

I. 서 론
II. 딥러닝 기반 음성 디노이징 기술 동향
2.1 위상 정보 처리를 위한 접근법
2.2 오프라인 및 실시간 처리를 위한 모델
2.3 경량 실시간 모델과 DeepFilterNet
III. 글로벌 성능 벤치마크와 한국어 데이터 환경
3.1 공인 DB 기반 글로벌 성능 비교
3.2 한국어 음성 디노이징 연구의 한계
IV. 한국어 데이터 적용 및 모델 검증
4.1 Baseline 모델 선정
4.2 실험 모델 구조
4.3 손실 함수
4.4 성능 평가
V. 결론 및 고찰
I. 서 론
잡음 환경에서의 음성 향상 기술은 통신 시스템의 음질 개선, 자동 음성인식의 성능 향상, 보청기 및 음성 비서 서비스 등 다양한 분야에서 필수적인 역할을 수행한다.[1] 특히 단일 채널 음성 신호에서 잡음을 효과적으로 제거하거나 억제하여 청취 명료도와 주관적 품질을 높이기 위한 연구가 지난 수십 년간 활발히 진행되어 왔다.
초기 연구는 주로 디지털 신호처리에 기반한 통계적 기법에 집중되었다. 대표적으로 잡음의 평균 스펙터럼을 추정하여 음성 스펙트럼에서 차감하는 스펙트럴 차감법이나, 신호 대 잡음비(Signal-to-Noise Ratio, SNR)에 따라 적응적으로 평균 가중치를 적용하는 위너 필터 및 최소 평균 제곱 오차 추정 기반의 기법들이 널리 활용되었다.[2] 이러한 전통적 기법들은 구현이 비교적 간단하고 낮은 지연 시간으로 실시간 처리가 가능하다는 장점이 있으나, 비정상적 잡음 환경 변화에 대한 대응 능력이 부족하고 뮤지컬 노이즈와 같은 왜곡이 발생하는 한계를 보였다.
이러한 한계를 극복하고자 2000년대 후반부터 기계학습을 접목한 접근법이 등장했다. 그중 비음수 행렬 분해 기반의 방법은 잡음과 음성의 주파수 성분을 각각의 기저 벡터 조합으로 표현하여 서로 분리하는 방식으로 초기 음성 향상 연구에서 큰 가능성을 보였다. 하지만 잡음과 음성의 부분 공간이 중첩되는 경우 두 신호를 명확히 구분하기 어렵다는 근본적인 한계가 존재했다.
2010년대 중반 이후 심층 신경망(Deep Neural Network, DNN) 기술이 급격히 발전하면서 음성 향상 분야에도 본격적으로 도입되었다. 초기 DNN 모델들은 주로 잡음이 섞인 음성의 스펙트로그램을 입력받아 깨끗한 목표 스펙트로그램을 출력하도록 매핑하는 회귀 문제로 접근했다. Xu et al.[3]은 DNN을 이용하여 로그 스펙트럼 영역에서 잡음과 음성 간의 변환을 학습시켜 기존의 최소 평균 제곱 오차 추정 필터 대비 상당한 성능 향상을 보고했으며, 다양한 SNR 환경에서 객관적 음질 평가지표인 Perceptual Evaluation of Speech Quality(PESQ) 점수를 평균 0.32만큼 개선했다. 이후 순환 신경망(Recurrent Neural Network, RNN)과 그 발전된 형태인 장단기 메모리(Long Short-Term Memory, LSTM) 및 Gated Recurrent Unit(GRU)을 활용하여 시간적 문맥 정보를 모델링하거나, 합성곱 신경망(Convolutional Neural Network, CNN)을 이용해 스펙트로그램의 시간-주파수 패턴을 학습하는 모델들이 연이어 제안되었다.[4] 이러한 초기 모델들은 음성 인식 성능 개선이나 음성 합성을 위한 데이터 정제 등에도 성공적으로 활용되어 그 효용성을 입증했다.[5] 그러나 이들 모델은 스펙트럼의 크기 정보만을 복원하고 위상 정보는 원본 신호의 것을 그대로 사용하는 한계가 있었다. 이로 인해 예측된 크기와 원본 위상을 결합하는 과정에서 위상 불일치로 인한 왜곡이 발생했으며, 이를 해결하기 위해 위상 정보까지 통합적으로 처리하는 새로운 접근법의 필요성이 대두되었다.
이러한 배경을 바탕으로, 본 논문은 두 가지 목표를 가진다. 첫째, 최신 딥러닝 기반 음성 디노이징 기술 동향을 체계적으로 고찰한다. 둘째, 이를 기반으로 성능이 검증된 실시간 모델을 한국어 환경에 적용하여 그 성능과 구현 가능성을 검토하는 타당성 연구를 수행한다. 이 과정에서, 단순히 모델을 적용하는 것을 넘어 한국어 데이터의 특성이 모델 성능에 미치는 영향을 분석하고, 실질적인 구현 과정에서 발생하는 핵심 과제를 도출하는 데 본 연구의 의의가 있다.
본 논문의 구성은 다음과 같다. 2장에서는 딥러닝 기반 음성 디노이징 기술의 주요 동향을 살펴보고, 3장에서는 글로벌 성능 벤치마크와 한국어 데이터 환경의 한계를 짚어본다. 4장에서는 SOTA(State of the Art) 모델의 한국어 적용 실험 설계와 그 결과를 제시하며, 특히 이 과정에서 발견된 데이터 품질 불일치 문제를 상세히 분석한다. 마지막으로 5장에서는 연구 결과를 요약하고, 안정적인 한국어 모델 개발을 위한 향후 과제를 논의한다.
II. 딥러닝 기반 음성 디노이징 기술 동향
딥러닝 기술의 도입은 음성 디노이징 분야에 비약적인 변화를 가져왔다. 초기 딥러닝 모델들이 통계적 기법의 한계를 넘어서는 가능성을 보인 이후, 연구는 더 높은 음질을 위한 핵심 과제들을 해결하는 방향으로 전개되었다. Table 1은 이러한 기술 발전의 전체적인 흐름을 요약한 것이다.
Table 1.
A phased summary of the evolution of speech denoising technology.
본 장에서는 이러한 기술 동향을 두 가지 주요 축을 중심으로 살펴본다. 첫째는 초기 모델의 근본적인 한계였던 위상 왜곡 문제를 해결하려는 기술적 접근법이다. 이는 스펙트럼의 크기만 다루던 방식에서 벗어나 복소수 스펙트럼 전체나 시간 영역의 파형을 직접 모델링하는 방식으로 이어졌다(2.1절). 둘째는 연구의 목적이 세분화 되면서 나타난 기술의 분화 현상이다. 이는 최고의 음질을 추구하는 고성능 오프라인 모델과, 통신 및 모바일 기기 등 실제 응용을 위한 저지연 실시간 모델로 연구 방향이 나뉘는 결과로 나타났다(2.2절). 이러한 흐름 속에서 본 연구의 기반이 되는 경량 실시간 모델이 등장하게 된 배경을 기술한다(2.3절).
2.1 위상 정보 처리를 위한 접근법
초기 딥러닝 모델들이 위상 정보를 간과했던 한계를 극복하기 위해, 크기와 위상을 통합적으로 처리하는 연구가 활발히 진행되었다. 대표적인 접근법은 복소수 스펙트럼을 직접 입출력으로 사용하여 실수부와 허수부를 모두 예측하는 것이다. 더 나아가 네트워크 내부의 가중치와 연산을 복소수 형태로 구현하여 위상 정보를 보다 직접적으로 학습하려는 시도도 이루어졌다. 이러한 위상 인지 접근의 대표적인 사례인 Deep Complex Convolutional Recurrent Network(DCCRN)은 CNN과 RNN에 복소수 연산을 도입하여 위상까지 함께 처리함으로써, 주관적 평가지표 Mean Opinion Score(MOS) 기준 최상위권의 잡음 제거 성능을 달성하며 그 효과를 입증했다.[6]
한편, 단기 푸리에 변환(Short-Time Fourier Transform, STFT) 과정을 생략하고 시간 영역의 파형을 직접 입출력으로 사용하는 종단간 모델도 주목받았다. 이 방식은 위상 손실 문제를 원천적으로 방지하는 장점이 있다. 생성적 적대 신경망을 활용한 Speech Enhancement Generative Adversarial Network(SEGAN)은 파형 기반 잡음 제거를 시도하여 다양한 잡음 환경에서 종단간 모델의 초기 가능성을 보였으며,[7] 이후 제안된 Conv-TasNet은 시간 영역에서 직접 음성을 분리하는 모델로 이상적인 시간-주파수 마스크의 성능을 뛰어넘으며 파형 기반 접근법의 잠재력을 입증했다.[8] 그러나 이러한 모델들은 파형을 직접 처리하기 위해 긴 시간의 문맥을 학습해야 하므로 모델의 파라미터 수와 연산량이 증가하여 실시간 구현에 어려움이 따랐다.[9] 이처럼 모델의 성능과 계산 복잡도 사이에는 트레이드 오프가 존재하며, 이는 음성 향상 기술 발전의 중요한 화두가 되고 있다.
2.2 오프라인 및 실시간 처리를 위한 모델
딥러닝 기반 음성 향상 기술은 응용 분야의 요구사항에 따라 고성능 오프라인 기술과 저지연 실시간 기술로 분화하며 발전하고 있다.
오프라인 환경에서는 실시간 제약이 없으므로, 대규모 연산을 통해 최고의 음질을 달성하는 것을 목표로 한다. U-Net, 대규모 RNN, Transformer와 같은 복잡한 구조를 도입하여 장기 의존성을 학습하고, 이중 경로 구조로 지역적 및 전역적 패턴을 동시에 모델링하여 성능을 극대화한다.[8] 최근에는 DOSE[10]와 같은 확산 모델이 도입되어 기존의 예측 기반 모델보다 월등히 자연스럽고 왜곡이 적은 음성을 생성하며 최고 성능을 경신하고 있다. 하지만 이는 높은 계산 비용과 느린 추론 속도로 인해, 오프라인 환경에 적합한 기술이라 할 수 있다.
반면, 실시간 환경에서는 통신, 스트리밍, 보청기 등에서 요구하는 낮은 지연 시간과 제한된 연산 자원을 만족시키는 것이 핵심이다. 이를 위해 모델 경량화와 인과적 처리에 초점을 맞춘 연구가 주를 이룬다. RNNoise는 DSP 필터와 소규모 RNN을 결합한 하이브리드 접근으로 실시간 잡음 억제의 성공 사례를 보여주었으며,[11] PercepNet, GaGNet 등은 인간의 청각 특성을 모방하거나 멀티밴드 구조를 도입하여 효율성을 높였다.[12] 특히 보청기와 같이 수 밀리초(ms) 이하의 초저지연이 요구되는 분야에서는 딥 필터링 기법을 적용한 DeepFilterNet이 등장했다. 이 모델은 매우 짧은 프레임(5 ms 이하)을 사용하면서도 저하되는 주파수 해상도 문제를 학습된 FIR 필터로 보완하여 음질을 유지하는 새로운 가능성을 제시했다.[9]
2.3 경량 실시간 모델과 DeepFilterNet
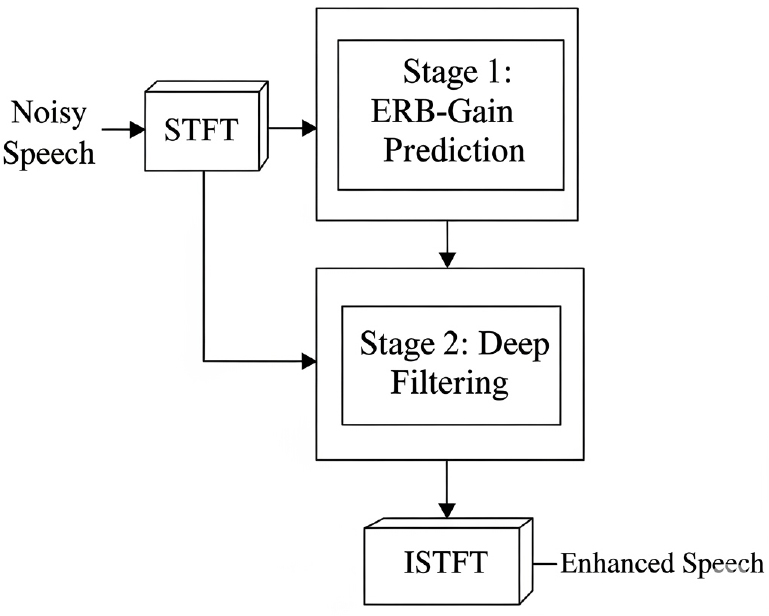
DeepFilterNet은 실시간 저복잡도 환경에 최적화된 대표적인 프레임워크로, 높은 성능과 낮은 계산 복잡도를 동시에 달성했다.[9] 이 모델의 핵심은 Fig. 1에서 보여지는 바와 같이 2단계 처리 방식에 있다. 1단계에서는 인간의 청각 특성을 모사한 등가 구형 대역폭 스케일로 스펙트럼을 압축한 뒤, 각 대역의 증폭률을 예측하여 스펙트럼 포락선을 부드럽게 향상시킨다. 2단계에서는 음성의 하모닉 성분이 밀집된 저주파 대역에만 딥 필터링을 적용하여 잔여 잡음을 제거하고 미세 구조를 복원한다.[9] 이러한 구조는 연산량을 크게 줄이면서도 청각적으로 중요한 정보를 효과적으로 처리한다. 또한, depthwise separable convolution과 같은 경량화 기법을 적용하여 1.3 M 수준의 적은 파라미터로도 SOTA급 성능을 달성했으며, 일반 CPU 환경에서 25배 이상 빠른 실시간 처리 지수 0.04를 기록하여 효율성을 입증했다[9].
III. 글로벌 성능 벤치마크와 한국어 데이터 환경
3.1 공인 DB 기반 글로벌 성능 비교
음성 디노이징 알고리즘의 성능을 객관적으로 비교하기 위해 국제적으로 통용되는 표준 데이터베이스와 평가지표가 사용된다. 그중 가장 널리 쓰이는 것은 Valentini-Botinhao 등이 제안한 VoiceBank + DEMAND 데이터셋이다. 이 데이터셋은 모델 훈련을 위해 28명 화자의 음성을 0 dB, 5 dB, 10 dB, 15 dB의 SNR로 합성하여 구성되며, 평가에는 학습에 사용되지 않은 별도의 2명 화자 음성을 2.5 dB, 7.5 dB, 12.5 dB, 17.5 dB의 다른 SNR 조건으로 합성한 데이터를 사용하여 모델의 일반화 성능을 측정한다.[5] Table 2는 이 데이터셋을 기준으로 주요 모델들의 객관적 성능을 각 원논문 등에서 인용하여 비교한 것이다.[6,9,11,12] 이 결과들을 살펴보면, 처리되지 않은 원본 음성의 PESQ 점수가 1.97에 머무는 반면, DCCRN(2020)과 같은 복소수 RNN 기반 모델은 2.54점으로 성능을 개선했다. 특히 2022년에 발표된 FullSubNet+, GaGNet과 같은 최신 모델들은 각각 2.88, 2.94점을 기록하며 3.0점에 근접하는 높은 성능을 보였다. DeepFilterNet2는 3.08점을 달성하여 이 비교군에서는 유일하게 3.0점을 넘었으며, 가장 적은 파라미터 수(~1.36 M)로 높은 효율성을 입증했다. 이처럼 딥러닝 기반 기법들은 Short-Time Objective Intelligibility(STOI)와 같은 음성 명료도 지표에서도 0.95에 근접하는 등, 객관적 지표상으로 높은 수준의 성능을 보인다.
Table 2.
Performance comparison of major models on the VoiceBank + DEMAND dataset. Results are cited from the respective original papers.
한편, Microsoft가 주최하는 DNS Challenge와 같은 국제 대회에서는 실제 환경에서 녹음된 잡음 데이터를 활용하여 주관적 음질 평가 MOS를 수행한다. 2022년 ICASSP DNS Challenge 결과에 따르면, 화자 정보 없이 범용적으로 동작하는 실시간 잡음 제거 부문에서는 Multi-scale Temporal Frequency Convolutional Network with Axial Attention 모델[13]이 1위를 차지했으며, DNSMOS P.835 전체 음질 평가 기준 3.5 이상을 기록하였다.[14,15]
3.2 한국어 음성 디노이징 연구의 한계
이처럼 영어 데이터셋을 기반으로는 활발한 연구와 성능 경쟁이 이루어지고 있으나, 한국어와 같은 다른 언어 환경에서는 몇 가지 중요한 한계에 직면한다. 지금까지의 연구 및 성능 평가는 대부분 영어 음성 데이터를 중심으로 이루어졌다. 그러나 한국어는 음절 구조, 종성 발음 등 측면에서 영어와 음운 구조가 다르고, 방언이나 말의 속도 등에서 차이가 있어 영어 데이터로 학습된 모델을 그대로 적용할 경우 최적의 성능을 기대하기 어렵다.
Table 3은 본 연구에서 활용된 주요 데이터셋의 핵심 특징과 한계를 요약한 것이다. Table 3에서 볼 수 있듯이, 한국어 환경에서는 활용 가능한 대규모 병렬 데이터셋이 부재하고 데이터 간 품질이 불일치하는 문제가 핵심적인 한계로 작용한다. AI Hub 등을 통해 대규모의 깨끗한 한국어 음성 데이터와 다양한 소음 데이터가 공개되어 있는 것은 사실이다. 하지만 SOTA 모델 훈련에 사용되는 글로벌 데이터셋은 단순히 두 데이터를 합치는 것을 넘어, 수만 개 이상의 개별 잡음 클립과 수천 개의 공간 음향 특성(Room Impulse Response, RIR)을 체계적으로 조합하여 현실 세계의 다양한 소리 환경을 정교하게 재현한다. 이러한 고품질의 대규모 병렬 데이터셋을 구축하는 과정은 상당한 공학적 자원과 시간이 요구되는 작업이며, 아직 한국어에 대해서는 이와 같은 수준의 데이터셋이 공개되지 않은 실정이다.
Table 3.
Comparison of key characteristics of major speech and noise datasets.
더욱이, 공개된 한국어 음성 데이터 중 KsponSpeech 등 일부를 제외하면 깨끗한 음성으로 분류된 데이터에도 미세한 배경 잡음이 포함되거나, 48 kHz환경을 표준으로 하는 최신 연구들과 달리 16 kHz로 녹음된 경우가 많다. 이러한 데이터를 단순히 업샘플링하여 고품질 데이터와 혼합해 학습할 경우, 모델이 제한된 주파수 대역을 깨끗한 상태로 오인하여 오히려 성능이 저하되는 현상이 발생할 수 있다. 이러한 데이터셋의 한계는, 본 논문에서 진행하는 것과 같이 기존의 검증된 모델을 기반으로 한국어 데이터를 적용하고 그 성능 변화를 분석하는 연구의 필요성을 제기한다.
IV. 한국어 데이터 적용 및 모델 검증
4.1 Baseline 모델 선정
본 연구에서는 한국어 데이터 적용을 위한 기반 모델로 DeepFilterNet2를 선정했다. 이 모델은 효율적인 경량화 구조를 가지며, 공개된 소스 코드를 통해 구현이 용이하다는 장점이 있다.[9] 특히 48 kHz 전대역 음성에 대해 CPU 환경에서도 실시간 처리가 가능하며, VoiceBank + DEMAND 벤치마크에서 SOTA 수준의 성능이 보고되어 기술적 위험이 낮으면서도 높은 성능을 확보할 수 있다고 판단하였다. 기준 모델은 원 논문의 설정을 따르며, 프레임 크기 20 ms와 프레임 시프트 10 ms를 사용했고, 총 파라미터 수는 약 1.36 M이다.[9]
4.2 실험 모델 구조
본 실험에서는 기반 모델의 구조를 그대로 사용하되, 실시간 처리 조건과 성능의 균형을 검증하기 위해 Fig. 2에서 보이는 바와 같이 세 가지 인과성 설정으로 나누어 학습 및 평가를 진행했다.

첫째, 완전 인과적 모델은 현재 프레임 처리 시 미래 신호를 전혀 참조하지 않는 구조(lookahead = 0)로, 알고리즘으로 인한 추가 지연이 발생하지 않아 지연 최소화가 최우선인 통신이나 보청기 환경에 적합하다.
둘째, 부분 인과적 모델은 2개 프레임의 미래 신호를 참조(lookahead = 2)하도록 설계했다. 즉, 현재 프레임 를 처리할 때, +1과 +2 시점의 미래 신호 정보를 함께 사용한다. 이는 2 × hop size(10 ms) = 20 ms의 추가적인 알고리즘 지연을 발생시키는 대신, 폭발음이나 성조 변화 등을 미리 참고하여 잡음 제거의 정확도를 높이는 것을 목표로 한다. 약간의 지연을 대가로 성능 개선을 꾀하는 절충적인 설정이다.[12]
셋째, 비인과적 모델은 양방향 GRU를 활용하여 전체 입력 시퀀스의 과거와 미래 정보를 모두 반영한다. 즉, 프레임 의 출력을 계산할 때 전체 입력 시퀀스의 과거와 미래를 모두 사용한다. 고정된 lookahead 값이 없으며, 각 에 대해 남은 전 구간이 미래 문맥이 된다. 오프라인 처리 특성상 출력은 시퀀스 종료 이후에 산출된다. 이 모델은 실시간 적용은 어렵지만, 미래 정보 부재로 인한 성능 손실이 어느 정도인지 파악하고 이론적인 성능 상한치를 가늠하기 위한 비교 목적으로 설계되었다.
4.3 손실 함수
딥러닝 모델의 훈련은 예측 결과와 실제 정답 간의 오차를 최소화하는 방향으로 진행되며, 이 오차를 측정하는 기준이 바로 손실 함수이다. 본 연구에서는 다중 해상도(Multi-Resolution, MR) STFT 손실을 사용하였다. 이는 서로 다른 STFT 파라미터(FFT 크기, 윈도우 크기 등)를 갖는 여러 개의 STFT 손실을 조합한 것으로, 시간 및 주파수 영역에서 다양한 관점의 오차를 동시에 줄여 음질을 효과적으로 개선할 수 있다. MR-STFT 손실 은 스펙트럼 수렴 손실 와 로그 STFT 크기 손실 의 합으로 구성되며, 각 손실은 다음과 같이 정의된다.
여기서 와 는 각각 깨끗한 음성과 예측된 음성의 스펙트로그램, 는 크기 스펙트럼, 와 은 각각 Frobenius norm과 L1 norm을 의미한다. 최종적으로 는 개의 다른 해상도에 대한 손실들의 평균으로 계산된다.
본 연구에서는 48 kHz 샘플링 레이트 오디오에 대해 세가지 해상도를 사용하였으며, 각 해상도의 FFT 크기는 {2048, 1024, 512}, 윈도우 크기는 {40 ms, 20 ms, 10 ms}로 설정하였다.
4.4 성능 평가
본 연구의 훈련 및 평가에 사용된 데이터셋의 구성은 다음과 같다. 훈련 데이터셋은 두 종류로, 첫째 ‘Eng’ 훈련셋은 DNS Challenge 데이터와 Valentini 데이터셋(28 spk, 56 spk 버전 포함)을 통합하여 구성하였다. 둘째, ‘Eng + Kor’ 훈련셋은 여기에 대규모 한국어 데이터인 KsponSpeech 코퍼스[16]를 추가했다. KsponSpeech는 전체 데이터의 85 %를 학습용, 15 %를 검증용으로 분리하여 사용하였다. 학습 데이터 생성 시, SNR은 –10 dB부터 40 dB까지(–10 dB, –7 dB, –5 dB, 0 dB, 3 dB, 5 dB, 7 dB, 10 dB, 15 dB, 20 dB, 40 dB)의 넓은 범위에서 다양하게 설정하여 모델이 여러 잡음 환경에 강인하게 학습되도록 하였다. 모델 학습은 8개의 NVIDIA A40 GPU가 장착된 서버에서 수행되었다.
평가 데이터셋 또한 두 종류로 구성되었다. ‘Eng’ 평가셋으로는 표준 벤치마크인 VoiceBank + DEMAND 테스트셋을 사용하였다. ‘Kor’ 평가셋은 본 연구에서 직접 구축한 것으로, KsponSpeech의 공식 평가용 데이터(eval_clean)에 잡음을 합성하여 제작하였다. 이때, 모델의 일반화 성능을 공정하게 측정하기 위해 VoiceBank + DEMAND 테스트셋과 동일하게 학습 시 사용되지 않은 SNR 조건(2.5 dB, 7.5 dB, 12.5 dB, 17.5 dB)을 적용하였다. 평가지표로는 음질 PESQ와 음성 명료도 STOI를 사용했다.
평가 결과는 Table 4에 요약되어 있다. 비인과적 모델은 전체 시퀀스를 활용하여 세 모델 중 가장 높은 성능 상한선을 보였고, 완전 인과적 모델은 지연이 없지만 성능은 가장 낮았다. 주목할 만한 점은 한국어 데이터를 추가 학습했음에도 불구하고 한국어 테스트셋에서의 성능이 기대만큼 향상되지 않았다는 것이다. 영어로만 학습된 Baseline Lookahead 모델은 한국어 테스트셋에서 PESQ 2.36을 기록했으나, 한국어 데이터를 추가 학습한 Lookahead 모델은 PESQ 2.38로 개선 폭이 미미했다. Causal 모델의 경우, 오히려 성능이 PESQ 2.30으로 소폭 하락하는 예상 밖의 결과를 보였다.
Table 4.
Performance comparison of the proposed DeepFilterNet2-based models and baselines on English and Korean test sets. For details on the dataset composition for ‘Eng’ and ‘Kor’, please refer to Section 4.4.
이러한 예상 밖의 결과는 학습 데이터 간의 품질 불일치 문제, 특히 샘플링 레이트 차이에서 비롯된 것으로 분석된다. 본 연구에 사용된 영어 데이터셋(DNS, Valentini)은 48 kHz의 고품질 광대역 음성인 반면, 한국어 데이터셋(KsponSpeech)은 16 kHz로 녹음된 협대역 음성을 48 kHz로 업샘플링하여 사용했다. 업샘플링은 파일의 샘플링 레이트를 맞출 수는 있지만, 실제로는 8 kHz 이상의 고주파수 대역에 유의미한 정보를 생성하지 못한다. 따라서 모델은 학습 과정에서 깨끗한 영어 음성은 풍부한 고주파수 성분을 가지지만, 깨끗한 한국어 음성은 고주파수 성분이 없다는 상충되는 정보를 학습하게 된다.
결과적으로, 혼합 데이터로 학습된 모델은 잡음이 섞인 한국어 음성을 처리할 때, 잡음뿐만 아니라 유의미한 고주파수 성분까지 함께 제거하여 훈련 시 학습했던 고주파수 정보가 없는 한국어 데이터와 유사하게 만들려는 경향을 보인 것으로 추정된다. 이러한 고주파수 정보의 손실은 PESQ와 같은 객관적 음질 평가 지표에서 큰 감점 요인으로 작용하여, 한국어 데이터 추가 학습의 효과가 기대에 미치지 못하는 결과를 낳은 것이다.
V. 결론 및 고찰
본 논문은 딥러닝 기반 음성 디노이징 기술 동향을 살펴보고, SOTA 모델을 한국어 환경에 적용하는 실험을 진행했다. 이를 위해 영어 중심 데이터로 학습된 기준 모델과, 16 kHz 한국어 데이터를 업샘플링하여 추가 학습한 모델의 성능을 비교 분석하였다. 실험 결과, 한국어 데이터를 추가 학습한 모델이 영어로만 학습한 모델보다 오히려 한국어 테스트셋에서 성능이 저하되거나 개선 폭이 미미한 현상을 관찰했다. 이는 학습 데이터셋 간 샘플링 레이트 불일치로 모델이 깨끗한 한국어 음성의 특징을 잘못 학습했기 때문으로 분석된다. 즉, 모델이 잡음과 함께 유의미한 고주파수 성분까지 제거하며 대역폭이 제한된 학습 데이터의 특징을 모방하려 한 것이다. 이는 다국어 데이터셋 활용 시 데이터의 양보다 품질, 샘플링 레이트 등 물리적 특성의 동질성 확보가 모델 성능에 결정적임을 실증한다. 향후 과제로는 본 연구에서 확인된 문제를 해결하기 위해, 주파수 대역 확장기술이나 도메인 적응기법을 모델 구조에 통합하는 연구를 탐색할 계획이다. 또한, 데이터 품질 불일치의 영향을 명확히 규명하기 위해 한국어 데이터셋만으로 학습한 모델과의 비교 분석 연구가 필수적이다.
