

I. 서 론
수중에서는 감쇄로 인해 몇 미터 밖의 거리에서도 광학 영상으로는 대상을 판별하기 어렵다. 수중에서는 감쇄가 상대적으로 적은 음파를 사용한다. 음파는 빛에 비해 파장이 길며, 수중은 해양 잡음이 존재하므로 광학 영상보다 해상도가 떨어진다. 이러한 한계를 극복하기 위해 음파를 이용한 사이드 스캔 소나, 합성 개구 소나 영상 분야의 수중 탐사에 대한 연구가 활발히 진행되고 있다. 해저 지형 영상은 3채널인 광학 영상과는 달리 단일채널 영상이며 흑백 영상으로 표현이 가능하다.
사이드 스캔 소나나 합성개구 소나 같은 영상 소나가 장착된 Automatic Under Vehicle(AUV)는 물체를 찾기 위한 장거리 탐색에 적합하다. AUV에 의한 탐색은 기뢰, 난파선, 익사자, 해저지형을 탐지하고 분류하며 군사 및 상업 용도로 널리 사용된다. AUV로 사이드 스캔 소나, 합성 개구 소나를 이용해 수중을 탐색함으로써 저위험, 저비용으로 광대한 지역에 대한 영상 획득이 가능하고 수중 물체의 자동 표적 인식(Automatic Target Recognition, ATR)의 입력으로 사용될 수 있다. 수중 물체에 대한 ATR에서 수중 표적으로는 기뢰, 잠수함, 익사체, 침몰된 선박 등이 될 수 있다.
표적의 자동 탐지 및 식별 알고리즘으로는 인공지능 방식이 적용될 수 있으며 Convolutional Neural Network(CNN) 기반의 딥러닝 기술이 표적 탐지 및 식별 알고리즘으로 활발하게 적용되고 있는 추세이다. 딥러닝은 은닉된 대상을 찾기 위해 2개 이상의 계층을 포함하는 신경망으로 구축된다. CNN이 해저 분류 및 객체 분류에 사용되었고 여러 계층의 CNN을 사용하는 딥러닝 접근 방식으로 정확도를 높일 수 있다.[1]
딥러닝에서 영상 표적의 자동 탐지 및 식별을 위해서는 일반적으로 객체 검출 알고리즘이 적용되는데, 객체 검출 알고리즘은 분류를 다루는 문제와 영상 분할을 통해 표적의 위치를 나타내는 지역화(Localization) 문제로 구분된다. 딥러닝 알고리즘은 하나의 물체를 분류하고, 위치를 찾은 후 슬라이딩 윈도우 방식으로 영상 전체를 훑어서 해결한다. CNN 방식은 간단하고 쉬운 방법이지만, 여러 번 실행하므로 느리다는 문제가 있다. 위의 비효율성을 개선하기 위해 물체가 존재할 가능성이 높은 윈도우를 탐색하는 방법[2]이 개발되어 있으며 이는 1-stage detector와 2-stage detector로 분류할 수 있다. Object Detection은 Classification, Localization 두 가지를 합한 문제이다. 2-stage는 이 두 문제를 순차적으로 해결하고, 1-stage는 동시에 해결한다. 2-stage에 비해 1-stage가 속도 면에서 더 우수한 성능을 보이지만, 정확도는 2-stage가 더 높다. 1-stage detector로는 You Only Look Once(YOLO)와 Single Shot Multibox Detector(SSD)방식이 있으며 YOLO는 속도가 빠르지만 저해상도인 수중영상에서는 적합하지 않을 수 있고, SSD 방식은 표적의 크기가 작은 수중영상에서 적용이 어려울 수 있다. 2-stage detector 방식은 Regions with Convolutional Neural Networks(R-CNN)이 있으며, R-CNN은 첫 번째 모듈에서 영상 데이터를 입력받아서 물체를 인지하고 분류하는 Bounding Box를 찾는다.[3]
R-CNN은 이 단계에서 Selective Search라는 알고리즘을 이용해서 ‘임의의’ Bounding Box를 설정한다. Selective Search 알고리즘은 Segmentation 분야에 많이 쓰이는 알고리즘이며, 객체와 주변 간의 색감, 질감 차이, 다른 물체에 에워 쌓여 있는지 여부 등을 파악해서 인접한 유사한 픽셀끼리 묶어 물체의 위치를 파악할 수 있도록 하는 알고리즘이다.[4] 첫 번째 모듈인 Region Proposal에서 사용되는 Selective Search는 CPU를 사용하는 알고리즘이다. 그리고 이 Selective Search에서 뽑아낸 2000개의 영역 영상들에 대해서 모두 CNN 모델에 넣는다. R-CNN은 전처리 과정이 필요하며 전처리 과정 속도가 느려 실시간 적용이 어렵다는 단점이 있다. 또한 수중영상에서는 수중잡음과 불명확한 표적의 형상에 따라 Region Proposal 알고리즘 성능이 낮을 수 있다.
따라서 본 논문에서는 수중영상과 수중 표적에 적합한 모폴로지를 이용한 Segmentation 방법을 제안한다. 모폴로지를 이용한 Segmentation은 Selective Search 알고리즘에 비해 연산량이 적고 연산 속도가 빠르며 추출된 영상의 개수가 현저히 작다. 또한 비교적 명확한 그림자 영역을 이용하여 수중표적 후보영상을 분류하므로 분류에 모호성이 적다. 따라서 모폴로지 이용하여 R-CNN의 전단계인 Segmentation 속도 및 효율성을 개선할 수 있다. R-CNN에서는 배경잡음이 그대로 있는 원본 영상을 Segmentation 하여 사용한다. 그러나 배경잡음은 표적의 형상을 인식하기 어렵게 해서 분류 시 난이도가 있는 과정이 진행될 수 있고 분류 성능도 좋지 않을 수 있다. 본 연구에서는 R-CNN의 입력으로 3-모드 영상을 제시하며 이를 이용하면 R-CNN의 성능을 개선할 수 있을 것이다.
모폴로지는 일반적으로 동물과 식물의 형태와 구조를 다루는 생물학의 한 분야이다. 영상처리에서 모폴로지 연산은 영역 형태를 표현하는데 사용되며 필터링과 같이 영상의 전후처리에 사용되기도 한다. 모폴로지 기법이 소나 영상에도 적용되었는데 수중영상의 잡음을 개선하는데 사용되거나[5] 표적의 영역을 구분하고[6] 윤곽을 구하는데[7] 사용이 되었다. 그러나 이와 같은 연구는 표적이 육안으로도 명확히 구분되는 경우나 표적의 크기가 상당한 물체(침몰한 선박 혹은 비행선)에 적용된 사례이며 표적과 주변 근처만 배경이 존재하는 수중영상이었다. 본 연구에서는 수중영상에서 표적의 크기가 작아 분별이 잘 안되고 실제 사이드 스캔 소나 영상에서 지형과 고도선이 존재할 때 모폴로지를 이용하여 Segmentation 하는 과정을 적용한다.
II. 모폴로지 Segmentation 알고리즘
수중에서 표적은 광활한 해저지형에 비해 국소적이며 또한 수중영상에서 배경 잡음과 표적의 픽셀값은 다르지만 명암 형태가 유사하여 표적을 구분해 내는 것은 쉽지 않은 작업이다. 반면에 수중영상에서 그림자는 표적에 비해 일정한 픽셀값을 유지하며 잡음의 편차가 크지 않고 표적 및 배경 영역과 구분되는 특성을 갖는다. 따라서 본 연구에서는 그림자를 이용해 표적 영역을 추출한다.
모폴로지를 이용한 Segmentation 알고리즘의 과정은 1. 고도선 정의, 2. 히스토그램 평활화, 3. 고역통과 필터, 4. 모폴로지 처리, 5. 레이블링으로 구분된다.
소나 영상의 가로축으로 해저지형의 후방산란 이전에 중간 지점에서 고도선까지 영역이 수중으로부터 산란되는 신호로 인해 거의 흑색으로 표시되는데 이 영역이 모폴로지 처리를 할 때 혼선을 줄 수 있으므로 고도선 정의를 통해 고도선 이하 영역을 제로인 흑색으로 대치한다.
히스토그램 평활화는 소나 영상의 명암의 히스토그램이 한쪽으로 치우쳐서 영상이 전체적으로 너무 밝거나 어두울 때 전체 영상이 균일한 픽셀값을 갖도록 조정하는 작업이다.
고역통과 필터 적용은 굴곡이 낮은 지형의 영향을 제거하고 거리에 따라 신호가 감쇄하는 Time Varied Gain(TVG) 보상을 포함한다.
모폴로지 기법은 영상의 기본적인 특징은 유지하면서 형태에 변화를 주는 처리이다. 형태소는 일종의 마스크이며 형태소를 이용해 침식, 팽창을 수행한다. 침식은 형태소들이 입력영상과 일치했을 때를 의미하며 팽창은 형태소들이 입력영상과 히트했을 때를 의미한다. 재구성은 입력 영상의 반복적인 팽창을 수행하며 마스크 영상에 의해 제한된다.[8] 본 연구에서는 형태소의 사이즈를 실제 사이드 스캔 소나 영상의 잡음 형태에 맞게 조정하였다.
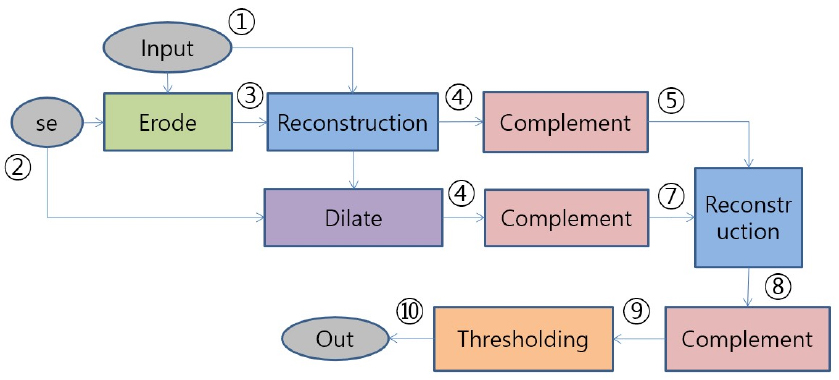
모폴로지 알고리즘의 순서도는 Fig. 1과 같다.[9] 순서 ①에서 영상이 입력되고, 순서 ②에서 침식을 통해 배경의 흰색 잡음이 축소되며 흑색 그림자가 확장된다. 순서 ③에서 배경은 입력 영상의 흑색 픽셀값으로 평준화되며 순서 ⑤에서 영상은 반전된다. 순서 ④의 팽창에 의해 배경잡음이 모두 뭉그러지며, 순서⑥ 영상의 반전인 순서 ⑦과 순서 ⑤의 영상이 순서⑧에 의해 재구성되어 흰색 배경잡음이 배경의 상대적으로 검은 픽셀까지 떨어진다. 순서 ⑨은 결과의 반전 영상으로 순서 ⑩에서 임계값에 의해 이진화된다. 모폴로지 처리 과정으로부터 배경과 표적 영상의 Salt-and-Pepper Noise 같은 부분이 제거되고 그림자 영역만 남게 된다. Fig. 2는 모폴로지를 이용하여 수중 표적의 그림자 영역을 추출한 결과이며 본 연구에서는 수중 표적 영상에서 나아가 실제 사이드 스캔 영상에서 그림자를 추출해 Segmentation을 수행한다. 표적을 확정하는 임계값 또한 사용하는 사이드 스캔 소나 표적 후보 영상의 평균 픽셀값에 따라 조정되도록 개선하였다.

레이블링은 각각의 개체를 구분하는 방식이다. 이진화된 영상에서 수행되며 흑색 픽셀은 배경을 흰색 픽셀들은 객체로 인식하며 각각의 객체는 다른 숫자로 번호가 매겨진다. 레이블링은 4-방향 연결성 혹은 8-방향 연결성에 의해 수행되며 Grass-Fire 알고리즘, Two-pass 알고리즘으로 구분되며 Grass-Fire 알고리즘은 인접 요소가 모두 레이블링 될 때까지 재귀 호출로 검사하여 레이블링하며 Two-pass 알고리즘은 레이블링 스택을 이용하여 정보를 저장하고 반환하여 레이블링 처리를 한다. 이로써 그림자에 의해 표적은 Segmentation 될 수 있다.
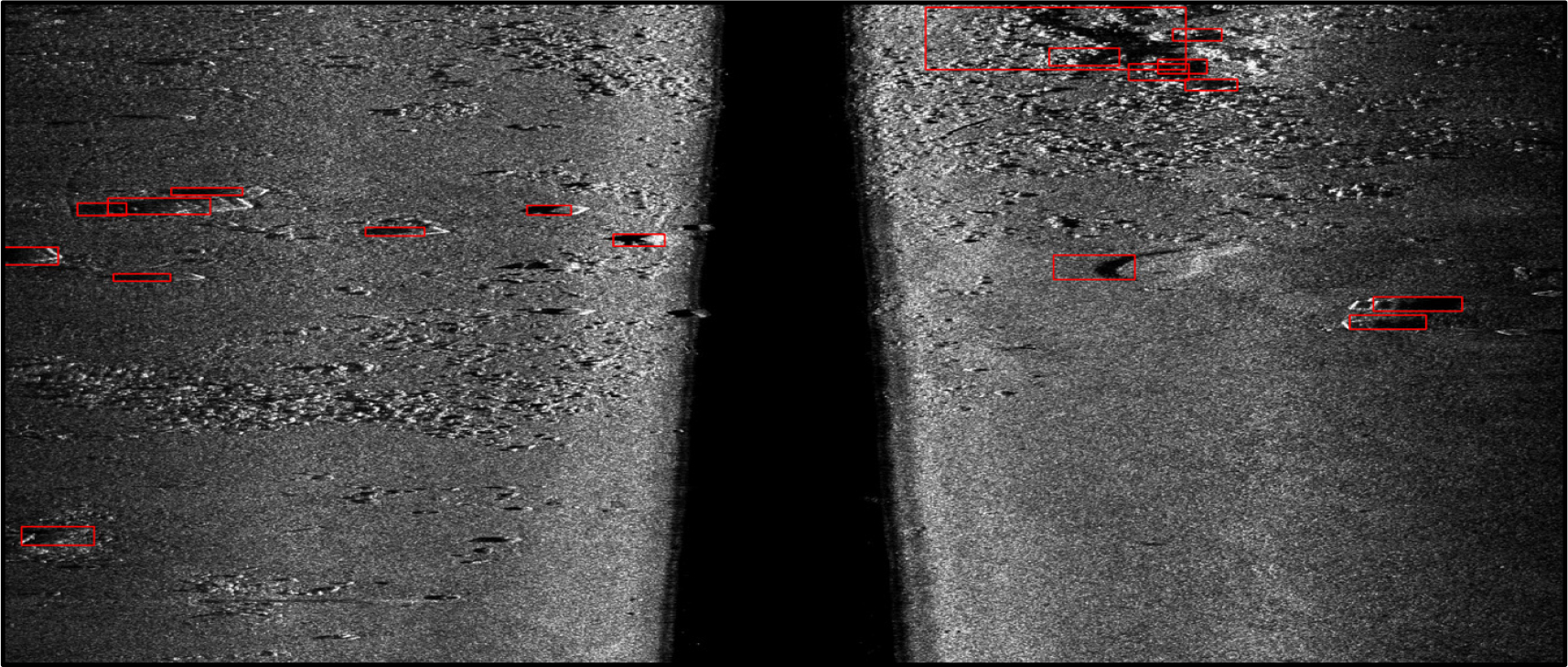
Fig. 3은 다수의 표적을 그림자를 이용하여 Segmentation 한 결과이다. 모폴로지를 이용한 Segmentation 방식은 다른 수중 Segmentation 방식과 월등한 성능을 보이며 행렬의 연산으로 처리되므로 빠른 수행 속도를 지닌다. 이전 연구[9]에서는 수행시간은 268 × 260 사이즈의 입력영상에서 Matlab으로 0.418155 s의 성능을 보여주었지만, 본 연구에서 2529 × 1181 사이즈의 입력영상에서 0.042 s로 탁월히 감소되는 결과를 보여주었다. 모폴로지 알고리즘은 C++언어로 프로그래밍 하였고, 영상처리에 사용되는 오픈소스 라이브러리인 Open Source Computer Vision(OpenCV)가 사용되었다. 모폴로지 방식은 전체 입력 영상에서 수행되며 다수의 표적 후보를 전체 영상에서 한 번에 찾으므로 속도가 빠른 편이다. 따라서 AUV에 탑재되어 실시간으로 표적 후보 영상을 추출해 내는데 적합한 알고리즘이다.
해저의 지형영상은 영상의 잡음의 크기가 어느 정도 큰 Salt-and-Pepper Noise와 같은 양상을 보인다. 이러한 배경 잡음은 표적의 명암과도 섞여 표적을 구별해내기 어렵게 한다. 따라서 배경과 표적을 분리함으로써 표적의 검출 성능을 향상시킬 수 있다.
그림자에 더 나아가 표적도 모폴로지 Segmentation을 수행하였다. 표적에 대한 모폴로지 처리는 그림자 보다 표적에 잡음의 편차가 있기 때문에 주의가 필요하다. 이는 저역통과 필터나 메디안 필터 등을 사용함으로써 해결될 수 있다. 그러나 표적 Segmentation은 표적이 인식될 때도 있고 배경에 묻히는 경우가 있어 표적 영역에서 그림자만 추출되기도 한다.
그림 Fig. 4(a)는 원본 사이드 스캔 표적 영상이며 이 영상은 딥러닝의 입력으로 해석이 어려운 영상일 수 있다. 모폴로지 Segmentation 방식을 이용하여 표적 영상에서 Fig. 4(b)와 같이 표적은 흰색, 그림자는 흑색 그리고 배경은 회색으로 표현하는 3-모드 영상을 생성할 수 있다. 3-모드 영상은 불명확한 배경의 영향이 적어 혼선을 주지 않아 딥러닝의 전처리 과정보다 딥러닝의 입력으로 유용할 수 있다. Fig. 4(c)는 3-모드 영상에서 표적과 그림자 영역에만 원래 픽셀값을 표현한 영상이다. 표적 부분의 특성이 중요할 수 있으므로 이 영상이 딥러닝에는 더 적합한 영상일 수 있다.

III. 결 론
본 연구에서 제시한 수중영상은 실해역 실험에서 얻어진 것으로, 해상 실험은 AUV에 사이드 스캔 소나를 탑재하여 수중영상을 취득하는 방식으로 진행되었다. 표적의 크기는 지름 0.5 m, 길이 2 m인 표적의 식별을 목표로 하고, 수심은 약 10 m ~ 15 m이며 최대수심 20 m인 수중환경에 적용된다. 따라서 표적의 크기가 작지 않고 어느 정도 크기가 있는 수중영상이 생성된다. 해저환경은 해저평면이 거칠지 않은 환경에 적용된다. 따라서 해저배경이 물결 무늬가 아닐 수 있으며 암벽이 적은 환경으로 유사 표적 후보가 존재해도 영상의 모든 영역에서 산출되지 않으므로 본 연구를 통한 표적의 구분과 결과 영상 획득에 적합한 환경이다. 만약, 해상 실험환경의 해저평면이 거칠거나 암벽이 다수 존재하는 경우 표적 후보가 다수 발생하므로 추가적인 연구가 필요하다.
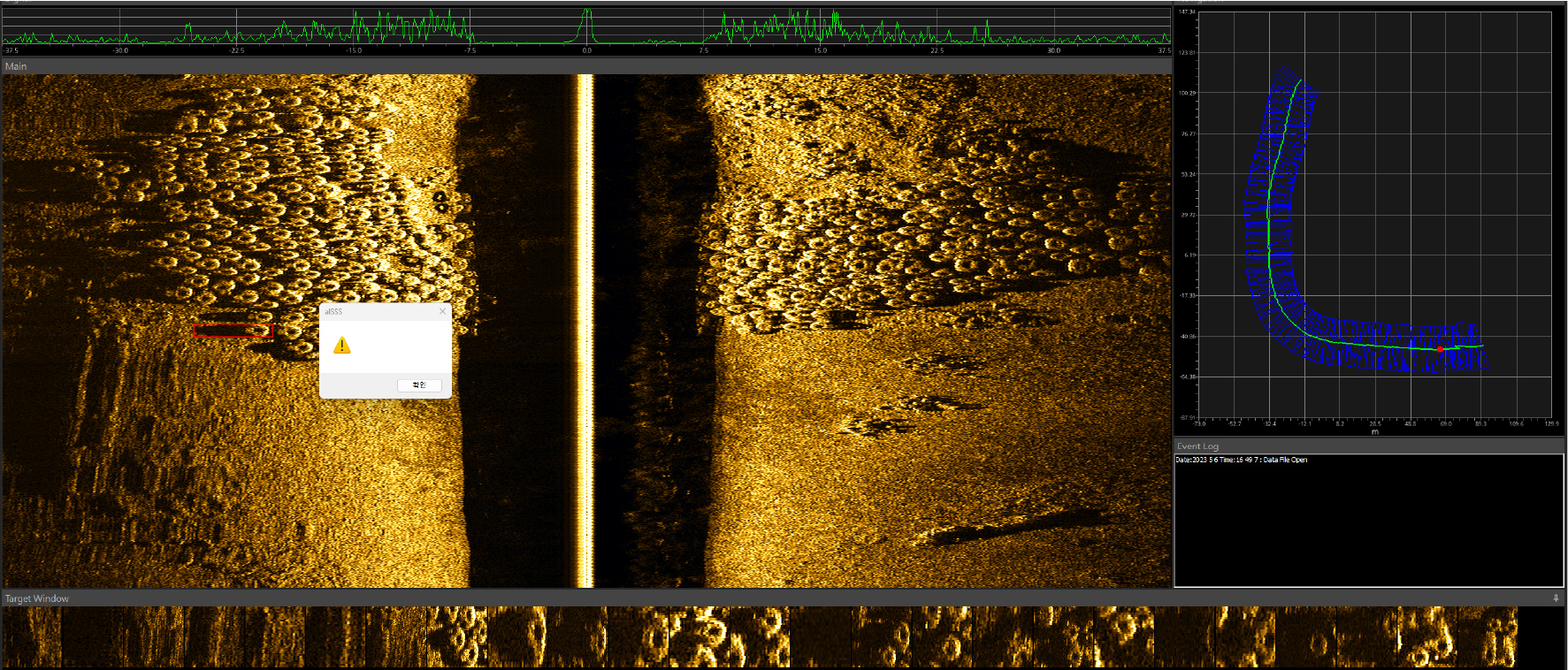
본 연구에서 제시한 3-모드 방식의 수중영상 데이터는 표적과 그림자의 특징을 함께 도시하므로, 딥러닝을 위해 보다 다양한 정보를 제공할 수 있다. 현재 모폴로지 알고리즘은 AUV에 탑재되어 있어 표적 영역의 Segmentation이 가능하다. 이는 역시 C++ 언어로 프로그래밍 되어 AUV 내에 탑재되어 있고 실시간으로 유사 표적에 대한 Segmentation 영상을 생성하고 위치를 출력한다. 또한 AUV 내에 사이드 스캔 소나 원시 파일로 저장을 하여 후처리 프로그램에서도 Global Positioning System(GPS) 위치에 대한 표적 영역이 표시된다(Fig. 5). 현재 AUV 내에 프로그램에는 그림자 추출을 통한 세그먼테이션이 적용되어 있어 표적 영역의 분류가 가능하다.
수중영상에서 표적을 식별하기 위해서는 R-CNN 같은 딥러닝 방법이 적용될 수 있다. 그러나 R-CNN은 Segmentation 영상을 입력으로 하며, R-CNN의 Segmentation 방식인 Region Proposal은 수행시간이 느리고 연산량이 많으며 후보 표적영상의 개수가 상당히 많다. 또한 Region Proposal에 의한 Segmentation은 배경을 분리하지 않은 영상으로 식별 성능을 저하시킬 수 있다. 한편 3-모드 영상은 모폴로지 기반의 Segmentation 방식으로 처리 속도가 빠르며 수중배경과 표적이 분리되는 영상을 제공한다. 향후 AUV Segmentation 프로그램에서 3-모드 영상을 자동으로 생성하여 R-CNN의 입력 영상을 만들고 R-CNN의 입력 영상으로 두어 표적 식별성능을 실험할 예정이다.
