

I. 서 론
II. 주성분 분석을 이용한 진동 스펙트럼 차원 축소
2.1 선박용 발전기 진동 실험 데이터
2.2 진동 스펙트럼을 이용한 기관 고장진단
2.3 주성분 분석을 이용한 차원 축소
III. 실험 데이터 분석
3.1 차원 축소 데이터와 인공신경망을 이용한 고장진단
3.2 고장진단 정확도 분석
3.3 인공신경망 입력 기여도(contribution) 분석
IV. 결 론
I. 서 론
자율운항선박과 같이 무인 또는 최소 인원만으로 운용되는 선박을 운항하기 위해서는 안전을 위해 선박 기관시스템의 효과적인 상태진단 방법이 필요하다. 진동 신호는 기관 상태에 영향을 주지 않고 측정이 가능하고, 기관 건전성과 관련된 정보를 풍부히 지니고 있어 상태진단에 폭넓게 사용되고 있으나, 다른 데이터에 비해 상대적으로 샘플율이 높은 단점이 있다. 높은 샘플율에 따른 데이터 차원수 증가는 상태진단에 사용되는 머신러닝 알고리즘의 크기를 증가시키고 훈련을 느리게 만들거나 최적해 탐색을 어렵게 만들 수 있다. 이를 완화시키기 위하여 다양한 차원수 감소 기법이 시도되었으며, 디젤 엔진과 같은 내연 기관의 고장진단과 관련된 연구에서도 적용된 바 있다. Fog et al.[1]은 선박 엔진에서 측정된 음향 방출 시계열 신호에 주성분 분석(Principal Component Analysis, PCA)를 적용하여 차원 축소를 수행하고, 차원 축소된 신호에 신경망을 이용하여 고장진단을 수행하였다. 연구에서는 총 2,048개의 차원수를 가지는 음향 방출 신호에 PCA를 적용하여 76개의 차원을 가지는 신호로 변환하고, 신경망을 적용하여 엔진 실화에 대한 고장진단 성능을 확인하였다. He et al.[2]은 내연 기관에 대해 마이크로폰으로 측정된 음향 신호를 이용해 엔진 마모를 진단하는 연구를 진행하였는데, 음향 신호에서 추출된 특성 변수의 차원 축소를 위해 PCA를 적용하였다. Yang et al.[3]은 디젤 엔진에서 측정된 진동 신호의 다양한 시간-주파수 분포 함수에 대해 비음수 행렬 분해(Nonnegative Matrix Factorization, NMF)와 PCA를 적용하여 차원 축소를 수행하고, K-최근접 이웃 알고리즘을 이용하여 엔진 밸브 이상에 대한 고장진단 연구를 수행한 바 있다.
본 연구에서는 선박용 디젤 엔진의 진동 데이터를 이용해 고장진단을 수행한 연구 결과를 제시한다. 고장진단을 위한 특징으로 전력 스펙트럼 밀도를 사용하되, PCA를 이용해 차원 축소를 적용한 후 다층 인공신경망(Multi-Layer Perceptron, MLP)[1,4]에 입력하는 방법을 사용하였다. 이와 함께 고장 분류 과정에서 차원 축소 데이터의 기여도를 정량적으로 평가하기 위해 머신러닝 입력 변수의 중요도 평가(variable importance measure) 방법으로 제안된 integrated gradients[5]와 feature permutation[6]을 이용하여 입력 변수 기여도를 분석하고, 일반적으로 널리 이용되는 통계적 특징 변수들과 비교하였다.
II. 주성분 분석을 이용한 진동 스펙트럼 차원 축소
2.1 선박용 발전기 진동 실험 데이터
본 연구에서는 실물의 선박용 발전기 디젤 엔진에서 측정된 진동 실험 데이터를 사용하였다. 데이터는 한국선급 그린쉽 기자재 시험․인증센터에 설치된 실험용 선박 발전기 디젤 엔진에서 측정된 것이다. 사용된 발전기는 MAN B&W Type 6L27/38 4행정 6실린더 모델로서 750 RPM의 공칭 속도로 동작한다. 실험은 0 %, 10 %, 25 %, 50 %, 75 %, 100 %의 6가지 부하 조건에서 진행되었으며, 총 2개의 정상상태와 6가지의 고장상태에 대해 데이터가 취득되었다. Table 1은 발전기에 적용된 고장의 종류를 정리한 것이다. 진동 측정을 위해 총 13개의 발전기 진동 측정 위치에 Dytran Model 3148E 가속도계가 설치되었으며 본 연구에서는 터보차저에 설치된 센서 2개를 제외한 11개의 센서 데이터를 이용하였다. 데이터는 16,384 Hz의 샘플율로 획득되었다.[7]
Table 1.
Fault scenarios of the experiment.
2.2 진동 스펙트럼을 이용한 기관 고장진단
본 연구에서는 전력 스펙트럼 밀도를 고장진단 특징으로 사용한다. 전력 스펙트럼 밀도를 사용하면, 앞서 소개한 기존 연구에서 사용한 시계열 신호 또는 시간-주파수 분포 함수에 비해 시간적인 변화를 감지하는 데에 제한이 따르나, 엔진 사이클에 동기화되지 않은 측정 데이터에도 적용이 가능한 장점을 지닌다. 이는 동일한 파형을 가지되 상대적인 시간 지연 차이가 있는 두 신호가 스펙트럼 밀도에서는 동일한 형태를 가지기 때문이다. 따라서 상대적인 시간 지연은 스펙트럼 밀도 상에서는 서로 다른 특징으로 나타나지 않는다.
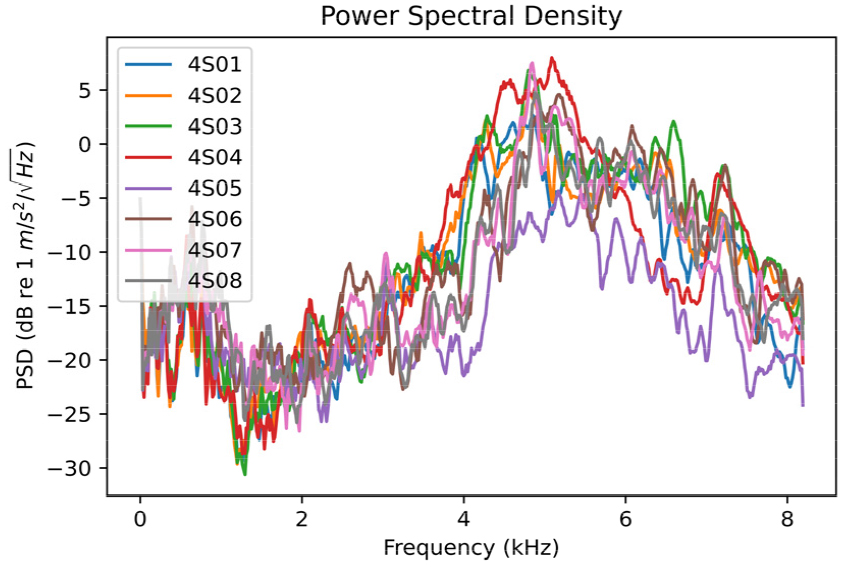
Fig. 1은 Table 1에 나타낸 고장의 종류별로 5초 길이의 샘플 데이터에 대한 전력 스펙트럼 밀도 그래프를 나타낸 것이다. 그래프의 4S01, 4S08은 정상상태의 센서 데이터, 4S02 ~ 4S07은 각각 Table 1에 표시된 고장에 따른 비정상상태의 센서 데이터를 나타낸다. 스펙트럼은 웰치 방법(Welch’s method)를 이용하여 추정하였다. 웰치 방법 적용 시에는 1,024개의 샘플을 가지는 세그먼트로 나누어 Hanning 창함수를 적용하고, 각 세그먼트는 50 %의 오버랩을 가지도록 하였다. 그래프에서 나타난 바와 같이, 발전기의 상태에 따라 주파수 영역에서 전력 스펙트럼 밀도의 그래프 형태가 다르게 나타나며, 상태별로 나타나는 특정 주파수에서의 특징들을 통해 상태의 구분이 가능하다. 그러나 스펙트럼 정보의 차원수가 크기 때문에 이를 입력으로 받는 인공신경망을 구성할 경우 훈련에 많은 시간과 학습 데이터를 필요로 한다. 따라서 발전기의 상태별 데이터 특징에 대한 정보의 손실을 최소화하며, 데이터의 차원을 요약, 축소하여 효과적으로 분류할 수 있는 방법을 적용할 필요가 있다.
2.3 주성분 분석을 이용한 차원 축소
본 연구에서는 주성분 분석을 이용해 측정된 진동 스펙트럼 데이터의 차원을 축소하였다. 주성분 분석이란 데이터들의 분산이 크게 나타나는 방향 벡터에 해당하는 주성분을 계산하여 데이터를 방향 벡터에 투영하는 것으로 상관성이 높은 변수들로 데이터의 차원을 축소, 요약하는 방법이다. Eq. (1)에서 는 4S01 ~ 4S08의 모든 상태에 대한 진동 데이터를 의미하며, 은 총 데이터 개수이다. 각 데이터 는 차원의 크기가 인 벡터로 전력 스펙트럼 밀도 데이터를 의미하며, Eqs. (2), (3)과 같이 데이터의 공분산 행렬 를 계산한 후, 고유값 분해를 수행하여 데이터 차원의 크기에 해당하는 수만큼 주성분을 의미하는 고유 벡터 를 구할 수 있다.[2]Eq. (3)에서 는 주성분 분석에서 사용된 차원수를 나타낸다. 최종적으로 Eq. (4)와 같이 데이터를 번째 차원의 고유벡터 에 투영하여 차원이 축소된 데이터 를 계산할 수 있다. 여기서 고유값이 가장 큰 고유 벡터가 데이터의 분산이 가장 큰 것을 의미한다.[2]
III. 실험 데이터 분석
3.1 차원 축소 데이터와 인공신경망을 이용한 고장진단
선박용 발전기의 데이터에 대한 각 채널별 주성분 분석을 수행하기 위해 시계열 데이터에 대해 5초길이 단위로 분리하였으며, 이 때 데이터의 수는 모든 부하 조건에 대해 정상상태 데이터 564개, 비정상 상태 데이터 1,692개를 모두 포함하여 채널별로 약 2,256개가 존재한다. 채널별 데이터는 고장상태별로 분류되어 있으며, 기계학습 모델이 다양한 고장상태를 학습하기 위해서 데이터를 셔플(shuffle)하였으며, 기계학습을 여러 번 반복 시 셔플된 데이터의 분포에 따른 영향을 없애기 위해 동일한 시드(seed)로 고정하였다. 그 중 약 90 %에 해당하는 2,031개 데이터를 기계학습 모델의 학습용 데이터로, 나머지 10 %인 225개 데이터는 모델의 최종 상태 진단 성능을 평가하기 위한 테스트 데이터로 사용하였다.
학습용 데이터에 대해 Eqs. (1), (2), (3)과 같이 주성분 분석을 수행하여 Eq. (4)와 같이 주성분 계수로 정의되는 고유 벡터 에 투영된 데이터 를 계산하였다. 학습용 데이터에 대한 주성분 분석 이후, 축소된 차원의 데이터인 주성분 계수를 입력으로 하여 발전기의 상태를 진단하는 다층 인공신경망 모델(Fig. 2)을 통한 기계학습을 수행하였다. 학습 모델의 입력으로 사용되는 주성분의 개수에 따른 학습 모델의 상태 진단 정확도 변화를 관찰하기 위해 주성분의 개수에 해당하는 의 차원 를 1부터 15까지 변화시켜가며 기계학습 모델의 입력으로 사용하였으며, 학습된 모델에 테스트 데이터를 입력하여 발전기 상태 진단 성능을 관찰하였다. 검증용 데이터는 설정하지 않았으며, 반복 학습을 통해 학습데이터의 손실함수 값이 수렴하고, 테스트 데이터에 대한 진단 성능이 높은 기계학습 모델의 하이퍼 파라미터를 최적화하는 과정을 추가하여 검증용 데이터의 역할을 대체하였다. 테스트 데이터의 경우, 기존에 학습되지 않은 데이터에 대해 상태를 진단하는 것이므로 주성분 분석을 수행하지 않고, 학습용 데이터에서 얻어진 주성분을 이용해 차원 축소를 수행한다.
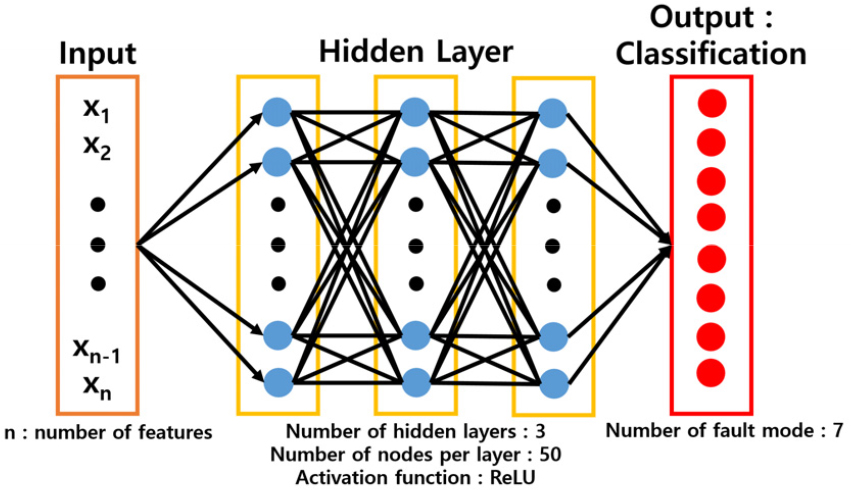
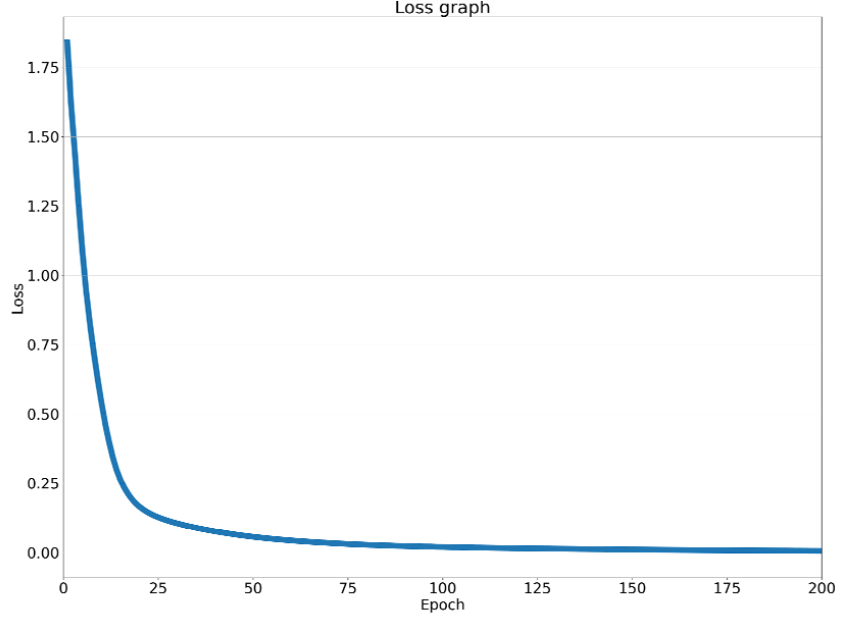
다층인공신경망 모델에 대한 하이퍼파라미터의 경우, 학습 시간을 단축하고 모델의 진단 성능을 높이기 위해 학습하는 데이터의 계산에 최적화된 설정을 찾을 필요가 있다. 해당 모델의 하이퍼파라미터 설정을 바꿔가며 학습동안의 손실함수 값의 수렴성과 한 에폭(epoch)당 계산 시간을 확인하여 최적화를 수행하였다. 최종적으로 다층인공신경망 모델의 레이어의 개수는 입력층, 은닉층 3개로 총 4개이며, 레이어의 활성화 함수는 Eq. (5)의 ReLU 함수를 사용하였다. 또한, 기계학습의 학습 속도를 높이기 위해 10개의 미니배치를 설정하였고, 충분한 학습을 위해 에폭 수를 2000회로 설정하였다. 손실 함수의 경우, 발전기의 상태를 분류하는 기계학습 모델이기 때문에 Eq. (6)과 같이 소프트맥스(softmax) 함수와 크로스 엔트로피(cross entropy) 함수가 결합된 형태인 손실 함수로 설정하였다.[8] 발전기 상태는 모두 7가지로 소프트맥스 함수를 통해 학습 모델의 결과 값을 모든 상태에 대한 총합이 1인 이산 확률 분포를 계산한다. 이후, 크로스 엔트로피 함수를 통해 실제 상태와 학습 모델이 예측한 상태를 비교하여 손실을 계산한다. 손실 함수가 0에 가까울수록 학습 모델이 예측하는 상태의 정확도가 높아진다. Eq. (6)의 와 는 각각 테스트 데이터의 실제 고장상태에 해당하는 점수(score), 번째 고장상태에 대한 인공신경망 출력값을 의미한다. 앞서 설명한 바와 같이 사용된 데이터는 총 7개의 고장상태를 가진다(Table 1). 따라서, Eq. (6) 첫째 줄 괄호안의 소프트맥스 출력은 식별된 고장상태가 에 해당할 확률을 의미한다. Fig. 3은 전체 2,000 에폭 중 200 에폭까지의 진행에 따른 인공신경망 손실 함수의 변화를 나타낸 것으로, 에폭 증가에 따라 손실 함수의 값이 매우 작은 값으로 수렴하는 것을 확인할 수 있다.
3.2 고장진단 정확도 분석
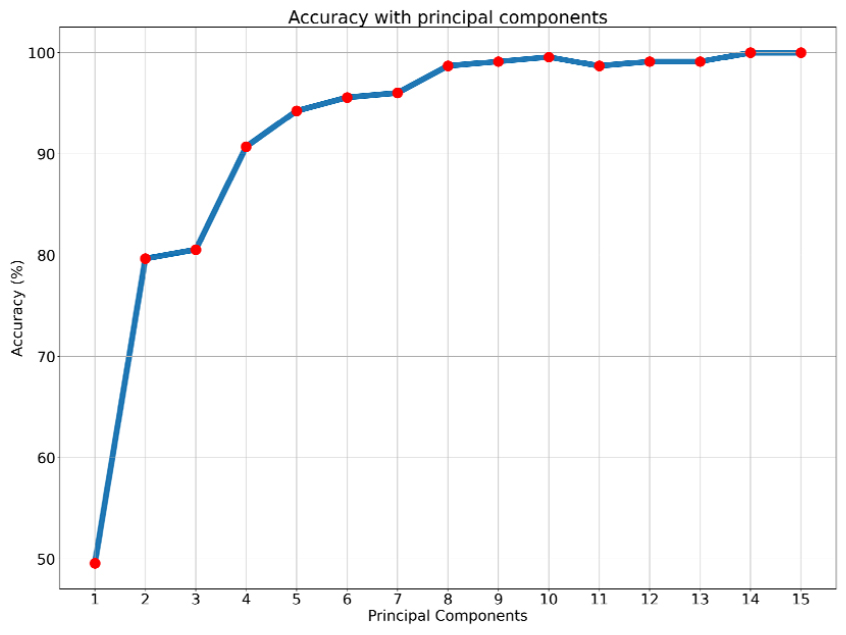
앞서 설명한 바와 같이, 다층인공신경망 모델의 입력으로 사용되는 주성분 개수에 따른 진단 성능을 평가하기 위해 주성분 개수를 1부터 15까지 증가시키며 기계학습을 수행하였다. 선박용 발전기 상태 진단 성능은 학습이 완료된 모델의 테스트 데이터에 대한 상태 진단 정확도로 평가하였다. Fig. 4는 사용된 주성분 개수의 변화에 따른 고장진단 정확도를 나타낸 것이다. 주성분의 개수가 증가하면서 모델의 상태 진단 정확도가 증가하는 것을 확인할 수 있다. Fig. 5는 10개의 주성분 계수를 입력으로 하는 기계학습 모델의 진단 결과로 약 99.11 %의 정확도로 발전기의 상태를 진단하는 것을 확인하였다. 또한, 주성분의 개수가 10개 이상인 경우 정확도가 약 99 %에서 수렴하였으며 따라서 최종적으로 기계학습 모델의 입력으로 사용되는 주성분의 개수를 10개로 설정하였다.
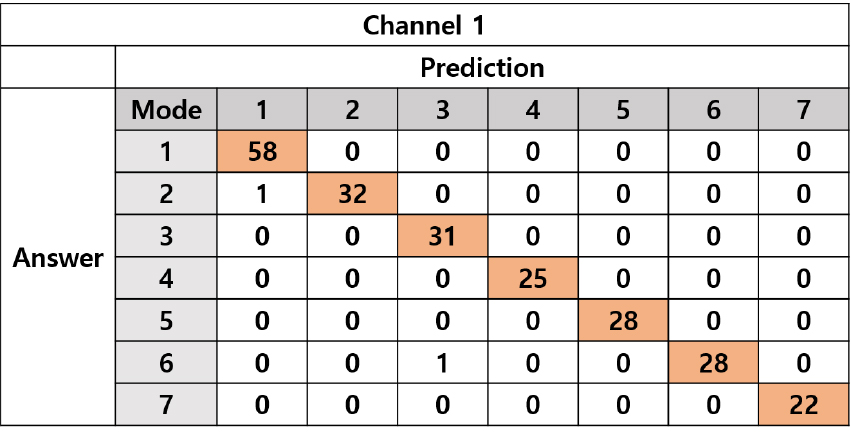
주성분 계수 값에 의한 발전기의 상태 진단 성능을 비교하기 위해, 고장진단을 위해 널리 이용되는 일반 특징을 사용하였을 때의 고장진단 결과와 비교하였다. 사용된 다층인공신경망은 주성분 계수 값을 입력으로 하는 다층인공신경망과 동일한 구조를 가진다. Table 2는 비교에 사용된 진동 신호의 일반 특징들로 각각 시간 영역, 주파수 영역으로 분류되는 특징과 대표적인 통계적 특징들이 포함되어 있다.[9]
Table 2.
Description of conventional features.
Table 3은 두 가지 입력 데이터에 대한 인공신경망의 고장 분류 정확도를 비교하여 나타낸 것이다. Table 2에서 제시한 일반 특징을 입력으로 사용하여 기계학습을 수행하였을 때, 11개 채널에 대한 고장진단 정확도의 산술 평균은 약 90.11 %으로 나타났으며, 10개의 주성분 계수를 입력으로 기계학습을 수행하였을 때에는 평균 정확도가 99.40 %로 계산되어 주성분 분석을 사용하는 경우가 더 높은 정확도를 나타내었다. 이와 함께, 일반 특징을 입력으로 하는 인공신경망의 경우 채널 간 정확도 차이가 크게 나타났는데 채널 2에서 99.57 %로 가장 높고 채널 11에서 73.45 %로 가장 낮은 정확도를 가진다. 주성분 계수를 입력으로 하는 인공신경망의 경우, 입력 데이터의 차원이 10으로 일반적인 특징의 차원수 23보다 더 적음에도 모든 채널에서 99 % 이상의 정확도를 가진다. 이는 전력 스펙트럼 밀도 데이터에 주성분 분석을 적용하여 기계학습을 수행하는 것이 통계적 특징 변수들을 이용하는 것보다 전반적으로 고장 분류에 유리함을 보여준다.
Table 3.
Comparison of classification accuracies of conventional features and principal components.
3.3 인공신경망 입력 기여도(contribution) 분석
학습 모델의 상태 진단 정확도와 더불어 다층인공신경망의 발전기 상태 진단 성능에 대한 입력 데이터 특징의 기여도를 평가하였다. 기여도는 입력 데이터 특징이 기계학습 모델의 상태 진단에 작용한 영향력을 정량적으로 계산한 값을 의미하며, 기여도를 통해 입력 데이터의 특징이 학습 모델이 예측한 상태의 정확도에 끼치는 영향을 알 수 있다. 본 연구에서는 Eq. (7)로 표현되는 적분 경사(Integrated Gradients, IG)와 특성 순열(Feature Permutation, FP) 방법을 이용하여 기여도 분석을 수행하였다.[10] 일반적으로 비선형성을 가지는 기계학습 모델의 입출력 관계를 1차 테일러 급수로 근사하면, 데이터 입력 특징이 출력에 미치는 영향력인 기여도를 입출력에 따른 기울기와 입력 값의 곱으로 근사적으로 측정할 수 있다. 문제는 신경망의 비선형성에 의해 일부 입력값 범위에서 입력에 대한 기울기가(실제로는 영향력을 가지고 있지만) 0에 가까운 값으로 나타날 수 있으며, 이 경우 기여도를 정확하게 표시하지 못하게 된다. 적분 경사 방법은 이러한 기여도 계산 방법을 수정한 것으로 입력 데이터 특징과의 비교 대상으로서 기준이 되는 베이스라인(baseline) 벡터를 정의하고, 베이스라인 기준으로 입력 데이터 특징 값까지 점차 증가시켜가며 계산된 출력의 기울기를 더해 누적된 값과 입력 데이터 특징 값을 곱한 값을 기여도로 정의한다. 따라서 일부 구간의 입력값 범위에서 기울기가 작게 나타나더라도 베이스라인으로부터 변화한 입력값 범위 전체에 대해 기여도를 적분하여 산출하므로 이를 보완할 수 있다. 적분 경사 방법은 Eq. (7)과 같이 베이스라인으로부터 입력 데이터 특징의 값까지의 직선 거리상의 모든 점들을 적분하여 계산하며, 여기서 는 베이스라인, 는 수치적분을 위한 계수, 는 기계학습 모델의 네트워크를 의미한다.
적분 경사 방법은 민감도(sensitivity)와 구현 불변성(implementation invariance) 등의 특징을 만족하여 기여도의 정량적 평가를 수행하는데 있어 효과적인 것으로 알려져 있다. 앞서 설명한 바와 같이, 민감도는 입력 데이터 값의 변화에 따른 학습 모델의 경사 값의 변화를 의미하며, 적분 경사 방법을 이용하면 입력 데이터 값의 변화에 따른 경사 값이 특정 구간에서 변하지 않는 문제를 해결할 수 있다. 또한, 적분 경사 방법은 학습 모델의 레이어 배치, 노드 수 등의 구조가 바뀌어도 동일한 기여도 값을 계산할 수 있어 기여도 평가 시 학습 모델에 따른 영향을 최소화한다.[5] 특성 순열 방법은 입력의 특징 중 특정 값들을 무작위로 섞었을 때 변화한 예측 성능을 기존의 예측 성능과 비교하여 영향력을 평가하는 방법으로 적분 경사 방법과 마찬가지로 기계학습 모델에 상관없이 기여도 계산이 가능하다. 이를 부연 설명하면, 주어진 입력 배치(batch)에서 특정한 입력 특징값을 측정 시간 순서에 대해 무작위로 섞어서 입력을 재구성한 후 신경망에 넣었을 때 신경망의 예측 에러를 증가시켰다면 해당 입력값은 중요한 입력값으로 간주되어야 한다. 반대로, 무작위로 입력을 섞었을 때에도 신경망의 예측 성능에 변화가 없다면 해당 특징은 중요도가 낮은 것으로 간주되어야 할 것이다. 특성 순열 방법도 기여도 계산 방법이 비교적 간단하여 시간 및 자원의 소모를 아낄 수 있다.
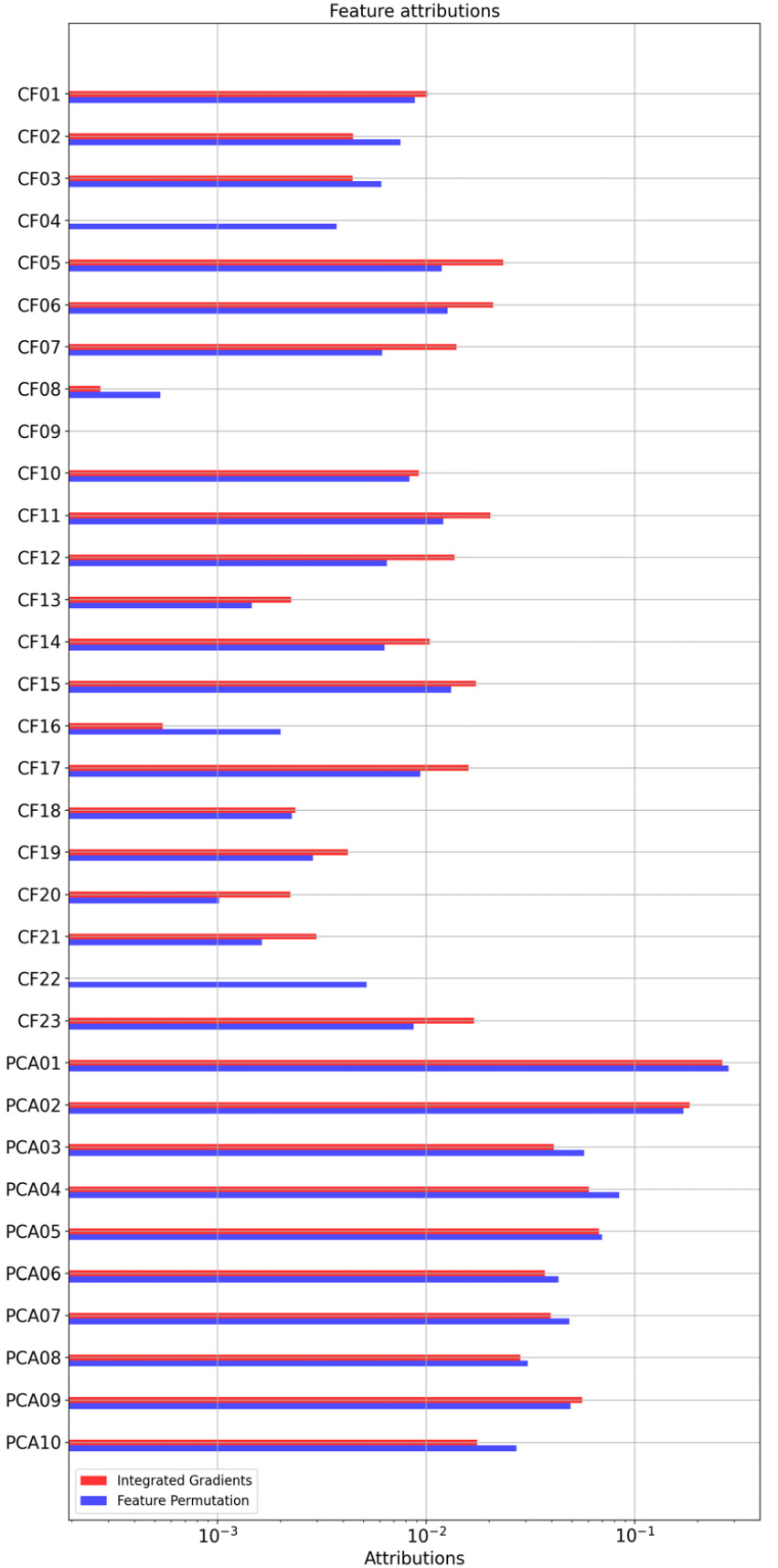
이러한 입력 기여도 기반 성능 분석을 위하여 진동 신호의 일반적인 특징과 주성분 차원 축소 데이터 모두를 입력으로 하는 다층인공신경망 모델을 구성하여 입력 기여도 계산을 수행하였다. 사용된 다층인공신경망 모델은 입력 노드의 개수만 다르고 Fig. 2와 동일한 뉴런 개수와 구조를 가진다. Fig. 6은 그 결과로서 IG방법과 FP방법에 의해 측정된 입력 기여도를 비교하여 나타낸 것이다. 두 방법에 의한 입력 기여도 측정 결과는 전반적으로 서로 유사하게 나타났으나, 일반 특징의 경우에 IG가 FP보다는 다소 크게 나타나는 경향을 보여준다. 그래프에서 확인되듯이, 진동 신호의 일반 특징들보다 주성분 계수의 기여도가 대체적으로 크게 나타났으며 주성분 계수의 고유값이 큰 순서대로 기여도가 크게 나타나는 것을 알 수 있다. 이는 PCA에 의한 차원 축소된 데이터가 Table 2의 일반 특징들에 비해 상대적으로 많은 고장 관련 정보를 포함하고 있음을 보여주며, PCA 적용 시에는 가능한 큰 고유값에 해당하는 주성분 계수를 사용하는 것이 유리함을 보여준다.
IV. 결 론
본 연구에서는 선박용 발전기 엔진의 진동 데이터에 대하여 주성분 분석을 통한 차원 축소를 수행하고, 차원 축소된 주성분 계수를 이용하여 고장 분류를 수행한 연구 결과를 제시하였다. 고장 분류를 위한 특징 변수로 진동 시계열 데이터로부터 스펙트럼 밀도를 사용하였으며, 다층인공신경망을 이용하여 고장 분류를 수행하였다. 실제 스케일의 선박용 디젤 발전기 실험 데이터에 적용하였을 때, 제안된 방법이 모든 고장 시나리오에 대해 정확하게 고장 데이터를 분류해내는 것을 확인하였으며, 이는 주성분 분석으로 축소된 데이터가 고장진단에 필요한 정보를 충분히 포함하고 있음을 보여준다. 이와 함께 고장진단에 널리 사용되는 일반 특징을 인공신경망의 입력값으로 사용하는 경우와 분류 정확도를 비교하였으며, 비교 결과, 주성분 분석이 더 작은 입력 데이터 차원을 가지고 있음에도 더 높은 분류 정확도를 나타내었다. 머신러닝 입력 변수의 중요도 평가방법인 integrated gradients와 feature permutation를 이용한 기여도 평가 결과에서도 주성분 분석에 의해 차원 축소된 데이터가 일반 특징과 비교하여 더 높은 고장 분류 기여도를 가지는 것으로 나타나, 주성분 분석이 고장진단을 위한 차원 축소에 효과적으로 사용될 수 있음을 보여준다.
