

I. 서 론
II. BOW기반 음향 상황 인지
2.1 1st level 특징 추출: 주파수-캡스트럴 특징
2.1.1 주파수 특징 벡터(Frequency Feature Vector)
2.1.2 캡스트럴 특징 벡터(Cepstral Feature Vector)
2.2 코드북 생성
2.3 2nd level 특징 추출: 히스토그램 특징
2.4 Support Vector Machine (SVM)
III. 실 험
3.1. 실험 database
3.2. Baseline 1: MFCC-SVM 실험
3.3 Baseline 2: BOW 기반 음향 상황 인지
3.4 제안하는 방법
3.5 실험 결과 분석
3.5.1 MFCC-SVM
3.5.2 BOW 기반 음향 상황 인지
3.5.3 제안하는 방법
IV. 결 론
I. 서 론
음향 상황 인지(acoustic context awareness)는 다양한 음원이 발생하는 환경에서 현재 어떠한 장소에 있는지 혹은 어떠한 사건이 발생하였는지를 판단하는 기술이다. 사용자가 항상 소지하고 다니는 스마트폰에 상황 인지 알고리즘을 적용하면 사용자에게 여러 편의를 제공할 수 있다.[1]
음향 이벤트 검출 또는 인식에 기반하여 음향 상황을 인지를 수행하는 기존 연구에서 Mel Frequency Cepstral Coefficient(MFCC)와 Hidden Markov Model (HMM)을 사용하였다.[2-6] 또한 Linear Predictive Coding Cepstrum(LPCC)와 HMM을 사용하여 5가지 환경음을 인식한 연구도 발표되었다.[7] HMM이외에 Support Vector Machines(SVM)을 사용하여 음향 이벤트를 인식한 연구도 발표되었다.[8,9] 감시 시스템을 위한 비정상 상황 인지 기술에서는 MFCC와 음색특징을 사용하여, Hierarchical Gaussian Mixture Model(Hierarchical- GMM)로 인식을 수행했다.[10] 최근 음원 분리 기술을 적용하여 중첩된 이벤트가 발생하는 상황에서도 인식을 수행하고 있다.[11,12] 하지만 기존의 접근 방법으로는 동일한 이벤트가 발생하는 서로 다른 상황을 인지하기 어렵다.
본 논문에서는 동일한 이벤트가 발생하는 버스와 지하철 상황을 인지하기 위해 Bag of Words (BOW) 기반의 인식 알고리즘을 적용하였다. BOW 기반 인식 알고리즘은 코드북 기반의 히스토그램 특징을 이용하여 인식을 수행하기 때문에 동일한 이벤트가 발생하는 상황에서도 상황을 인식할 수 있다. 이때, 코드북의 표현력을 결정하는 코드북 크기와 코드북을 구성하는 특징에 관한 이슈가 있다.[13] 코드북이 각 상황의 대표적인 특징을 효과적으로 반영하도록 주파수-캡스트럴 특징을 제안하였고, 코드북 크기에 따라 상황 인지 실험을 수행하였다. 실험을 통해 제안하는 특징을 사용한 경우 동일한 이벤트가 발생하는 상황을 인지하는데 가장 높은 인식 성능을 확인하였다.
본 논문은 II장에서 BOW 기반 음향 상황 인지의 흐름도(flowchart)와 제안하는 특징을 설명하고, III장에서 기존의 방법들과 제안하는 방법을 이용한 실험에 대해 다루며, IV장에서 결론으로 구성되었다.
II. BOW기반 음향 상황 인지
이벤트 인식에 기반한 기존의 상황 인지 알고리즘은 잡음과 여러 이벤트가 중첩되어 발생되는 환경에서 이벤트 인식률을 보장하기 위해 잡음 제거 또는 음원 분리 알고리즘이 요구된다. 특히 버스와 지하철 상황은 승객들로 인해 말소리, 기침, 웃음소리, 비닐봉지 소리 등 공통된 이벤트들이 발생하기 때문에 두 상황을 인지하는데 어려움이 있다. 반면, BOW기반 알고리즘은 코드북과 유사도 비교를 통해 가장 유사한 요소로 대체되기 때문에 비교적 왜곡에 강인하다. 또한 유사한 이벤트가 발생하는 환경에서 일정 시간 동안 발생한 특징의 분포를 고려함으로써 문제를 해결할 수 있다.
이러한 BOW기반 상황 인지 알고리즘의 성능은 코드북의 크기와 이를 구성하는 특징에 따라 다르다.[13] 코드북의 크기가 크고 이를 구성하는 벡터가 음향적 특징을 효과적으로 반영할수록 다양한 경우를 포괄할 수 있어 높은 성능을 기대할 수 있다.
Fig. 1은 BOW기반 음향 상황 인지 알고리즘의 흐름도를 나타낸다. 블록은 인식 결과를 도출하는 주기를 뜻하고, 한 블록 안에는 여러 frame이 존재한다. 프레임마다 1st level 특징을 추출하고 사전에 훈련된 코드북과 비교하여 가장 유사한 index를 찾는다. 이 index의 분포로써 2nd level 특징을 추출한다. 인식 단계에서는 Support Vector Machine(SVM)을 이용하여 인식 결과를 도출한다.
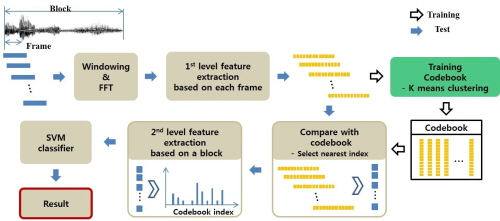
본 논문에서는 BOW기반 음향 상황 인지에서 코드북을 구성하는 1st level 특징 벡터로써 주파수-캡스트럴 특징을 제안한다.
2.1 1st level 특징 추출: 주파수-캡스트럴 특징
2.1.1 주파수 특징 벡터(Frequency Feature Vector)
음색 정보는 주로 음악의 장르를 인식하기 위한 특징으로 사용된다.[15] 음색은 주파수에 따른 에너지 분포와 밀접한 관계가 있기 때문에 음향 특징을 반영하기 위해 사용할 수 있다. 최근 비정상 상황인지를 위한 논문 중에도 음색 정보를 사용하여 신뢰할만한 성능을 보이고 있다.[10,14]
Table 1에 논문에서 사용한 음색 특징을 정리했다. 본 논문에서는 frame 에너지 E, frame 에너지 변화량 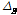 , 에너지의 실효값을 의미하는 volume V지표를 위 음색 특징과 함께 사용했으며, 수식은 각각 다음 Eqs.(1)~(3)과 같다.
, 에너지의 실효값을 의미하는 volume V지표를 위 음색 특징과 함께 사용했으며, 수식은 각각 다음 Eqs.(1)~(3)과 같다.
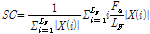
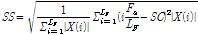
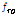 )[10]
)[10]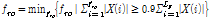
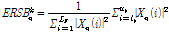
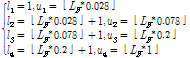
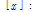 the largest integer not greater than x
the largest integer not greater than x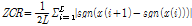
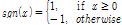
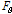 : sampling rate,
: sampling rate, 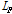 : maximum FFT bin, L: frame length,
: maximum FFT bin, L: frame length,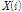 : i-th magnitude of a frame in frequency domain,
: i-th magnitude of a frame in frequency domain, 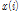 : i-th amplitude of a frame in time domain.
: i-th amplitude of a frame in time domain. 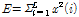 .
.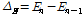 .
.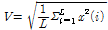 .
.위 Eq.(2)에서 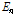 은 n번째 frame에서 에너지를 뜻한다.
은 n번째 frame에서 에너지를 뜻한다.
2.1.2 캡스트럴 특징 벡터(Cepstral Feature Vector)
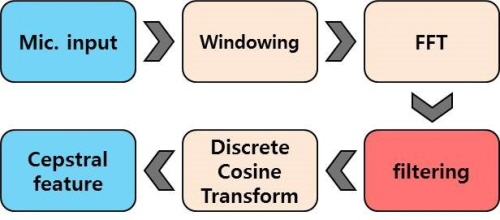
캡스트럴 특징을 사용하면 스펙트럼(spectrum)의 포락선(envelope)을 반영할 수 있다. Fig. 2는 논문에서 제안하는 캡스트럴 특징 추출 과정을 나타내며 필터링(filtering) 단계를 제외하고 MFCC를 추출하는 과정과 동일하다. 본 논문에서는 필터링과정에서 버스와 지하철 상황에서 에너지 분포가 유사한 대역에서 높은 분해능을 갖는 필터뱅크(filterbank)를 사용했다. 따라서 에너지 분포가 유사한 대역에서 스펙트럼의 포락선 차이를 효과적으로 반영할 수 있다. 필터뱅크의 분해능은 각 필터의 중심 주파수의 위치에 따라 다르다. 본 논문에서는 Eq.(4)를 이용하여 필터뱅크의 중심주파수를 설계했다.
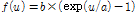 .
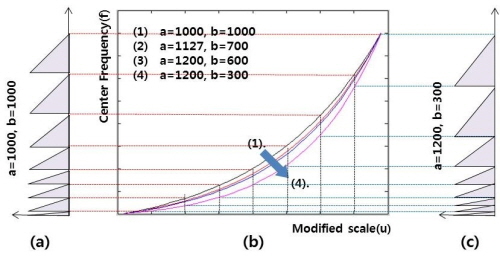
.Eq.(4)에서 u는 필터뱅크의 index를 뜻하며, f(u)는 u번째 필터의 중심 주파수를 뜻한다. a와 b는 상수 값으로 이를 조절함으로써 f(u)를 조절할 수 있다. Fig. 3은 a, b 두 상수에 따라 설계된 필터뱅크를 보여준다.
필터뱅크의 중심주파수가 밀집된 대역에서 스펙트럼의 포락선이 효과적으로 반영됨으로써 높은 분해능을 갖게 된다. 버스와 지하철에서 공통으로 발생하는 이벤트들은 사람 말소리(babble), 휴대전화 벨소리, 안내방송 등이 있다. 이러한 이벤트들은 공통적으로 약 2 kHz 이상의 주파수 대역에서 에너지가 분포하기 때문에 해당 대역의 분해능을 낮추어 유사한 이벤트로 발생하는 오류를 줄일 수 있다. 본 논문에서는 필터뱅크에서 두 변수 a, b에 따라 총 38개의 필터를 사용하였으며, HTK[16]를 이용하여 추출한 MFCC와 성능 비교를 위해 Fig. 3과 같이 삼각모양의 필터를 사용하였다.
2.2 코드북 생성
코드북 생성에는 훈련데이터로 부터 frame 기반의 1st level특징이 사용된다. 훈련데이터는 각 frame에서 주파수-캡스트럴 특징을 추출한 뒤 K-means 군집화를 통해 K개의 군집으로 분할된다. 이때, 각 군집의 평균 벡터들을 이용하여 코드북을 구성한다. K는 코드북의 크기를 결정하는 동시에 2nd level 특징의 차원이 된다. K가 클수록 상황을 대표하는 특징 벡터의 수가 증가하여 코드북의 표현력이 향상되지만 인식에 사용되는 특징벡터의 차원은 증가한다.
2.3 2nd level 특징 추출: 히스토그램 특징
인식에 사용할 특징 벡터로 일정기간(블록) 동안 발생한 1st level특징의 분포를 사용한다. 앞서 추출된 frame 기반의 주파수-캡스트럴 특징은 코드북과 유클리디안 거리를 사용하여 가장 유사한 코드북의 index로 변환된다. 블록 내 모든 frame에 대해서 코드북의 index로 변환한 뒤 index에 대한 히스토그램으로 나타낼 수 있다. BOW를 이용하면 훈련에 사용되지 않은 입력벡터라도 코드북에서 가장 유사한 특징으로 대체되기 때문에 다양한 이벤트가 발생하는 상황도 적은 훈련 데이터를 사용하여 인식할 수 있다.
2.4 Support Vector Machine (SVM)
본 논문에서는 특징벡터 차원(코드북 군집 수)이 크고 대부분 0의 요소를 갖기 때문에(블록 내 frame 수 << 코드북 군집 수) SVM을 이용한 방법이 인식에 효율적이다. SVM은 커널 함수에 따라 성능이 달라질 수 있기 때문에, 본 논문에서는 네 가지 커널함수를 사용하여 성능을 비교 측정하였다.
III. 실 험
3.1 실험 database
본 논문에서는 유사한 환경음 속에 동일한 음향 이벤트가 발생하는 상황을 인식하기 위해 버스와 지하철 상황을 선정 하였다. Table 2는 실험에 사용된 DB의 분량을 보여준다. 실험 database는 녹음기를 이용하여 서울 시내 일반버스(Normal)와 저상버스(Low), 그리고 서울 지하철(1호선 ~ 9호선과 분당선, 공항철도)에서 수집하였다. 녹음 데이터는 실험을 위해 16 kHz, Mono, 16 bits resolution으로 변환하였다.
코드북 생성과 SVM 훈련을 위한 데이터는 버스와 지하철의 주행 잡음 구간으로 약 2,000 s 분량을 구축하였다. 테스트 데이터는 한 블록 단위(4 s)로 분할하여 총 15,448개의 database를 구축 하였다. 테스트 데이터는 실제 상황과 동일하게 대화소리, 기침 등 승객들로 인해 발생할 수 있는 이벤트들과 라디오, 안내방송, 버스 경적음, 버스카드부저음, 버스 하차벨음, 버스 또는 지하철 주행음 등 다양한 이벤트들이 포함되어 있다.
3.2 Baseline 1: MFCC-SVM 실험
첫 번째 baseline은 BOW를 적용하지 않고 MFCC를 이용한 성능이다. Frame 길이는 32 ms, 50 % 중첩하여 MFCC 특징 벡터를 추출하였다. 이때 특징 벡터는 11 차원의 MFCC와 Delta특징으로 총 22차원 벡터를 사용했다. SVM 훈련에서 사용된 커널함수는 선형(linear) 커널, 2차형(quadratic) 커널, Gaussian Radial Basis Function(GRBF), Multilayer Perceptron Kernel(MLP)로 4개의 커널 함수를 적용했다.
3.3 Baseline 2: BOW 기반 음향 상황 인지
참고문헌 14 논문에서는 코드북 구성을 위해 SC, SS, roll-off, ERSB, ZCR, E, V의 주파수 특징을 사용하였다. 실험은 코드북 크기에 따라 128, 256, 512 총 세 가지 경우에 대해서 진행했으며, 인식을 위한 SVM은 MFCC- SVM 실험과 동일한 커널 함수에서 성능을 각각 측정했다.
3.4 제안하는 방법
BOW를 위해 주파수-캡스트럴 특징을 이용하여 코드북을 구성했다. 캡스트럴 특징은 22차원 벡터를 사용했고, 두 번째 baseline과 동일하게 코드북의 크기에 따라 실험을 진행했다. 두 baseline 실험 결과와 제안하는 방법의 실험 결과를 Table 3에 정리했다.
3.5 실험 결과 분석
본 실험에서는 코드북 크기, 필터뱅크 매개변수(parameter), SVM 커널함수에 따른 인식 실험을 진행하였다. BOW 기반 음향 상황인지 알고리즘에서 코드북 크기가 클수록 다양한 음향 상황을 표현할 수 있어 높은 성능을 확인할 수 있다. 제안하는 방법을 적용한 실험에서 코드북 크기가 동일하더라도 코드북을 구성하는 특징 벡터에 따라 성능이 달라짐을 확인할 수 있다. 2 kHz 보다 낮은 주파수 대역에 높은 분해능을 갖는 필터뱅크를 사용한 경우(a = 1127, b = 700 또는 a = 1000, b = 1000)에 유사한 성능을 확인할 수 있으며, 2 kHz보다 높은 주파수 대역에 높은 분해능을 갖는 경우(a = 1200, b = 600 또는 a = 1200, b = 300)보다 높은 성능을 보임을 확인할 수 있다.
3.5.1 MFCC-SVM
Table 3에서 MFCC 특징벡터를 사용한 경우, MLP 커널을 사용했을 때 인식률이 가장 높다. 훈련 데이터가 주행 잡음으로만 구성되어 있기 때문에 다양한 이벤트가 복합적으로 발생하는 상황에서 오인식이 많이 발생했다. 만일 훈련 데이터에 복합적인 상황의 데이터가 포함되었다면 인식률이 더 상승할 것이다. 하지만 그 만큼 많은 훈련 데이터가 필요하다.
3.5.2 BOW 기반 음향 상황 인지
이번 경우에는 2차형 커널에서 인식률이 가장 높다. 14에선 이벤트가 중첩된 상황이 아닌 단독으로 발생하므로 주파수 특징만으로 인식 대상을 표현할 수 있지만, 다양한 이벤트가 발생하는 버스 또는 지하철 상황을 표현하기에는 부족하다. 하지만 BOW 접근법을 적용하여 다양한 상황에 대응할 수 있어 기존의 MFCC보다 높은 성능을 보이고 있다.
3.5.3 제안하는 방법
코드북을 구성하는 벡터가 각 음향 상황을 효과적으로 표현하고 있기 때문에 상황인지를 위한 히스토그램 특징이 버스와 지하철에 따라 차별적으로 추출된다. 실험 결과에서도 대부분 1차 선형 커널 함수를 사용한 경우에 가장 높은 인식률을 확인할 수 있다.
Table 3의 결과들을 바탕으로, 주파수-캡스트럴 특징이 공통으로 발생하는 이벤트의 영향을 줄이고 복합적인 상황을 더욱 자세히 반영할 수 있기 때문에 BOW기반 음향 상황 인지를 위한 특징벡터로 적합하다고 할 수 있다.
IV. 결 론
기존 음향 상황 인지를 위한 알고리즘은 이벤트가 중첩되거나 유사한 이벤트가 발생하는 상황에서는 어려움이 있다. 이러한 문제점을 해결하기 위해 본 논문에서는 주파수-캡스트럴 특징 기반의 BOW 접근법을 사용하였다. 본 논문에서 제안하는 특징은 주파수에 따른 에너지 분포와 스펙트럼의 포락선을 반영하고 있으며 동시에 본 논문에서 사용한 캡스트럴 특징은 에너지 분포가 유사한 대역에서 높은 분해능을 갖는 필터뱅크를 사용함으로써 포락선을 효과적으로 반영할 수 있다. SVM을 이용한 비교 실험을 통해 제안한 방법을 적용한 경우 기존 방법들보다 높은 성능을 확인하였다.
