

I. 서 론
II. 유동 해석 기법
III. 다중충실도 모델
3.1 모델 학습 데이터 베이스 구축
3.2 모델 학습 전략
IV. 결 과
4.1 예측 오차 및 성능 향상률 정의
4.2 모델 예측 성능 검증
4.3 연산 비용 절감 효율성 분석
V. 결 론
I. 서 론
최신 의류 건조기는 기본적인 건조 기능을 넘어 위생 관리 및 미세먼지 제거 등 다양한 부가 기능을 제공하며 필수 가전제품으로 자리 잡고 있다. 건조기의 핵심 성능지표인 건조시간은 내부 순환 유량에 의해 결정되며, 이는 팬 시스템의 공력 성능과 직결된다. 따라서 건조시간을 단축하고 에너지 효율을 높이기 위해서는 높은 유량을 확보할 수 있는 고효율 팬 시스템의 개발이 필수적이다. 이에 본 연구에서는 건조기 내부에 장착된 다익 원심팬을 대상으로 공력 성능을 효율적으로 극대화하기 위한 형상 최적화를 수행하여, 건조 성능 향상을 달성하고자 한다.
의류 건조기용 원심팬 및 공기 배출 시스템을 대상으로, 공력 성능을 향상 시키기 위한 연구가 활발히 수행되어왔다. Choi et al.[1]은 원심팬, 입·출구 덕트, 하우징을 포함한 의류 건조기 배기 시스템 전체에 대해 3차원 Reynolds Averaged Navier-Stokes(RANS) 기반의 전산유체역학(Computational Fluid Dynamics, CFD) 해석을 적용하였다. 해당 연구는 팬 날개의 입·출구각을 설계 변수로 선정하고 반응표면법(Response Surface Methodology, RSM) 기반의 최적 설계를 수행하여, 최적 블레이드 적용 시 유량 성능을 향상 시켰다. Cho et al.[2]은 의류 건조기 순환 원심팬 시스템을 대상으로 2차원 및 3차원 RANS 기반의 수치해석을 수행하였다. 이때, 2차원 RANS와 3차원 RANS 결과를 각각 저충실도(Low-Fidelity, LF)와 고충실도(High-Fidelity, HF) 데이터로 활용하는 다중충실도 인공신경망(Artificial Neural Network, ANN) 기반의 최적화 설계기법을 제안하였다. 연구 결과로서 스크롤 컷오프 각도와 날개 입·출구각을 설계 변수로 하여 유량 성능 최적화를 수행하였으며, 2차원 해석 수준의 연산 비용으로 3차원 해석에 근접한 성능 예측 정확도를 확보하였다. 이를 통해 약 24 %의 유량 성능 향상을 달성하였다.
한편, 의류 건조기뿐만 아니라 다양한 응용 분야의 다익 원심팬을 대상으로 한 형상 최적화 연구 또한 다수 보고되고 있다. Han과 Maeng[3]은 스크롤 컷오프 형상 최적화를 위해 컷오프 각도와 반경을 설계 변수로 설정하고, 반응표면법을 활용하여 팬의 전체 효율 고려한 설계를 수행함으로써 최적의 컷오프 각도 및 설계 조건을 도출하였다. Kim et al.[4]은 주거용 환기 시스템의 다익 원심팬을 대상으로 스크롤 컷오프 각도, 스크롤 확산 각도, 허브 비, 블레이드 출구각 등 네 가지 주요 인자를 설계 변수로 선정하였다. 해당 연구는 반응표면법과 다목적 진화 알고리즘을 결합하여 공력 성능을 최적화하였으며, 도출된 최적 형상이 기준 모델 대비 전체 효율을 향상하였다. Zhou et al.[5]은 클래스-형상 변환 기법(Class-Shape Transformation, CST)을 기반으로 다익 원심팬 블레이드 형상을 변수화하고, 방사 기저 함수(Radial Basis Function, RBF) 기반 대리모델과 유전 알고리즘을 결합하여 총압 효율 향상을 달성하는 최적 설계를 수행하였다. Liu et al.[6]은 임펠러 블레이드 수, 출구각 및 스크롤 확산 각도 등을 설계 변수로 설정하고 직교배열 실험법과 CFD 해석을 연계하였다. 이들은 정상 상태 RANS 해석뿐만 아니라 대와류 모사기법(Large Eddy Simulation, LES)을 이용해 유동장을 분석함으로써, 정압 및 효율 성능을 효과적으로 향상시켰다.
그러나 이러한 선행 연구들은 대부분 고충실도 CFD 해석에 기반하여 제한된 설계 변수와 운전 조건에서만 최적화를 수행하였기 때문에, 설계 공간을 확장하여 다양한 운전 조건과 복잡한 다수의 설계 변수를 동시에 고려할 경우 막대한 계산 자원 및 시간이 요구된다는 한계가 있다.
따라서, 본 연구에서는 설계 변수의 추가로 인한 설계 공간의 확장이 발생하였을 때 설계 변수 추가로 인해 계산 공간이 확장되었을 때, 예측 정확도를 유지하면서 학습 데이터 수를 절감할 수 있는 전이학습 기법을 활용하였다. 먼저, 설계 변수로서 팬 시스템의 성능에 지배적인 영향을 주는 임펠러의 입·출구각을 고려하였으며, 스크롤 컷오프 각도와 임펠러의 운전 압력을 추가하여 설계 공간을 확장하였다. 먼저, 2차원 RANS 기반의 저충실도 데이터를 활용하여 신경망을 사전 학습시켰다. 또한, 새로운 변수가 포함된 데이터에 대해 전이 학습(Transfer learning)을 수행함으로써 입력 차원 증가에 따른 학습 부담을 최소화하였다.
이후, 소수의 3차원 CFD 고충실도 데이터를 단계적으로 학습에 활용하고, Automated Machine Learning(Auto-ML)을 적용하여 최적의 심층신경망(Deep Neural Network, DNN) 대리모델을 구축하였다. 이를 통해 다익 원심팬 시스템의 효율적인 최적 설계를 수행하였으며, 기존 다중충실도 모델을 이용한 경우와 다중충실도 모델에 전이 기법을 적용한 경우를 비교함으로써, 제안된 전이 학습 기반 DNN 모델의 예측 오차를 줄이고 비용을 절감하였다.
II. 유동 해석 기법
본 연구에서는 다익 원심팬의 내부 유동 특성을 정밀하게 예측하기 위해 상용 전산유체역학 코드인 ANSYS Fluent 2024 R1을 사용하여 수치해석을 수행하였다. 지배 방정식으로는 비압축성 유동에 대한 RANS 방정식을 적용하였으며, 연속 방정식과 운동량 방정식은 각각 다음 식으로 표현된다.
여기서 𝜌는 유체의 밀도, t는 시간, 𝜇는 유체의 점성 계수를 의미한다. 와 는 직교 좌표계에서의 좌표 성분을 나타낸다. 또한, 시간 평균 유속을 나타낸다. Eq. (2)의 우변 마지막 항인 는 난류 유동의 불규칙한 속도 섭동 성분 u'에 의해 발생하는 가상의 응력 항으로, Reynolds 응력이라 정의된다. 본 연구에서는 팬 날개 주변의 복잡한 유동을 정확히 모사하여 학습 데이터의 신뢰도를 높이기 위해, 벽 근처에서는 역압력 구배 예측 성능이 우수한 k-𝜔 모델을 사용하고, 외부 유동에서는 안정적인 예측을 하는 k-𝜖 모델을 사용하는 Shear Stress Transport(SST) k-𝜔난류 모델을 선정하였다. 해당 모델에서 도입된 변수 k는 난류 운동 에너지를 나타내며, 𝜔는 비소산율을 의미한다. 본 연구에서 사용한 속도 압력 연성 기법과 공간 차분 기법은 Table 1과 같다.
Table 1.
Numerical schemes for pressure-velocity coupling and discretization methods.
3차원 해석을 위해 구성한 계산 영역을 Fig. 1에 나타내었다. 2차원 해석은 3차원 형상의 임펠러의 스팬 50 %에서의 단면을 기준으로 수행되었으며, 해당 계산 영역에서의 형상을 Fig. 2에 나타내었다. 이때 유량 산출을 위한 기준 깊이는 스크롤의 높이인 0.025 m로 설정하여 2차원 해석을 수행하였다.
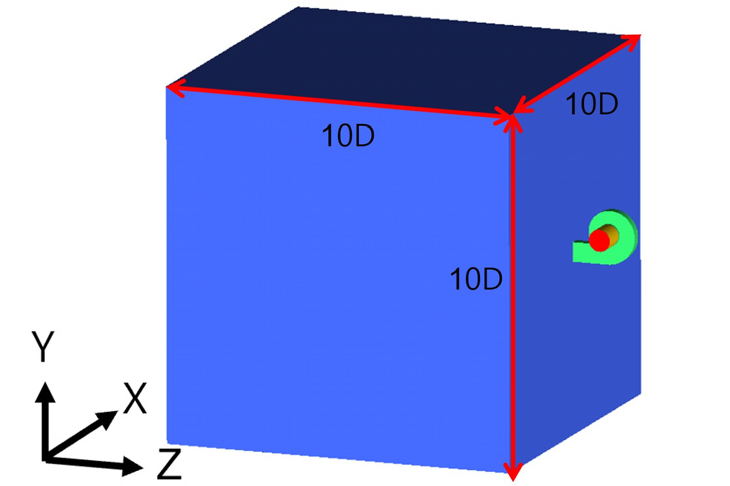
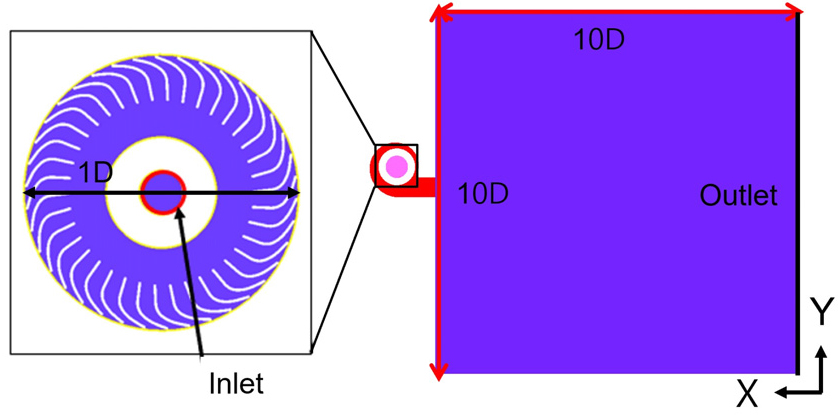
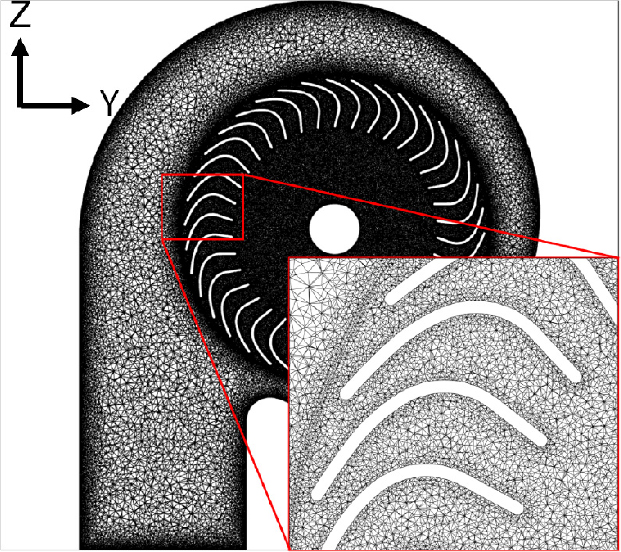
격자 생성에는 비정렬 사면체 요소를 사용하였으며, Fig. 3에 나타난 바와 같이 벽면 근처의 경계층 유동을 정확히 해석하기 위해 표면 격자크기를 조절하여 첫 번째 격자점 높이가 <5 이하를 유지하도록 조밀하게 격자를 구성하였다.[1,7] 해석에 사용 된 전체 격자수는 약 2,600만 개다. 임펠러의 회전 운동을 모사하기 위해 슬라이딩 메쉬 기법을 적용하였으며, 회전 속도는 2,500 r/min으로 설정하였다. 경계 조건으로는 입구와 출구에 각각 압력 조건을 부여하였으며, 0 Pa ~ 200 Pa 범위의 정압 차를 인가하여 다양한 운전점에서의 유동 특성을 분석하였다.
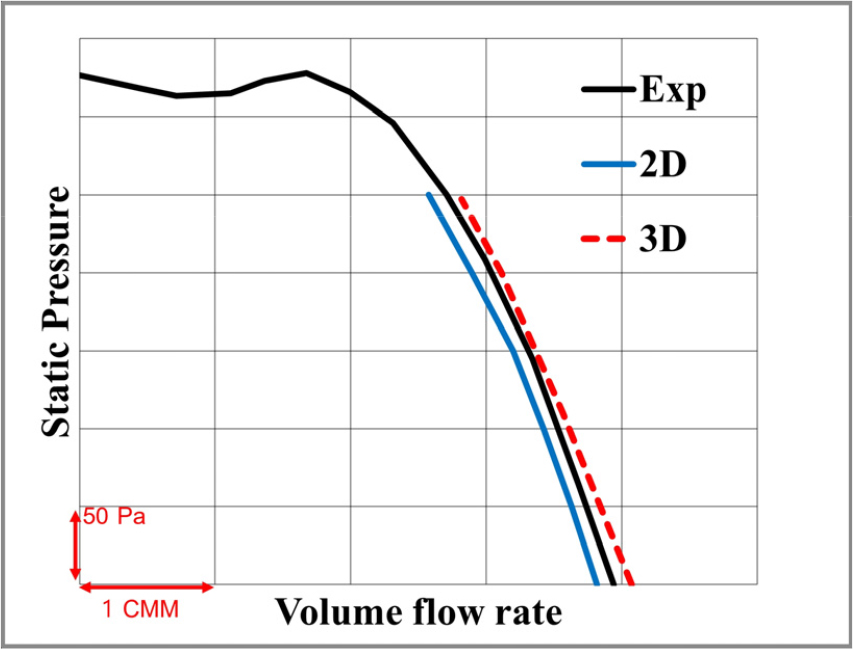
본 연구에서 적용된 2차원 및 3차원 수치해석 기법의 타당성을 검증하기 위해, 해석 결과와 실제 유동 실험 결과를 비교 분석하였다. 유동 실험은 Fig. 4에 나타낸 팬 성능 시험기를 이용하여 수행되었으며, 해당 장비는 AMCA 210-07[8] 규격을 준수하여 0.6 m × 0.6 m × 1.5 m의 규격으로 제작되었다. 대상 팬을 정격 회전수인 2,500 r/min으로 구동하여 P-Q 선도를 도출하였다.

수치해석 결과와 실험의 유량에 대한 압력 값을 나타낸 P-Q 선도는 Fig. 5와 같다. 정압이 0인 무부하 지점을 기준으로 2차원 및 3차원 해석 결과 모두 실험값 대비 약 3 % 이내의 오차를 나타내어, 본 해석 모델이 실제 유동을 정확하게 모사하고 있음을 확인하였다.
III. 다중충실도 모델
3.1 모델 학습 데이터 베이스 구축
본 연구에서는 설계 변수 확장에 따른 수치해석 비용 문제를 해결하기 위해, 전이 학습과 다중충실도 기법을 결합한 효율적인 설계기법을 제안한다. 이는 다량의 저충실도 데이터와 소량의 고충실도 데이터를 연계 학습하여, 최소한의 데이터로 추가된 설계변수에 대한 높은 예측 정확도를 확보한다.
학습 데이터 구축을 위해 팬 시스템의 성능에 지배적인 영향을 미치는 임펠러 입·출구각(, )을 1차 설계변수 로 선정 하였고, 추가한 2차 설계변수로는 스크롤 컷오프 각도(), 그리고 운전 압력(P)을 선정하였다. 입·출구각, 그리고 스크롤 컷오프 각도는 Fig. 6과 같이 정의된다.
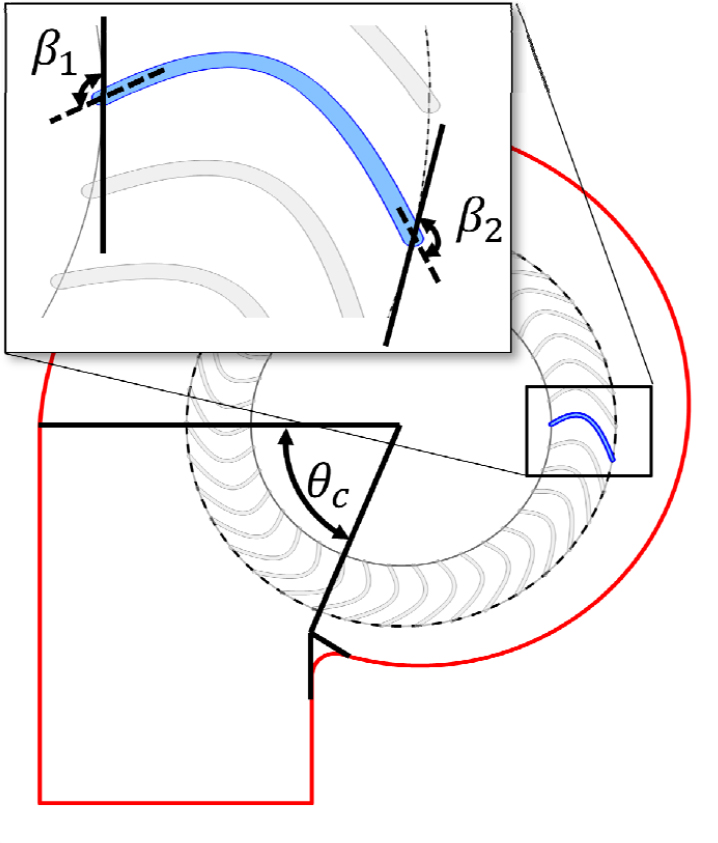
본 연구의 데이터 집합은 Table 2에 제시된 중심 복합 설계(Central Composite Design, CCD) 실험계획법을 적용하여 2인자 3수준의 임펠러 형상 변수와 4수준(20°, 40°, 60°, 80°)의 스크롤 컷오프 각도를 완전 요인 배치법으로 조합하여 총 36개의 케이스로 구성하였다. 저충실도 데이터 집합은 모든 형상 케이스에 대해 각각 세 가지 운전 조건에서 2차원 해석을 수행하여 총 108개로 구축하였다. 반면, 고충실도 데이터 집합은 설계 공간 내에서 무작위로 선정된 12개의 설계 변수 조합에 대해 3차원 해석을 수행하여 확보하였다.
Table 2.
Impeller inlet and outlet angle value.
| Num | Inlet angle [˚] | Outlet angle [˚] |
| 1 | ||
| 2 | + 22 | |
| 3 | – 22 | |
| 4 | – 12 | |
| 5 | – 15 | + 8 |
| 6 | + 15 | + 8 |
| 7 | – 15 | – 8 |
| 8 | +12 | |
| 9 | + 15 | – 8 |
3.2 모델 학습 전략
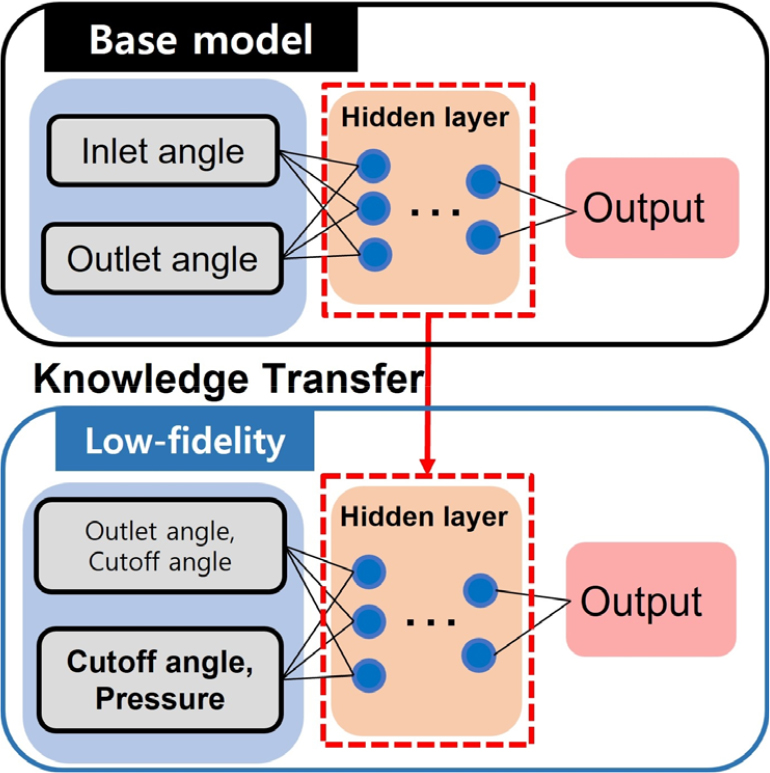
제안된 설계기법은 입력 변수의 차원 증가에 따른 학습 부담을 완화하고, 충실도 차이를 극복하기 위해 Figs. 7과 8 같이 모두 설계변수를 입력변수로 받고, 유량성능을 출력변수로 출력하는 두 개의 모델에 대해 각각의 학습 과정을 수행한다. 설계 공간 확장을 위한 Fig. 7의 첫 번째 단계인 전이 학습은 설계 변수가 늘어남에 따라 요구되는 과도한 학습 데이터 구축 부담을 완화하기 위한 과정이다. Fig. 7에 도시된 바와 같이, 먼저 핵심 변수인 임펠러 입· 출구각(, )만을 입력으로 하는 기저 모델을 구성하고 팬 날개 형상에 따른 기본 성능 특성을 사전 학습시킨다. 이후, 기저 모델의 가중치 정보를 전이 받아 스크롤 컷오프 각도와 운전 압력이 추가된 확장된 입력 공간을 갖는 저충실도 모델을 학습한다. 이 방식은 복잡한 다변수 공간에서의 초기 학습 수렴 속도를 높이는 데 기여한다.
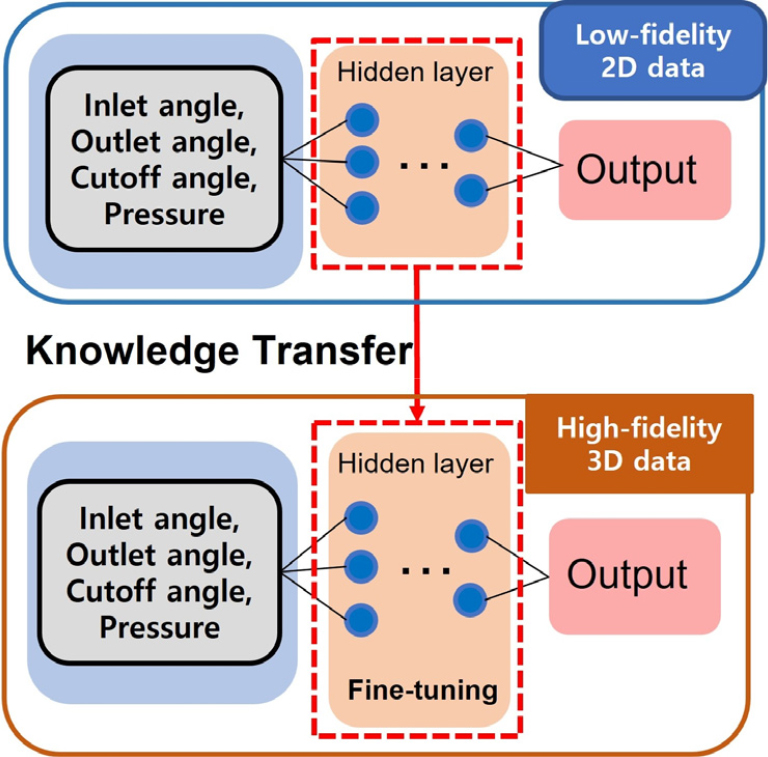
그리고 충실도 향상을 위한 전이 학습 두 번째 단계는 저충실도 모델의 예측오차를 보정하여 고충실도 예측 성능을 확보하는 과정이다. Fig. 8과 같이, 앞선 단계에서 2D 데이터로 충분히 학습된 저충실도 모델의 파라미터를 다시 고충실도 모델로 전이시킨다. 이때 저충실도 모델은 유동의 경향성에 대한 사전 지식 역할을 한다. 고충실도 모델은 이러한 사전 정보를 바탕으로 소량의 3차원 데이터를 이용해 가중치를 미세 조정함으로써, 2차원 해석과 3차원 해석 간의 정량적 오차를 보정하고 높은 정확도를 달성하게 된다.
최종적으로 구축된 고정밀 다중충실도 대리 모델은 최적화 알고리즘과 연동되어, 주어진 제약 조건 하에서 유량 성능을 극대화하는 최적 설계 변수 조합을 도출하는 데 활용된다. 본 연구에서는 Storn과 Price[9]가 제안한 차분 진화(Differential Evolution, DE) 알고리즘을 적용하였다. DE는 개체군 기반의 확률적 탐색 기법으로, 목적 함수의 미분 정보를 요구하지 않으므로 심층신경망과 같은 강한 비선형성을 갖는 블랙박스 최적화 문제에 효과적이다. 최적화는 초기화, 변이, 교차 그리고 선택 과정을 반복하며 진행된다.
변이 단계에서는 Eq. (3)과 같이 서로 다른 세 개체 벡터 ()의 차분을 이용하여 새로운 변이 벡터 를 생성한다. 이후 교차 연산을 통해 시험 벡터를 구성하고, 선택 단계에서 다중충실도 모델을 이용해 목적 함수인 유량 성능을 평가한다. 시험 벡터의 성능이 기존 개체보다 우수한 경우에만 다음 세대로 보존하는 방식으로, 해는 반복적으로 갱신되며 전역 최적해로 점진적으로 수렴한다.
한편, 본 연구에서는 다중충실도 모델의 예측 성능을 극대화하기 위해, 심층신경망의 구조와 학습 변수를 자동으로 탐색하는 Auto-ML 기법을 도입하였다.[10] 특히 본 연구에서는 베이지안 최적화 알고리즘을 적용하였는데, 이는 목적 함수의 분포를 추정하는 대리 모델을 통해 성능 개선 가능성이 높은 영역을 우선적으로 탐색하는 전략을 취한다.[11] 이를 통해 기존의 무작위 탐색 방식 대비 적은 연산 비용으로도 전역 최적해에 빠르고 효과적으로 수렴할 수 있다.[12] 학습 데이터, 검증 데이터 그리고 시험 데이터의 비율을 8:1:1로 분할한 다음, “은닉층의 수는 2개 ~ 5개, 각 층의 뉴런 수는 32개 ~ 256개 범위로 지정하였다. 또한, 최적해 탐색 과정에서 가중치의 갱신 보폭을 결정하는 학습률은 5 × 10–5 ~ 1 × 10–3 범위로 설정하였으며, 가중치의 크기를 제한하여 과적합을 억제하는 정규화 기법인 가중치 감쇠율은 1 × 10–6 ~ 1 × 10–4 범위에서 탐색을 수행하였다. 목적 함수는 검증 데이터 집합에 대한 손실 함수 최소화로 설정하였으며, 총 1,000회의 반복 탐색을 통해 최적의 하이퍼파라미터 조합을 도출하였다. Auto-ML 기법을 적용하여 탐색 결과 도출된 최적의 하이퍼파라미터 조합은 Table 3과 같다. 최적 모델은 3개의 은닉층 구조를 가지며, 각 층의 뉴런 수는 입력층에서 출력층 방향으로 각각 238, 247, 231개로 구성되었다. 또한 학습률은 0.00092, 가중치 감쇠율은 2.04e-05로 결정되어, 과적합을 방지하면서도 안정적인 학습 수렴이 가능하도록 설정되었다.
IV. 결 과
4.1 예측 오차 및 성능 향상률 정의
본 연구에서는 제안된 다중충실도 모델의 예측 성능과 최적 설계의 유효성을 정량적으로 평가하기 위해, 아래와 같이 예측 오차율(Prediction Error, )을 정의하였다.
여기서 과 는 각각 고충실도 CFD 해석을 통해 얻은 실제 유량 값과 대리모델이 예측한 유량 값을 의미한다.
또한, 최적 설계를 통한 성능 개선 효과는 유량 성능 향상률()을 통해 평가하였다.
와 는 각각 최적 모델과 기준 모델의 유량을 나타낸다.
4.2 모델 예측 성능 검증
본 연구에서 구축된 최적 모델의 데이터 효율성을 검증하기 위해, 저충실도 학습데이터 개수 변화에 따른 모델의 예측 오차 추이를 분석하였다. Fig. 9는 2D 데이터 수 증가에 따른 검증 데이터의 최대 오차와 평균 절대 오차의 변화를 나타낸다.
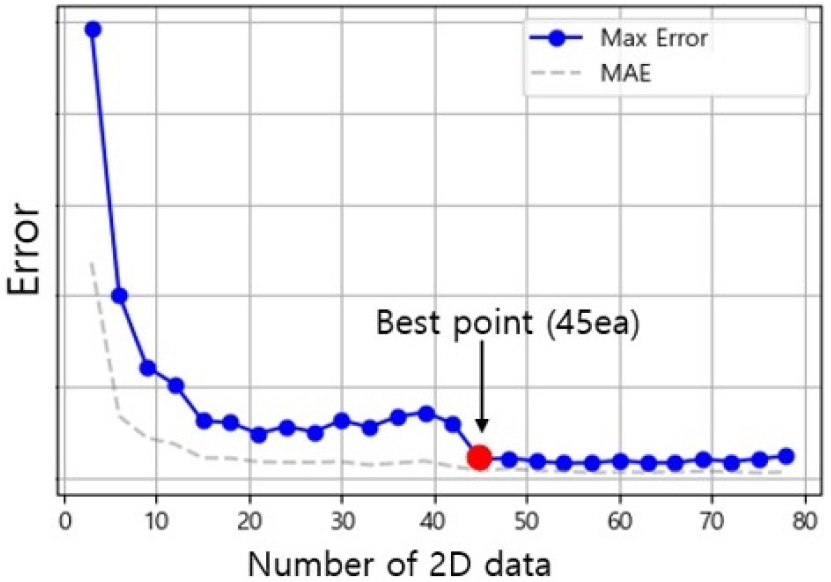
Fig. 9에서 확인할 수 있듯이, 학습데이터 수가 적은 초기 구간에서는 오차가 급격히 감소하다가, 약 45개 지점을 기점으로 오차 감소 폭이 수렴하는 경향을 보인다. 이는 입·출구각 데이터를 사전 학습한 기저 모델을 활용할 경우, 설계 공간이 확장되더라도 약 45개의 2차원 데이터만으로 스크롤 컷오프 각도와 운전 압력에 따른 주요 유동 경향성을 충분히 학습할 수 있음을 의미한다.
제안된 전이 학습 기반 다중충실도 모델의 예측 성능을 정량적으로 검증하기 위해, 학습에 참여하지 않은 무작위 테스트 케이스를 선정하여 저충실도 모델과 다중충실도 모델의 유량 예측 오차를 고충실도해석 결과와 비교 분석하였다.
주요 검증 케이스에 대한 모델별 예측 오차율 비교한 결과는 Table 4와 같다. 표에서 확인할 수 있듯이, 2차원 해석 기반의 저충실도 모델은 7.31 % ~ 22.44 % 의 다소 높은 오차율을 보였다. 이는 2차원 해석이 3차원 유동장에서 발생하는 복잡한 2차 유동 손실이나 형상적 특징을 완벽히 반영하지 못하는 물리적 한계에 기인한다.
Table 4.
Comparison of prediction errors between 2D (LF) and MF models.
| Case | 2D Prediction error (%) | MF Prediction error (%) |
| 1 | 15.77 | 2.55 |
| 2 | 18.00 | 3.44 |
| 3 | 7.31 | 2.44 |
| 4 | 22.44 | 3.82 |
그러나 본 연구에서 제안한 전이 학습 기반 다중충실도 모델은 모든 검증 케이스에서 오차율을 2.44 % ~ 3.82 % 수준으로 획기적으로 감소시켰다. 특히 2D 예측 모델에서 22.44 %의 가장 큰 오차율을 보였던 Case 4의 경우, Multi Fidelity(MF) 모델 적용 후 오차율이 3.82 %로 줄어들어 약 18. 62 % p(percentage point)의 절대 오차 감소 효과를 보였다. 이는 저충실도 모델이 학습한 전역적인 유동 경향성을 유지하면서도, 전이 학습을 통해 2차원과 3차원 해석 간의 정량적 격차를 보정하였음을 입증한다. 결론적으로, 제안된 모델은 적은 수의 고충실도 데이터만으로도 전체 설계 공간에서 3차원 CFD 수준의 높은 예측 신뢰도를 확보하였으며, 이를 기반으로 효율적인 설계 최적화 수행이 가능함을 확인하였다.
구축된 예측 모델과 차분 진화 알고리즘을 연동하여, 제한된 설계 범위 내에서 유량 성능을 극대화하는 전역 최적해를 탐색하였다. 최적화 결과 설계 변수는 스크롤 컷오프 각도, 임펠러 입구각 그리고 출구각이 각각 80°, +0.2° 그리고 -11°로 도출되었다. 도출된 최적 형상의 성능을 검증하기 위해 3차원 해석을 수행한 결과, 기준 모델대비 유량이 약 24 % 향상됨을 확인하였다. 이때 다중충실도 모델이 예측한 유량 값과 실제 검증 해석 값 사이의 오차율은 약 1.4 %로 낮게 나타나, 제안된 최적화 설계기법이 실제 설계 공간에서 높은 신뢰성을 가짐을 추가로 입증하였다.
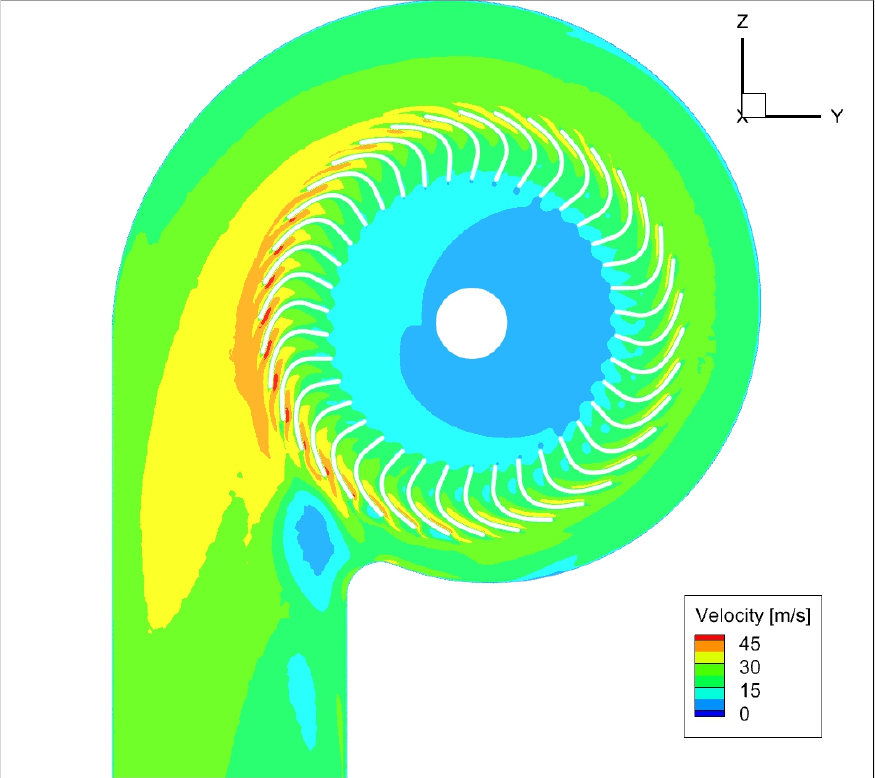
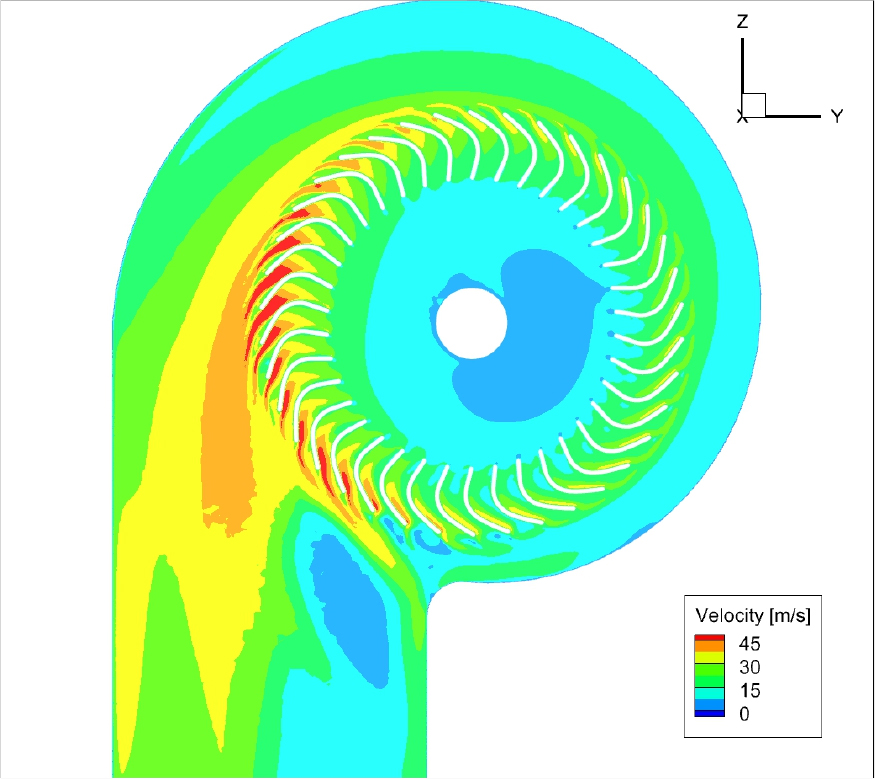
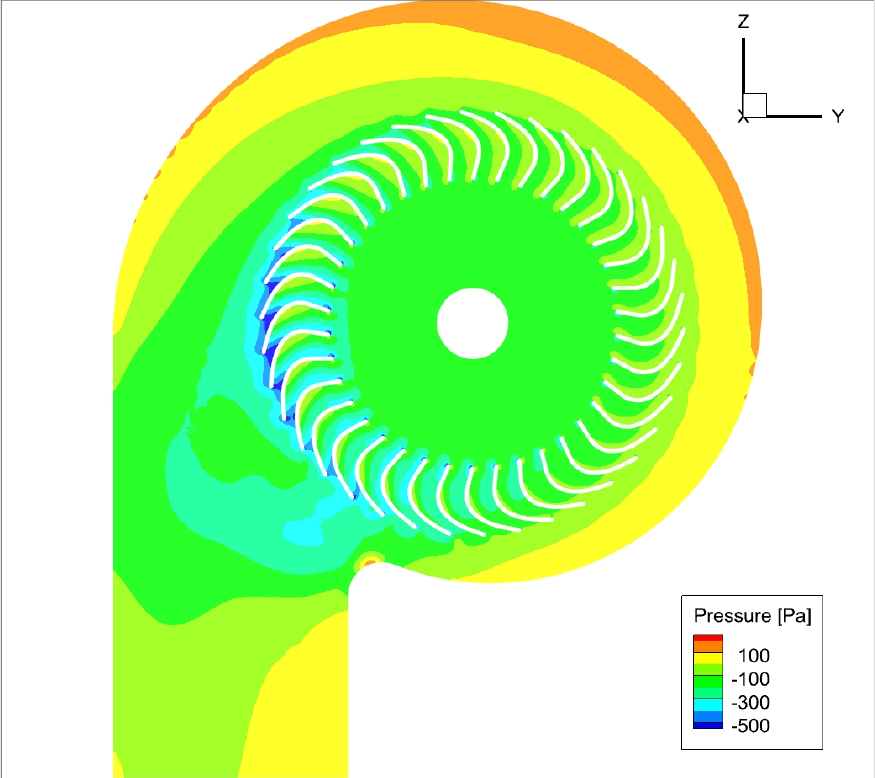
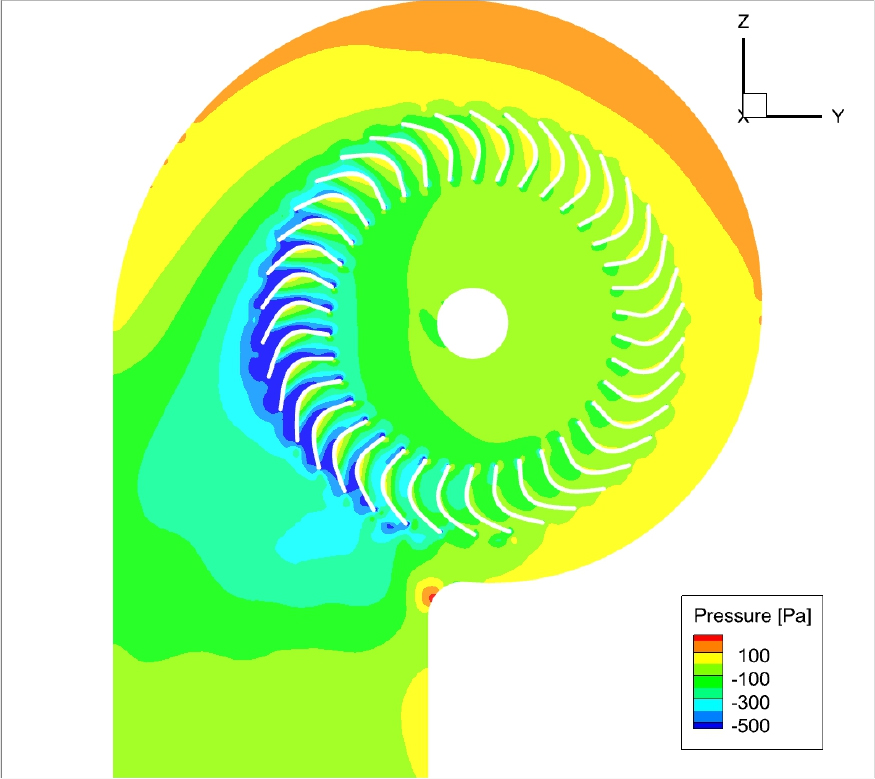
성능 향상의 원인을 유동장을 통하여 확인하기 위해, 기준 모델과 최적 모델의 내부 유동장을 비교 분석하였다. Figs. 10과 11은 각각 두 모델의 임펠러 및 스크롤 내부 속도장을 나타낸다. Fig. 11의 최적 모델은 컷오프 각도 확장(80°)과 임펠러 날개 각도 최적화를 통해, 블레이드를 통과하는 유동이 효과적으로 가속됨이 확인되었다. 그리고 Figs. 12와 13의 압력 분포를 통해, 최적 모델의 블레이드 표면 정압 상승 능력이 기준 모델 대비 우수함을 확인할 수 있었다.
또한 입·출구각 변경에 따른 유동 특성을 분석하기 위해, Fig. 14에 정의된 위치에서의 와도 분포와 유적선을 Figs. 15와 16에 각각 도시하였다.
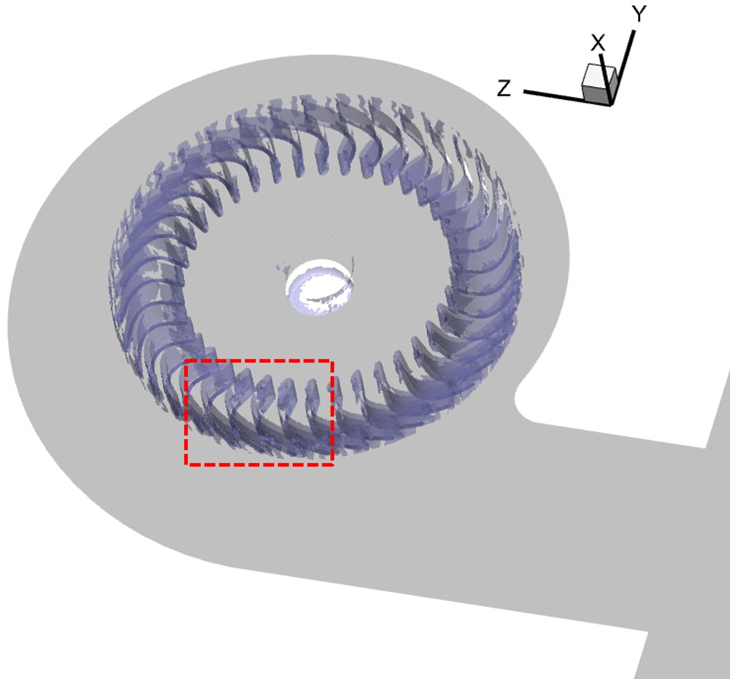
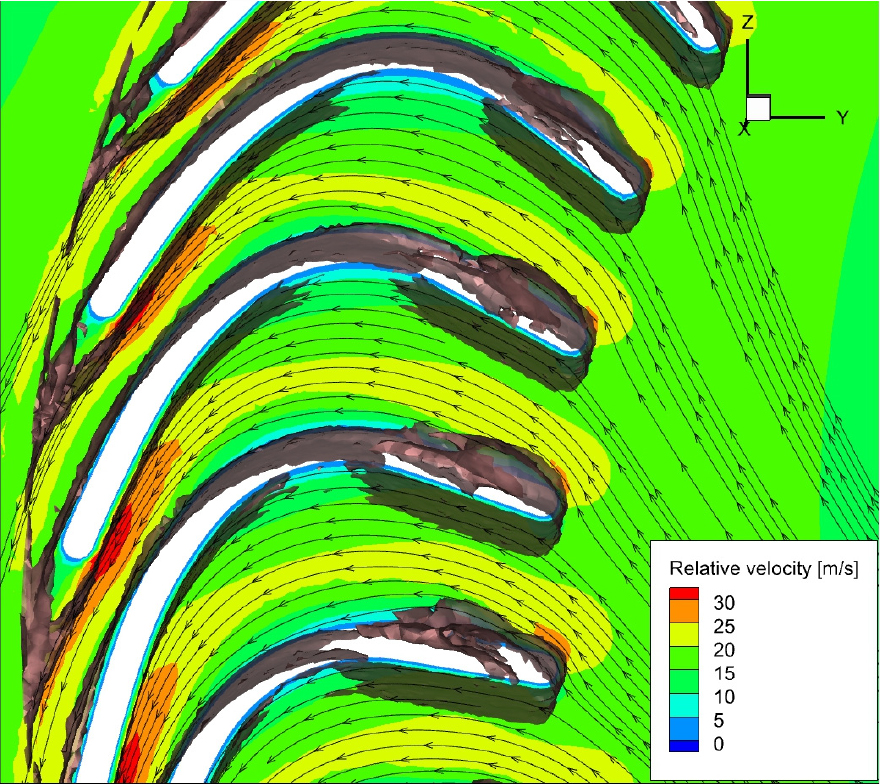
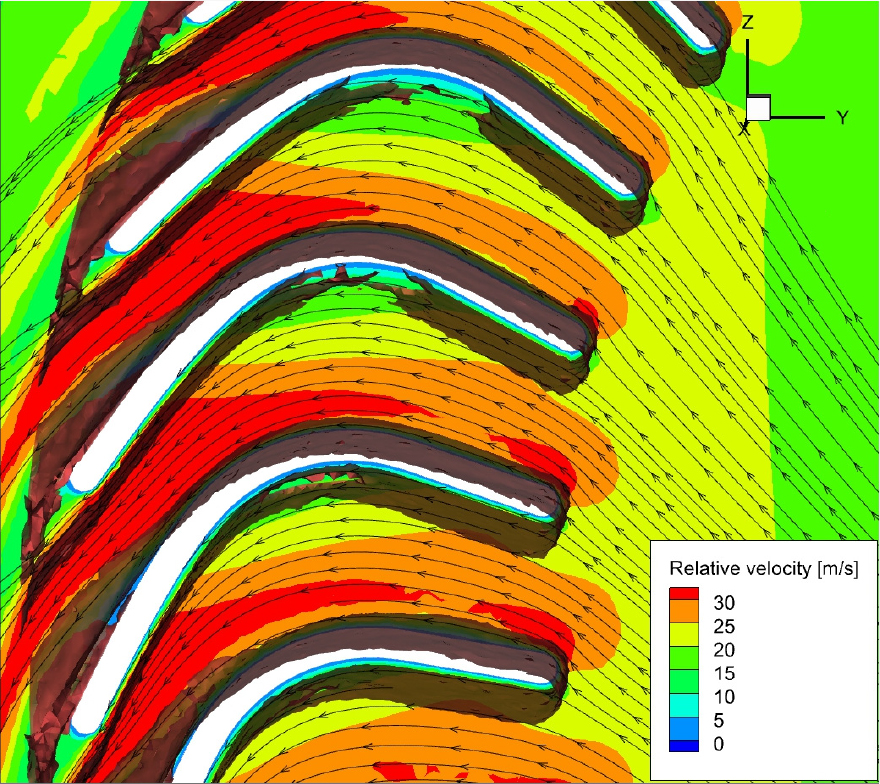
그림의 벡터 선은 유적선을 나타내며, 배경 색상은 상대속도의 크기를 나타낸다. Fig. 15에서는 블레이드 앞전 부근에서 강한 와도 구조가 관찰된다. 이로 인해 유선이 블레이드 표면을 따라 흐르지 못하고 심하게 왜곡되며, 상대 속도장에서 확인할 수 있듯이 유동 박리로 인해 유속이 급격히 저하되는 현상이 확인되었다. 반면, Fig. 16의 앞전에서는 이와 같은 불안정한 와도 구조가 관찰되지 않았다. 따라서 유동이 블레이드 표면에 밀착하여 흐르며, 입구부터 출구까지 유속이 지속적으로 증가하는 가속 흐름이 형성되는 것을 볼 수 있었다.
이러한 유동 개선 효과는 Fig. 17의 적색 면에서의 반경 방향 유속 분포에서도 명확히 드러난다. Figs. 18과 19에 도시된 바와 같이 최적 모델은 기준 모델 대비 전반적인 유속이 상승하였으며, 특히 검은색 점선으로 표시한 컷오프 영역에서의 유속 증가가 두드러진다.
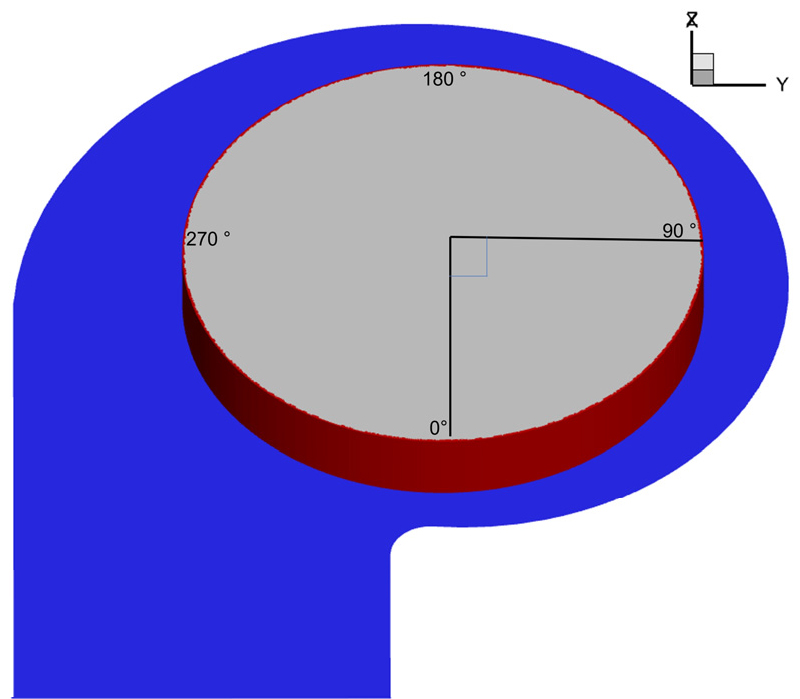
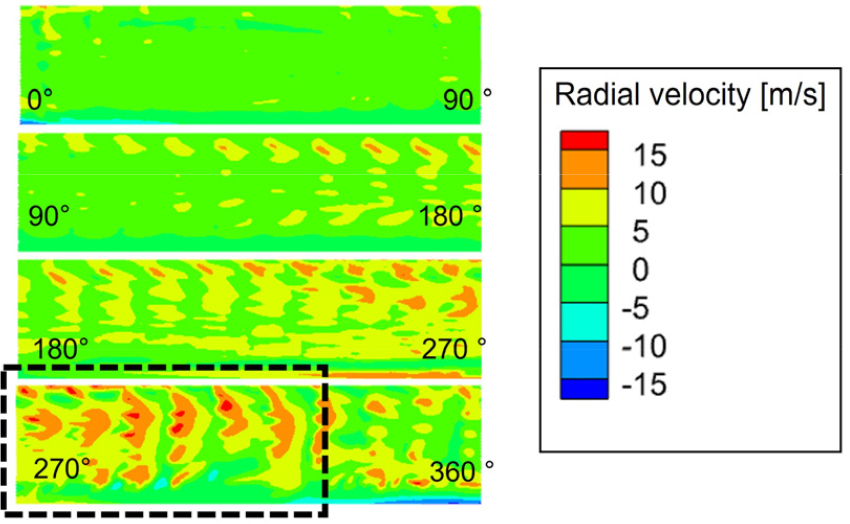
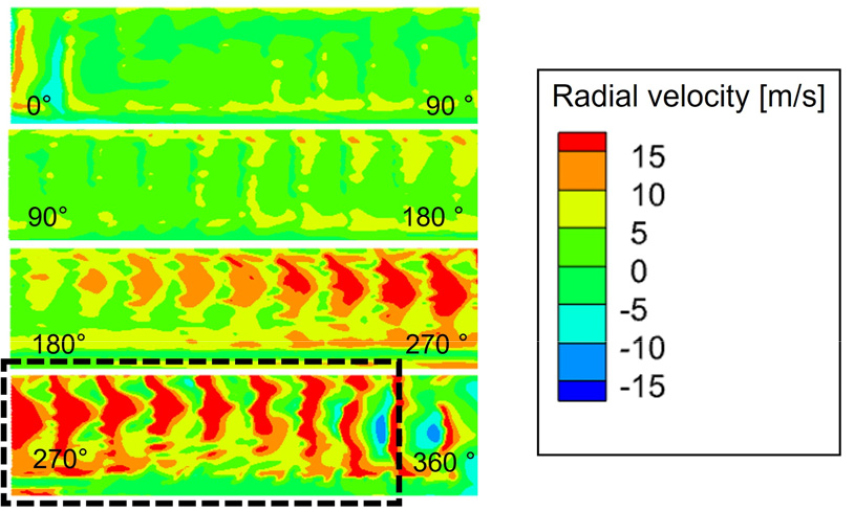
결과적으로, 최적화된 형상은 블레이드 내부의 유동 박리를 억제하고 유로 저항을 감소시켰다. 이로 인해 블레이드에서 가속된 유동이 스크롤 내부에서 감속 손실 없이 유지되어 출구 측 유속이 전반적으로 증가하였으며, 이러한 유동 개선이 앞서 확인한 24 %의 유량 성능 향상으로 직결된 것으로 분석된다.
4.3 연산 비용 절감 효율성 분석
본 연구에서는 제안된 모델의 효율성을 정량적으로 평가하기 위해, 데이터 구축에 소요되는 연산 비용을 분석하였다. 연산 비용 산정의 기준은 단일 케이스 해석에 소요되는 물리적 시간으로 정의하였다. 동일한 연산 자원(CPU 14 cores) 환경에서 2차원 RANS 해석(LF)은 케이스당 약 6 h이 소요된 반면, 3차원 RANS 해석(HF)은 약 360 h 소요되었다. 따라서 2차원 해석의 비용()을 1로 정규화하였을 때, 3차원 해석의 비용()은 약 60으로 산정된다.[1] 이를 바탕으로 전체 데이터 구축 비용()은 식 다음과 같이 정의할 수 있다.
여기서 와 는 각각 저충실도와 고충실도 데이터의 표본 개수를 의미한다. Table 5에 제시된 바와 같이, 기존 다중충실도 모델은 108개의 LF 데이터와 12개의 HF 데이터를 사용하여 총 비용은 108 × 1 + 12 × 60 = 828로 산출된다. 반면, 제안된 전이 학습 기반 모델(Proposed TL)은 54개의 LF 데이터와 8개의 HF 데이터만으로도 목표 정확도를 달성하였으며, 이때 총 비용은 54 × 1 + 8 × 60 = 534이다. 결과적으로 제안된 모델은 기존 모델 대비 약 35.5 %의 연산 비용 절감 효과를 보였으며, 다음과 도출되었다.
이러한 결과는 전이 학습 기법이 설계 공간 확장에 따른 데이터 구축 부담을 효과적으로 완화함을 시사한다.
V. 결 론
본 연구에서는 고비용의 3차원 전산유체역학 해석에 대한 의존도를 낮추고 다익 원심팬의 설계 효율성을 극대화하기 위하여, 전이 학습 기반의 다중충실도 심층신경망을 이용한 최적 설계 기법을 제안하고 그 유효성을 검증하였다.
우선, 설계 변수의 차원 증가에 따른 학습 부담을 완화하기 위해 전이 학습 전략을 도입하여 데이터 구축 및 학습 효율을 획기적으로 개선하였다. 해석 비용이 낮은 2차원 해석 데이터 54개를 활용하여 설계 변수에 따른 유량 경향성을 사전 학습하고, 이를 바탕으로 3차원 해석 데이터 8개만을 이용하여 정밀도를 보정하는 방식을 적용하였다. 그 결과, 전이 모델을 적용하지 않은 기존 다중충실도 모델 대비 전체 데이터 구축 비용(Computational Cost)을 약 35.5 % 절감하였으며, 동시에 모델의 수렴 속도와 학습 안정성을 효과적으로 확보할 수 있었다.
제안된 모델의 예측 성능을 검증한 결과, 2차원 데이터만을 이용한 저충실도 예측 모델은 3차원의 복잡한 유동 박리나 손실을 완벽히 모사하지 못하여 최대 22.44 %의 높은 예측 오차율을 보였다. 그러나 다중충실도 모델은 이러한 물리적 오차를 효과적으로 보정하여, 모든 검증 케이스에서 예측 오차율을 2.44 % ~ 3.82 % 수준으로 감소시켰다. 이는 2차원 모델 대비 최대 18.62 % p의 절대 오차율 개선을 의미하며, 적은 수의 고충실도 데이터만으로도 3차원 CFD 해석에 준하는 높은 예측 신뢰도를 확보했음을 입증한다.
이러한 고정밀 대리 모델을 기반으로 차분 진화 알고리즘을 연동하여 최적 설계를 수행한 결과, 기준 형상 대비 유량 향상률() 약 24 % 향상된 최적 형상(스크롤 컷오프 각도 80°, 임펠러 입구각 +0.2°, 출구각 –11°)을 도출하였다. 최적 형상에 대한 3차원 검증 해석 시 예측 오차는 약 1.4 %로 매우 낮게 나타나, 제안된 최적화 과정이 실제 설계 문제에 적용 가능함을 확인하였다.
결론적으로, 본 연구에서 제안한 다중충실도 최적화 기법은 제한된 연산 자원과 데이터 환경에서도 저비용 고효율의 공력 성능 최적화를 달성할 수 있는 실용적인 방법론임을 확인하였다. 본 연구의 결과는 향후 팬 시스템뿐만 아니라, 실험이나 고정밀 해석 비용이 막대한 다양한 유체 기계 및 기계 시스템의 최적 설계 분야에 폭넓게 응용될 수 있을 것으로 기대된다.
