

I. 서 론
II. 제안 방법
2.1 트랜스포머 기반 도메인 적대적 훈련
2.2 동적 가중 손실을 사용한 도메인 적대적 훈련 방법
III. 실험 및 결과
3.1 실험 데이터
3.2 실험 설정
3.3 실험 결과
IV. 결 론
I. 서 론
음성인식 기술이 발전하면서 제조, 교육, 언어 치료 등 다양한 분야에 음성인식이 도입되고 있다. 최근에는 다양한 키즈 콘텐츠가 생겨나면서 어린이를 대상으로 하는 음성인식 서비스도 증가하고 있다. 하지만 어린이 음성인식은 성인에 비해 인식 성능이 낮아 추가 연구가 필요한 분야이다.[1] 어린이의 불분명한 발음 등의 이유가 있지만, 성인에 비해 어린이 음성 데이터를 획득하기 어렵다는 점이 큰 이유 중 하나이다.[2] 따라서, 기존 어린이 음성인식 연구들은 성인의 음성 데이터를 추가로 사용하여 어린이 음성인식 성능을 개선하고자 하였다. 하지만 성인 데이터 사용의 효과를 더 높이기 위해서는 성인과 어린이 음성 간 음향학적 차이를 극복해야 한다.[3] 성인에 비해 어린이의 성도 길이가 짧기 때문에 음의 높낮이, 포먼트 등에서 음향학적 차이가 발생한다.[3,4] 화자의 연령에 따른 음향학적 차이를 극복하기 위해, 기존 연구들은 성인과 어린이 사이 음향학적 다양성을 일반화하기 위한 방법을 시도하였다. 예로서 화자 적응에서 사용하는 Vocal Tract Length Normalization(VTLN)과 Constrained Maximum Likelihood Linear Regression (CMLLR)을 적용한 음성인식 모델이 제안되었다.[5,6,7] 또한, 도메인 적대적 훈련 방식을 도입하여 성인과 어린이의 음향학적 차이를 효과적으로 줄일 수 있음을 확인하였다.[3,8] 어린이 음성에 대한 전사 데이터 없이 비지도 도메인 적대적 훈련하는 방식[8]과 adversarial loss를 사용한 지도 도메인 적대적 훈련 방식[3]이 연구되었다.
이전 어린이 음성인식 연구에서 지도 도메인 적대적 훈련을 사용한 경우, 성인과 어린이 간 데이터 비대칭성이 적은 상태에서 실험을 진행하였다.[3] 하지만 실제로 성인과 어린이 음성 데이터의 양은 불균형을 이루고 있다. 한국지능정보사회진흥원에서 운영하는 국내 공개 데이터 AI Hub에서도 음성 시간 기준으로 성인 데이터가 어린이 대비 약 6.6배 많다(성인: 약 49,950 h, 어린이: 약 7,525 h). 따라서, 어린이 대비 구하기 쉬운 성인 데이터를 더 많이 활용하여 어린이 음성인식 성능을 개선할 수 있는지에 대한 연구가 필요하다.
본 논문에서는 어린이보다 성인 데이터가 많은 데이터 불균형 환경에서 성인 데이터를 추가로 사용하여 어린이 음성인식 성능을 개선하는 방법을 새롭게 제안한다. 제안하는 방법은 어린이 음성인식 성능을 확보하기 위해, 제한된 어린이 음성 데이터에 비해 구하기 쉬운 성인 음성 데이터를 추가한다. 그리고 사용하는 성인 음성 데이터의 양이 많아질수록 발생하는 데이터 불균형 환경에서 연령 간 음향학적 차이를 줄이기 위한 방법으로 dynamically weighted loss[9,10,11] 기반 도메인 적대적 훈련 방식을 제안한다. 미니 배치 내 성인과 어린이 음성 데이터 빈도 기반으로 가중치를 조절하여 소수 클래스인 어린이 음성에 대한 도메인 적대적 훈련 효과를 높이고자 하였다. 제안하는 방법의 효용성은 NHN 다이퀘스트에서 구축한 자유대화 음성 데이터를 사용하여, 성인과 어린이 데이터셋을 단순히 합하여 훈련하는 방법과 기존 도메인 적대적 훈련 방법과의 성능 비교를 통해 검증하였다. Proxy A-distance(PAD)[12]를 통해 성인과 어린이 도메인 간 유사도를 수치화하여 확인하였고, 음성인식 성능은 문자 오류율(Character Error Rate, CER) 기준으로 측정하여 비교하였다.
본 논문의 구성은 다음과 같다. 2장에서는 어린이 음성인식 성능을 높이기 위한 동적 가중 손실 기반 도메인 적대적 훈련 방법을 제안한다. 그리고 3장에서는 제안 방법을 실험을 통해 검증하고, 4장에서 본 논문의 결론을 맺는다.
II. 제안 방법
본 논문은 성인과 어린이 데이터 불균형 환경에서 어린이 음성인식 성능을 높이기 위한 방안으로 dynamically weighted loss를 사용한 도메인 적대적 훈련 방식을 제안한다. 이전 연구에 따르면, 어린이 음성 데이터가 제한적인 환경에서 성인의 음성 데이터양이 많아질수록 어린이 음성인식 성능이 높아진다.[1] 하지만 성인 데이터양을 늘려 도메인 적대적 훈련하는 경우, 성인과 어린이 간 데이터 불균형이 발생한다. 이로 인해, 소수 클래스인 어린이 음성에 대한 분류 성능이 저하되어 도메인 적대적 훈련 효과가 감소할 수 있다. 따라서, 본 논문은 데이터 불균형을 해소하기 위한 방안으로 트랜스포머 기반 Fig. 1 모델을 제안한다.
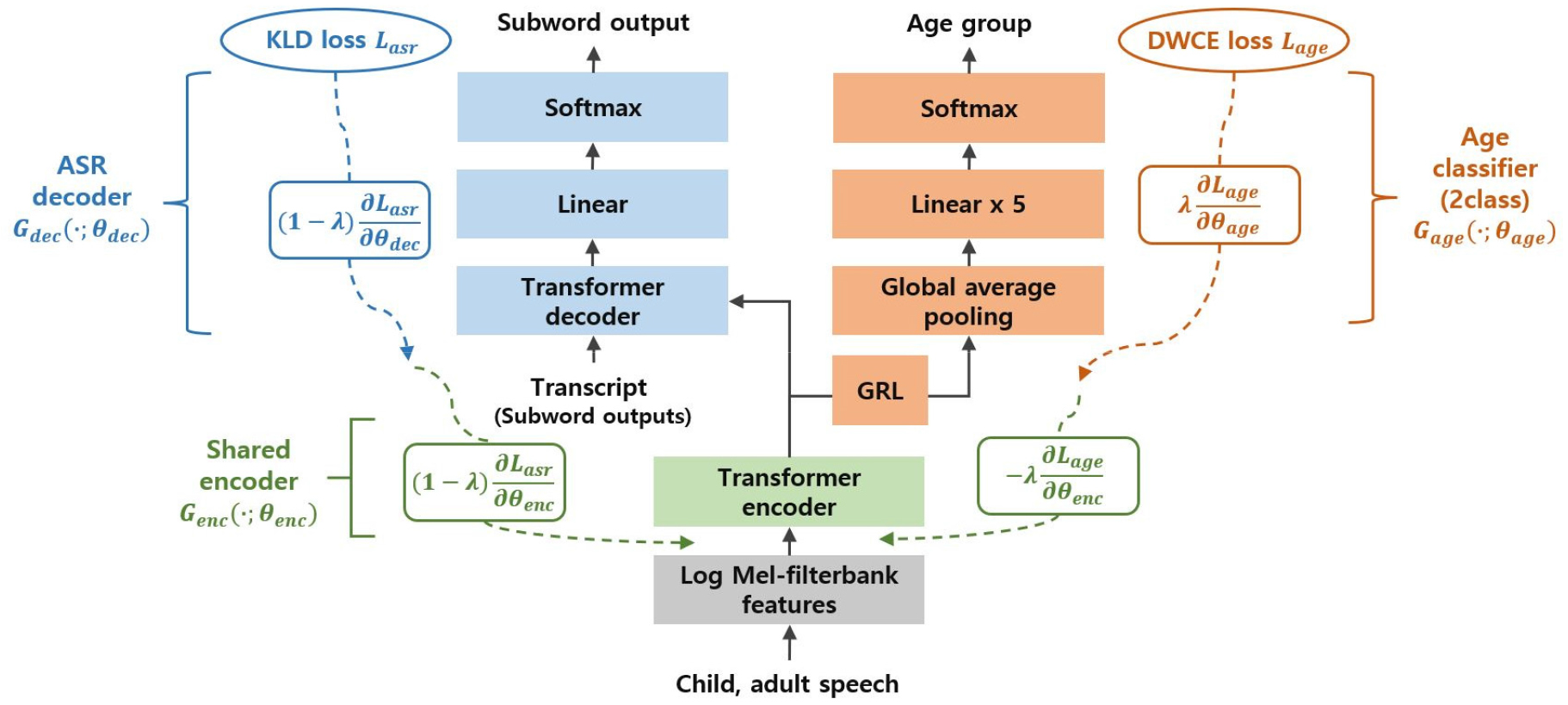
2.1 트랜스포머 기반 도메인 적대적 훈련
제안하는 모델은 크게 공유 인코더, ASR 디코더, 연령 분류기 3가지로 구성되어 있다. 먼저, 입력된 음성에 대해 80차 로그 멜-필터뱅크 특징을 추출하여 공유 인코더 의 입력으로 사용한다. 그리고 공유 인코더의 출력을 참조하는 ASR 디코더 와 입력으로 사용하는 연령 분류기 를 multi-task learning 구조로 구성하고, 공유 인코더와 연령 분류기 사이에 Gradient Reversal Layer(GRL)[13]을 추가하여 연령 정보를 제외한 음성 특징 기반으로 subword 단위 음성인식을 수행하도록 설계하였다.
제안하는 모델의 공유 인코더와 ASR 디코더는 각각 트랜스포머[14] 모델을 사용하였다. 기계 번역에서 처음 제안된 트랜스포머는 현재 음성인식에서도 우수한 성능을 보이는 신경망 모델이다.[15,16] Fig. 2는 트랜스포머 모델 구조로 왼쪽은 인코더, 오른쪽은 디코더를 나타낸다.
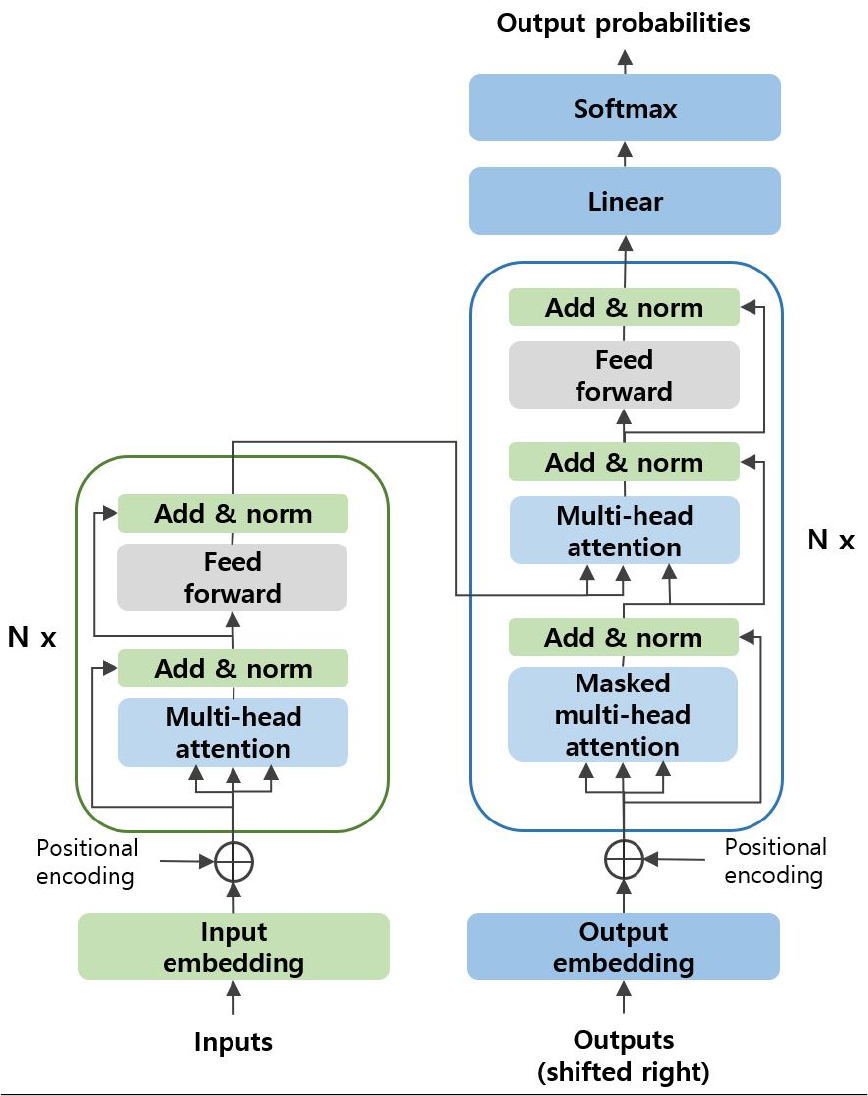
공유 인코더에 80차 로그 멜-필터뱅크 특징을 입력하면, 입력 임베딩을 생성하고 위치 정보를 더하여 N개로 구성된 인코더 블록에 입력된다. 트랜스포머 인코더 블록에는 Multi-head attention이 있어, 병렬로 self-attention을 수행하면서 입력 음성 특징 벡터 간 연관성을 다양하게 훈련할 수 있다.
ASR 디코더는 훈련 과정에서 음성에 대한 전사 데이터를 입력으로 사용한다. Subword 단위의 토큰들로 구성된 입력 텍스트에 <sos/eos> 토큰을 추가한 후, 임베딩과 순서 정보를 더하는 과정을 거쳐 N개로 구성된 디코더 블록에 입력한다. 디코더 블록에서는 Masked multi-head attention을 통해 전사 데이터의 토큰을 하나씩 순차적으로 예측하는 과정을 병렬로 훈련한다. 이를 통해 정답 토큰을 포함한 미래 토큰들은 제외하고, 이전 토큰 간 연관성을 효과적으로 학습할 수 있다. 그리고 Multi-head attention에서 인코더의 출력을 참조함으로써, 연령에 강인한 음성 특징과 이전 토큰들의 언어 정보를 기반으로 다음에 출력될 토큰을 예측하도록 훈련한다. 최종 디코더 블록의 출력은 linear layer와 softmax 함수를 거쳐 다음 subword 토큰에 대한 확률 분포로 출력된다.
마지막으로, 연령 분류기는 5개의 linear layer와 Rectified Linear Unit(ReLU) 함수, 그리고 softmax 함수로 구성되어 있다. 공유 인코더의 출력을 Global average pooling을 사용하여 평균값으로 압축하고, 연령 분류기에 입력하여 성인과 어린이 두 연령 그룹으로 분류한다. 그리고 기존 도메인 적대적 훈련[17]과 같이 공유 인코더와 연령 분류기 사이의 GRL을 통해 역전파 과정에서 gradient에 -1을 곱하여 학습함으로써 공유 인코더에서는 연령 정보를 제외한 음성 특징을 훈련할 수 있다.
2.2 동적 가중 손실을 사용한 도메인 적대적 훈련 방법
성인과 어린이 데이터 간 불균형 환경에서 도메인 적대적 훈련을 하기 위해 본 논문에서 제안하는 최종 목적 함수는 Eq. (1)과 같다.
목적함수 는 ASR 디코더와 연령 분류기를 통해 계산되는 손실 함수 와 로 구성되어 있다. 는 각각 공유 인코더와 ASR 디코더, 그리고 연령 분류기 네트워크의 파라미터이다. 𝜆는 음성인식과 도메인 적대적 훈련의 비율을 조정하기 위한 hyperparameter로, 0과 1 사이의 값을 가진다. 로는 Kullback-Leibler divergence[18] loss를 사용하였고, 는 dynamic weighted cross entropy loss를 사용하였다. 도메인 적대적 훈련에서 도메인 분류기의 손실 함수는 일반적으로 cross entropy loss를 사용한다.[19] 하지만, 데이터 불균형 환경에서 cross entropy loss를 도메인 분류기 손실 함수로 사용하는 경우, 다중 클래스 위주로 도메인 분류 훈련이 진행될 수 있다. 도메인 적대적 훈련은 도메인 분류기에서 균형 있는 분류 학습이 진행되어야 GRL을 통해 도메인 정보를 제외한 특징을 추출할 수 있다. 따라서, 분류 테스크에서 클래스 불균형 문제를 해결하기 위해 사용하는 손실 함수의 가중치 조절 방식[9,10,11]을 도메인 적대적 훈련에 적용하고자 하였다. 본 논문에서는 많은 성인 데이터를 사용하며 발생하는 데이터 불균형 환경에서 도메인 적대적 훈련 성능을 높이기 위해, 미니 배치 내 성인과 어린이 클래스 빈도 기반으로 cross entropy loss의 클래스 가중치를 조절하도록 설계하였다.
각 미니 배치의 손실 함수 는 이전 분류 관련 연구[10]의 동적 가중 손실 함수를 참고하여 Eq. (3)과 같이 설정하였다. 여기서 와 는 각각 one-hot encoding 방식으로 표현된 정답 레이블과 연령 분류기의 출력값으로, 미니 배치 내 번째 데이터의 번째 클래스 값을 의미한다. 은 미니 배치 사이즈, 는 클래스 수를 의미하며 는 2로 설정하였다. 그리고 와 는 각각 미니 배치 내 번째 클래스에 대한 가중치와 빈도수이다. 빈도수가 큰 클래스에는 작은 가중치를, 빈도수가 작은 클래스에는 큰 가중치를 부여하도록 설계하였다. 이를 통해 데이터 불균형 환경에서 소수 클래스인 어린이 음성에 대한 분류 성능을 높여 도메인 적대적 훈련 효과를 향상하였다. 그리고 는 마지막에 가중치의 합으로 나누어 가중 평균으로 나타내었다.[20]
최종적으로 제안하는 모델의 파라미터는 아래와 같은 수식으로 갱신된다. 𝛼는 학습률을 나타낸다.
위 훈련 과정을 통해, ASR 디코더와 연령 분류기는 각각 와 를 최소화하는 방향으로 학습되며, 공유 인코더는 는 최소화하지만 는 최대화하는 방향으로 학습된다. 본 논문에서 제안하는 방법을 통해, 공유 인코더는 데이터 불균형 환경에서도 연령에 강인한 음성 특징을 추출할 수 있다.
III. 실험 및 결과
3.1 실험 데이터
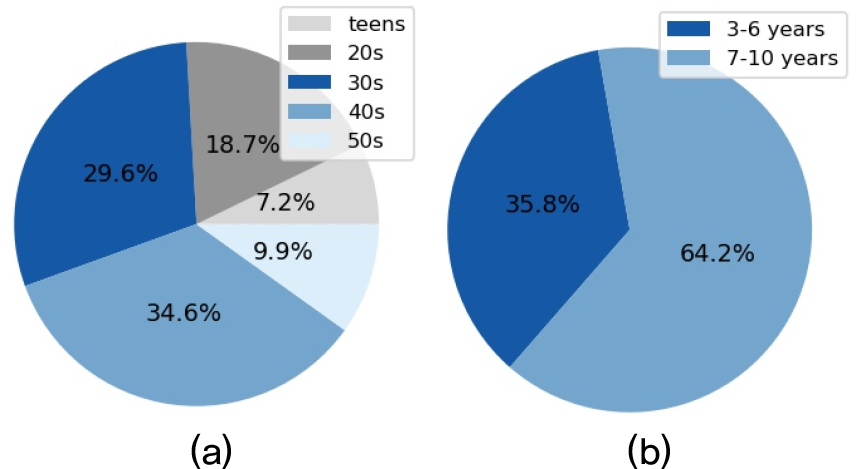
본 논문의 실험을 위해 NHN 다이퀘스트에서 구축한 자유대화 음성 데이터 중 성인과 어린이 카테고리의 일부 데이터셋을 사용하였다.[21,22] 성인 음성 데이터는 10대에서 50대 연령 화자의 발화로 구성되어 있고, 어린이 음성 데이터는 3세에서 10세 연령 화자의 발화로 구성되어 있다. 본 연구는 성인 음성 데이터 증가에 따라 변화하는 어린이 음성인식 성능을 확인하기 위해, 어린이 데이터셋은 고정하고, 성인 음성 데이터 수를 증가하면서 실험을 진행하였다. 훈련에 사용한 성인 음성 데이터셋을 구분하기 위해, 데이터셋 명칭을 지정하였고 각 데이터셋의 학습, 검증, 테스트 데이터 발화 수를 Table 1에 기술하였다. 그리고 성인과 어린이 데이터의 연령별 분포는 Fig. 3에 나타내었다.
Table 1.
Summary of the dataset.
3.2 실험 설정
본 연구에서는 ESPnet 툴킷[23]을 사용하여 제안하는 종단간 음성인식 모델을 구현하였다. 제안 모델은 크게 공유 인코더, ASR 디코더, 연령 분류기로 구성되며, 공유 인코더와 ASR 디코더는 트랜스포머 모델을 사용하였다. 실험에 사용한 트랜스포머 모델에 대한 설정은 Table 2에 나타내었다. 그리고 연령 분류기는 뉴런 수 64, 64, 32, 32, 2개로 구성된 5개의 linear layer와 ReLU 함수로 구성하였다.
Table 2.
Hyperparameters of transformer model.
훈련을 위해 Adam optimizer와 warm-up scheduler (25,000 warm-up steps)를 사용하였으며, 배치 사이즈는 128, 결과 스무딩은 0.1로 설정하고 50 epoch 학습하였다. 그리고 도메인 적대적 훈련을 위한 손실 함수 파라미터 𝜆 값은 실험을 통해, 0.2로 설정하였다. 또한, 모델 훈련 사전 단계에서 SentencePiece[24]를 사용하여 텍스트 레이블을 subword 단위의 5,000개 토큰으로 나누어 훈련에 사용하였다.
3.3 실험 결과
제안하는 방법을 검증하기 위해 성인 학습 데이터양을 조정하며, 성인과 어린이 데이터셋을 단순히 합하여 훈련하는 방법(Mix)[1]과 일반적으로 사용되는 cross entropy loss 기반 도메인 적대적 훈련 방법(DAT)[25,26] 과의 비교를 수행하였다. 어린이 음성 데이터는 Table 1에서 기술한 child-40 k 데이터를 사용하였고, 성인 데이터는 adult-40 k에서 adult-320 k까지 데이터양을 증가하면서 훈련하였다. 각 방법의 음성인식 성능은 문자 오류율(Character Error Rate, CER)을 이용하여 평가하였다. CER은 수식 Eq. (7)과 같이 정의된다.
은 정답 텍스트 문자 수이고 는 각각 음성인식 결과에서 잘못 대체, 삭제, 삽입된 문자 수를 의미한다. 본 논문의 실험 결과는 Table 3에 정리하였다.
Table 3.
Children’s speech recognition CER (%) of NHN diquest dataset.
| Method | Train data ratio (Adult:Child) | ||||
| 1:1 | 2:1 | 4:1 | 6:1 | 8:1 | |
| Mix | 12.2 | 10.9 | 10.8 | 10.8 | 10.6 |
| DAT | 11.8 | 10.7 | 10.5 | 10.9 | 10.9 |
| Proposed | 11.8 | 10.6 | 10.4 | 10.3 | 10.4 |
먼저, 성인과 어린이 학습 데이터 비율이 1:1로 동일한 환경에서 DAT 하는 경우, Mix 대비 0.4 %p 음성인식 성능 개선되었다. 그리고 데이터 불균형이 없는 경우, DAT와 Proposed 방법은 동일한 음성인식 성능을 보였다.
다음, 성인 학습 데이터양을 추가하며, 3가지 방법에 대한 어린이 음성인식 성능을 비교하였다. Mix 결과를 살펴보면, 성인의 음성 데이터가 증가할수록 어린이 음성인식 성능이 개선된다.[1] 그리고 DAT를 적용하면, 성인과 어린이 학습 데이터 비율이 4:1인 경우까지는 연령 간 음향학적 특징 차이를 줄여 음성인식 성능이 향상됨을 확인할 수 있다. 하지만, DAT는 성인과 어린이 학습 데이터 비율이 6:1이 되면 Mix와 Proposed 방법에 비해 어린이 음성인식 성능이 낮아진다. 반면, Proposed 방법은 데이터 불균형 환경에서도 Mix와 DAT 대비 개선된 성능을 보임을 CER을 통해 확인할 수 있다. 성인과 어린이 학습 데이터 비율이 6:1인 경우에는 Mix와 DAT 대비 각각 0.5 %p, 0.6 %p 개선된 성능을 보였고, 8:1에서도 Mix와 DAT 대비 0.2 %p, 0.5 %p 성능 개선되었다. Proposed 방법은 데이터 불균형 환경에서 성인과 어린이 간 음향학적 차이를 효과적으로 감소시키고, 이로 인해 어린이 음성인식 성능이 향상됨을 예측할 수 있다.
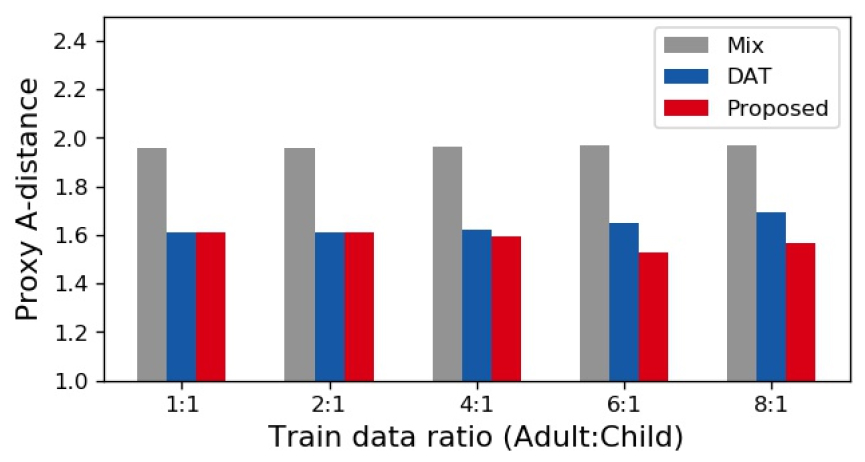
실제로 제안하는 방법을 통해 성인과 어린이 간 음향학적 차이가 감소하였는지 확인하기 위하여, 도메인 간 음성 특징 유사도를 Proxy A-distance(PAD)[12]로 측정하여 Fig. 4에 나타내었다. PAD는 도메인 간 불일치 정도를 나타내기 위해 제안된 척도이며, Eq. (8)과 같이 정의된다.
𝜀는 도메인을 분류하도록 훈련된 linear Support Vector Machine(SVM)의 일반화 오차로, PAD가 작을수록 연령 무관 음성 특징 추출 성능이 높다고 할 수 있다. Fig. 4를 살펴보면, 성인과 어린이 도메인 간 학습 데이터 비율이 비슷한 경우에는 DAT와 Proposed 방법의 PAD가 유사하지만, 데이터 비대칭성이 커질수록 DAT보다 Proposed 방법의 PAD가 작다. 따라서, 성인과 어린이 데이터 비대칭 환경에서 Proposed 방법을 통해 성인과 어린이 간 음향학적 차이를 효과적으로 줄일 수 있음을 알 수 있다.
위에서 측정한 PAD를 시각화하여 확인하기 위해, 공유 인코더의 출력 임베딩을 t-SNE[27] plot으로 나타내었다. Fig. 5의 상단과 하단은 각각 성인과 어린이 학습 데이터 비율을 1:1과 6:1로 훈련한 공유 인코더의 출력 임베딩 t-SNE plot이다. 어린이 대비 성인 음성 데이터를 6배 추가하고 Proposed 방법으로 훈련한 Fig. 5(f)의 경우, Fig. 5(b)와 (c)와 같이 성인과 어린이 음성 특징이 유사함을 확인할 수 있다.
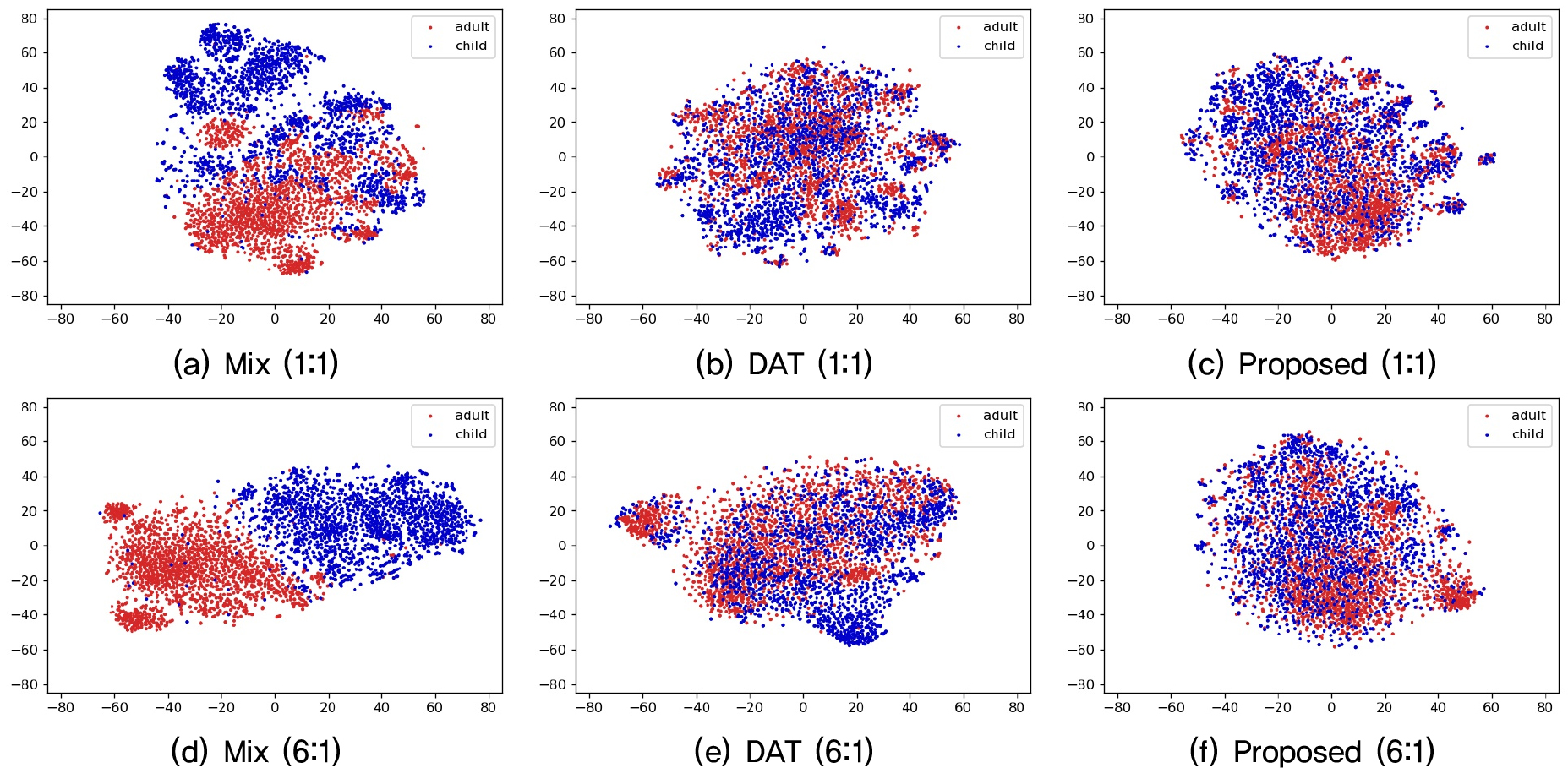
하지만, DAT 방법을 사용한 Fig. 5(e)는 Proposed 대비 어린이와 성인 음성 특징 분포가 상이하여 유사도가 낮음을 t-SNE plot에서도 확인할 수 있으며, 이는 어린이 음성 인식률 저하에 영향을 주는 것으로 판단된다.
본 논문의 실험 결과를 통해, 제안하는 방법은 성인과 어린이 음성 데이터 불균형 환경에서 두 도메인의 음성 특징 간 거리를 감소시키고, 어린이 음성인식 성능을 개선함을 확인하였다. 본 논문에서 실험한 데이터베이스의 경우, 성인 데이터를 어린이 데이터 대비 6배 추가하고 제안한 도메인 적대적 훈련한 경우, 어린이 음성인식 CER이 10.3 %로 가장 낮았다. 이는 어린이와 동일한 양의 성인 데이터를 추가하고 기존 도메인 적대적 훈련만 진행한 경우와 비교하여, 상대적으로 12.7 % 성능 향상된 결과이다. 성인 학습 데이터양을 늘리고 제안된 도메인 적대적 훈련함으로써 어린이 음성인식 성능이 개선됨을 확인할 수 있었다.
IV. 결 론
본 논문에서는 성인과 어린이 음성 데이터 불균형 환경에서 어린이 음성인식 성능을 개선하기 위한 도메인 적대적 훈련 방법을 제안하였다. 학습에 사용되는 성인 데이터양이 증가하면서 발생하는 데이터 불균형 환경에서 성인과 어린이 음성 간 음향학적 특징 차이를 줄이기 위해 dynamically weighted loss를 사용한 트랜스포머 기반 도메인 적대적 훈련을 제안하였다. 제안하는 방법의 효용성을 검증하기 위해 성인 학습 데이터의 양을 추가하며 실험하였다. 실험 결과, 학습 데이터 내 연령 간 비대칭성이 발생하는 모든 조건에서 제안하는 방법이 기존 도메인 적대적 훈련 방식보다 높은 어린이 음성인식 성능을 보였다. 어린이 음성 인식률은 어린이 대비 성인 데이터를 6배 추가하고 제안하는 도메인 적대적 훈련한 경우, 문자 오류율 10.3 %로 가장 좋은 성능을 나타내었다. 이를 통해, 성인 학습 데이터의 양을 증가시키고 제안된 도메인 적대적 훈련함으로써 어린이 음성인식 성능을 높일 수 있음을 확인할 수 있었다.
