

I. 서 론
수중 수동 소나는 여러 개의 배열 센서로부터 다양한 수중 신호가 혼합된 음향신호를 수신한다. 이러한 신호로부터 각각의 신호원을 분리하여 위험도를 판단하는 기술은 국가보안 측면에서 매우 중요한 기술이다. 하지만, 드넓은 바다에서 전달되는 수중 신호에는 다양한 신호원으로부터 생성된 신호가 혼합되고, 그 품질 또한 매우 낮아 이를 적절하게 분해하는 것은 매우 까다로운 문제이다.
현재 주로 사용되는 방법들은 Short-Time Fourier Transform(STFT)를 사용하여 수신된 음향신호의 스펙트로그램을 얻은 뒤, 시간별 주파수의 특성의 변화를 분석하여 신호를 분리하는 기술들이다. 예를 들어, 시간-주파수 마스킹기법, 스펙트로그램을 이용한 비음수 행렬 분해, 독립 성분 분석 등이 대표적이다.[1,2,3,4] 그러나 이러한 방식에는 몇 가지 제한 사항이 존재한다. 먼저 STFT 출력은 시간 및 주파수 해상도에 영향을 미치는 오디오 프레임의 크기 및 겹침 등과 같은 많은 매개변수에 영향을 받는다. 이러한 매개변수는 신호 분리 성능을 최대화하기 위해 분리 모델의 매개변수와 함께 최적화되어야 한다. 그러나 실제 변환 매개변수는 특정 값으로 고정되어 있어서 변화하는 데이터에 적응적으로 대응할 수가 없게 되어 분리 성능의 제한된다. 또한, 스펙트로그램을 얻는 과정에서 위상 정보를 제거하고 크기 성분만을 주로 이용하기 때문에 분리 모델이 원신호의 위상을 고려하지 않는다. 이는 분리 모델의 추정한 신호와 원래 입력 신호(혼합신호)의 위상과 결합하여 다시 시간 도메인으로 변환할 때, 잠재적으로 정보 손실을 초래할 수 있다.[5]
이와 같은 문제를 해결하기 위해, 최근에는 크기 및 위상 정보를 함께 반영할 수 있는 시간 영역의 신호를 직접 활용하여 분리하는 접근 방법이 도입되었다. 이러한 방법으로는 Adaptive front-end와 direct regression으로 구분된다.[6]Adaptive front-end는 기존에 STFT를 통해 신호의 특징을 추출 후 분리 모델에 넣어주는 전처리과정을 미분 가능한 변환을 사용하여 학습한다. 즉, 전처리과정 네트워크와 신호 분리 네트워크를 연결하여 동시에 학습시킨다. Adaptive front-end는 STFT와 독립적이므로 창 크기와 기저 함수를 더 유연하게 선택할 수 있다.[7]Direct regression은 전처리과정 없이 혼합된 신호를 입력으로 받아 각 원신호의 추정치를 학습하는 방법이다. Direct regression은 전처리과정이 없으므로, 모델의 구현이 간단하고, 학습 파라미터의 감소로 인해 빠르게 학습할 수 있다. 또한, 시계열 데이터를 바로 사용하여 기존 기법에서 학습 데이터를 역변환을 통해 시계열 데이터로 복원하는 과정을 생략함으로써 보다 경제적인 효율성을 가진다.[8]
그러나, 위의 방법들은 입력 데이터의 길이가 매우 길 때 한 번에 처리하는 것이 어렵다. 따라서 일부 구간을 잘라서 처리하는 방식을 사용하게 되는데, 이로 인해 구간 간의 연속성이 부여되지 않아 일부 구간에 잡음이 생길 수 있다. 즉, 데이터의 길이에 따라 분리의 성능이 변동되는 한계점들이 있다.[9]최근 긴 시퀀스 신호를 학습하려는 방법으로 두 방향 순환 신경망(Dual-path Recurrent Neural Network, DPRNN)이 제안되었다. 두 방향 순환 신경망은 입력 데이터를 짧은 조각으로 분할하고, 두 개의 순환 신경망을 활용하여 조각의 로컬 특성(하나의 조각 내의 순환 신경망)과 글로벌 특성(조각과 조각 간의 순환 신경망)을 학습하는 모델로 긴 시계열 신호 처리에서 좋은 성능을 보였다. 그러나 이는 단일채널 신호를 처리하는 기법으로 다중 채널에서 취득되는 수중 소나 신호를 분리하기에는 모델과 데이터 간의 일치성의 부족으로 인해, 다중 채널 간의 비선형 관계를 모델이 학습하지 못하여 신호 분리 성능 감소한다.[6]
본 논문에서는 이러한 다중 채널의 소나 데이터를 학습하기 위해서, 3차원 텐서를 활용한 세 방향 순환 신경망(Triple-path RNN)을 제안한다. 세 방향 순환 신경망은 짧은 조각 내부를 나타내는 방향, 짧은 조각끼리를 나타내는 방향, 3차원 텐서 내 채널을 나타내는 방향을 말하며 각 방향에 대한 RNN을 통해서 데이터의 특징만으로 이루어진 3차원 텐서를 학습한다.
II. 모델 설계
2.1 모델 구성
Fig. 1은 제안 모델의 전체 흐름을 보여주며, 모델은 세 단계로 구성되어 있다: 인코딩, 분리과정, 디코딩. 인코딩 단계에서는 시퀀스로부터 특징맵을 추출하여 3차원 텐서를 만든다. 이 텐서는 분리과정에 전달되어 세 가지 순환 신경망(채널 간의 순환 신경망, 조각 내의 순환 신경망, 조각 간의 순환 신경망)을 순차적으로 거친다. 분리과정이 완료된 후 디코딩을 통해서 각 원신호로 변환한다.
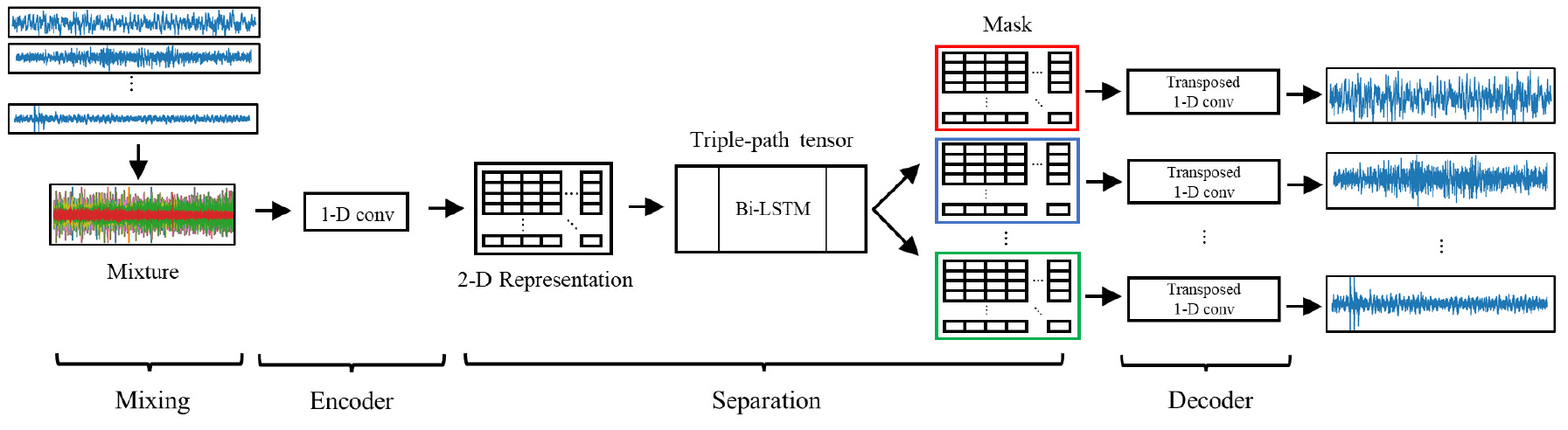
2.2 인코더
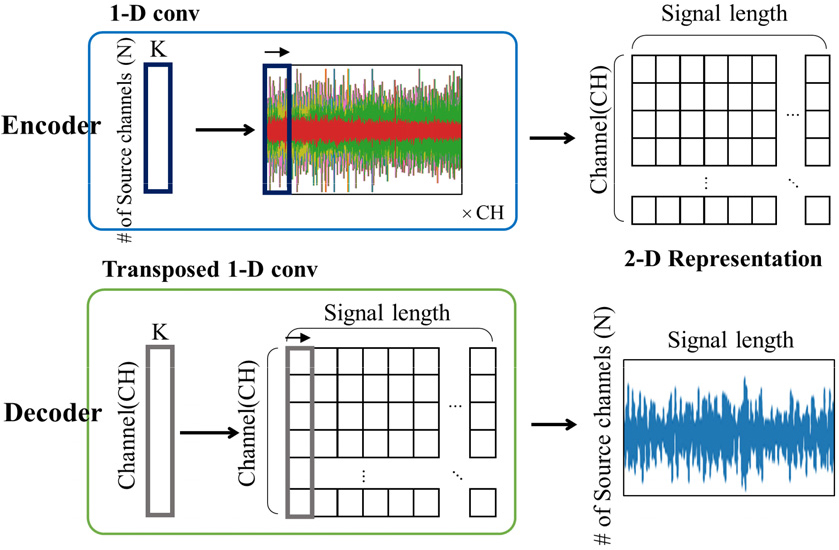
인코더는 1차원 합성곱 계층으로 구성되어 있다. Fig. 2에서 보이는 합성곱 계층의 필터 크기는 혼합된 신호의 채널 수이며, 는 하이퍼파라미터이다. 합성된 신호가 인코더의 입력으로 들어오게 되면 1차원 합성곱 계층이 2차원 특징맵을 출력으로 내보낸다.
얻어낸 2차원 특징맵으로부터, Fig. 3에서 보이는 것과 같이, 여러 개의 조각으로 분할한다. 이때 각 조각은 서로 겹치게 분할된다. 잘라낸 조각들로 3차원 텐서를 만들면 3차원 텐서의 세 가지 방향은 각각 채널 방향, 조각 내 방향, 조각 간 방향을 나타낸다. 실험 시, 사용한 하이퍼 파라미터의 경우, 조각의 높이(H)는 1로 설정하였으며, 하나의 시퀀스당 조각 개수(L)은 조각끼리 겹치는 정도를 50 %로 설정하였기에 다음과 같이 정해진다.
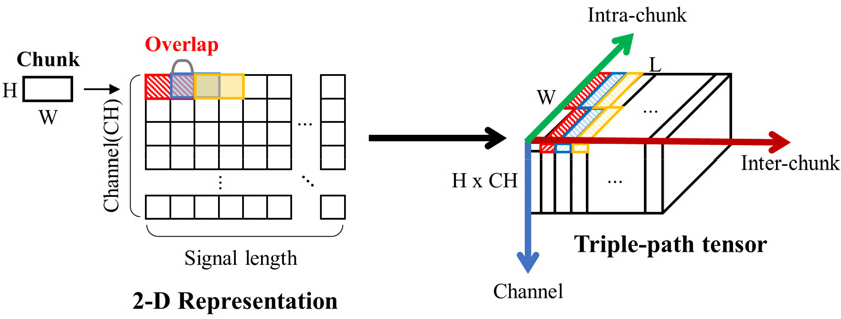
이때, Signal length(Sl)는 모델에 입력되는 신호의 길이에 대한 차원을 의미하며, W는 조각의 크기이다.
2.3 분리과정
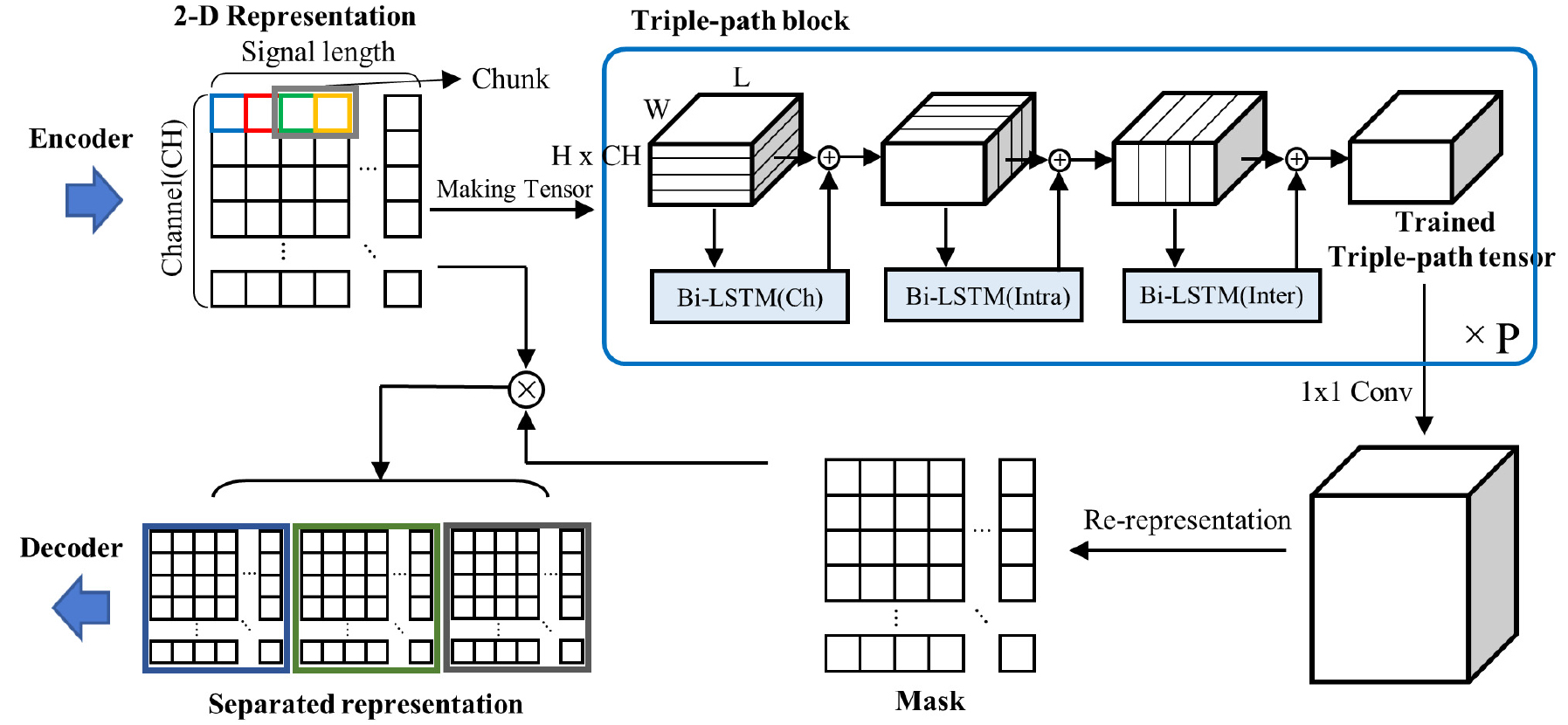
Fig. 4는 3차원 텐서가 Triple-path block을 거쳐서 마스크를 얻어내는 과정을 보여준다. 먼저 2차원 특징맵으로부터 변환된 3차원 텐서를 입력으로 세 가지 장단기 메모리(Long Short Term Memory, LSTM)가 진행된다. 이 과정을 세 방향 블록이라고 하고, P번 반복하게 된다. 연구에 사용된 장단기메모리는 양방향 장단기 메모리로, 기존 장단기 메모리의 순방향과 추가로 역방향 입력을 처리함으로써 과거 정보와 미래 정보를 모두 보존한다. 양방향 장단기 메모리는 채널 방향, 조각 내 방향, 조각 간 방향 순으로 진행되며, 잔차 연결을 사용하여 학습 과정이 길어짐에 따른 성능 저하 현상을 방지한다.[10] 분리과정이 완료된 후 3차원 텐서에 대해서 1 x 1 컨볼루션 계층를 사용하여 채널의 개수를 원신호 개수만큼 배로 늘리고, 각 원신호에 해당하는 3차원 텐서로 분할한다. 각 3차원 텐서는 인코딩 단계에서 3차원 텐서로 변환했던 과정의 역순을 통해 마스크로 변환된다. 이 마스크는 합성된 신호의 특징맵에서 각 원신호의 성분을 추출하는 역할을 한다.[11]
2.4 디코더
합성된 신호의 2차원 특징맵과 각 원신호의 마스크를 원소별로 곱한 후, 최종적으로 얻어진 2차원 특징맵에 대해서 전치 1차원 합성곱 계층을 통과시켜 원신호를 구한다. 이 계층은 역방향으로 합성곱 연산을 수행하여 입력 특징맵의 크기를 필터 개수의 배수만큼 확장하는 역할을 한다. 이때 Fig. 2에서 보이는 것과 같이, 전치 1차원 합성곱 계층의 하이퍼 파라미터는 인코딩 단계에서 사용된 1차원 합성곱 계층의 하이퍼 파라미터와 같다.
III. 실험데이터셋
실험에 사용된 데이터는 해양 음향 연구자들을 위한 음향신호 데이터인 ShipsEar 데이터를 활용하였다.[12] 총 11개의 선박 유형에 대한 90개의 단일채널 음향신호 파일로 구성되어 있으며, 수중 소음이 포함되어 있다. 본 연구에서는 motorboat, passenger boat, Roll-on/roll off(RORO) 세 가지 선박과 보트를 선택하여 사용하였다. 선택한 레이블마다 파일을 25개씩 나누고, 각 파일에 4가지 종류의 시간 지연을 적용하여 단일채널을 4채널로 변환하였다. 시간 지연에 대해서는 제로 패딩을 적용하였으며, 원활한 학습을 위해 값이 0인 부분을 제외하고 20,000개의 시퀀스를 샘플링하였다. 따라서 모델로 들어가는 혼합된 음향신호 입력의 차원은 이며, 은 각각 음향신호 채널의 개수, 시퀀스 길이를 나타낸다. 각 레이블마다 시간 지연이 적용된 100개의 데이터를 임의 추출한 후, 모두 합쳐서 정규화하였다. 이렇게 처리한 결과물이 하나의 다중 채널 음향신호 파일로 변환되었다.
IV. 실험 구성
각 데이터의 길이는 약 1 s이며, 훈련 데이터셋은 약 11,000개, 검증 데이터셋은 약 1,000개, 테스트 데이터셋은 약 1,000개로 구성되어 있으며, 배치 크기(batch size)는 4로 설정하였다. 모델 구조는 총 6개의 세 방향 블록을 포함하며, 1차원 합성곱 필터 크기(K)는 2이다. 위와 같은 하이퍼 파라미터를 사용하여 모델을 구성하였을 때, 4채널 데이터 기준으로 제안 모델에서 사용되는 학습 가능한 파라미터 개수는 9,248,309개이며, 두 방향 순환 신경망의 학습 가능한 파라미터 개수는 8,798,645개이다. 실험에 사용된 프로그래밍 언어와 라이브러리(library)는 파이썬(python)의 파이토치(Pytorch)2.0.0 버전으로, 8대의 NVIDIA RTX A5000 Graphics Processing Unit(GPU)를 이용하여 분산학습을 수행하였다.[13] 추론 과정에서는 단일 GPU를 사용하였다.
전체 학습 에포크 수는 150으로 설정하고, 학습 과정에서 검증 결과가 가장 우수한 파라미터를 기준으로 테스트를 수행하였다. 초기 학습률은 0.001로 설정하였으며, 만약 연속적으로 5 에포크 동안 손실 값이 감소하지 않을 경우 학습률을 절반으로 줄였다. 최적화 방법으로는 Adam을 사용했고, 손실함수는 Scale-Invariant Signal to Noise Ratio(SI-SNR)방법을 적용하였다. SI-SNR 수식은 다음과 같다.[14,15]
이때, 과 는 각각 추정된 신호(estimated signal), 원신호(reference signal)이며, 손실함수를 계산하기 전에, 각각 평균이 0이 되도록 정규화하는 과정을 거쳤다. 은 와 의 내적과 가 요소곱을 통해 얻어지는 값이다. 실험 후 얻어진 SI-SNR을 혼합된 신호와 비교하기 위해 SI-SNRi를 사용하였는데, SI-SNRi는 추정된 신호와 원신호 사이에서 얻어진 SI-SNR과 혼합된 신호와 원신호 사이에서 얻어진 SI-SNR의 차이이다. 또한, 손실 값 계산 시 발생하는 순열(permutation) 문제를 해결하기 위해서 순열 불변 훈련(Permutation Invariant Training, PIT) 방법이 사용되었다.[16] 순열 문제는 추정된 신호의 순서가 무작위이기 때문에 원신호와의 1:1 대응이 어렵다는 것이며, 순열 불변 훈련 방법은 각 추정된 신호마다 모든 원신호에 대해 손실 값을 계산하여 그중 가장 작은 값으로 선택하는 것이다.
V. 실험 결과
Fig. 5는 원신호, 두 방향 순환 신경망, 제안 모델으로 추정한 각 신호의 스펙트로그램을 비교하여 나타낸 것이다. 순열 문제로 인해 추정된 신호의 순서는 무작위이지만, 원신호의 스펙트로그램과 유사한 것끼리 대응시켰다.
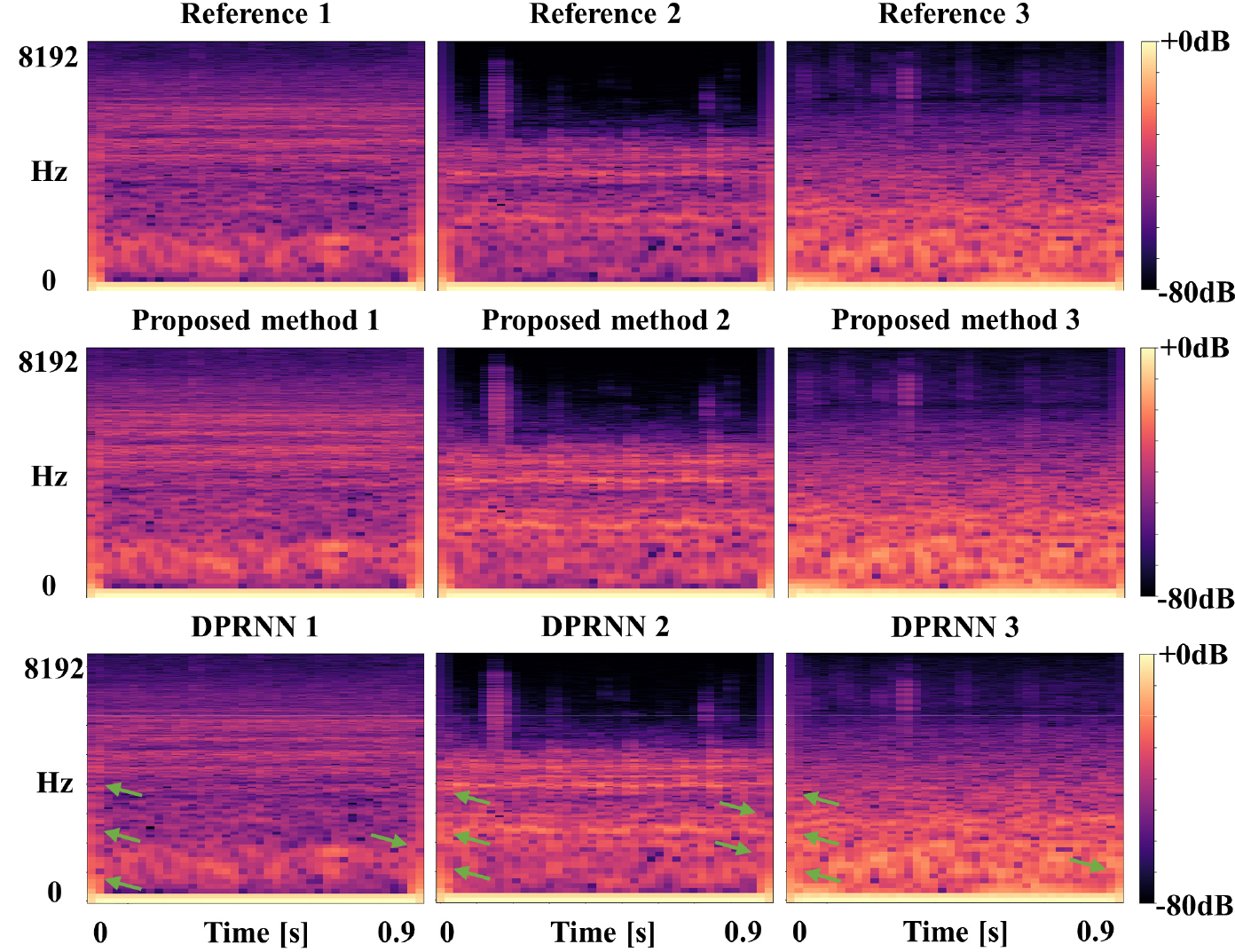
Fig. 5의 스펙트로그램 비교를 통해 볼 수 있듯이, 제안된 모델이 기존의 두 방향 순환 신경망 모델보다 더 나은 성능을 보여준다. 초록색 화살표는 두 방향 순환 신경망 모델의 결과로 얻은 스펙트로그램과 원신호의 스펙트로그램 간의 차이를 나타낸다.
이를 정량적으로 평가하기 위해, Root Mean Square Error(RMSE)와 Scale-Invariant Signal to Noise Ratio improvement(SI-SNRi)를 평가 지표로 사용하여 두 모델의 성능을 비교하였다. Table 1을 보면, 기존 두 방향 순환 신경망 모델의 경우, RMSE는 3.92로 측정되었으며, SI-SNRi는 38.21이었다. 반면, 제안된 모델은 RMSE가 3.49로 더 낮은 값을 보였고, SI-SNRi는 41.00으로 더 큰 값을 보였다. 이 결과는 제안된 모델이 두 방향 순환 신경망 모델보다 다중 채널 음향신호 분리에 더 효과적이라는 것을 시사한다. 따라서 실험 결과를 통해 제안된 모델이 기존의 모델에 비해 더 우수한 성능을 보여주며, 다중 채널 수동 소나 신호 분리를 위한 좋은 대안으로 사용될 수 있음을 확인할 수 있었다.
Table 1.
Comparison of RMSE and SI-SNRi values for DPRNN and the proposed model.
| Method | RMSE | SI-SNRi |
| DPRNN | 3.92 | 38.21 |
| Proposed model | 3.49 | 41.00 |
본 연구에서는 제안된 모델의 기본적인 성능 검증을 위해 적은 수의 채널로 수중 신호를 모델링 하여 그 성능을 검증하였다. 따라서, 후속 연구에서는 채널 데이터 수를 늘리고, 여러 물리현상을 반영한 다양한 모델을 고려하여 좀 더 현실에 가까운 다중 채널 소나 신호를 생성하고, 이를 바탕으로 성능을 검증할 계획이다. 또한, 현재 시계열 데이터를 사용하고, 3차원 텐서를 구성하는데, 이로 인해 데이터의 크기가 기존의 스펙트로그램 기반 데이터보다 상당히 커지는 한계점이 있었다. 학습 시 사용하고자 하는 데이터의 크기는 채널 개수만큼 늘어나기 때문에, 채널 수를 확장한 모델을 효과적으로 학습하기 위해서는 데이터를 효율적으로 경량화하는 방법이 필요하다. 후속 연구에서는 적절한 전처리, 혹은 압축 센싱 등의 방법들을 사용하여 해당 데이터셋의 크기를 줄이면서도 성능을 비슷하게 유지할 수 있는 모델을 연구하고자 한다.
VI. 결 론
본 연구에서는 다중 채널 수동 소나 데이터를 각 원신호로 분리하기 위한 모델로서, 3차원 텐서를 이용한 순환 신경망 기반 신호 분리 모델을 제안하였다. 제안된 모델은 기존 단일채널 오디오 데이터 신호 분리를 위한 모델에서 채널 방향 순환 신경망을 추가함으로써 모델과 데이터 간의 일치성을 만족시켰다. 실험을 위해서 공개된 수중 소나 신호를 활용하여 모의 다중 채널 데이터를 생성하여 모의실험을 수행하였다. 실험 결과 기존 모델과 제안 모델이 추정한 신호와 원신호를 비교하였을 때, 개선된 RMSE와 SI-SNRi 결괏값을 확인하여 향상된 신호 분리 성능을 검증하였다.
