
I. Introduction
II. Proposed Audio Fingerprinting Method
2.1 Fingerprint Extraction Based on Segmentation
2.2 Local Invariant Fingerprint Matching
III. Experimental Results
IV. Conclusion
I. Introduction
Fingerprints are perceptual features or short sum-maries of a multimedia content. Similar to a human fingerprint which has been used for identifying an individual, a multimedia fingerprint is used for rec-ognizing a multimedia clip. A fingerprinting system must make allowances for some modification of content while distinguishing one content clip from another [1-4]. Promising applications of multimedia fingerprinting are filtering for file-sharing services, automated monitoring for broadcasting stations, audio recognition through mobile network, and auto-mated indexing of large-scale multimedia archives.
This paper proposes an audio fingerprinting method that is robust to linear speed changes. The robustness against speed changes is essential since speed changes are a common phenomenon in many contexts where audio fingerprinting is of importance, for example in radio broadcast, and easy to impose with modern computers [5]. However, few results have been re-ported that explicitly consider this problem in the context of audio recognition. In [5], the shift invariance of autocorrelation function is utilized to extract speed- change resilient fingerprints from audio spectrum. This, however, can not provide explicit temporal synchronization, which makes the method only robust against speech changes up to 6 %.
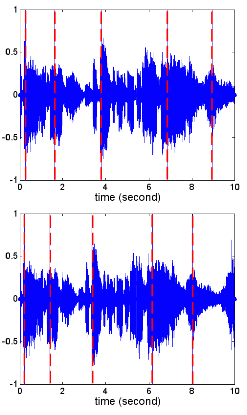
Fig. 1 shows a 10-second clip of the original and speed-changed (10 % speed-up) audio. Although the start positions of the two audio clips are the same, there is a significant temporal mismatch, which renders the conventional fingerprint matching methods, based on fixed-length segments, fail to identify the two clips as the same. This motivates us to combine segmentation with fingerprinting. Temporal synchro-nization can be achieved from the segmentation boundaries. Moreover, by extracting a fingerprint from a segment, the number of fingerprints reduces, which is conducive for fingerprint storage and search. However, the segmentation boundaries extracted from the original and the severely distorted audio may be different. To mitigate the limited repeatability, we propose a local invariant matching method in which only small numbers of correct boundaries are needed for claiming successful matching.
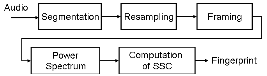
II. Proposed Audio Fingerprinting Method
2.1 Fingerprint Extraction Based on Segmentation
Any suitable segmentation and fingerprint extraction method can be utilized for the proposed finger-printing method. In this paper we use the seg-mentation algorithm [6] based on the spectral dif-ference, which has shown superior performance in a comparative test [6] and does not require any prior training, and the audio fingerprinting method based on the normalized spectral subband centroid (NSSC), which was originally proposed for speech recognition and has shown superior performance for audio fin-gerprinting [2].
An overview of the proposed fingerprinting method is shown in Fig. 2. First, an input audio is converted to mono and downsampled to 11025 Hz. The down-sampled signal is windowed by the Hanning window of length 2048 with 75 % overlap, and each windowedframe is transformed into the Fourier domain. Let S [n,k] be the short-time Fourier transform (STFT) of an audio signal at frequency bin k of the n-th frame. The magnitude and the phase of S [n,k] are respect-ively denoted by R [n,k] and ![]() [n,k]. The spectral difference in complex domain [6] is given as the difference between the current STFT and the estimated (or predicted) STFT as shown below:
[n,k]. The spectral difference in complex domain [6] is given as the difference between the current STFT and the estimated (or predicted) STFT as shown below:
|
Fig. 2. Overview of proposed fingerprint extraction method. |
![]() (1)
(1)
where ||x|| denotes the magnitude of complex number x, and ![]() [n,k] is principal argument of (2
[n,k] is principal argument of (2![]() [n-1,k]-
[n-1,k]-![]() [n-2,k]). Summing the above measures across all k, we can construct a frame-by-frame novelty function
[n-2,k]). Summing the above measures across all k, we can construct a frame-by-frame novelty function ![]() as
as
![]() (2)
(2)
A peak-picking algorithm is applied to the novelty function to locate the segmentation boundaries. Prior to applying the peak-picking algorithm, the novelty function ![]() is lowpass-filtered (typically, Gaussian filter with zero mean and standard deviation 5.0). The lowpass filtering makes the resulting segmen-tation boundaries more reliable and robust against various audio processing steps. As in [6], we use the median-based peak-picking algorithm. The resulting segmentation boundaries do not change significantly after various processing steps including speed changes.
is lowpass-filtered (typically, Gaussian filter with zero mean and standard deviation 5.0). The lowpass filtering makes the resulting segmen-tation boundaries more reliable and robust against various audio processing steps. As in [6], we use the median-based peak-picking algorithm. The resulting segmentation boundaries do not change significantly after various processing steps including speed changes.
The length of each audio segment is normalized into a certain length (typically 8192) by resampling. We divide the resampled audio into two non- overlapping frames. The spectrum of each frame is divided into M critical bands [7] (typically M=16 from 300 Hz to 5300 Hz, which is known to be relevant to human perception and robust [2]), and at each critical band, the NSSC is calculated. Let P [n, k] be the short-time power spectrum of an audio signal at frequency bin k of the n-th frame. The centroid of the n-th subband audio spectrum is defined as
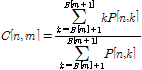 (3)
(3)
where B [m] denotes the frequency boundary of the m-th critical band. Through the above normalization, the subband centroids are resilient against the equali-zation of the audio spectrum [8]. By normalizing the the range of C [n, m], NSSC of the m-th critical band is given by [8]
![]() (4)
(4)
Then NSSC has a range between -0.5 and 0.5 regardless of the critical bands.
As we divide a segment into two frames, we obtain 2M NSSCs from a segment. The NSSCs of each segment, denoted by x, are further normalized by its mean and standard deviation (denoted by mx and σx respectively) as follows:
![]() (5)
(5)
where n=1,2, ... , 2M. Finally the p [n] is used as the fingerprint of a segment.
2.2 Local Invariant Fingerprint Matching
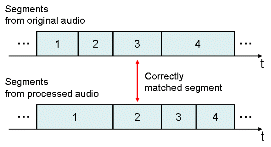
Conventionally the fingerprint matching is per-formed on a fingerprint block (fingerprints from N consecutive audio segments) [1-4] since a fingerprint from one segment does not contain enough infor-mation to identify an audio. However, the segmen-tation boundaries obtained from a distorted audio may be different from those from the original audio. If one segmentation boundary is missing or added, the segments after the segmentation boundary are out of synchronization as shown in Fig. 3. Thus we propose a novel local fingerprint matching method.
|
Fig. 3. An example of extracted segmentation boundaries from the original (top) and the processed (bottom) audio. Each rectangular block represents a segment. |
In the proposed method, we regard each segment of an audio as an independent information source for the final decision whether the two audio clips are from the same audio or not. A fingerprint block (fingerprints of N consecutive segments) is used for fingerprint matching. By querying the reference- fingerprint database (DB), which contains all the fingerprints of audios that we want to identify, with each fingerprint in the block, we obtain the candidate matched DB positions corresponding to the block. If the same DB position is matched more than ![]() times out of the N fingerprints in a fingerprint block, the query audio block is claimed to be the audio in the DB corresponding to the matched DB position.
times out of the N fingerprints in a fingerprint block, the query audio block is claimed to be the audio in the DB corresponding to the matched DB position.
For the DB query of each fingerprint, the square of the Euclidean distance measure D is used as follows:
![]() (6)
(6)
where p and q are the fingerprints from the different audio segments. If D is smaller than a threshold T, it is hypothesized that the two audio segments p and q are from the same audio segment. The selection of the threshold T is usually performed based on the false alarm rate PFA which is the pro-bability to declare different audios as similar. By the central limit theorem, the distance measure D has a normal distribution if M is sufficiently large and the contributions in the sums are sufficiently independent [1]. Through the normal approximation ![]() of the distance measure D, the false alarm rate PFA-seg of individual matching is given as follows:
of the distance measure D, the false alarm rate PFA-seg of individual matching is given as follows:
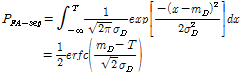 (7)
(7)
By assuming that the fingerprint p is independent and identically distributed random process with zero mean and unit variance from (5), the mean and the standard deviation of D can be estimated as mD = 2 and ![]() = 0.4677 from the typical value of E[p4[n]] = 2.5. The details of the estimation were covered at [2].
= 0.4677 from the typical value of E[p4[n]] = 2.5. The details of the estimation were covered at [2].
By viewing each fingerprint as independent infor-mation sources, we claim that the two fingerprint blocks are from the same audio if the same DB position is matched more than ν times. Then the false alarm probability of an audio block PFA-blk is given by
![]() (8)
(8)
For a certain value of PFA-blk, the threshold T for D can be determined from (7) and (8).
III. Experimental Results
The proposed method was tested using the finger-print DB generated from 1000 songs that include various genres, such as classic, jazz, pop, rock, and hiphop. DB search and fingerprint matching were performed using a fingerprint extracted from each segment of the input query audio. The local invariant fingerprint matching method in Section 2.2 is used to finally verify the matching results.
To test the robustness of the proposed method, the original audios were subjected to various kinds of audio processing steps, including MP3 compression, equalization, linear speed change, and time-scale modification, and their respective fingerprint blocks were extracted (see [1] for a detailed description of the processing steps). For the two different values of ν, the false rejection rates of the proposed fingerprint matching method are shown in Table 1 for randomly selected 2000 audio blocks in the 1000 song DB. In the experiments, we use M=16, N=25, and the matching threshold T corresponding to PFA-blk =10-12. The table shows that the proposed method is robust against the common audio processing steps as well as speed changes. Although the previous method [2], based on fixed-length segment, showed slightly better performance on compression and equalization, it was highly vulnerable to the linear speed changes. In practice, the weak robustness against speed changes is a pitfall in broadcast monitoring and could be easily utilized by attackers to avoid filtering in file-sharing system. However, some of the recently- published audio fingerprinting methods [9-10] still could not handle the linear speed changes properly and thus show robustness up to just 2% speed changes [9]. Specialized schemes [5,11,12], that can handle the linear speed changes, have been proposed. But those countermeasures to speed changes typically degrade robustness against other distortions as in the proposed method (Table 1). Thus future work is needed to develop a method which can maintain high robustness against all kinds of audio distortions including compression, equalization, filtering, speed changes, and time-scale modifications.
IV. Conclusion
In this paper, we show that the robustness of an audio fingerprinting against speed changes can be significantly improved by synchronizing fingerprint extraction and matching with the segmentation boundaries. The limited repeatability of the segmen-tation boundaries was overcome by the local invariant matching in which only small numbers of correct boundaries are needed for claiming successful match-ing. Experimental results show that the proposed method is highly robust against significant amount of speed changes and other common distortions including compression and equalization.
