

I. 서 론
II. 멀티모달 감정인식 시스템
2.1 EEG 특징 추출
2.2 오디오 특징 추출
2.3 시간적 합성곱 신경망
2.4 Conformer
2.5 예측 및 손실함수
III. 실험 및 결과
IV. 결 론
I. 서 론
감정인식은 인간-컴퓨터 상호작용, 의료 및 의학 분야에서 광범위하게 연구되어 온 도전적인 주제이다. 감정인식에 대한 초기 연구는 주로 텍스트, 오디오, 시각적 신호 또는 생리적 신호와 같은 단일 모달리티 데이터를 활용하여 주목할 만한 성과[1,2]를 거두었다. 그러나 단일 모달리티 신호만으로는 감정을 정확하게 설명하는 데 한계가 존재하기 때문에, 최근에는 두 개 이상의 모달리티를 통합한 멀티모달 감정인식에 대한 연구[3]가 활발하게 진행되고 있다. 이러한 접근 방식은 생리적 신호와 비생리적 신호를 다중 모달리티에 적용하고, 각 모달리티로 부터 감정표현에 미치는 영향을 포괄적으로 포착함으로써 감정인식의 정확도를 향상시키는데 기여한다.
언제 어디서든 콘텐츠를 즐기고 싶어하는 현대인들에게 비디오는 시각적, 청각적 특징으로 풍부한 감정적 의미를 표현할 수 있는 가장 인기 있는 멀티미디어 자극이다. 또한, 해당 비디오를 시청하는 동안 발생하는 인간 뇌파(Electroencephalogram, EEG) 특징은 직접적이고 즉각적인 피드백을 제공하기 때문에 비디오 감정인식에 실제적으로 유용한 정보를 제공할 수 있다. 그러나 EEG 신호의 신호 대 잡음비가 낮아 감정인식 정확도에 영향을 미치는 단점으로 인해, EEG 신호와 함께 결합되어 감정인식 성능을 향상시킬 수 있는 추가적인 모달리티 신호의 적용이 필요하다.
비디오에 포함되어 있는 오디오 신호도 감정 정보를 전달한다는 점을 고려하여, 본 논문에서는 비디오 시청 시 사용자로부터 획득된 EEG 데이터와 해당 비디오의 청각 정보를 포함하고 있는 오디오 신호를 결합한 멀티모달 감정인식 방식을 제시한다.
II. 멀티모달 감정인식 시스템
Fig. 1은 뇌파와 해당 오디오 신호의 두 가지 모달리티로부터 추출한 특징을 융합하여 감정인식 정확도를 향상시키는 멀티모달 감정인식 시스템의 구조도를 나타낸다.
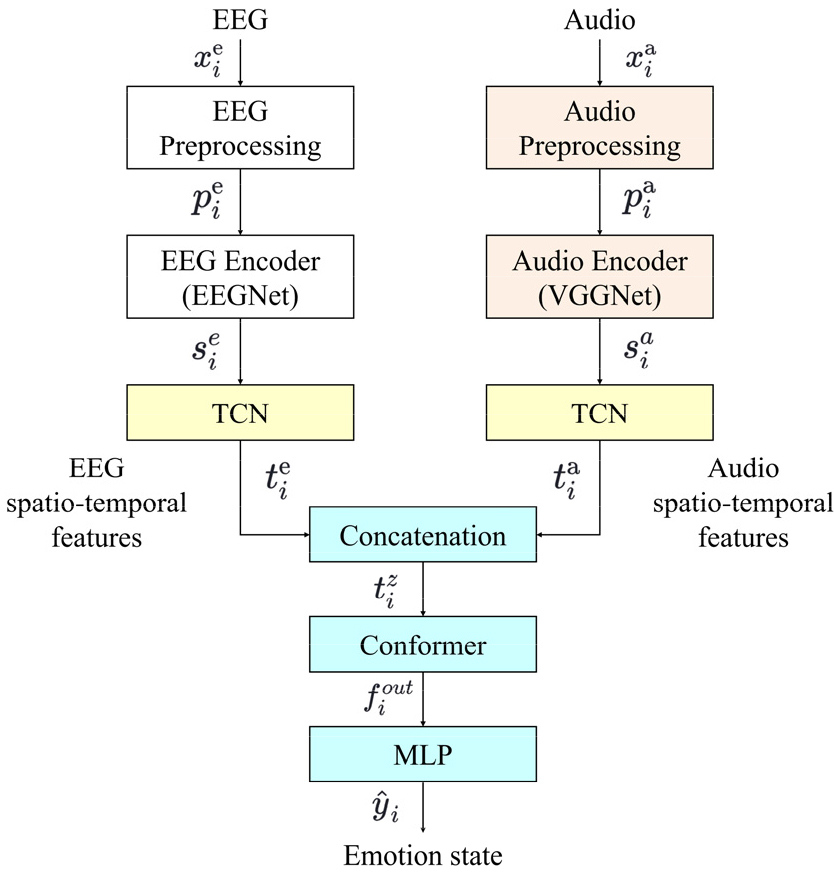
EEG 및 해당 청각 정보에 많은 감정 정보가 포함되어 있다는 사실을 고려하여,[4,5] 제안한 방식에서는 각 모달리티의 입력 데이터에 적합한 공간적 인코더를 각각 적용한 후에 TCN[6]이라는 시간적 인코더를 공통적으로 사용함으로써 모달리티의 원시 데이터로부터 높은 수준의 시공간 특징을 추출한 다음, Conformer[7] 메커니즘을 적용하여 각 시공간적 특징을 병합하여 모델링한 후 다층 퍼셉트론(Multi-Layer Perceptron, MLP)으로 구성된 분류기를 통해 4개의 감정클래스에 대한 분류 결과를 출력한다.
2.1 EEG 특징 추출
EEG 신호는 대뇌피질 내의 신경세포의 전기적 활동을 두피에 부착한 다양한 전극 위치에서 측정하여 감정 자극에 대한 사람의 즉각적인 반응을 획득할 수 있기 때문에 생리 반응 측정 기술을 이용한 감정측정 연구에서 최근 가장 선호되고 있는 생리학적 신호이다.
본 논문에서는 뇌파 신호로부터 시공간 특징을 추출하기 위해 전처리, EEGNet,[8] TCN으로 구성된 EEG 인코더를 적용한다.
먼저, 전처리 과정으로 원시 뇌파신호 로부터 눈 깜박임 아티팩트를 제거하고 세그먼트로 분할하여 주파수 변환을 통해 델타(0 Hz ~ 4 Hz), 세타(4 Hz ~ 8Hz), 알파(8 Hz ~ 13 Hz), 베타(13 Hz ~ 30 Hz) 및 감마(30 Hz ~ 45 Hz) 등의 5개 주파수 대역에 대한 평균 파워를 계산하여 파워 스펙트럼 밀도인 를 구한다. 여기에 EEGNet을 적용하여 공간적 특징을 추출한다.
EEGNet은 EEG 기반 경량형 합성곱 신경망(Convolutional Neural Network, CNN)으로, 2차원 시간적 합성으로 시작하여 주파수 필터를 학습한 다음에 깊이별 합성(depthwise convolution)을 사용하여 주파수별 공간 필터를 학습하고, 분리형 합성을 통해 각 특징맵에 대한 시간 요약을 개별적으로 학습한 후 특징맵을 혼합한다. EEGNet의 분리형 합성(separable convolution)의 출력 특징맵에는 여전히 시간 정보가 포함되어 있기 때문에, 우리는 시간정보를 효과적으로 활용할 수 있도록 TCN을 EEGNet과 연결하여 시공간 특징을 추출한다.
2.2 오디오 특징 추출
EEG 신호를 기반으로 한 감정인식 모델은 가장 실제적인 인간의 감정 상태를 얻을 수 있지만, 단일 모달리티 신호만으로는 감정을 정확하게 설명하는 데 한계가 존재하기 때문에 추가적인 모달리티 신호의 적용이 필요하다. 이와 관련하여, 음성, 리듬, 사운드 등을 포함하는 오디오 신호도 인간의 뇌에 영향을 미치는 감정 정보를 전달한다는 점을 고려하면 뇌파와 오디오 두 가지 신호 모달리티를 융합함으로써 더 나은 감정인식 효과를 얻을 수 있다.
이러한 이유로, 본 논문에서는 해당 비디오에 포함된 원시 오디오 신호를 EEG 신호와 함께 다중 모달리티에 적용하고, 전처리, VGG-Net, 그리고 TCN으로 구성된 오디오 인코더를 이용하여 오디오 시공간 특징을 추출한다.
먼저, 오디오 신호 를 세그먼트로 분할하고 50 ms 길이의 해밍 윈도우와 10 ms의 홉 길이를 가진 단구간 푸리에 변환을 통해 각 단구간 프레임 내 신호의 주파수 신호 성분을 계산한다. 그리고 각각의 프레임에 대해 얻어낸 주파수 성분들을 사람 달팽이관 특성을 고려한 Mel-Scale로 변환하기 위해 20개 멜 필터 뱅크를 일정한 간격으로 적용하여 각 멜 필터 내의 스펙트럼 성분들을 합산하여 출력하고, 이에 로그를 취하여 로그 멜스펙트럼(Log-Mel Spectrum, LMS)인 를 생성한다. 그 다음, 대규모 오디오 데이터 세트에서 사전 학습된 VGG-Net[9]을 통해 LMS를 입력받아 공간적 특징맵을 추출하고, 여기에 TCN을 적용하여 프레임 수준의 오디오 임베딩의 시간 역학을 인코딩함으로써 오디오 시공간 특징을 추출한다.
2.3 시간적 합성곱 신경망
TCN 은 순환신경망과 비교하여 병렬로 시퀀스를 처리할 수 있으며 그래디언트(gradient) 소실 및 폭발 문제를 방지할 수 있다는 장점을 갖고 있다. 이러한 TCN은 인과적 합성곱, 팽창된 합성곱(dilated convolution), 잔차 합성곱(residual convolution)의 세 부분으로 구성되어 시간 경과에 따른 특징의 시간적 패턴과 종속성을 포착할 수 있다. 주요 특징 중 하나로서 TCN의 인과적 합성곱(causal convolution)은 단방향 구조로서 이전 원인에서 다음 결과를 예측할 수 있도록 한다. 또한, 팽창된 합성곱은 합성곱 중에 간격을 두고 팽창계수를 통해 샘플링 속도를 제어함으로써 넓은 시간적 범위를 처리할 수 있으며, 잔차 합성곱은 계층 간에 정보를 효과적으로 전달하는 특성을 갖고 있다.
우리는 각 모달리티에 입력된 뇌파, 그리고 오디오 신호에 적합한 인코더들을 각각 적용하여 추출한 공간적 특징으로부터 시간적 특징을 획득하기 위해 TCN을 공통적으로 적용하였다. 이는 다음 수식과 같이 표현될 수 있다:
여기서 는 EEG 인코더를 통해 추출된 뇌파 공간적 특징, 는 오디오 인코더를 통해 추출된 오디오 공간적 특징, 는 뇌파 시공간 특징, 는 오디오 시공간 특징을 각각 나타낸다. i 는 시간에 따른 데이터 시퀀스의 특정 시점을 나타내며, 이는 EEG와 오디오 신호가 시간에 따라 동기화되어 처리됨을 의미한다. 즉, 모든 에 대해 같은 시간 단계의 EEG와 오디오 데이터가 처리된다.
본 연구에서는 주로 팽창된 합성곱을 사용하여 시간-주파수 데이터에서 시간적 특징을 학습하였다. 즉, TCN을 시청하는 비디오의 각 세그먼트에서 뇌파와 해당 오디오 신호가 시간에 따라 어떻게 변하는지 학습한 후 뇌파와 해당 오디오에 대한 출력 특징 벡터를 차원을 따라 연결하여 결합하였다. 이를 통해 해당 비디오의 각 세그먼트에 대한 오디오 및 해당 뇌파 정보가 모두 포함된 새로운 특징 벡터 를 다음과 같이 연결하여 Conformer에 입력하였다:
2.4 Conformer
Conformer는 전역적인 정보 표현에는 강점이 있지만 지역적 정보 표현에서는 단점을 갖는 트랜스포머 구조에 합성곱 신경망의 기능을 보강함으로써 지역적 및 전역적인 특성을 모두 모델링 할 수 있는 장점을 갖고 있다.
Fig. 2는 Conformer 인코더의 구조를 나타내며, 이는 합성곱 서브샘플링(convolution subsampling) 계층, 선형 계층(linear layer), 드롭아웃(dropout) 계층, 그리고 Conformer 블록으로 구성된다. 합성곱 서브샘플링 계층은 2D 합성곱 연산을 사용하여 입력 시퀀스의 시간과 주파수 차원을 모두 다운샘플링하여 초기 특징을 추출하고 시퀀스 길이를 줄이는 역할을 한다. 선형 계층은 단순한 선형 변환을 수행하여 특징의 차원을 조정한다. 이는 순방향 모듈(feed forward module)과는 달리 단일 선형 변환만을 수행하며, 주로 차원 조정에 사용된다. 드롭아웃 계층은 과적합을 방지하기 위해 학습 중 무작위로 일부 뉴런을 비활성화시키는 정규화 기법이다.
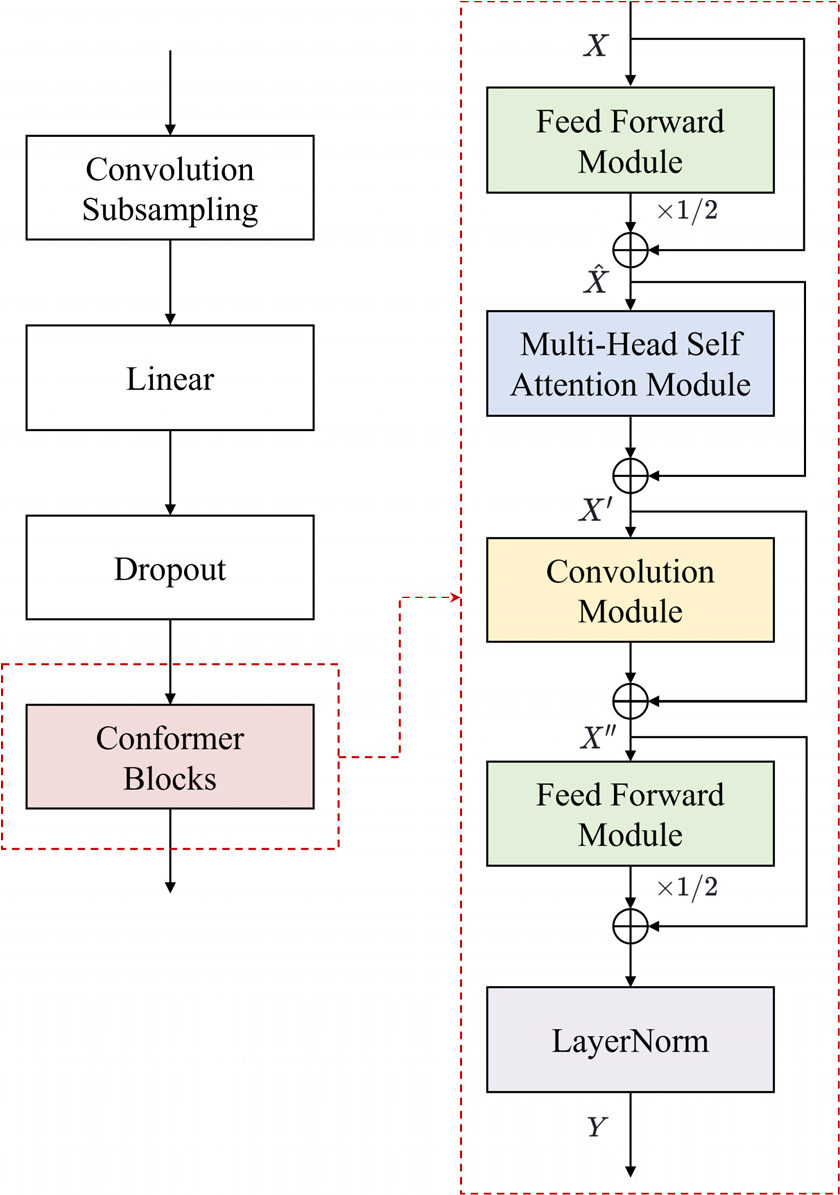
합성곱 서브샘플링 계층과 선형 계층은 입력 데이터의 중요한 특징은 유지하면서 시퀀스의 길이를 줄이는 역할을 하고, Conformer 블록은 전통적인 트랜스포머 구조와 달리 멀티헤드 자기 주의(Multi-Head Self Attention, MHSA) 모듈 뒤에 보강된 합성곱 모듈을 배치하고, 순방향 모듈을 두 부분으로 나누어 멀티헤드 자기 주의 모듈을 감싸는 구조를 통해 성능을 향상시킨다. 순방향 모듈은 두 개의 선형 계층과 그 사이의 비선형 활성화 함수로 구성되어 있어 더 복잡한 비선형 변환을 수행한다.
각 모듈은 층 정규화 단계로 시작하며, 입력을 출력에 더하는 잔차 연결(residual connection)이 적용되었다. Conformer 블록의 입력과 출력을 각각 와 로 할 때, Conformer 블록은 다음 Eqs. (3), (4), (5), (6)과 같이 표현될 수 있다:
여기서 , , 그리고 는 각각 순방향 모듈, 멀티헤드 자기주의 모듈, 합성곱 모듈, 그리고 층 정규화 모듈을 의미한다. 그리고 , , 는 각각 MHSA의 입력, 합성곱 모듈의 입력, 두 번째 순방향 신경망의 입력을 나타낸다.
따라서 EEG 및 오디오 정보가 모두 포함된 시공간 특징 벡터 를 Conformer 인코더에 적용하여 출력 특징 벡터 를 다음과 같이 생성한다:
일반적으로 Conformer 인코더는 단일 세그먼트 내의 컨텍스트만을 모델링하기 때문에 세그먼트 간 프레임의 종속성이 간과될 수 있다. 그러나 제안된 방법에서는 전처리 과정에서 수행된 연속된 세그먼트 간의 중첩을 활용하여, 서로 다른 세그먼트가 미치는 영향을 효과적으로 포착함으로써 프레임 간의 컨텍스트 상호작용을 고려하였다. 특히, Conformer를 통해 출력된 특징 벡터 는 비디오의 각 세그먼트에서 EEG와 오디오 신호의 다른 부분이 서로 어떻게 관련되어 있는지 학습할 수 있기 때문에 입력된 시공간 특징 벡터 보다 내용적 의미와 표현력이 더 뛰어나다.
2.5 예측 및 손실함수
Conformer를 적용한 모델링 후에, 특징 는 마지막으로 감정 예측을 위해 MLP에 다음과 같이 공급된다:
여기서 는 번째 데이터 샘플의 예측값 이다.
MLP는 입력의 비선형 변환을 학습할 수 있는 여러 층의 뉴런으로 구성되어 있으며 예측 벡터와 실제 값 벡터 간의 오류를 최소화하도록 학습할 수 있어 감정분류에 효과적으로 적용할 수 있다. 본 연구에서는 130개의 뉴런으로 구성된 단일 은닉층을 갖는 MLP를 적용하였으며, 학습을 위해서 다음과 같은 손실함수로 교차 엔트로피(cross-entropy) 손실을 사용하였다:
여기서 은 전체 데이터 샘플의 수이며, 는 각 데이터 샘플의 인덱스를 의미한다. 는 번째 샘플의 실제 레이블을 나타내는 원-핫 인코딩 벡터이며, 는 번째 샘플에 대한 모델의 예측 확률 분포를 의미한다. 이 손실 함수는 모델의 예측 확률 분포와 실제 레이블 분포 간의 차이를 측정한다.
III. 실험 및 결과
제안된 방식의 성능을 평가하기 위해 DEAP 데이터세트[10]를 적용하였다. DEAP 데이터세트는 32명의 참가자(19세 ~ 37세 사이의 남성 16명과 여성 16명)의 EEG와 오디오 신호, 그리고 주변 신호가 포함되어 있는 공개 데이터베이스로 차원적 감정 모델을 사용한다. EEG 신호는 각 참가자가 40개의 음악 비디오 클립을 시청하는 동안 32개의 전극을 사용하여 512 Hz의 샘플링 속도로 기록되었으며, 각 시도에는 63 s의 EEG 신호가 포함되어 있다. 특히, 본 연구에서 적용된 EEG 데이터는 다운샘플링, 대역 필터링을 통해 잡음 제거가 수행되었으며, 눈 깜빡임, 시선의 이동 등과 같은 아티팩트가 사전에 제거되어 있다. 각 참가자는 각 비디오를 시청하고 Self-Assessment Manikin[11] 기법을 사용하여 각성(arousal), 가치(valence), 지배력(dominance) 및 선호도(liking) 수준을 1 ~ 9의 연속 척도로 평가했다.
본 연구에서는 성능 평가 실험을 위해 20명의 참가자(남성 10명, 여성 10명)의 EEG 데이터를 선택했으며, 해당 오디오 신호의 경우 1초 길이의 슬라이딩 윈도우를 사용하여 오디오 신호를 분할하고 중첩 시킨 후, 해당 EEG 데이터와 동기화를 수행하여 오디오 샘플을 획득하였다. 그리고 행복, 슬픔, 화남, 편안함 등의 네 가지 감정 상태를 Leave-One-Subject-Out Cross Validation 방식을 활용하여 제안된 모델의 감정인식 정확도를 측정하였다. 이 측정방식에서는 한 피험자에 속한 샘플은 테스트 세트로 사용되고 나머지 피험자에 속한 샘플은 훈련 세트로 사용된다.
제안한 다중 모달 감정인식 방식의 성능을 비교하기 위하여 참고문헌 조사를 통해 학습한 기존의 방식들을 결합하여 구현된 방식들은 다음과 같다:
∙E-CNN + A-BiLSTM + Softmax[12]: 이 방식은 CNN을 사용하여 EEG 특징을 추출하고, 양방향 장단기 메모리(Bidirectional LSTM, BiLSTM) 신경망을 사용하여 오디오 특징을 추출한 후에, 결합된 다중 모달리티 특징을 Softmax 기반 분류방식에 적용한다.
∙E-TCN + A-TCN + CF + MLP: 공간적 특징추출 없이 TCN만을 사용하여 EEG와 오디오로부터 시간적 특징을 각각 추출한 후에 결합한 다중 모달리티 특징을 Conformer에 입력시킨 후 다층퍼셉트론에 적용시켜 감정을 인식한다.
∙E-ViT + A-CRNN + MLP: 비전 트랜스포머(Vision Transformer, ViT)[13]를 사용하여 EEG 신호로부터 특징을 추출하고, CNN과 Recurrent Neural Network (RNN)을 결합한 CRNN 방식을 적용하여 오디오 특징을 추출한 후에, 오 디오 특징과 EEG 특징을 융합하여 MLP 기반의 분류기에 적용한다.
∙E-EEGNet + A-VGG + CF + MLP: TCN을 적용하지 않고 EEGNet을 통해 추출한 EEG 특징과 VGG 신경망을 통해 추출한 오디오 특징을 융합하여 Conformer를 통해 모델링한 후 분류를 위해 MLP를 적용한다.
∙E-EEGNetTCN + MLP: 이 방식에서는 오디오 특징을 적용하지 않고, EEG 신호에 EEGNet을 적용하여 공간특징을 추출한 후에 TCN을 통해 시공간 특징을 추출한다. 추출된 시공간 특징은 MLP 분류기에 입력되어 감정인식을 수행한다.
∙E-SFCGT[14]: 뇌파 신호의 각 주파수 영역에 합성곱 신경망 계층을 사용하여 뇌파 특징의 공간정보를 획득한 후에 게이트 트랜스포머를 이용한 주의집중 메커니즘을 사용하여 각 주파수 대역에서 두드러진 주파수 정보를 학습하고, 주파수 간 대역 매핑을 통해 보완 주파수 정보를 학습하여 최종 주의집중 표현에 반영한다.
∙A-VGGTCN + MLP: EEG 특징을 제외하고, 오디오 신호에 VGG와 TCN으로 결합된 오디오 인코더만을 적용하여 오디오 시공간 특징을 추출한 후에 MLP 분류기를 통해 감정인식을 수행한다.
∙PM: 본 논문에서 제안한 방식이다.
Table 1은 다양한 신경망 구조를 적용한 방식들과 제안한 방식의 감정인식 성능 결과를 비교한다. 감정인식을 위한 학습에 소요된 시간은 3시간 15분으로 Windows 10, Intel Core i5 8500 프로세서, NVIDIA GeForce GTX 1070 Ti GPU, DDR4 32GB RAM을 사용하는 하드웨어 환경과 Python 3.10.8을 사용하는 소프트웨어 환경에서 측정되었다.
Table 1.
Multimodal emotion recognition results using DEAP dataset.
실험결과, 제안한 방식이 90.2 %로 가장 높은 분류 정확도를 나타냄을 알 수 있다. 이 결과는 오디오 시공간 특징 혹은 뇌파 시공간 특징만을 적용했을 때의 결과보다 매우 우수하였다. 또한, 뇌파와 오디오 신호로부터 공간적 특징만을 각각 추출하여 융합하거나, 뇌파와 오디오 신호로부터 시간적 특징만을 추출한 다음 융합하여 Conformer를 통해 모델링 한 방식은 제안한 방식보다 인식 정확도가 낮았지만, 다른 네 가지 방식보다는 우수한 성능을 제공하였다. 이를 통해 시공간적 특징의 융합이 감정인식에 미치는 영향을 확인할 수 있었다. 그리고 E-SFCGT 방식은 E-EEGNetTCN + MLP 방식과 비교하여 2.9 % 정도 인식 정확도가 높았는데 게이트 트랜스포머를 이용한 주의집중 메커니즘이 영향 때문이라고 추정된다. 마지막으로, 가장 낮은 감정인식 정확도는 오디오신호로부터 시공간 특징을 추출하여 감정인식을 한 경우였다.
IV. 결 론
제안한 방식은 비디오에 포함된 오디오 신호와 비디오를 시청하는 동안 획득된 EEG 신호로부터 각각 특징맵을 추출하고, TCN과 Conformer 기반 모델의 조합을 통해 뇌파 및 해당 오디오의 특징 정보를 통합하여 감정인식에 적용하였다. DEAP 데이터 세트에 대한 실험은 제안된 방식이 기존의 방식보다 감정을 높은 정확도로 인식할 수 있음을 입증하였다. 향후 연구에서는 EEG 특징과 해당 비디오의 오디오비주얼 특징을 융합하고, 최근에 다중 모달리티 방식에서 괄목할 만한 성과를 보이고 있는 대조학습(contrastive learning) 방식과 교차 모달 어텐션 메커니즘(cross modal attention)을 적용하여 감정인식의 성능을 개선하고, 이를 기반으로 외부 자극, 기분 변화, 생리적 각성이라는 세 가지 측면의 내적 관계를 탐색하고자 한다.
