

I. 서 론
음향 신호를 분석하여 음향 신호에서부터 정보를 획득하는 것은 최근의 기계학습 기술 발전에 힘입어 다양한 분야에서 활용되고 있다. 기계학습 기반의 음향 신호 정보 분석은 음향 장면 분석,[1] 음향 이벤트 감지,[2] 비정상 기계 작동음 감지,[3] 수면음 감지,[4] 심박음 감지[5] 등과 같은 다양한 분야에서 응용되고 있다. 이러한 기계학습 기반의 음향 신호 분석 시스템의 학습 과정에서는 분석하고자 하는 대상에 대한 정보를 내포하고 있는 다량의 음향 신호가 필요하다. 일반적인 기계학습 과정에서는 양질의 학습 데이터를 다량 사용하여 대형 신경망 모델을 학습시키는 것이 가장 성능을 확보하기 확실한 방법이지만, 현실적으로 다량의 데이터를 획득하는 것이 어려운 경우가 많다. 음향 장면 인식 혹은 음향 이벤트 감지의 경우 지도학습을 위한 정답 데이터를 만들기 위해서는 사람이 직접 청취하여 정보를 만드는 과정이 필요하며 이에 따라 학습 데이터 제작 비용이 증가한다. 또한 목표로 하는 음향 이벤트 자체가 수집의 어려움으로 인하여 다수의 데이터 확보 자체가 어려운 때도 있다. 앞서 서술한 바와 같이 현실적으로 다량의 데이터를 확보하기가 어려운 경우가 다수 존재하기 때문에, 적은 수의 학습 데이터만 가용한 환경을 상정한 연구 또한 많이 진행되고 있다.
가용할 수 있는 데이터가 적은 환경에서는 일반적으로 다른 공개 데이터셋에서 유사한 데이터를 사용하거나 사전 학습된 모델을 사용하는 등의 방법을 사용하여 부족한 데이터로 인한 문제를 완화하고자 한다.[6,7] 그렇지만 공개 데이터셋을 사용하는 경우 데이터가 수집된 환경이 다른 경우가 많으며 같은 분류로 범주화되어 있을 때도 녹음 장치의 기기 특성 및 녹음된 환경의 공간적 특성과 같은 음향적 특성이 다르거나 데이터의 품질이 담보되어 있지 않으면 추가적인 정련 작업을 필요로 한다. 목표로 하는 데이터와 다른 데이터로 구성된 음향 데이터셋을 사용하여 이미 학습이 완료된 모델을 사용하는 방법은 같은 방식으로 획득한 입력 특징을 사용하여야 하며 신경망의 구조 또한 대상으로 하는 사전학습 모델에서 변경하기 어려운 제약이 존재한다. 그러므로 다량의 데이터에서 학습된 사전 학습된 모델을 사용하고자 하는 경우 추론을 하기 위해 필요로 하는 연산량이 크며 상대적으로 다량의 매개변수를 가지기 때문에 추론 하드웨어의 성능 제약이 상대적으로 커지게 된다.
초기의 음향 장면 인식을 위한 시스템은 추출한 음향 신호의 특징을 사용하여 은닉 마르코프 모형, 서포트 벡터 머신, 제약 볼츠만 머신 등의 방법을 사용하였으나,[8] 이후 분류 성능상의 이점으로 신경망을 사용하는 기계학습 기반의 분류기가 주로 사용되었으며, 간단한 합성곱 계층 위주로 구성된 신경망에서부터[9] 발전하여 다수의 합성곱 계층이 깊게 구성된 VGGNet[10]과 유사한 구조의 신경망[11]을 사용하며 이후 다중 필터 크기의 합성곱 계층이 병렬로 구성되는 Inception network[12]의 구조 일부를 차용하거나[13] 잔차를 사용하여 다수의 합성곱 계층의 학습을 용이하게 하는 ResNet[14] 구조의 분류 신경망[15] 및 자기어텐션 메커니즘을 가지는 Transformer[16] 신경망 구조가 사용되고 있다. 최근에는 이러한 방법들이 조합되어 목적에 맞도록 신경망 구조를 개선 및 변형하여 사용하고 있다.
본 논문에서는 가용할 수 있는 데이터가 적은 제약조건 아래에서 음향 장면 분류를 위한 신경망을 학습시키기 위해 2단계로 구성된 기계학습 방법론 및 신경망 구조를 제안한다. 제안하는 기계학습 방법론은 사전 학습된 모델을 교사 모델로 사용하여 대상으로 하는 데이터 및 공개 데이터셋으로부터의 다량의 데이터를 사용하여 특징 추출 신경망을 사전학습 모델의 결과를 추종하도록 학습시킨다. 이후 정답 분류가 없는 데이터에서부터 학습 완료한 특징 추출 신경망을 사용하여 레이블이 존재하는 소규모의 데이터의 특징을 추출하여 추출한 특징을 입력으로 받는 작은 규모의 분류기 신경망을 학습한다. 제안하는 신경망 구조는 적은 양의 매개변수로 구성된 경량 모델로 사전 학습된 모델의 결과를 효율적으로 추종하도록 구성하였다. 제안하는 학습 방식과 유사한 지식 증류(knowledge distillation) 학습 방식이 음향 장면 인식 과제에서 사용된 바 있으나, 이러한 학습 방식은 복잡도가 제한된 환경에서 복잡도 제한이 없는 교사 모델을 먼저 학습시킨 이후 학생 모델의 학습 과정에서 교사 모델의 출력을 사용한다는 것에서 제안하는 방식과는 차별성이 존재한다.
제안하는 방법을 검증하기 위하여 소규모의 데이터로 구성된 실내 사무실 환경을 대상으로 하는 음향 장면 인식 문제를 설정하여 실험을 진행하였다. 수집한 소규모의 데이터 및 기존의 음향 장면 데이터셋 중 유사한 분류의 음향 장면을 가지는 소량의 데이터를 사용하여 음향 장면 분류 성능을 실험하였으며 일반적으로 사용하는 분류기 모델과 제안하는 모델의 복잡도를 비교하여 제안하는 모델의 경량화 정도를 평가하였다. 분류 성능 및 경량화 정도를 평가한 결과 제안하는 방법론은 기존의 분류기 학습 방식과 대비하여 유사한 복잡도 수준에서 더 우수한 분류 성능을 달성하였다.
II. 관련 연구
음향 장면 인식 문제는 기록된 음향 신호를 분석하여 어떠한 음향 상황에서 기록되었는지 사전에 정의된 분류에 따라 분류하는 문제이다. 음향 신호를 분석 및 분류하는 시스템은 특정 시간 길이를 가지는 음향 신호를 분석하여 분류 결과를 출력하는 것을 목표로 한다. 목표로 하는 음향 장면 인식 문제를 도식화하면 아래의 Fig. 1과 같다.
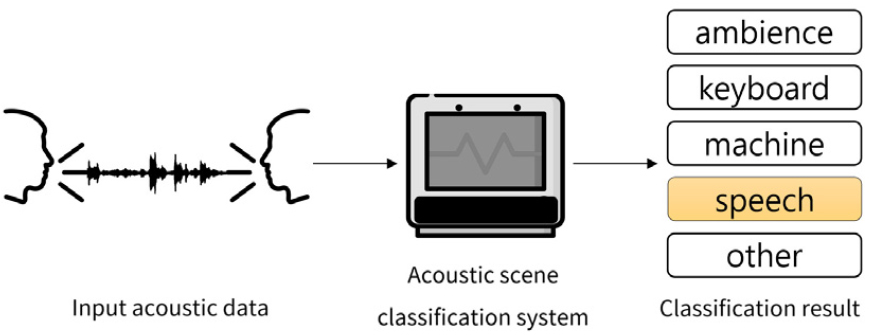
본 연구는 수집한 실내의 사무실 환경에서의 음향 장면들을 분류하는 것을 목표로 하며 학습 데이터로 소량의 데이터만 사용할 수 있는 환경에서 효율적으로 분류기를 학습하고자 한다. 음향 장면 인식 연구의 대다수는 실외 환경에서 수집한 데이터를 대상으로 진행된다. 이러한 음향 장면 인식 연구를 위한 데이터셋들은 대부분 넓은 야외 공간의 환경에서 기록된 음향 신호로 구성되어 있으며 공항, 쇼핑몰, 지하철 역사, 공원, 대중교통과 같은 공간에서의 환경 데이터로 구성되어 있다.[17,18] 음향 장면 인식을 위한 데이터의 경우 대부분 야외에서 수집된 데이터가 위주로 되며 실내에서의 음향 장면이 위주가 되는 데이터셋은 희소한 편이다. 실내 환경에서의 음향 장면 데이터셋은 드물게 존재하며, 공개 되어 있는 실내 음향 장면 데이터셋[19]의 경우 실내 가정환경의 음향 장면을 수집하였으며, 가정환경을 대상으로 하는 데이터셋이기에 본 연구와는 다른 특성의 음향 장면으로 구성되었다. 이러한 실내 가정환경의 데이터셋은 식사, 음식조리, 집안일과 같은 음향 장면 데이터가 다수를 차지하기 때문에 목표로 하는 음향 장면과의 특성 차이로 인하여 같은 실내 환경임에도 데이터 사용이 제한적이다.
본 연구에서의 음향 장면 분류 시스템이 목표로 하는 실내 사무실 환경의 음향 데이터는 실제 사무실 환경에서 수집한 데이터를 사용하였으며, 데이터는 ‘ambience’, ‘keyboard’, ‘machine’, ‘other’, ‘speech’의 5개의 분류로 구성하였다. 시스템은 실내의 사무실 환경에 위치하는 기기에 탑재되어 수집한 음향 신호를 분석하여 5개의 분류에서 어떤 음향 장면 분류인지에 대한 정보를 제공하는 것을 목표로 한다. 실제 기기에서 추론이 가능한 신경망을 목표로 하기에 신경망 복잡도 또한 추산하여 일정 수준 이하로 억제하는 것을 목표로 한다.
이와 관련된 연구로는 최근 매해 진행되고 있는 Detection and Classification of Acoustic Scenes and Events(DCASE) challenge의 Task 1의 음향 장면 인식이 있으며 음향 장면 인식은 challenge의 처음 시작과 같이 계속 진행되고 있다. 최근에 진행된 2024년은 ‘data efficient low complexity acoustic scene classification’의 주제로 진행되었으며 신경망이 실제 모바일 단말기에서 추론 연산이 가능하도록 낮은 복잡도를 가지도록 하며 학습 데이터의 양적 비율을 점진적으로 감소시켜서 분류 성능을 평가하여 적은 데이터 규모에서도 분류 성능감소를 최소화하도록 한다. DCASE Task 1의 경우 학습 데이터를 점진적으로 감소하여 총 139,620개의 학습 데이터 샘플의 성능에서부터 50 %, 25 %, 10 %, 5 %의 감소한 양의 학습 데이터를 사용하여 신경망을 학습하여 분류 성능을 평가한다. 최소의 학습 데이터로 평가하는 경우인 5 %의 학습 데이터로 학습할 때 6,980개의 샘플을 사용하여 학습하게 된다. 이외의 적은 데이터를 사용하는 연구로는 8,732개의 학습 데이터 샘플로 구성된 UrbanSound8K,[20] 8,640개의 학습 데이터 샘플로 구성된 TUT Urban Acoustic Scenes 2018[18]과 같은 경우로 적은 데이터를 사용하여 진행하는 음향 장면 인식 연구의 학습 데이터도 약 7,000 ~ 8,000개 정도의 양을 지닌다.
본 연구는 이와 유사하게 소수의 분류 데이터만 가용할 수 있는 상황에서도 효과적인 분류기 개발을 하는 것을 목표로 하였으나, 학습에 사용할 수 있는 데이터 중 목표로 하는 환경의 데이터가 1,514개의 샘플 및 유사한 분류의 타 데이터셋의 샘플 2,863개의 데이터로 작은 규모의 학습 데이터 환경에서 분류기 학습을 진행하였다.
본 연구에서는 학습 데이터의 부족을 완화하기 위하여 사전학습 모델을 사용하여 신경망 일부를 학습하는 방식을 사용하였는데, 이는 규모가 큰 신경망에서부터 작은 규모의 신경망을 학습시킨다는 것에서 지식 증류 방식의 학습과 공통점을 지닌다. 지식 증류는 일반적으로 모델의 복잡도에 대한 제약이 존재하는 경우 크기의 제약 없이 큰 모델을 먼저 학습한 이후 학습 한 모델을 교사 모델로 삼아 소규모의 학생 모델을 학습하는 방식의 학습 기법이다. 그렇기에 교사 모델은 목표로 하는 데이터에 대해서 먼저 학습을 진행하며 학생 모델과 같은 데이터를 사용하여 학습하게 된다. 음향 장면 인식 문제에서 지식 증류를 사용하는 경우는 사전학습 모델을 사용하지 않는 상태로 학습하는 것이 일반적이며[21,22,23,24] 사전학습 모델을 사용하는 경우 목표로 하는 데이터에 맞추어 추가적인 미세조정을 위한 학습을 하여 사전학습 모델 자체가 교사 모델의 형태로 사용된다.[25,26] 본 연구의 경우 다른 데이터를 사용하여 학습이 완료된 사전학습 모델의 출력 특징을 차원 축소하여 학습하고자 하는 신경망 대다수를 지식 증류로 학습하며 이후 목표로 하는 데이터를 사용하여 학습을 진행하는 방식으로 기존 음향 장면 인식에서 사용되어 온 지식 증류 방식과는 차이가 존재한다.
III. 제안하는 시스템
본 논문에서는 부족한 학습 데이터로 인한 신경망 학습의 어려움을 극복하기 위하여 특징 추출기와 분류기로 구성된 2단계의 분류기 시스템을 제안한다. 대부분의 매개변수가 위치하는 특징 추출 신경망은 학습 과정에서 음향 신호의 분류 정보를 사용하지 않으며 사전 학습된 대형 신경망 모델의 출력을 추종하도록 학습하기 때문에 학습 데이터로 분류되지 않은 데이터 혹은 다른 데이터셋의 데이터를 사용하여 학습할 수 있으므로 분류된 학습 데이터의 부족 문제를 완화할 수 있다.
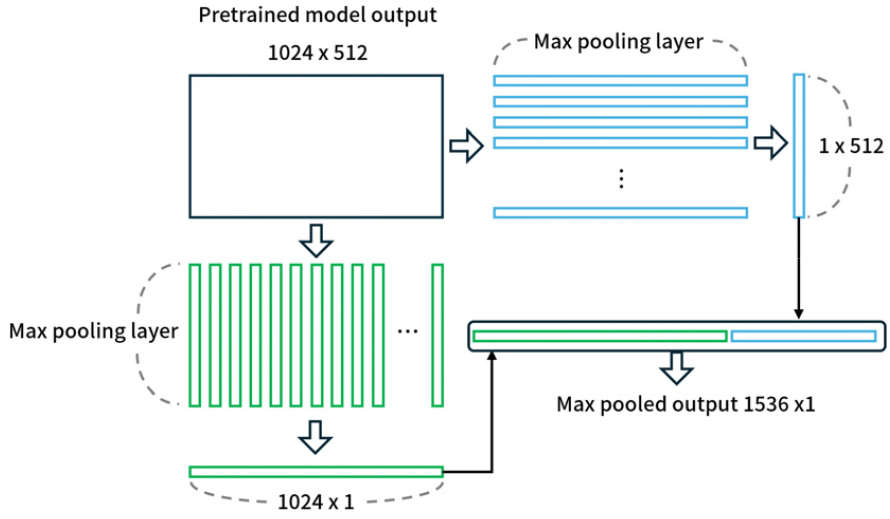
분류기 시스템의 신경망은 사전 학습된 거대 신경망의 출력을 추종하도록 특징 추출기를 학습하며 이후 목표로 하는 음향 장면을 분류하도록 분류기를 학습한다. 신경망 구성 중 먼저 학습되는 특징 추출을 위한 신경망은 사전학습이 완료된 약 3억 개의 매개변수를 가지는 음향 특징 추출 모델인 Reference [27]의 EAT-large 모델에서부터 획득하는 음향 신호의 표현형을 추종하도록 특징 추출 신경망을 학습한다. 본 연구에서 사용하는 사전학습 모델에서 획득하는 음향 특징은 1,024 × 512의 차원의 데이터이며 이러한 방대한 차원 데이터 전체를 추종하도록 학습하는 경우 특징 추출 신경망의 크기 및 필요 연산량 또한 증가하게 된다. 그래서 신경망 규모 및 연산량을 절감하기 위하여 제안하는 시스템은 사전 학습된 모델에서 획득하는 방대한 크기의 특징 데이터에 대해 max pooling layer를 사용하여 각 축에서 최댓값을 획득하는 방식으로 차원 축소를 진행한다. 본 연구에서 max pooling layer를 적용하는 경우 Fig. 2와 같이 사전학습 모델에서 획득한 특징 데이터에 대해 max pooling layer를 사용하여 차원 축소를 거친 결과물인 1,536 × 1차원의 데이터를 학습 목표로 사용하며 특징 추출기의 학습 과정에서는 사전학습의 출력 결과물을 학습 목표로 사용하기 때문에, 음향 장면이 분류되지 않은 상태의 신호를 사용한 지도학습이 가능해진다.
사전 학습된 음향 특징 추출 모델의 출력 결과를 사용하여 특징 추출기를 지도학습을 한 이후 별도의 분류기 신경망을 학습시킨다. 분류기 신경망은 특징 추출 신경망의 출력을 입력으로 사용하여 학습을 진행하며 분류기 신경망의 학습 과정에서 특징 추출 신경망의 가중치는 고정된 상태로 갱신되지 않는다. 분류기 신경망은 적은 양의 분류 데이터에서부터 학습하기 위하여 적은 양의 가중치를 가지는 구조로 구성하였다. 특징 추출 신경망 및 분류기 신경망을 순차적으로 학습시키는 방식 및 신경망 구조에 대한 전반적인 시스템 개요를 Fig. 3과 같이 나타내었다.
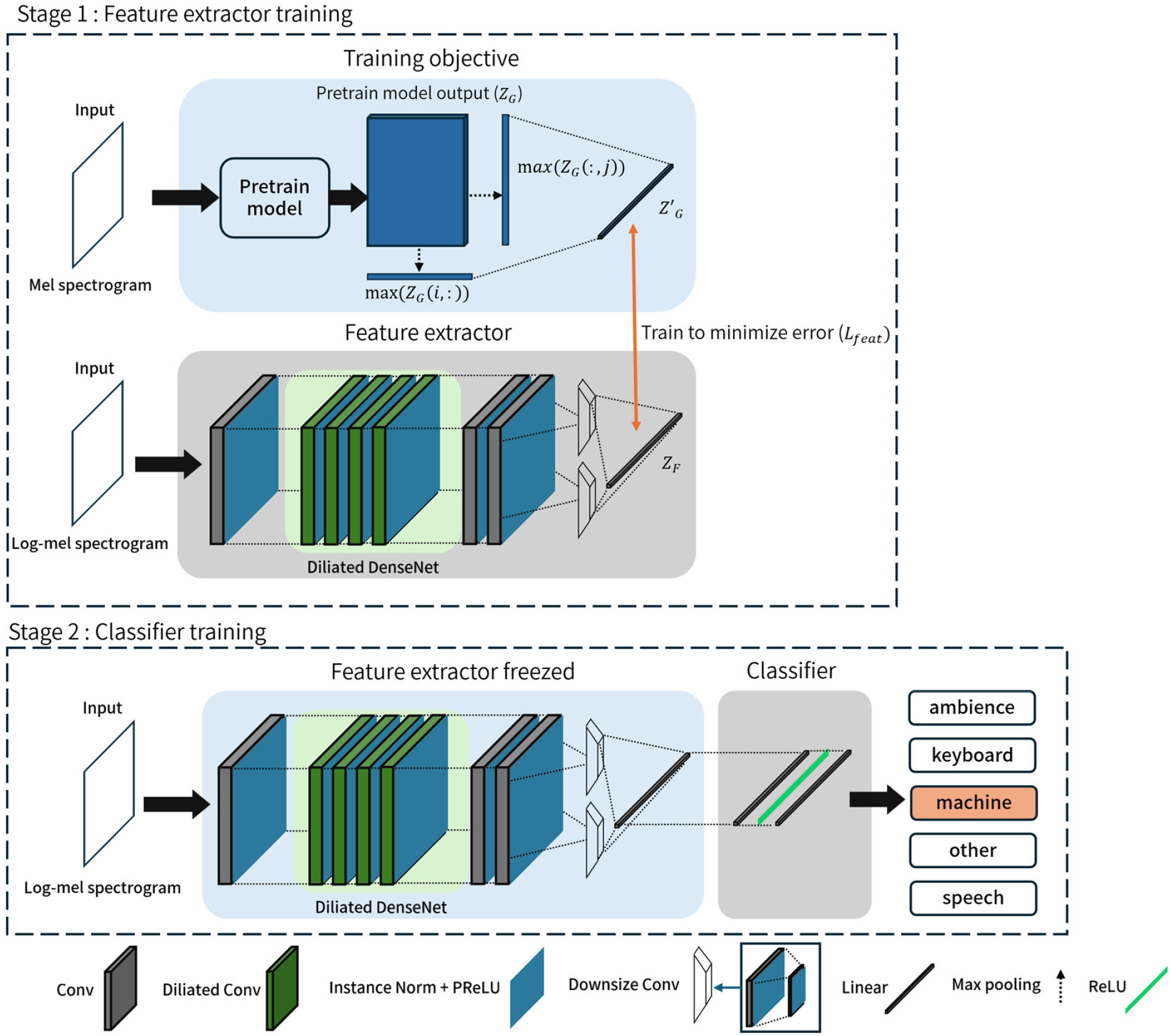
Fig. 3에서의 Stage 1에 해당하는 신경망 중에서 먼저 학습이 진행되는 특징 추출 신경망은 파라미터 대비 효과적인 특징 추출기로 음성 신호 향상을 위한 신경망 구조의 일부로 사용된 바 있는[28,29] Dilated DenseNet[30]을 기반으로 하는 신경망으로 Instance normalization 및 PReLU 활성화 함수가 추가된 합성곱 계층이 Dilated DenseNet의 전후에 위치하며, 이후 출력 특징의 차원을 축소하기 위한 합성곱 블록을 통과한다. 입력 데이터는 1 × 1 크기의 필터로 구성된 합성곱 계층을 통과한 이후 깊이 4의 Dilated factor의 Dilated DenseNet을 거친다. Dilated DenseNet의 출력 결과물은 1 × 3의 필터 및 3 × 1의 필터로 구성된 합성곱 계층을 거친다. 이후의 차원 축소를 위한 합성곱 계층 이전까지의 모든 합성곱 계층은 같은 채널 수로 구성이 되어 있으며 본 실험에서는 64 및 128채널의 구성의 신경망을 사용하여 실험을 진행하였다. Dilated DenseNet 이후의 차원 축소를 위한 합성곱 블록은 같은 입력을 받는 2개의 같은 구조가 병렬화되어 각각 별개의 출력을 출력한다. 병렬화된 합성곱 블록은 각기 3 ×3의 필터 크기를 가지며 각 16, 4개의 채널 수를 가진다. 차원 축소를 위한 합성곱 계층 이후 선형 계층을 통과한 결과가 특징 추출 신경망의 출력이 된다. 특징 추출 신경망은 학습 과정에서 신경망의 출력 결과물이 사전학습 모델의 출력 결과물과의 오차를 최소화하도록 학습한다. 멜 스케일의 스펙트로그램을 입력으로 받은 사전학습 모델의 출력을 라고 할 때 학습하고자 하는 특징 추출 신경망이 학습 목표로 하는 사전학습 모델의 출력 특징에서 차원 축소를 진행한 결과인 은 아래의 Eq. (1)과 같이 쓸 수 있다.
로그 멜 스케일의 스펙트로그램을 입력으로 받는 학습하고자 하는 특징 추출 신경망의 출력을 라고 할 때 사전학습 모델의 출력 과의 오차를 최소화하도록 학습하는 과정에서 데이터의 강조된 특징점 및 일반화 성능을 확보하고자 L1 및 L2 오차의 합을 손실 함수로 사용하였으며, 사용한 손실 함수 은 아래의 Eq. (2)와 같이 쓸 수 있다.
특징 추출 신경망의 학습이 완료된 후 분류기 학습 과정에서는 특징 추출 신경망의 가중치 갱신을 멈춘 상태로 특징 추출 신경망의 출력 을 입력으로 하는 선형 계층의 조합으로 구성된 분류기 의 출력을 사용하여 정답 레이블인 에 대하여 교차 엔트로피 손실 함수를 사용하여 아래의 Eq. (3)과 같이 학습한다.
IV. 실험 설정 및 평가
4.1 실험 환경 설정
모든 실험 과정에서는 16 kHz의 샘플링 주기를 가지는 10 s 단위의 음향 신호를 사용하였으며 소모시간 평가 과정에서는 Nvidia RTX 4090 GPU 및 AMD Threadripper 3970x CPU를 사용하여 시간을 산출하였다. 사전학습 모델의 경우 학습되었을 때와 같은 입력 특징인 128개의 멜 스케일의 스펙트로그램을 사용하였다. 이외의 모든 신경망의 입력으로는 2,048개의 샘플을 75 % 오버랩을 하여 128개의 멜 단위로 구성한 로그 멜 스케일의 스펙트로그램을 사용하였으며 이는 시험 과정에서 멜 스케일의 입력 특징을 사용하는 것 대비하여 로그 멜 스케일을 사용하여 학습한 경우의 성능이 모든 모델에서 상대적으로 우수한 성능을 보이는 것을 확인하였기 때문에 사전학습 모델 이외의 입력 특징은 로그 멜 스케일의 입력 특징을 사용하였다. 제안하는 방식의 분류 성능을 비교하기 위하여 실내 음향 활동 분류를 목표로 하는 DCASE 2018 Task 5의 baseline 시스템[31]으로 사용되었던 합성곱 계층을 사용하여 구성된 간단한 구조의 분류기 신경망의 구조 증강 버전 및 잔차 연결 구조로 인해 효과적인 학습이 가능하며 일반화 성능이 우수하여 분류기 신경망으로 광범위하게 사용되고 있는 ResNet 분류 신경망 시스템을 사용하여 비교 분석을 진행하였다. DCASE 2018 Task 5에서 사용되었던 신경망의 합성곱 계층은 필터 수 32, 64의 2개로 구성되어 있으나, 3개의 합성곱 계층, 64, 128, 256개의 필터 개수로 증강하여 사용하였다. ResNet 신경망은 전체 계층 수에 따라서 숫자를 추가하여 명명하는데, 본 연구에서는 비교 평가에 ResNet 18, 34, 50, 101의 신경망을 사용하였으며 ResNet 이후의 각 숫자의 경우 계층 수의 합을 의미한다. 모든 학습 과정에서는 AdamW 최적화기[32]를 사용하였으며, StepLR 학습률 조정기를 사용하였다. 학습 및 평가에 사용한 데이터는 아래의 표와 같이 수집한 데이터에 대해 학습 데이터를 85 % 및 평가 데이터를 15 %로 나누어 구성하였다. 사용한 외부 데이터의 경우 Arca 23K[33] 및 FSD 50K[34] 데이터셋을 사용하였으며, 분류기 학습 과정에서는 분류한 녹음 데이터 및 외부 데이터셋에서 유사한 분류 값을 가지는 데이터를 같이 사용하였으며 제안하는 방식의 특징 추출기의 학습 과정에서는 레이블을 지니는 분류기 학습 데이터 및 레이블을 지니지 않는 외부 데이터를 모두 사용하였다. 각 레이블에 따른 학습 데이터 샘플수를 Table 1와 같이 정리하였다.
Table 1.
Data distribution of each class used for training and evaluation. Target train and external train (labeled) were used in all training processes, while external train (unlabeled) was additionally used for training the feature extractor in the proposed method.
4.2 성능 평가 지표
제안하는 방법론에 대해 분류 성능 및 경량화 정도에 대해 평가를 진행하였으며 학습 과정에서 사용되지 않은 15 %의 데이터에 대한 분류 성능을 평가하였다. 일반적으로 분류 성능 평가를 위해 사용하는 지표인 F1 점수를 사용하여 제안하는 방법의 분류 성능을 평가하였으며, F1 점수를 사용하였다. F1 점수는 정답과 분류기가 예측한 결과로 산출되는 점수로 True Positive(TP: 정답), False Positive(FP: 위양성), False Negative(FN: 위음성)로 산출하며 아래의 Eq. (4)와 같이 산출한다.
분류에 따른 평가 데이터의 양이 다르기에, 각 분류에 따른 평가 결과를 합산 내는 방식에 따라서 세부적인 F1 점수가 나뉜다. F1 micro는 결과를 따로 레이블에 따라 분류하지 않고 전체에 대해서 산출하는 경우이며 F1 macro는 레이블별로 결과를 산출하여 평균 내는 경우이다. F1 weighted는 각 레이블에 따른 평가 데이터양의 불균일을 보정하기 위해서 각 분류별 샘플수에 따라 가중 평균하여 결과를 도출하는 경우이다. 분류 성능에 대한 평가는 상술한 F1 micro, F1 macro, F1 weighted 점수를 사용하여 평가하였다.
경량화 정도의 평가는 신경망 모델이 가지는 가중치 숫자 및 추론 과정에서의 누적 연산 횟수인 Multiply-Accumulate operations(MACs)로 평가하였다. 신경망 모델 가중치의 수가 적으면 학습 및 추론 과정에서 필요로 하는 하드웨어 시스템 메모리의 요구 조건이 낮아지며 MACs 값이 낮아지는 경우 모델의 추론 과정에서의 필요 연산량이 감소한다. 그러므로 모델의 복잡도 정도의 평가는 장치에서의 필요 시스템 메모리 및 결과를 추론하기 위한 필요 연산량의 2가지 측면에서 평가하였다. 또한 각 방법에 따른 학습 과정의 속도 차이를 산출하기 위하여 1 epoch의 학습에 소모되는 시간을 산출하여 기존의 방법들 및 학습 과정에서 사전학습 모델의 추론이 동시에 진행되는 경우와 사전학습 모델이 사용되지 않는 경우 필요한 추가적인 소모 시간 또한 산출하여 비교 평가를 진행하였다.
V. 실험 결과 및 분석
제안하는 방법의 분류 성능 및 경량화 정도를 평가하기 위해 학습 과정에 사용되지 않은 15 %의 분할된 데이터를 사용하여 분류 성능을 산출하였다. 분류 성능 평가 과정에서는 제안하는 방법의 특징 추출기의 목표인 사전학습 모델에서부터 획득한 특징을 직접 사용하여 학습한 모델(teacher output) 및 같은 신경망 구조로 사전학습 모델을 사용하지 않고 분류 문제로 학습한 결과(proposed w/o pretrain)를 Table 2와 같이 성능을 산출하였다.
Table 2.
Classification performance comparison of the proposed methods with other methods.
각 방법의 분류 성능을 평가한 결과, 제안하는 방법을 사용하여 학습하였을 때 기존 방식으로 학습된 분류 신경망 대비하여 개선된 성능을 획득할 수 있었다. 학습 과정에서 사용할 수 있는 데이터양의 부족으로 인하여 ResNet 계열의 모델의 경우 가장 적은 매개변수를 가지는 ResNet 18 모델의 성능이 ResNet 계열 모델 중에서 가장 우수하였으며 신경망의 규모가 커질수록 데이터 부족으로 인한 성능 저하가 커지는 결과를 확인할 수 있었으며 같은 구조의 신경망을 사용하였지만, 사전학습 모델을 사용하지 않은 경우와 대비하여 제안하는 방식으로 학습을 한 경우 분류 성능을 개선할 수 있었다. 데이터의 부족으로 인해 데이터양 대비하여 신경망의 규모가 큰 ResNet 50 및 101 모델의 경우 더 적은 계층을 가지는 ResNet 18 및 34 모델보다 오히려 분류 성능이 감소하였으며 또한 간단한 구조의 신경망인 DCASA baseline의 구조 증강 버전의 분류 성능이 ResNet 50, 101 신경망 대비하여 우수한 결과를 달성한 것으로도 확인할 수 있다. 64채널을 사용하는 제안하는 모델의 결과는 F1 micro 기준 75.0 %, F1 macro 기준 65.59 %, F1 weighted 기준 74.21 %의 성능을 확보하였으며 이는 ResNet 계열 모델 중에서 가장 우수한 성능을 보인 ResNet 18 모델의 F1 micro 기준 74.63 %, F1 macro 기준 63.59 %, F1 weighted 기준 73.59 %의 성능보다 소폭 우수한 분류 성능을 달성하였다. 64채널의 모델 대비하여 128채널을 사용한 결과는 F1 micro 기준으로 2.27 %, F1 macro 기준으로 2.10 %, F1 weighted 기준으로 2.73 % 개선되어 64채널로 구성된 모델 대비하여 3 % 이상의 큰 성능 개선 폭을 달성하였다. 제안하는 방법의 특징 추출 신경망 학습 과정에서는 사전 학습된 모델의 출력을 추종하도록 학습하기 때문에 사전학습 모델과 같은 출력을 내주는 것이 이상적이다. 그렇기에 학습 과정에서 추종해야 할 대상을 사용하여 직접적으로 분류기를 학습하여 분류 성능을 평가하는 경우 제안하는 방법으로 가능한 성능 상한치를 추정해 볼 수 있다. 사전학습 모델의 출력을 제안하는 방식의 학습 과정에서의 같은 저차원화를 거친 결과를 사용하여 분류기를 학습한 모델의 성능의 경우 F1 micro 기준 78.03 %, F1 macro 기준 68.61 %, F1 weighted 기준 77.78 %의 성능으로 128채널로 구성한 제안하는 방법과 비교하면 F1 micro 기준 0.76 %, F1 macro 기준 0.92 %, F1 weighted 기준 0.84 %의 성능이 우세한 것을 확인할 수 있다. 사전학습 모델의 결과를 직접적으로 저차원화한 결과와 비교하였을 때의 분류 성능 차이가 1 % 미만의 근소한 차이의 성능 하락을 보였으며, 제안하는 방법이 효과적으로 사전학습 모델을 추종하도록 학습하였다는 것을 확인할 수 있었다. 또한 각 신경망 모델의 복잡도 정도를 산출하여 연산량 대비 분류 성능 및 경량화 정도와 사전 모델을 사용함으로써 추가로 발생하는 학습 자원 증가 정도를 판단하고자 Table 3과 같이 매개변수의 양 및 신경망의 연산량 정도를 판단하기 위한 MACs, 매 epoch 학습에 소모되는 학습 시간을 산출하여 정리하였다.
Table 3.
Complexity comparison of the proposed methods with other methods.
신경망의 복잡도를 비교하여 보았을 때, 제안하는 방법의 신경망을 64채널로 구성하였을 경우 모델의 매개변수는 9.85 M개로 ResNet 계열의 가장 소형 모델인 ResNet 18 모델이 가지는 11.17 M 매개변수 대비하여 작은 규모를 가졌으며 연산량 정도를 추산 가능한 MACs의 경우 10.29 G MACs으로 ResNet 18의 21.87 G의 MACs 대비하여 절반 정도의 MACs으로 더 적은 필요 연산량이 필요하였으며, 제안하는 방식의 더 많은 가중치를 사용하는 128채널로 구성하였을 때 17.91 M개의 파라미터를 가지며 41.40 G MACs의 연산량을 가져서 ResNet 34의 21.28 M개의 파라미터 및 45.70 G MACs의 연산량 대비하여 적은 매개변수 및 연산량을 가진다. 제안하는 모델 구조의 경우 학습 과정에 사전학습 모델의 추론 결과를 사용하기 때문에 제안하는 방식의 학습 시간은 기존 방식의 분류기 학습 과정과 대비하여 많은 학습 시간을 요구한다는 단점이 있으나, 이는 학습 때 사전학습 모델의 출력을 매번 새로 추론하여 사용하는 경우이며 사전학습 모델의 출력을 저장하여 불러와서 사용하는 경우 이러한 단점은 완화할 수 있다. ResNet 계열의 분류 모델은 학습 데이터의 부족으로 인하여 ResNet 18의 분류 성능이 가장 우수하였으며 더 많은 매개변수를 가지며 가용할 수 있는 학습 데이터에 대비하여 학습해야 할 매개변수가 방대해짐으로 인한 결과로 추정할 수 있다. 그렇지만 제안하는 방법론으로 학습한 시스템의 경우 기존의 방식에서는 성능이 저하되는 매개변수의 양을 가짐에도 성능이 감소하지 않고 개선되는 결과를 얻을 수 있었다. 간단한 구조로 구성된 DCASE baseline 신경망의 경우 시험한 신경망 중 가장 적은 매개변수를 가지며 또한 가장 낮은 연산량을 가지지만, 그로 인하여 제안하는 방법론 대비하여 분류 성능이 제안하는 64채널 모델 기준 약 3 % ~ 4 %, 128채널 모델 대비해서는 6 % ~ 7 % 정도의 분류 성능이 감소하였기 때문에, 제안하는 방법이 더 많은 매개변수 및 연산량을 지니지만 더 개선된 분류 성능을 달성하였다.
VI. 결 론
본 논문에서는 가용할 수 있는 학습 데이터의 양이 부족하여 신경망 학습이 어려운 환경에서 신경망을 원활하게 학습하기 위해 사전 학습된 모델을 활용하는 2단계의 과정으로 학습하는 시스템을 제안하였다. 제안하는 방법은 사전 학습된 모델 및 정답 분류가 없는 다수의 데이터를 사용하여 대다수의 매개변수로 구성되는 특징 추출 신경망은 사전 학습된 모델의 결과를 추종하도록 학습하며 소수의 매개변수로 구성되는 분류기 신경망 학습 과정에서는 적은 양의 데이터를 사용한 분류 학습을 진행한다. 제안하는 방법을 소규모의 학습 데이터로 구성된 실내 사무실 환경의 음향 장면 환경 데이터를 사용하여 학습 및 평가를 진행하였다. 평가 과정에서는 학습 데이터로 사용되지 않은 데이터를 사용하였으며, 일반적인 분류기 학습 방식으로 학습된 분류기 신경망들을 사용하였다. 각 신경망의 분류 성능 및 경량화 정도를 평가한 결과 신경망 전체를 분류 문제로 학습할 때 학습 데이터가 부족한 상황에서는 ResNet 50, 101과 같은 신경망은 ResNet 18 신경망 구조 대비하여 F1 score 기준으로 약 6 %의 성능이 저하되어 매개변수가 적은 경우가 오히려 성능적으로 더 우수한 결과를 얻을 수 있었다. 그러나 제안하는 방법으로 학습을 한 경우는 더 큰 규모의 매개변수를 가지는 신경망을 사용하는 경우 분류 성능이 상승하여 기존 신경망 구조 중 가장 분류 성능이 좋았던 ResNet18의 결과였던 F1 macro 기준의 73.59 %의 성능 대비 76.94 %의 성능을 획득하여 4.1 %의 성능을 개선 가능하였다. 또한 유사한 규모 매개변수를 가지는 신경망과 비교를 하면 제안하는 방식의 분류 성능이 더 우수한 것을 확인할 수 있었다. 또한 동일한 신경망 구조로 사전학습 모델을 사용하지 않은 상태로 학습을 진행한 결과 대비하여 제안한 방식의 경우 F1 score 기준으로 약 10 % 내외의 개선을 보여주어 제안하는 방식이 데이터가 적은 학습 환경에서 효과적으로 성능을 개선 가능한 것을 확인하였다. 제안하는 방식은 레이블이 없는 데이터에 대해 사전 학습된 특징 추출 모델에서의 출력을 저차원화하여 학습하기 때문에 레이블이 없는 데이터 및 유사한 분야에서 학습된 모델이 필요하다는 한계점 및 학습을 위한 연산 자원이 추가된다는 단점을 지니지만, 레이블이 존재하는 데이터가 제한적인 상황에서 효과적으로 신경망을 학습 가능하다는 장점이 존재한다. 또한 목표로 하는 복잡도 정도에 따라서 신경망의 규모 조절이 쉬우며 사전학습 모델의 입력 특징과 같은 길이의 시간 입력을 가지는 것 이외에는 자유롭게 입력 특징을 설계 가능하다는 장점이 존재한다. 향후 연구에는 음향 장면 인식 이외의 다른 분야의 음향 인식으로의 적용 범위 확대 및 특징 추출기 학습 과정에서 비지도 학습에서 사용하는 학습 방법론 등을 통합하여 특징 추출기 신경망 개선과 같은 연구로 확장하고자 한다.
