

I. 서 론
딥러닝 기반 음성 향상(Speech Enhancement, SE)은 대규모 데이터에서 학습된 표현력을 바탕으로 전통적 신호처리 기법을 지속적으로 상회하는 성능을 보여 왔다.[1] 특히 자기지도 방식으로 방대한 음성 자료에서 사전학습된 음성 표현 학습(Speech Representation Learning, SRL) 계열 기저 모델이 확산되면서, 음성 인식·분리·합성뿐 아니라 잡음 환경에서의 향상 문제에도 폭넓게 적용되고 있다.[2,3]
음성 향상에 SRL 모델을 결합하는 전형적 방법은 SRL이 출력하는 임베딩 벡터를 음성 향상 모델에 직접 제공하는 것이다.[3] 이 임베딩 벡터는 화자·음운·발화 맥락을 포함하는 고차원 표현으로, 제한된 감독 신호만으로도 우수한 일반화 성능을 이끈다. 그러나 SRL 모델을 추론 경로에 직접 포함하는 방식은 대규모 파라미터 수와 메모리 요구량으로 인해 경량 디바이스 탑재를 어렵게 하고, 비인과 구조나 긴 지연으로 실시간 응용을 제약한다.[3,4] 이러한 제약을 완화하기 위해 SRL을 손실 함수에만 사용하는 접근도 제안되지만, SRL을 추론 경로에 포함하는 방식에 비해 성능 저하가 뚜렷하게 관찰된다는 한계를 가진다.[4]
이 한계를 완화하기 위해 최근 연구[5]에서는 학습을 두 단계(two-stage)로 분리하는 전략이 제안되었다. 먼저 SRL과 함께 학습된 1단계 모델(Stage-1, conditioned baseline model)이 은닉 벡터를 생성하고, 이어 SRL 없이 학습하는 2단계 모델(Stage-2, baseline model)이 이를 모사하도록 훈련한다. 이러한 두 단계 학습은 SRL 사용에 따른 성능 이득을 상당 부분 유지하면서도, 추론 시에는 SRL 모델을 제거하여 실시간성을 확보하고 모델 복잡도를 낮출 수 있다는 장점을 가진다. 다만 기존 연구는 Stage-1에서 얻은 은닉 벡터를 별도의 가공 없이 표적으로 사용하고, 단순 ℓ2 정합으로 정보를 이전하는 수준에 머물러 있어, 거대 SRL이 생성한 복잡한 정보가 투영된 은닉 표현을 2단계 모델이 잘 모사하지 못하는 문제가 존재한다.[6]
본 연구의 기여는 다음과 같이 정리된다.
(1) 두 단계 학습 체계에서 표적 은닉 벡터 설계를 핵심 변수로 재정의하고, t-sne기반 분포 완화, 최대 엔트로피 정규화, 크기 조정을 포함하는 구체적인 은닉 벡터 가공 전략을 제안한다. 베이스라인 모델로는 실시간 음성 향상을 위해 널리 사용 되고 있는 DEMUCS[7]를 채택하고, Reference [5]의 두 단계 학습 절차를 따르되, Stage-1에서 생성된 디코더 입력 은닉 벡터 구성을 네 가지 전략으로 분류하여 비교한다.
(2) 표준 벤치마크 데이터베이스와 Perceptual Evaluation of Speech Quality(PESQ), a composite measure for signal distortion(CSIG), a composite measure of background noise distortion(CBAK), a composite measure for overall speech quality(COVL), Short Time Objective Intel ligibility(STOI) 등 객관적 평가 지표군에 기반한 정량 평가를 통해 각 은닉 벡터 가공 전략의 특성과 한계를 분석하고, 은닉벡터 통계치를 적절히 조정하는 설계 방법의 필요성을 실증한다.
(3) SRL 모델의 추론 비용에 증가 없이 혹은 무시할 만한 증가만 있는 구조 변경에서, 은닉 벡터를 가공하는 것만으로 Stage-2 모델의 성능을 유의하게 개선할 수 있음을 보인다. 이를 통하여 경량·실시간 지향 단일 채널 음성 향상 시스템 설계에 실질적인 시사점을 제공한다.
II. 관련 연구
SRL 모델은 대규모 비라벨 음성 데이터로부터 다양한 다운스트림 태스크로 전이 가능한 잠재 표현을 학습하도록 설계된다. 대표적으로 wav2vec 2.0은 원시 파형을 합성곱 신경망(Convolutional Neural Network, CNN) 인코더로 잠재 시퀀스로 변환한 뒤 일부 구간을 마스킹하고, 양자화된 코드북을 표적으로 하는 대조 학습(InfoNCE)을 통해 문맥적 표현을 학습한다.[8]
Reference [3]은 인과 및 비인과 설정에서 SRL을 음성 향상 시스템에 통합하는 두 가지 접근 (i) SRL 임베딩 벡터의 직접 주입, (ii) SRL 기반 보조 손실을 체계적으로 비교하였다. 비인과 설정에서는 임베딩 벡터 직접 주입이 가장 큰 성능 향상을 보였고, 보조 손실은 개선 폭은 상대적으로 작지만 일관된 이득을 제공하였다. 반면 인과 설정에서는 다수 SRL 모델의 비인과적 구조로 인해 임베딩 벡터 직접 주입이 현실적으로 어렵고, 대안으로 검토된 보조 손실 접근 또한 통계적으로 유의미한 이득을 안정적으로 제공하지 못하는 한계를 보였다.
이후 연구들[3,4]은 추론 단계에서 SRL을 배제하면서도 성능을 유지하거나 개선하기 위하여 적대적 학습, 지식 증류, 사전학습 구조의 변형 등 다양한 방법을 탐색하였다. 그러나 전반적으로 인과 SE 환경에서 얻어지는 성능 향상은 제한적이라는 점이 지적된다.[3,4]
최근 제안된 두 단계 학습 방법[5]은 추론 시 SRL을 사용하지 않기 때문에 실시간 구현과 연산 복잡도 측면에서 제약이 상대적으로 작다. 먼저 Stage-1에서 SRL을 결합한 음성 향상 모델이 목표 태스크에 특화된 은닉 벡터를 생성하고, 이어서 Stage-2가 SRL 없이 이 은닉 벡터를 모사하도록 학습하였다. 다만 그 성능 개선량이 Stage-1 에서 보여준 성능에는 크게 미치지 못하는 한계가 있었다.
III. 제안 방법
본 장에서는 두 단계 학습 체계 내에서 표적 은닉 벡터 를 설계하고 정합하는 방법을 제시한다. Stage-1의 전체 구조는 Fig. 1과 같다. DEMUCS 모델에 SRL 모델의 출력(즉 임베딩 벡터)을 결합하여 훈련한다. 이 때 디코더 입력을 다양한 방식으로 가공하여 Stage-2 모델이 쉽게 모사할 수 있는 표적으로 만든다. SRL 모델로는 wav2vec 2.0을 사용하였다.
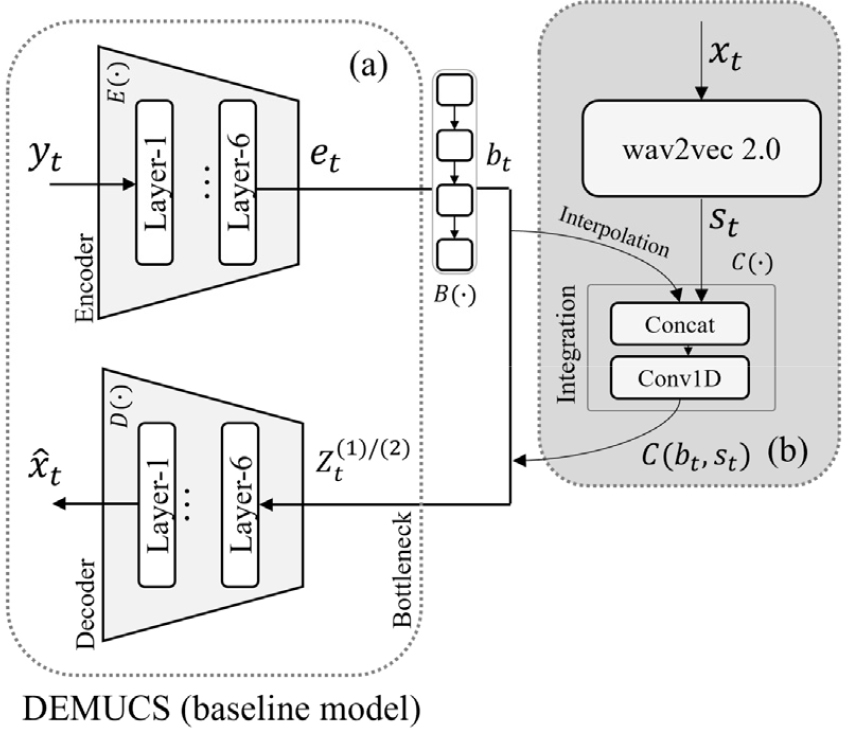
Stage-2 에서는, Stage-1 구조에서 SRL을 제거하여, DEMUCS 모델만 남기고 훈련시킨다. 이 과정에서 표적 은닉 벡터와의 정합을 통해, 추론 시 SRL 의존성을 제거하면서도 성능 이득을 유지하도록 학습한다.
3.1 전체 프레임워크
Fig. 1은 SRL 모델을 사용하는 두 단계 학습의 전체 프레임워크를 나타낸다. Baseline model 로 사용된 DEMUCS는 합성곱(convolution) 기반 U-Net형 인코더–디코더 구조에 스킵 연결을 결합하여 시간영역 파형을 직접 복원하는 베이스라인 모델이다.[7] 인코더는 다단 스케일 다운샘플링과 비선형 활성화를 통해 입력 파형을 다중 해상도의 은닉 벡터로 압축하고, 병목 구간에서는 순환/시퀀스 모듈(예: LSTM, TCN 등)을 통해 장기 의존 정보를 통합한다. 디코더는 업샘플링과 스킵 연결을 이용해 세부 구조를 복원하며, 최종적으로 시간영역 신호를 출력한다.
Stage-1 훈련은 다음과 같다. DEMUCS 인코더 는 잡음이 더해진 음성 를 로 변환한다. 한편 wav2vec 2.0 모델은 동일한 음성의 깨끗한 버전 를 SRL 임베딩 벡터 로 만든다. 결합 모듈 는 병목 계층 을 통해 만들어진 와 임베딩 벡터 를, Fig. 1의 (b) 같이 합성곱을 이용하여 은닉 벡터 를 생성한다(그림에서 사용된 위첨자는 Stage 번호를 표시한다. 즉 는 Stage-1에서의 은닉 벡터를 의미한다). 디코더 는 은닉 벡터를 입력으로 향상된 음성 출력을 생성한다.
Stage-2에서는 SRL 모델을 사용하지 않으므로, 결합 모듈 없이, DEMUCS 인코더와 병목 계층만으로 은닉 벡터 를 생성한다(즉, ). 학습 과정에서는 가 은닉 에 수렴하도록 학습한다. 그러므로 우리는 Stage-1에서 생성한 은닉 벡터 을 표적 은닉 벡터라고 한다. 본 논문에서 가 표적 은닉 벡터 을 잘 추종하게 하도록, 다음의 네 가지 가공 전략을 시도하였다.
(1) 원본 은닉 벡터를 표적화(ideal)
아무 가공 없이, SRL이 결합된 이상적인 은닉 벡터를 직접 표적으로 사용한다. 이를 제안한 여러 기법과 비교하는 기준으로 삼는다.
(2) t-SNE 변환을 이용한 표적화(t-SNE)
고차원 임베딩 벡터의 복잡한 분포를 t-SNE 기반 저차원 매니폴드로 투영·완화한다. 이 저차원 벡터를 인코더의 출력과 결합하여 얻은 표적 은닉 벡터를 Stage-2 모델이 모사한다.
(3) 최대 엔트로피 정규화를 통한 표적화(MER)
Stage-1 훈련 과정에서 손실함수에 이 최대 엔트로피를 가지도록 정규화(Maximum Entropy Regularization, MER)를 추가한다. 이를 통하여 생성된 표적 은닉벡터 는 최대 엔트로피를 가짐으로서, 그 값은 가능한 분산된다. 그러므로 Stage-2에서 모사가 일부 부정확하더라도, 추론 성능의 저하에 미치는 영향이 적을 수 있을 것이다.
여기서 는 최대엔트로피 졍규화로 훈련되었다.
(4) 크기 조정을 통한 표적화(scaling)
크기 조정 방식은 큰 값을 더 크게, 작은 값은 더 작아지게 만든다. 이를 통해, 은닉벡터의 큰 값, 즉 고에너지 성분을 더 쉽게 모사할 수 있도록 만든다.
표적 은닉벡터를 학습하는 Stage-2 모델은 기본적으로 Fig. 1(a) baseline model이다. 다만, 크기 조정된 은닉벡터 를 모사한 경우, Fig. 2와 같이 원래의 크기로 되돌리는 계층이 DEMUCS 디코더의 입력 앞에 추가된다. 이때, 원래의 크기로 되돌리는 계층이 필요한 이유는 모사하고자 하는 벡터가 크기 조정되지 않은 벡터이기 때문이다.
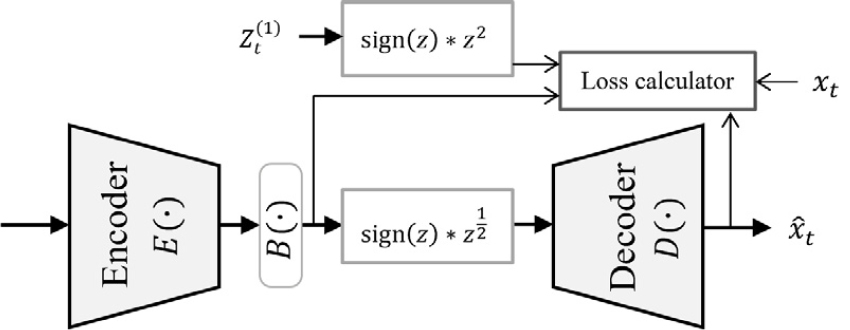
해당 계층의 기능은 Eq. (5)와 같으며, DEMUCS 디코더의 입력은, 다른 경우와 달리, 이다.
3.2 손실함수
Stage-1의 손실 함수는 DEMUCS[6]에서 사용된 것과 동일하게 L1 loss와 multi-resolution STFT loss를 더하여 사용하였다. Stage-2의 손실 함수는 Stage-1에서 사용했던 손실과, 은닉 벡터 정합 손실을 더하여 구성한다. 은닉 벡터 정합 손실은 은닉 벡터를 처리한 것에 따라 다르게 사용되며, 구체적인 내용은 Eq. (6)와 같다.
여기서 method ∈ {ideal, tSNE, MER, scaling}이다. 는 weighting factor를 의미하며 실험을 통하여 경험적으로 정하였다.
IV. 실험 환경
실험에서는 네 가지 표적 은닉 벡터 가공 전략(ideal, tSNE, MER, scaling)을 DEMUCS 구조에서 동일 학습 방법을 사용하여 비교·분석하였다. 학습 데이터베이스로는 딥러닝 기반 단일 채널 음성 향상 연구에서 사실상 표준 벤치마크로 활용되는 VoiceBank + DEMAND(VBD) 데이터셋[9]을 사용하였다. VBD는 28명의 영어 화자 음성과 다양한 실제·인공 잡음을 여러 신호대잡음비(Signal to Noise Ratio, SNR) 조건에서 혼합한 11,572개의 학습용 발화와, 학습에 사용되지 않은 2명의 화자 및 별도의 잡음·SNR 조합으로 구성된 824개의 테스트 발화로 이루어진다.
모든 음성 및 잡음 데이터는 16 kHz로 샘플링하였으며, 잡음이 더해진 음성은 4 s 분량, 그리고 1 s씩 이동하면서 분할하여 DEMUCS의 입력으로 사용하였다. 모델 훈련에는 Adam 옵티마이저를 사용하였다.
성능 평가는 객관적 음질 평가 지표인 PESQ , 합성 MOS 예측치 세 종류(CSIG, CBAK, COVL), 그리고 명료도 지표인 STOI 를 사용하였다. PESQ 점수는 최대 4.5, 합성 MOS 예측치는 1점 – 5점 척도, STOI는 0 % – 100 % 범위로 표현되며, 모든 지표는 값이 클수록 성능이 우수함을 의미한다.
V. 실험 결과 및 분석
Table 1는 DEMUCS 베이스라인과 네 가지 표적 은닉 벡터 설계에 대해, Stage-1과 Stage-2에서 얻은 객관적 평가 지표를 요약한 것이다. Stage-1(ideal) 은 모든 척도에서 DEMUCS(baseline)에 비하여 상당히 우월한 성능을 보인다. 하지만, Stage-1(ideal)의 표적 은닉 벡터 을 모사한 Stage-2(ideal)의 성능이 DEMUCS(baseline) 보다 우월하다고 보기 어렵다.
Table 1.
Performance evaluation of proposed method modifying the Stage‑1 latent vectors.
본 연구에서 제안한 방식으로 만든 표적 은닉벡터로 훈련한 Stage-2 의 경우, 특히 크기 조정을 통한 표적 은닉벡터를 모사한 Stage-2(scaling)는, DEMUCS(baseline)에 비하여, 모든 지표에서 일관되게 개선된 성능을 보였다. 이는 고에너지 구간의 왜곡을 줄이는 전략이 전체적인 지각 품질과 주관적 만족도 그리고 명료도에 직접적으로 기여함을 시사한다.
Stage-2(tSNE)의 경우, DEMUCS(baseline)와 Stage-2(ideal)에 비하여, 소폭 성능 개선이 있음을 보여준다. 하지만 비교대상에 비하여 CBAK 가 낮으며, 상대적으로 CSIG은 높은 데, 이는 저차원 메니폴드가 신호 복원에는 도움이 되지만 잡음 제거에는 도움이 되지 못한다는 것을 시사한다. 또한 STOI가 Stage-2(ideal)보다 소폭 낮은 것은 만족스럽지 못한 결과이다. Stage-2(MER)의 경우, DEMUCS(baseline)에 비해서는 소폭 성능 개선을 보였다. 하지만 Stage-2(ideal)에 비하여 PESQ, CSIG 만 개선되었다는 한계를 보여준다.
Stage-2(tSNE)와 Stage-2(MER)의 결과를 정리해 보면, 여전히 표적 은닉벡터의 정보가 충분히 모사되지 못하여 음성의 세부적인 부분이 복원되지 못한다고 해석할 수 있다. 반면 Stage-2(scaling) 방식을 사용하면 상대적으로 표적 은닉벡터의 모사가 원활하여 일관된 품질 개선을 얻을 수 있음을 알 수 있다.
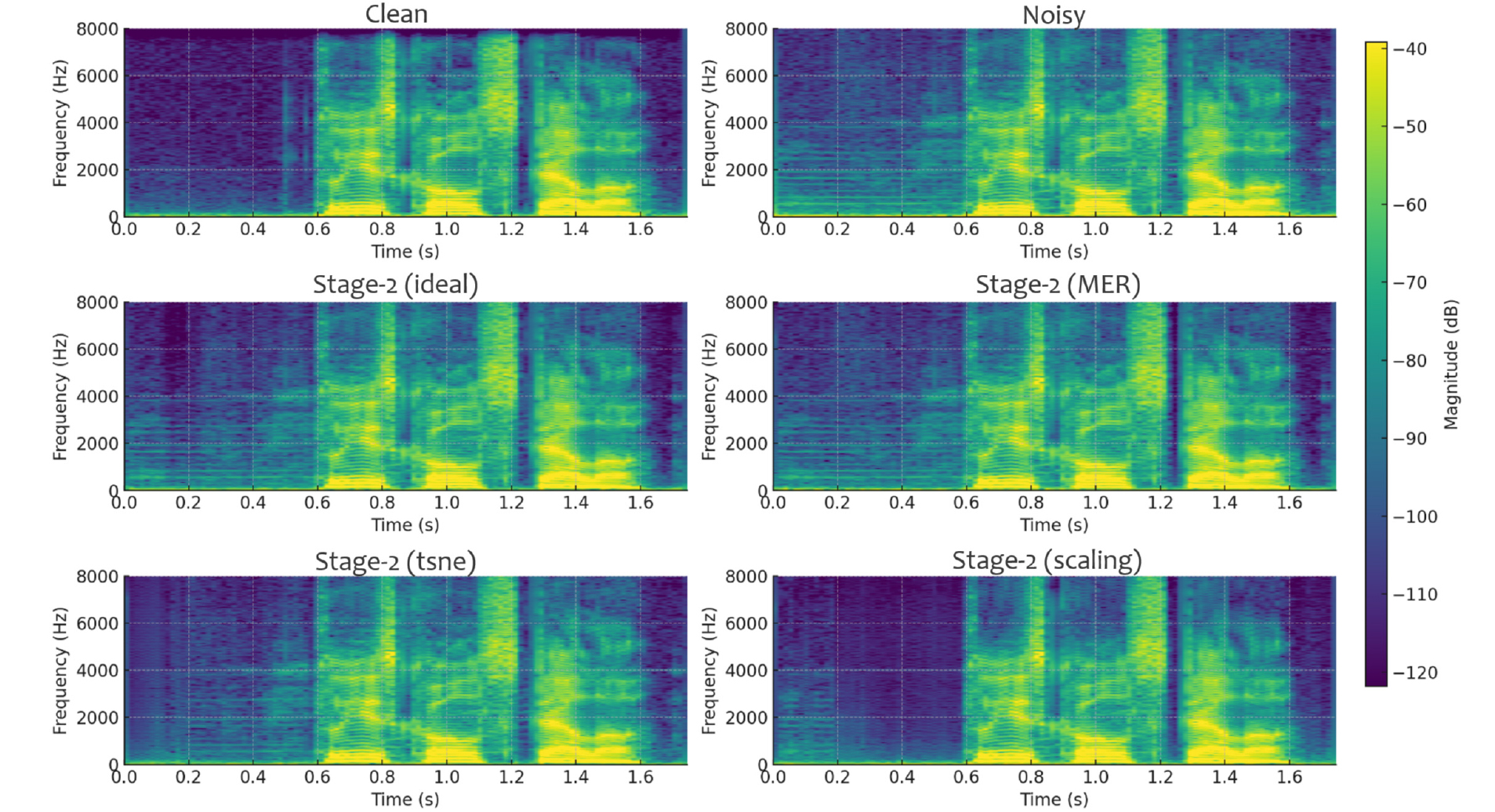
Fig. 3은 (a) clean speech, (b) 0 dB SNR의 잡음 섞인 음성, 그리고 추정 음성 스펙트로그램을 (c) Stage-2(ideal), (d) Stage-2(tSNE), (e) Stage-2(MER), (f) Stage-2(scaling) 모델의 처리 결과를 비교하여 보여준다. (c) ~ (e)는 전반적으로 잔류 배경 잡음 성분이 넓게 남아 있는 반면 (f)는 잡음이 많이 제거되어 깨끗한 음성 (a)와 유사한 모습을 보인다. 이는 Table 1에서 확인한 경향과 일치한다.
VI. 결 론
본 연구에서는 음성 표현 학습(SRL) 모델을 추론 단계에서 배제하면서도 그 이점을 유지하고자 하는 두 단계 학습 체계에서, 네 가지 형태의 표적 은닉 벡터를 비교·평가하였다. 이를 통해 “Stage-1에서 얻은 은닉 벡터를 무엇으로, 어떻게 표적화할 것인가”라는 설계 선택이 단일 채널 음성 향상 성능에 실질적인 영향을 미칠 수 있음을 확인하였다. 동일한 베이스라인 모델(DEMUCS)과 데이터셋, 손실 함수, 하이퍼파라미터를 엄격히 통제한 조건에서 실험을 수행한 결과, 제안한 네 가지 표적 설계 가운데 크기 조정기반 크기 조정 방식이 PESQ와 COVL을 포함한 대부분의 객관적 지표에서 가장 안정적이고 일관된 성능 향상을 제공함을 보였다. 비록 본 연구의 실험은 DEMUCS 아키텍처에 한정하여 수행되었으나, 이는 소폭의 파라미터를 추가한 경량 구조라도 Stage-1 은닉 벡터의 스케일을 적절히 조정한다면, 두 단계 훈련 방법을 사용하여 음성 향상 시스템의 성능을 유의하게 개선할 수 있음을 시사한다.
