

I. 서 론
최근 인터넷과 무선 네트워크를 통해 모니터링 대상의 행동패턴, 생체 신호, 주변 환경과 같은 데이터를 적용하여 언제 어디서나 모니터링 대상을 확인할 수 있도록 하는 사전 예방적이고 지능적인 스마트 모니터링 시스템이 연구되어 다양한 분야에 적용되고 있다.[1,2]
이러한 모니터링 시스템은 위급한 비상상황이 발생하였을 경우, 특히 장애인, 노인 및 어린이와 같은 안전 취약 계층을 위해 중요한 기능을 수행한다. 실내 환경의 위험 상황을 알리기 위해 실내 총격 소리 검출,[3] 외부 침입자 소리 검출[4]과 같은 연구가 활용 될 수 있다. 또한 실외 환경에서 화재 현장 비명소리 인식,[5] 범죄 현장 소리 인식[6] 등을 통해 위급 상황을 검출할 수 있다.
그러나 정확한 비상상황을 제대로 모니터링 하기 위해서는 실내 공간 내에 카메라 또는 소리 센서나 그에 상응하는 장비를 설치해야 고품질 서비스가 가능하다. 또한, 다양한 상황을 실시간으로 자동적으로 식별하여 비상 시 전송 시스템을 통해 보호자와 가족에게 알리는 지능형 시스템이 필요하다.
현대인에게 일상생활의 필수 요소가 된 스마트폰은 이제 단순한 전화, 문자 등 통신 기능만을 사용하는 것이 아닌 다양한 분야의 도구로 사용되고 있는데, 특히 스마트폰의 내장된 센서는 사용자의 상황인지를 위해 유용하게 활용될 수 있다.[7]
이로 인해, 스마트폰의 센서를 이용해 사용자의 행동을 분석하여 제공하는 어플리케이션 개발이 매우 활발히 진행되고 있다.[8]
본 논문에서는 소리와 활동 등의 두 가지 유형의 상황정보를 사용하여 실내 위급상황을 인식할 수 있는 효과적인 모바일 접근 방식을 제안한다. 제안된 방법에서는 모니터링 하는 사람의 비상상황이 자동으로 감지되고 알림이 보호자에게 빠르게 전달됨으로써 보호자가 인터페이스에서 제공된 세부 정보를 사용하여 비상 상황을 대처할 수 있게 한다.
II. 제안하는 시스템의 구조
Fig. 1은 제안된 실내 비상상황 인식 시스템의 프로세스 흐름을 나타낸다.
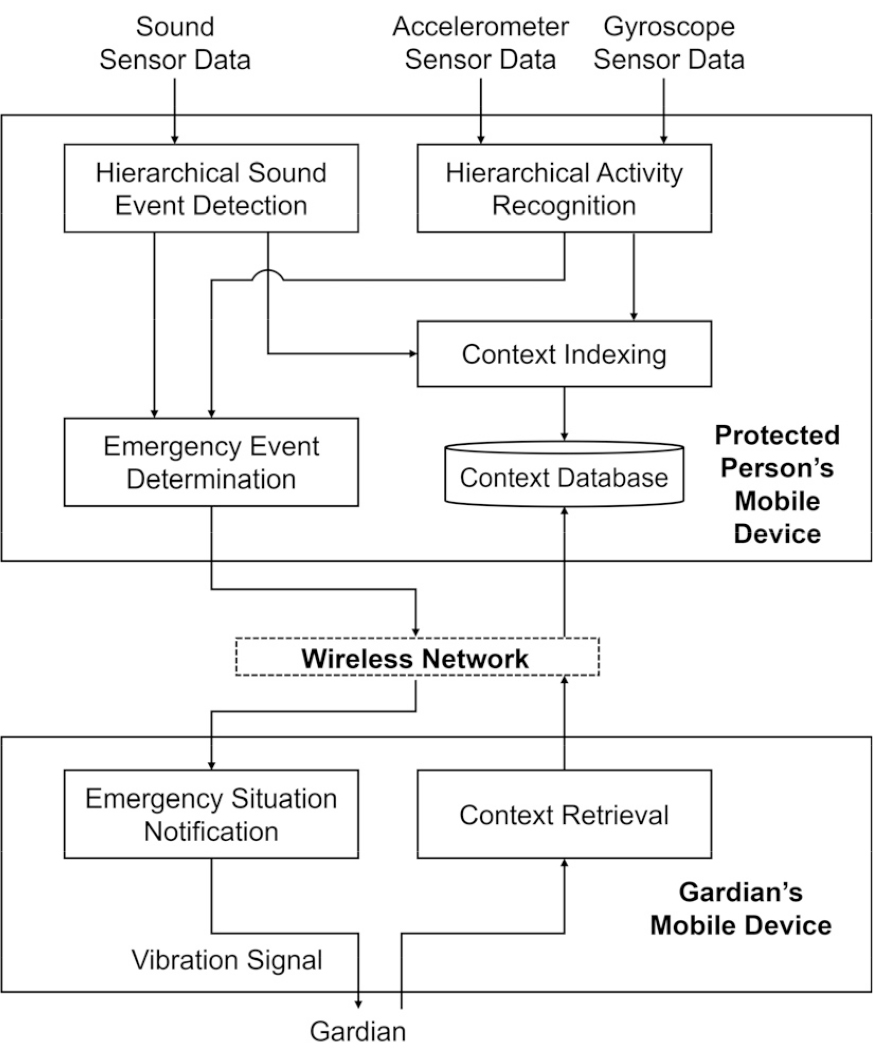
제안하는 시스템은 보호 대상자의 모바일 기기에 있는 실내 비상상황 인식과 보호자 모바일 기기에 있는 모니터링 인터페이스 등의 두 부분으로 구분된다. 실내 비상상황 인식은 계층적 사운드 이벤트 검출, 계층적 활동 인식, 비상상황 결정, 컨텍스트 색인 및 저장으로 구성된다.
계층적 사운드 이벤트 감지 모듈은 입력되는 사운드로부터 비상상황과 관련된 사운드 이벤트를 감지하며, 사운드 이벤트에는 실내 환경과 보호 대상자로부터 직접 발생하는 사운드가 모두 포함된다.
반면, 계층적 활동 인식 모듈은 입력 가속도계 및 자이로스코프 센서 데이터에서 비상상황과 관련된 활동을 독립적으로 인식한다.
감지된 비상 사운드와 활동의 결과를 결합하여 비상상황이 결정되면 시스템은 모바일 전송 모듈을 사용하여 보호자 또는 가족 구성원에게 비상상황 경보 신호를 전송하고, 보호자가 보호 대상자의 상황을 검색할 수 있도록 상세한 사운드 이벤트 및 활동 유형이 색인화되어 시간표 형태의 컨텍스트 데이터베이스에 저장된다.
2.1 계층적 사운드 이벤트 검출
Fig. 2는 제안된 계층적 사운드 이벤트 분류 모듈을 나타내며, 두 개의 계층으로 구성된다. 첫 번째 계층은 보호 대상자의 모바일 기기에 입력된 사운드를 비상 사운드 이벤트(Emergency Sound Event, ESE), 또는 일반 사운드 이벤트(Normal Sound Event, NSE)라는 두 개의 클래스 중에서 하나로 분류하여 비상 상황 감지(Emergency Situation Detection, ESD)을 확인한다.
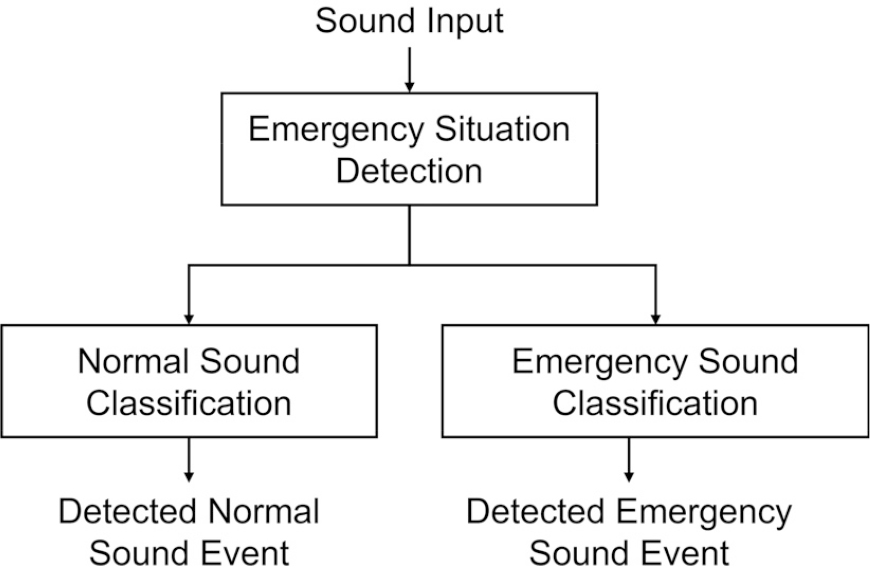
전체 사운드 데이터의 23개 클래스 중 아기울음, 유리 깨짐, 접시 떨어짐, 비상경보, 비명, 신음, 구조 요청, 떨어지는 물체로부터 발생하는 8개 사운드 이벤트가 비상 사운드 이벤트 클래스에 속한다.
반면, 끓는 물, 수돗물 소리, 휴대폰 벨소리, 개 짖는 소리, 문 닫힘, 서랍 닫힘, 초인종, 문손잡이 흔들림, 문 두드리는 소리, 대화 소리, 음악, 전화 벨소리, 슬라이딩 도어 소리, 청소기 소리, 배경음과 같은 15개의 사운드 이벤트가 일반 사운드 이벤트 클래스에 포함된다.
두 번째 계층은 첫 번째 계층에서 감지된 사운드 이벤트의 특정 레이블을 상세하게 분류한다. 즉, 첫 번째 계층에서 발생하는 비상 사운드 이벤트는 8가지 비상 사운드 이벤트 중 하나로 분류된다. 반면, 첫 번째 계층에서 발생하는 일반 사운드 이벤트는 15가지 일반 사운드 이벤트 중 하나로 분류된다.
비상상황을 감지하고 높은 정확도로 상세한 사운드 이벤트를 분류하기 위해 사운드 신호로부터 로그 스펙트로그램을 추출하여 합성곱층을 통과하여 자기주의 잔차 시간적 합성곱 신경망(Self-Attentive Residual Temporal Convolutional Networks, SARTCN)에 적용한다.
2.2 계층적 인간 활동 인식
Fig. 3은 제안된 두 개의 계층으로 구성된 계층적 활동 인식 모듈의 구조를 보여준다. 첫 번째 계층은 보호 대상자의 모바일 기기에 입력된 가속도계와 자이로스코프 신호가 비상 활동인지 정상 활동인지를 판별하는 활동 인식을 한다. 비상 활동 인식(Emergency Activity Recognition, EAR) 시, 인식된 정보는 비상 이벤트 결정 모듈에 입력된다. 반면, 정상 활동 인식(Normal Activity Recognition, NAR)의 경우에는 두 번째 계층에서 7가지 정상 활동 클래스 중 하나로 분류된다.
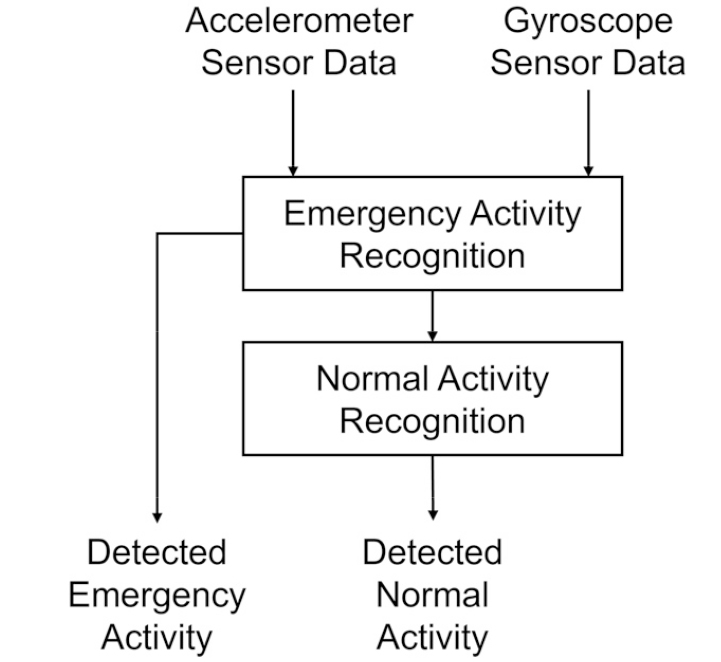
가속도계와 자이로스코프 신호의 전체 활동 인식 데이터 세트의 9개 클래스는 큰 범주로 비상 및 정상 활동으로 구분된다. 2개의 “넘어짐”, “떨어짐”은 비상 활동의 범주이고, 7개의 “걷기”, “앉기”, “서기”, “누워 있기”, “점프하기”, “계단 내려오기”, “계단 오르기”는 정상 활동 범주에 포함된다.
비상상황을 감지하고 높은 정확도로 상세한 활동을 분류하기 위해, 우리는 사운드 이벤트 신호와 다르게 가속도계와 자이로스코프 신호를 스펙트럼 변환과 합성곱 연산 없이 바로 SARTCN에 적용하였다.
2.3 SARTCN
사운드 이벤트 및 활동 인식에는 정확도 성능향상을 위해 SARTCN이 공통적으로 적용된다.
사운드 이벤트 검출을 위하여, 사운드 신호는 로그 스케일 스펙트럼으로 변환되고, 컴팩트한 중간 표현을 학습하기 위해 세 개의 합성곱층에 순차적으로 입력된다. 우리는 30 ms의 윈도우 크기와 동일한 지속 시간의 홉 크기를 사용하여 가청 주파수 범위를 포함하는 40개 대역의 로그 스케일 스펙트로그램을 추출하였다.
연속된 두 개의 합성곱 계층은 주파수 방향으로 3개의 빈에 대한 후속 최대 풀링이 있는 3 × 3 크기의 필터 16개가 있고, 마지막 세 번째 계층은 풀링 없이 1 × 8 크기의 필터 16개가 존재한다. 이런 식으로 5개 프레임의 컨텍스트를 가진 작은 스펙트로그램 조각이 단일 프레임과 16개 특징으로 축소된다. 지수 선형 단위(Exponential Linear Unit, ELU)는 합성곱 계층에서 활성화 함수로 사용되고, 그 후에 0.1의 드롭아웃 비율이 적용되었다. 이렇게 추출된 16차원의 특징은 SARTCN 네트워크에 입력된다.
Fig. 4에 따르면, SARTCN은 Residual Temporal Convolutional Networks(RTCN)[9]와 셀프 어텐션 메커니즘[10]의 두 부분으로 구성된다. 이 중 RTCN은 16차원의 특징과 사운드 이벤트 간의 상관관계 모델링을 완료하는 반면 셀프 어텐션 메커니즘 계층에서는 특징이 전달하는 사운드 이벤트 정보의 비율에 따라 가중치를 재분배한다. RTCN 네트워크는 TCN과 잔여 연결로 구성된다. TCN 네트워크는 특징 시퀀스를 병렬로 처리하여 사운드 이벤트 정보를 학습한 다음 잔여 연결을 사용하여 모델이 학습 프로세스 중에 안정적인 그래디언트 최적화 경로를 생성하도록 한다.
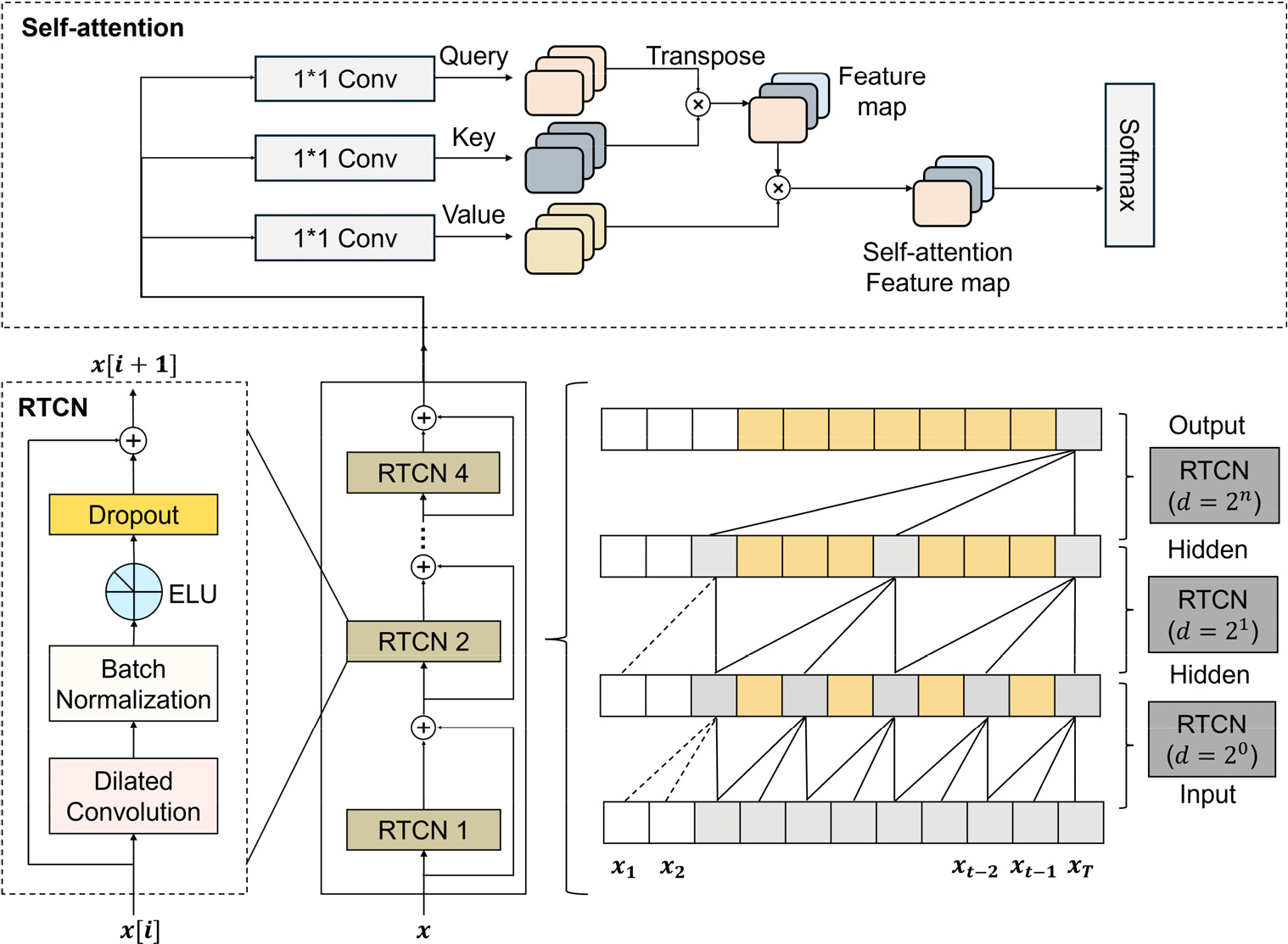
Fig. 4의 좌측은 RTCN의 번째 블록의 연산 과정을 보여준다. 먼저, 입력 특징 는 확장된 합성곱 계층을 통과한 후 배치 정규화, ELU 활성화 함수, 드롭아웃 계층을 차례로 통과한다. 그리고 드롭아웃 계층의 출력은 와 융합하여 을 생성하고 이는 RTCN의 +1번째 층의 입력으로 공급된다. 여기서 는 시퀀스의 길이 또는 시간 단계의 총 수를 나타낸다. 즉, 각 입력 는 개의 시간 단계로 구성된 시퀀스 이다.
확장된 합성곱 계층의 Dilation rate는 블록이 깊어질수록 증가하여 넓은 시간적 컨텍스트를 고려할 수 있도록 한다. Dilated convolution은 입력 시퀀스의 원소들 사이에 특정 간격을 두고 합성곱을 수행한다. Dilation rate에 따른 1차원 Dilated convolution의 출력은 다음과 같이 계산된다:
여기서 는 출력, 는 입력 시퀀스, 는 필터의 가중치, 는 필터 크기, 는 Dilation rate이며, 로 설정하여 점진적으로 넓은 수용 영역을 얻을 수 있다.
RTCN 계층의 출력은 셀프 어텐션 메커니즘 모듈에 직접 공급되고, 자기 주의적 메커니즘의 쿼리와 키를 곱하여 사운드 이벤트 가중치 특징을 얻고, 이를 값에 적용하여 로컬 자기 주의적 가중치 특징을 높인다. 즉, 자기 주의적 메커니즘의 쿼리와 키를 곱하여 자기 주의적 가중치 특징을 생성한다.
여기서 는 각각 쿼리 벡터, 키 벡터, 값 벡터를 의미하며, 는 키 벡터의 차원 수로, 계산의 안정화를 위해 스케일링에 사용한다. , , 는 학습 시 사용하는 가중치로 학습 과정에서 갱신된다. 그리고 소프트맥스 함수를 통해 각 쿼리-키 간의 내적 값을 확률 분포로 변환한다. 이렇게 구한 확률 분포를 통해 사운드 이벤트 분류를 수행한다.
활동 인식은 사운드 신호에서 수행되었던 로그 스펙트럼 변환과 세 개의 합성곱 계층에 로그 스펙트럼을 적용할 필요 없이 가속도계와 자이로스코프로부터 획득된 시간축 신호가 직접 SARTCN에 입력되어 활동 분류가 수행된다.
최종적으로 제안하는 시스템의 비상 상황 감지는 계층적 사운드 이벤트 검출 모듈과 계층적 인간 활동 인식 모듈에서 모두 비상상황으로 감지한 경우에만 비상 상황으로 분류한다.
III. 실험 및 결과
제안된 시스템은 3개 층으로 구성된 사무실 건물에서 평가되었다. 각 층에는 계단, 복도, 3개의 사무실이 있다. 사운드 이벤트 감지 성능을 평가하기 위해 사무실 건물에서 스마트폰을 통해 실제 사운드를 녹음했으며, 총 녹음 시간은 558 min이다. 그 중에서 학습 및 검증을 위해서는 390 min의 데이터가 사용되었고, 테스트를 위해서는 168 min의 데이터를 사용했다. 학습, 검증, 테스트 데이터의 분배 비율은 4:3:3으로 구성한다. 학습데이터의 비상 사운드 이벤트 클래스의 데이터와 일반 사운드 이벤트 클래스의 데이터의 비율이 유사하도록 배분을 하였다.
녹음은 16 kHz 샘플링 속도와 16비트 해상도를 사용하여 수행되었다. 총 23개의 사운드 이벤트 클래스로 구성되며, 그 중 8개의 사운드 이벤트가 비상 사운드 이벤트 클래스에 포함되고 15개가 일반 사운드 이벤트 클래스에 포함된다.
활동 인식 성능을 평가하기 위해 사무실 건물 공간에서 9가지 활동에 대한 스마트폰의 가속도계 및 자이로스코프 센서 데이터를 수집했으며, Android API의 센서 관리자를 사용하여 가속도계 데이터는 50 Hz로 샘플링 되도록 설정했다. 실험에는 16 ~ 60세 사이의 25명의 참가자가 참여했으며, 스마트폰은 사용자의 주머니에 보관하여 실험을 수행했다. 총 9개의 활동 클래스 중 2개는 비상 활동, 7개는 정상 활동에 포함된다. 활동 인식의 수집된 데이터는 학습, 검증, 테스트를 4:3:3 비율로 구성하여 실험에 사용하였다.
실험을 위해, 우리는 7개의 센서 판독값을 지원하는 상용 안드로이드 스마트폰(옥타코어 2.3 GHz CPU와 8 GB RAM)에 제안된 실내 비상 상황 인식 알고리즘을 구현했다. 스마트폰의 리소스가 제한되어 있기 때문에, 우리는 모바일 기기에 적용하기 전에 서버에서 학습된 모델의 크기를 줄이기 위해 8비트 양자화를 적용했다. 문맥 정보의 인식은 병렬 처리로 수행되고, 전체 시스템은 3 s마다 비상상황 인식을 수행한다. 제안된 방법을 적용할 때 CPU 사용량은 51 %이고 메모리 크기는 85 MB이다. 실험 환경에서는 녹음된 테스트 데이터를 별도로 재생하여 테스트용 스마트폰으로 다시 수신하여 테스트 하였다.
Table 1은 사운드 이벤트 검출에서 제안된 SARTCN 방식에 macro average를 적용하여 RTCN, TCN 방식의 사운드 이벤트 검출 정확률과 비교한 4가지의 상황에 대한 실험결과를 보여준다. 이는 첫 번째 계층에서의 2개 클래스에 대한 비상 상황 감지(ESD), 두 번째 계층에서 15개의 일반 사운드 이벤트(NSE), 8개의 비상 사운드 이벤트(ESE)의 분류, 마지막으로 계층 구분 없이 23개의 통합된 사운드 이벤트 검출(Integrated Sound Event Detection, ISED)에 대한 결과이다. 이는 5일 동안 하루에 4번씩 수행한 실험에서 얻은 평균 결과를 나타낸다.
Table 1.
Sound event detection results.
| Model | SARTCN | RTCN | TCN |
| ESD | 100 % | 98.5 % | 95.1 % |
| NSE | 94.6 % | 92.4 % | 84.6 % |
| ESE | 97.8 % | 95.7 % | 90.4 % |
| ISED | 83.9 % | 81.5 % | 72.7 % |
| Average | 94.1 % | 92.0 % | 85.7 % |
실험 결과 4가지의 상황에 대하여 SARTCN의 평균 정확도는 94.1 %로 다른 방법보다 훨씬 우수하였다. 비상 상황 인식에서 SARTCN 방법은 100 %, 그리고 RTCN은 98.5 %의 정확도에 도달하였다. 반면, 23개의 사운드 이벤트 분류결과는 다른 분류결과보다 전체적으로 저조함을 알 수 있었다. 셀프 어텐션 방식을 갖추지 않은 RTCN의 방식은 TCN 방식보다 분명하게 우수한 반면, 제안된 SARTCN의 방식보다 낮았다. 그 이유는 셀프 어텐션 메커니즘은 RTCN이 출력한 피처 맵의 가중치를 효과적으로 재지정하여 합성곱 특징의 유사 사운드 이벤트 간의 정보를 더욱 완벽하게 탐색할 수 있기 때문이었다.
Table 2는 시계열 가속도계와 자이로스코프 신호를 사용하여 사람의 9가지의 활동 유형을 3가지 상황에 따라 인식한 결과를 제공한다. Table 2에서 보듯이 SARTCN 방식은 2개의 비상 활동 인식(EAR), 7개의 정상 활동 인식(NAR), 그리고 9가지 통합 활동 인식(Integrated Activity Recognition, IAR)에서 RTCN과 TCN보다 우수한 성과를 보인다. 정상 활동의 경우, 사람의 작은 움직임이 유사한 활동 클래스로 인해 분류에 잘못된 영향을 미칠 수 있다.
Table 2.
Human activity recognition results.
| Model | SARTCN | RTCN | TCN |
| EAR | 100 % | 100 % | 96.2 % |
| NAR | 95.7 % | 93.2 % | 87.8 % |
| IAR | 93.5 % | 91.4 % | 84.5 % |
RTCN과 TCN은 시계열 데이터의 장단기 패턴을 포착할 수 있지만, 작은 움직임의 중요성을 동적으로 평가하는 데 한계가 있다. 반면 SARTCN은 RTCN의 시간적 의존성 모델링 능력과 셀프 어텐션 메커니즘을 결합하여, 작은 움직임의 시간적 관계를 더 효과적으로 포착하고 그 중요성에 따라 가중치를 부여한다. 이를 통해 SARTCN은 작은 움직임이 중요한 역할을 하는 복잡한 활동을 더 정확하게 분류하고, 노이즈와 유의미한 신호를 더 잘 구분하여 인식 정확도를 향상시킨다.
종합적으로 사운드 이벤트와 인간 활동 인식을 결합한 비상상황 인식에 대한 실험 결과는 Table 3과 같다. 비상상황 인식의 계산을 위하여 계층적 사운드 이벤트 검출과 계층적 인간 활동 검출의 출력을 AND 연산을 통해 통합적으로 고려하였다. 이 과정에서 각 검출의 True Positive Rate(TPR)를 계산하였다. TPR은 실제 발생한 비상상황 중 시스템이 정확하게 비상상황으로 식별한 비율을 나타내며, 이는 시스템의 비상상황 감지 능력을 반영한다.
Table 3.
Emergency awareness results combining sound and human activity.
| Model | SARTCN | RTCN | TCN |
| Accuracy | 93.7 % | 91.4 % | 84.8 % |
최종 비상상황 인식의 TPR은 사운드 이벤트 검출의 TPR과 인간 활동 검출의 TPR을 곱하여 계산하였다. 이는 두 검출기에서 모두 비상상황으로 판단한 경우에만 최종적으로 비상상황으로 인식하는 접근 방식을 반영한다.
실험 결과, 제안하는 SARTCN 모델은 93.7 %의 정확도로 RTCN(91.4 %)과 TCN(84.8 %) 모델보다 우수한 성능을 보였다. 이는 SARTCN 모델이 사운드 이벤트와 인간 활동을 더 정확하게 감지하고, 두 정보를 효과적으로 통합할 수 있음을 나타낸다.
IV. 결 론
본 논문에서 소리와 인간 활동, 이 두 가지 유형의 상황 정보를 사용하여 실내 비상 인식을 위한 효과적인 모바일 접근 방식을 제안했다.
3개 층으로 구성된 작은 건물에서 수행한 실험 결과에 따르면 제안된 시스템은 사용자의 요구를 충족하고 모든 실용적인 모바일 기기에서 사용하기에 적합한 높은 정확도의 비상 상황 인식 성능을 제공한다. 향후에는 백화점이나 쇼핑센터와 같은 대규모 실내공간 뿐만 아니라 실외 공간에도 효과적으로 적용 가능한 상황 인식 시스템을 구현하여 제안된 시스템을 확장하고, 뇌파신호의 측정을 통해 비상 상황 시의 사용자의 상태를 함께 탐구하고자 한다.
