

I. 서 론
II. 관련 연구
III. 제안하는 기법
3.1 PLM 분기
3.2 스펙트로그램 분기
3.3 특징 융합 모듈
IV. 실험 설계 및 결과
4.1 데이터셋
4.2 구현 세부사항
4.3 도메인 내 잡음 환경 평가 결과
4.4 도메인 외 잡음 및 다양한 잡음 환경 평가 결과
V. 결 론
I. 서 론
화자 인증이란 입력된 음성의 화자가 시스템에 등록된 화자와 일치하는 지 여부를 판단하는 과제로 금융 서비스, 보안 인증 등 다양한 분야에서 활용되고 있다. 최근 화자 인증 분야에서는 딥러닝 기반 화자 인증 시스템이 우수한 성능을 보이고 있다. 그러나 이러한 시스템은 깨끗한 발화 환경에서는 우수한 성능을 보이나, 잡음이 섞인 발화에 대해서는 성능이 저하되는 현상을 보인다.[1]
잡음 환경에서 화자 인증 시스템의 일반화 성능을 개선하기 위해, 교사 학생 학습을 활용한 연구가 수행되었다.[2,3] 교사 학생 학습이란 잡음이 섞인 발화를 입력 받은 학생 모델의 출력이 깨끗한 발성을 입력 받은 교사 모델의 출력과 유사하도록 학습을 진행하는 학습 방식이다. 선행 연구들에서는 화자 인증 시스템을 학생 모델로 채택하여 화자 인증 시스템의 잡음 강인성을 향상시켜 잡음 환경에서 우수한 성능을 달성하였다.
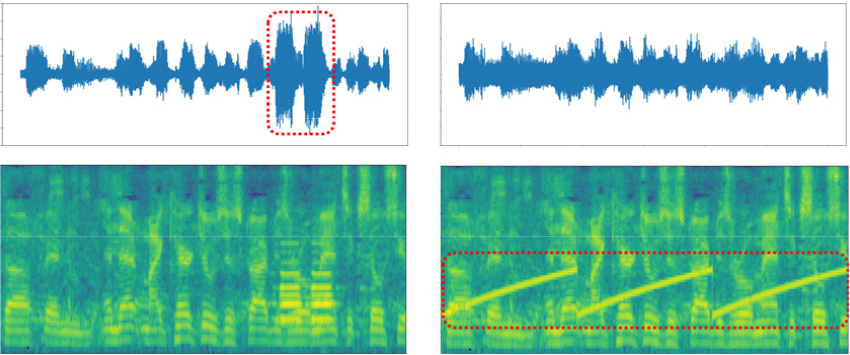
그러나 대부분의 선행 연구들은 시간 축 상의 원시 파형 또는 주파수 축 상의 스펙트로그램 정보 중 하나에만 의존하는 구조적 한계를 갖는다. 실제 음성 환경에서는 다양한 잡음 유형이 존재하며, 이들은 표현 방식에 따라 서로 다르게 나타날 수 있다. Fig. 1의 왼쪽은 특정 발화에 짧고 강한 충격음이 혼입된 경우를 시각화한 그래프 및 히트맵이며, 오른쪽은 일정한 세기의 사이렌 소리가 혼입된 경우의 시각화이다. 짧고 강한 충격음이 혼입된 경우, 시간 축 상에서는 불규칙한 패턴이 뚜렷하게 나타나는 반면, 주파수 기반 스펙트로그램 상에서는 그 패턴이 불명확하게 표현된다. 반면, 일정한 세기의 사이렌 소리가 혼입된 경우, 스펙트로그램 상에서는 선명하게 구분되지만 시간 축 상에서는 식별이 어렵다. 이러한 사례는 화자 정보와 잡음이 표현 방식에 따라 상이하게 드러난다는 점을 시사하며 두 표현 방식이 상호보완적인 정보를 제공할 수 있음을 암시한다.
한편, 최근 음성 딥페이크 탐지 분야에서는 원시 파형과 스펙트로그램 입력 특징을 동시에 활용하는 다중 관점 학습 기반 시스템이 제안 되었다.[4] 다중 관점 학습은 서로 다른 표현 공간의 정보를 통합하여 더 풍부하고 강인한 특징을 활용하는 기법으로, 원시 파형과 스펙트로그램과 같이 상호보완적인 입력 특징을 통해 시스템의 강인성을 향상시킬 수 있음을 입증하였다.
이러한 가능성에 기반하여, 본 논문에서는 다양한 잡음에서의 화자 인증 시스템의 일반화 성능 개선을 위해 다중 입력 특징을 활용하는 교사 학생 학습 기반 화자 인증 시스템을 구축하였다. 구체적으로, 교사 학생 학습을 적용한 사전 학습된 거대 모델(Pre-trained Large Model, PLM) 기반 시스템에 2개의 1D 컨볼루션 블록으로 구성된 컨볼루션 기반 추출기를 통해 스펙트로그램을 가공하는 분기를 병렬적으로 설계하여 다중 특징을 활용하도록 하였다. 또한, 특정 잡음에 적합한 입력 특징이 다를 수 있음을 반영하기 위해, 특징 융합 모듈을 구축해 각 분기에서 추출된 특징의 정보를 선택적으로 활용할 수 있도록 하였다.
제안한 시스템은 12개 트랜스포머 인코더 계층으로 이루어진 WavLM base+ 를 교사 및 학생 모델로 사용하여 VoxCeleb2 데이터셋에서 학습을 진행하였고, 화자 인증 백엔드 모델로 ECAPA-TDNN을 결합하였다. 실험은 VoxCeleb1 trial-O 평가 파티션에 도메인 내 잡음 환경으로 MUSAN 데이터셋을, 도매인 외 잡음 환경으로 Nonspeech 100 데이터셋을 SNR 0 dB, 5 dB, 10 dB, 15 dB, 20 dB로 합성하여 평가하였다. 그 결과, WavLM base+ 모델에 ECAPA-TDNN을 결합한 시스템(Baseline)이 도메인 내 잡음환경에서 평균 동일 오류율(Equal Error Rate, EER) 2.65 %를, 도메인 외 잡음 환경에서 3.87 %를 기록한 반면, 제안한 시스템은 도메인 내 잡음 환경에서 2.16 % , 도메인 외 잡음 환경에서 1.99 % 달성해 기준 시스템 대비 최대 약 56 %의 상대 개선율 향상을 보이며, 제안한 시스템의 우수성을 입증하였다.
본 논문은 다음과 같이 구성된다. II장에서는 관련 연구를 검토하고, III장에서는 본 논문에서 제안하는 잡음 환경을 위한 다중 입력 특징 기반 화자 인증 시스템의 구성 요소를 설명한다. IV장에서는 제안한 시스템에 대한 잡음 환경 화자 인증 실험의 설계 및 실험 결과의 분석을 다루며, 마지막으로 V장에서는 결론 및 향후 연구 계획을 제시한다.
II. 관련 연구
잡음 환경에서의 화자 인증 시스템의 일반화 성능을 개선하기 위해 교사 학생 학습을 활용하는 연구들이 진행되었다. MohammadAmini et al.[2]은 스펙트로그램을 입력으로 사용하는 ResNet 기반 화자 인증 시스템에 교사 학생 학습을 적용한 프레임워크를 구축하였다. 이러한 프레임워크는 잡음이 포함된 음성과 깨끗한 음성의 x-벡터 간 거리를 최소화하여 잡음 환경에서도 일관된 화자 표현을 추출할 수 있도록 하였다. Lim et al.[3]은 원시 파형을 입력으로 사용하는 자가 지도 학습 기반 사전 학습된 모델의 잡음 강인성을 향상시키기 위해 Noise Adaptive Warm-up training for Speaker Verification(NAW-SV) 프레임워크를 제안하였다. 이들은 추가적인 학습 단계를 제안하였으며, 이러한 단계에서 교사 학생 학습을 적용하여 화자 정보를 효과적으로 보존하면서 깨끗한 원시 파형에서 추출된 특징과 유사한 품질의 특징을 추출할 수 있도록 하였다. 그러나 이러한 선행 연구들은 잡음 환경에서의 화자 인증 시스템의 일반화 성능을 개선하였지만, 단일 입력 특징을 활용한다는 구조적 한계점이 존재한다.
한편, 최근 음성 딥페이크 탐지 분야에서는 원시 파형과 스펙트로그램 입력 특징을 동시에 활용하는 다중 관점 학습 기반 시스템이 제안되었다. Zhang et al.[4]은 음성 딥페이크 탐지를 위해 시간 도메인과 주파수 도메인의 특징을 결합하는 다중 관점 협업 학습 네트워크를 제안하였다. 이들은 서로 다른 도메인의 특징이 상호보완적 정보를 제공함을 실험적으로 입증하였으며, 특히 시간 축에서 포착하기 어려운 미세한 변조 패턴을 주파수 도메인에서 효과적으로 탐지할 수 있음을 보였다.
이러한 가능성을 기반으로, 본 연구는 다중 입력을 활용하는 교사 학생 학습 기반 화자 인증 시스템을 구축하는 연구를 수행하였다.
III. 제안하는 기법
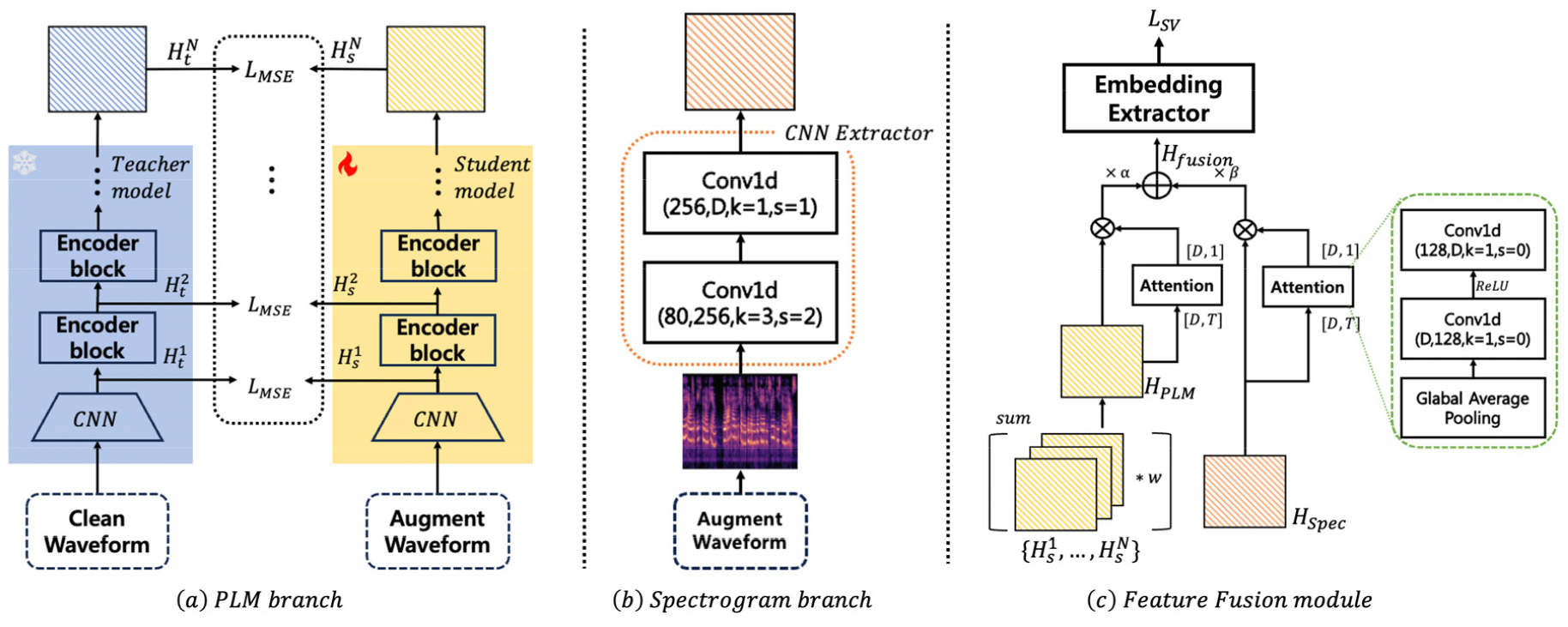
본 장에서는 다양한 잡음에서의 화자 인증 성능을 개선하기 위한 다중 입력 특징을 활용하는 교사 학생 학습 기반 화자 인증 시스템의 전반적인 동작 과정과 각 구성요소에 대해 상세히 기술한다. Fig. 2 (a)-(c)는 제안하는 시스템의 각 분기 및 모듈을 도식화 하였다.
기존 교사 학생 학습 기반 프레임워크는 잡음이 섞인 발화를 입력 받은 학생 모델의 출력과 깨끗한 발화를 입력받은 교사 모델의 출력이 유사해지도록 학습을 진행한다. 그러나 선행 연구들은 시간 축 상의 원시 파형 또는 주파수 축 상의 스펙트로그램 중 하나만을 활용하는 구조적인 한계점이 존재한다. 실제 환경에서는 다양한 잡음 유형이 존재하며, 이러한 잡음이 혼입되는 경우, 화자 정보와 잡음은 입력 특징에 따라 상이한 패턴을 보일 수 있다.
이러한 한계를 극복하기 위해, 본 연구에서는 시간 축 상의 원시 파형을 활용하는 PLM 기반 교사 학생 학습 기반 시스템에 주파수 축 상의 스펙트로그램을 활용하는 분기를 병렬적으로 구성하여, 두 가지 상호보완적인 특징을 동시에 활용하도록 구축하였다. 이를 통해 각 표현 방식의 장점을 최대한 활용하면서 단일 입력의 한계를 보완하고자 한다.
3.1 PLM 분기
PLM 분기에서는 교사 학생 학습 전략을 활용하여 시간 축 상의 원시 파형에서 잡음에 강인한 특징을 추출하는 것을 목표로 한다. Fig. 2(a)는 PLM 분기의 구체적인 동작 과정의 도식화를 나타낸다. 먼저, 교사 모델은 사전 학습된 PLM의 파라미터를 고정한 상태로 깨끗한 원시 파형을 입력 받아 참조 특징 를 출력한다. 이와 동시에, 학생 모델은 교사 모델과 동일한 구조를 가지되, 잡음이 포함된 음성을 입력받아 를 출력하며, 생성된 는 특징 융합 모듈로 전달된다.
학습 과정에서 각 트랜스포머 계층의 출력에 대해 평균 제곱 오차 손실(Mean Square Error, MSE)을 적용하여, 학생 모델이 다양한 추상화 수준에서 잡음에 불변인 표현을 학습하도록 유도한다. 이를 통해, 학생 모델은 잡음이 섞인 원시 파형으로부터도 깨끗한 원시 파형에서 출력된 특징과 유사한 품질의 특징을 추출할 수 있다는 장점을 갖는다.
여기서 은 계층의 인덱스를, 은 PLM 의 전체 계층 수를 나타내며, 과 은 각각 교사 모델과 학생 모델의 번째 계층의 출력을 의미한다.
3.2 스펙트로그램 분기
PLM 분기와 병렬적으로, 스펙트로그램 분기는 Fig. 2(b)와 같이 주파수 영역의 정보를 활용하여 PLM 분기를 보완할 수 있는 특징을 추출하는 것을 목표로 한다. 원본 스펙트로그램과 PLM 분기의 출력의 차원을 일치시켜 합연산을 쉽게 하기 위해, 2개의 1D 합성곱 계층으로 구성된 컨볼루션 기반 추출기를 구축하였다. 먼저, 잡음이 섞인 발화를 푸리에 변환을 통해 스펙트로그램으로 변환한다. 컨볼루션 기반 추출기가 스펙트로그램으로부터 을 생성하여 특징 융합 모듈로 전달한다. 이를 통해 입력 발화의 주파수 기반 특징을 효과적으로 추출하여 원시 파형 기반 특징과 상호보완적으로 활용할 수 있다.
3.3 특징 융합 모듈
특징 융합 모듈은 두 분기에서 추출된 특징 과 을 적응적으로 통합하여 임베딩 추출기에 전달한다. 발화에 혼입되는 다양한 잡음들은 표현 방식에 따라 상이한 패턴을 나타낼 수 있기에 모델이 직접 필요한 특징을 취합할 수 있도록 각 특징에 Attention을 부여하고 통합하도록 설계하였다. 먼저, Fig. 2(c)와 같이 PLM 분기의 학생 모델의 특징을 을 가중합을 통해 으로 집계한다. 이때, 은 학습 가능한 가중치 벡터를 의미한다.
그 후, 각 분기의 특징인 , 에 Attention 연산을 삽입하여 시간축으로 중요한 정보를 부각한다. 그 후, 학습 가능한 파라미터 𝛼와 𝛽를 사용하여 최종적으로 가중합된 특징 을 생성한다.
생성된 특징 은 화자 인증 임베딩 추출기에 전달되며, 화자 인증 손실 함수를 통해 학습된다.
IV. 실험 설계 및 결과
4.1 데이터셋
본 연구에서는 제안한 시스템의 학습을 위해 VoxCeleb2[5] 개발 데이터 세트를 활용하였다. 해당 데이터 세트는 YouTube에 업로드된 5,994명의 유명 인사의 인터뷰 등의 동영상에서 추출된 음성으로 구성된다. 또한 잡음 증강을 위해 MUSAN[6] 데이터 세트를 훈련과 평가 데이터 셋으로 분할하여 사용하였으며, 학습 데이터 셋에 0 dB ~ 20 dB 신호대잡음비(Signal to Noise Ratio, SNR) 범위에서 무작위로 잡음을 주입하여 활용하였다.
학습된 모델은 도메인 내 잡음 및 도메인 외 잡음 데이터 세트에서 평가 되었다. 도메인 내 잡음 강인성을 평가하기 위해 VoxCeleb1 trial-O 평가 데이터 세트와 MUSAN 평가 데이터 세트를 0 dB, 5 dB, 10 dB, 15 dB, 20 dB SNR로 합성하여 평가하였다. 또한, 도메인 외 잡음 강인성을 평가하기 위해 VoxCeleb1 trial-O 평가 데이터 세트와 Nonspeech 100[7] 평가 데이터를 0 dB, 5 dB, 10 dB, 15 dB, 20 dB SNR로 합성하여 평가하였다. 마지막으로 제안한 기법의 범용성을 확인하기 위해 VoxSRC 2023,[8] VCMix,[9] VOiCES[10] 평가 데이터 세트를 사용하여 평가하였다.
4.2 구현 세부사항
본 연구에서는 사전 학습 거대 모델로는 WavLM base+[11]를 사용했으며, 해당 모델의 은닉 차원()은 768차원으로 설정되어 있다. 스펙트로그램 특징으로는 80 차원 Log Mel Spectrogram을 활용하였다. 임베딩 추출기로는 512 채널의 ECAPA-TDNN[12] 모델을 사용했다. 출력된 화자 임베딩은 AAM-Softmax를 통해 학습되며, 마진 값은 0.2, 스케일 값은 30으로 설정하였으며, 평가 지표로는 동일 오류율(Equal Error Rate, EER)을 사용했다.
제안한 시스템의 우수성을 평가하기 위한 baseline 시스템으로는 사전 학습된 거대 모델인 WavLM 또는 HuBERT와 임베딩 추출기인 ECAPA-TDNN을 결합한 시스템을 제안하는 시스템과 동일한 환경에서 학습을 진행한 모델을 활용하였다.
4.3 도메인 내 잡음 환경 평가 결과
Table 1은 학습 환경에서 마주칠 수 있는 잡음에 대한 강인성을 평가하기 위해, 도메인 내 잡음 환경에서 각 SNR 별 시스템에 따른 화자 인증 성능을 비교한 결과이다. 이 때, 분석의 용이성을 위해 잡음 환경의 경우 평균 동일 오류율을 추가로 표기하였다. 기준 시스템으로 활용된 단일 입력을 활용하는 미세조정 시스템의 경우, 깨끗한 환경에서 동일 오류율 0.94 %를 기록하였으며, 잡음 환경의 경우 평균 동일 오류율 2.65 %를 기록하였다.
Table 1.
EER of the each systems in In-domain (MUSAN) noise environment.
단일 입력을 활용한 교사 학생 학습을 적용한 시스템인 NAW-SV[3]의 경우, 깨끗한 환경에서 동일 오류율 0.85 %를 기록하여 기준 시스템 대비 약 9 % 의 상대 개선율을 달성하였고, 잡음 환경의 경우 평균 동일 오류율 2.31 %를 기록하여 12 %의 상대 개선율을 달성하였다. 이는 선행 연구 흐름에서 알려진 바와 같이 기존 교사 학생 학습이 잡음 환경에서의 화자 인증 시스템의 일반화 성능 개선에 효과적임을 시사한다.
다중 입력을 활용하는 제안한 시스템의 경우, 깨끗한 환경에서 동일 오류율 0.76 %를 기록하여 기준 시스템 대비 약 19 %의 상대 개선율을, NAW-SV 시스템 대비 약 10 %의 상대 개선율을 달성하였다. 또한 잡음 환경에서는 기준 시스템 대비 평균 동일 오류율 18 %을, NAW-SV 시스템 대비 약 6 %의 상대 개선율을 달성하였다. 특히, SNR 조건별 성능을 분석한 결과, Speech 및 Music 잡음 환경에서 SNR 0 dB을 제외한 모든 SNR 조건에서 제안한 다중 입력 시스템이 가장 우수한 성능을 보였다. 이는 다중 입력 기반의 특성이 다양한 잡음에 대해 강인한 특징을 추출할 수 있음을 의미한다. 반면, SNR 0 dB 조건에서는 제안한 시스템의 동일 오류율이 다소 증가하는 경향을 보였는데, 이는 음성 신호와 잡음 신호의 크기가 동일하여 잡음 속에 발화 신호가 부분적으로 섞여 있는 경우가 많기 때문으로 해석된다. 이러한 상황에서는 모델이 발화와 잡음을 명확히 구분하기 어려워 성능 저하가 발생할 수 있다. 그럼에도 불구하고, 전반적으로 제안한 시스템은 다양한 잡음 조건에서도 기존 시스템 대비 일관된 성능 향상을 달성하였다.
4.4 도메인 외 잡음 및 다양한 잡음 환경 평가 결과
Table 2 는 미지의 잡음에 대한 강인성을 평가하기 위해, 도메인 외 잡음 환경에서 각 SNR 별 시스템에 따른 화자 인증 성능을 비교한 결과이다. 단일 입력을 활용하는 기준 시스템의 경우, 도메인 외 잡음 환경에서 평균 동일 오류율 3.87 %을 기록하였으며, 선행 연구인 NAW-SV시스템은 평균 동일 오류율 3.29 %를 기록하였다.
Table 2.
EER of the baseline and proposed system in out-of-domain (Nonspeech 100) noise enviroment.
다중 입력을 활용하는 제안한 시스템의 경우, 도메인 외 잡음 환경에서 평균 동일 오류율 1.99 %를 달성하였다. 이러한 결과는 기준 시스템 대비 약 49 %의 상대 개선율을, NAW-SV 시스템 대비 약 40 %의 상대 개선율을 달성한 결과이며, 특히 모든 SNR 조건에서 큰 폭으로 개선되는 것을 확인할 수 있다.
Table 3은 다양한 환경에서의 제안한 시스템의 강인성을 평가하기 위해, VoxSRC 2023, VOiCES, VCMix 챌린지 데이터 셋에서 기준 시스템 및 NAW-SV, 제안한 시스템을 평가한 결과이다. 제안한 시스템은 VoxSRC 2023과 VCMix 데이터셋에 대해 성능 향상을 나타냈으며, 기준 시스템 대비 최대 6 %, NAW-SV 시스템 대비 최대 4.4 %의 상대 개선율을 기록하였다. 이러한 결과는 제안한 다중 입력 기반 시스템이 미지의 잡음 환경뿐만 아니라 실제 환경에서도 높은 일반화 성능과 강인성을 보임을 나타낸다. 이는 서로 다른 입력 특징 간의 상호보완적 정보를 효과적으로 통합함으로써, 시스템이 다양한 잡음 유형에 대해 적응적으로 대응할 수 있음을 시사한다.
Table 3.
EER of the baseline and proposed system in various datasets.
| Dataset | Method | EER (%) |
| VoxSRC 2023 | Baseline | 5.66 |
| NAW-SV | 5.55 | |
| Proposed | 5.31 | |
| VCMix | Baseline | 2.87 |
| NAW-SV | 2.86 | |
| Proposed | 2.77 | |
| VOiCES | Baseline | 8.13 |
| NAW-SV | 6.65 | |
| Proposed | 8.02 |
그러나 VOiCES 데이터셋에 대한 실험 결과에서는 기존 연구인 NAW-SV 시스템이 제안한 시스템 대비 우수한 성능을 보여준다. 이는 NAW-SV에서 제안된 잡음 환경에 적합한 학습 전략 및 손실함수로 인한 결과로 분석된다. 따라서, 향후 연구에서 본 연구의 다중 특징 구조와 이러한 학습 전략을 결합하여 실제 환경에서 더욱 향상된 잡음 강인성을 달성하는 방향으로 발전시킬 계획이다.
V. 결 론
본 연구는 다양한 잡음 환경에서의 화자 인증 성능을 향상시키기 위한 다중 입력 특징 기반 교사 학생 학습 프레임워크를 제안하였다. 다양한 잡음 유형에 효과적으로 대응하기 위해, 시간 축 상의 원시 파형과 주파수 축 상의 스펙트로그램 정보를 병렬적으로 처리하는 구조를 도입하고, 어텐션 기반 특징 융합 모듈을 통해 두 입력의 상호보완적인 정보를 적응적으로 통합하였다. 제안한 시스템은 WavLM base+를 사전 학습된 거대 모델로 교사 및 학생 모델에 활용하였으며, 화자 인증 백엔드 모델로는 ECAPA-TDNN을 결합하여 구성하였다.
제안한 시스템은 VoxCeleb2 학습 데이터를 활용하여 학습되었고, 평가는 VoxCeleb1 trial-O 파티션에 대해 도메인 내 잡음 환경, 도메인 외 잡음 환경과 다양한 챌린지 데이터셋을 이용하여 수행되었다. 실험 결과, 기준 시스템에 비해 도메인 내 잡음 환경에서는 약 18 %의 상대 개선율, 도메인 외 잡음 환경에서는 약 49 %의 상대 개선율을 달성하였으며, 다양한 실제 환경 데이터셋인 VoxSRC 2023, VCMix 환경에서 최대 6 %의 성능 향상을 보여주었다. 이는 다중 입력 기반 구조가 잡음 환경에서 화자 인증 시스템의 강인성과 일반화 성능을 효과적으로 향상시킬 수 있음을 시사한다. 그러나 VOiCES 데이터셋에서는 기존 연구인 NAW-SV 시스템 대비 열화된 성능을 보여주었다. 이는 NAW-SV의 학습 전략 및 손실 함수에 기인한 결과로 판단되며, 향후 연구에서 잡음 환경에 적합한 학습 전략 및 손실 함수와의 결합을 통한 실제 잡음 환경에서의 잡음 강인성을 탐구할 필요성이 존재함을 관찰하였다.
