I. 서 론
II. 기존 암묵음원분리 방법
2.1 문제 정의
2.2 암묵음원분리에서 rank-1 공간 모델
2.3 잔향을 고려한 이상적인 공간 모델에 기반한 암묵음원분리
2.4 공분산 행렬의 공동 행렬대각화 조건
2.5 인접 채널 및 인접 시간에 대한 역상관화(decorrelation)를 이용한 암묵음원분리 및 잔향제거
III. 제안 방법
3.1 대각화 행렬분해
3.2 온라인에서의 최적화
IV. 실 험
4.1 평가 지표
4.2 실험 환경
4.3 실험 결과
V. 결 론
I. 서 론
암묵음원분리(Blind Source Separation, BSS)란 음원의 혼합과정에 대한 사전 정보 없이 동시 다발적으로 발생, 혼합된 음원 신호를 분리하는 것이다. 주파수 영역에서 혼합된 신호를 분리하는 대표적인 기술들로는 주파수영역 독립성분분석(Frequency-Domain Independent Component Analysis, FDICA),[1] 독립벡터분석(Independent Vector Analysis, IVA),[2] 보조함수를 통해 안정성과 필터의 빠른 학습을 적용한 독립벡터분석(auxiliary-function-based IVA, AuxIVA),[3,4] 음원 신호의 분산에 대하여 비음수행렬분해(Nonnegative Matrix Factorization, NMF)를 적용한 Independent Lowrank Matrix Analysis(ILRMA)[5]들이 있다. 이런 전통적인 암묵음원분리 방법은 국소푸리에변환(Short- Time Fourier Transform, STFT)의 프레임 길이가 잔향 시간보다 충분히 긴 경우에만 성능 저하가 없다는 단점이 있다. 이러한 단점은 weighted prediction error[6,7]와 같은 잔향제거 방법을 통해 프레임 길이보다 긴 잔향 성분을 제거하여 해결할 수 있다. 특히, 최근에는 오프라인 과정에서 암묵음원분리와 잔향제거를 함께 진행하는 방법[8]도 연구되고 있다. 또한, 공분산 행렬에 대하여 공동 행렬대각화 조건을 적용하여 음원 신호의 인접 채널, 주파수, 프레임에 대한 상관도를 고려한 암묵음원분리[9,10]와 공분산 행렬을 full-rank로 추정하는 암묵음원분리[11]에 대한 연구가 있다. 하지만 실제 상황에 대하여 고려한다면 화자가 발화하는 중에 움직이는 상황 뿐 만 아니라, 보청기와 같은 장비는 온라인 동작을 요구한다. 기존 온라인 방식의 암묵음원분리[12,13,14]와 잔향제거[15]를 적용한 연구가 있다. 본 논문은 오프라인에서 공동 대각화 조건 기반 및 행렬 분해를 통해 암묵음원분리 및 잔향제거 알고리즘 제안과 더 나아가 온라인 방식의 알고리즘을 제안한다.
II. 기존 암묵음원분리 방법
여기서는 전통적인 암묵음원분리로서 rank-1의 공간 모델로 가정한 접근과 잔향을 고려한 이상적인 공간 모델에 대한 접근에 대하여 살펴본다.
2.1 문제 정의
N개의 음원 신호가 혼합된 M개의 다채널 마이크입력 신호에 대한 국소푸리에변환 영역에서 각각의 시간 프레임 t 와 주파수 인덱스 f 에서의 마이크 입력 신호는
와 같이 표현된다.[1] 여기서 와 는 마이크와 음원의 신호에 대한 벡터이며, 는 전치행렬을 의미한다. 는 음원에서 마이크까지의 선형시불변 특성을 갖는 전달함수이며, 은 해당 필터의 길이를 의미한다. 이 때, N개의 음원 신호를 역으로 추정하기 위한 선형 분리과정[16]은
와 같이 표현된다.은 분리 행렬이며, 은 잔향제거 행렬이다. 은 각각 벽에 의해 반사되어 마이크에 도달하는 초기반사음 시간과 잔향 길이를 나타낸다.
2.2 암묵음원분리에서 rank-1 공간 모델
마이크 입력신호 는 N개의 음원 공간 이미지들 의 합으로 구성된다.
각각의 음원 신호 는 복소정규분포를 따른다고 가정하여
로 표현할 수 있다. 은 n번째 음원 신호에 대한 파워 스펙트럼의 분산을 나타낸다. 만약 음원 신호가 점 음원이면, 혼합 모델 는 다음과 같이 rank-1인 특성을 갖게 된다. 즉, 음원 공간 이미지 은
으로 표현되며 은 의 n번째 열벡터에 해당한다. 음원 의 확률 분포는
로 표현된다. 은 rank-1을 갖는 n번째 음원 신호의 공간분산행렬이며, 은 공분산 행렬, 은 켤레 전치행렬이다. Eqs. (3), (6)과 가우시안 분포의 특징을 통해 마이크 입력 신호의 확률 분포는
으로 표현된다. Table 1을 통해 주요 변수들에 대한 설명을 정리하였다.
Table 1.
Glossary and definition of variables.
2.3 잔향을 고려한 이상적인 공간 모델에 기반한 암묵음원분리
음원의 공간 이미지에는 마이크 채널간의 상관관계를 갖고 있기 때문에 공간에 대한 정보를 얻을 수 있고, 혼합된 신호로부터 음원을 분리할 수 있다. 하지만 실제 환경에서는 잔향 성분에 의해 공간에 대한 모델이 복잡해진다. 국소푸리에변환을 위한 윈도우의 길이가 음원과 마이크 간에 주파수 응답보다 충분히 길면 잔향에 의한 영향이 줄어들지만 실제 환경에서는 보통 이 가정이 적절하지 않기 때문에 국소푸리에변환을 통해 완벽하게 인접 시간 프레임간의 상관관계를 제거하지 못한다. 본 논문에서는 수식의 단순화를 위해 아래와 같은 표기법을 정의한다.
음원 신호들은 독립적인 특성[2]을 갖기 때문에
의 식을 만족한다. 이 때 각각의 음원 공간 이미지 는 평균이 0이고, 공분산 행렬 을 갖는다. 변량 복소정규분포를 따른다고 가정하면
와 같이 표현된다. 이때, 는 K×K 크기를 갖는 에르미트 양의 준정부호행렬이다. Eqs (3), (12) ~ (13)과 정규분포의 특성을 통해
을 갖는다.
결론적으로, 이 추정된다면, 음원의 공간 이미지는 다채널 Wiener 필터를 통해
와 같이 각각의 음원 공간이미지를 추정한다. 하지만 공분산 행렬의 차원은 N(FTM)으로 상당히 많은 수의 매개변수를 최적화하는 문제점이 존재한다.
2.4 공분산 행렬의 공동 행렬대각화 조건
공분산 행렬의 차원을 줄이기 위하여 N개의 공분산 행렬을 공동으로 대각화하는 방법[9,10,11을 적용하여 나타내면
와 같다. 이때 은 정칙행렬이며, 은 비음수 벡터이다. Eqs. (14)과 (16)로부터
이고, 공분산에 대한 비대각성분들이 0이 되어 의 요소들이 상관관계가 없는 독립적특성을 갖는다. 따라서 를 각각의 음원 신호로 간주할 수 있으며, 공동 행렬대각화 방법으로 인해 의 매개변수 수는 N(FTM)2개에서 (FTM)2 + FTM으로 줄어들게 된다. P와 의 추정을 위한 마이크 입력 신호의 스펙트럼에 대한 음의 우도비용 함수는 다음과 같다.
Eq. (18)의 비용함수가 최소가 될 때, P와 을 추정해 공분산 행렬을 구할 수 있다.
2.5 인접 채널 및 인접 시간에 대한 역상관화(decorrelation)를 이용한 암묵음원분리 및 잔향제거
주파수영역 독립성분분석,[1] 독립벡터분석,[2,3,4] ILRMA[5]는 마이크 입력 신호와 음원 신호의 수가 같은 상황에서 잘 작동하는 대표적인 암묵음원분리 방법이다. 또한 마이크 입력 신호의 잔향성분을 제거하기 위한 여러 효과적인 잔향제거 알고리즘 기술들도 존재한다.[6,7] 음원 스펙트럼의 인접 채널 및 인접시간에 대한 역상관 모듈 통합 방법[9,10,11]으로 잔향을 제거함과 동시에 음원 분리를 수행할 수 있다. 인접 채널 및 시간프레임을 고려하여 식(16)의 정칙행렬 P를 각 주파수에 대하여 개의 M×M의 차원을 갖는 블록으로 구성된 블록 상 Toeplitz 행렬 로 정의하고, 행렬의 ()번째 블록은
와 같이 정의한다. 이때 은 의 영행렬이다. 따라서 정칙행렬 P는 아래 Eq. (20)과 같이 표현된다.
이때, 은 행렬의 블록 대각행렬이다. Eq. (20)을 통해 Eq. (16)은
와 같이 표현된다. Eqs. (18)과 (21)로 대각화기 를 최적화하는 비용함수는 다음과 같다.[9]
공동 대각화 은 , 는 이며, 은 m 번째 항이 1인 단위벡터이다.
III. 제안 방법
공동 행렬대각화 조건을 사용한 기존 방법에서는 인접 채널 및 인접 시간의 상관도를 없애는 하나의 필터 를 제안하였다. 하지만 매 시간 프레임마다 필터를 추정하기에는 필터의 차원이 다소 크기 때문에 암묵음원분리 및 잔향제거 된 신호를 추정하는 것이 불안정하다. 따라서 하나의 필터를 추정하는 것보다 행렬분해를 적용하여 잔향제거와 음원분리의 필터로 분해하는 방법을 제안하고 온라인 알고리즘 구현을 제안한다.
3.1 대각화 행렬분해
식(22)의 공동 대각화 행렬을 와 로 분리하여 표현하면,
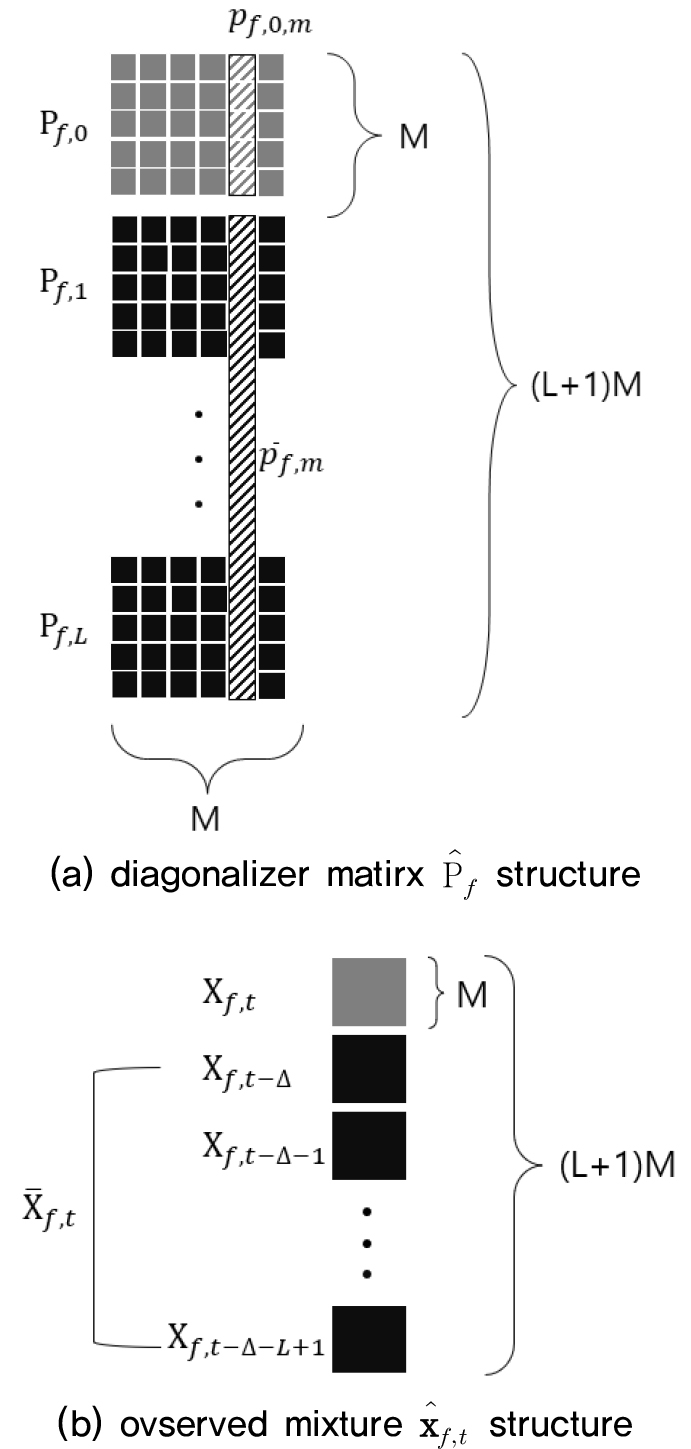
와 같이 표현되며, 은 각각 와 의 m번째의 열벡터이다. 공동 대각화 행렬에 대한 구조는 Fig. 1(a)와 같다.
m번째 열벡터에 대하여 행렬분해를 진행하면
로 은 단위행렬로 표현된다. 이 때, Eq. (23)를 통해 아래와 같이 표현된다.
의 필터는 단일 음원신호에 대한 잔향 제거 필터다. 각 마이크 채널별 잔향 제거된 출력은 은 이전 시간 프레임에 대한 입력신호이며 자세한 구조는 Fig. 1(b)와 같다. 는 분리행렬 의 m번째 열벡터이다. Eqs. (22)와 (26)을 통해 최적화 함수는
과 같다. 음원 분리행렬 를 업데이트 하는 수식은 보조함수를 이용한 기존 방법[3,4]과 같다. 이 방식은 기존의 경사하강법의 방식[17]보다 안정적이고 빠르게 수렴한다.
여기서 은 아래 Eq. (30)이다.
선형 예측 필터 를 업데이트하는 수식은 Eq. (27)를 로 편미분하여 구할 수 있다.
Eq. (31)를 통해 선형 예측 필터 는 다음과 같다.
3.2 온라인에서의 최적화
앞서 설명한 오프라인의 방식인 batch processing 알고리즘은 프레임 전반에 걸쳐 얻어진 입력 신호를 통해 필터를 추정한다. 하지만 이러한 시스템은 실제 환경에서와 같이 화자의 위치가 고정되지 않고 발화하는 비정상 음원에 대해서는 채널 간 및 프레임 간의 상관관계가 변하기 때문에 잔향 제거 및 암묵음원분리 성능이 저하된다. 또한 보청기와 같은 음원향상 장치에서는 온라인 동작을 요구한다는 점이다. 이러한 점을 고려하여 앞서 제안한 오프라인 방식 대신에 매 프레임마다 필터를 업데이트하며 분리된 음원을 출력하는 온라인 방식의 알고리즘을 제안한다.
온라인 암묵음원분리를 위해 재귀최소자승법(Recursive Least Squares, RLS)[12,13,14]을 사용하여, 현재 시간 프레임의 을 이전 시간 프레임의 을 통해 재귀적으로 계산한다. 따라서 Eq. (30)의 는
와 같이 계산되고, 는 망각인자로 과거 신호에 대한 비중을 조절하는 요소이다. 또한, Eq. (28)의 역행렬 연산은 연산비용이 크기 때문에 실시간 동작에서 적합하지 않다. 이를 해결하기 위해 아래 식의 matrix inversion lemma[18]를 이용한다.
이 때,
와 같이 역행렬 행렬을 설정하면 Eq. (36)를 사용하여 유도하면 각각의 역행렬들은 이전 시간 프레임에 대해
와 같이 매 프레임마다 추정된다. 은 의 m번째 열벡터 의 업데이트 전과 후의 차이를 나타내며 아래와 같이 반영된다.
다음으로 온라인 잔향제거[15]의 경우에는 이전과 같은 방식으로 Eq. (32)의 LM×LM의 차원을 갖는 의 역행렬 연산이 음원 분리보다 더 큰 연산비용을 갖게 된다. 마찬가지로 재귀최소자승법의 방식을 적용하여 다음과 같이 나타낼 수 있다.
또한, matrix inversion lemma를 통해 을
와 같이 매 프레임마다 추정할 수 있다. 온라인 알고리즘에서 잔향제거 부분에서의 는 전 시간 프레임을 통해 업데이트된 필터를 통해 다음과 같이 추정할 수 있다.
이 때, 는 음원 신호가 정규분포를 따른다고 가정하여 다음과 같이 계산할 수 있다.
IV. 실 험
4.1 평가 지표
첫 번째 지표는 신호 대 왜곡 비(Signal-to-Distortion Ratio, SDR)[19]이다. 즉, 마이크에 들어온 입력 신호를 암묵음원분리를 통해 얻은 해당 음원 clean 신호 와 해당 음원 출력신호 의 power 비로 아래의 식과 같다.
두 번째 지표는 Perceptual Evaluation of Speech Quality (PESQ)[20]이다. 이 지표는 해당 음원 신호와 암묵음분리를 통한 해당 신호 간의 유사도를 인지적 특성을 반영하여 측정하는 방식이다. PESQ는 주관적 음질 평가 방법을 대체할 수 있는 객관적 음질평가로 만점인 4.5점에 가까울수록 사람들은 음질이 높다고 느낀다.
4.2 실험 환경
본 실험은 WSJCAM0 데이터베이스[21]를 기반으로 음원 신호를 구성했고, 잔향이 존재하는 입력신호는 음원으로부터 마이크 위치까지의 임펄스 응답을 image method[22]에 따라 음원 신호에 합성 곱하여 혼합입력 신호를 생성하였다. 이때, 음원신호와 마이크는 각각 2개, 6개로 구성하고, 혼합하는 음원들은 서로 중복되지 않고, 임의로 선택하였다. 구체적인 실험 환경은 Fig. 2와 같다.
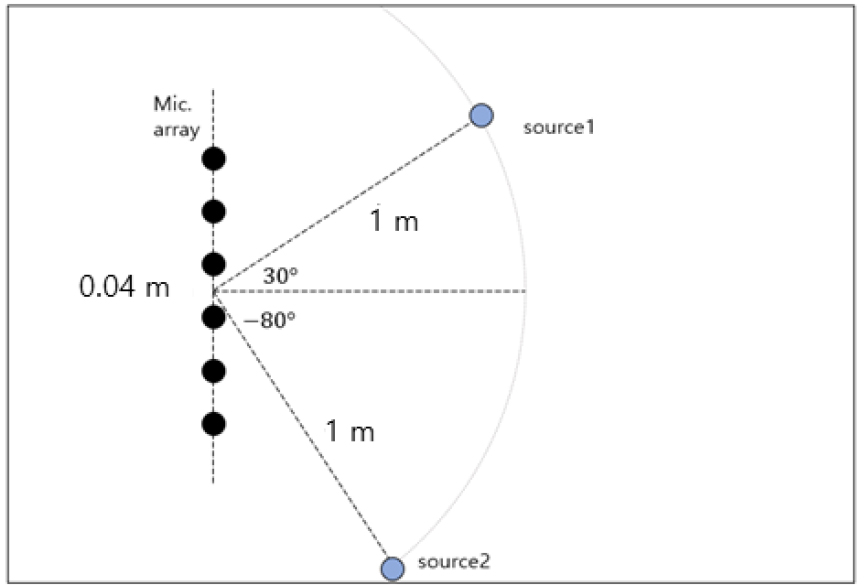
마이크 어레이는 0.04 m 간격으로 일렬로 위치시켰다. 마이크 어레이의 중심은 [2.5 m, 2.5 m, 1 m]에 존재하고, 음원의 거리는 1 m이고, 음원의 각도는 중심선을 기준으로 30°, -80°를 이룬다. 방의 크기는 5 m × 4 m × 3 m이다. 이때, 잔향 시간(RT60)은 잔향시간이 작은 0.2 s부터 잔향시간이 큰 1 s로 0.2 s 간격으로 설정했다. 그리고 각 음원과 마이크 위치 사이의 임펄스 응답을 합성 곱하며 잔향 별로 동일한 음원 데이터를 생성하였다. 마이크 입력신호의 샘플링 주파수는 16 kHz이며, 국소푸리에변환에서 Hanning 윈도우 및 윈도우 프레임 길이와 프레임 간 간격은 각각 64 ms, 16 ms로 설정하였다. 필터 및 매개변수의 초기 값에 대해서는 와는 는 및 매개변수 {}는 {0.98, 0.99}로 설정하였다.
4.3 실험 결과
본 실험은 기존 온라인 IVA[13]와 제안 알고리즘을 두 가지 지표를 통해 비교하였다. 두 방법 모두 암묵음원분리에서 사용되는 음원 파워 스펙트럼 밀도 의 값은 정규분포를 따른다는 가정으로 동일하게 설정하였다.
잔향 환경에서 초기 반사는 음성인식에 있어서 사람의 명료도를 향상시키고,[23] 음성인식(ASR) 성능을 향상시킨다.[24] 따라서 초기 반사음 및 잔향 시간 {}의 값을 고려하여 잔향 시간이 짧은 0.2 s부터 비교적 긴 1 s의 실험 환경에서 SDR과 PESQ의 평균 값 성능을 평가한다.
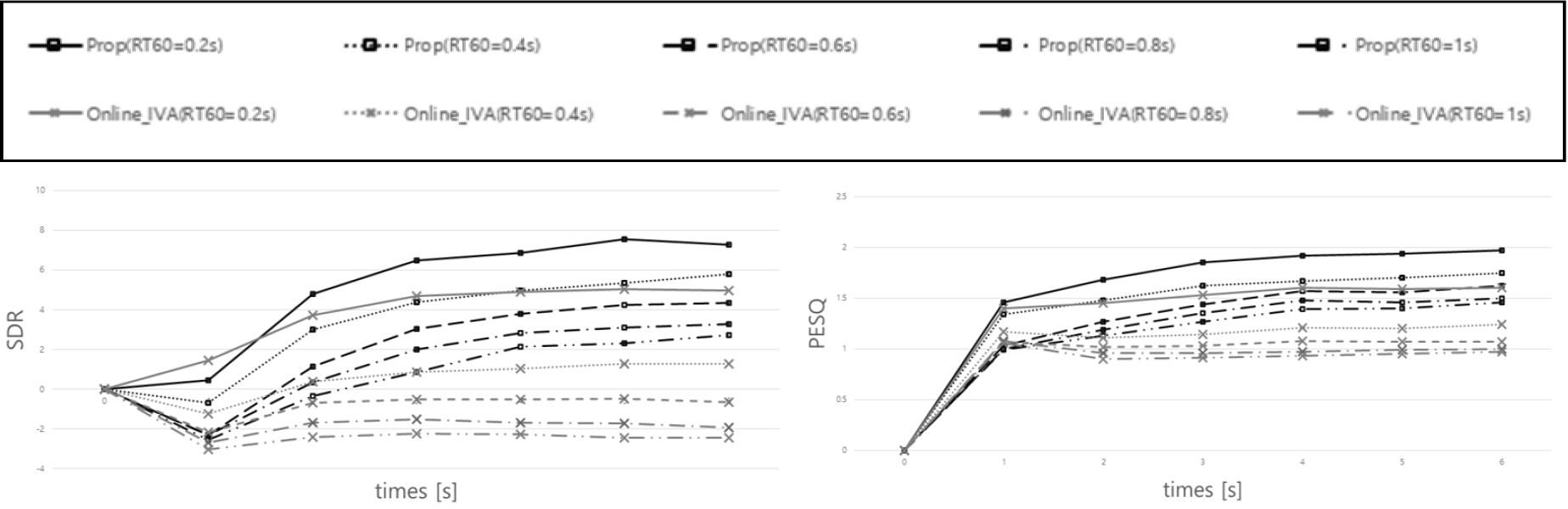
위의 Table 2은 실험을 통해 가장 높은 성능을 나타내는 초기반사음과 잔향길이를 고려한 실험 결과이다. 기존 온라인 IVA보다 제안한 방법의 성능이 모두 높은 것을 확인 할 수 있다. Fig. 3은 초기 반사음 및 잔향시간에 따른 성능 추이 그래프이다. 첫 번째로 초기 반사음에 따른 성능 추이를 살펴보면, 초기 반사음의 길이를 =1로 설정할 경우 가장 높은 성능을 나타내는 것을 확인할 수 있다. 또한 초기 반사음의 길이가 길수록 분리 성능이 낮아지는 것을 확인할 수 있다. 이러한 점은 초기 반사음을 길게 설정할 경우 반사되어 돌아오는 잔향신호 성분이 남아있기 때문에 성능이 낮아지게 된다. 두 번째로 잔향시간에 따른 성능 추이를 살펴보면, 잔향이 커짐에 따라 최적의 필터 길이가 길어짐을 알 수 있다. 즉 잔향에 영향이 클수록 고려해야하는 이전 시간의 입력 또한 길어진다는 것이다.
Table 2.
Source separation performance in terms of SDR, PESQ according to reverberation time.
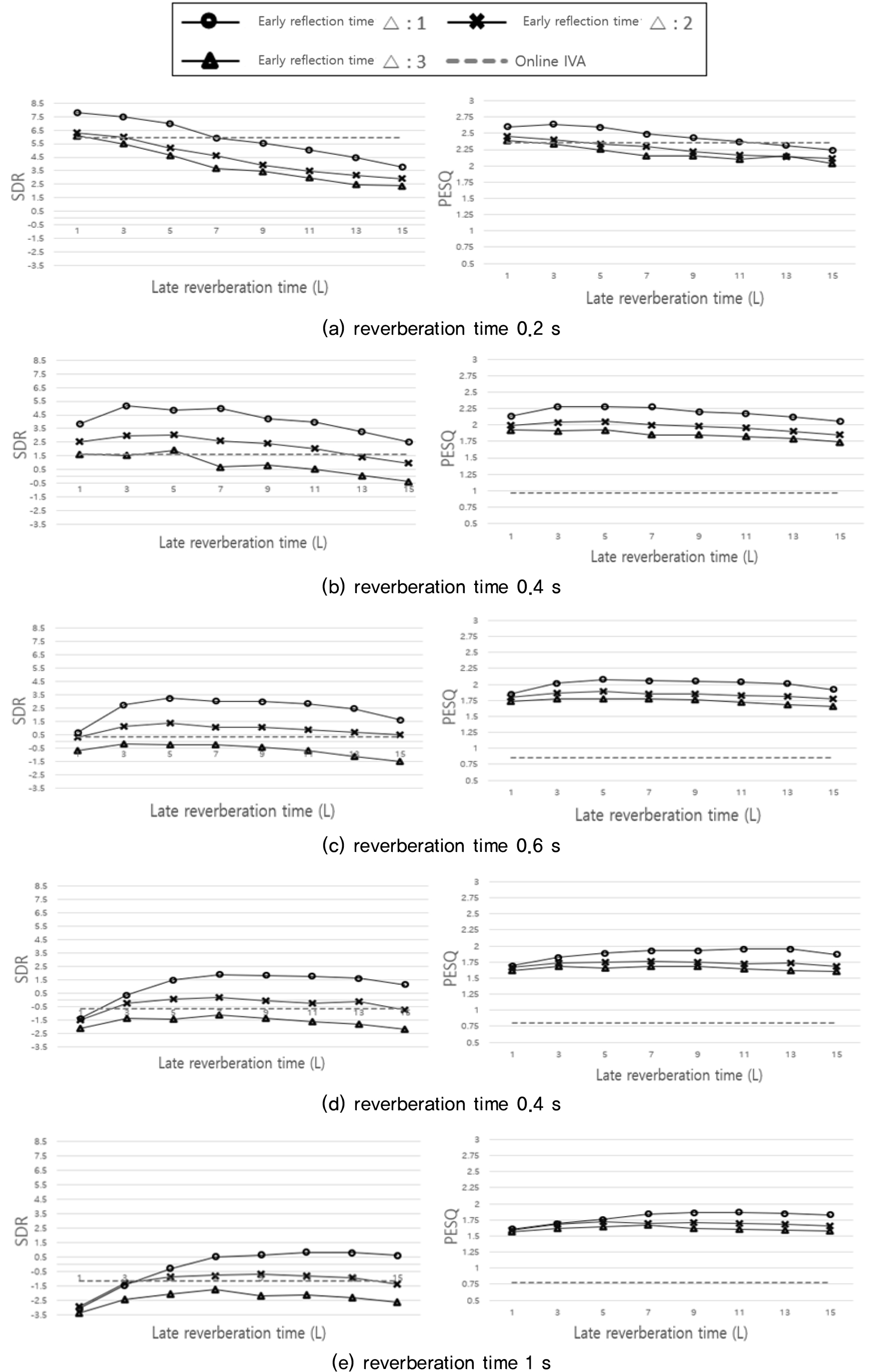
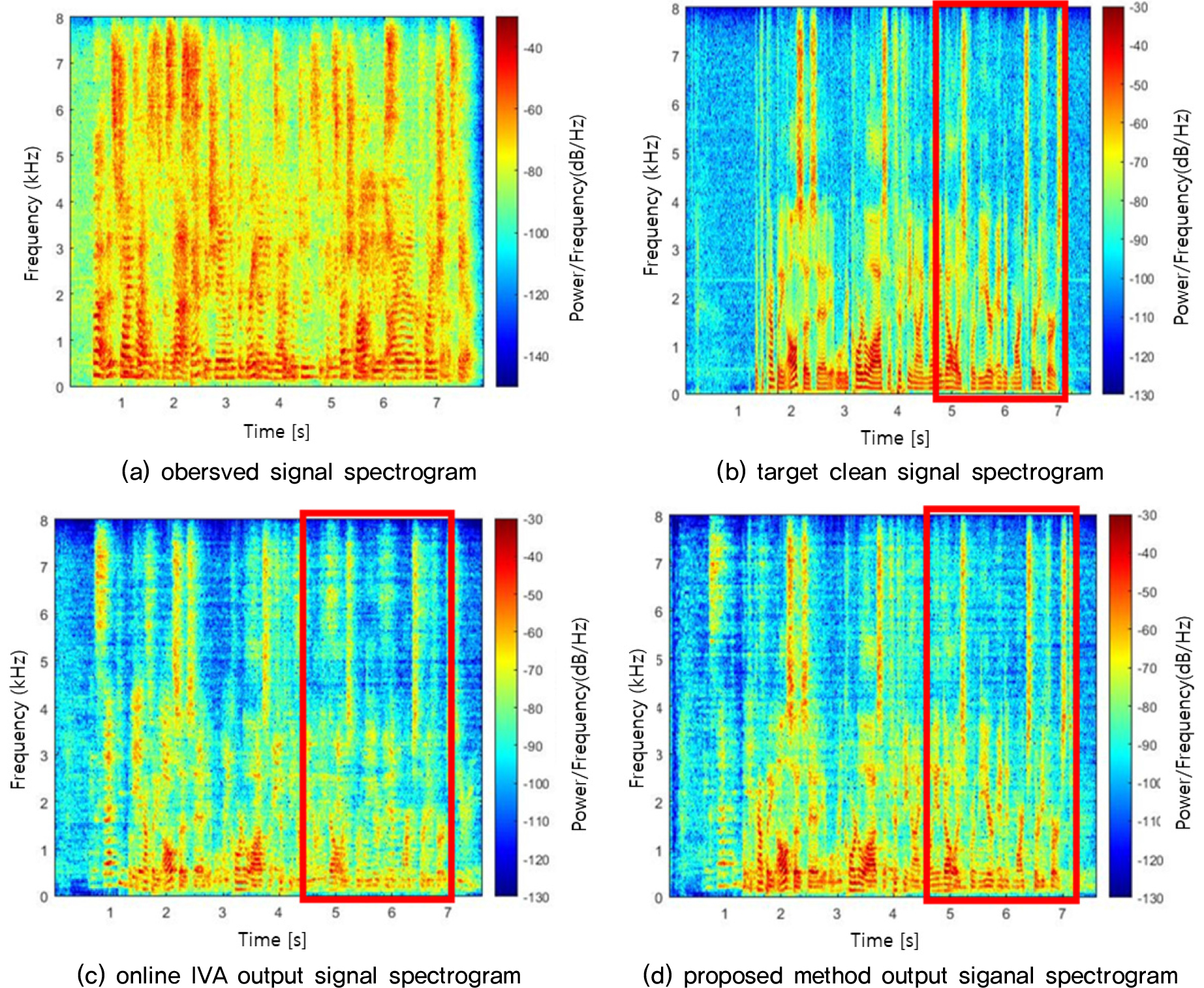
다양한 잔향 실험에서 기존의 온라인 분리 방법보다 SDR과 PESQ 모두 높은 성능을 확인할 수 있다. 하지만 온라인 방식은 시간경과에 따른 재귀적 방식을 사용하기 때문에 잔향의 영향이 큰 환경일수록 잔향의 영향이 적은 환경보다 성능이 낮아지는 것을 확인할 수 있다. 다음 실험은 시간 경과에 따른 SDR 및 PESQ의 성능을 통해 온라인 방식에서의 시간에 따른 각 온라인 분리방법의 암묵음 분리 성능을 살펴보았다. Fig. 4는 Fig. 3의 실험 결과를 통해 각 잔향 환경마다 높은 성능을 나타내는 최적의 초기 반사음과 잔향 시간을 설정하여 실험하였다. Fig. 4의 결과를 살펴보면, 기존의 Online-IVA는 잔향의 영향이 적은 환경(RT60 = 0.2 s)에서는 시간에 따른 분리성능이 향상되지만, 잔향의 영향이 커질수록 제대로 분리가 되지 않는 것을 확인 할 수 있다. 기존의 방법과 비교하여, 제안한 방법을 살펴보면 초기 시간에는 분리 성능이 떨어지지만 시간의 경과에 따라서 분리 성능이 점차 향상되는 것을 확인할 수 있다. 상단의 Fig. 5 는 잔향 시간이 0.4 s인 실험 환경에서의 음원 분리 결과 스펙트로그램의 예시이다. 온라인 방식으로 인해 두 방법 모두 초기 시간에서는 신호의 분리가 뚜렷하게 나타지 않는다. 하지만 기존 방법(c)에서는 시간이 경과해도 목표 음원 신호에 가깝게 분리되지 않지만 제안 방법(d)에서는 목표 음원신호(b)에 가깝게 분리된 것을 확인 할 수 있다.