
I. 서 론
전화망을 통한 철도예약서비스 (IVR) [1], 자동티켓발매기 (ATIM) [2], 역안내서비스 (KIOSK) 등 고객접점의 자동화서비스에 음성인식을 적용하기 위하여 가장 먼저 고려해야 할 대상은 「기차역에 대한 역명인식」을 위한 음성인식 DB의 구축이다 [3]. 현재 코레일에서 운영하는 광역지하철역을 포함한 640개의 기차역명은 최소 인식 어휘이다. 음성인식을 위한 모델링의 기본단위로 단어, 음절, 음소, PLU (유사음소 단위: Phoneme-Likely Unit) 등 을 사용할 수 있다 [3]. 본 논문에서는 640개의 기차역명의 트라이폰 단위의 음소기반의 음성인식을 위하여 46 PLU (표 1의 State [2 ~ 4]의 각 열, sil 포함)를 사용하였다. 하지만 기차역명의 트라이폰 단위의 음성인식을 위한 음향 모델링시 훈련데이터의 부족으로 Unseen Data 에 대한 문제가 발생한다. 이러한 문제를 효율적으로 해결하기 위하여 트라이폰 단위의 음소 결정트리 (Phonetic Decision Tree)를 이용한 상태공유 방법을 사용한다 [4,8]. 이 방법은 결정트리의 분류와 예측으로 훈련 데이터에서 나타나지 않은 모델의 합성을 가능하게 하고 결정트리 기반의 상태공유를 위한 노드 분할 과정과 모델 선택 과정을 통해 모델의 복잡성을 완화시키고 한정된 훈련 데이터로부터 강건한 모델 파라미터 추정을 가능하게 하여 필요한 파라미터 양과의 균형을 유지할 수 있는 장점을 가지고 있다 [4-7]. 음소결정트리에서는 중심음소를 기준으로 음성학적 질의에 의해 새롭게 생성된 음향모델은 군집화된 어느 하나의 덩어리에 포함되어 상태를 공유하며 미지의 음소에 대하여 군집화된 대표 상태를 공유하게 됨으로써 인식률의 향상을 가져올 수 있다. 이러한 군집화의 정도의 결정에 영향을 줄 수 있는 임계치의 설정은 대부분 실험치에 의하여 일괄 적용하거나 음소단위로 가변적으로 적용한다. 하지만 실험치에 의해 이러한 부분을 정확히 가늠하기는 쉽지가 않다 [4-7]. 음소의 개수에 대한 상태별 군집화 정도를 판단해야 하기 때문이다. 또한 이것이 반드시 인식률 향상에 가져온다고 볼 수 없다. 군집화의 정도가 너무 크거나 너무 작으면 변별력이 떨어져 인식률이 오히려 감소할 수 있다. 따라서 본 논문에서는 이러한 임계치의 자동결정을 위하여 앞서 언급한 음소별 상태별 군집화율에 대하여 PLU 빈도수 와 군집화율의 상관관계를 분석하고 이를 바탕으로 회귀분석을 통하여 도출된 회귀식에 의해 기차역명에서의 음소의 빈도수에 대한 자료를 바탕으로 군집화율을 추정하고 추정된 군집화율에 따라 임계치를 자동으로 결정하도록 한다. 이러한 방법이 기존 수작업 임계치 결정방법보다 제안된 임계치 자동결정알고리즘 에서의 인식률이 크지는 않지만 1.4~2.3 %의 인식률의 향상을 보임을 알 수 있다. 이는 적어도 제안된 임계치 자동결정알고리즘이 실험에 의하여 수작업으로 임계치를 결정하는 방식 보다는 효율적이며 유효성이 확인 할 수 있다. 본 논문의 구성은 Ⅰ장 서론에 이어, Ⅱ장에서는 이론적 배경에 대하여 살펴보고, Ⅲ장에서는 제안하는 방식에 대하여 알아보고, Ⅳ 실험을 통하여 제안하는 방식의 알고리즘의 유효성을 확인하고, Ⅴ장에서는 결론 및 향후 계획에 대하여 이야기한다.
II. 이론적 배경
한 음소에 대한 결정트리는 어느 모델들이 특정 문맥내에서 사용될지를 결정해줌으로써 하나의 트라이폰이 주어지면 루트노드에서부터 출발하여 현재의 문맥에 관한 음성학적 질의 (「왼쪽 또는 오른쪽 음소가 집합 ![]() 의 원소인가?」의 형태)의 결과에 따라 다음노드를 선택하는 방식의 트리순회를 통하여 하나의 모델을 선택한다. 이런 트리는 훈련 데이터에 없던 트라이폰 모델을 합성해 낼 수 있고, 해당 트라이폰 모델의 문맥과 가장 비슷한 단말 트리 노드를 찾아 이와 연관된 공유상태들로 구성 할 수 있다 [8-10]. 임의의
의 원소인가?」의 형태)의 결과에 따라 다음노드를 선택하는 방식의 트리순회를 통하여 하나의 모델을 선택한다. 이런 트리는 훈련 데이터에 없던 트라이폰 모델을 합성해 낼 수 있고, 해당 트라이폰 모델의 문맥과 가장 비슷한 단말 트리 노드를 찾아 이와 연관된 공유상태들로 구성 할 수 있다 [8-10]. 임의의 ![]() 를 HMM 상태들의 집합이라고 하고
를 HMM 상태들의 집합이라고 하고 ![]() 를
를 ![]() 의 Log Likelihood라 할 때 집합 S에 있는 모든 상태들이 묶였다는 가정하에 훈련 데이터의 프레임들의 집합인 F에서 생성된다고 하면, 공통 평균
의 Log Likelihood라 할 때 집합 S에 있는 모든 상태들이 묶였다는 가정하에 훈련 데이터의 프레임들의 집합인 F에서 생성된다고 하면, 공통 평균 ![]() 와 분산
와 분산 ![]() 를 공유한다 [10]. (단, 전이 확률은 무시된다.) 또한 묶인 상태들의 상태별 프레임의 정렬이 바뀌지 않는다고 가정하면
를 공유한다 [10]. (단, 전이 확률은 무시된다.) 또한 묶인 상태들의 상태별 프레임의 정렬이 바뀌지 않는다고 가정하면 ![]() 에 대해 수식 (1)과 같이 쓸 수 있다.
에 대해 수식 (1)과 같이 쓸 수 있다.
![]() (1)
(1)
![]() 는 상태
는 상태 ![]() 에 의하여 생성되는 관측 프레임
에 의하여 생성되는 관측 프레임 ![]() 의 사후확률이다. 만일 출력확률밀도함수가 가우시안식이면 수식 (2)와 같이 쓸 수 있다.
의 사후확률이다. 만일 출력확률밀도함수가 가우시안식이면 수식 (2)와 같이 쓸 수 있다.
![]() (2)
(2)
![]() 은 데이터의 차수를 나타낸다. 그러므로 전체 데이터 집합의 로그 확률은 상태들의 분산
은 데이터의 차수를 나타낸다. 그러므로 전체 데이터 집합의 로그 확률은 상태들의 분산 ![]() 와 전체 상태 점유인
와 전체 상태 점유인 ![]() 만으로 계산할 수 있게 된다. 상태들의 평균과 분산으로부터 앞부분을 계산할 수 있으며, 상태 점유수는 이전 단계의 Baum- Welch 재추정하는 동안 저장될 수 있다. 질의
만으로 계산할 수 있게 된다. 상태들의 평균과 분산으로부터 앞부분을 계산할 수 있으며, 상태 점유수는 이전 단계의 Baum- Welch 재추정하는 동안 저장될 수 있다. 질의 ![]() 에 의해 두 하위 집합
에 의해 두 하위 집합 ![]() 와
와 ![]() 를 나누는 상태들
를 나누는 상태들 ![]() 와 함께 주어진 노드일 경우, 그 노드는 다음 수식 (3)을 최대화하는 질의
와 함께 주어진 노드일 경우, 그 노드는 다음 수식 (3)을 최대화하는 질의 ![]() 를 사용하여 분할한다.
를 사용하여 분할한다.
![]() (3)
(3)
수식 (3)의 ![]() 는 음성학적 질문
는 음성학적 질문 ![]() 에 대한
에 대한 ![]() 로 응답한
로 응답한 ![]() 의 로그유사도 (Log Likelihood)이고,
의 로그유사도 (Log Likelihood)이고, ![]() 는 분할하기전의 파티션 전체의 로그유사도이다.
는 분할하기전의 파티션 전체의 로그유사도이다. ![]() 가 최대가 되는 지점에서 질문과 분할노드를 선택하며 여기에서 가장 적합한 질의를 사용했을 때 로그 유사도의 증가량이 기준 문턱치 보다 높은 경우에만 분할을 하며 그 이득이 특정 임계치가 될 때 까지 이러한 과정을 반복한다. 본 논문에서는 이러한 임계치의 결정을 위하여 통계적 기법인 상관관계 분석과 회귀분석을 활용하고자 하였다 [11].
가 최대가 되는 지점에서 질문과 분할노드를 선택하며 여기에서 가장 적합한 질의를 사용했을 때 로그 유사도의 증가량이 기준 문턱치 보다 높은 경우에만 분할을 하며 그 이득이 특정 임계치가 될 때 까지 이러한 과정을 반복한다. 본 논문에서는 이러한 임계치의 결정을 위하여 통계적 기법인 상관관계 분석과 회귀분석을 활용하고자 하였다 [11].
III. 제안하는 방법
3.1. 음소의 빈도수에 따른 군집화율
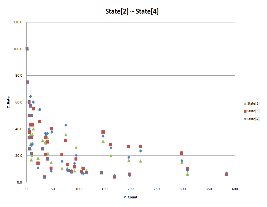
본 논문에서는 표 1과 같이 기차역명에서의 음소의 빈도수 (P_Count), 훈련 데이터의 음소의 상태별 점유 빈도수 (S_Count), 음소 결정트리에서의 임계치 증가에 따른 음소별 군집화율의 평균치 (C_Rate)를 가지고 그 상관관계를 분석하고 각 빈도수에 따른 군집화율을 추정하고자 하였다. 그림 1에서 알 수 있듯이 640개의 기차역명에서 음소의 빈도수가 높을수록 군집화율이 감소하고 있는 것을 알 수 있다. X축의 음소별 빈도수 대비 Y축의 군집화율의 상관관계를 분석해보면 State [2]~State [4]의 총 빈도수 대비 군집화율에서 Pearson 상관계수는 -0.501의 부의 상관관계를 가진다. 이는 State Tying 시 음소의 빈도수가 적은 경우에 Unseen Data에 대하여 질의에 의해 더 많은 상태공유를 가진다는 것으로 이해할 수 있다. 그리고 훈련 데이터의 음소의 상태별 점유 빈도수와 앞서 분석한 음소의 빈도수와의 상관관계를 보면 Pearson 상관계수 0.949의 정의 강한 상관관계를 가지고 있음을 알 수 있다. 이는 기차역명의 음소의 출현 빈도수가 클수록 훈련데이터의 음소의 상태별 점유 빈도수가 커지고 있는 것으로 이해할 수 있다. 또한 음소의 상태별 점유 빈도수와 군집화율의 상관관계를 보면 Pearson 상관계수 -0.550으로 음소별 상관관계와 같이 부의 상관관계를 가지고 있음을 알 수 있다. 이 또한 훈련 데이터의 음소의 상태별 점유 빈도수가 커질수록 군집화율이 감소하는 것으로 이해할 수 있다. 위에서 살펴본 바와 같이 기차역명의 음소의 빈도수와 훈련 데이터의 음소의 상태별 점유 빈도수는 군집화율에 영향을 주고 있음을 알 수 있으며 상관계수는 모두 0.01 수준에서 양쪽에서 유의하였다. 따라서 음소의 빈도수, 훈련 데이터의 음소의 상태별 점유 빈도수에 따른 군집화율에 대하여 회귀분석하게 되면 다음과 같은 회귀모형을 고려할 수 있다. Model1의 경우는 음소의 빈도수만을 가진 단순 회귀모형, Model2의 경우에는 훈련 데이터의 음소의 상태별 점유 빈도수를 가진 단순 회귀모형, Model3의 경우에는 Model1과 Model2의 변수를 모두 포함한 다중 회귀모형이다. 표 2를 살펴보면 분산분석 (ANOVA) 결과 Model1과 Model2의 경우 P값이 0.000으로 5 % 신뢰수준일 때의 P값의 임계치 0.05보다 작기 때문에 귀무가설을 기각하여 편회귀계수는 0이 아니라고 할 수 있다. 하지만 Model3의 경우 (t 검정에서) 훈련 데이터의 음소의 상태별 점유 빈도수는 P값이 0.001로 5 % 신뢰수준일 때의 P값의 임계치 0.05보다 작기 때문에 유의하였으나 음소의 빈도수는 P값이 0.366으로 5 % 신뢰수준일 때의 P값의 임계치 0.05보다 크기 때문에 유의하지 않았다. 또한 다중 공선성을 진단할 수 있는 통계량인 Tolerance (공차한계)의 값이 0.100, VIF (Variance Inflation Factor: 분산팽창계수)의 값이 10.048로 독립변수간의 약간의 다중 공선성의 문제가 있음을 알 수 있다. 따라서 Model3은 적합하지 않다. 본 논문에서는 Model1과 Model2의 회귀모형을 고려하였다. 회귀분석에 의해 결정된 Model1과 Model2의 수식은 (4), (5)와 같으며 각각 음소의 빈도수 (P_Count), 상태별 점유빈도수 (S_Count)가 1단위 증가할 때 군집화율 C (C_Rate)가 0.116, 0.038 감소함을 의미하며 상수 36.7, 40.2는 절편을 나타낸다. 또한 수식 (6)의 경우에도 같은 의미를 가진다.
|
그림 1. 음소의 출현 빈도수에 따른 군집화율 Fig. 1. Phoneme Frequency and Clustering Rate. |
![]() (4)
(4)
![]() (5)
(5)
표 2에서와 같이 Model2의 R Square는 0.302로 Model1의 R Square의 0.251 보다 0.051 더 높으므로 Model2의 독립변수가 종속변수에 대하여 설명력이 더 큼을 알 수 있다. 본 논문에서는 Model2의 경우를 선택하기로 한다. Model2의 종속변수인 C_Rate에 대하여 Log10 함수로 변환하여 회귀분석을 하게 되면 변환된 모형인 Model4의 R Square는 0.339 이다. 이는 변환하지 않은 모형인 Model2의 0.302에 비해 큰 값이며, 분산분석 결과인 F 값 또한 68.116으로 Model2의 57.584 보다 큰 값이다. 따라서 변환한 모형이 변환하지 않은 모형보다 종속변수에 대한 설명력이 크다고 할 수 있다. 또한 그림 2에서 알 수 있듯이 Model4의 히스토그램은 Model2의 잔차의 도표에 비해 훨씬 근접해 있으며 정규확률산점도의 경우에도 Model2의 산점도에 비해 45도선에 거의 근접해 있음을 보여주고 있다. 그리고 종속변수는 Model2의 산점도에 비해 예측값의 크기에 관계없이 잔차의 대부분이 일정한 범위 내에서 균등하게 분포되어 있다. 따라서 종속변수인 C_Rate에 Log 값을 취하여 변환한 모형이 변환하지 않은 모형보다 더 좋은 결과를 나타내고 있음을 알 수 있다. Model4의 수식은 (6)과 같다.
|
그림 2. 잔차 그래프 Fig. 2. Graph of Residual. |

![]() (6)
(6)
3.2. 군집화율에 따른 임계치 결정
일괄 적용된 임계치 증가에 따른 인식률을 보면 Th (Threshold) 50.0에서 95.2 %, Th 100.0에서 95.3 %, Th 200.0에서 95.8 %, Th 300.0에서 94.9 %, Th 400.0에서 95.0 %, Th 500.0에서 94.4 %로 Th 200.0에서 95.8 % 최고치를 가지며 계속 증가 할수록 감소 또는 소폭 반등하고 있음을 알 수 있다. 이는 반드시 임계치의 값이 높다고 인식률이 높은 것은 아님을 알 수 있으며 적정한 수준 (실험치)에서 임계치를 결정해야함을 알 수 있다. 하지만, 일괄 적용된 임계치 보다는 음소의 상태별 임계치를 적용하는 것이 최적의 선택이나 이 또한 많은 실험과 시행착오를 통해서만 결정이 가능하며 많은 시간이 필요이다. 따라서 적정수준의 군집화율에서 임계치를 결정하는 것이 중요하다. 그림 3에서 그래프를 살펴보면 X축의 Log를 취한 평균 군집화율 LogC_Rate와 Y축의 임계치 Th의 상관관계를 분석해보면 Pearson 상관계수 -0.957의 부의 강한 상관관계를 가진다. 이는 LogC_Rate가 증가할수록 거의 선형적으로 Th가 감소하고 있음을 의미한다. 본 논문에서는 임계치별 평균 군집화율에 따른 Th 결정을 최적이라고 가정하고 이를 음소의 상태별 임계치로 사용하고자 하였다. ![]()
![]() 은 로그를 적용한 추세선의 수식이다. 여기서 C (X축의 값)는 로그를 취한 군집화율을 의미하며 Th (Y축의 값)는 결정되는 임계치의 값을 의미한다. 따라서 앞서 설명한 Model4의 수식 (6)에서 상태별 빈도수에 따라 결정된 군집화율인 C가 입력값이 되며 이에 따라 Th값 (임계치)이 결정된다. 또한 실험을 통하여 기존 일괄 임계치 적용방법 보다 유효성이 있음을 확인하였다.
은 로그를 적용한 추세선의 수식이다. 여기서 C (X축의 값)는 로그를 취한 군집화율을 의미하며 Th (Y축의 값)는 결정되는 임계치의 값을 의미한다. 따라서 앞서 설명한 Model4의 수식 (6)에서 상태별 빈도수에 따라 결정된 군집화율인 C가 입력값이 되며 이에 따라 Th값 (임계치)이 결정된다. 또한 실험을 통하여 기존 일괄 임계치 적용방법 보다 유효성이 있음을 확인하였다.
|
그림 3. 군집화율에 따른 임계치 Fig. 3. Clustering Rate and Threshold. |
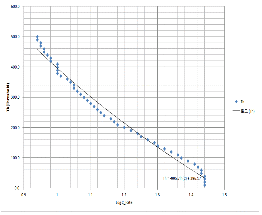
그림 4는 ![]() ~
~ ![]() 까지의 45개의 PLU (sil은 제외)에 대한 Th를 결정하기 위한 알고리즘의
까지의 45개의 PLU (sil은 제외)에 대한 Th를 결정하기 위한 알고리즘의 ![]() 이다.
이다. ![]() 에서
에서 ![]() 일 때 군집화율
일 때 군집화율 ![]() 는 절편 1.538에서 기울기 0.001과
는 절편 1.538에서 기울기 0.001과 ![]() 에서의 상태별 점유 빈도수
에서의 상태별 점유 빈도수 ![]() (첫번째 PLU에 대한 상태별 점유 빈도수)을 곱한 값을 빼서 결정된다. 이렇게 계산된 군집화율
(첫번째 PLU에 대한 상태별 점유 빈도수)을 곱한 값을 빼서 결정된다. 이렇게 계산된 군집화율 ![]() 가 0.94 이하일 경우에는 Th는 500.0으로 고정하고 1.44 이상일 경우에는 10.0으로 고정한다. 그렇지 않을 경우에는 그림 3의 Th 결정수식인 추세선에 해당하는 로그 수식을 이용하여 앞서 계산된 군집화율
가 0.94 이하일 경우에는 Th는 500.0으로 고정하고 1.44 이상일 경우에는 10.0으로 고정한다. 그렇지 않을 경우에는 그림 3의 Th 결정수식인 추세선에 해당하는 로그 수식을 이용하여 앞서 계산된 군집화율 ![]() 를 입력값으로 하여 계산되는 값을 임계치로 결정한다. 결과는
를 입력값으로 하여 계산되는 값을 임계치로 결정한다. 결과는 ![]() ,
, ![]() : 첫 번째 PLU,
: 첫 번째 PLU, ![]() :임계치 순으로 출력한다.
:임계치 순으로 출력한다. ![]() 에 대하여
에 대하여 ![]() (45번째 PLU) 까지 반복수행하며 State [3], State [4]에 대해서도 같은 과정을 수행한다.
(45번째 PLU) 까지 반복수행하며 State [3], State [4]에 대해서도 같은 과정을 수행한다.
|
그림 4. 알고리즘 의사코드 Fig. 4. Pseudo Code for Algorithm. |
IV. 실험 및 고찰
음소 결정트리에서의 효율적인 임계치 결정을 위해 제안한 임계치 자동 결정알고리즘의 유효성을 확인하기 위하여 각 Model 별 구성을 표 3과 같이 4가지의 경우로 구성하여 음향모델을 작성하였고 트라이폰 단위의 학습용 발음열과 발음사전을 구성하여 인식률 실험을 진행하였다 [12,13]. 객관적인 실험을 위하여 표준 음성인식기인 HTK (39 MFCC, CHMM, 3 State, 8 Mixture) [14]를 이용하였고 640개의 기차역명의 인식률 평가를 위해 20~30대 남자 40명 과 여자 40명이 조용한 사무실 환경에서 녹음한 총 80명의 화자 중 학습에 참여한 화자 60명 (남: 30, 여: 30)을 제외한 학습에 참여하지 않은 화자 20명 (남: 10, 여: 10)이 녹음한 음성파일 (샘플링 8 kHz, 양자화 16 bit)을 사용하였다. 그리고 회귀모형에 따라서 결정된 음소의 상태별 임계치에 대하여 인식률을 보면 기존 일괄 적용을 Baseline (기준선)으로 볼 때 Model1, Model2, Model4에서의 결정된 Th를 사용하는 것이 Baseline 보다 1.4 ~ 2.3 %의 수준에서 인식률이 향상되고 있음을 알 수 있다. 이는 추정된 군집화율에 따라 임계치를 결정하는 것이 기존의 방법보다 아주 큰 폭의 차이는 없지만 좀 더 세밀한 임계치를 줄 수 있고 음성인식에 있어서 유효성이 있음을 알 수 있다. 모델에 따른 인식률은 그림 표 3과 같고 Model4에서 98.1 %의 인식률을 보였다.
표 3. 인식률 Table 3. Recognition Rate (%). | ||||
Model | Baseline | Model1 | Model2 | Model4 |
Recog.Rate | 95.8 | 97.2 | 97.8 | 98.1 |
V. 결론 및 향후계획
본 논문에서는 코레일에서 운영중인 640개 기차역명의 음소기반의 음성인식을 위한 트라이폰 단위의 음향 모델링 시 발생할 수 있는 훈련 데이터의 부족 문제를 해결하기 위하여 음소 결정트리를 이용한 상태공유 방법을 사용하였다. 이를 위한 음소 결정트리 구축시 노드 분할을 위하여 사용되는 임계치의 결정에 있어 통계적 기법인 상관관계 분석과 회귀분석을 활용하여 군집화율을 추정하고 이를 이용하여 임계치를 자동으로 결정하는 방법을 제안하였다. 제안된 방법의 유효성 검증을 위한 인식률 실험에서 기존의 일괄 적용된 Baseline (95.8 %) 보다 1.4 ~ 2.3 % (97.2 ~ 98.1 %) 향상된 인식률을 보였다. 이러한 통계적 기법을 활용한 방식은 한국의 기차역명의 음성인식을 위한 좋은 토대가 될 것으로 기대된다. 향후 좀 더 확장된 기차역명 (각 지역의 지하철역명이 포함된) 및 지명에 대하여도 이러한 분석을 통하여 좀 더 효율적인 인식방법에 대해 연구할 계획이다.
