

I. 서 론
마이크로폰 배열 기반의 음원 위치추정법은 국방, 산업 안전, 인명구조 및 로봇 분야 등 다양한 분야에서 꾸준한 요구가 있어 온 기술 분야이다.[1] 기존의 접근 방법으로는 도달시간차(Time-Different Of Arrival, TDOA), 빔포밍, 음향 홀로그래피 등이 있으며,[2] 특히 도달시간차를 이용한 방법은 배열의 기하학적 구조를 기반으로 계산되는 마이크로폰 간 상호상관함수를 통해 시간 지연이 결정되므로 계산이 간단한 특징이 있다.[3] 한편, 많은 연구에서 위치추정의 정확도를 높이기 위해 일반화된 상호상관 방법이 광범위하게 사용되었다.[4,5,6]
실제 환경에서는 다양한 잡음이 동시에 측정되며, 따라서 마이크로폰에서 계측된 음향 신호의 왜곡은 결과적으로 이를 통한 음원 위치추정 성능 저하를 유발한다. 또한, 디지털 신호처리 과정에서 나타나는 시간 분해능 한계 및 마이크로폰 배열에 도달하는 음원의 방향에 따른 내재적인 오차의 원인들은 측정 방법의 강건성을 낮추는 문제를 유발한다.[7]
최근에는 딥러닝을 적용하여 데이터의 숨겨진 패턴을 찾아내는 방법으로 음원 위치 추정하는 문제에 적용되어, 기존의 방식이 갖는 성능 한계를 극복하고 있다.[8] 도달시간차 방법을 적용하기 위하여, 상호상관함수를 통한 음원 위치추정을 위해 딥러닝의 적용이 최근 활발히 시도된 바 있으며,[9,10,11] 이러한 연구들은 대부분 측정된 원신호로부터 곧바로 음원의 위치를 추정하는 방식으로 접근하였으나 시간 또는 공간분해능을 제한함으로써 음원 위치 추정 성능의 본질적인 한계가 남아있다.
본 연구에서는 딥러닝을 통해 정확한 도달시간차 추정 기술을 제안한다. 이를 통해, 측정 과정에서 발생하는 양자화 오류를 극복함으로써 도달시간차 방법을 기반으로 한 음원 위치 추정 정확도를 향상시키는 것을 목적으로 한다. 또한, 마이크로폰이 2개 및 3개로 이루어진 배열에 대한 시뮬레이션 및 실험을 통해 본 연구에서 제안하는 방법을 검증하고 결과에 대해 논의한다.
II. 배경 이론 및 문제 정의
2.1 상호상관함수를 이용한 음원 위치추정
마이크로폰의 기하적 배치 및 음원이 도달하는 방향에 따라 각 음원에 대한 마이크로폰의 도달시간이 달라지게 된다. 따라서 마이크로폰 배열을 통해 이러한 시간차를 역으로 계산하면 음원의 위치를 추정할 수 있다. 도달시간차는 마이크로폰 배열에서 계산되는 상호상관함수를 통해 계산되며 다음과 같은 수식으로 표현된다.
여기서 은 두 마이크로폰에서 측정된 음압 사이의 상호상관함수이며,
여기서 은 음원 신호 , 는 비상관 잡음, 는 음원 신호에 대한 자기상관함수, 는 의 최대값에 해당하는 시점이며 실제 시간지연에 해당한다. 따라서 마이크로폰 배열에서 계산되는 복수의 상호상관함수 및 마이크로폰의 기하적 배치에 따라 음원의 위치를 추정할 수 있다.
2.2 문제 정의
도달시간차를 통한 음원위치 추정 방법에서 마이크로폰에서 측정된 상관함수에서 를 추론하는 것이 가장 중요한 과정이다. 이를 추론하는 과정에서 산란 및 굴절과 같은 음향 전파에 따른 현상 또는 반사 및 잔향과 같은 요소들은 시간지연의 왜곡을 초래할 수 있다. 또한, 실제 측정에 따라 계산되는 이산화된 상호상관함수는 공간분해능을 떨어지게 하는 주요한 요인 중 하나이다. 따라서 이러한 오차의 요인들은 결국 위치추정 정확도를 떨어뜨리고 측정결과의 불확도를 커지게 한다.[7]
본 연구의 주요 목적은 음향 신호의 시간 지연을 정확하게 추정할 수 있는 딥러닝 모델을 개발하는 것이다. 아래와 같이 특정 추정 모델을 획득하는 것을 목표로 한다.
여기서 은 실제 측정 결과를 통해 계산되는 상호상관함수를 나타내고, 은 모델에서 추론된 도달시간 차이다.
본 모델의 핵심 목표는 편항된 상호상관함수 로부터 실제 값을 보상하는 것이다. 이러한 문제를 해결함으로써 기존의 도달시간차를 이용한 음원 위치추정 방법보다 정확한 시간지연 값을 계산할 수 있으며, 따라서 본 제안된 방법은 음원 위치추정 정확도를 향상시키는 데 적용할 수 있다.
III. 딥러닝 기반 도달시간차 추정
본 연구의 주요 목표는 로 구성된 데이터 세트에 대해 훈련된 딥러닝 모델을 활용하여 를 직접 예측하는 것이다. 문제 해결을 위해서 대표적인 딥러닝 모델인 Multi-Layer Perceptron(MLP)를 이용하였으며, 과적합이 발생하지 않는 선에서 높은 유추 성능을 확보하기 위해서 MLP의 은닉층을 4개로 구성하였다. 이에 따라 모델의 하이퍼파라미터는 직접 탐색을 통해 선정되었다. Fig. 1에 본 연구에서 제안하는 딥러닝 모델에 대한 구성을 나타내었다.
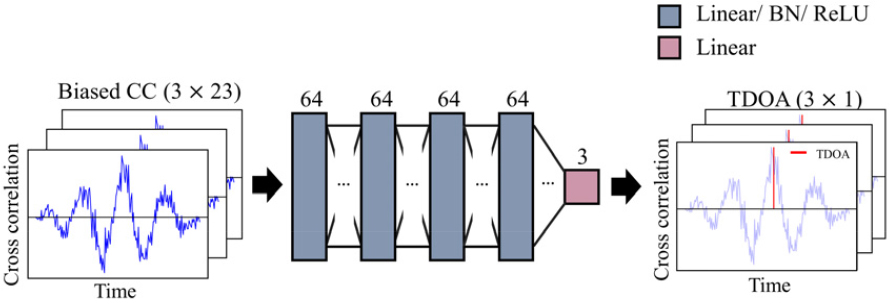
모델 학습에 있어서, 손실 함수로는 평균 제곱 오차(Mean Squared Error, MSE)가 사용되었다. 학습 과정에서의 학습률은 0.01로 설정되었으며, 모델 최적화는 Adam Optimizer를 사용하여 수행되었다.[12]
제안 모델의 도달시간차 추정 성능을 확인하기 위해 Fig. 2와 같이 마이크로폰 2개 및 3개로 구성된 배열을 사용하여 시뮬레이션을 진행하였다. 성능 비교를 위하여 실제 시간 지연과 예상 시간 지연 사이의 평균절대오차(Mean Absolute Error, MAE)를 사용하였다. 2개 마이크로폰으로 구성된 배열에 대해서는 1개의 상호상관함수, 그리고 3개 마이크로폰으로 구성된 배열에 대해서는 3개의 상호상관함수가 데이터 세트에 포함되며, 총 10,000개의 데이터 쌍을 포함한다. 각 데이터는 Matlab을 통한 시뮬레이션으로 생성되었다. 여기서 간격이 0.03 m인 마이크로폰 배열을 적용하였고, 데이터 형성에 적용된 음속 및 샘플링 주파수는 각각 343 m/s, 10 kHz이며, 대역 제한된 백색잡음에 대하여 상호상관함수를 계산하였다. 상호상관 함수는 총 23개의 시간지연에 대한 계산 결과를 포함하며 그 범위는 에 해당한다.

Fig. 3은 2개의 마이크로폰으로 구성된 배열에서, 서로 다른 3개 음원 방향에 대해 계산된 상호상관함수 및 도달시간차 추정 결과를 나타낸다. 여기서 x-축은 데이터 순서를 나타내고, 11번째 데이터가 에 해당한다. Fig. 3(a) ~ (c) 결과를 비교해보면, 각기 다른 상호상관함수에 대해 모두 = 0으로 예측하는 것을 알 수 있다. 를 중심으로 확대 도시 된 결과를 통해 상세히 살펴보면, 도달시간차 예측값인 가 에 비해서 오히려 정확도가 낮은 것을 볼 수 있다. 이를 통해, 제안된 모델은 단일 상호상관함수로부터 도달시간차를 예측하는 패턴을 제대로 학습하지 못하였음을 알 수 있고, 따라서 딥러닝을 통해 단일의 상호상관함수에서 획득할 수 있는 정보만으로는 도달시간차 예측을 수행하기 어려운 것을 확인할 수 있다.
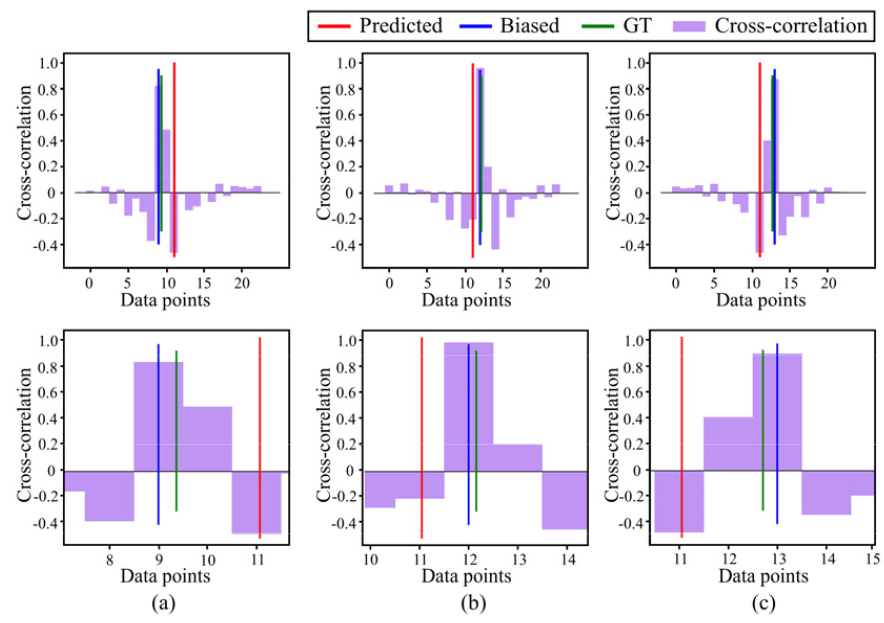
Fig. 4는 3개의 마이크로폰으로 구성된 배열에서, 임의로 선정된 한 음원 방향에 대해 계산된 상호상관함수 , , 및 도달시간차 추정 결과를 나타낸다. Fig. 4(a) ~ (c) 결과를 통해 높은 정확도로 가 를 추정하는 것을 볼 수 있다. 한편, 는 시간분해능 제한에 따라 와 차이를 나타내는 것을 볼 수 있고, 이는 양자화 오차에 해당한다. 이를 통해, 제안된 딥러닝 모델을 이용하여 양자화 오차를 보상함으로써 도달시간차 기반의 음원 위치 추정법의 정확도를 향상시킬 수 있음을 알 수 있다.
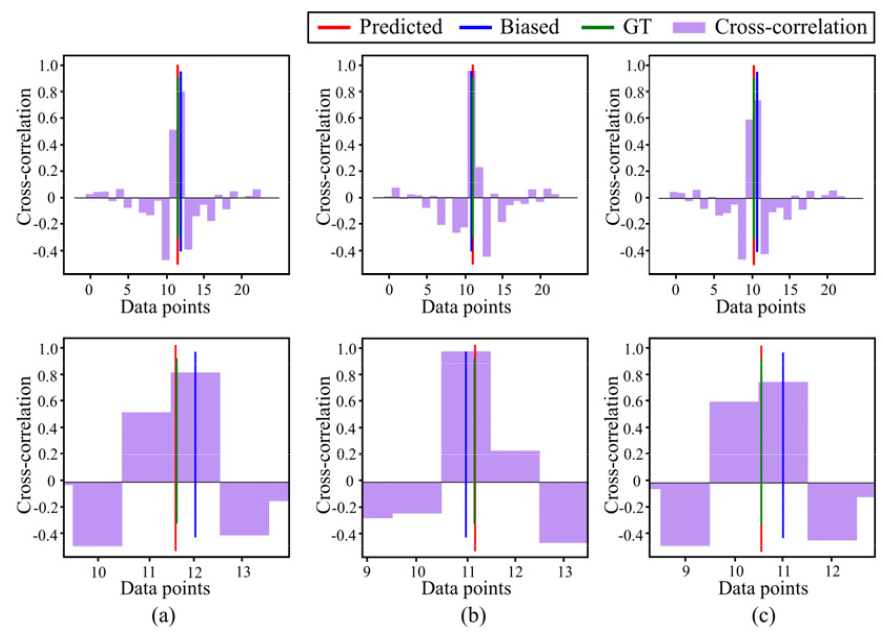
Table 1은 마이크로폰 2개와 3개로 구성된 배열에 대한 도달시간차 추정의 정량적 결과(MAE)를 나타낸다. 여기서는 1,000개의 데이터 세트가 계산에 활용되었다. 이를 토대로 분석한 결과, 마이크로폰을 3개 사용한 경우에는 도달시간차의 오차가 감소하지만, 마이크로폰이 2개인 경우에는 딥러닝 모델 적용 시 오히려 오차가 커지는 것을 볼 수 있다. 이로부터, 상호상관함수를 통한 도달시간차의 추정을 위한 핵심은 주어진 마이크로폰 배열에서 획득된 서로 다른 상호상관함수 간의 연관성에 있음을 유추할 수 있다.
Table 1.
Comparison of the mean absolute error for averaged TDOA estimation for 1000 test sets for random DOAs.
| Average | ||||
| Previous | 1.98E-05 | 2.11E-05 | 1.81E-05 | 1.97E-05 |
| 2-microphone | 1.30E-4 | - | - | 1.30E-04 |
| 3-microphone | 7.52E-06 | 8.76E-06 | 7.64E-06 | 7.97E-06 |
이를 통해, 딥러닝 적용 결과의 유효성을 확립하기 위해서 최소 3개 이상의 마이크로폰이 필요한 것을 알 수 있다. 2개의 마이크로폰으로는 cone of confusion에 의하여 도달시간차를 통한 정확한 방위각 추정이 어려운 점을 고려하였을 때, 이는 충분히 보상 가능한 조건이라 생각할 수 있다.
본 연구에서는 음원 추정을 위한 가장 기본적인 마이크로폰 배열로부터 딥러닝 모델 적용 가능성을 검토하였으며, 향후에는 딥러닝 모델의 최적화를 위한 마이크로폰 배열 및 마이크로폰 개수에 대한 분석이 필요하다.
IV. 실험을 통한 검증
제안 모델의 도달시간차 추정 성능을 확인하기 위한 실험적 검증을 수행하였다. Fig. 2(b)와 같은 정삼각형 형태의 마이크로폰 배열을 사용하였으며, 무향실 내에서 임의의 252개 방향에서 전파되는 음원에 대한 측정을 수행하였다.
본 실험에서는 실제 마이크로폰을 사용함으로써, 실험 수행에 따라 발생할 수 있는 측정 오차를 포함한다. 또한, 마이크로폰의 간격을 0.14 m로 설정하여 딥러닝 모델이 다양한 크기를 갖는 마이크로폰 어레이에 적용될 수 있는지에 대한 여부를 확인하였다. 따라서, 측정 데이터의 일부는 마이크로폰 간격조정에 따른 정밀 보정을 위해 사용되었다.
실험 결과 중 하나를 선정하여 Fig. 5에 나타내었다. 그 결과, 에 비해서 가 를 더욱 정확하게 추정하는 것을 볼 수 있다. 딥러닝을 적용하지 않은 결과에서는 실험 조건에 따른 편차가 크게 나타나는 반면, 딥러닝을 적용한 실험 결과에서는 실험 조건이 바뀌어도 강건한 추정 특성을 나타내는 것을 보여준다. Table 2에 실험 결과에 대한 정량적인 분석 결과를 나타내었으며, 그 결과 기존 방법 대비 평균 오차가 54 % 저감된 것을 볼 수 있다.

Table 2.
Experiment results of mean absolute error for averaged TDOA estimation using 3 microphones.
| Average | ||||
| Previous | 2.30E-05 | 2.36E-05 | 1.50E-05 | 2.06E-05 |
| Deep Learning based | 1.25E-05 | 7.77E-06 | 8.18E-06 | 9.40E-06 |
본 실험에서는 자유음장조건에 대한 딥러닝 모델의 특성을 관찰하였으며, 향후에는 배경소음 및 잡음을 포함하는 일반적인 공간에서 제안된 딥러닝 모델의 적용 가능성을 검토할 필요가 있다.
V. 결 론
본 연구에서는 마이크로폰 배열을 통해 계산된 상호상관함수에서 도달시간차를 추론하기 위한 딥러닝 기반 접근 방법을 적용하였다. 이 방법은 실제 측정결과로부터 계산되는 상호상관함수에 내재하는 양자화에 따른 정보 손실로 인한 오차를 보상하여 시간지연 계산 정확도를 향상시킨다. 이를 검증하기 위해 간단한 구조의 배열 구성으로부터 시뮬레이션 및 실험을 수행하였고, 그 결과 본 연구에서 제시하는 딥러닝 기반의 접근법의 강건성을 검증하였다. 결론적으로 딥러닝 기반의 방법은 높은 해상도의 시간분해능을 가지는 도달시간차 계산을 수행할 수 있고, 이를 통해 높은 공간분해능을 갖는 음원 위치 추정자로써 음원의 위치를 정확하게 추정하는데 적용할 수 있다.
