

I. 서 론
적응 필터는 능동소음 제어, 시스템 식별, 채널 등화기, 잡음 제거 등 많은 응용 분야에서 사용되어져 왔다. 적응 필터 알고리즘들 중에, LMS(Least Mean Square)와 NLMS(Normalized Least Mean Square)는 상대적으로 낮은 연산량을 요구하고, 구현이 간단하다는 장점으로 인해 널리 사용되고 있다. 그러나 LMS와 NLMS는 일반적으로 음성 신호와 같이 입력 샘플들 간에 상관도가 큰 입력 신호를 다루는 경우, 알고리즘의 수렴속도가 저하된다. 이러한 단점을 극복하기 위해 RLS(Recursive Least Square)가 제안되었다. RLS는 고유치 분포가 큰 입력 신호에 빠른 수렴속도를 보이지만 LMS와 NLMS와 비교하여 구현이 어렵고 많은 연산량을 요구한다는 단점을 가지고 있다.[1,2]
K. Ozeki와 T. Umeda는 구현이 간단하다는 NLMS의 장점과 유색 신호를 다루는 환경에서 빠른 수렴속도를 보이는 RLS의 장점을 가지는 인접 투사 알고리즘(Affine Projection Algorithm, APA)을 제안하였다.[3] APA는 투사 차원이 커짐에 따라 RLS의 성능에 가까워지며 투사차원이 작아짐에 따라 NLMS의 성능에 가까워진다. 하지만 APA는 필터 계수를 갱신하기 위해 사용된 입력 신호의 역행렬을 요구한다는 단점이 있다. 투사 차원이 높아짐에 따라 고유치 분포가 큰 입력 신호를 다루는 환경에서 빠른 속도를 보이지만 역행렬 연산으로 인해 많은 연산량을 요구하게 된다. 이러한 문제를 해결하기 위해, 역행렬 연산을 효율적으로 처리하기 위한 여러 알고리즘들이 제안되었다.[4,5]
한편, APA는 충격성 잡음 환경 하에서 성능이 저하된다는 단점을 갖고 있다.[6] 이는 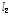 -norm을 최적화하는 알고리즘이 가지는 단점으로써 APA 역시 이에 해당한다. 많은 연구자들이
-norm을 최적화하는 알고리즘이 가지는 단점으로써 APA 역시 이에 해당한다. 많은 연구자들이 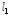 -norm을 최적화하는 부호 알고리즘이 충격성 잡음환경에서 안정적으로 동작함을 보였다. 또한 부호 알고리즘은 상대적으로 낮은 연산량을 요구한다는 장점을 가지고 있다. 최근 T. Shao et al.[7] 가 유색신호에 빠르게 동작하는 APA을 충격성 잡음 환경으로 확장하여 충격성 잡음 환경에서 안정적으로 동작하며 역행렬 연산을 요구하지 않는 인접 투사 부호 알고리즘(Affine Projection Sign Algorithm, APSA)을 제안하였다.
-norm을 최적화하는 부호 알고리즘이 충격성 잡음환경에서 안정적으로 동작함을 보였다. 또한 부호 알고리즘은 상대적으로 낮은 연산량을 요구한다는 장점을 가지고 있다. 최근 T. Shao et al.[7] 가 유색신호에 빠르게 동작하는 APA을 충격성 잡음 환경으로 확장하여 충격성 잡음 환경에서 안정적으로 동작하며 역행렬 연산을 요구하지 않는 인접 투사 부호 알고리즘(Affine Projection Sign Algorithm, APSA)을 제안하였다.
본 논문에서는 기존의 APSA의 수렴 속도를 증가시키는 새로운 APSA를 제안한다. 제안된 APSA 또한 기존의 APSA와 같이 충격성 잡음 환경에서 안정적으로 동작하며 역행렬 연산을 요구하지 않는다는 공통점을 가지고 있다. 두 알고리즘의 차이점으로는 기존의 알고리즘은 필터 계수 갱신을 위해 사용되는 각각의 입력 신호를 모든 입력 신호의 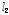 -norm으로 정규화하는 반면에 제안된 알고리즘은 각각의 입력 신호를 각각의 입력 신호의
-norm으로 정규화하는 반면에 제안된 알고리즘은 각각의 입력 신호를 각각의 입력 신호의 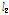 -norm으로 정규화한다는 점이 다르다.
-norm으로 정규화한다는 점이 다르다.
본 논문의 구성은 다음과 같다. I장 서론에 이어서 II장에서는 APA와 APSA를 살펴보고 III장에서 새로운 APSA를 제안한다. IV장에서 컴퓨터 모의 실험을 통하여 기존의 APSA와 제안된 APSA의 성능을 비교 및 분석하며 V장에서 결론을 맺는다.
II. APA와 APSA
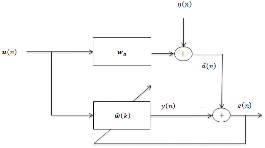
Fig. 1은 적응 필터가 시스템 식별 환경에서 적용되는 블록도를 나타낸다.
시스템 식별 환경에서 원하는 신호 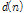 은 미지의 시스템
은 미지의 시스템 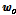 를 통과한 출력으로써 아래와 같이 표현된다.
를 통과한 출력으로써 아래와 같이 표현된다.
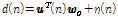 , (1)
, (1)
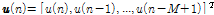 은 입력 신호이고
은 입력 신호이고 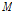 은
은 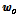 의 길이를 나타낸다.
의 길이를 나타낸다. 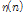 은 배경 잡음과 충격성 잡음이 더해진 측정 잡음을 나타낸다. 첨자
은 배경 잡음과 충격성 잡음이 더해진 측정 잡음을 나타낸다. 첨자 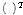 는 벡터 또는 행렬의 전치를 나타낸다.
는 벡터 또는 행렬의 전치를 나타낸다. 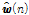 을
을 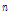 번째 반복에서 미지의 시스템
번째 반복에서 미지의 시스템 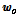 를 추정하는 적응 필터 벡터로 설정하면 아래와 같은 오차 신호를 정의할 수 있다.
를 추정하는 적응 필터 벡터로 설정하면 아래와 같은 오차 신호를 정의할 수 있다.
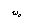
 , (2)
, (2)
가장 최근의 입력 신호 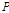 개를 모아
개를 모아 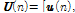
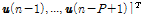 을 정의하면 아래와 같은 사전 오차 벡터와 사후 오차 벡터를 정의 할 수 있다.
을 정의하면 아래와 같은 사전 오차 벡터와 사후 오차 벡터를 정의 할 수 있다.
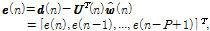 (3)
(3)
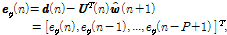 (4)
(4)
여기서 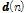 은
은 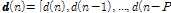
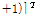 을 나타낸다. K. Ozeki와 T. Umeda가 APA을 아래와 같은 최적화 문제를 통해 제안하였다.[3]
을 나타낸다. K. Ozeki와 T. Umeda가 APA을 아래와 같은 최적화 문제를 통해 제안하였다.[3]
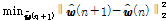 , (5)
, (5)
subject to 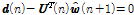 , (6)
, (6)
여기서 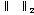 는
는 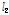 -norm을 나타내며,
-norm을 나타내며, 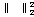 은
은 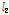 -norm의 제곱이다. Lagrange multiplier를 이용하여 수 Eq.(6)의 제약을 가지는 Eq.(5)의 최적화 문제를 풀면 아래와 같이 APA의 필터 갱신 수식을 얻을 수 있다.
-norm의 제곱이다. Lagrange multiplier를 이용하여 수 Eq.(6)의 제약을 가지는 Eq.(5)의 최적화 문제를 풀면 아래와 같이 APA의 필터 갱신 수식을 얻을 수 있다.
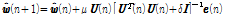 . (7)
. (7)
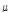 는 step size를 나타내며,
는 step size를 나타내며, 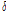 는
는 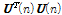 이 0이 되는 것을 막기 위한 작은 양수이며
이 0이 되는 것을 막기 위한 작은 양수이며 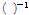 은 역행렬을 나타낸다. APA이 상관관계가 큰 입력신호를 다루는 환경에서 수렴속도가 빠르다는 장점을 갖고 있지만 충격성 잡음이 추가된 환경에서는 수렴속도가 느리다는 점과 필터 계수를 갱신하기 위해 역행렬을 구해야한다는 단점을 가지고 있다. 이를 해결하기 위해, T. Shao et al.[7]가 아래와 같은 최적화 문제를 통하여 APSA을 제안하였다.
은 역행렬을 나타낸다. APA이 상관관계가 큰 입력신호를 다루는 환경에서 수렴속도가 빠르다는 장점을 갖고 있지만 충격성 잡음이 추가된 환경에서는 수렴속도가 느리다는 점과 필터 계수를 갱신하기 위해 역행렬을 구해야한다는 단점을 가지고 있다. 이를 해결하기 위해, T. Shao et al.[7]가 아래와 같은 최적화 문제를 통하여 APSA을 제안하였다.
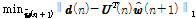 , (8)
, (8)
subject to 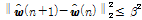 . (9)
. (9)
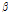 는 필터 계수 벡터가 급격하게 적응되는 것을 방지하기 위한 파라미터로써 수식이 전개 된 후 step size로 대체된다. Lagrange multiplier를 사용하기 위해 Eqs.(8)과 (9)를 이용하여 아래와 같은 비용함수를 정의해 보자.
는 필터 계수 벡터가 급격하게 적응되는 것을 방지하기 위한 파라미터로써 수식이 전개 된 후 step size로 대체된다. Lagrange multiplier를 사용하기 위해 Eqs.(8)과 (9)를 이용하여 아래와 같은 비용함수를 정의해 보자.
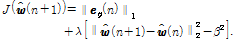 (10)
(10)
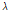 는 Lagrange multiplier를 나타낸다. 비용함수
는 Lagrange multiplier를 나타낸다. 비용함수 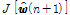 을
을 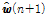 로 미분하면 아래와 같은 결과를 얻을 수 있다.
로 미분하면 아래와 같은 결과를 얻을 수 있다.
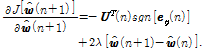 (11).
(11).
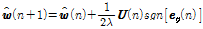 , (12)
, (12)
여기서 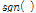 은 부호 함수를 나타내고 Eq.(12)는 Eq.(11)의 오른쪽 항을 0으로 취한 후 전개한 결과이다. 제약 (9)의
은 부호 함수를 나타내고 Eq.(12)는 Eq.(11)의 오른쪽 항을 0으로 취한 후 전개한 결과이다. 제약 (9)의 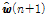 을 Eq.(12)로 대체하면 아래와 같은 결과를 얻을 수 있다.
을 Eq.(12)로 대체하면 아래와 같은 결과를 얻을 수 있다.
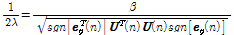 . (13)
. (13)
Eqs.(12)와 (13)을 통해 T. Shao et al.[7]가 제안한 APSA의 필터 갱신 수식을 아래와 같이 얻을 수 있다.
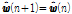
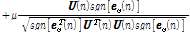 ,
,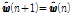
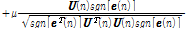 .
.Eq.(13)의 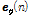 이
이 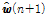 의 정보를 요구하기 때문에 Eq.(14)와 같이
의 정보를 요구하기 때문에 Eq.(14)와 같이 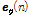 을
을 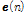 으로 대체하여 사용한다. 기존 APA과 비교하여 APSA는 역행렬 연산을 요구하지 않기 때문에 연산량이 적으며 충격성 잡음 환경에 안정적으로 동작한다는 장점을 가지고 있다.
으로 대체하여 사용한다. 기존 APA과 비교하여 APSA는 역행렬 연산을 요구하지 않기 때문에 연산량이 적으며 충격성 잡음 환경에 안정적으로 동작한다는 장점을 가지고 있다.
III. 제안된 APSA
본 논문에서 제안하는 APSA를 유도하기 위해 아래와 같은 비용함수를 정의한다.
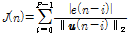 , (15)
, (15)
여기서 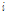 는 투사차원
는 투사차원 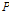 개까지의 과거 신호를 가리키는 인덱스이다.
개까지의 과거 신호를 가리키는 인덱스이다. 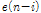 는 Eq.(3)으로부터 아래와 같이 정의할 수 있다.
는 Eq.(3)으로부터 아래와 같이 정의할 수 있다.
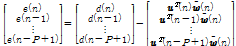 , (16)
, (16)
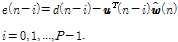 , (17)
, (17)
비용함수 (15)는 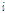 번째 과거 오차 신호의 절대값을
번째 과거 오차 신호의 절대값을 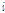 번째 과거 입력 신호의
번째 과거 입력 신호의 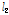 -norm으로 정규화한
-norm으로 정규화한 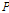 개의 결과를 합함을 의미한다. 최대 경사법을 기반으로 아래와 같은 새로운 APSA의 필터 갱신 수식을 제안한다.
개의 결과를 합함을 의미한다. 최대 경사법을 기반으로 아래와 같은 새로운 APSA의 필터 갱신 수식을 제안한다.
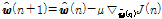 . (18)
. (18)
비용함수의 경사도 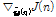 은 아래와 같은 연쇄 법칙을 사용하여 얻을 수 있다.
은 아래와 같은 연쇄 법칙을 사용하여 얻을 수 있다.
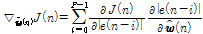 . (19)
. (19)
Eq.(19)의 오른쪽 두 항은 아래와 같이 구할 수 있다.
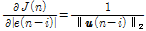 , (20)
, (20)
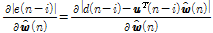
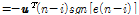 ,
, 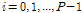 ,
,Eqs.(20)과 (21)를 통하여 비용함수의 경사도 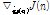 을 아래와 같이 구한다.
을 아래와 같이 구한다.
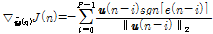 . (22)
. (22)
Eq.(18)의 비용함수의 경사도를 Eq.(22)으로 대체하면 본 논문에서 제안하는 APSA의 필터 갱신 수식을 얻을 수 있다.
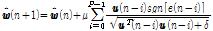 . (23)
. (23)
기존에 제안된 APSA의 필터 갱신 Eq.(14)와 본 논문에서 제안된 APSA의 필터 갱신 Eq.(23)을 비교하여 보자. 두 수식 모두 역행렬 계산을 요구하지 않는다는 공통점이 있다. 차이점으로는 기존 APSA는 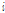 번째 과거 입력신호
번째 과거 입력신호 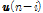 를 과거
를 과거 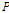 개까지의 입력 신호의
개까지의 입력 신호의 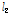 -norm으로 정규화하는 반면에 제안된 APSA는
-norm으로 정규화하는 반면에 제안된 APSA는 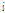 번째 과거 입력 신호
번째 과거 입력 신호 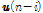 를 해당 입력신호의
를 해당 입력신호의 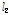 -norm으로 정규화한다는 차이점이 있다.
-norm으로 정규화한다는 차이점이 있다.
IV. 실험 결과
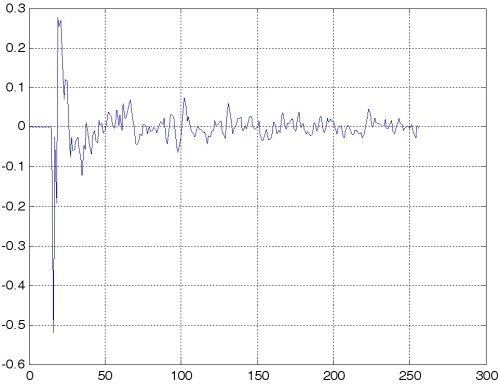
제안된 APSA와 기존의 APSA의 성능을 비교하기 위하여 시스템 식별 환경을 통하여 컴퓨터 모의실험을 실시하였다. 적응 필터의 길이는 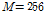 이며 미지의 시스템은 Fig. 2와 같이 256차의 room impulse response를 사용하였다.
이며 미지의 시스템은 Fig. 2와 같이 256차의 room impulse response를 사용하였다.
상관관계를 가지는 입력 신호 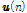 은 평균 0, 분산 1을 가지는 백색 가우스 잡음을 자기회귀과정
은 평균 0, 분산 1을 가지는 백색 가우스 잡음을 자기회귀과정 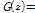
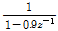 에 통과시켜 생성하였다.
에 통과시켜 생성하였다.
측정 잡음은 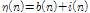 과 같이 설계되었으며 미지의 시스템을 통과한 출력 신호에 가산된다.
과 같이 설계되었으며 미지의 시스템을 통과한 출력 신호에 가산된다. 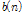 은 배경 잡음으로써 30 dB의 신호 대 잡음비를 가지는 평균 0의 백색 잡음이다.
은 배경 잡음으로써 30 dB의 신호 대 잡음비를 가지는 평균 0의 백색 잡음이다. 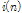 은 충격성 잡음으로
은 충격성 잡음으로 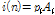 로 설계되며
로 설계되며 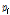 는
는 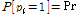 의 성공확률을 가지는 베르누이 과정을 나타내고,
의 성공확률을 가지는 베르누이 과정을 나타내고, 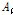 는 평균 0의 백색 가우시안 잡음으로써 분산
는 평균 0의 백색 가우시안 잡음으로써 분산 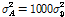 또는
또는 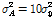 이 컴퓨터 모의 실험을 위해 사용되었다. 다양한 조건 하에서 두 알고리즘의 성능을 비교하기 위해 Pr=0.1, 0.01, 0.001이 사용되었다. 실험 결과는
이 컴퓨터 모의 실험을 위해 사용되었다. 다양한 조건 하에서 두 알고리즘의 성능을 비교하기 위해 Pr=0.1, 0.01, 0.001이 사용되었다. 실험 결과는 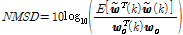 값을 구하여 도시한 것이다. 여기서
값을 구하여 도시한 것이다. 여기서 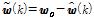 를 나타낸다.
를 나타낸다.
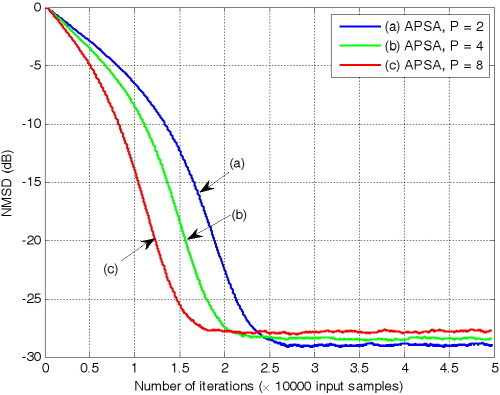
Figs. 3과 4는 기존의 APSA와 제안된 APSA의 투사차원 수에 따른 수렴 특성을 보여준다. 이 실험 결과는 30개의 ensemble 평균을 한 것이다. Pr과 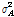 은 특별히 언급되지 않은 경우
은 특별히 언급되지 않은 경우 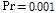 그리고
그리고 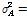
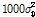 이 사용되었다.
이 사용되었다.
|
Fig. 3. The NMSD learning curve for the conventional APSA with |
|
Fig. 4. The NMSD learning curve for the proposed APSA with |
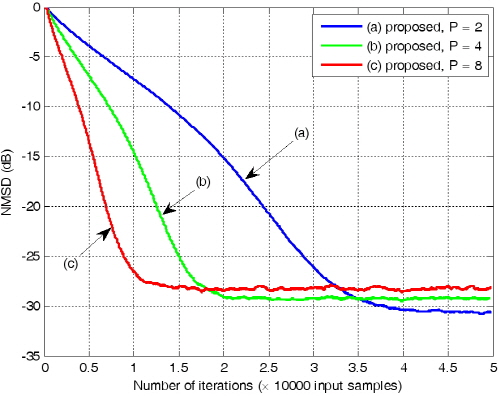
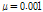 .
.
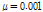 .
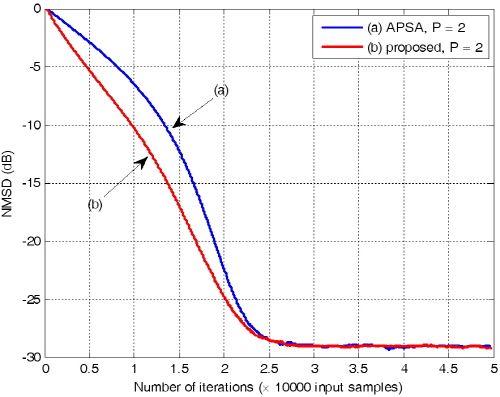
.Figs. 3과 4를 통하여 두 알고리즘의 수렴 특성을 비교하여 보면, 두 알고리즘 모두 투사 차원이 증가함에 따라 수렴속도가 향상되며 수렴 후 오차가 커진다는 것을 확인 할 수 있다. 또한 기존의 APSA보다 제안된 APSA가 투사 차원 증가로 인한 수렴속도의 향상이 더욱 크며 더 낮은 수렴 후 오차를 보이는 것을 알 수 있다. 투사 차원이 2인 경우 기존 APSA보다 제안된 APSA의 수렴속도가 더 느린 것을 확인 할 수 있는데 제안된 APSA의 수렴 후 오차가 더 낮으므로 이를 명확히 비교하기 위해 두 알고리즘의 수렴 후 특성이 같도록 step size를 조정하여 Fig. 5에 도시하였다.
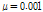 and
and 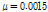 .
.Fig. 5를 통해 제안된 APSA가 더 빠른 수렴속도를 보임을 알 수 있다. Fig. 6은 투사차원이 4, 8인 경우 두 알고리즘의 성능을 같이 비교하기 위해 도시화한 것이다.
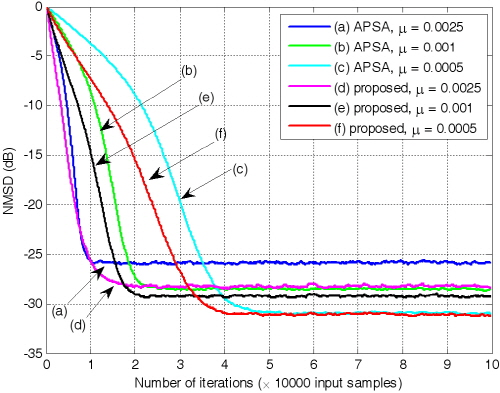
Fig. 6에서 두 알고리즘은 step size 0.001을 동일하게 갖는다. 투사 차원이 4인 경우 기존의 APSA보다 제안된 APSA가 더 빠른 수렴속도를 가질 뿐만 아니라 더 낮은 NMSD 값을 갖는 것을 확인 할 수 있다. 투사 차원이 8인 경우 수렴 후 유사한 NMSD값을 가지지만 제안된 APSA가 훨씬 더 빠른 수렴속도를 갖는 것 또한 확인할 수 있다.
Fig. 7은 step size의 값에 변화를 주어 두 알고리즘의 성능을 비교한 것이다. 투사 차원은 4로 설정하였다.
step size의 크기가 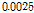 ,
, 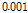 ,
, 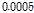 인 경우 두 알고리즘의 수렴 특성을 살펴보면, 해당 step size에 대해 제안된 APSA가 더 빠른 수렴속도 혹은 더 낮은 NMSD값을 보임을 확인 할 수 있다. Fig. 8은
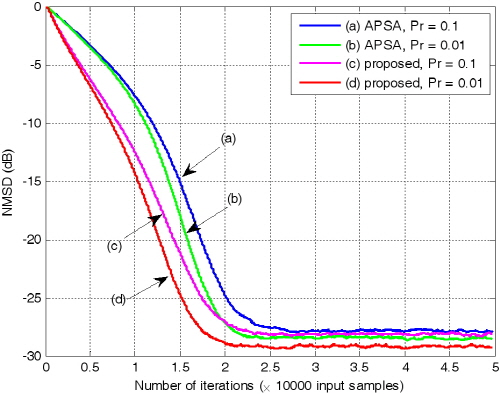
인 경우 두 알고리즘의 수렴 특성을 살펴보면, 해당 step size에 대해 제안된 APSA가 더 빠른 수렴속도 혹은 더 낮은 NMSD값을 보임을 확인 할 수 있다. Fig. 8은 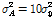 인 경우 두 알고리즘의 성능을 비교한 것이다. 투사차원은 4로 설정하였다.
인 경우 두 알고리즘의 성능을 비교한 것이다. 투사차원은 4로 설정하였다. 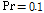 인 경우와
인 경우와 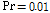 인 두 경우 모두 제안된 알고리즘의 성능이 우수함을 쉽게 확인할 수 있다.
인 두 경우 모두 제안된 알고리즘의 성능이 우수함을 쉽게 확인할 수 있다.
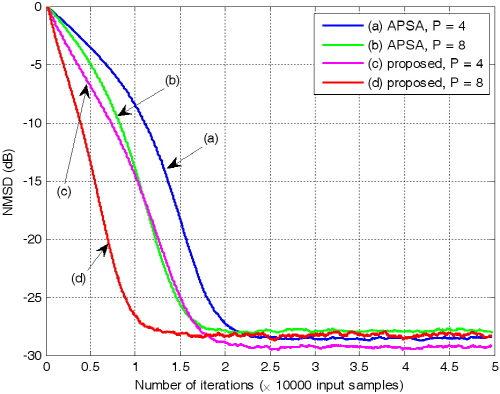
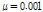 .
.
 .
.
 (
(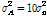 ).
).IV. 결 론
본 논문에서는 기존의 APSA보다 빠른 수렴속도를 가지는 새로운 APSA를 제안하였다. 제안된 알고리즘은 역행렬 연산을 요구하지 않으며 충격성 잡음 환경에서 안정적으로 동작한다는 기존의 APSA의 장점을 유지하면서 기존의 APSA보다 더 빠른 수렴속도를 보인다. 두 알고리즘의 차이로는 필터 계수를 갱신하는 수식에서 기존의 알고리즘은 각각의 과거 입력 신호를 투사차원의 수만큼의 모든 과거 입력 신호의 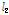 -norm으로 정규화하는 반면, 제안된 알고리즘은 각각의 과거 입력 신호를 해당 입력 신호의
-norm으로 정규화하는 반면, 제안된 알고리즘은 각각의 과거 입력 신호를 해당 입력 신호의 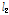 -norm으로 정규화한다는 점이 다르다. 다양한 컴퓨터 모의 실험을 통하여 제안된 APSA가 기존의 APSA보다 더 우수한 수렴 특성을 갖는다는 것을 보였다.
-norm으로 정규화한다는 점이 다르다. 다양한 컴퓨터 모의 실험을 통하여 제안된 APSA가 기존의 APSA보다 더 우수한 수렴 특성을 갖는다는 것을 보였다.
