

I. 서 론
현대의 발달된 IT환경과는 달리, 디지털 콘텐츠의 음량 조절은 매우 비효율적이다. 청자는 음원 재생 전에 실제로 출력될 음량을 알 수 없으므로 선행 출력시킨 후, 시행착오 과정을 거치면서 원하는 수준으로 음량을 수동 조절해야 한다. 또한 재생되는 음원마다 음량이 다르기 때문에 수시로 음량 설정값을 변경해야 한다. 이러한 음량제어 문제를 완화시키기 위해서 여러 가지 음량평준화 방법들이 제시된바 있으나 제작단계에서 발생한 근본적인 문제 해결이 불가능하므로 성능 및 활용성에서 매우 제한적이다.[1]
기존의 음량 평준화 방법은 크게 원본 변형 방식과 AGC(Automactic Gain Control) 방식, RG(Replay Gain)방식으로 나눌 수 있다. 원본 변형 방식은 2000년대 초반의 MP3 Gain 등과 프로그램에서 사용되었으며, 그외에 MP3Normalizer나 SuperMP3Normalizer 등의 프로그램들이 해당된다. 하지만 원본 변형 방식은 음원의 진폭을 직접 변화시키기 때문에 원본자체가 손상되는 결함을 가지고 있다. 또한 증폭과정에서 피크가 발생할 확률이 높고, 진폭을 감소시킬 경우, 음원 자체의 다이내믹레인지가 좁아지는 근본적인 문제가 있다.
AGC(Automactic Gain Control)은 음원의 진폭을 실시간으로 측정하여 목표한 기준치보다 낮으면 증폭하고, 높을 경우 감소시키는 방식을 취한다. 이 방법은 콘텐츠 자체의 진폭을 변화시키는 것이 아닌 출력단에서 증폭감소가 이루어지므로 원본의 손상이 없다는 점과 초보자가 사용하기 편리하여 현재 TV, 멀티미디어 재생기 등에 이용되고 있다. 하지만 이 방식은 실시간으로 목표한 음량이 되도록 음량을 변경하므로, 제작자가 의도한 시간에 따른 음량 균형이 왜곡된다. 예를 들어 제작자가 작은 음량으로 의도해서 제작한 부분은 음량을 키워버리고 의도적으로 큰 소리로 제작한 부분은 음량을 줄여버리므로 감상의 목적으로 사용할 수 없다. 이외에도 AGC의 일종으로 컴프레서를 응용한 DRC(Dynamic Range Control)방식들이[2-3] 제안되었으나 인위적인 선별적 파형 압축으로 인해 시간대별 음량 균형과 음색이 왜곡되므로 AGC의 근본적인 문제를 해결할 수 없다.
마지막으로 RG(Replay Gain)는 2001년에 제안된 음량 표준화 방식으로 음원에 저장된 태그를 기반으로 음량을 조절하는 방식이다. 현재 Winamp나 Foobar 등의 일부 음악재생기에서 지원하고 있으며 아이튠즈에도 RG와 유사한 개념을 사용하는 사운드 조절옵션이 존재한다. RG는 음량판단에 참고할 수 있는 최대피크나 평균에너지 같은 간단한 파라미터 도구를 제공하지만 제대로 활용하기 위해서는 청취자가 개별 음원을 직접 청취하여 볼륨 태그를 입력해야 하는 문제가 있다. 또한 인위적으로 태그설정을 바꿀 수 있고 사용자마다 음량 판단 기준 및 인지능력, 청취 의도가 현저히 달라서 공용화가 불가능하다. 마지막으로 제작자가 의도한 상대적인 음원별 음량차이를 구현할 수 없다.
위에서 언급한 평준화 방식은 음원이 최종 완성된 후에 후처리 과정에 해당한다. 하지만 근본적인 원인은 음원 제작의 마지막 단계인 마스터링 작업에 있다. 마스터링 엔지니어 개인의 성향과 기준에 따라서 음원의 음량이 필연적으로 크게 변하기 때문이다.
이러한 문제를 보완하기 위해 LKFS(Loudness, K-weighted, Relative to Full Scale)와 같은 권고 기준이 발표되기도 하였다. LKFS는 다양한 종류의 방송 콘텐츠 음원을 제작할 때, 참고하는 피크레벨 기준을 효과적으로 제시하기 위한 것으로, dBFS(deci-Bell Full Scale)의 단점을 일부 보완한다.[4-5] 이와 같은 피크 레벨 범위 지정은 제작 과정상에 참고로 활용될 수 있으나, 모든 음원의 진폭 특성을 규정대로 획일화 하는 것은 올바르지 않으며, 실현가능하지도 않다. 그리고 상황에 따라서 0 dBFS 범위를 모두 활용하지 않으므로 신호대잡음비가 감소한다. 마지막으로 음원 전체의 음량을 대표하는 단위로 사용할 수 없다.
다양한 음량제어 문제의 가장 근본적인 원인은 개별 디지털 음원의 대표 음량을 효과적으로 표현할 수 있는 절대적인 기준단위가 없기 때문이다. 만약 이러한 단위가 존재한다면 모든 음원의 음량 평준화 작업은 획기적으로 간단해지며, 보다 효율적인 음량제어 체계를 구상할 수 있다.
본 논문은 사람이 최종적으로 인지한 음량을 표현하기 위한 디지털 음원의 음량 단위와 그것을 기준으로 모든 음량을 제어하는 체계의 개념을 설명하였다.
II. 절대음량
사람이 최종적으로 음량을 인지하는 원리는 대단히 복잡한 것으로 기존의 단위로는 효과적인 측정이 불가능하다.[6] 사람이 느끼는 음량은 청각적인 개인차를 논외로 두더라도, 최대피크와 평균에너지, 음색, 리듬, 에너지 변화양상 등의 요소가 복합적으로 작용하며, 무한대의 음향특성에 따라 세부음원을 제작하여 측정 및 기준을 잡는 것은 현실성이 없다. 또한 이러한 세부적인 측정 결과들을 결합시킨다고 단순히 합산된 결과가 나오지 않으며 다른 형태의 변수들이 끊임없이 생성된다. 결과적으로 개별적인 측정결과를 결합하여 최종적인 인지음량을 예측하는 방법은 비효율적이다.
앞서 설명한 바와 같이 실제 느끼는 최종적인 음량을 예측하거나 그러한 감각을 수치로 표현하는 것은 대단히 어려운 작업이다. 하지만 사람은 두 개의 음원을 비교 청취하면서 자신이 원하는 수준의 음량으로 정확하게 조절할 수 있는 감각적인 능력을 가지고 있다. 실제 출시되고 있는 모든 음반의 개별 음원들은 전적으로 사람이 직접 들은 체감음량 결과에 의해 음량이 조정되어 마스터링 된 것이다.[7] 이렇게 완성된 하나의 앨범 내에서는 모든 청자가 트랙마다 음량을 조절할 필요성을 못 느낀다. 이것은 전문가의 음량판단능력으로 모든 사람에게 보편타당한 수준의 정확한 음량 밸런스 구현이 가능하기 때문이다.[8] 이러한 인간의 음량인지 능력은 절대음량 측정이 실현가능한 가장 중요한 개념적 근거이다.
절대음량(ASL: Absolute Sound Level)이란 하나의 독립적인 음원의 음량을 대표하는 하나의 절대적인 수치를 제시하기 위해 제안된 것으로 단위는 dB(S: Sound)이다.[9-10] 음량척도의 가장 중요한 가치는 결국 사람이 직접 들어서 느낀 음량이므로 절대음량은 사람의 인지음량을 표현하는 척도이기도 하다. 절대음량을 표현하는 단위 dB(S)는 60 dB(S)=60 dB(A)로 출력되는 핑크잡음 환경의 인지음량을 기준으로, 모든 음원의 인지음량을 동등하게 만드는 dB차이를 적용한 것이다. 이것은 기준 음원 1000 Hz를 기준으로 상대적인 dB차이를 통해 동등한 음량을 곡선화 시킨 등라우드니스 곡선의 기준 음원/음량과 개념과 일부 유사하다.
일반적인 관점에서 청자가 어떠한 음원(주로 음악)을 적극적으로 감상할 때 최적의 음량은 청각적으로 안전하며 불쾌감이 없는 범위의 최대 음량이며, 이것을 쾌적최대음량(CML: Comfortable Maximum Level)이라고 한다.[9-10]
CML에 해당하는 인지음량 수준을 정확하게 측정하는 것은 불가능하기 때문에 아래 식과 같이, 상대적으로 감각의 구분이 명확한 음량인지 기준인 MCL (Most Comfortable Level)과 UCL(Uncomfortable Level)의[11] 중간값을 사용한다.
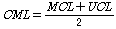 .
.절대음량 측정의 기준 음원은 핑크잡음이 사용되며 기준 음량은 쾌적최대음량(CML: Comfortable Maximum Level)의 개념으로 선정된 60 dB(A)를 사용하였다.[9-10] CML은 권장하는 음량의 최대 기준과 같은 의미로 해석할 수 있으며 이 기준에서부터 상대적인 음량 차이를 통해 효과적인 음량 판단을 할 수 있다.
즉 절대음량 기준 60 dB(S)는 핑크잡음 60 dB(A)와 같으며 이후부터 dB(A)단위는 사용하지 않는다.
Fig. 1은 dB(S)의 측정 순서도이다. 우선 60 dB(A)= 60 dB(S)의 청음 환경에서, 절대음량을 측정할 대상 음원을 출력한다. 만약 측정 대상 음원의 음량이 작게 느껴진다면, 핑크잡음의 음량을 감소시켜 측정 대상 음원과 동등한 수준으로 조절한다. 이 때 감소량이 ‘a’ dB라면 측정하고자 하는 음원의 절대음량은 기준 음량 60 dB(S)에서 ‘a’을 뺀 수치가 된다. 만약 측정 대상 음원이 핑크잡음보다 크다면 측정대상 음원의 음량을 ‘b’ dB 감소시켜서 기준 핑크잡음과 동등한 수준으로 조절한다. 이때의 측정 대상의 절대음량은 60+‘b’ dB(S)가 된다.
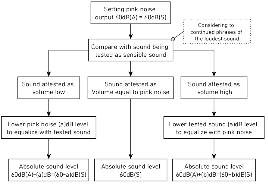
측정 대상 음원에서 실제 세부측정 구간은 전체 중 가장 큰 음량이 지속되는 프레이즈[12] 구간이며, 이것은 대부분 코러스(후렴)에 해당한다. 이 구간은 마스터링 엔지니어가 개별 트랙의 대표음량을 판단하는데 가장 중요한 역할을 한다.
이렇게 측정된 개별 디지털음원의 절대음량을 통해 간단하게 모든 음원의 음량 평준화가 가능하다.[12] 절대음량 측정 결과의 보편타당성을 확인하기 위해 누구나 큰 음량 차이를 느끼는 1980~1990년대와 2010년대에 마스터링된 음악음원을 대상으로 절대음량을 측정한 후, 그 결과를 기준으로 음량 평준화를 실시하였다. 20~30대 성인 30명을 대상으로 위의 방법으로 평준화된 개별 음원을 30개 이상 들려준 결과, 음원별 음량차이에 문제를 느낀 사례는 없었다.
해당 음량척도를 실제 음향 환경에 광범위하게 활용하기 위해서는 수동으로 측정한 절대음량과 유사한 dB(S)를 도출하는 절대음량 자동산출 알고리즘이 요구된다.
절대음량을 자동으로 산출하기 위해서는 수동 측정 과정에서 음량 판단에 영향을 미친 주요 음향 요소들을 분석한 후, 개별 파라미터로 제작하여 성능을 검증하여야 한다. 최종단계에서 모든 파라미터들을 유기적으로 결합시키는 복잡한 과정이 요구된다. 현재 이와 관련된 알고리즘 개발 및 구현 연구가 진행 중이다.
III. 절대음량 체계
절대음량 체계는 현재의 음량 제어 문제를 근본적으로 해결하기 위해 제안된 것으로, 절대음량을 통해 모든 음원의 대표음량을 판단하고, 의도한 출력을 결정한다. 여기서 말하는 음원의 주체는 음악, 혹은 영상과 결합된 멀티미디어 콘텐츠와 같은 제작물을 말한다.
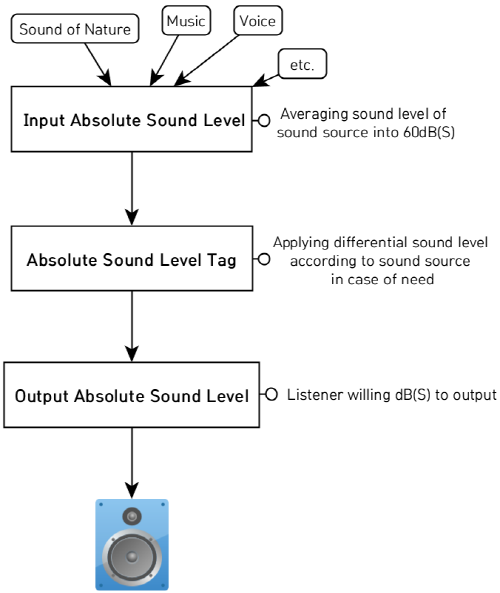
절대음량 체계는 아래의 3가지 요소로 최종적인 음량출력이 결정된다. 첫째, 0 dBFS의 범위를 가지는 디지털 음원 자체의 입력절대음량. 둘째, 청자가 최종적으로 목표한 출력절대음량. 셋째, 제작자가 의도한 음원에 따른 음량의 차이를 구현하는 절대음량태그의 차등감소이다.
입력절대음량이란 음향시스템의 영향을 받지 않는 개별 디지털 음원의 절대적인 대표음량이다. 절대음량 체계는 우선적으로 개별 음원의 입력절대음량 차이만큼 출력게인을 조절하여 모든 개별 음량을 60 dB(S)로 평준화 시킨다. 최종 청취환경도 측정환경과 동일하게 핑크잡음이 60 dB(S)=60 dB(A)로 출력되는 레벨을 기준으로 설정하면, 실제 입력절대음량 60 dB(S)와 출력 절대음량 60 dB(S)이 동등하게 매칭된다. 결과적으로 모든 음원의 음량이 적극적인 음악감상 수준에 적합한 쾌적최대음량(CML)로[9-10] 출력되며, 청자는 이 기준을 통해 언제든지 자신이 원하는 출력절대음량으로 청취할 수 있다. 만약 청자의 경험상 손님과 함께 대화하면서 음악을 청취하고 싶은 음량이 50 dB(S)라면, 해당 수치만 입력하면 모든 음원의 음량은 50 dB(S) 수준으로 출력되는 것이다.
반면 음원에 따라서는 음량의 차등화도 필요하다. 실제 음원 제작자는 음원의 성격과 목적에 따라서 음원별 음량을 다르게 제작한다. 정상적으로 제작된 음반 내에 수록된 곡들에 대한 절대음량 차이는 제작자가 의도한 것이다. 즉 모든 트랙이 동등한 음량으로 출력되는 것은 다른 의미의 음량불균형 문제를 초래한다. 뉴스, 드라마, 영화 대사 등의 일반적인 음성 음원들 역시 일반적인 음악 음원보다 현저히 작은 음량으로 차등 출력되어야 한다.
만약 절대음량을 이용하여 무조건 모든 음원의 음량을 60 dB(S)로 평준화 할 경우, 제작자가 의도한 음량차이를 반영해서 감상 할 수 없다. 이러한 문제는 제작단계에서 차등감소태그에 원하는 감소 수치를 설정하여 해결한다.
Table 1는 절대음량 총 8바이트로 구성된 태그의 기존 구조이다.(Table 1의 윗부분: 바이트 순서) 맨 앞 3바이트 공간의 “DBS”표기는 이것이 절대음량의 태그임을 선언한다. 4번째 바이트는 절대음량산출 알고리즘 및 태그자체의 버전을 설명한다. 5번째 바이트는 해당 음원의 절대음량이 저장되는 공간이다. 만약 이 부분에 저장된 수치가 없거나 사용자가 갱신을 원한다면, 절대음량 산출을 거쳐 dB(S)산출 결과가 저장된다. 저장된 dB(S)값이 있을 경우 절대음량 산출 작업을 하지 않는다. 6번째 바이트는 의도한 차등 음량을 구현하기 위해 있는 절대음량 감소 영역이다. 만약 해당 음원의 절대음량을 다른 음원보다 ‘4 dB’감소 시켜서 출력하고 싶다면 Table 1과 같이 ‘4’가 입력된다. 이 부분은 악의적인 음량증폭을 근본적으로 차단하기 위해 무조건 음수로만 처리한다. 마지막 2개 바이트는 향후 기능 확장을 대비한 공간이다.
Table 1. Basic structure of absolute sound level tag. | |||||||
[1] | [2] | [3] | [4] | [5] | [6] | [7] | [8] |
D | B | S | 01 | 55 | 4 | 00 | 00 |
Tag recognition | Version | dB(S) | Differential decrease | Extension | |||
Table 2는 ‘핑크잡음 60 dB(S)=60 dB(A)’환경에서 태그내 차등감소가 입력된 음원이 실제 출력될 절대음량의 예시이다. 만약 제작자가 차등감소 태그에 “5”를 입력할 경우, 이것은 해당 음원이 음악 청취 환경의 음량에 비해 상대적으로 5 dB(S) 작게 출력시키기 위한 것이다.
이러한 차등감소수치와는 별개로, 청자가 목표 출력절대음량을 55 dB(S)로 설정할 경우, 청자가 의도한 목표 절대음량을 기준으로 제작자의 상대적인 차등감소 의도가 반영되어 최종적인 출력절대음량은 50 dB(S)가 된다. 하지만 제작자가 의도한 상대적인 차등음량 수치가 무엇인지는 청취자 입장에서 아무 의미가 없다. 따라서 청취자는 자신이 의도한 목표 출력절대음량만 알면 된다.
이처럼 절대음량태그의 차등감소 설정을 통해 청자는 제작자가 의도한 음량 균형에 맞춰 최종적으로 감상할 수 있다. 결국 음원 제작자는 현재 제작중인 음원의 진폭수준에 따라서 실제로 어떤 음량으로 출력될지 신경 쓸 필요 없이, 60 dB(S)를 기준으로 제작자가 원하는 차등감소 수치만 입력하면 된다. 절대음량 체계에서는 음원의 파형을 왜곡하여 억지로 음압을 올려도 결국 절대음량 기준 60 dB(S)에 맞춰지기 때문이다. 그러므로 제작자는 불필요한 파형 왜곡을 통해 억지로 음량을 올리거나, 반대로 0dBFS 영역을 낭비하면서 파형을 축소할 필요 없이 음원 자체의 작품성에만 집중할 수 있다.
IV. 출력절대음량의 개념 및 예시
Table 3은[13-15] 현재 출판된 서적들에 제시된 dB(A), dBSPL 레벨에 따른 음원, 환경간의 관계를 비교하기 위해 나열한 것으로, 음량의 대략적인 판단 기준으로 사용된다. dB(A)는 dBSPL에 청각특성을 고려한 주파수대역별 가중치를 적용한 단위로 현재 가장 광범위하게 사용된다.[16] 하지만 사람이 실제로 인지하는 음량을 제대로 반영하지 못할 뿐 아니라, 일반적인 상황보다 음량 기준이 다소 과장되어 있다.
dB(A)측정에서 가장 일반적으로 사용하는 ‘FAST’설정은 125 ms구간의 순간적인 평균에너지를 측정하며, ‘SLOW’설정은 1초 구간의 평균에너지를 측정한다. 이와 같이 순간적인 에너지평균 측정법으로는, 대부분 매우 동적인 에너지 변화를 가지는 소리의 음량을 제대로 표현할 수 없다. 그러므로 측정자는 그나마 직관적으로 제시할 수 있는 순간적인 최대치에 가장 큰 의미를 부여할 수밖에 없다.
하지만 순간적인 최대치는 환경과 상황에 따라 차이가 크고 실제로 느끼는 음량과도 연관성이 낮다. 뿐만 아니라, 이러한 결과는 측정자의 실수나 의도에 따라 쉽게 왜곡된다. 예를 들어 매미의 음량을 측정할 경우 바로 앞에서 측정한 값, 1 m에서 측정한 값과, 실제 집안에서 듣는 소리의 최대 순간 피크치는 에너지로 봤을 때 1000배(30 dB) 이상의 차이를 보일 수 있다. 실제 피해나 청취 상황을 대표하는 측정값은 집안에서 들리는 매미의 음압레벨이지만 사회적으로 이슈가 되는 것은 근접하여 측정한 기계적인 최대피크레벨이다.
지하철 소음이나 버스 소음의 경우도 측정기를 어디에 두냐에 따라 순간피크레벨의 차이는 극단적으로 변하며, 음악도 마찬가지이다. 이슈가 되는 음압레벨은 대부분 일반적이지 않은 상황을 대변하고 있으며, 전체적인 음압레벨의 기준자체가 다소 왜곡되는 결과를 만들었다.
예를 들어, Table 3에서 제시된 음악에 적절한 90 dB(A)로 동일하게 출력되는 핑크잡음, 혹은 백색잡음을 재생할 경우, 실험자 모두가 즉각적인 고통을 호소할 정도로 매우 큰 음량이다. 10 dB나 작은 80 dB(A)환경에서도 여전히 음악 청취 목적에 대입이 불가능한 수준의 매우 큰 음량이다.
다른 예로서, 100 dBSPL로 제시된 1 m거리 피아노 타건음의 경우, 어떤 건반을 얼마만큼의 강도로 타건했느냐에 따라서 수치가 크게 변하기 때문에 음량수준을 설명하는 예시로서 부적절하다. 이처럼 dBSPL이나 dB(A)으로 제시된 기준 음압레벨과 여러 예시들은 환경과 음원의 종류에 따라서 실제로 느끼는 음량과 현격한 차이가 있기 때문에, 효과적인 지표가 되지 못하며, 수치도 다소 과장되어 있다. 따라서 구체적인 권장 음량범위를 제시할 수 없으며, 보편타당한 수준의 음량의 측정/표현/출력이 모두 불가능하다.
Table 4는 절대음량체계에서 사용하는 출력절대음량 참고 기준으로, 청음실험에[9-10] 참여한 음량엔지니어들과 실험과정에서 느낀 음량 수준을 반영한 것이다. 개인이 처한 상황과 취향에 따라 선호하는 음량에 다소 차이는 있을 수 있으나, 대부분이 공감하는 음량의 범위는 분명히 존재한다.
음향엔지니어가 절대음량 태그의 차등감소값을 입력할 때 Table 4는 대략적인 참고기준이 될 수 있다. 만약 제작된 음원이 의미전달 목적의 다큐멘터리 내레이션 음원이라면, 적극적인 감상목적의 음악음량보다 상대적으로 작게 출력되어야 한다. 이럴 경우 제작자는 Table 4를 55 dB(S)를 참고하여 차등음량에 -’5’ dB(S) 수치만 입력하면 무난한 음량 밸런스가 구현된다. 물론 제작자의 의도에 따라서 차등감소 수치는 자유롭게 설정할 수 있다.
현재의 음량 제어 체계는 최종 출력단계까지 음량을 변경할 수 있는 주체가 너무 많아서 효과적인 음량 제어가 불가능하다. 이 체계의 특징은 음량 제어 주체의 일원화시켜 DAC 직전 혹은 직후 단계에서 음량을 제어한다. 청자 관점에서 봤을 때 절대음량 체계는 자신이 실제로 원하는 음량을 직관적으로 적용할 수 있는 환경이다.
Fig. 3의 순서도는 절대음량 체계가 적용된 환경을 가정하여, 청자가 목표한 출력절대음량이 어떠한 과정을 거쳐 출력되는지 나타낸다. 우선 사용자는 음원 출력 전에 자신의 청취 목적에 맞는 절대음량 수치를 시스템에 입력한다. 음원을 재생하면 시스템은 해당 음원의 절대음량 태그에 저장된 입력절대음량 dB(S)를 파악한 후, 60 dB(S)로 평준화 시킨다. 예를 들어 55 dB(S)에 해당하는 음원이면 기준음량 60 dB(S)에 맞춰서 5 dB를 증폭시키는 것이다.
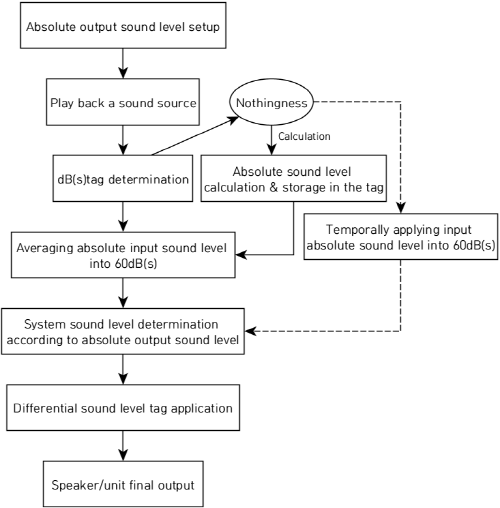
이후 미리 세팅된 설정에 따라서 목표한 출력이 결정된다. 만약 청취자가 최종적으로 듣고 싶은 출력절대음량이 65 dB(S)라면 시스템은 5 dB를 추가로 증폭시켜서 출력한다. 만약 차등음량 태그에 3 dB가 입력되어 있을 경우 설정된 수치만큼 감소시켜 출력한다.
결과적으로 청취자가 설정한 출력절대음량은 65 dB(S)이지만, 실제로 출력되는 음량은 62 dB(S)가 된다. 하지만 이 부분은 제작자의 의도에 따라서 음량 밸런스를 맞춘 것이므로 62 dB(S)라는 실제 출력음량은 알 필요가 없다. 또한 제작자가 의도한 음량 밸런스는 음원에 따라서 변하기 때문이다. 결국 모든 음원의 음량은 최초 청취자가 설정한 출력절대음량 65 dB를 기준으로 제작자의 차등음량이 적용되어 재생된다.
만약 절대음량 태그에 dB(S)가 저장되어 있지 않을 경우, 절대음량 산출 연산을 거친 후, 그 결과를 기반으로 위의 과정이 진행된다. 이때 입력절대음량 연산 및 적용에는 알고리즘의 버전과 음원의 길이, 프로세서의 처리속도에 따라서 최대 10초 이하의 딜레이가 발생할 수 있기 때문에, 입력절대음량을 60 dB(S)로 가정하여 임시로 선행 출력한다. 입력절대음량을 60 dB(S)로 가정하는 이유는, 디지털 음원의 dBFS영역에서 표현할 수 있는 사실상 최고 음량에 해당하므로 의도하지 않은 과도한 음압을 예방할 수 있기 때문이다.[17]
태그에 저장된 절대음량은 사용자가 특별히 갱신시키지 않는 이상, 영구적으로 저장되며, 향후 다시 출력될 경우 절대음량 연산을 거치지 않고 바로 적용된다. 만약 절대음량 산출 알고리즘의 버전이 업데이트 됐을 경우, 기존 태그에 저장되어 있는 입력절대음량 dB(S)수치를 임시적으로 선행 적용시킨 후 상위 버전의 알고리즘 연산을 거쳐, 절대음량 태그와 현재 출력중인 음량레벨을 갱신한다.
V. 결 론
현시점에서 제안한 절대음량 체계의 개념은 이상적인 음량제어 환경을 표방한다. 따라서 이러한 개념이 실제 상용 환경에 적용하기 위해서는 표준안을 비롯한 다양한 현실적인 문제 해결이 필요하며, 현재 관련된 후속연구들이 진행중이다.
절대음량 체계의 기대효과는 다음과 같다. 첫째, 음량 조절 환경의 근본적인 문제를 해결할 수 있다. 현재의 음량 조절은 청자가 실제 출력될 음량을 전혀 예측하지 못한 상태에서 시행착오를 거치면서 감으로만 음량을 조절한다. 또한 음원에 따라서 최적 음량으로 듣기 위해서는 지속적으로 음량을 수동으로 조절해야 한다. 절대음량체계는 dB(S)단위를 이용하여 모든 음원의 입력절대음량을 평준화시키므로, 출력절대음량을 통해 음원을 재생하기 전에 목표한 음량을 한 번에 설정할 수 있으며, 개별 음원에 따라서 음량을 수동으로 조절할 필요가 없다. 또한 절대음량은 범용성을 가지므로, 상대방에게 자신이 원하는 음량을 정확하게 제시할 수 있다. 만약 카페에서 들리는 음악 소리가 너무 크거나 작다면, 자신이 원하는 출력절대음량을 알려주는 것만으로 음량 조절에 대한 모든 설명이 끝난다.
둘째, 0 dBFS 영역의 활용도가 증가한다. 현재의 음량 체계에서 제작자가 의도적으로 작은 음량의 음원을 제작하고자 할 때, 진폭 자체를 감소시켜야 하므로, 필연적으로 dBFS 영역의 다이내믹레인지와 신호대잡음비의 손실을 초래한다. 절대음량 체계에서는 dBFS영역을 모두 활용하여 음원을 제작할 수 있으며, 기준음량 미만의 음량을 의도할 경우 절대음량 태그의 차등감소 설정을 적용하면 된다.
마지막으로, 음원을 왜곡시켜서 음량을 올리더라도 산출된 dB(S)값에 따라 최종 출력단에서 음량이 평준화 및 적정 음량 밸런스로 차등화 되므로 불필요한 음량 경쟁을 할 필요가 없다.
