에 대한 스펙트로그램을 보여준다.
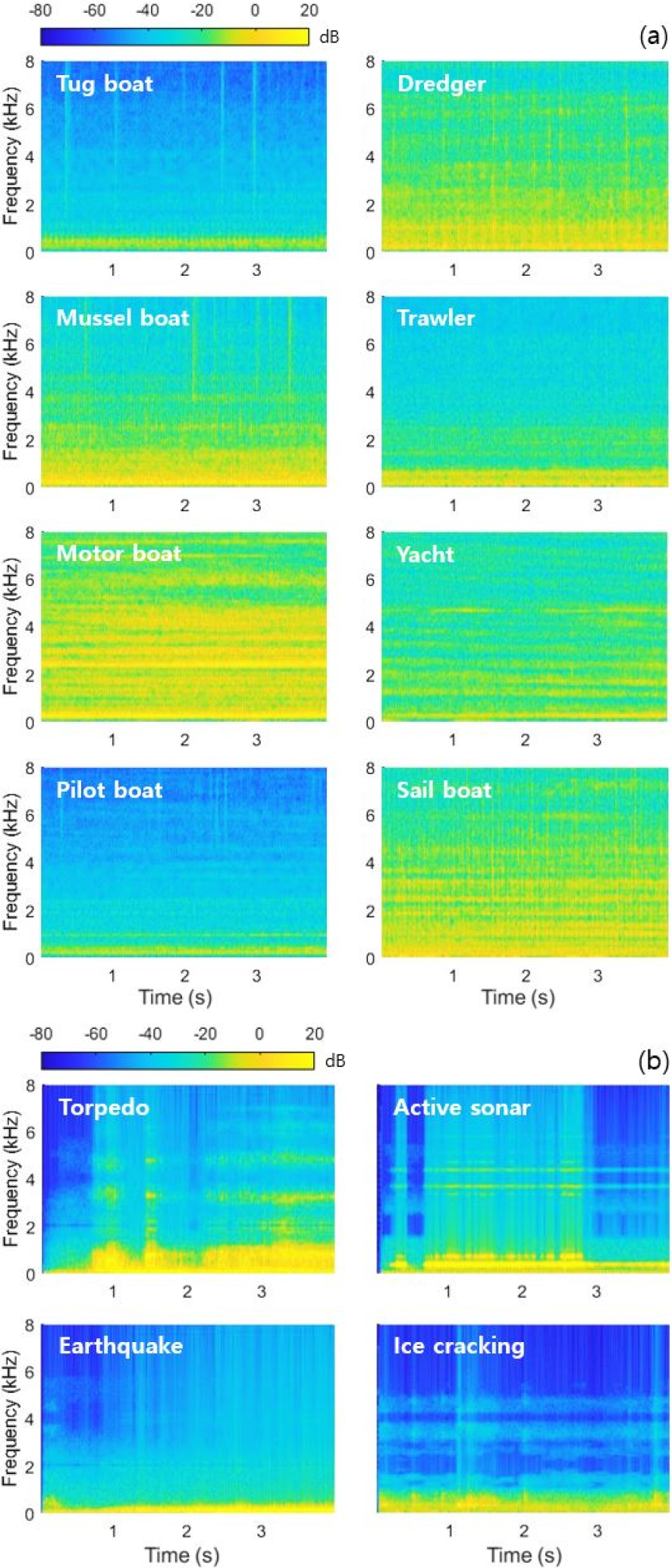
Table 2.
Underwater acoustic dataset for experiments.
| Normal dataset[13] | |||
| Data type | Length (s) | Data type | Length (s) |
| Tug boat | 144 | Motor boat | 108 |
| Dredger | 108 | Yacht | 108 |
| Mussel boat | 108 | Pilot boat | 108 |
| Trawler | 108 | Sail boat | 108 |
| Abnormal dataset[14] | |||
| Data type | Length (s) | Data type | Length (s) |
| Torpedo | 28 | Earthquake | 12 |
| Active sonar | 16 | Ice cracking | 12 |
실험에 사용되는 데이터는 16 kHz의 표본화율을 가지며 단시간 푸리에 변환을 통해 1초 단위 시간 윈도우 및 90 % 오버랩이 적용된 스펙트로그램으로 표현된다. 이후 90 % 오버랩을 유지하며 32 × 128 크기로 분절된 스펙트로그램은 표준점수 정규화 과정을 거쳐 단일 클래스 분류 모델에 입력된다. 단일 클래스 분류 모델의 학습을 위해 학습률 0.001의 Adam optimizer가 사용되며 30 ~ 100의 에폭이 설정된다. Table 3은 실험에 사용되는 데이터 처리 및 단일 클래스 분류 모델 학습을 위한 설정을 보여준다.
Table 3.
Parameters and settings for data training.
단일 클래스 분류를 위한 인코더 네트워크는 32, 64, 128, 256, 512개의 합성곱 필터 5, 5, 5, 3, 3의 커널 크기, (1, 2), (1, 2), (2, 2), (2, 2), (2, 2)의 보폭으로 구성되는 5층의 은닉층을 보유한다. 여기서 각각의 합성곱 층은 합성곱 연산 이후에 배치 정규화와 Rectified Linear Unit(ReLU) 활성화 함수에 대한 수행을 포함한다. 인코더의 출력은 40개의 합성곱 필터를 보유하는 합성곱 층으로 구성되어 인코딩된 특징이 길이 40의 잠재벡터로 표현된다. 사전학습을 위한 오토인코더의 디코더 네트워크는 잠재벡터를 확장하기 위한 완전 연결 층을 우선 포함하며 인코더를 미러링하는 5개의 역합성곱 층으로 구성된다. Table 4는 실험을 위해 구성된 네트워크 구조를 보여준다.
Table 4.
Network architecture.
3.2 정상 특징 변화에 대한 온라인 학습
본 논문에서는 시변 정상 데이터에 대한 온라인 비정상 탐지 성능을 평가한다. 오프라인 단계에서 각각 72 s의 8종의 정상 데이터로 구성된 총 576 s의 학습 데이터로 모델을 학습한다. 따라서 오프라인 학습에는 8종의 정상 데이터에 대해 각각 227개로 구성된 총 1816개의 스펙트로그램이 사용된다. 이후 온라인 단계에서 167개의 스펙트로그램으로 변환되는 54 s의 예인선 엔진음 데이터에 대한 시간에 따른 점진적 학습을 수행한다. 여기서 는 오프라인 학습 데이터의 약 25 %인 467로 설정되어 144 s의 데이터 특징을 학습하며 =25개의 데이터를 갱신한다. 따라서 단일 클래스 분류 모델은 온라인 학습 단계에서 오프라인 학습 데이터 대비 약 1.3 %인 7.7 s마다 학습을 반복한다. 학습 및 탐지 성능 평가를 위해 오직 오프라인 학습된 모델과 점진적 중심 갱신의 유무에 따른 온라인 학습 모델의 성능을 함께 비교한다. 점진적 중심 갱신을 하지 않는 온라인 학습은 Eq. (1)과 같이 오프라인 학습 단계에서 설정된 초기 중심을 기준으로 새로운 데이터를 학습한다. 비정상 탐지 성능 평가에는 각각 47개, 214개의 스펙트로그램으로 변환된 18 s의 예인선 엔진음 데이터와 어뢰를 포함한 4종의 데이터로 구성된 총 68 s의 비정상 데이터가 사용된다. Fig. 5는 7.7 s의 예인선 엔진음 데이터 입력에 대한 온라인 학습에서 에폭에 따른 손실 값을 나타낸다. Fig. 5에서 온라인 학습 모델은 점진적 중심 갱신을 통해 전반적으로 약 1.25배 낮은 손실을 통해 효율적인 학습을 수행한다. 점진적 중심 갱신 유무에 따른 온라인 학습 성능 비교를 위해 개의 갱신된 데이터에 대하여 Eq. (5)와 같이 계산된 비정상 점수의 합을 도출한다. Fig. 6은 오프라인 및 온라인 학습 모델의 시간에 따른 예인선 엔진음 데이터 입력에 대한 비정상 점수의 합을 나타낸다. Fig. 6에서 오프라인 학습 모델은 새로운 데이터를 학습하지 않아 온라인 학습 모델과 비교하여 전반적으로 높은 비정상 점수의 합을 가진다. 반면에 온라인 학습 모델은 새로운 데이터 학습을 통해 시간에 따라 감소되는 비정상 점수의 합을 나타낸다. 특히, 점진적 중심 갱신을 통해 54 s의 데이터 학습 시 오프라인 학습 모델과 비교하여 4.95배 낮고 점진적 중심 갱신을 하지 않는 온라인 학습과 비교하여 1.68배 낮은 수치를 보인다. 여기서 온라인 탐지 알고리즘은 점진적 중심 갱신 및 학습을 위해 단지 약 2 %의 추가적인 시간을 사용한다.
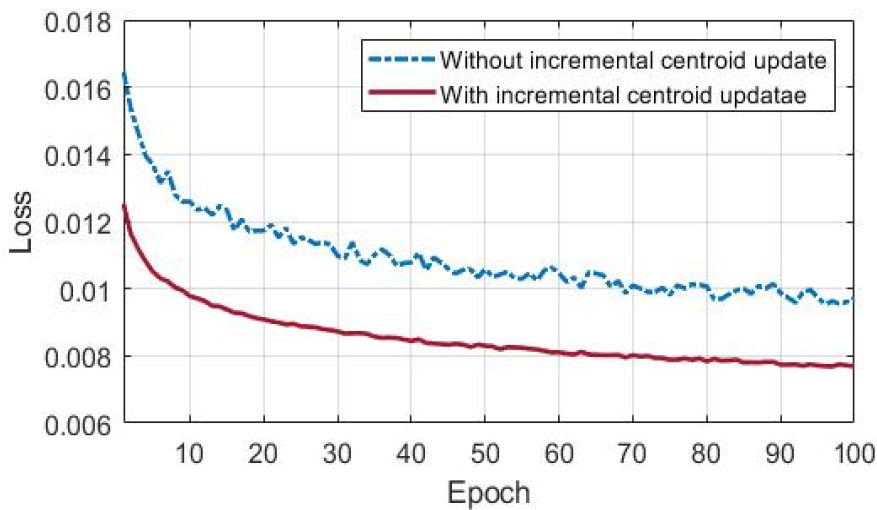
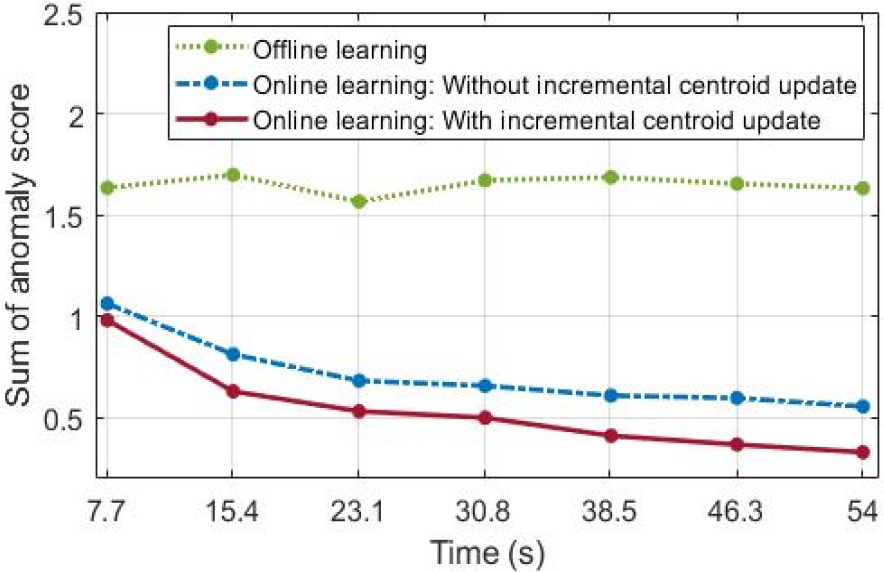
Fig. 7은 단일 클래스 분류 모델의 오프라인 및 온라인 학습 과정에서 학습 데이터에 대한 잠재벡터의 t-Stochastic Neighbor Embedding(t-SNE) plot을 보여준다. 또한, Table 5는 Fig. 7에 나타낸 t-SNE plot에서 학습 모델에 따른 잠재벡터의 분산을 나타낸다. Fig. 7의 (a)는 Fig. 1의 (a)와 같이 오프라인 학습을 통해 형성된 잠재벡터의 t-SNE plot을 나타낸다. Fig. 7의 (a)에서 오프라인 학습에 사용된 정상 데이터들은 Deep SVDD 학습을 통해 선박 종류에 관계없이 잠재 공간에서 서로 밀집되어 표현된다. Fig. 7의 (b)는 온라인 학습을 위한 네트워크의 초기 상태를 보여준다. Fig. 7의 (b)에서 오프라인 학습에 사용되지 않은 새로운 예인선 엔진음 데이터는 다른 학습 데이터의 외곽에 밀집하여 나타나며, Table 5에서 오프라인 학습 모델에 대한 분산 (328.59, 223.72)는 새로운 데이터 입력에 의해 (320.81, 245.57)로 변동하여 정상 데이터의 특징 변화를 반영한다. Fig. 7의 (c)와 (d)는 초기 중심을 기준으로 새로운 데이터에 대한 온라인 학습 모델과 Fig. 1의 (b)와 같이 제안하는 점진적 중심 갱신을 통한 온라인 학습 모델의 잠재벡터에 대한 t-SNE plot을 보여준다. Fig. 7의 (c)와 (d)에서 점진적 중심 갱신을 통한 온라인 학습은 오프라인 학습 데이터와 새로운 데이터의 특징을 모두 반영하는 중심에서 학습을 수행하여 초기 중심을 이용한 온라인 학습 모델보다 밀집된 잠재벡터를 도출할 수 있다. Table 5에서 점진적 중심 갱신을 통한 온라인 학습 모델에 대한 분산은 점진적 중심 갱신을 하지 않는 경우와 비교하여 (43.41, 92.58) 낮게 계산된다.
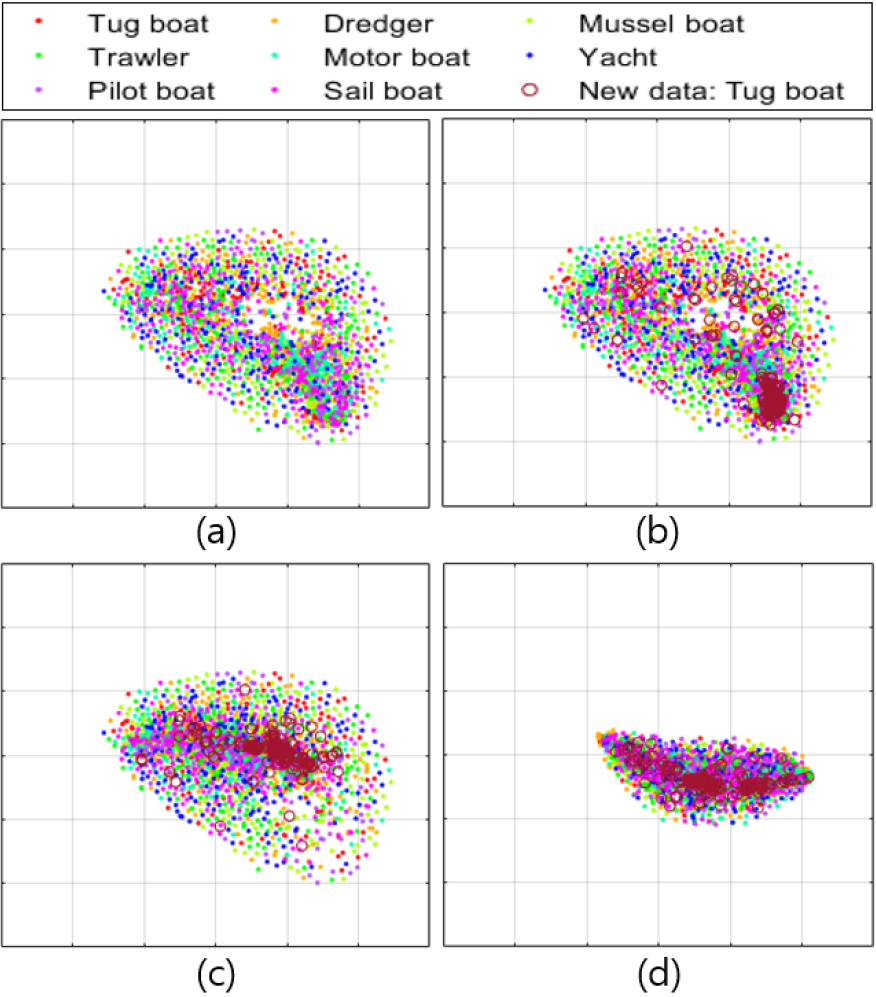
Table 5.
Variances of t-SNE plot outputs.
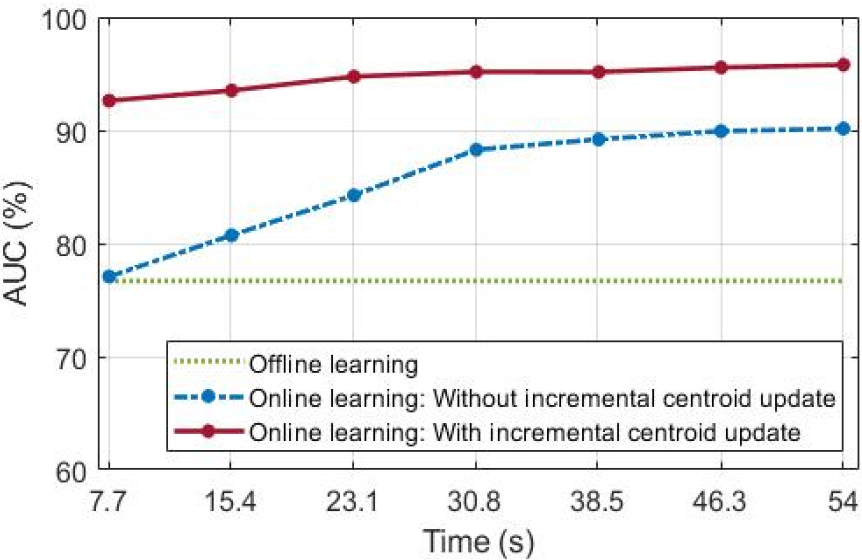
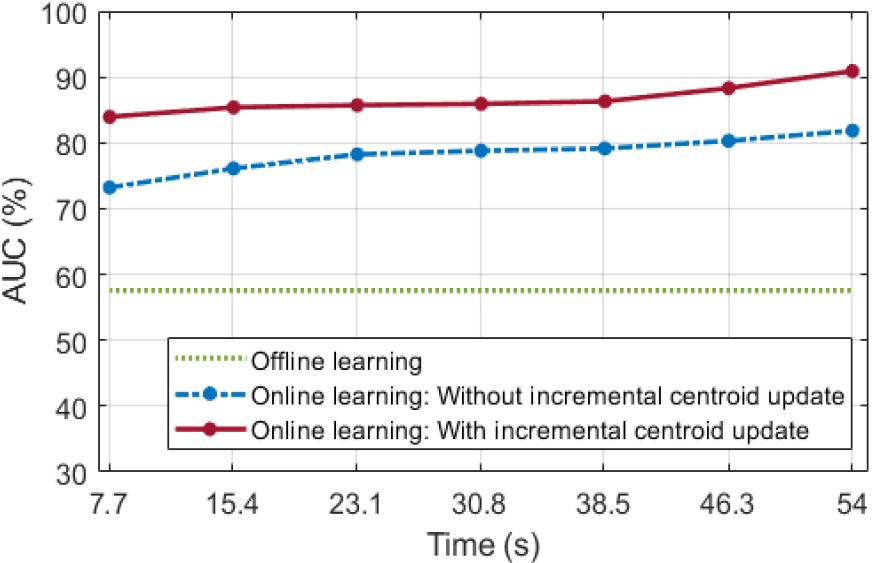
온라인 학습을 통한 비정상 탐지 성능은 불균형 데이터에 적합한 평가 방법인 Area Under the receiver operating characteristic Curve(AUC)를 사용하여 수치화한다. Fig. 8은 오프라인 학습 모델과 시간에 따른 새로운 데이터에 대한 온라인 학습 모델의 비정상 탐지 성능을 AUC로 나타낸다. 오프라인 학습 모델은 새로운 데이터에 대한 학습을 수행하지 않아 시간에 따른 변동 없이 76.68 %의 AUC 성능을 갖는다. 초기 중심을 기준으로 온라인 학습을 수행한 결과, 시간에 따라 탐지 성능이 향상되어 54 s 학습 시 90.14 %의 AUC 성능을 확보할 수 있다. 제안하는 점진적 중심 갱신을 통한 온라인 학습 모델은 단지 7.7 s의 새로운 데이터 학습에서 92.61 %로 우수한 AUC 성능을 나타내며, 54 s 학습 시 오프라인 학습 모델 및 점진적 중심 갱신을 하지 않는 온라인 학습 모델과 비교하여 19.10 %, 5.64 % 향상된 95.78 %의 AUC 성능을 갖는다.
3.3 새로운 정상 특징에 대한 온라인 학습
오프라인 학습에서 반영되지 않은 새로운 종류의정상 데이터에 대한 온라인 학습 성능을 평가한다.오프라인 학습 단계에서 예인선 엔진음 데이터를 제외한 각각 108 s의 7종의 정상 데이터로 구성된 총 756 s의 학습 데이터로 모델을 학습한다. 따라서 오프라인 학습에는 7종의 정상 데이터에 대해 각각 347개로 구성된 총 2429개의 스펙트로그램이 사용된다. 이후 온라인 학습 단계에서 167개의 스펙트로그램으로 변환되는 54 s의 예인선 엔진음 데이터에 대한 시간에 따른 점진적 학습을 수행한다. 여기서 예인선 엔진음 데이터는 108 s의 데이터 중 2 s 단위의 무작위로 선택되며, 와 은 앞선 실험과 동일하게 설정되어 144 s의 데이터 특징을 학습하고 7.7 s마다 학습을 반복한다. 또한, 앞선 실험과 같이 학습 및 탐지 성능 평가를 위해 오직 오프라인 학습된 모델과 점진적 중심 갱신의 유무에 따른 온라인 학습 모델의 성능을 함께 비교하며, 비정상 탐지 성능 평가에는 18 s의 예인선 엔진음 데이터와 어뢰 외 4종의 데이터로 구성된 총 68 s의 비정상 데이터가 사용된다. Fig. 9는 오프라인 및 온라인 학습 모델의 시간에 따른 새로운 예인선 엔진음 데이터 입력에 대한 비정상 점수의 합을 나타낸다. Fig. 9에서 온라인 학습 모델은 새로운 종류의 데이터 학습을 통해 시간에 따라 감소되는 비정상 점수의 합을 나타낸다. 특히, 점진적 중심 갱신을 통한 온라인 학습 모델은 54 s 학습 시 초기 중심 기준으로 학습된 모델보다 2.49배 낮은 비정상 점수의 합을 나타내며 오프라인 학습 모델과 비교하여 9.05배 낮은 수치를 갖는다.

Fig. 10의 (a)는 앞서 3.2절에서 예인선 엔진음 데이터를 포함한 8종의 선박 엔진음에 대해 사전학습된 오토인코더의 잠재벡터를 t-SNE plot으로 나타내며, Fig. 10의 (b)는 예인선 엔진음 데이터가 제외된 7종의 선박 엔진음으로 사전학습된 오토인코더의 잠재벡터에 대한 t-SNE plot을 보여준다. 또한, Fig. 11은 Fig. 10의 (b)와 같이 7종의 선박 엔진음 데이터로 사전학습된 오토인코더 기반의 오프라인 및 온라인 학습 모델에 대한 잠재벡터의 t-SNE plot을 보여주며, Table 6은 Fig. 11에 나타낸 t-SNE plot에서 학습 모델에 따른 잠재벡터의 분산을 나타낸다. Fig. 10의 (b)와 Fig. 11의 (a)에서 앞서 3.2절과 유사하게 오프라인 단계에서 Deep SVDD의 학습을 통해 모든 종류의 정상 데이터를 잠재 공간에서 밀집시킨다. Table 6에서 예인선 엔진음 데이터를 제외한 7종의 정상 특징을 반영하는 오프라인 학습 모델은 (223.42, 347.09)의 분산을 나타내어 Table 5에서 8종의 정상 데이터 학습 모델과 유사한 밀집 특성을 보여준다. Fig. 11의 (b)는 온라인 학습을 위한 네트워크의 초기 상태로 새로운 종류의 예인선 엔진음 데이터를 오프라인 학습 데이터와 다른 지점에 위치시킨다. 이는 새로운 종류의 입력 데이터에 의해 (205.98, 417.36)의 분산 값을 나타내어 정상 특징의 변화를 유발한다. Fig. 11의 (c)와 (d)는 점진적 중심 갱신 유무에 따른 온라인 학습 모델의 잠재벡터를 t-SNE plot으로 보여준다. 제안하는 점진적 중심 갱신 기반의 온라인 학습 모델은 새로운 종류의 데이터와 이전 학습 데이터의 특징을 모두 반영하는 중심으로 모델을 학습하여 초기 중심 기준의 온라인 학습 모델보다 (6.71, 35.58) 낮은 분산 값을 나타낸다.
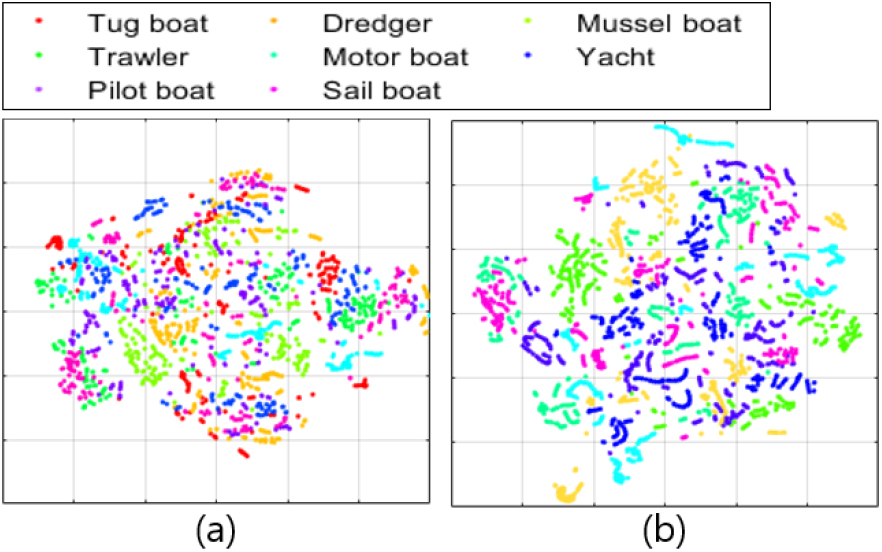
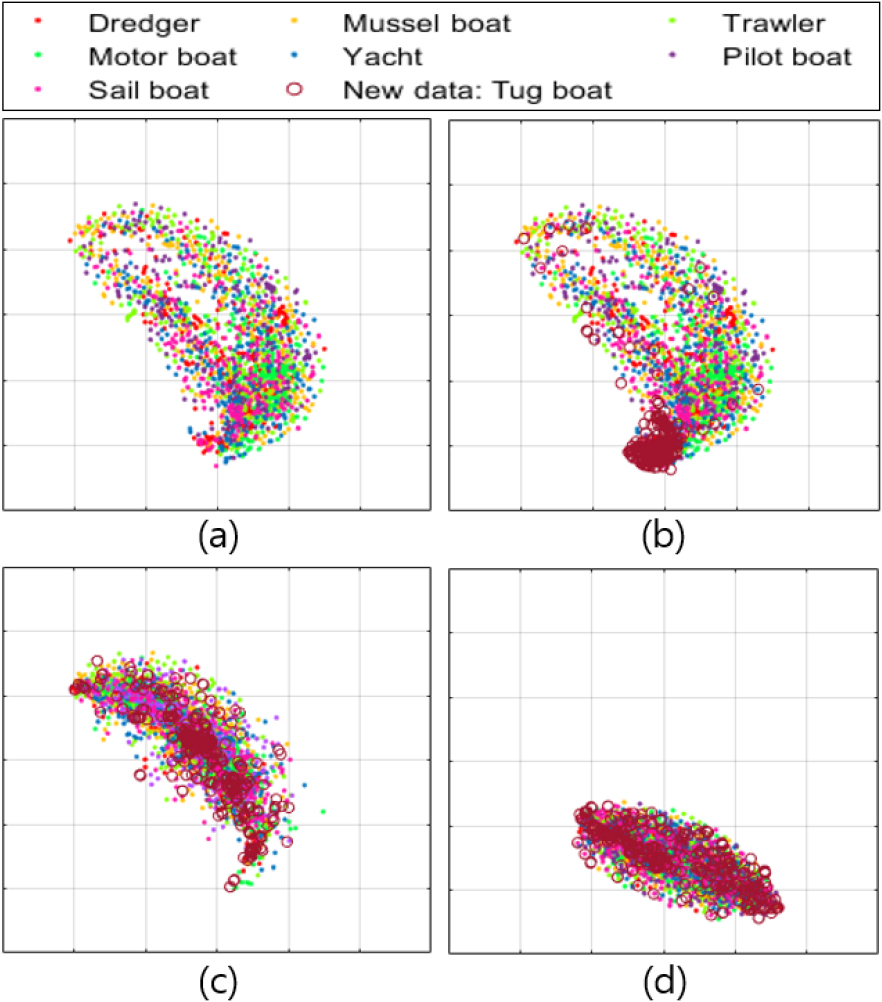
Table 6.
Variances of t-SNE plot outputs.
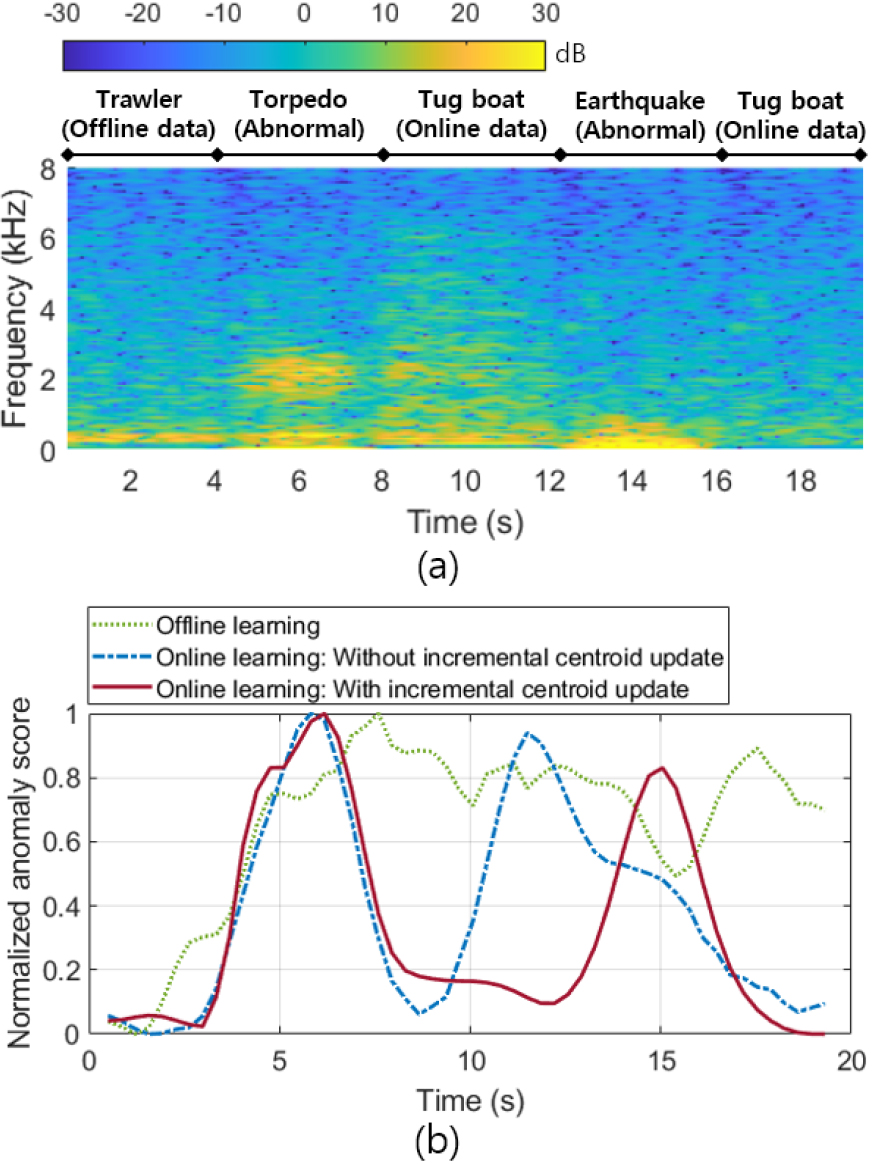
Fig. 12는 오프라인 학습 모델과 시간에 따른 새로운 데이터에 대한 온라인 학습 모델의 비정상 탐지 성능을 AUC로 나타낸다. 오프라인 학습 모델은 새로운 데이터에 대한 학습을 수행하지 않아 시간에 따라 57.56 %의 동일한 AUC 성능을 나타낸다. 초기 중심을 기준으로 온라인 학습을 수행한 결과, 시간에 따라 탐지 성능이 향상되어 54 s 학습 시 81.84 %의 AUC 성능을 확보할 수 있다. 제안하는 점진적 중심 갱신을 통한 온라인 학습 모델은 단지 7.7 s의 새로운 데이터 학습에서 83.94 %로 우수한 AUC 성능을 나타내며, 54 s 학습 시 오프라인 학습 모델 및 점진적 중심 갱신을 하지 않는 온라인 학습 모델과 비교하여 33.33 %, 6.95 % 향상된 90.89 %의 AUC 성능을 갖는다. 추가적으로, Fig. 13과 같이 선종에 따른 선박 엔진음과 어뢰, 해저 지진에 의한 비정상 음향 신호를 이용하여 가상 시나리오에 따른 신호를 생성하고 학습 모델에 따른 비정상 점수를 비교한다. Fig. 13의 (a)는 가상 시나리오에 따라 생성된 시계열 데이터의 스펙트로그램을 나타내며, (b)는 오프라인 학습 모델과 점진적 중심 갱신 유무에 따른 온라인 학습된 모델의 정규화된 비정상 점수를 나타낸다. 온라인 학습 모델은 오프라인 학습 이후에 54 s의 예인선 엔진음 데이터를 학습한다. Fig. 13의 (b)에서 오프라인 학습 모델은 새로운 예인선 엔진음 데이터에 대해 학습되지 않아 높은 비정상 점수를 나타내어 어뢰 및 해저 지진과 같이 비정상으로 탐지된다. 점진적 중심 갱신이 미포함된 온라인 학습 모델은 오프라인 학습 단계에서 설정된 초기 중심을 사용한 학습으로 예인선 엔진음 데이터에 대한 일부 오탐지 가능성을 내포한다. 반면에 점진적 중심 갱신에 의한 온라인 탐지 알고리즘은 시간에 따라 보다 정확한 비정상 점수의 변화를 나타낸다.
IV. 결 론
본 논문에서는 점진적 중심 갱신을 통한 단일 클래스 분류 모델 기반 온라인 비정상 탐지 알고리즘을 제안하였다. 대부분의 비정상 탐지 알고리즘은 배치 학습에 기반하여 시간에 따른 정상 특징 변화에 한계가 있다. 제안하는 온라인 비정상 탐지 알고리즘은 시간에 따른 정상 데이터의 특징 변화를 학습할 수 있다. 온라인 비정상 탐지 알고리즘은 오프라인 및 온라인 학습 과정을 포함한다. 오프라인 학습 단계에서 사전 확보된 데이터가 잠재 공간의 중심에 근접하도록 학습한다. 이후 온라인 학습 단계에서 점진적 중심 갱신을 통해 새로운 데이터 입력에 대한 특징 변화를 반영하고 갱신된 중심으로 데이터가 밀집되도록 학습을 반복한다. 공개된 수중 음향 데이터를 이용한 실험에서 제안하는 온라인 비정상 탐지 알고리즘은 신규 데이터에 대한 점진적 중심 갱신 기반의 학습을 통해 정상 특징 변화에 우수한 적응성을 보여준다. 제안하는 온라인 비정상 탐지 알고리즘은 점진적 중심 갱신 및 학습을 위해 단지 약 2 %의 추가적인 시간을 사용하여 95.78 %의 우수한 AUC 성능을 나타낸다. 또한, 오프라인 학습 단계에서 사용되지 않은 새로운 종류의 정상 데이터를 온라인 학습하여 90.89 %의 우수한 AUC 성능을 확인하였다. 제안된 온라인 비정상 탐지 알고리즘은 네트워크가 시간에 따라 변화하는 정상 특징을 학습하도록 하여 탐지모델의 장시간 운용이 요구되는 상황에서 적용이 가능할 것이라 기대한다.
