

I.서 론
II. 잡음 파워 스펙트럼 추정 알고리즘
2.1 상관도 정보를 이용한 양이형 잡음 파워 스펙트럼 추정 알고리즘
2.2 잡음 상관도 모델링
III. 제안된 1차 재귀 평균을 이용한 잡음 상관도 추정 알고리즘
IV. 컴퓨터 시뮬레이션 및 결과
V. 결 론
I. 서 론
현대사회에서 휴대폰, 보청기와 같은 다양한 휴대용 음성 통신 장비들의 이용이 일반화됨에 따라 잡음이 존재하는 환경에서 신호의 품질을 높일 수 있는 음성 음질개선 알고리즘의 필요성 또한 증가되고 있다.
음질 개선 시스템에서 잡음의 파워 스펙트럼 밀도(Power Spectral Density, PSD) 추정 부분은 알고리즘의 성능을 결정하는 중요한 부분이기 때문에 정확도를 향상시키기 위해 많은 연구들이 진행되고 있다. 정확하지 않은 잡음 스펙트럼 추정 결과는 음성의 왜곡 또는 듣기에 불편한 잔여 잡음을 발생시키는 원인이 된다. 초기 음질 개선 알고리즘들은 단일 마이크를 이용한 알고리즘들로 입력 신호의 최소 파워는 잡음의 파워와 같다는 가정을 이용해 잡음의 파워를 추정하거나[1,2] 음성의 존재유무에 따라 잡음의 파워를 갱신하여 입력 신호의 신호대 잡음비(Signal to Noise Ratio, SNR)를 높이는 알고리즘들이 주를 이루었다.[3,4]
최근에는 두 개 이상의 마이크를 이용하는 다채널 알고리즘들이 연구되고 있으며 특히 왼쪽과 오른쪽에 마이크를 하나씩 이용하는 양이형 음질 개선 알고리즘들이 많이 제안되고 있다. 제한된 정보만을 이용해 잡음을 추정해야하는 단 채널 방식과는 달리 양이형 시스템에서는 공간 정보와 같은 추가적인 정보를 활용 할 수 있게 됨으로써 향상된 잡음 제거 성능을 기대할 수 있게 됐다.[5]
확산음장에서의 잡음 파워 스펙트럼 추정의 정확도를 향상시키기 위해 다양한 알고리즘들이 제안 되었다. 일반적으로 실생활에서 많이 접할 수 있는 확산 음장 잡음은 특정한 방향성이 없이 전 방향에서 양쪽 마이크에 동일한 크기, 임의의 위상을 가지고 집음 되는 잡음 신호를 뜻한다. 대표적으로는 카페테리아에서 집음 된 버블 잡음, 엔진 소음, 바람 소리 그리고 잔향 등이 있다.[6]
양이 환경에서 잡음의 공간 상관도 정보를 이용하여 잡음의 파워 스펙트럼을 추정하거나 음질 개선 이득을 형성하는 기술들이 최근 소개되었다.[7-11] 위너 필터 기반의 음질 개선 알고리즘에서는 잡음 제거 이득을 구하기 위해 양이 마이크의 상호 파워 스펙트럼 정보를 이용한다. 이때 정확한 상호 파워 스펙트럼 추정을 위해 잡음의 상관도 정보를 이용하는 기술이 제안되었고[7,8] 이를 통해 더 높은 잡음 제거율과 낮은 음성 왜곡률을 달성 할 수 있음을 보였다.[8]
또한 잡음 파워 스펙트럼 추정 단계에서 상관도 정보를 활용한 기술도 발표되었다.[9-11] 이러한 알고리즘들은 양 마이크 간의 잡음이 서로 낮은 상관도를 가진다는 기존의 알고리즘들과 다르게 잡음 상관도 모델을 이용해 저주파대역에서 분명히 존재하는 높은 상관도 값을 고려해주었다. 결과적으로 추정된 잡음 파워 스펙트럼이 저주파 대역에서 실제 값보다 더 작게 추정되는 문제를 보상 할 수 있었다.[9-11]
기존의 알고리즘들은 실제 환경에서 잡음 상관도를 정확히 알 수 없으므로 수학적으로 모델링된 잡음 상관도를 활용하였다.[7,8,12,13] 이때 상관도는 마이크간의 거리, 머리에 의한 음영 효과(head shadowing effect) 등을 고려한 실수 값의 형태로 모델링 되었다.
그러나 실제 환경에서 잡음의 상관도는 잡음의 특성, 음원의 이동 그리고 음향 환경 등에 영향을 받으며, 그 특성 또한 시간에 따라 변화한다.[13] 따라서 기존의 잡음 상관도 모델을 사용할 경우 음질향상 알고리즘의 성능이 저하 될 수 있다.
본 논문에서는 실제 환경에서 변화하는 잡음의 상관도를 추적하여 고정된 모델 보다 정확한 상관도를 구하고 이를 이용해 잡음 파워 스펙트럼 추정 알고리즘의 정확도를 높일 수 있는 방법을 제안한다. 잡음의 상관도는 음성이 존재하지 않는 구간에서 1차 재귀 평균을 이용해 업데이트되며 추정된 상관도 모델을 이용하여 정교한 잡음 파워 스펙트럼을 추정 할 수 있다.
본 논문은 II장에서 잡음 상관도를 이용한 잡음 파워 스펙트럼 추정 알고리즘과 기존에 사용되었던 잡음 상관도의 수학적 모델에 대해 소개한다. 이어서 III장에서 본 논문에서 제안하는 잡음 상관도 온라인 추정 알고리즘을 소개하고 IV장에서 실험을 통해 제안 알고리즘의 성능을 평가한다. 마지막으로 V장에서 결론을 맺는다.
II. 잡음 파워 스펙트럼 추정 알고리즘
2.1 상관도 정보를 이용한 양이형 잡음 파워 스펙트럼 추정 알고리즘
양이 시스템에서 각 마이크로 들어오는 잡음이 섞인 음성 신호는 주파수 도메인에서 다음과 같이 표현 할 수 있다.
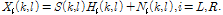 (1)
(1)
위의 수식에서 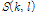 는 음성 신호,
는 음성 신호, 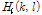 는 음성의 위치부터
는 음성의 위치부터 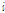 -마이크까지의 전달함수를 나타내며
-마이크까지의 전달함수를 나타내며 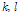 은 각각 주파수와 시간 인덱스이다.
은 각각 주파수와 시간 인덱스이다. 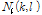 은
은 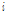 -마이크에 집음 된 잡음 신호이다.
-마이크에 집음 된 잡음 신호이다.
Eq.(1)과 같이 표현되는 신호 환경에서 채널 신호 간 예측 기법을 사용하여 잡음의 파워 스펙트럼을 추정하는 알고리즘이 제안되었다.[9] 이 알고리즘은 음성과 잡음이 동시에 존재하는 환경에서도 잡음의 파워 스펙트럼을 수식적으로 계산해 낼 수 있다는 장점이 있지만 목표 음성 신호가 정면이 아닌 다른 방향에 존재 할 때에 채널 예측 알고리즘의 인과성을 성립시키기 위해 임의의 딜레이를 고려해 주어야 한다는 단점이 있다. 이러한 임의의 딜레이가 정확히 맞지 않을 경우 위너 채널 예측 알고리즘의 성능을 저하시키는 원인이 된다.
또 다른 양이형 알고리즘으로 2-채널 신호의 공분산 행렬의 고유치를 이용하여 잡음의 파워 스펙트럼을 추정하는 기술이 제안되었다.[11] 이 기술의 경우 인과성을 만족시키기 위한 임의의 딜레이를 고려하지 않아도 목표 음성의 방향에 관계없이 잡음의 파워 스펙트럼을 추정 할 수 있다는 장점이 있으므로 본 논문에서는 고유치 기반의 알고리즘을 이용하여 잡음의 파워 스펙트럼을 추정하고자 한다. 기존 논문에[11] 제안된 알고리즘을 간단히 정리하면 다음과 같다.
잡음과 음성이 서로 낮은 상관도를 가지고 양쪽 마이크로 들어오는 잡음의 파워가 동일하다고 가정 할 때[4] 즉 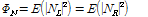 , 2-채널 신호의 공분산 행렬은 다음과 같이 쓸 수 있다.
, 2-채널 신호의 공분산 행렬은 다음과 같이 쓸 수 있다.
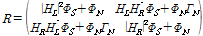 . (2)
. (2)
수식의 간결성을 위해 주파수와 시간 인덱스 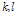 은 생략하였다. 위 수식에서
은 생략하였다. 위 수식에서 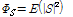 는 음성신호의 자기 파워 스펙트럼 밀도를 나타낸다. 한편 잡음의 상호 파워 스펙트럼은 자기 파워 스펙트럼과 상관도 정보
는 음성신호의 자기 파워 스펙트럼 밀도를 나타낸다. 한편 잡음의 상호 파워 스펙트럼은 자기 파워 스펙트럼과 상관도 정보 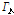 를 이용해
를 이용해 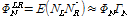 로 쓸 수 있다. 따라서 위의 공분산행렬 Eq.(2)에서 고유치를 계산한 수식은 다음과 같다.
로 쓸 수 있다. 따라서 위의 공분산행렬 Eq.(2)에서 고유치를 계산한 수식은 다음과 같다.
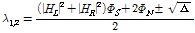 . (3)
. (3)
일반적으로 저주파대역에서의 ILD(Interaural Level Difference)는 무시할 수 있을 만큼 작은 값을 가지며[12] 음향 경로간의 위상차를 무시할 수 있다고 한다면 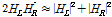 로 쓸 수 있으므로 Eq.(3)의 루트안의 수식은 다음과 같이 근사화 할 수 있다.[9]
로 쓸 수 있으므로 Eq.(3)의 루트안의 수식은 다음과 같이 근사화 할 수 있다.[9]
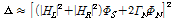 . (4)
. (4)
근사화 된 Eq.(4)를 Eq.(3)에 대입하고 식을 재정렬하면 입력신호의 잡음 파워 스펙트럼은 아래와 같이 계산된다.
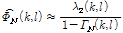 . (5)
. (5)
하지만 위의 잡음 파워 스펙트럼 추정기 Eq.(5)는 Eq.(4)의 근사화 조건이 만족하지 않는 고주파대역에서 가정의 불일치로 오차가 생길 수 있다. 그렇지만 Eq.(4)에서 근사화를 위해 무시한 부분은 완전 제곱 부분에 비하여 작은 값을 가지며 특히 고주파대역으로 갈수록 낮은 값을 가지는 상관도의 영향으로 전체적인 값에 큰 영향을 미치지 않음을 알 수 있다.[9]
2.2 잡음 상관도 모델링
기존의 많은 논문들에서 확산음장 환경에서 잡음의 상관도는 수학적으로 모델링 될 수 있음을 보였다. 가장 일반적으로 사용되는 모델링 수식은 아래와 같다.[6]
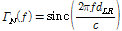 . (6)
. (6)
이때 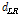 은 두 마이크간의 거리,
은 두 마이크간의 거리, 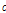 는 소리의 속도를 나타낸다. 그렇지만 위의 모델은 자유 음장(free-field) 환경에서 두 채널의 전방향 마이크로폰에 대한 상관도를 모델링한 수식이므로 양이 시스템에서 발생하는 머리에 의한 음영 효과 즉, 회절이나 반사 등은 고려하지 않았다. 이후 이러한 머리의 영향을 고려하여 잡음의 상관도를 모델링한 알고리즘들이 제안되었다.[7,12]
는 소리의 속도를 나타낸다. 그렇지만 위의 모델은 자유 음장(free-field) 환경에서 두 채널의 전방향 마이크로폰에 대한 상관도를 모델링한 수식이므로 양이 시스템에서 발생하는 머리에 의한 음영 효과 즉, 회절이나 반사 등은 고려하지 않았다. 이후 이러한 머리의 영향을 고려하여 잡음의 상관도를 모델링한 알고리즘들이 제안되었다.[7,12]
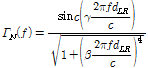 . (7)
. (7)
위의 수식에서 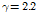 ,
, 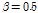 로 실험적으로 결정된 값이다. 최근에는 사람의 3차원적인 머리 모양을 고려하여 설계된 수학적 모델을 곡선 적합(curve-fitting)을 이용해 구해낸 잡음 상관도 모델이 제안되었다.[13]
로 실험적으로 결정된 값이다. 최근에는 사람의 3차원적인 머리 모양을 고려하여 설계된 수학적 모델을 곡선 적합(curve-fitting)을 이용해 구해낸 잡음 상관도 모델이 제안되었다.[13]
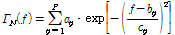 . (8)
. (8)
위의 수식에서 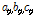 는 각각
는 각각 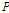 차 오더에 해당하는 모델링 수식의 계수 값으로 매틀랩의 곡선 접합을 통해 구해진 자세한 파라미터는 Reference [13]에 소개되어 있다.
차 오더에 해당하는 모델링 수식의 계수 값으로 매틀랩의 곡선 접합을 통해 구해진 자세한 파라미터는 Reference [13]에 소개되어 있다.
III. 제안된 1차 재귀 평균을 이용한 잡음 상관도 추정 알고리즘
앞장에서 잡음의 상관도를 이용하여 저주파대역에서도 실제 값보다 낮게 측정되는 값없이 안정적인 성능을 보장하는 잡음 파워 스펙트럼 추정 알고리즘과 잡음 상관도 모델을 소개하였다.
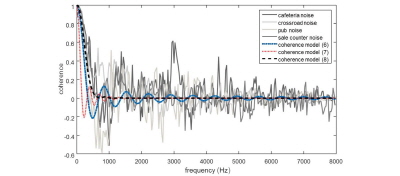
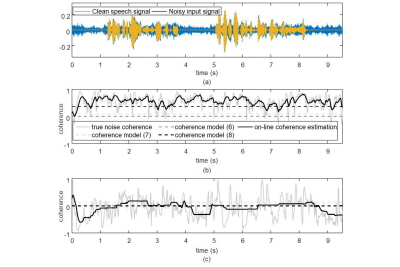
실제 환경에서 잡음의 상관도는 시간에 따라 그리고 잡음의 특성에 따라 변화한다.[11,13] 특히 빠르게 변화하는 입력 신호의 특성을 추정하기 위해 사용하는 짧은 시간 평균 매개변수로 인해 잡음 상관도의 변화량이 커지게 된다. Fig. 1은 실제 양이형 시스템에서 녹음 된 서로 다른 잡음 신호들의 상관도를 나타내고 있다. 실험을 위해 ETSI(European Telecommunications Standards Institute)에서 제공하는 두 채널로 녹음 된 잡음 데이터베이스 중 카페테리아 , 도로, 술집 그리고 마트의 카운터에서 녹음 된 잡음이 이용되었다. 두 채널로 녹음 된 잡음 신호의 상관도는 아래 수식을 이용해 측정되었다.
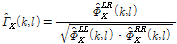 (9)
(9)
각각의 PSD는 1차 재귀평균을 이용해 구해졌으며 스무딩 파라미터는 0.75로 설정하였다. 측정된 실제 잡음의 상관도를 Eqs.(6)과 (7) 그리고 Eq.(8)의 분석 모델과 비교하였다. 그림에서 보이는 것처럼 기존의 잡음 상관도 모델과는 달리 실제 공간 상관도는 큰 변화량을 가지는 것을 볼 수 있다. 특히 큰 값을 갖는 500 Hz 이하의 대역에서도 실제 잡음 상관도와 수학적 모델들의 값에 차이가 있으며 잡음의 특성에 따라서도 그 차이가 존재한다.
정교하지 못한 잡음 상관도 모델에 의한 오차는 잡음 파워 스펙트럼 추정의 정확도를 떨어뜨려 최종 출력 신호에서 잔여잡음과 음성의 왜곡을 발생시킨다. 따라서 본 논문에서는 음질개선의 성능 향상을 위해 음향 환경의 변화에 따라 온라인으로 잡음의 상관도를 업데이트하는 기술을 제안한다. 이를 위해 잡음의 상관도를 음성이 존재하지 않는 구간, 즉 잡음만 존재하는 구간에서 1차 재귀 평균을 이용하여 다음과 같이 추정한다.
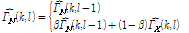
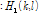
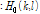 (10)
(10)
이때 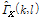 은 두 마이크로 들어온 입력 신호간의 상관도로 Eq.(9)를 이용해 측정된다. 잡음의 상관도는 음성이 존재하는 구간에서는 그 전 프레임 값을 사용하며, 음성이 존재하지 않는 구간, 즉 잡음만 존재하는 대역에서만 업데이트 된다. 음성의 존재 구간을 판단하기 위해 많은 기술들이 연구되었으며 그 중 에너지 기반의 알고리즘들은 대표적으로 널리 이용되고 있는 기술이다.[4,15] 본 논문에서는 에너지 비율을 계산하기 위해 공분산 행렬의 최대 최소 고유치의 비율을 이용하였으며 이를 기반으로 음성의 존재 구간을 판별하였다. 이는 양쪽 채널의 잡음의 상관도가 낮다는 가정아래 Eq.(3)을 이용하여 최대 최소 고유치의 총합의 비율을 계산하면 대략 a priori SNR의 근사값으로 정리되는 성질을 이용한 것이다.[11]
은 두 마이크로 들어온 입력 신호간의 상관도로 Eq.(9)를 이용해 측정된다. 잡음의 상관도는 음성이 존재하는 구간에서는 그 전 프레임 값을 사용하며, 음성이 존재하지 않는 구간, 즉 잡음만 존재하는 대역에서만 업데이트 된다. 음성의 존재 구간을 판단하기 위해 많은 기술들이 연구되었으며 그 중 에너지 기반의 알고리즘들은 대표적으로 널리 이용되고 있는 기술이다.[4,15] 본 논문에서는 에너지 비율을 계산하기 위해 공분산 행렬의 최대 최소 고유치의 비율을 이용하였으며 이를 기반으로 음성의 존재 구간을 판별하였다. 이는 양쪽 채널의 잡음의 상관도가 낮다는 가정아래 Eq.(3)을 이용하여 최대 최소 고유치의 총합의 비율을 계산하면 대략 a priori SNR의 근사값으로 정리되는 성질을 이용한 것이다.[11]
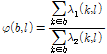 (11)
(11)
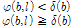
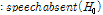
 (12)
(12)
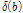 는
는 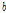 번째 밴드에서 음성의 존재 유무를 판단하는 역치 값으로 음성의 주파수 대역 특성을 고려하여 실험적으로 결정되었다.[4]
번째 밴드에서 음성의 존재 유무를 판단하는 역치 값으로 음성의 주파수 대역 특성을 고려하여 실험적으로 결정되었다.[4]
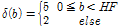 . (13)
. (13)
위의 수식에서 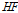 는 고주파대역이 시작되는 주파수 빈 인덱스이며 본 논문에서는 5 kHz를 그 기준으로 두었다. 고유치간의 비율을 이용해 음성 존재 구간을 판단하는 알고리즘은 앞 절에서 소개한 잡음 파워 스펙트럼 추정 알고리즘과 하나의 고유치 도메인에서 결합될 수 있어 추가적인 파라미터가 필요 없다는 장점이 있다.
는 고주파대역이 시작되는 주파수 빈 인덱스이며 본 논문에서는 5 kHz를 그 기준으로 두었다. 고유치간의 비율을 이용해 음성 존재 구간을 판단하는 알고리즘은 앞 절에서 소개한 잡음 파워 스펙트럼 추정 알고리즘과 하나의 고유치 도메인에서 결합될 수 있어 추가적인 파라미터가 필요 없다는 장점이 있다.
결과적으로 해당 주파수 대역이 역치 값 이하로 떨어지면 잡음만 존재하는 것으로 판단하여 상관도를 업데이트 할 수 있다.
IV. 컴퓨터 시뮬레이션 및 결과
본 논문에서 제안하는 잡음 상관도 추정 알고리즘의 성능을 평가하기 위해 컴퓨터 시뮬레이션이 진행되었다. 실험을 위해 HRIR(Head-Related Impluse Response)[16]를 이용해 렌더링 된 TIMIT 데이터베이스의 10개의 여성 음성과 ETSI 데이터베이스의 5개의 잡음 신호를 이용하였다. 사용된 HRIR은 Messachusetts Institute of Technology(MIT)에서 제공하는 데이터베이스로 Knowles Electronic Manikin for Acoustic Research (KEMAR) 더미 헤드로부터 얻어진 값이다.
샘플링 주파수는 16 kHz로 설정하고 한 프레임 사이즈는 32 ms, 50 % overlap-add 방식을 이용하였으며 sine 윈도우가 적용되었다.
입력 신호의 파워 스펙트럼은 1차 재귀 평균을 이용하여 추정되었다. 이때 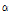 는 시간 축 평균 매개 변수로 빠르게 변화하는 잡음의 특성을 추정하기 위해 작은 값
는 시간 축 평균 매개 변수로 빠르게 변화하는 잡음의 특성을 추정하기 위해 작은 값 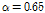 을 사용하였다.
을 사용하였다.
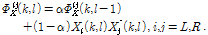 (14)
(14)
제안된 알고리즘은 기존에 고정된 값을 가지는 상관도 모델 Eqs.(6)에서 (8)을 이용한 경우와 비교되었으며 실제 잡음 신호의 상관도를 계산하기 위해 다음과 같은 수식이 이용되었다.
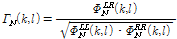 . (15)
. (15)
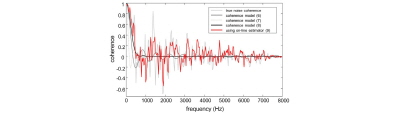
먼저 제안 알고리즘의 잡음 상관도 추적 성능을 측정하였다. 아래 Figs. 2와 3은 청자의 정면 0 °에 위치하는 목표 음성 신호가 ETSI 데이터베이스의 카페테리아 잡음과 0 dB SNR로 섞인 입력 신호의 잡음 상관도 추적 결과를 나타내고 있다. Fig. 2(b)는 150 Hz 대역으로 음성이 거의 존재하지 않는 대역이며 Fig. 2(c)는 1 kHz 대역에서의 잡음 상관도로 음성이 분명히 존재하는 주파수 대역이다. 그림을 보면 음성 부재 구간에서 제안하는 알고리즘이 변화하는 잡음의 상관도를 고정된 값을 가지는 모델링 식보다 더 근사한 값으로 추정해 가고 있음을 확인 할 수 있다. 한 프레임에서의 잡음 상관도를 비교해본 결과는 Fig. 3을 통해 확인 할 수 있다. 그림을 통해 모델링 된 값보다 온라인으로 잡음을 추정하는 제안 알고리즘이 실제 정답 상관도를 더 가깝게 추정함을 알 수 있다. 이를 통해 공간 상관도 정보를 이용해 잡음의 파워 스펙트럼을 추정하는 알고리즘에서의 정확도 향상을 기대할 수 있다.
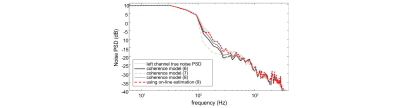
Fig. 4는 동일 입력 신호에 대하여 다양한 잡음 상관도 값을 사용했을 때의 잡음 파워 스펙트럼 추정 결과를 로그 도메인에서 보이고 있다. 상대적인 성능 평가를 위해 동일한 잡음 파워 스펙트럼 추정 알고리즘 Eq.(5)에 모델링된 상관도인 Eqs.(6) ~ (8)과 제안된 기술인 Eq.(10)을 대입하여 음성이 존재하는 구간에서 그 파워 스펙트럼 추정 결과를 구했다. 높은 상관도 값을 가지는 저주파대역에서의 차이를 살피기 위해 Fig. 4는 0 ~ 4 kHz 대역의 실험 결과를 보이고 있다. 모델링된 잡음 상관도를 사용한 경우보다 제안된 잡음 상관도를 이용한 경우 실제 잡음의 파워 스펙트럼을 더 잘 추정하는 것을 확인 할 수 있다.
|
Fig. 3. Noise coherence tracking performance with frequency axis. |
|
Fig. 4. Noise PSD estimation results at 0~4 kHz. |
|
Fig. 5. Objective parameters with a speech source at 0° azimuth angle : (a) LogErr, (b) segmental SNR, (c) Composite parameters and (d) PESQ. |
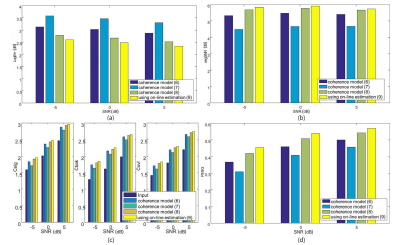
마지막으로 제안하는 알고리즘의 객관적인 성능 평가를 위해 다음과 같은 파라미터들이 측정되었다. 먼저 제안된 알고리즘이 잡음 파워 스펙트럼 추정 알고리즘의 성능에 미치는 영향을 확인하기 위해 0 ~ 4 kHz 대역에서의 실제 잡음과 추정 된 잡음 스펙트럼간의 로그 에러(Logarithm Error : LogErr)가 측정되었다. 실험 결과 온라인 추정된 잡음 상관도를 사용하는 경우가 모델링된 잡음 상관도를 사용하는 경우보다 잡음의 파워 스펙트럼을 더 정확하게 추정해 감을 확인 할 수 있었다.
더 나아가 최종 출력 신호의 품질을 측정하기 위해 segmental SNR, composite parameters 그리고 PESQ (Perceptual Evolution of Speech Quality)가 측정되었다.[17] composite parameters는 신호의 왜곡정도(Csig), 배경 잡음의 왜곡정도(Cbak), 그리고 오디오 신호의 전체적인 품질(Covl)을 평가하는 파라미터로 0 ~ 5 사이의 값을 가지며 5에 가까울수록 신호의 품질이 깨끗한 원음에 더 가까운 신호임을 뜻한다. 이때 composite parameters와 PESQ는 8 kHz로 다운 샘플링 후 측정 되었다. segmental SNR과 PESQ의 경우 입력과 출력 신호 각각의 측정치의 차이 값을 구해 입력 신호 대비 출력 신호의 품질 향상을 쉽게 확인하고자 하였다. 이때 Fig. 5는 목표 음성 신호가 청자의 정면 0 °에 위치하는 경우이고 Fig. 6은 청자의 오른쪽 90 ° 방향에 위치하는 경우이다. 실험 결과 전체적인 객관적 성능 평가 파라미터에서 제안된 기술이 목표 음성의 방향에 관계없이 잡음의 파워 스펙트럼을 더 정확히 추정하며 따라서 최종 출력 신호에서 더 높은 품질을 가짐을 확인 할 수 있다.
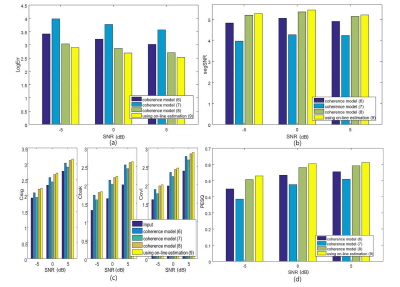
V. 결 론
본 논문에서는 양이형 음질개선 알고리즘을 위한 잡음 상관도 온라인 추정 방법을 제안하였다. 제안 알고리즘은 음향 환경에 따라 변화하는 잡음 상관도를 음성 부재 구간에서 업데이트함으로써 변화하는 상관도 값을 온라인으로 추정하고자 하였다. 이를 통해 고정된 값을 가지는 상관도 모델을 사용할 때보다 잡음 파워 스펙트럼 추정 알고리즘의 정확도를 높일 수 있었다. 제안된 온라인 추정 기술은 기존에 제안된 다른 양이형 음질 개선 알고리즘에도 결합 될 수 있다. 컴퓨터 실험 결과 최종 출력 신호에서 제안 기술을 사용한 경우 기존의 기술보다 더 나은 성능을 보이는 것을 확인 할 수 있었다.
