
I. Introduction
II. Overview of the Voice Transformation System
III. Transformation Rules
3.1 Overall transformation rules
3.2 Inter-speaker model
3.3 Intra-speaker model
3.4 Feature selection
IV. Experimental Results
4.1 Objective evaluation
4.2 Subjective evaluation
V. Conclusions
I. Introduction
Voice personality transformation [1-16] is a process by which voice personality is altered, so that one voice is made to sound like another. The process has numerous applications in a variety of areas such as personification of text-to-speech synthesis systems, preprocessing for speech recognition [17], and enhancing the intelligibility of abnormal speech [8].
Voice personality transformation is generally per-formed in two steps. In the first step, the training stage, a set of speech feature parameters of both thesource and target speakers are extracted and appropriate mapping rules that transform the para-meters of the source speaker onto those of the target speaker are generated. In the second step, the transformation stage, the features of the source signal are transformed using mapping rules developed in the training stage so that the synthesized speech possesses the personality of the target speaker.
To implement voice personality transformation, the first problem is to determine which features should be extracted from the underlying speech signals and how to modify these features in a way so that the transformed speech signals mimic target speaker’s voice. The vocal-tract transfer function (VTF) is a primary identifier of speaker individuality [18]. For this reason, feature parameters that represent the VTF including formant frequencies [4,5], the linear prediction coefficient cepsturm (LPCC) [2,10,11] and LSP (Line Spectrum Pair) coefficients [9], have been widely used in voice personality transformation. In the presented study, the LPCC was used as a feature parameter that represents the VTF. Prosody is another discriminator of speaker individuality [18]. Speaking style is highly correlated with prosody [2]. Hence, prosody modification is highly desirable for acquisition of transformed speech signals that are perceptually closer to a target voice. In the proposed method, prosody modification is accomplished by replacement of both the pitch and the gain.
The second problem can be described as finding acceptable mapping rules from the source speaker’s feature parameters to those of the target speaker. In previous studies, the entire speaker space was partitioned into several clusters using vector quanti-zation (VQ) [19], the mapping rules for each partition are then estimated using either a histogram [1] or minimum mean square error criterion [3,10]. The underlying assumption is that each cell corresponds to a phoneme. Hence these mapping rules reflect phonetic variation. However, mapping rules based on VQ present problems that result from hard clustering of VQ-based classification. According to Stylianou’s study [7], VQ-based classification causes discontinuity in transition regions. Hence, for voice conversion, the use of a soft-clustering approach is desirable [7,11,12]. Recently, a unit-selection based approach, which was originally devised for implementing the corpus- based concatenative text-to-speech (TTS) systems [20]was used to both alter the VTF parameters [13,14,16] and predict the target LP-residuals [15].
This paper is an extension of our previous work on voice transformation [12] based on a statistical approach. The listeners indicated that transformed utterances converted by the previous method sounded “ambiguous” and “unclear”. This is mainly due to the bandwidth widening problem caused by the averaging effects. The artifacts caused by the averaging effects cannot be avoided in the voice transformation methods where the transformed feature vector is given by the weighted sum of the mean vectors (e.g. codebook mapping [1], GMM-based [7] and MMSE-based [12]).
To alleviate this problem, a feature-selection based approach was employed in the present study, where the sequence of the transformed features is given by the sequence of the features selected from the target speaker’s database. We propose selection of the features that optimize the overall similarities between the transformed and the target features by maximizing two likelihood functions: the correlation probability between the transformed and the source parameters and the likelihood of the transformed parameters with respect to the target model. Objective and subjective tests were performed to evaluate the efficiency of the proposed method. For the objective tests, both the distance reduction ratio and likelihood ratio for each feature were used to evaluate performance of the transformation. ABX tests using several phonetically balanced sentences were performed to subjectively evaluate performance. In addition, a preference test was administered to evaluate improvement in quality.
This paper is organized as follows. Section 2 provides an overview of the proposed VT method; including both the training and online transformation procedures. Section 3 describes both the modeling and transformation of the features. The experimental results are presented in Section 4, and concluding remarks are summarized in Section 5.
II. Overview of the Voice Transformation System
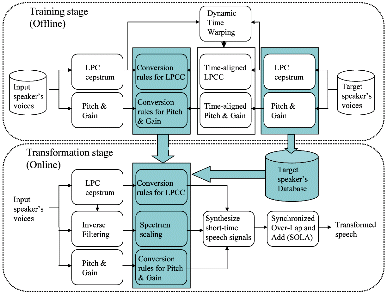
A block diagram of the proposed voice personality transformation system is shown in Fig. 1. In the training stage, voices from both source and target speakers were recorded. These speech samples were then analyzed for determination of the feature parameters to be transformed. In this work, the LPCC, pitch and gain were used as the feature parameters. In practice, even if two speakers utter the same words, given their different speaking rates, it is unlikely that a synchronized set of LPCC sequences would result. To time-align these sequences, dynamic time warping (DTW) [22] was applied in a preprocessing step. The resulting time-aligned LPCC, pitch and gain sequences were used to build conversion rules for each feature parameter. Note that pitch is valid only for the voiced frames. Hence, the unvoiced frames were eliminated from the time-aligned pitch sequences.
In the online stage, the features extracted during the training stage were derived from the incoming speech signals. The features were then replaced with those selected from a target database using the conversion rules constructed during the training stage. The short-time speech signals were synthesized from the estimated parameters. Finally, continuous waveforms were obtained by concatenating the short-time speech signals. This procedure used the Synchronized Over-Lap and Add (SOLA) [23] algorithm to align each short-time speech signal. Note that the LP-residual was not included in the list of features to be transformed. Rather, the LP-residual from the source speaker was scaled in the frequency domain so that the fundamental frequency of the scaled LP-residual was identical to the target fundamental frequency (or equivalently, the inverse of the target pitch).
Each part of the proposed system is described in greater detail in the following sections.
|
Fig. 1. Block diagram of the proposed voice transformation method. |
III. Transformation Rules
3.1 Overall transformation rules
In this work, transformation is performed on a sequence of features during speaking spurts. Let ![]() and
and ![]() be the source and the target sequences, respectively, where the features of a sequence are assumed to be time-aligned. Note that
be the source and the target sequences, respectively, where the features of a sequence are assumed to be time-aligned. Note that ![]() and
and ![]() include all three features selected from transformation-LPCC, pitch and gain. i.e.
include all three features selected from transformation-LPCC, pitch and gain. i.e.
![]()
where the terms “C”, “p” and “g” denote the LPCC, the pitch and the gain, respectively.
In the present study, the optimal transformed sequence ![]() for a given source sequence
for a given source sequence ![]() is given by
is given by
![]() (1)
(1)
where ![]() is the likelihood function of
is the likelihood function of ![]() given
given ![]() and
and ![]() .
. ![]() is a model that describes the target features, which are represented in the context of the HMM. In (1)
is a model that describes the target features, which are represented in the context of the HMM. In (1) ![]() is a set of features obtained from the target speaker’s utterances that were recorded in the training stage. The transformation rule in this work indicates that a transformed sequence for a given source sequence
is a set of features obtained from the target speaker’s utterances that were recorded in the training stage. The transformation rule in this work indicates that a transformed sequence for a given source sequence ![]() is composed of the selected features from a target database, where the likelihood of the selected features is maximized with respect to both the given source sequence
is composed of the selected features from a target database, where the likelihood of the selected features is maximized with respect to both the given source sequence ![]() and the target model. The objective function in (1) can be written as follows:
and the target model. The objective function in (1) can be written as follows:
![]()
(2)
where ![]() is the cross-correlation probability density function (PDF) between X and Y. Note that the two functions
is the cross-correlation probability density function (PDF) between X and Y. Note that the two functions ![]() and
and ![]() in proposed transformation rule (2) are associated with the inter-and intra-speaker models, respectively. A more detailed description of each model is explained in the following subsection.
in proposed transformation rule (2) are associated with the inter-and intra-speaker models, respectively. A more detailed description of each model is explained in the following subsection.
3.2 Inter-speaker model
The model proposed in our previous study [12], in which inter-speaker variability was described by an inter probabilistic model, was used in the present study. According to this model, the joint probability of the source feature ![]() , the target feature
, the target feature ![]() , source speaker’s
, source speaker’s ![]() -th random source
-th random source ![]() and target speaker’s
and target speaker’s ![]() -th random source
-th random source ![]() is given by
is given by
![]()
(3)
where ![]() is the cross correlation probability between the
is the cross correlation probability between the ![]() -th random source of the source feature and the
-th random source of the source feature and the ![]() -th random source of the target feature. This term describes the dependencies of the two random vector sets. Because the random sources
-th random source of the target feature. This term describes the dependencies of the two random vector sets. Because the random sources ![]() are assumed to be Gaussian,
are assumed to be Gaussian,
![]()
(4)
![]()
(5)
where ![]() and
and ![]() are the covariance matrix and mean vector of the
are the covariance matrix and mean vector of the ![]() -th random source for the source feature, respectively. Similarly,
-th random source for the source feature, respectively. Similarly, ![]() and
and ![]() are the covariance matrix and mean vector, respectively, of the
are the covariance matrix and mean vector, respectively, of the ![]() -th random source for target feature.
-th random source for target feature. ![]() is the order of the features. The method for estimating
is the order of the features. The method for estimating ![]() ,
, ![]() and parameters describing
and parameters describing ![]() and
and ![]() from a given training corpus is based on a maximum likelihood criterion, as described in [12]. Using the adopted inter-speaker model, the cross-correlation PDF
from a given training corpus is based on a maximum likelihood criterion, as described in [12]. Using the adopted inter-speaker model, the cross-correlation PDF ![]() is given by
is given by
![]() (6)
(6)
where
![]() (7)
(7)
and
![]()
![]()
![]()
Note that observations of both source and target features are independent in different time frames ![]() . We assumed that the cross-correlation PDFs for each type of feature are also independent. Hence the cross-correlation PDF at time
. We assumed that the cross-correlation PDFs for each type of feature are also independent. Hence the cross-correlation PDF at time ![]() ,
, ![]() is given by
is given by
![]() (8)
(8)
where ![]() ,
, ![]() and
and ![]() are the cross correlation PDFs for LPCC, pitch and gain, respectively.
are the cross correlation PDFs for LPCC, pitch and gain, respectively.
3.3 Intra-speaker model
As noted above, the target model ![]() is represented in the HMM context. Hence, the target model includes the following HMM parameters.
is represented in the HMM context. Hence, the target model includes the following HMM parameters.
![]() (9)
(9)
where ![]() is the transient PDF from states
is the transient PDF from states ![]() and the state
and the state ![]() ,
, ![]() is the state observation PDF for state-
is the state observation PDF for state-![]() and
and ![]() is the initial PDF of state-
is the initial PDF of state-![]() .
. ![]() is the number of states. In this work, we focused on representation of the state observation PDF
is the number of states. In this work, we focused on representation of the state observation PDF ![]() , which models the relationship between features.
, which models the relationship between features.
A model of state observation density when multi- channel observation sequences are given has been proposed previously [24]. This model was primarily used for representation of the relationship between multi-channel observations. In the present study, this model is adopted for representation of inter-feature relationships. There are several methods available for integration of individual features to represent the relationship among them. The models can be categorized as either early integration (EI) or late integration (LI) models [24]. In the EI model, integration is performed in the feature space to form a composite feature vector that represents multiple features of each channel. Hence, the state observation density is given by the probability of this composite feature vector. In the LI model, a density function is defined for each feature, and the state observation density is obtained by integrating individual density functions. This paper focuses on the LI model.
A simple way of implementing the LI model is based on the assumption that all of the individual density functions are statistically independent. In this case, the state observation density is given by
![]() (10)
(10)
where ![]() ,
, ![]() and
and ![]() denote the density functions for LPCC, pitch and gain, respectively. In (10), the state index
denote the density functions for LPCC, pitch and gain, respectively. In (10), the state index ![]() is omitted for simplicity. When the Gaussian mixture model is adopted, an individual density function is given by
is omitted for simplicity. When the Gaussian mixture model is adopted, an individual density function is given by
![]()
(11)
where ![]() are the number of Gaussian com-ponents for LPCC, pitch and gain, respectively, and
are the number of Gaussian com-ponents for LPCC, pitch and gain, respectively, and ![]() are the mixture weights of each feature of the
are the mixture weights of each feature of the![]() -th Gaussian component.
-th Gaussian component. ![]() , are the
, are the ![]() -th Gaussian component for each feature. Using (11), the state observation density is given by
-th Gaussian component for each feature. Using (11), the state observation density is given by
![]()
(12)
where ![]() is the joint probability function of the set of the observation features
is the joint probability function of the set of the observation features ![]() ,
, ![]() and
and ![]() and the set of the Gaussian random sources
and the set of the Gaussian random sources ![]() ,
, ![]() and
and ![]() , which is given by
, which is given by
![]()
(13)
3.4 Feature selection
For the approach proposed in the present study, the use of a large database is critical for the transformation of high-quality speech signal, because high-quality speech synthesis requires a sufficient variety of waveforms to cover various manifestations of each feature. In practice, most corpus-based TTS systems involve a large database that is constructed from a speech corpus that exceeds 1 hour in length [20]. However, selection of the optimal features from a large database is not a trivial undertaking. As the size of the target database increases, it takes more times to select the optimal features. Hence, it would be highly desirable to determine the required number of candidates a prior, rather than computing the likelihood, given by (1) for all features in the database. A set of the candidates ![]() was constructed using the predicted target feature
was constructed using the predicted target feature ![]() as follows.
as follows.
![]() (14)
(14)
where ![]() is the threshold, which can be adjusted so that the number of candidates is 20~30. In the present study, the minimum mean square error (MMSE) -based transformation method [12] was employed to get the predicted target feature for LPCC. For pitch and gain, the predicted target value was obtained by scaling, so that the average of the scaled values is identical to that of the target values.
is the threshold, which can be adjusted so that the number of candidates is 20~30. In the present study, the minimum mean square error (MMSE) -based transformation method [12] was employed to get the predicted target feature for LPCC. For pitch and gain, the predicted target value was obtained by scaling, so that the average of the scaled values is identical to that of the target values.
The optimal transformed sequence is constructed from the features selected from the set of candidates. For the source feature sequence ![]() , the target model
, the target model ![]() and the arbitrarily selected HMM state sequence
and the arbitrarily selected HMM state sequence ![]() , the log- likelihood of the target feature sequence
, the log- likelihood of the target feature sequence ![]() is given by
is given by
![]()
(15)
where
![]()
![]()
![]()
The optimal transformed sequence ![]() is then given by
is then given by
![]() (16)
(16)
where ![]() is the set of candidates for
is the set of candidates for ![]() and
and ![]() denotes the set of all possible HMM state sequences.
denotes the set of all possible HMM state sequences.
Equation (16) can be maximized using a dynamic programming technique, such a Viterbi-trellis search.
In some sense, the objective of the log likelihood function (15) is similar to that of the cost function employed in corpus-based concatenative TTS systems [20]. In this type of TTS system, the optimal unit sequence is obtained by minimizing the total cost function which includes a target cost and a conca-tenation cost. The objective of a target cost is to maximize the similarities (or, equivalently, minimizing the differences) between the selected units and the targets. In TTS systems, the targets are specified based on the context information to be synthesized. Whereas, in VT, the targets are characterized by the target speaker’s speech signals and the source speaker model. Accordingly, the term ![]() in (15) is referred to as the target likelihood function in this study. The objective of a concatenation cost in TTS systems is to build the unit sequence so that spectral trajectory of the selected unit sequence possess some degree of smoothness. For a quasi-stationary random process (e.g. speech signal), the transient PDFs between the same states are higher than those between the different states. Thus, the maximum likelihood criterion (16) tends to select the feature sequence so that the state indices of the neighboring features are same. Since the the features belonging to the same states are close to each other, maximizing
in (15) is referred to as the target likelihood function in this study. The objective of a concatenation cost in TTS systems is to build the unit sequence so that spectral trajectory of the selected unit sequence possess some degree of smoothness. For a quasi-stationary random process (e.g. speech signal), the transient PDFs between the same states are higher than those between the different states. Thus, the maximum likelihood criterion (16) tends to select the feature sequence so that the state indices of the neighboring features are same. Since the the features belonging to the same states are close to each other, maximizing ![]() in (15) leads to smoothly evolving spectral trajectories over time. This means that the role of
in (15) leads to smoothly evolving spectral trajectories over time. This means that the role of ![]() is similar to that of the concatenation cost function in TTS systems. Accordingly,
is similar to that of the concatenation cost function in TTS systems. Accordingly, ![]() is referred to as the concatenation likelihood function in this study.
is referred to as the concatenation likelihood function in this study.
IV. Experimental Results
The database used to obtain the conversion rules consisted of 200 utterances spoken in Korean by three men and one woman whom we refer to as M1, M2, M3 and F, respectively. M1, M2 and F were professional voice actors. An additional 100 utterances spoken by the same individuals were prepared for both objective and subjective evaluation. Speech signals were digitized at a rate of 16 kHz. The orders of the LPC coefficients and the LPC cepstrum were 20 and 30, respectively. A 25-ms Hanning window was used to both compute and extract the LPC parameters at 10 ms intervals. The pitch period was estimated by applying the clipped autocorrelation method [21]. Each Gaussian component was constrained to a diagonal covariance matrix. Variance limiting [25]was also used to estimate each component of the covariance matrices. Results of two VT experiments are presented. The first experiment involved male- to-male conversion (M3→M1), while the second tested male-to-female conversion (M2→F).
4.1 Objective evaluation
To evaluate the performance of the proposed voice transformation method, two objective measurements were adopted. First, the following distance reduction ratio [6] was used
![]() (17)
(17)
where ![]() ,
, ![]() and
and ![]() are the feature sequences for the source speaker, the target speaker and the transfor-mation, respectively,
are the feature sequences for the source speaker, the target speaker and the transfor-mation, respectively, ![]() denotes the averaged Euclidean distance between vectors
denotes the averaged Euclidean distance between vectors ![]() and
and ![]() . A large reduction ratio indicates increased similarity between the transformed and target features.
. A large reduction ratio indicates increased similarity between the transformed and target features.
Another objective measure is the following log likelihood ratio [9].
![]()
(18)
where ![]() and
and ![]() are probabilistic models estimated from the source speaker’s training corpus and the target speaker’s training corpus, respectively. In this work, the HMMs were employed to represent each speaker’s probabilistic model. These models used five states and five Gaussians. According to the above equation,
are probabilistic models estimated from the source speaker’s training corpus and the target speaker’s training corpus, respectively. In this work, the HMMs were employed to represent each speaker’s probabilistic model. These models used five states and five Gaussians. According to the above equation, ![]() is typically less than zero when
is typically less than zero when ![]() is similar to the source speaker’s feature sequence. By contrast, if
is similar to the source speaker’s feature sequence. By contrast, if ![]() approximates the target speaker’s feature sequence,
approximates the target speaker’s feature sequence, ![]() is greater than zero. Hence, large positive values of the log likelihood ratio indicate that the transformed features are statistically similar to the target features.
is greater than zero. Hence, large positive values of the log likelihood ratio indicate that the transformed features are statistically similar to the target features.
For comparison, three types of conversion methods were adopted in this experiment; the VQ-based approach proposed by Abe et al. [1], the GMM-based approach proposed by Stylianou et al. [7] and the ML-based statistical approach proposed by author [12]. For each method, the conversion rules for each feature (LPCC, pitch and gain) were constructed separately. Table 1 presents the ![]() obtained for the test corpus using the three methods. The number of source/target random sources, centroids (VQ-based) or Gaussians (GMM-based method) ranged from 4 to 128. When the number of random sources exceeded 128, it was impossible to evaluate the performance of all three methods due to over-estimation. In most cases,
obtained for the test corpus using the three methods. The number of source/target random sources, centroids (VQ-based) or Gaussians (GMM-based method) ranged from 4 to 128. When the number of random sources exceeded 128, it was impossible to evaluate the performance of all three methods due to over-estimation. In most cases, ![]() increased with the number of random sources. For the GMM method, the
increased with the number of random sources. For the GMM method, the ![]() was nearly saturated, when the number of Gaussians exceeded 32. The overall
was nearly saturated, when the number of Gaussians exceeded 32. The overall ![]() of the proposed method was not greater than the values reported previously, because the proposed method employed the maximum likelihood criterion. For the GMM-based approach, the mapping rules were set so as to minimize the overall distance between the transformed and target features. Similarly, in VQ-based and ML-based, the transformed feature was given by a linear combination of the code vectors, for which the linear combination weights were obtained using the minimum mean square error (MMSE) criterion. In the proposed method, the optimal combinations of the three features were selected to maximize the likelihood with respect to the target model. The results indicate that the selected features that have the maximum likelihood do not necessarily correspond to minimal distortion. The overall
of the proposed method was not greater than the values reported previously, because the proposed method employed the maximum likelihood criterion. For the GMM-based approach, the mapping rules were set so as to minimize the overall distance between the transformed and target features. Similarly, in VQ-based and ML-based, the transformed feature was given by a linear combination of the code vectors, for which the linear combination weights were obtained using the minimum mean square error (MMSE) criterion. In the proposed method, the optimal combinations of the three features were selected to maximize the likelihood with respect to the target model. The results indicate that the selected features that have the maximum likelihood do not necessarily correspond to minimal distortion. The overall ![]() of the voice transformation between genders (M2→F) was greater than that within gender (M3→M1). The difference between inter- and intra-gender transformation was more remarkable for pitch transformation. This result most likely occurred because the difference in feature distributions of men and women is larger than the difference in feature between two speakers of the same gender. In this case, the larger denominator
of the voice transformation between genders (M2→F) was greater than that within gender (M3→M1). The difference between inter- and intra-gender transformation was more remarkable for pitch transformation. This result most likely occurred because the difference in feature distributions of men and women is larger than the difference in feature between two speakers of the same gender. In this case, the larger denominator ![]() in (17) leads to an increase in
in (17) leads to an increase in ![]() .
.
In terms of the likelihood ratio, the performance of the proposed method was superior to that of VQ-based approach and close to that of the GMM approach, as shown in Table 2. Moreover, the reults of the proposed method was slighlty better than the ML-based approach. Considering that the maximum likelihood criterion was employed in the proposed method, this result is somewhat expected. It was also observed that the likelihood ratio increased with the number of candidates. This is because the probability of finding combinations of the three features (LPCC, pitch and gain) that more closely approximate the target speaker’s model increases when there are more candidates. The average log likelihood for the transformed features relative to the target model was -10.21 and -11.01 for the speakers F and M1, respectively. These values are close to those of the target features (-9.81 for speaker F and -10.45 for speaker M1). This result indicates that the proposed method yields transformed features that are statistically close to the target.
4.2 Subjective evaluation
In addition to the objective evaluation, two subjective listening tests were conducted. The first one was designed to evaluate the conversion of speaker individuality using the ABX test. For this test, 10 utterances were selected from 100 test utterances and each sentence was presented to 15 subjects. The first and second stimuli, A and B, were either the source speaker’s utterances or the target speaker’s utterances, while the last stimuli X was the transformed speech. Then, the subjects were asked to select either A or B as the original source of X. The subjects were presented the stimuli via headphones. Each listener was allowed to listen to the stimuli as many times as needed before determination. Audio examples can be listened on the web site: http://home.konkuk.ac.kr/ ~kseung/VT/ demo_page.htm.
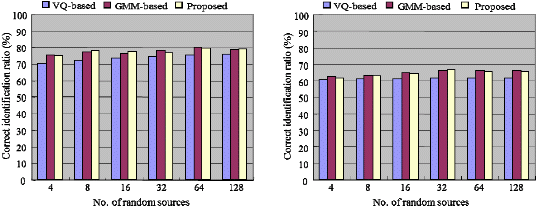
Fig. 2 shows the correct identification ratios versus the number of target/source random sources. Although the objective performance of the proposed method was inferior to that of the GMM-based approach, the subjective performance of the proposed method was nearly identical to that of the GMM-based approach. Compared with the VQ-based method, the proposed method showed the higher identification ratios even thought average ![]() of the proposed method was not higher than that of the VQ-based method. A possible explanation for this ABX test result is that for the proposed method, the transformed features were given by the features derived from the target speaker. By contrast, for both the VQ-based and GMM-based methods, the transformed features were artificially obtained.
of the proposed method was not higher than that of the VQ-based method. A possible explanation for this ABX test result is that for the proposed method, the transformed features were given by the features derived from the target speaker. By contrast, for both the VQ-based and GMM-based methods, the transformed features were artificially obtained.
For inter-gender transformation (M2→F), the subjects clearly perceived differences between the speakers, and even smaller modifications affected the perceived voice characteristics. The subjects tended to choose the target source when the transformed utterances sounded more or less different from the source speaker’s utterances, regardless of the perceptual similarities with the target voices. As a result, the overall identification ratio for the M2→F conversion was increased for all three methods. For the M2→F conversion, the number of random sources was highly correlated with the correct identification (The correlation coefficients for VQ-based, the GMM- based and the proposed method were 0.8279, 0.7242 and 0.7075, respectively).
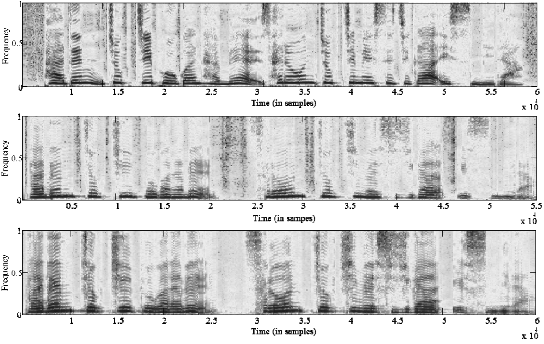
In the second test, we compared the quality of speech synthesized using our method with that obtained using either VQ-based or the GMM-based method. In this test, subjects were asked to indicate which was more preferred. The utterances used in the first test were also used in the second test. As summarized in Table 3, the proposed method performed slightly better than the conventional approaches. The subjects indicated that the clarify of the speech signals synthesized using the proposed method was superior to that of the other methods. This difference in quality most likely resulted from bandwidth widening problem caused by the averaging of the transformed speech signals in VQ-mapping and the GMM-based method. An example of the spectrograms for the target signal, the transformed signal using the GMM-based method and the trans-formed signal using the proposed method is shown in Fig. 3. This example clearly explains the reasons for the perceptual superiority of the proposed method, compared with the GMM-based method. In this example, more clear formant trajectories are observed in the transformed signal using the proposed method, especially in the high frequency regions. For the GMM-based method, the formants at the higher frequency regions are weaker and sometimes lost. This is mainly due to the averaging effects of the GMM-based method. However, pop and click sounds were sometimes perceived in the speech signals transformed using the proposed method. These sounds might result from abrupt changes in the sequence of the transformed features. Increased emphasis on the concatenation likelihood function in (15) might reduce these sounds, as the transitional probabilities between identical states tend to have a larger value. However, excessive emphasis on the concatenation likelihood function might degrade voice transfor-mation performance if the target likelihood function is not given adequate weight. Hence the quality of the synthesized speech signals can be further improved by careful
Table 3. Preference test results of each method. | |||
Target speaker | VQ-based | GMM-based | Proposed |
M1 | 27.3 | 34.5 | 38.2 |
F | 27.1 | 35.4 | 37.5 |
V. Conclusions
A new voice transformation algorithm that is based on feature selection was proposed. The sequences of the transformed features were constructed by selection of the appropriate features from the target speaker’s database. During the feature selection process, two probability models were taken into consideration-the inter- and intra-speaker models. For the inter-speaker model, the source/target features were controlled by the random sources shared between the two speakers. The intra-speaker model was represented in the context of HMM, which was built from the training source features.
Both objective and subjective tests were performed to evaluate the effectiveness of the proposed method. Sets of utterances from four speakers were used in the evaluation. The results of the objective test showed that the performance of the proposed method was inferior to that of the conventional methods. However, the results of the subjective evaluation show that the proposed method performed better than the conventional methods, because the transformed features were given by the original target features and not by the modified source features. In addition, results of a likelihood test showed that higher likelihood scores were obtained for the proposed model compared with the independent feature model, indicating superior matching of features from real speech signals.
