

I. 서 론
최근 우리가 살아가는 실생활에서도 실제적인 음성 신호처리 시스템이 필요한 환경이 늘어나면서 음성 향상 기술에 대한 연구가 주목 받고 있다. 실제로 음성 신호처리 기술에서 음성 향상을 위한 다양한 방법들이 시도되었다. 이러한 방법들 중에는 스펙트럼 차감법,[1] Wiener filtering,[2] soft decision 추정,[3] 최소 평균 자승 오차(MMSE, Minimum Mean Square Error)[4] 등이 주로 사용되고 있다. 위의 방법들은 구현상의 편리함과 다양한 배경 잡음에 적용 가능한 이점을 가지고 있으며, soft decision에 근거한 음성 향상 방법이 뛰어난 성능을 가진다는 것이 알려져 있다. 특히 global soft decision 방법에서는 기존의 지역 음성 부재 확률(LSAP, Local Speech Absence Probability)과 매 프레임에서 하나의 값으로 표현되어지는 전역 음성 부재 확률(GSAP, Global Speech Absence Probability)이 결합되어 통계적으로 견실한 음성 부재 확률을 새롭게 도출하였다.[5]
하지만 음성 부재 확률을 구하기 위해 기존의 통계적 가정을 바탕으로 고정된 음성 부재와 존재에 대한 a priori 확률값의 비(![]() )를 적용한 것은,[3-5] 다양한 음성 환경 변화에서 한계를 나타낸다. 특히 비정상적인 잡음 환경을 고려하였을 때, 잡음이 음성 신호를 간섭하면 음성의 꼬리와 같은 약한 음성 신호를 추정하기 힘들다. 이를 극복하기 위해 Malah가 제안한 음성 존재 부정확성 추적 방법은 기존의 soft decision에서 음성 부재 확률을 구할 때 사용되는
)를 적용한 것은,[3-5] 다양한 음성 환경 변화에서 한계를 나타낸다. 특히 비정상적인 잡음 환경을 고려하였을 때, 잡음이 음성 신호를 간섭하면 음성의 꼬리와 같은 약한 음성 신호를 추정하기 힘들다. 이를 극복하기 위해 Malah가 제안한 음성 존재 부정확성 추적 방법은 기존의 soft decision에서 음성 부재 확률을 구할 때 사용되는 ![]() 값이 고정된 값이었던 것과는 다르게 프레임, 채널마다 입력 신호의 a posteriori SNR을 특정 임계값과 비교하여 음성인지 아닌지를 판별하여
값이 고정된 값이었던 것과는 다르게 프레임, 채널마다 입력 신호의 a posteriori SNR을 특정 임계값과 비교하여 음성인지 아닌지를 판별하여 ![]() 값을 다르게 적용하여 음성 부재 확률의 신뢰도를 높이는 방법으로 음성을 향상시켰다.[6] 또한 이 Malah의 음성 존재 부정확성 추적 방법에서 입력 신호가 음성인지 아닌지 여부를 판별할 때 사용된 a posteriori SNR을 대신하여, 잡음이 섞인 신호의 국부 에너지와 주어진 윈도우에서의 최소값 사이의 비를 특정 임계값과 비교하여 음성 유무를 판별 후
값을 다르게 적용하여 음성 부재 확률의 신뢰도를 높이는 방법으로 음성을 향상시켰다.[6] 또한 이 Malah의 음성 존재 부정확성 추적 방법에서 입력 신호가 음성인지 아닌지 여부를 판별할 때 사용된 a posteriori SNR을 대신하여, 잡음이 섞인 신호의 국부 에너지와 주어진 윈도우에서의 최소값 사이의 비를 특정 임계값과 비교하여 음성 유무를 판별 후 ![]() 값을 다르게 적용하여 음성을 향상시키는 방법도 있었다.[7]
값을 다르게 적용하여 음성을 향상시키는 방법도 있었다.[7]
본 논문에서는 기존의 global soft decision에서 음성 부재 확률(SAP, Speech Absence Probability)을 구할 때 사용되는 고정된 ![]() 값이나, 단순히 특정 파라미터 값을 임계값과 비교하여 몇 가지의 다른
값이나, 단순히 특정 파라미터 값을 임계값과 비교하여 몇 가지의 다른 ![]() 값을 적용했던 방법과는 달리, 직전 2 프레임에서의 음성 존재 여부와 스펙트럼 변이 값을 기반으로 한 세 가지의 상태 조건에 따른 시그모이드 형태(sigmoid type) 함수를 사용하여 모든 프레임마다 적응적으로 변화하는 각기 다른
값을 적용했던 방법과는 달리, 직전 2 프레임에서의 음성 존재 여부와 스펙트럼 변이 값을 기반으로 한 세 가지의 상태 조건에 따른 시그모이드 형태(sigmoid type) 함수를 사용하여 모든 프레임마다 적응적으로 변화하는 각기 다른 ![]() 값을 이끌어냄으로써 보다 견실한 음성 부재 확률을 추정하는 기법을 제안한다. 현재 프레임은 인접한 프레임들에 큰 영향을 받기 때문에 프레임 간 상관관계와 연산량을 고려하여 직전 2 프레임에서의 음성 존재 여부를 활용하였다.[9] 그리고 스펙트럼 변이는 이전 프레임 동안 예측된 평균 long-term 파워 스펙트럼과 현재 파워 스펙트럼의 차이다.[8] 즉, 직전 2 프레임이 모두 음성 존재일 경우와 그 이외의 경우를 구분하여,[9] 각각 프레임 간 스펙트럼 변이에 따라 증가하는 경우, 유지되는 경우, 감소하는 경우의 세 가지 경우에 대해
값을 이끌어냄으로써 보다 견실한 음성 부재 확률을 추정하는 기법을 제안한다. 현재 프레임은 인접한 프레임들에 큰 영향을 받기 때문에 프레임 간 상관관계와 연산량을 고려하여 직전 2 프레임에서의 음성 존재 여부를 활용하였다.[9] 그리고 스펙트럼 변이는 이전 프레임 동안 예측된 평균 long-term 파워 스펙트럼과 현재 파워 스펙트럼의 차이다.[8] 즉, 직전 2 프레임이 모두 음성 존재일 경우와 그 이외의 경우를 구분하여,[9] 각각 프레임 간 스펙트럼 변이에 따라 증가하는 경우, 유지되는 경우, 감소하는 경우의 세 가지 경우에 대해 ![]() 값을 적응적으로 변화하게 하여 보다 견실한 음성 부재 확률을 도출하는 새로운 알고리즘을 도입하였다.
값을 적응적으로 변화하게 하여 보다 견실한 음성 부재 확률을 도출하는 새로운 알고리즘을 도입하였다.
제안된 음성 향상 기법은 PESQ(Perceptual Evaluation of Speech Quality)와[10] Covl(composite measure) 방법을[11] 통해 평가하였고, 기존의 global soft decision 방법보다 향상된 결과를 나타내었다.
II. Global Soft Decision 개요
먼저 원래의 음성 신호 ![]() 에 잡음 신호
에 잡음 신호 ![]() 가 더해져서 오염된 음성 신호
가 더해져서 오염된 음성 신호 ![]() 를 만들었다고 가정한다. 음성 향상 기법에서 사용되고 있는 기본 가설
를 만들었다고 가정한다. 음성 향상 기법에서 사용되고 있는 기본 가설 ![]() 이 각각 음성의 부재와 존재를 나타낸다고 하면 다음과 같이 표현된다.
이 각각 음성의 부재와 존재를 나타낸다고 하면 다음과 같이 표현된다.
| (1) |
| (2) |
여기서 ![]() 그리고
그리고 ![]() 은 각각 입력 신호, 원래 음성 신호, 그리고 잡음 신호의 이산 퓨리에 변환(DFT, Discrete Fourier Transform) 계수를 나타내고,
은 각각 입력 신호, 원래 음성 신호, 그리고 잡음 신호의 이산 퓨리에 변환(DFT, Discrete Fourier Transform) 계수를 나타내고, ![]() 번째 프레임에서의
번째 프레임에서의 ![]() (=0,1,...,K-1)번째 주파수 성분이 된다.
(=0,1,...,K-1)번째 주파수 성분이 된다.
음성 신호와 잡음의 스펙트럼이 복소가우시안 분포를 따른다고 가정을 하면, 가설 ![]()
![]() 을 조건으로 한 확률밀도함수는 다음과 같이 주어진다.
을 조건으로 한 확률밀도함수는 다음과 같이 주어진다.
| (3) |
| (4) |
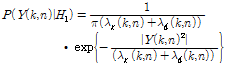
위에서 ![]() ,
, ![]() 는 각각 음성과 잡음의 분산을 나타낸다. 음성의 존재와 부재에 관한 가설을 바탕으로 주파수 채널별 지역 음성 부재 확률은 다음과 같이 구해질 수 있다.
는 각각 음성과 잡음의 분산을 나타낸다. 음성의 존재와 부재에 관한 가설을 바탕으로 주파수 채널별 지역 음성 부재 확률은 다음과 같이 구해질 수 있다.
| (5) |
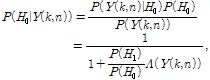
또한 한 프레임에서 음성 부재 확률은 현재 프레임의 관찰 결과를 기반으로 다음과 같이 구할 수 있다.
| (6) |
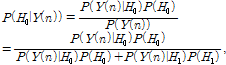
여기서 각 주파수 대역이 통계적으로 서로 독립이라고 가정하면 한 프레임에서의 음성 부재 확률을 다음과 같이 표현할 수 있다.
| (7) |
여기서 ![]() 은 음성 부재와 존재에 대한 a priori 확률값의 비로서
은 음성 부재와 존재에 대한 a priori 확률값의 비로서 ![]() 로 나타낼 수 있고,[5]
로 나타낼 수 있고,[5]![]() 는
는 ![]() 번째 주파수 채널에서의 우도비(likelihood ratio)로서 다음과 같이 나타낼 수 있다.
번째 주파수 채널에서의 우도비(likelihood ratio)로서 다음과 같이 나타낼 수 있다.
| (8) |
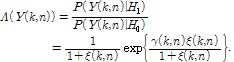
여기서 ![]() ,
, ![]() 이 되고,
이 되고, ![]() ,
, ![]() 는 각각 a priori SNR과 a posteriori SNR을 나타낸다. 기존의 global soft decision에서 이
는 각각 a priori SNR과 a posteriori SNR을 나타낸다. 기존의 global soft decision에서 이 ![]() 값은 보통 고정된 값으로 사용되었다. 본 논문에서는 이
값은 보통 고정된 값으로 사용되었다. 본 논문에서는 이 ![]() 값을 직전 2 프레임에서의 음성 존재 여부와 스펙트럼 변이 값의 상태 조건에 따라 적응적으로 변화하게 하여 음성 부재 확률을 향상시키는 기법을 제안한다.
값을 직전 2 프레임에서의 음성 존재 여부와 스펙트럼 변이 값의 상태 조건에 따라 적응적으로 변화하게 하여 음성 부재 확률을 향상시키는 기법을 제안한다.
또한 음성의 존재와 부재를 고려한 음성과 잡음의 전력 스펙트럼의 평균 기대값은 다음과 같이 주어질 수 있다.[5]
| (9) |
| (10) |
III. 스펙트럼 변이를 이용한 향상된 Global Soft Decision
기존의 global soft decision 방법에서는 고정된 파라미터 값 ![]() 를 사용하였기 때문에 비정상적인 잡음환경에서 정확한 음성 부재 확률을 추정하지 못하였다. 이러한 취약점을 개선하기 위해 본 연구에서는 직전 2 프레임에서의 음성 존재 여부와 음성 스펙트럼 변이를 이용한 가변적인 파라미터 값을 사용하여 주어진 환경에 따라 변화함은 물론, 음성과 음성 사이의 상호 연관성을 고려한 향상된 global soft decision 기법을 제시한다.
를 사용하였기 때문에 비정상적인 잡음환경에서 정확한 음성 부재 확률을 추정하지 못하였다. 이러한 취약점을 개선하기 위해 본 연구에서는 직전 2 프레임에서의 음성 존재 여부와 음성 스펙트럼 변이를 이용한 가변적인 파라미터 값을 사용하여 주어진 환경에 따라 변화함은 물론, 음성과 음성 사이의 상호 연관성을 고려한 향상된 global soft decision 기법을 제시한다.
먼저 직전 2 프레임이 모두 음성 존재일 경우와 그 이외의 경우를 구분하기 위해 식(7)에 따른 GSAP 값을 이용하여 다음과 같이 정의한다.
| (11) |
여기서 ![]() 는 음성 존재를 결정하기 위한 임계값이며,
는 음성 존재를 결정하기 위한 임계값이며, ![]() 는 음성 존재 여부를 나타내는 것으로써 음성 존재일 경우에는 1로 정의하고 음성 부재일 경우에는 0으로 정의하여 다음 식에 의해 직전 2 프레임의 상태를 판단한다.
는 음성 존재 여부를 나타내는 것으로써 음성 존재일 경우에는 1로 정의하고 음성 부재일 경우에는 0으로 정의하여 다음 식에 의해 직전 2 프레임의 상태를 판단한다.
| (12) |
여기서 ![]() 는 인디케이터 값으로서 직전 2 프레임이 모두 음성인 경우
는 인디케이터 값으로서 직전 2 프레임이 모두 음성인 경우 ![]() (
(![]() )와 그 이외의 경우
)와 그 이외의 경우 ![]() (
(![]() )로 분류하여 준다. 이 두 가지 경우에 대하여 음성 스펙트럼 변이 값의 범위에 따라 가변적인
)로 분류하여 준다. 이 두 가지 경우에 대하여 음성 스펙트럼 변이 값의 범위에 따라 가변적인 ![]() 값을 적용하게 된다. 음성 스펙트럼 변이는 이전 프레임 동안 예측된 평균 long-term 파워 스펙트럼과 현재 파워 스펙트럼의 차이이며 그 식은 다음과 같다.[8]
값을 적용하게 된다. 음성 스펙트럼 변이는 이전 프레임 동안 예측된 평균 long-term 파워 스펙트럼과 현재 파워 스펙트럼의 차이이며 그 식은 다음과 같다.[8]
| (13) |
여기서 ![]() 은 현재 파워 스펙트럼을,
은 현재 파워 스펙트럼을, ![]() 는 전 프레임 동안 예측된 평균 long-term 파워 스펙트럼을 각각 나타낸다. 또한 초기값은
는 전 프레임 동안 예측된 평균 long-term 파워 스펙트럼을 각각 나타낸다. 또한 초기값은 ![]() 이 되며,
이 되며, ![]() 는 다음 식에 의해 갱신된다.[8]
는 다음 식에 의해 갱신된다.[8]
| (14) |
위의 식들로부터 얻은 값을 실험을 통해 찾은 최적화된 ![]() 값 즉, 문턱값에 따라 3가지 조건으로 나누어서
값 즉, 문턱값에 따라 3가지 조건으로 나누어서 ![]() 값을 추정하게 된다.
값을 추정하게 된다.
| (15) |
먼저 ![]() 인 경우에는 현재 프레임도 음성일 확률이 높으므로
인 경우에는 현재 프레임도 음성일 확률이 높으므로 ![]() 값이 문턱값을 기준으로 유지되고 있을 때에는 기존의 고정된 값으로 유지시키고, 그 값이 증가하고 있을 때와 감소하고 있을 때에는 아래와 같은 시그모이드 형태 함수를 이용하여
값이 문턱값을 기준으로 유지되고 있을 때에는 기존의 고정된 값으로 유지시키고, 그 값이 증가하고 있을 때와 감소하고 있을 때에는 아래와 같은 시그모이드 형태 함수를 이용하여 ![]() 값을 점진적으로 높아지게 한다.
값을 점진적으로 높아지게 한다.
| (16) |
여기서 상수 ![]() ,
, ![]() 값은 다양한 잡음 환경과 여러 SNR에 대해 실험적으로 얻은 최적화된 값으로서 각각
값은 다양한 잡음 환경과 여러 SNR에 대해 실험적으로 얻은 최적화된 값으로서 각각 ![]() ,
, ![]() 으로 적용하였고, 기울기 파라미터
으로 적용하였고, 기울기 파라미터 ![]() , 오프셋 (offset)
, 오프셋 (offset) ![]() 으로 설정하였다.
으로 설정하였다.
반대로 ![]() 인 경우에는 현재 프레임도 음성이 아닐 확률이 높으므로
인 경우에는 현재 프레임도 음성이 아닐 확률이 높으므로 ![]() 값이 문턱값을 기준으로 유지되고 있을 때에는 기존의 고정된 값으로 유지시키고, 그 값이 증가하고 있을 때와 감소하고 있을 때에는
값이 문턱값을 기준으로 유지되고 있을 때에는 기존의 고정된 값으로 유지시키고, 그 값이 증가하고 있을 때와 감소하고 있을 때에는 ![]() 값을 점진적으로 낮아지게 한다. 이 경우에는 식(16)의 상수 및 파라미터 값들을 각각
값을 점진적으로 낮아지게 한다. 이 경우에는 식(16)의 상수 및 파라미터 값들을 각각 ![]() ,
, ![]() ,
, ![]() ,
, ![]() 으로 설정하였다.
으로 설정하였다.
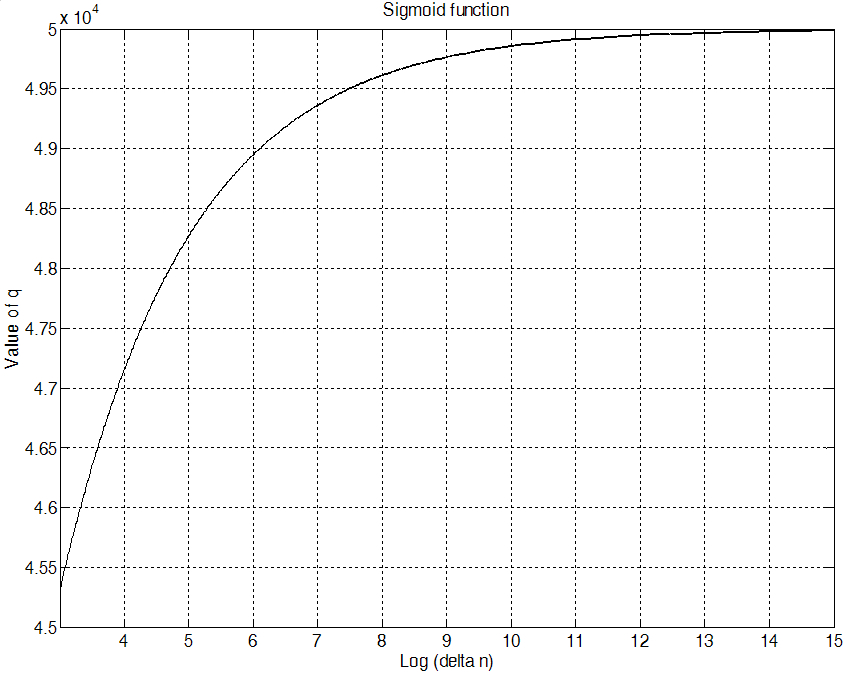
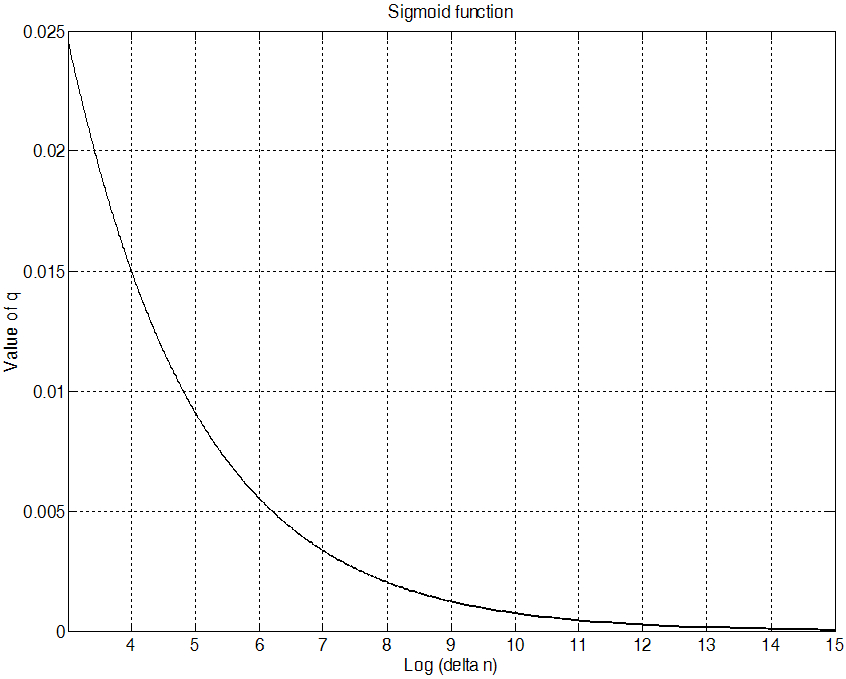
결과적으로 ![]() 값이 높을 때에는 음성 부재 확률 값을 1에 가깝게 만들어줌으로써 성능을 향상시킨다. 이 두 가지의 경우와 같이
값이 높을 때에는 음성 부재 확률 값을 1에 가깝게 만들어줌으로써 성능을 향상시킨다. 이 두 가지의 경우와 같이 ![]() 값을 적응적으로 증감시키기 위해 적용시킨 시그모이드 형태 함수를 각각 Fig. 1과 Fig. 2에 나타내었다. Fig. 1은
값을 적응적으로 증감시키기 위해 적용시킨 시그모이드 형태 함수를 각각 Fig. 1과 Fig. 2에 나타내었다. Fig. 1은 ![]() 인 경우, 그리고 Fig. 2는
인 경우, 그리고 Fig. 2는 ![]() 인 경우에
인 경우에 ![]() 값에 따라
값에 따라 ![]() 값에 적용된 sigmoid type 함수를 각각 보여 주고 있다. 그리고 Fig. 3은 제안된 스펙트럼 변이 기법을 이용하여 얻은 음성 존재 확률과 시그모이드 함수가 적용되어 그에 따라 변화하는
값에 적용된 sigmoid type 함수를 각각 보여 주고 있다. 그리고 Fig. 3은 제안된 스펙트럼 변이 기법을 이용하여 얻은 음성 존재 확률과 시그모이드 함수가 적용되어 그에 따라 변화하는 ![]() 값을 보여 주고 있다.
값을 보여 주고 있다.
|
Fig. 1. The sigmoid type function for the value of |
|
Fig. 2. The sigmoid type function for the value of |
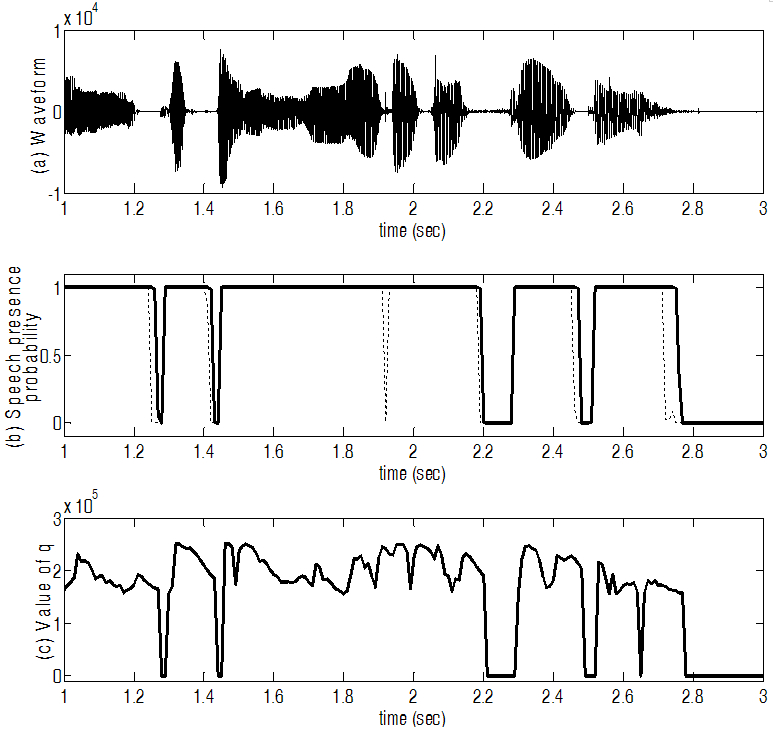
이를 통해 이전의 고정된 파라미터 ![]() 값을 사용하던 global soft decision보다 제안된 스펙트럼 변이 기법을 이용한 방법이 음성 부재 확률을 구할 때 보다 나은 성능을 보임을 확인할 수 있다. 또한 음성이 끝나는 부분에서는 늦게 떨어지면서 음성임에도 불구하고 음성이 아니라고 판단하는 경우를 줄여 주는 것을 볼 수 있다.
값을 사용하던 global soft decision보다 제안된 스펙트럼 변이 기법을 이용한 방법이 음성 부재 확률을 구할 때 보다 나은 성능을 보임을 확인할 수 있다. 또한 음성이 끝나는 부분에서는 늦게 떨어지면서 음성임에도 불구하고 음성이 아니라고 판단하는 경우를 줄여 주는 것을 볼 수 있다.
IV. 실험 결과
본 연구에서는 기존의 global soft decision 에서 음성 부재 확률을 구할 때 사용되는 ![]() 값이 고정된 값이었던 것과는 달리,
값이 고정된 값이었던 것과는 달리,
직전 2 프레임에서의 음성 존재 여부와 스펙트럼 변이 값의 상태 조건에 따라 가변적인 ![]() 값을 적용하여 음성 부재 확률을 향상시키는 기법을 사용하였다. 제안된 알고리즘의 음질 평가를 위해 널리 적용되고 있는 ITU-T P.862 PESQ 방법과[10] composite measure 중 대표적인 Covl 방법으로[11] 음성 향상의 성능 비교를 하였다.
값을 적용하여 음성 부재 확률을 향상시키는 기법을 사용하였다. 제안된 알고리즘의 음질 평가를 위해 널리 적용되고 있는 ITU-T P.862 PESQ 방법과[10] composite measure 중 대표적인 Covl 방법으로[11] 음성 향상의 성능 비교를 하였다.
위의 테스트를 위해 한 프레임의 크기가 10 ms, 8 kHz로 샘플링 된 남성, 여성 화자 각각이 96개의 문장을 발음하도록 한 데이터에 다섯 가지 형태의 잡음이 부가되었다. 잡음은 배블 잡음(babble noise), 자동차 잡음(car noise), 사무실 잡음(office noise), 거리 잡음(street noise), 백색 작음(white noise)에서 각각 5, 10, 15 dB의 SNR로 부가하였다. 또한 기존의 global soft decision의 고정 파라미터 ![]() 값은 0.0625로 설정해 주었고, 제안된 방법에서 세 가지 조건에서의 각
값은 0.0625로 설정해 주었고, 제안된 방법에서 세 가지 조건에서의 각 ![]() 값은 sigmoid type 함수에 의해 얻어진 값이 적용되었다. PESQ 및 Covl 값은 각각 이들 샘플에 대한 평균 수치로 나타내었고, 전 프레임 동안 예측된 평균 long- term 파워 스펙트럼인
값은 sigmoid type 함수에 의해 얻어진 값이 적용되었다. PESQ 및 Covl 값은 각각 이들 샘플에 대한 평균 수치로 나타내었고, 전 프레임 동안 예측된 평균 long- term 파워 스펙트럼인 ![]() 값을 구할 때의
값을 구할 때의 ![]() 값은 0.8로 설정하였다.
값은 0.8로 설정하였다.
Table 1, 2는 기존의 global soft decision 방법보다 본 논문에서 제안한 스펙트럼 변이 기법을 적용한 것이PESQ 및 Covl 수치로 보았을 때, 모든 실험 조건에서 향상된 것을 보여 주고 있다. 즉, 기존의 고정된 파라미터 ![]() 값을 사용하던 global soft decision보다 제안된 스펙트럼 변이를 이용한 방법이 다양한 잡음 환경에서 음성 부재 확률을 구할 때, 보다 정확하게 추정할 수 있으므로 음성 향상 시스템에서의 성능이 좋음을 확인할 수 있다.
값을 사용하던 global soft decision보다 제안된 스펙트럼 변이를 이용한 방법이 다양한 잡음 환경에서 음성 부재 확률을 구할 때, 보다 정확하게 추정할 수 있으므로 음성 향상 시스템에서의 성능이 좋음을 확인할 수 있다.
이는 제안된 알고리즘의 음성 향상 기법이 기존 알고리즘보다 깨끗한 음성 신호에 좀 더 가까운 신호를 생성하는 것을 의미하는 것으로써 음성 부재 확률을 더 잘 추정함에 따라 성능의 향상이 있음을 확인할 수 있었다.
V. 결 론
본 논문에서는 기존의 global soft decision 알고리즘에서 음성 부재 확률의 고정 파라미터 대신 스펙트럼 변이 기법을 이용함으로써, 음성 부재와 존재에 대한 a priori 확률값의 비인 ![]() 값을 가변적으로 적용시켜 보다 견실한 음성 부재 확률을 추정하였다.
값을 가변적으로 적용시켜 보다 견실한 음성 부재 확률을 추정하였다.
기존의 global soft decision 방법은 음성 부재 확률을 구하기 위해 기존의 통계적 가정을 바탕으로 고정된 ![]() 값을 적용하였지만, 비정상적인 잡음 환경을 고려하였을 때 잡음이 음성 신호를 간섭하면 음성의 꼬리와 같은 약한 음성 신호를 추정하기 힘들다는 단점을 가지고 있었다.
값을 적용하였지만, 비정상적인 잡음 환경을 고려하였을 때 잡음이 음성 신호를 간섭하면 음성의 꼬리와 같은 약한 음성 신호를 추정하기 힘들다는 단점을 가지고 있었다.
하지만 제안된 알고리즘에서는 직전 2 프레임에서의 음성 존재 여부와 스펙트럼 변이 값의 상태 조건에 따라 가변적인 ![]() 값을 적용하여 이러한 단점을 극복하였다. 이를 통해 다양한 음성 환경에서의 정확한 음성 부재 확률 추정을 가능하게 하며, 실험 결과 기존의 방법보다 다양한 잡음 환경에 더욱 강인한 성능을 보였다.
값을 적용하여 이러한 단점을 극복하였다. 이를 통해 다양한 음성 환경에서의 정확한 음성 부재 확률 추정을 가능하게 하며, 실험 결과 기존의 방법보다 다양한 잡음 환경에 더욱 강인한 성능을 보였다.
