

I. 서 론
최근의 저비트율 오디오 코덱에서는 파라미터 기반의 채널 확장 기술이 많이 사용되고 있다.[1] 3GPP의enhanced aacPlus와 MPEG4 High Efficiency Advanced Audio Coding(HE-AAC) v.2에서는 Parametric Stereo(PS) 툴을 이용하여 부호화 시 스테레오 신호를 모노 신호로 다운믹스하고 AAC로 부호화 및 동시에 스테레오 파라미터들(stereo parameters)을 추출하여 양자화하고 그 인덱스를 이용해 비트열을 구성한다.[2,3] 또한, 복호화 시에는 다운믹스 모노 신호와 스테레오 파라미터들을 이용하여 일종의 업믹스(upmix) 과정을 통해 다시 스테레오 신호로 복원하게 된다. MPEG Surround에서는 이와 유사한 과정을 다채널 오디오 신호에 적용하여 최종적으로 다채널 혹은 바이노럴(binaural) 신호를 재생하며,[4] 이의 2채널용 수정 버전은 음성과 음악을 모두 지원하는 코덱인 Unified Speech and Audio Coding(USAC)에서 모노-스테레오 확장 기술로 채택된 바 있다.[5]
PS의 스테레오 파라미터들 및 MPEG Surround에서 이에 해당되는 공간 파라미터들(spatial parameters)은 비트열을 구성하는 중요 정보로써 비트열의 대부분을 차지하며, 따라서 이들의 코딩 방법을 바꾸거나 추가하는 방법으로 성능을 개선하는 연구들이 최근에 제안된 바 있다. 예를 들어, 원래 기술 대비 손실 기술로써 MPEG Surround의 공간 파라미터 중 Chan-nel Level Differences(CLDs)에 대해 Virtual Source Location Information(VSLI)로 대체하여 음질은 변화가 없으면서도 비트율을 낮추는 방법이 제안되었다.[6] 또한, 원본 대비 무손실 기술인 Pilot-Based Coding(PBC)을 원래의 코딩 구조에 추가하여 MPEG Surround의 공간 파라미터들을 부호화 및 복호화하는 기술이 제안되었고,[7] 이는 MPEG Surround의 표준에 채택된 바 있다.[4] PBC는 enhanced aacPlus의 PS 기술에도 기존 코딩 방식에 추가되는 형태로 제안되었다.[8]
한편, 최근 USAC에서는 코딩 성능을 더욱 높이기 위해서 양자화된 스펙트럼 데이터 등에 대해서 컨텍스트 적응 산술 코딩 방법이 사용되고 있다.[5] 본 논문에서는 PS에 대해 컨텍스트 적응 코딩을 적용하기 위한 사전 작업으로서, 특히 표준 성능의 부호화 및 복호화 SW가 모두 개방되어있는 enhanced aacPlus를 대상으로 하여 스테레오 파라미터들에 대한 가장 효율적인 컨텍스트를 찾는 것을 목표로 한다.
II. Enhanced aacPlus의 PS 코딩
Enhanced aacPlus의 PS에서는 스테레오 파라미터로 Inter-channel Intensity Differences(IIDs)와 Inter-Channel Coherence(ICC)를 사용한다.[2] 이들 파라미터는 신호를 시간 영역에서 서브밴드 영역으로 변환한 후에 추출 및 적용된다. 또한, 데이터 양을 줄이기 위해서 서브밴드들을 적절히 묶어서 스테레오 밴드 단위로 처리하며, 스테레오 밴드 수 M은 비트율에 따라서 10 혹은 20 중 하나가 된다.[2] 우선 IID는 스테레오 신호에서 왼쪽 채널 신호 l과 오른쪽 채널 신호 r 사이의 레벨 차이를 의미하며, b번째 스테레오 밴드에 대해 다음과 같이 정의된다.[2]
![]() (1)
(1)
단, eX(b)는 다음처럼 정의되며, ![]() 을 의미한다.
을 의미한다.
![]() (2)
(2)
여기에서 X는 l 혹은 r을 의미하고, X(k,n)은 서브밴드 영역의 신호로써 k와 n은 각각 서브밴드 및 시간 인덱스이고, kl과 kh는 b번째 스테레오 밴드의 시작 및 마지막 서브밴드 인덱스이고, L은 스테레오 파라미터가 적용되는 세그멘트의 길이이고, ε은 분모가 0이 되는 것을 방지하기 위한 매우 작은 값이다.[2]
공간 파라미터 중 ICC는 두 채널 신호 사이의 상관관계 정보를 의미하며 다음과 같이 정의된다.[2]
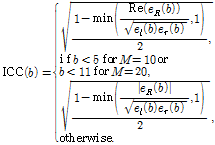 (3)
(3)
단, eR(b)는 다음과 같이 정의되며, 식에서 *는 켤레 복소수를 의미한다.
![]() (4)
(4)
Enhanced aacPlus의 PS에서는 스테레오 파라미터들의 값을 양자화하여 전송하는데, 양자화 인덱스는 IID의 경우는 -7에서 7까지, ICC의 경우는 0에서 7까지의 값 중 하나를 가진다.[2] k번째 스테레오 밴드 및 i번째 시간 인덱스에 해당하는 양자화된 스테레오 파라미터의 인덱스를 x(k,i)라고 할 경우, 이 인덱스들은 정보량을 더욱 줄이기 위해서 다음과 같은 주파수 차동 코딩(Frequency Differential Coding, FDC)
![]() (5)
(5)
혹은 시간 차동 코딩(Time Differential Coding, TDC)
![]() (6)
(6)
을 수행하고 이에 대해 추가적인 허프만 코딩을 각각 적용하여 비트 수가 더 낮은 방법을 비트열로 생성하고 전송한다.[2]
Enhanced aacPlus는 무선 통신 환경에 사용할 목적을 가지므로 에러가 발생하는 경우가 있을 수 있으며, 이 때 시간 차동 코딩만을 연속적으로 수행하면 에러의 전파를 피할 수 없다. 따라서, 부호화기에서 미리 정해진 주기마다 refresh 프레임을 구성하며, 이때는 항상 주파수 차동 코딩을 사용하게 된다.
III. 컨텍스트 후보 결정
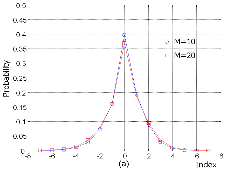
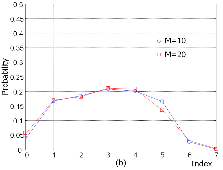
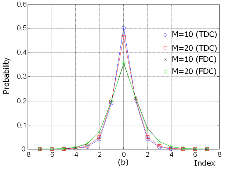
스테레오 파라미터는 PS 비트열 중 대부분을 차지하므로 우선 이들에 대한 확률 분포를 살펴볼 필요가 있다. 이를 위해서 그림 1과 2에서 일련의 샘플들을 이용하여 IID과 ICC의 양자화 인덱스와 주파수 차동 코딩 혹은 시간 차동 코딩이 적용된 인덱스들의 확률 분포를 파라미터 밴드수 M이 10과 20일 때에 대해 보이고 있다. 우선 그림 1 (a)에서 IID 양자화 인덱스는 0이 가장 확률이 높고 좌우로 갈수록 확률이 낮아지며, 그림 1 (b)의 ICC 양자화 인덱스는 상대적으로 넓게 퍼져있다. 한편, 그림 2에서는 IID와 ICC의 주파수 및 시간 차동 코딩 모두 그 인덱스가 0에 가까운 것이 확률이 높고 좌우로 갈수록 확률이 낮아진다. 이상의 결과에서 스테레오 파라미터 인덱스의 확률 분포는 IID과 ICC가 서로 다르지만, 이들 모두에 대해서 특정 시간-스테레오 밴드에서의 양자화 인덱스는 시간 및 스테레오 밴드 상에서 인접한 양자화 인덱스들과 값이 매우 유사함을 알 수 있다.
|
그림 1. 스테레오 파라미터의 양자화 인덱스 확률 분포 (a) IID (b) ICC Fig. 1. Probability distribution of the quantized indexes of stereo parameters. (a) IID (b) ICC |
|
그림 2. 주파수 차동 코딩 (FDC) 및 시간 차동 코딩 (TDC) 수행 후의 스테레오 파라미터의 양자화 인덱스 확률 분포 (a) IID (b) ICC Fig. 2. Probability distribution of the quantized indexes of stereo parameters after FDC and TDC. (a) IID (b) ICC |
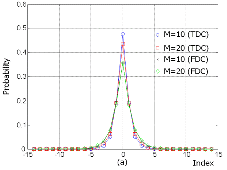
이에 의해 특정 소스 인덱스에 대한 컨텍스트 인덱스 후보는 시간-스테레오 밴드 상에서 가장 인접한 인덱스들 및 이의 조합으로 구성한다. 즉, 그림 3에서 스테레오 파라미터 양자화 인덱스 x(k,i)를 소스로 할 때, 사용 가능한 컨텍스트는 이를 둘러싸고 있는 8개의 인덱스들이다. 한편, 일반적인 코딩 방법에서 시간 순서 별로 낮은 스테레오 밴드부터 높은 스테레오 밴드로 순차적으로 복호화를 진행하는 것을 고려하면, x(k,i)를 복호화할 때 동일 시간에서의 스테레오 밴드 인덱스가 더 크거나 시간적으로 더 미래의 경우는 그 값들을 알 수 없다. 따라서, x(k,i)를 복호화할 때 사용 가능한 컨텍스트는 그림 3과 같이 x(k-1,i-1), x(k,i-1), x(k+1,i-1), x(k-1,i)의 4개로 제한된다.
|
그림 3. 시간-스테레오 밴드 영역의 스테레오 파라미터 양자화 인덱스 Fig. 3. Quantized indexes of stereo parameters in the time-stereo band domain. |
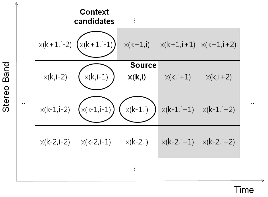
컨텍스트는 그림 3의 4개 스테레오 파라미터 양자화 인덱스들에 대해 1개부터 4개까지의 조합을 사용하는 것이 가능하다. 그러나, 3개 이상 사용할 경우 컨텍스트 값의 전체 경우의 수가 너무 많아지기 때문에, 실제 구현에 있어 메모리 사용량 등을 고려하여 1개 및 2개의 조합을 사용하는 것으로 제한한다. 우선 컨텍스트를 인덱스 1개, 소스를 x(k,i)로 구성할 경우 다음의 4가지 경우가 발생한다. 단, 각 경우에서 컨텍스트 및 소스의 순이다.
①: x(k-1,i), x(k.i)
②: x(k-1,i-1), x(k.i)
③: x(k,i-1), x(k.i)
④: x(k+1,i-1), x(k.i)
또한, 컨텍스트로 2개의 인덱스를 사용할 경우 컨텍스트를 2개의 인덱스의 조합, 소스는 x(k,i)로 구성한다. 이 경우 컨텍스트의 경우의 수는 4C2=6개가 되지만, 일반적으로 근접한 인덱스들의 유사도가 높음을 고려하여 추가 조건으로써 컨텍스트에 사용되는 양자화 인덱스들이 시간 및 스테레오 밴드 인덱스 차이가 각각 1 이하의 인접한 경우로 제한한다. 이에 의해 다음의 4가지 경우가 가능하며, 단 각 경우에서 컨텍스트 및 소스의 순이다.
⑤: x(k-1,i)와 x(k-1,i-1), x(k,i)
⑥: x(k-1,i)와 x(k,i-1), x(k,i)
⑦: x(k-1,i-1)과 x(k,i-1), x(k,i)
⑧: x(k,i-1)과 x(k+1,i-1), x(k,i)
한편, 이상의 8가지 컨텍스트 및 소스 후보에 대해서 최적의 후보를 정하기 위해서는 refresh 프레임 여부와 스테레오 밴드를 고려해야 한다. 우선 refresh 프레임의 경우 이전 시간의 정보를 사용할 수 없으므로, 첫 번째 스테레오 밴드(k=1)는 사용할 수 있는 컨텍스트가 없고, 둘째부터 마지막까지의 스테레오 밴드(2≤k≤M)는 x(k-1,i)만 컨텍스트로 사용할 수 있으므로 ①만 사용 가능하다. non-refresh 프레임의 경우, 첫째 스테레오 밴드(k=1)는 사용할 수 있는 인덱스가 x(k,i-1), x(k+1,i-1)로 제한되며, 따라서 ③, ④, ⑧ 등 3 가지만 사용할 수 있다. 둘째부터 마지막 전까지의 스테레오 밴드(2≤k≤M-1)는 모든 후보를 사용할 수 있으며, 마지막 스테레오 밴드(k=M)는 x(k+1,i-1)를 사용할 수 없으므로 ④, ⑧을 제외한 나머지를 사용할 수 있다. 이상의 내용을 정리하면, 상황별 사용 가능한 컨텍스트와 소스 조합의 후보는 다음과 같이 정리된다.
(a) Refresh 프레임(k=1): 없음
(b) Refresh 프레임(2≤k≤M): ①
(c) Non-refresh 프레임(k=1): ③, ④, ⑧
(d) Non-refresh 프레임(2≤k≤M-1): ①-⑧
(e) Non-refresh 프레임(k=M): ①-③, ⑤-⑦
IV. 최적 컨텍스트 탐색
최적의 컨텍스트 탐색을 위해서 상용 CD로부터 44.1kHz 샘플링 주파수를 가지는 클래식, 한국 가요 및 미국 팝송, 월드 뮤직 등 다양한 장르를 포함하는 스테레오 샘플들을 추출하여 데이터베이스를 구성하였다. 전체 샘플의 길이는 약 820,000개의 스테레오 파라미터 세트에 해당된다. 이 데이터베이스에 대해 enhanced aacPlus를 이용해 16 kbps와 32 kbps의 비트율로 인코딩하고 스테레오 파라미터 인덱스들을 추출하였다. 이 비트율들에 대해 스테레오 밴드 수 M은 각각 10 및 20이 해당된다.
이전 장에서 논의한 각 상황 (a)-(e)에 대해, 컨텍스트 적응 코딩이 가능한 (b)-(e)의 컨텍스트 및 소스 후보에 대해 성능 평가를 수행하였다. 성능 평가를 위해서는 엔트로피를 이용하였는데, 우선 컨텍스트 (C)가 c일 때 소스 (S)의 엔트로피는 다음과 같이 구해지며 [9], 이는 특정 컨텍스트 값에 대한 평균 비트 소모량에 해당된다. 단, p는 확률 값을 의미한다.
![]() (7)
(7)
또한, 모든 컨텍스트의 값에 대해 다음과 같이 엔트로피 평균을 구하면 [9], 이는 전체 평균 비트 소모량에 해당된다. 따라서, 이 값이 최소가 되는 후보를 판별하는 것으로 최적 컨텍스트를 결정할 수 있다.
![]() (8)
(8)
앞에서 기술한 데이터베이스를 이용하여 기존 방법인 주파수 차동 코딩(FDC) 및 시간 차동 코딩(TDC)과 각 후보별 엔트로피를 상황 (b)-(e)에 대해 구하고 표 1부터 표 4에서 보이고 있다(최소 엔트로피 값을 굵은 글자로 표시). 우선 표 1에서 후보 ①이 가장 우수하며, 표 2에서 후보 ⑧이 평균적으로 가장 우수하며 후보 ③ 또한 이와 근접한 성능을 보이고 있고, 표 3과 표 4에서 공통적으로 후보 ⑥이 가장 우수하다. 이상의 결과들은 기존 방법인 FDC와 TDC보다 우수하므로, 즉 소스 x(k,i)에 대해 상황 (b)에 대해서 x(k-1,i)를, 상황 (c)에 대해서 x(k,i-1)와 x(k+1,i-1) 혹은 x(k,i-1)을, 상황 (d)와 (e)에 대해서 x(k-1,i)와 x(k,i-1)를 컨텍스트로 사용하면, 기존 방법 대비 무손실로써 엔트로피 기준으로 약 10% 내외의 성능 향상을 기대할 수 있음을 의미한다.
한편, 본 논문의 범위 밖에 해당되지만 추가적인 논의 사항으로써, PS에 컨텍스트 적응 코딩을 적용할 경우 구현 상에서 실질적으로 고려할 점들을 간략히 기술한다. 첫째로, 상황 (a)에 대해서는 컨텍스트 적응 코딩을 적용할 수 없으므로 고정된 코딩 방법을 설계하여야 한다. 둘째로, 각 코딩의 실제 구현에 있어서 Huffman 코딩이나 산술 코딩(arithmetic coding) 등을 이용하게 되므로, 이들로 구현했을 때 제안된 컨텍스트 적응 코딩의 컨텍스트들이 최적의 성능을 가지는지는 추가 검증이 필요하다. 셋째로, 기존의 PS가 FDC와 TDC 등 2개를 선택적으로 사용하는 것과 같이 컨텍스트 적응 코딩도 2개 이상의 방법을 혼합하여 사용하는 것을 고려하여야 한다. 이 경우 어떤 방법들을 조합하는 것이 실제 구현에서 최적의 결과를 보장하는지는 추가 연구가 필요하다. 마지막으로, 컨텍스트들을 2개의 양자화 인덱스의 조합으로 사용하는 경우 메모리 사용량이 많아지므로, 이들의 간략화된 버전의 개발 및 실제 코딩 시스템에의 적용을 고려할 필요가 있다.
