

I. Introduction
II. Methods
2.1 Two speakers and face masks
2.2 Speech recording under mask-wearing conditions
2.3 Data extraction
III. Results
3.1 Vowel analysis
3.2 Spectral and cepstral analysis
IV. Discussion
4.1 Face masks like low-pass filters
4.2 Speech levels and CPPs due to face masks
4.3 Limitations and future work
V. Conclusions
I. Introduction
Wearing a mask has become the new normal option owing to the coronavirus disease 2019 (COVID-19) outbreak. However, people in Korea have significantly reduced the use of masks since the declaration of the end of the COVID-19 pandemic, but are wearing masks selectively due to concerns about yellow dust, fine dust, flu, and coronavirus. People wear masks according to their individual preferences regarding shape, thickness, and color.[1] Various studies have been conducted on the wearing of masks during the COVID-19 pandemic. Wearing a mask for a long time not only causes discomfort such as difficulty in breathing, speech difficulties, sweating, and moisture,[1] but also makes visual access to the speaker’s lips difficult and causes hearing impairment in noisy environments.[2] Furthermore, wearing a mask has been shown to weaken a speaker’s speech signal at 1 kHz – 2 kHz[3,4,5,6] and negatively affect intelligibility.[7,8] Table 1 shows the latest research on the acoustic characteristics of vowels and sentences according to various types of mask wearing. A group of studies found that face masks did not produce significant acoustic changes and affected only a few of the acoustic parameters. Fiorella et al.[9]found no statistically significant difference in any acoustic parameters: fundamental frequency (F0), vocal intensity, jitter, shimmer, and Harmonics-to-Noise Ratio (HNR), from sustained /a/ samples from 60 Italian participants-between the masked and unmasked conditions; however, in 65 % of the subjects, after wearing the surgical mask, there was a non-significant decrease in vocal intensity. A reduction in intensity can also affect social interactions and speech audibility, particularly in individuals with hearing loss. They concluded that wearing a mask was likely to induce an unconscious need to increase vocal effort, resulting in a greater risk of developing functional dysphonia. Joshi et al.[10] collected vowel extension vocalization samples from 19 adults (10 women and 9 men) wearing no masks, cloth masks, surgical masks, KN95 masks, or surgical masks over a KN95 mask with and without a face shield. The masks tested in this study did not have a significant impact on the sound pressure level, F0, Cepstral Peak Prominence (CPP), and first (F1) or second (F2) formant frequency compared with the voice output without a mask. McKenna et al.[11] evaluated voice acoustics and self-perceptual ratings in US healthcare workers who were required to wear face masks throughout their workdays. Healthcare workers who wore masks reported more negative vocal symptoms after the workday. These symptoms appeared to be related to an increase in vocal intensity and HNR, and a decrease in F0. The effect of the mask type (simple and N95) showed only a Low-to-High spectral ratio (L/H ratio) standard deviation. Magee et al.[7]investigated the effects of N95, surgical, and cloth masks on acoustic analysis and perceived intelligibility in four Australian participants and found effects at frequencies above 3 kHz for the 95 mask and above 5 kHz for surgical and cloth masks. Measures of timing and spectral tilt differed mainly with the N95 mask use. The cepstral and harmonics-to-noise ratios remained unchanged across mask types. Face masks changed the speech signal, but some specific acoustic features, such as measures of voice quality, remained largely unaffected irrespective of the mask type. Some studies showed significant changes in acoustic parameters owing to face masks. Gojayev et al.[12] measured F0, shimmer, jitter, s/z ratio, Maximum Phonation Time (MPT), and HNR in 204 Turkish patients under three different masking conditions: no mask, surgical mask, and valved Face-Filtering Piece-3 (FFP3). When wearing no mask or a surgical mask, no significant differences in F0, jitter, shimmer, HNR, s/z, or MPT were found. However, significant differences were observed in the shimmer and HNR values when wearing an FFP3. Lin et al.[13] examined whether medical masks affected the acoustic, aerodynamic, and formant parameters in 53 Chinese participants (25 males and 28 females). The Sound Pressure Level (SPL) increased significantly when medical masks were worn. The jitter, shimmer, and frequency of the third formant (F3) were significantly reduced.
Table 1.
Acoustic parameters affected by face mask extracted from previous studies.
| Speaker | Speech material | Face mask | Acoustic parameters | |||
| Gender + No | Language | Analysis | Effect of mask (P < 0.05) | |||
| Fiorella et al. (2021)[9] | M24, F36 | Hospital workers, Bari, Italy | A sustained /a/ | No Mask, Surgical | Maximum Phonation Time (MPT), Median Pitch, Mean Pitch, Nim Pitch, Max Pitch, Intensity, Number of pulses, Number of Periods, HNR, Jitter, Shimmer | None |
| Joshi et al. (2021)[10] | M9, F10 | Native speakers of Standard American English | Sustained /a/, /i/ | No Mask, Cloth, Surgical, KN95, Surgical + KN95, Surgical_KN95+shield | SPL 1ft and 6ft, F0, CPP, F1, F2 | No significant impact |
| McKenna et al. (2021)[11] | M7, F11 | English speaking healthcare workers |
Sustained vowels /i/, /a/, /u/ The first paragraph of the Rainbow passage Single words and sentences | Simple, N95 |
Spectral and cepstral:: CPP, CPP SD, L/H Ratio, LH SD, CPP f0, CPP f0 SD VCV: Relative Fundamental Frequency (RFF), Offset 10, Onset 1 Vowel: Intensity, HNR | LH SD |
| Magee et al. (2020)[7] | M2, F2 | Native English speakers | A Phonetically balanced text, the Grandfather Passage | No Mask, Surgical, N95, Cloth | Mean pause length, Variability of pause length, Percent of pauses Spectral tilt, Mean intensity, Intensity prominence, p95 Intensity, CPPS, HNR, f0 mean, f0 CoV, Jitter, Shimmer |
Head-mounted Mic : Mean Pause length, Percent of pauses (%), Spectral tile Tabletop Mic.: Percent of pause, Spectral tilt |
| Gojayev et al. (2021)[12] | M77, F127 | Turkish patients | A sustained /a/ | No Mask, Surgical, FFP3 | F0, Jitter, Shimmer, MPT, HNR, s/z |
No significant impact with surgical mask Overall with FFP3: Shimmer, HNR Female: HNR Male: Jitter, Shimmer, MPT, HNR |
| Lin et al. (2021)[13] | M25, F28 | Chinese speaking participants | A sustained /a/ | No Mask, Medical | F0, SPL, Jitter, Shimmer, NHR, CPP, MPT, F1, F2, F3 | SPL, Jitter, Shimmer, F3 |
| Nguyen et al. (2021)[14] | M4, F12 | English speakers |
A sustained /a/ CAPE-V phrases Rainbow Passage | No Mask, Surgical, KN95 | Mean spectral level in 0 kHz - 1 kHz and 1 kHz - 8 kHz, L/H(1 k), HNR, CPP, Intensity | Mean spectral level 1 kHz - 8 kHz, HNR |
| McKenna et al. (2022)[15] | M8, F13 | Standard American English speaking healthcare professionals |
Sustained /i/, /u/, /a/ Rainbow Passage VCV | Simple, N95, N95 + Simple | Vowel: f0, f0 SD, jitter, shimmer, HNR, Intensity, F1, F2, Vowel Articulation Index (VAI) Spectral and Cepstral: L/H(4k), L/H SD, CPP, CPP SD, VCV: RFF | HNR, CPP, L/H, L/H SD, RFF offset 10, VAI |
| Zhang et al. (2022)[8] | F3 | Native Hong Kong Cantonese | 30 trisyllabic words imbedded in a carrier structure | No Mask, Surgical, KF94, Face shield, Surgical + shield |
Speaking rate, Intensity, Acoustic attenuation in 0 kHz - 1 kHz and 1 kHz - 8 kHz, Vowel Space Area (VSA) Tone duration, F0, F1, F2 |
Speaking rate, Intensity, Acoustic attenuation in 0 kHz - 1 kHz and 1 kHz - 8 kHz, VSA, /aa/ F1, /aa/ F2, Tone duration, F0 |
| Cala et al. (2023)[16] | M5, F5 | Italian speaking otolaryngologists working in the hospital | Sustained /a/, /i/, /u/ A sentence |
No Mask, Surgical, Surgical + shield, FFP2 (N95), FFP2 + shield, FFP3, FFP3 + shield | F0 mean, Jitter, NNE, F1, F2, VSA, FCR (1/VAI) |
Female: Jitter /u/, NNE /i/, NNE /u/, F1a/F1i, F1a/F1u, F2i/F2u, VSA, FCR Male: NNE /a/, F1a/F1i, F1a/F1u, F2i/F2u, VSA, FCR |
| Geng et al. (2023)[17] | M15, F15 | Native Mandarin Chinese speakers (Fluent English as their 2nd language) | Phonetically balanced texts in both Chinese and English versions | No Mask, Surgical | F0, Speech rate, Intensity, HNR, Jitter, Shimmer, H1-H2 | F0, Intensity, HNR, Jitter, Shimmer |
|
Yang and Kwon (present study) | M1, F1 | Native Korean voice actors |
Sustained /a/, /i/, /u/ Phonetically balanced monosyllabic word lists | No Mask, Surgical, KF-AD vertically folded, KF-AD horizontally folded, KF-80 vertically folded, KF-80 horizontally folded, KF-94 vertically folded, KF-94 horizontally folded, N95 |
Vowel: f0 mean, F1, F2, VSA, VAI, HNR Lists: F0 mean, Speech level, L/H (4 k), CPP |
F0 mean (Hz), Speech level (dBA), L/H (4 k) (dB), CPP (dB) |
These changes may result from the adjustment of the vocal tract and the filtration function of medical masks, leading to the stability of voices being overstated. Nguyen et al.[14] conducted an acoustic analysis of F0, jitter, shimmer, MPT, HNR, and s/z in no-mask, surgical, and KN95 situations when performing standardized speech tasks on 16 Australian participants. In connected speech, the average spectral level in the 1 kHz – 8 kHz regions was significantly attenuated, and the L/H ratio of connected speech increased significantly while wearing either a surgical mask or a KN95 mask; however, no significant change in this measure was found for vowels. The HNR was higher when wearing a mask than when not wearing a mask. The CPPs and voice intensity did not change while wearing a mask. These results showed that surgical masks had less of an effect on the speech spectrum than KN95s. McKenna et al.[15] examined the spectral energy and vocal effort during speech while wearing Simple, N95, and N95 + Simple masks. They found a significant decrease in the VAI, high-frequency information (> 4 kHz), and a RFF offset of 10 when wearing a mask. The CPPs and perceived vocal effort increased when wearing an N95 mask, and high-frequency attenuation was noticeable compared with a simple mask. Zhang et al.[8] found significant changes in all acoustic correlates of Cantonese speech under Protective Facial Coverings (PFCs). The sound pressure levels were attenuated more intensely at higher frequencies in speech through face masks, whereas sound transmission was more affected at lower frequencies. Vowel spaces derived from formant frequencies shrank in all PFCs, with the vowel /aa/ demonstrating the largest changes in the first two formants. All tone-bearing parts were shortened and showed increments in F0 in speech through PFCs. The decrease in tone duration was statistically significant only for the high-level tones. They concluded that the general filtering effect of PFCs on Cantonese speech data confirmed the language-universal patterns of acoustic attenuation by PFCs. Cala et al.[16] reported significant differences between mask + shield configuration and no-mask conditions and between mask and mask + shield conditions with 10 Italian participants. The power spectral density decreased with statistical significance above 1.5 kHz when wearing masks. Subjective ratings confirmed an increase in discomfort from the no-mask condition to the protective mask and shield condition. Geng et al.[17] conducted a cross-linguistic study of masked speech in Mandarin Chinese and English. Continuous speech of phonetically balanced text in both Chinese and English versions was recorded from 30 native speakers of Mandarin Chinese, with and without a surgical mask. As a result of the acoustic analysis, mask speech exhibited higher F0, intensity, HNR, and lower jitter and shimmer than no-mask speech for Mandarin Chinese, whereas higher HNR and lower jitter and shimmer were observed for English mask speech. They concluded that wearing a surgical mask impacted both acoustic-phonetic and automatic speaker recognition approaches to some extent, suggesting particular caution in the real-case practice of forensic speaker identification.
This study explored the effects of face masks on the Korean language in terms of acoustic, aerodynamic, and formant parameters. We chose all types of face masks available in Korea based on filter performance and folding type. Professional voice actors with more than 20 years of experience who are native Koreans and speak standard Korean participated in this study as speakers of voice data. We hypothesized that (1) face masks could affect speech acoustic parameters, and (2) changes in these acoustic measures would be more pronounced with increased face mask thickness.
II. Methods
2.1 Two speakers and face masks
Two native Korean voice actors (male, 51 years old; female, 47 years old) with more than 20 years of experience participated as speakers. No participant had dysphonia or any other voice problems.
Table 2 and Fig. 1 show the eight different face masks used in this study: surgical mask, vertically folded KF-AD (anti-droplet) mask, horizontally folded KF-AD mask, vertically folded KF-80 mask, horizontally folded KF-80 mask, vertically folded KF-94 mask, horizontally folded KF-94 mask, and N95 mask. A surgical mask is a loose-fitting disposable device that creates a physical barrier between the wearer’s mouth and nose, and potential contaminants in the immediate environment.[18] Although a surgical mask with non-woven fabric fails to provide complete protection, many prefer to wear it because of its breathability.[19] The KF-80 and KF-94 masks are the ‘Korean filter’ standard; 80 (%) and 94 (%) refer to its filtration efficiency.[20] The KF-94 mask is equivalent to the N95. Horizontally and vertically folded KF94 masks have been the most widely used masks in Korea during the COVID-19 pandemic.[1] The experiment was conducted by randomly wearing 8 types of masks. Table 2 lists the specifications of the face masks used in this study.
Table 2.
Specifications of the face masks used in this study.
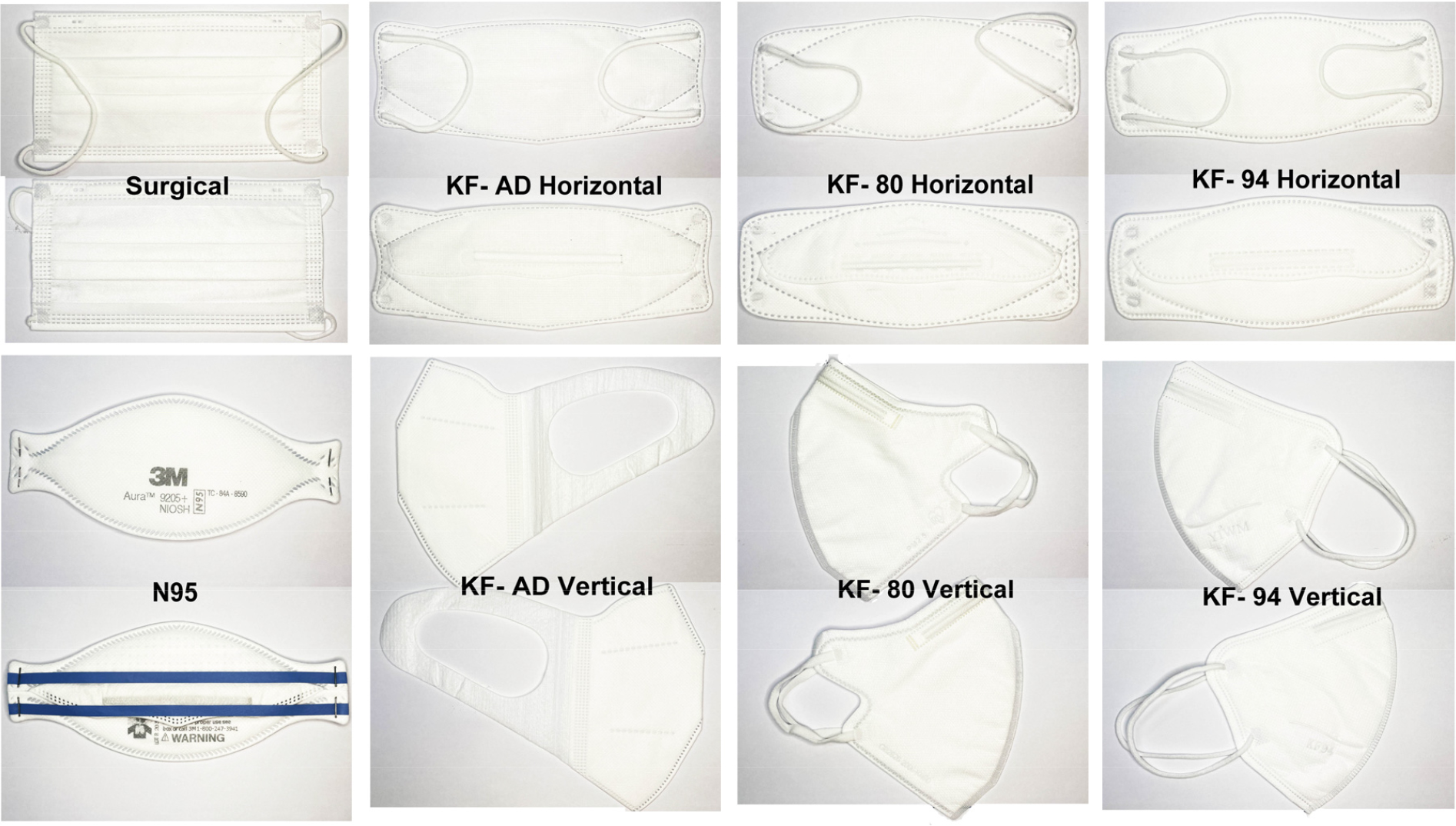
2.2 Speech recording under mask-wearing conditions
Recordings were completed in a flat-walled fully anechoic chamber[21] (8.2 m × 7.0 m × 7.5 m, = 50 Hz), using a class 1 sound level meter (RION NL-52) which is able to record speech signal and measure speech levels 1 m away from a speaker’s mouth. Because room conditions affect speech acoustics, an anechoic chamber was chosen to eliminate room effects from speech recordings.
Three sustained vowels, /a/, /i/, and /u/, were recorded twice per speaker for 5 s each. Speakers read the Korean Standard Monosyllabic Word List (KS-MWL),[22] which was developed based on the international standard for speech audiometry.[23] The speech speed was set at 2 s per word. Because the purpose of the acoustic measurements was to test the effects of face masks on human speech, monosyllabic word lists could be useful for providing phonetically balanced content and enhancing discrimination in mask-wearing conditions. Four 50-word lists from the KS-MWL for adults and four 25-word lists for preschoolers were used.
Three vowels and eight phonetically balanced KS-MWL lists were recorded under nine different conditions: one non-mask-wearing and eight mask-wearing conditions.
2.3 Data extraction
2.3.1 Vowel analysis
Acoustic measurements were manually extracted from the vowel segments using Praat version 6.3.10. The standard pitch settings (75 Hz – 500 Hz) provided by Praat were used. The middle portion of the sustained vowels was extracted for the analysis. Mean F0, HNR, and formant frequencies (F1 and F2) were obtained using Praat. The VSA and VAI[15] were calculated using F1 and F2.
2.3.2 Spectral and cepstral analysis
The mean F0, Speech Level (SL) in dBA, L/H ratio with a cut-off frequency of 4 kHz, and CPP were analyzed as per the KS-MWL list. The F0 and L/H ratio were calculated using the R programming language version 4.2.3. The L/H ratio, with a cutoff frequency of 4 kHz, is known to decrease in speakers with dysphonia[24,25] and vocal effort.[15,26]
The SL was measured using a RION NL-52 sound level meter. The CPP was achieved using Praat CPP plugin.[27] The cepstral peak range was set to a standard of 60 Hz – 330 Hz.
Factorial ANalysis Of VAriance (ANOVA) was used to test the effects of face masks and speakers on spectral and cepstral measures. Tukey’s HSD was applied to enable multiple comparisons, the significance level was set to p = 0.05, and statistical analyses were conducted using Minitab® 21.1 (Minitab, State College, PA, US).
III. Results
3.1 Vowel analysis
Table 3 summarizes the vowel analysis results for the two speakers. The mean F0 was approximately 200 Hz for the female and 100 Hz for the male. HNR tended to increase for both speakers as the mask thickness increased. HNR The first two formants of the three corner vowels varied under mask-wearing conditions, as shown in Fig. 2, and VSA and VAI decreased with increasing mask thickness. The first two formants of male /i/ changed less than the other two vowels. For the female speaker, the first two formants of the three vowels changed under mask-wearing conditions. Increased mask thickness seemed to affect VSA and VAI.
Table 3.
F0, HNR, formant frequency (F1 and F2), VSA, and VAI for three vowels (/a/, /i/, and /u/).
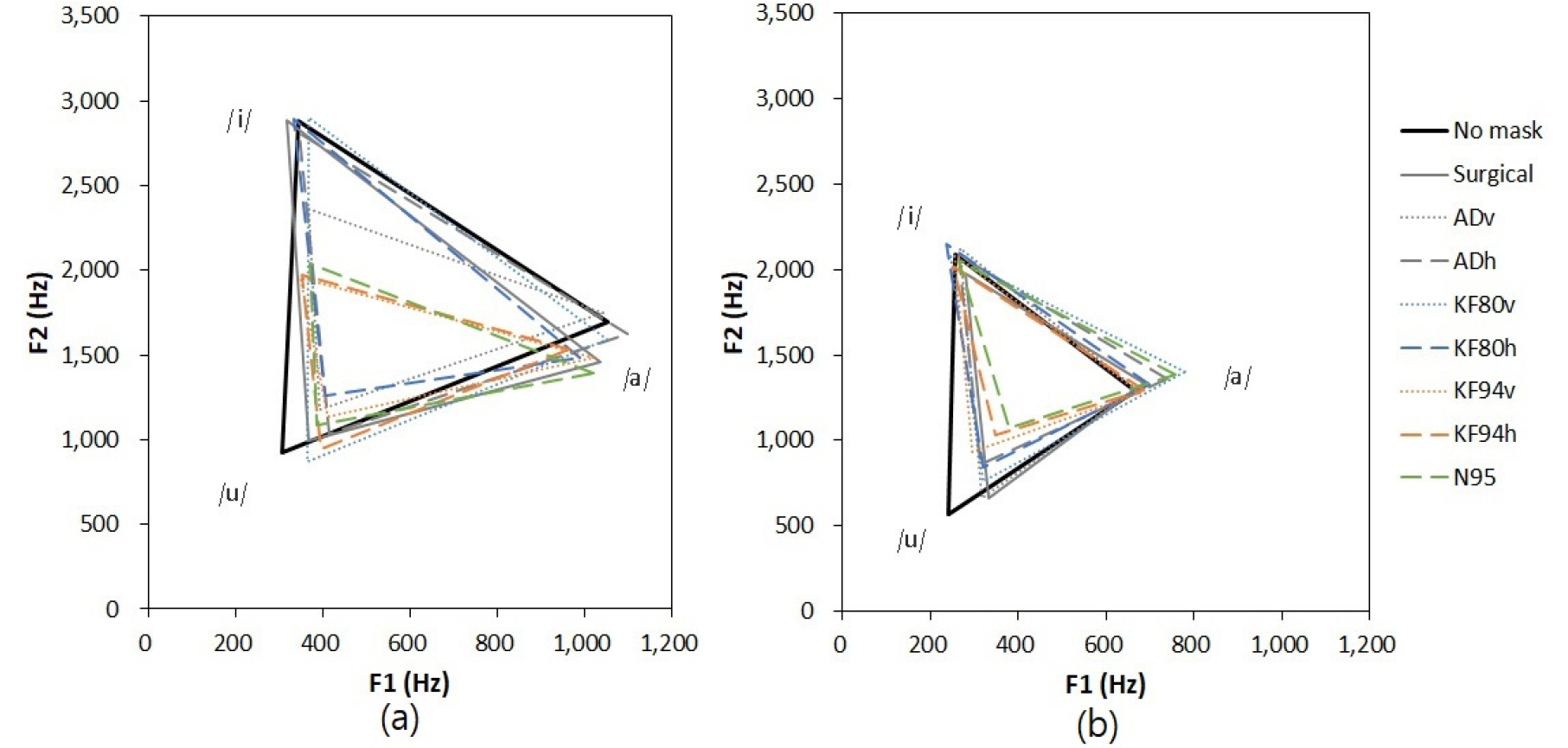
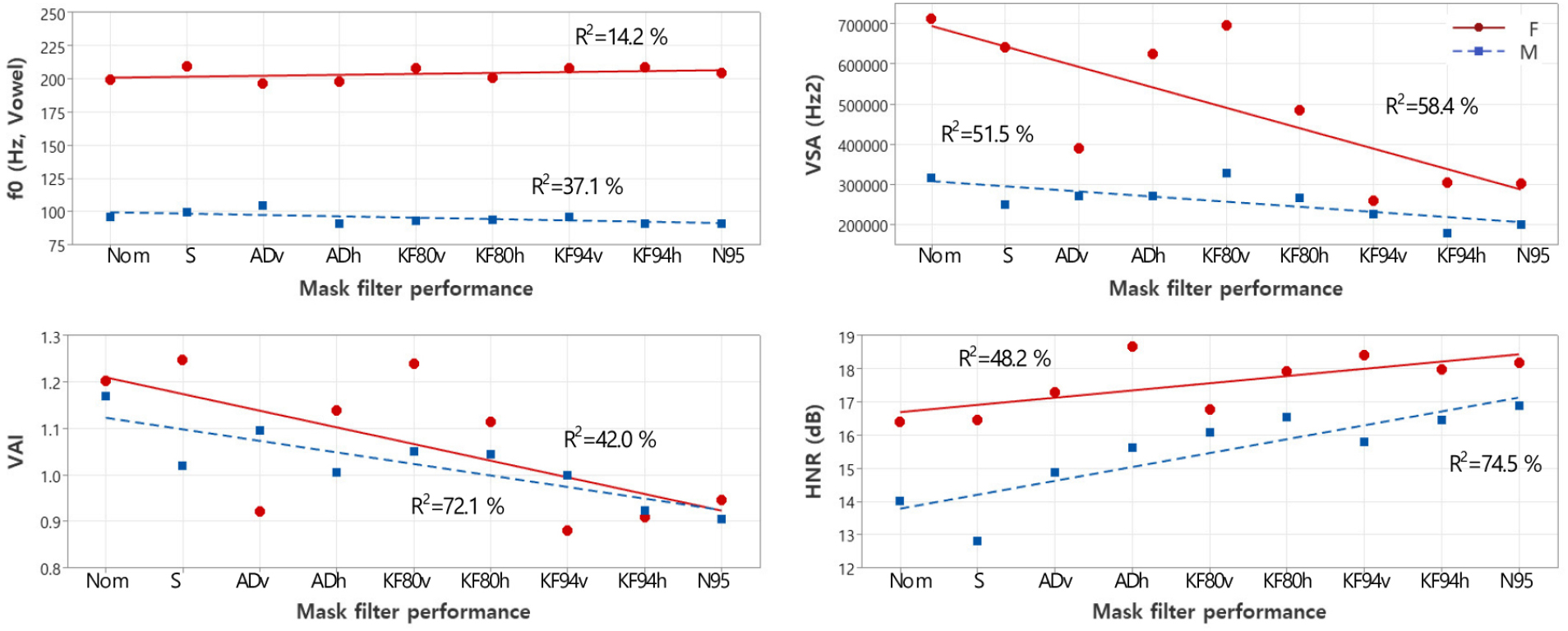
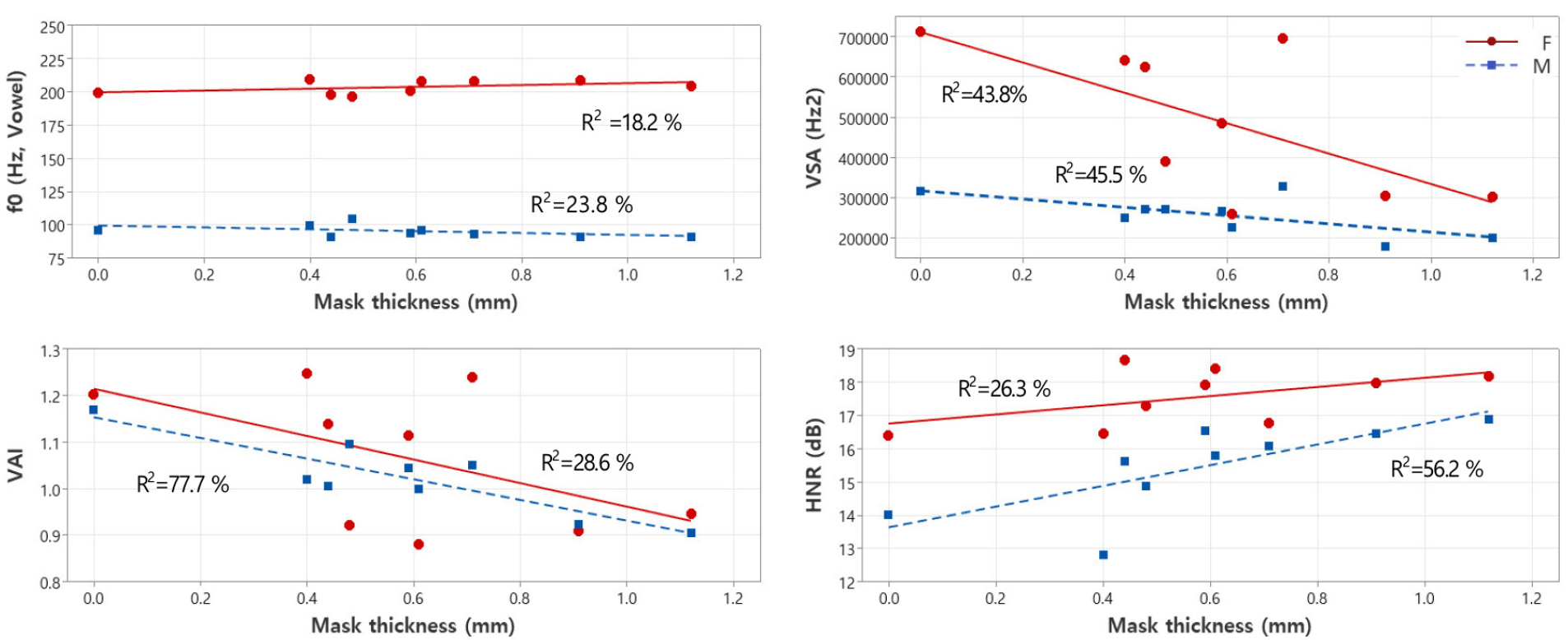
Figs. 3 and 4 show the tendencies of F0, HNR, VSA, and VAI according to mask filter performance and mask thickness, respectively. The mean F0 was not dependent on the face mask filter performance. The male speaker tended to have higher R2 values for HNR, and VAI based on face mask filter performance than the female speaker. The R2 values in Fig. 3 were all higher than those in Fig. 4. Therefore, the filtration properties of the mask appear to have a more substantial effect compared to mask thickness, affecting both male and female participants.
3.2 Spectral and cepstral analysis
The F0, SL, L/H ratio, and CPP of the eight phonetically balanced word lists were significantly affected by face masks, as shown in Table 4. Wearing a face mask considerably altered the acoustic parameters, with the effect size, L/H ratio, SL, and CPP exhibiting noticeable changes in that respective order. Table 5 lists the mean values, standard deviations, and Tukey’s post hoc results of the spectral and cepstral analyses. The mean F0 of female speaker decreased with face masks, whereas that of male speaker showed no statistically significant difference. The L/H ratio increased with increasing face mask thickness for both female and male speakers. For female speakers, the SL and CPP increased with increasing face mask thickness. However, for male speakers, these two parameters decreased with increasing face mask thickness. The mean speech level of the male speaker without face masks was 4.2 dBA greater than that of the female speaker.
Table 4.
ANOVA on the spectral and cepstral data.
Table 5.
F0, SL, L/H ratio with cut-off frequency of 4 kHz, CPP for the KS-MWL lists.
Fig. 5 shows the one-third octave band spectra of the speech levels. For the female speaker, the spectral energies below and above 3,150 Hz according to the face mask showed different patterns based on the no-mask spectrum. The spectral energy below 3,150 Hz with face masks was greater than that without face masks.
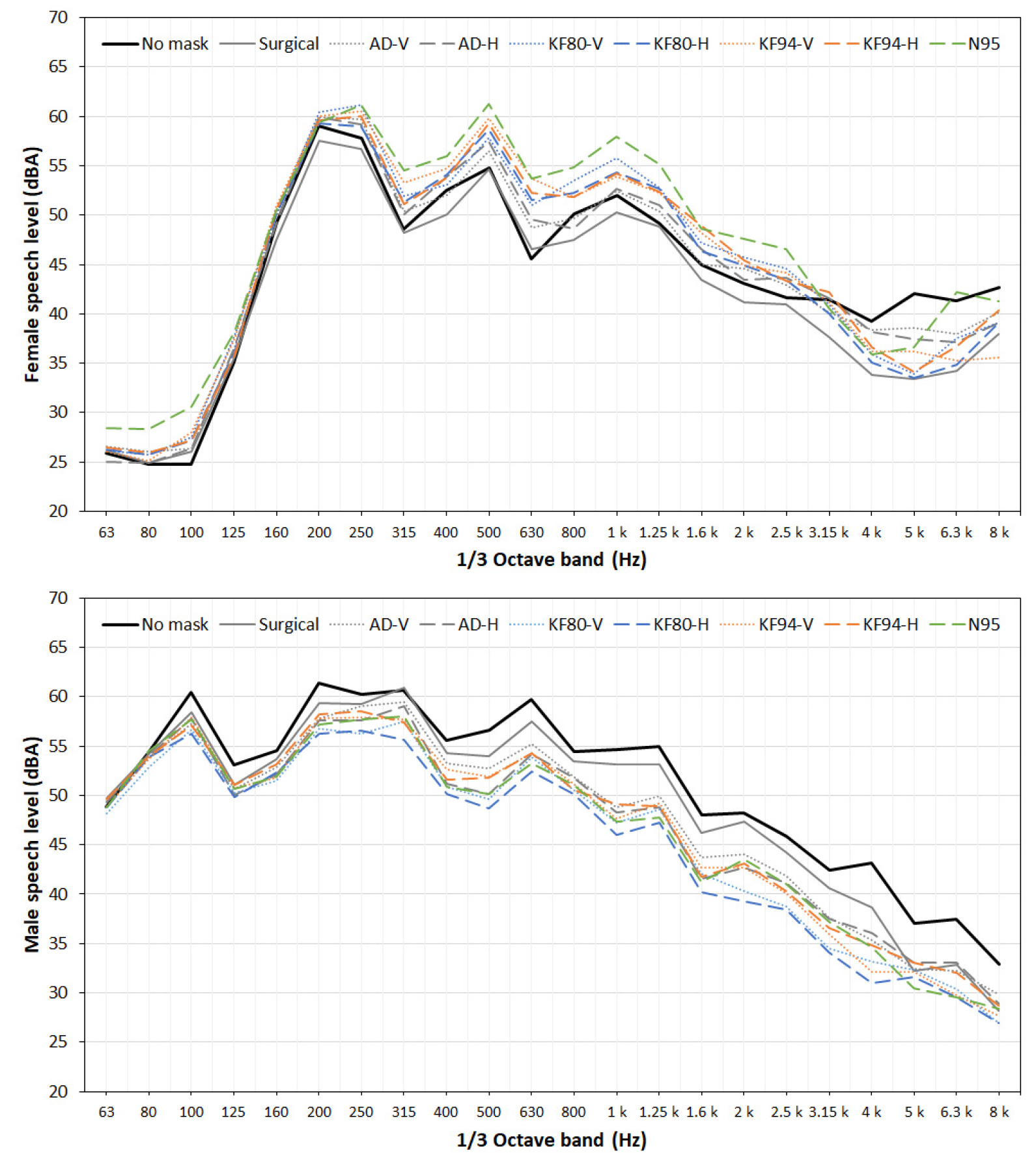
However, the spectral energy above 3,150 Hz with face masks was lower than that without face masks, except for the surgical mask. The male speaker showed no such reversal in speech spectra. The female voice had two adjacent fundamental peaks at approximately 200 and 220 Hz. Therefore, the change in her F0 may not have been caused by face masks.
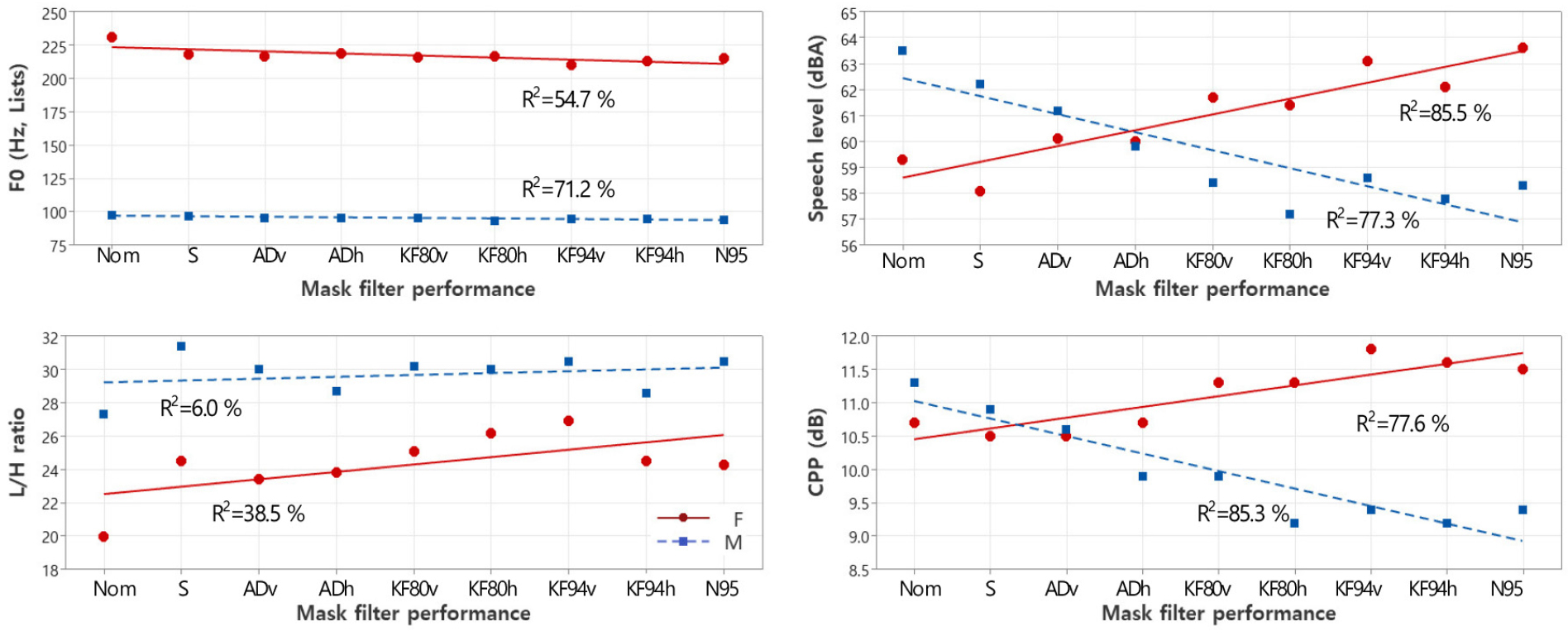
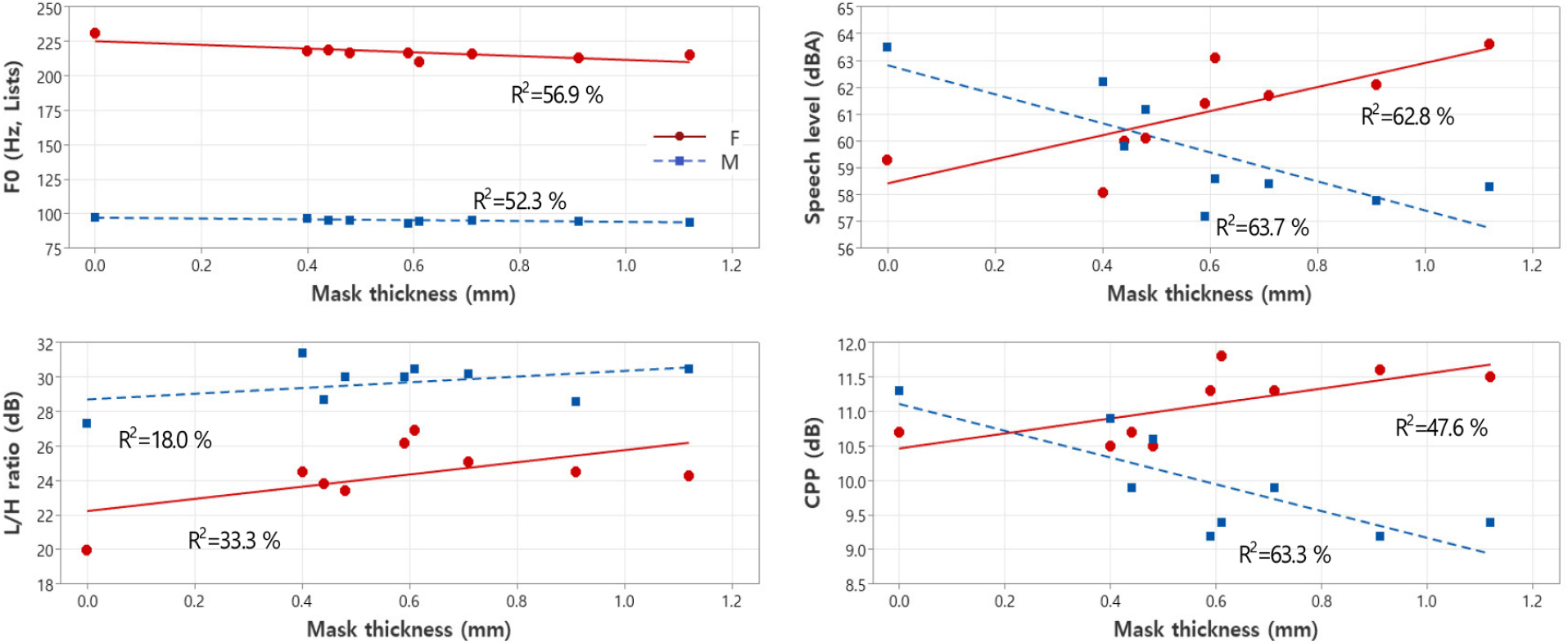
Figs. 6 and 7 similarly show the trends of F0, speech level, L/H ratio, and CPP of the word lists according to mask filter performance and mask thickness, respectively. Gender-based differences were clearly observed in SL and CPP. The filter properties of the masks had a more pronounced impact than mask thickness for both male and female subjects in Figs. 6 and 7. This observation aligns with the findings from the vowel analysis presented in Figs. 3 and 4.
IV. Discussion
4.1 Face masks like low-pass filters
In the vowel analysis, F0 was not affected by mask thickness, but HNR increased with increasing face mask filter performnance and mask thickness. It can be seen that when the additional noise caused by aperiodic vocal fold vibration is blocked by the mask, the acoustic noise gets attenuated. These results are consistent with those reported by Gojayev et al.,[12] Nguyen et al.,[14] McKenna et al.,[15] and Geng et al..[17] The VSA and VAI values decreased as mask thickness increased. This is consistent with the findings of McKenna et al..[15] Because the VSA tended to show a larger VSA during clear speech, the female voice was clearer than the male voice, even under the no-mask condition. The VAI value is an index related to speech intelligibility and tends to decrease as the vowels become centralized. Thus, when wearing a mask, there is a decrease in VSA and VAI because only the low-frequency sounds pass through the mask.
In the word list analysis, the L/H ratio (= 4 kHz) increased owing to the reduced high frequency caused by the face mask for the female and male speakers.
4.2 Speech levels and CPPs due to face masks
Opposite trends were observed between the male and female speaker in terms of SLs and CPPs. For the male voice, the SL and CPPs decreased with increasing face mask filter performnance and mask thickness, whereas for the female voice, the SL and CPPs increased.
The results for the female voice are consistent with those of McKenna et al.,[15] as previous studies have shown that CPP measures depend on voice intensity[28,29] predicting vocal effort.[30] The reverberation time of a room influences the vocal load.[31] In an anechoic chamber where speech recording was conducted in this study, vocal effort may have been greater for the female speaker whose speech level was lower than the male speaker.
By contrast, no vocal effort was found for the male speaker, regardless of the presence or thickness of the mask. His speech level without a mask was 63.5 dBA, and wearing a face mask did not increase his speech levels.
These results suggest that (1) the vocal effort of a person who does not have strong vocal intensity, such as women and children, may increase when wearing a face mask, and (2) reverberation time can be considered a risk factor for speakers, particularly occupational voice users, in masked speech situations.
4.3 Limitations and future work
First, we tested only two voices from professional actors. However, their voice quality for standard Korean pronunciation was reliable based on their professional experience. It is recommended that the number of men and women would be expanded to generalize the effects of face masks on speech in future study.
Second, the vocal effort differed between male and female voices in this study. A cross-check through self-evaluation of the voice load, fatigue, and effort before and after collecting voice samples is necessary to fully understand the vocal effort.
Third, /a/, /i/, and /u/ of the vowel triangle were analyzed, and /e/ and /o/ could be added to the vowel pentagram analysis to determine the acoustic properties of the vowels according to the face mask. In future research, we would like to examine the changes in detail and to add an auditory perception evaluation of the distortion of consonants and vowels during masked speech through a speech intelligibility test or speech acceptability test from the listener's perspective.
Fourth, KS-MWL was used as the speech sample in this study. A connected-speech sample such as sentences that are everyday utterances through natural breathing is recommended for further studies.
Fifth, this study did not account for potential variations in vocalization caused by restricted mouth movement due to the tension exerted by the mask strings. For future research, it is advisable to conduct acoustic analyses that take into consideration different mask-related variables that could impact speech production.
V. Conclusions
In this study, the presence or filer performance of a face mask was found to affect speech acoustic parameters according to the speech characteristics. Face masks attenuated the high-frequency range, resulting in decreased VSA and VAI scores and an increased L/H ratio in all voice samples. This can result in lower speech intelligibility. However, the degree of increment and decrement was based on the voice characteristics. For female speakers, the SL and CPP increased with increasing face mask thickness. However, for male speakers, these two parameters decreased with increasing face mask thickness. Face masks provoked vocal effort when the vocal intensity was not sufficiently strong, or the environment had less reverberance. Further research needs to be conducted on the vocal efforts induced by face masks to overcome acoustic modifications when wearing masks.
