

I. 서 론
II. 연구 및 실험 방법
2.1 시뮬레이션 설정
2.2 Deep-HUG 알고리즘
2.3 학습 및 손실함수
2.4 성능 평가
III. 실험 및 결과
3.1 시뮬레이션 결과
3.2 성능 평가 및 비교
IV. 결 론
I. 서 론
초음파는 산업용 비파괴 검사, 의료 영상 진단, 집속 초음파 치료를 위해 널리 사용되고 있다. 또한 초음파를 집속하였을 때 발생하는 힘을 사용하는 음향 집게와 그 응용에도 연구되어 왔다. 최근에는 더 나아가서 광학 홀로그램과 동일하게 초음파의 위상을 조절함으로써 원하는 형태의 홀로그램을 형성하는 초음파 홀로그램이 연구되고 있다.[1] 초음파 홀로그램을 이용하면 입자를 조작하고, 입자를 모아 모양을 만들며, 여러 위치의 신경에 동시에 자극을 줄 수도 있다.[2,3,4,5]
초음파 홀로그램은 배열형 변환자의 각 소자에서 송신 신호의 위상을 조절하거나,[6,7] 단일 소자 변환자에 위상 조절 렌즈를 붙임으로써[8,9] 음향장을 조절하여 형성할 수 있다. 여기서 음향장 조절은 단순하게는 의료 영상 진단, 집속 초음파 치료에 사용되는 단초점 빔포밍이지만 입자 조작, 신경 자극 등에서는 더욱 복잡한 음향장(초음파 홀로그램)을 필요로 하며 따라서 더 정교한 위상 조절이 필요하다.
원하는 홀로그램을 생성하기 위한 위상을 결정하는 문제는 잘 정의되지 않는 비볼록 역문제이다. 공간 광 변조기를 이용해 파동의 위상을 조절해 홀로그램을 형성한다는 점에서 초음파 홀로그램과 비슷한 광학 홀로그래피 분야에서는 광유전학, 홀로그래픽 디스플레이 등에서의 활용을 위해 지속해서 이 역문제를 풀려는 연구가 되어왔다.[10,11,12,13] 컴퓨터 홀로그램 생성을 위한 위상은 주로 원하는 형태와 시뮬레이션 결과 간의 오차를 줄이는 반복적인 최적화 알고리즘을 통해 결정된다.[14] 하지만 위상 결정 문제가 비볼록 문제(non-convex problem)이기 때문에 최소 오차 지점을 찾기가 어려울 뿐만 아니라 반복적인 최적화 방법이므로 시간 소모적이다. 따라서 최근에는 더 빠르고 정확하게 홀로그램을 형성하기 위해 딥러닝을 활용한 알고리즘이 개발되었다.[15,16,17]
반면에, 초음파 홀로그램 연구는 그 응용 범위가 무궁무진하여 이를 활용하는 것에 대한 연구는 활발히 이루어지고 있지만 초음파 홀로그램을 생성할 파동의 위상을 결정하는 방법은 1972년에 개발된 Gerchberg- Saxton(GS) 알고리즘[13]에서 크게 벗어나지 않고 있다.
이에 본 연구에서는 비지도 학습을 통해 기존에 비해 더 빠르게 초음파 홀로그램을 생성할 수 있는 딥러닝 기반 초음파 홀로그램 생성 알고리즘(Deep learning-based Holographic Ultrasound Generation, Deep- HUG)을 소개한다. 제안하는 알고리즘의 성능을 검증하기 위해서 시뮬레이션을 통해 기존에 일반적으로 사용되는 GS 알고리즘과 속도, 정확도, 균일도에 대해 비교하였다.
II. 연구 및 실험 방법
2.1 시뮬레이션 설정
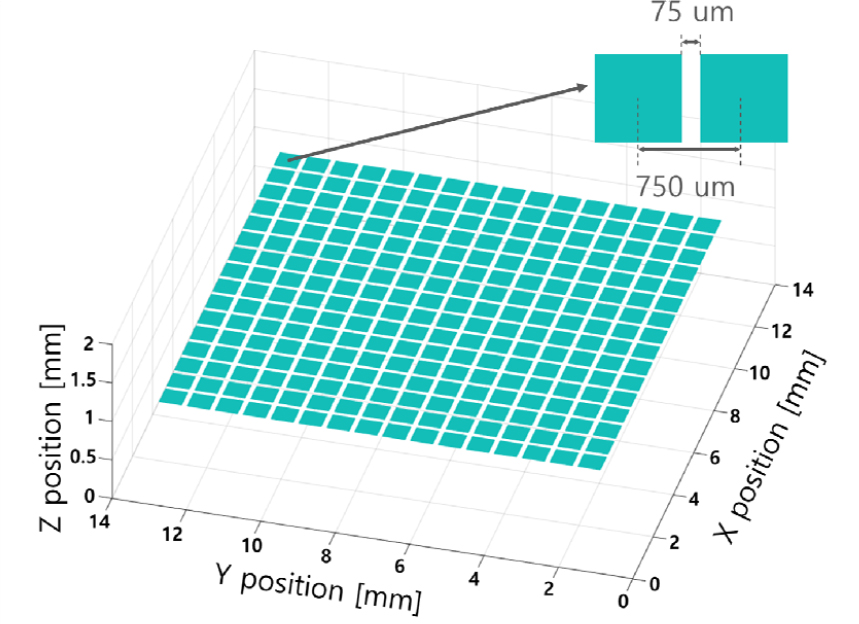
제안하는 알고리즘의 성능을 평가하기 위해 시간 영역 음향 시뮬레이션 공개 툴박스인 k-wave toolbox[18]를 사용하여 시뮬레이션하였다. 시뮬레이션에 사용된 변환자는 2 MHz, 16 × 16, 2차원 배열형 변환자이며 소자 간격(Element pitch)은 750 um, 커프(Element kerf)는 75 um로 구성되었다(Fig. 1). 매질은 물(음속: 1500 m/s)이며 음향감쇠(음향감쇠계수: 0.0022 dB/MHz/cm)도 고려되었다. 시뮬레이션에서 XYZ는 192 × 192 × 160개의 점으로 구성되었고 각 점 간의 거리는 물에서 2 MHz로 전파되는 음향장을 샘플링하기에 충분한 77 um으로 설정되었다. 각 소자 송신 신호는 2 MHz 사인파이며 진폭은 모두 동일하게 매질에서 1 MPa에 해당하는 음압을 출력할 수 있도록 설정되었다 위상은 각 알고리즘에서 출력된 값으로 입력된다. 시뮬레이션 결과는 192 × 192 × 160개의 점에서 각각 기록된 시간에 따른 음압이며 성능 평가를 위해 실효 음압()으로 계산하였다.
2.2 Deep-HUG 알고리즘
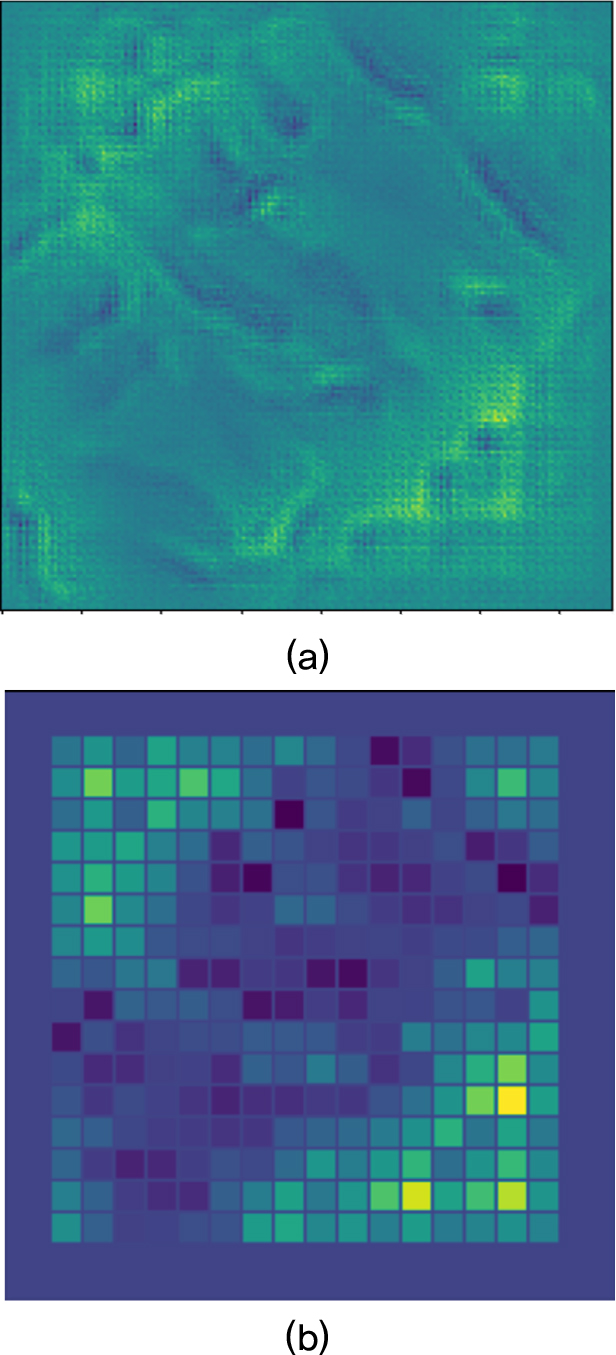
제안하는 알고리즘은 입력과 출력 간의 공간적 정보 간의 연관성을 고려하기 위해 Fig. 2와 같이 의미론적 영상 분할을 위해 개발되어 널리 쓰이는 U-Net 모델을 기반으로 구성되었다.[19] 구체적으로 U-Net은 convolution layer를 기반으로 입력 영상의 공간적 문맥을 학습하고 이와 연관된 출력을 픽셀 단위로 줄 수 있다.[20,21] 따라서 원하는 패턴을 입력으로 하여 이를 형성하는 송신 신호의 위상을 결정해야하는 본 알고리즘의 개발에 활용되었다. 입력은 원하는 거리에 형성할 패턴을 그린 이미지, 이며 각 픽셀의 값은 음향장에서의 진폭을 의미한다. 학습된 U-Net 기반 모델은 이 입력 이미지를 2차원 변환자에서 구현할 수 있도록 위상 정보를 결과 이미지로서 출력한다. 각 픽셀 값은 송신 신호의 위상으로서 0보다 작은 음수일 수도 있다. 따라서 일반적으로 출력 전의 마지막 layer에 적용되는 Rectified Linear Unit (ReLU) 등의 활성함수가 생략되어 수치적 제한없이 값이 출력된다. 결과적으로 출력되는 위상 정보는 변환자의 물리적 한계, 즉 한정된 소자의 개수와 한 소자에서는 같은 위상의 송신 신호를 보낼 수 있다는 점이 고려되지 않은 연속적인 이미지이다. 따라서 각 소자의 위치에 해당하는 값을 모아 평균을 취한 후, 다시 그 위치에 할당시켜 주었으며 이 값이 2차원 배열형 변환자의 각 소자에서 송신 신호의 위상, 으로 사용되었다(Fig. 3).
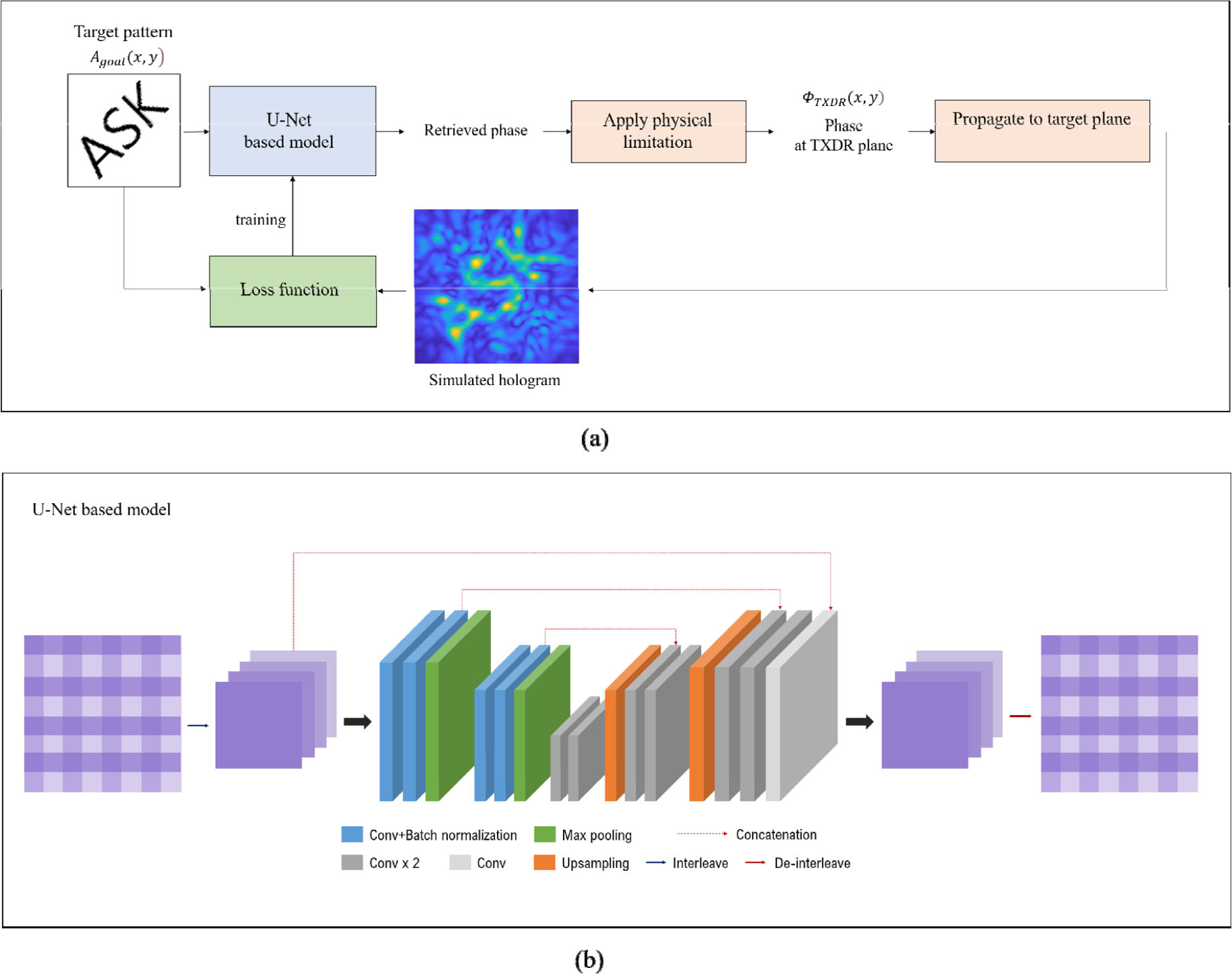
U-Net을 기반으로 한 알고리즘 구조 덕분에 반복적인 최적화 없이 빠르게 위상 정보의 예측이 가능하다. 계산 속도는 convolution layer와 커널의 개수, 커널의 크기 등 모델의 크기와 입력 이미지의 크기에 따라서 달라질 수 있으며 그 외에는 일정하다. 더욱 빠른 계산 속도를 위해서는 입력 이미지의 크기를 줄여야 하며 이를 위해서 interleave를 활용하였다.[22]
Fig. 2(b)에서 볼 수 있듯이 interleave layer는 입력 이미지 정보를 그대로 보존하면서 공간 해상도, 즉 이미지 크기를 줄이고 채널의 수를 늘린다. 입력 이미지가 의 픽셀을 가지고 있고, 이 이미지를 블록으로 interleave한다면 결과적으로 입력 이미지는 로 재배열된다. interleave된 입력 이미지는 U-Net 기반 모델의 마지막에서 상반되는 De-interleave layer를 통해 다시 원래의 크기인 로 배열되어 출력된다. Interleave/De-interleave layer를 통해 입력 이미지를 압축하여 U-Net에 입력할 수 있으며 이를 통해 계산 효율을 높일 수 있다. 본 연구에서는 입력 이미지(192 × 192)를 6 × 6 블록으로 interleave하여 32 × 32 × 36으로 재배열해 U-Net에 입력하였다.
2.3 학습 및 손실함수
제안하는 알고리즘은 비지도학습 방식으로 학습된다. 출력된 위상 정보에 대하여 정답을 주고 학습시키는 것이 아니라 출력된 위상 정보를 토대로 각도 스펙트럼 방법(Angular Spectrum Method, ASM)[23]을 통해 변환자 면에서 목표 면까지 초음파를 전파시켜 그 음향장의 진폭과 입력 이미지, 즉 목표 음향장의 진폭을 비교하여 그 오차를 줄이는 방향으로 학습시킨다.
입력 이미지, 와 각도 스펙트럼 방법을 이용해 얻은 음향장의 진폭, 간의 오차는 Eq. (1)과 같이 정의되었다.
여기서 기호 ∘는 행렬 요소 간의 곱을 의미하며 정규화가 고려되어 있으므로 진폭의 값이 서로 다르더라도 과 의 형태가 동일하다면 그 오차는 0이다. 이 오차를 0으로 줄여 나가며 학습이 진행되었다. 학습 최적화를 위해서는 ADAM 알고리즘이 사용되었다.
2.4 성능 평가
제안하는 알고리즘의 성능을 GS 알고리즘과 비교하기 위해 각 알고리즘에서 출력된 위상을 토대로 MATLAB에서 k-wave toolbox를 통해 시뮬레이션 하였다. 앞서 언급했듯이 시뮬레이션 결과인 시간 영역 음압으로 를 계산하여 비교에 사용하였다.
평가 기준은 계산 속도, 정확도, 균일도이며 정확도는 Eq. (1)에서 1을 뺀 값으로 계산하였다. 균일도는 시뮬레이션 결과, 에서 인 위치에 해당하는 값들의 표준편차를 그 값들의 평균으로 나누고 1에서 뺀 값으로 정의하였다. 그 식은 다음과 같다.
III. 실험 및 결과
초음파 홀로그램을 생성하는 면은 변환자로부터 5 mm 떨어진 면으로 설정되었으며 이 깊이는 변환자의 크기, 주파수를 고려하였을 때 기존에 사용되었던 GS 알고리즘으로도 비교적 홀로그램의 모양이 잘 형성되는 깊이이다.
딥러닝 기반 알고리즘의 위상 결정에 있어서의 일반화 가능성을 보기 위해 Deep-HUG 알고리즘은 무작위로 겹치지 않게 만든 원들로 구성된 이미지를 이용해 학습되었고 영어 알파벳 이미지로 그 성능이 평가되었다. 학습 데이터셋에서 원의 크기는 300 um ~ 750 um에서 무작위로 결정되었으며 개수는 한 이미지에서 1개 ~ 50개 중 무작위로 생성되었다. 또한 그 위치는 변환자가 위치한 면 위에서 벗어나지 않게 설정되었다. 이미지의 크기는 시뮬레이션 상에서의 XY면의 크기와 동일하게 192 × 192이며 학습에는 총 20000개 이미지가, 검증에는 총 2000개 이미지가 사용되었다.
성능 평가 및 비교를 위해 기존에 사용되는 GS알고리즘을 MATLAB 상에서 구현하였으며 GPU 가속을 사용할 수 있게 하는 Parallel Computing Toolbox를 이용하여 계산 속도를 향상시켰다. GS 알고리즘은 반복적인 최적화 방법이므로 반복 횟수에 따라 더욱 최적화된다. 따라서 충분한 횟수만큼 반복해야 하며 본 연구에서는 50회 반복되었다. Deep-HUG알고리즘은 TensorFlow 프레임워크를 이용하여 구현하였고 마찬가지로 GPU 가속을 사용하여 학습 및 평가하였다.
두 알고리즘 모두 Intel i7-9700 CPU, NVIDIA GeForce RTX 2080Ti, 32GB 램이 설치된 컴퓨터에서 학습 및 평가되었다.
3.1 시뮬레이션 결과
학습 및 검증 데이터셋과 동일한 방식으로 생성된 이미지에 대해 Deep-HUG를 이용하여 Fig. 4의 첫번째 그림과 같은 결과를 얻을 수 있었다. 학습 데이터와 비슷한 이미지에 대해 위상을 잘 결정하는 것을 확인할 수 있다.
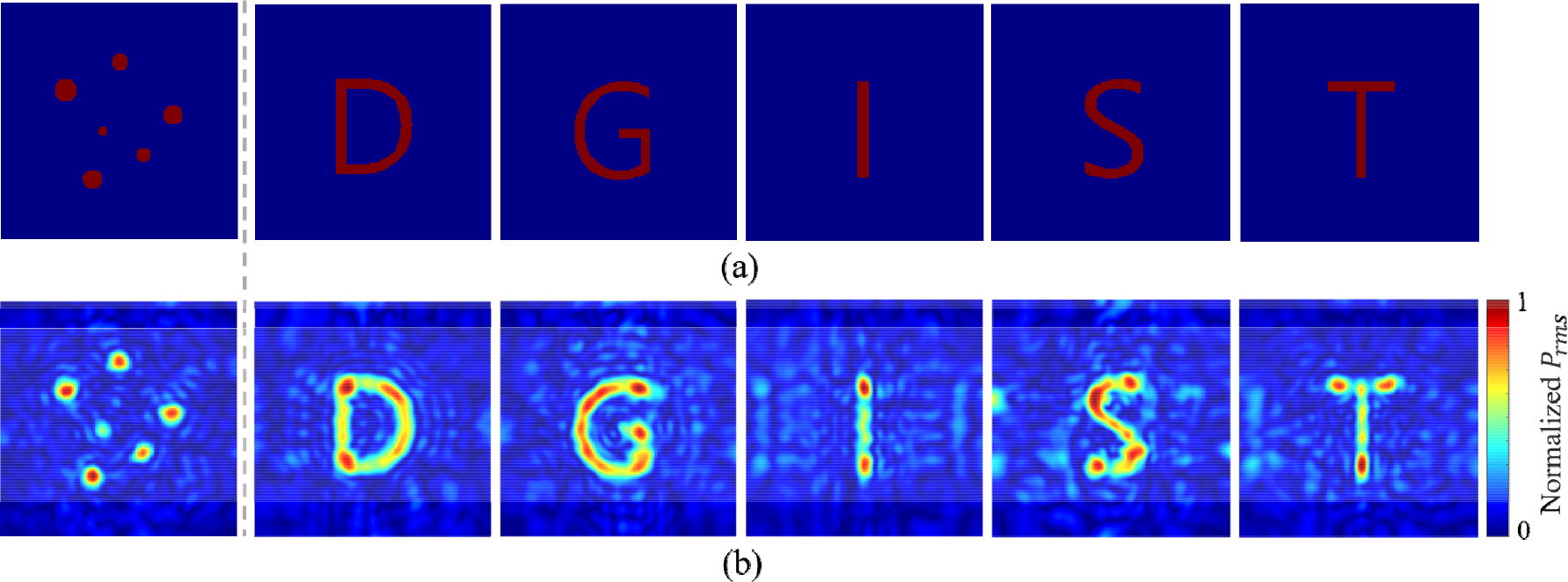
더 나아가서 원 모양의 초음파 홀로그램을 형성할 수 있도록 학습된 Deep-HUG가 더욱 복잡한 모양을 형성할 수 있는지, 일반화 가능성을 평가하기 위해 영어 알파벳을 입력 이미지로 사용하였다. Fig. 4와 같이 Deep-HUG가 영어 알파벳과 같이 복잡한 모양에 대해서도 홀로그램을 형성할 수 있도록 위상을 결정하는 것을 볼 수 있었으며 이는 딥러닝 기반 초음파 홀로그램 형성이 단순히 학습한 이미지에 대해서만 홀로그램을 형성할 수 있는 것이 아니라 그 외의 이미지에 대해서도 적용이 가능하다는, 즉 일반화 가능성을 보이는 결과이다.
3.2 성능 평가 및 비교
보다 정량적으로 Deep-HUG를 평가하고 GS알고리즘과 비교하기 위해 A부터 Z까지 모든 알파벳을 입력 이미지로 사용하였다. 계산속도, 정확도, 균일도를 측정 및 계산하였으며 그 결과는 Fig. 5와 같다.
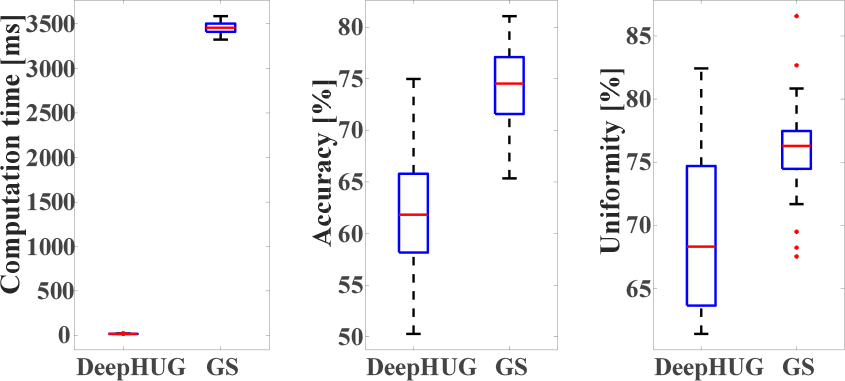
Fig. 5(a)에서 볼 수 있듯이 Deep-HUG는 기존의 GS알고리즘에 비해 압도적으로 계산 속도가 빠르다. 따라서 실시간으로 유동적인 초음파 홀로그램 생성을 가능하게 한다. 하지만 정확도와 균일도는 GS 알고리즘과 비교하여 떨어지는 결과를 보여주었다. 주목할 만한 것은 Deep-HUG의 정확도와 균일도가 큰 편차를 가진다는 것인데 이는 Deep-HUG가 학습한 이미지와 큰 차이를 가지는 이미지에 대해서는 낮은 성능을, 학습한 이미지와 비슷한 이미지에 대해서는 GS알고리즘과 비슷한 성능을 낸다는 것을 시사한다. 실제로 Deep-HUG가 좋은 정확도를 보인 알파벳은 높은 순서대로 O, Q, D 이며 낮은 정확도를 보인 알파벳은 낮은 순서대로 I, K, L이었다. 알파벳 O, Q, D 모두 학습한 원 모양과 비슷한 둥근 형태이며 I, K, L은 그 반대로 직선적인 형태이다.
IV. 결 론
본 연구에서는 초음파 홀로그램 생성을 위해 딥러닝 기반 알고리즘, Deep-HUG를 개발하여 그 성능을 평가하고 기존에 널리 사용되는 GS알고리즘과 비교 분석하였다. 더욱이 Deep-HUG를 무작위로 생성된 원 모양에 대해 학습시키고 영어 알파벳 모양으로 평가함으로써 초음파 홀로그램 생성에 있어서의 일반화 가능성을 검증했다.
주목할 만한 점은 Deep-HUG는 GS알고리즘에 비해 약 190배 빠른 속도로 홀로그램을 생성할 수 있는 위상을 결정하여 실제 관찰을 통한 피드백을 통해 유동적인 초음파 홀로그램을 필요로 하는 입자 조작, 신경 자극에 있어서 필수적인 실시간 초음파 홀로그램 생성을 가능하게 하는 알고리즘으로써 사용될 수 있는 가능성을 보였다는 것이다. 이 상당한 속도 차이는 GS알고리즘은 원하는 음향장 형성을 위한 위상 최적화에 최소 수십번의 입력을 바꾸는 과정이 필요한 반면에 Deep-HUG는 입력 이미지에 대해 각 레이어가 학습 가능하며 픽셀 단위의 출력을 내보내는 U-Net을 활용하여 단 한 번의 실행으로 위상을 결정할 수 있는 것에서 비롯되었다.
정확도와 균일도에 있어서는 GS알고리즘에 비해 다소 낮은 성능을 보였지만 본 연구에서 U-Net을 기반으로 기본적인 딥러닝 구조를 적용하였음을 고려할 때, SOTA 성능의 구조 채택 ․ 응용, 데이터셋 다양화, 손실함수 최적화 등을 통해 GS알고리즘에 버금가는 혹은 더 나은 성능을 기대할 수 있다. 예를 들어 본 연구에서 사용된 손실 함수 대신 이진 교차 엔트로피를 손실 함수로 사용한다면 픽셀마다의 최적화가 가능할 것이다.
결론적으로 본 연구에서는 기존의 반복적 최적화 방법이 아닌 딥러닝을 기반으로 하여 한 번에 초음파 홀로그램을 생성할 수 있는 위상을 결정할 수 있음을 보였다. 향후 모델의 개선, 손실함수의 최적화 등을 통해 빠르면서도 더 정확하게 위상을 결정할 수 있을 것으로 기대되며 이는 다음 연구로서 진행할 계획이다.
