

I. Introduction
II. Conventional Decision Tree Based Context Clustering Algorithms
2.1 MDL-based Context Clustering
2.2 Decision Tree Based Context Clustering Based on Cross Validation and Hierarchical Prior
III. Proposed Context Clustering Algorithm
3.1 Normalized Cross Likelihood Ratio
3.2 Node Splitting Criterion with Cross Likelihood Ratio Considering the Hierarchical Prior
IV. Performance Evaluation
4.1 Experimental Setup
4.2 Analysis on the Trainability of Context Clustering Algorithms
4.3 Objective Test Results
4.4 Subjective Test Results
V. Conclusions
I. Introduction
The training process of HMM-based speech synthesis system requires a context-dependent approach.[1] As the various combination of context information is utilized, the size of context-dependent HMMs increases unlimitedly. Since the amount of speech database is insufficient to represent all combination of context information, however, it is very difficult to obtain model parameters reliably. To relieve the problem by merging similar training sets, various types of context clustering techniques have been proposed.[2-6]
The Minimum Description Length (MDL)-based context clustering algorithm is the most popular one.[2-3] The HMM parameters, i.e. mean vector and covariance matrix, having the similar statistics are tied to the same context- dependent HMM states by the contextual dependent questions. However, since the MDL algorithm uses the Maximum Likelihood (ML) criterion, it has an overfitting problem if the amount of training data at any node is insufficient and outliers occur at any node.
In order to solve the overfitting problem, the cross validation for node splitting and stopping criterion was proposed.[4,5] Since it is still based on the ML criterion, however, the estimated model parameters are still not reliable if the amount of training data at any node is insufficient. A hierarchical prior-based context clustering algorithm is proposed to overcome the insufficiency of training data.[6] The hierarchical prior that is similar to Structural Maximum A Posteriori (SMAP) estimation[7] regularizes a parameter estimation process, thus it is possible to estimate reliable model parameters.
In the context clustering algorithms, the characteristics of model parameters at each node vary depending on the best chosen contextual question. Moreover, the effect caused by selecting any of the best question at the root node is propagated to the hierarchical tree structure afterwards. Therefore, it is important for designing a splitting criterion in the training process.
In the conventional algorithms, the node splitting criterion only depends on the likelihood ratio between the current node and child nodes to be split. In other words, a splitting criterion tries to maximize the summation of log-likelihood to each split child node. However, since the criterion does not consider the level of similarity between each other child node, it does not guarantee an important point such that the characteristics of model parameters in each other child node need to be statistically different.
This paper proposes a novel splitting criterion including the Cross Likelihood Ratio between split child nodes with their Hierarchical Prior (CLRHP). To minimize the similarity between each other child node, the proposed CLRHP algorithm includes the cross likelihood ratio into the splitting criterion. Furthermore, the cross likelihood ratio is normalized by the log-likelihood of each child node using the hierarchical prior, which results in the regularization process to the statistics of parent node. Subjective and objective test results show that the performance of the proposed context clustering algorithm is superior to the conventional ones.
II. Conventional Decision Tree Based Context Clustering Algorithms
2.1 MDL-based Context Clustering
The MDL-based context clustering keeps balancing between limited amount of speech database and unlimited combination of context information.[3] The approach takes a top-down clustering approach such that it maximizes the likelihood of model parameters to the training data. In the HMM-based TTS system, an HMM state-level clustering is adopted.
When the clustered node S is divided into ![]() and
and ![]() by a question q, the MDL-based criterion is defined as:
by a question q, the MDL-based criterion is defined as:
| (1) |
where denotes a weight of penalty term, and N is the number of parameters increased by the split. The total state occupancy count at the node S, ![]() , is defined as:
, is defined as:
| (2) |
where T denotes the number of frames in the training data, ![]() denotes a set of HMM states clustered to the node S.
denotes a set of HMM states clustered to the node S. ![]() denotes the posteriori probability of an HMM state m for an observation at frame t,
denotes the posteriori probability of an HMM state m for an observation at frame t, ![]() . The log-likelihood at node S to the associated training data is defined as:
. The log-likelihood at node S to the associated training data is defined as:
| (3) |
where K denotes the dimensionality of observation vector. ![]() and
and ![]() denote the mean and covariance of the leaf node S, respectively.
denote the mean and covariance of the leaf node S, respectively.
To determine whether a current node is split or not, the optimum question ![]() that maximizes Δq is chosen at first. Then, if Δ
that maximizes Δq is chosen at first. Then, if Δ![]() < 0, the current node is not split, otherwise the node S is divided into child nodes,
< 0, the current node is not split, otherwise the node S is divided into child nodes, ![]() and
and ![]() . This process is repeatedly carried out until there remains no nodes to be split.
. This process is repeatedly carried out until there remains no nodes to be split.
Note that the model parameters trained by the ML estimator are sensitive to the outliers if the amount of training data is insufficient. Furthermore, controlling the penalty term is not easy to determine an appropriate tree size. To overcome the problems of MDL-based context clustering, the Cross Validation (CV) and the Cross Validation based on the hierarchical prior similar to Structural Maximum a Posteriori estimation (CVSMAP) based context clustering algorithms are proposed in.[5-6]
2.2 Decision Tree Based Context Clustering Based on Cross Validation and Hierarchical Prior
In cross validation, the training data D is divided into K-folds ![]() , where
, where ![]() and
and ![]() for any i and j. The occupancy counts and the first and second order statistics of
for any i and j. The occupancy counts and the first and second order statistics of ![]() associated with the node S are written as:
associated with the node S are written as:
| (4) |
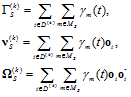 ,
,where ![]() ,
,![]() and
and ![]() denote the occupancy counts, the first, and second statistics, respectively. For the k-th fold, the subsets
denote the occupancy counts, the first, and second statistics, respectively. For the k-th fold, the subsets ![]() are used for the ML estimator, where . The mean vector and covariance matrix at the node S are estimated as:
are used for the ML estimator, where . The mean vector and covariance matrix at the node S are estimated as:
(5) |
where
(6) |
denotes the parent node of S and denotes the regularization factor for the prior statistics of S. Note that S equals zero in the CV-based algorithm. The use of hierarchical priors regularizes parameter estimation, thus reduces the overfitting problem.
From the first and second statistics, and equation (3), the log-likelihood of the model at the node S given the evaluation subset ![]() can be calculated as
can be calculated as
(7) |
where . This process is repeated over K-folds. Then, the CV or CVSMAP log-likelihood at the node S is calculated by summing the likelihood of each subset :
(8) |
In the CVSMAP-based algorithm, the prior statistics for the root node are set to
(9) |
The splitting and stopping criterion in the CV or CVSMAP based algorithm are same as the MDL method except the penalty term, while the log-likelihood is calculated by equation (7) and (8).
III. Proposed Context Clustering Algorithm
In the context clustering algorithm, determining the splitting criterion is important to make the model parameters be statistically inequivalent. In other words, the clustering algorithm is efficient if each other clustered models have statistically different characteristics. Typically, the splitting criteria try to maximize the summation of log-likelihoods of split child nodes. However, the conventional splitting criteria do not guarantee the fact that the model parameters of each other child nodes are statistically different because the criteria do not include the statistical similarity measure between each other child nodes. In this section, a novel splitting criterion with the CLRHP is proposed, which includes the similarity between each other child nodes into the criterion. Therefore, the CLRHP criterion not only maximizes the likelihood at the child nodes, but also minimizes the similarity of model parameters using the cross likelihood ratio.
3.1 Normalized Cross Likelihood Ratio
To describe the concept of cross likelihood ratio, a Normalized Cross Likelihood Ratio (NCLR)[8] should be defined first. The NCLR means a distance measure between two models having Gaussian distribution. Given two Gaussian models, and , the NCLR distance is defined as :
| (10) |
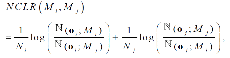
where and are the number of data and , respectively. ![]() and
and ![]() denote the cross likelihood of two Gaussian models and , and they are normalized by their own likelihood
denote the cross likelihood of two Gaussian models and , and they are normalized by their own likelihood ![]() and
and ![]() , respectively.
, respectively.
3.2 Node Splitting Criterion with Cross Likelihood Ratio Considering the Hierarchical Prior
From the log-likelihood ratio used for the cross validation with the hierarchical prior, and the modified normalized cross likelihood ratio, we propose a node splitting criterion using the CLRHP. The CLRHP-based splitting and stopping criterion is defined as:
| (11) |
where q is the best question at each node. , , and are calculated by the equation given in (7) and the node statistics based on the hierarchical priors, i.e. equation (5), and (6). The CLRHP term is defined in the equation (12).
| (12) |
(13) |
IV. Performance Evaluation
4.1 Experimental Setup
The performance of the proposed algorithm is compared to those of conventional context clustering algorithms. At first, a Korean HMM-based TTS system is constructed.[9-11] Around three thousand Korean utterances are recorded by a professional male speaker for training. Fifty sentences which are not included in the training set are used for the test. The sampling frequency is set to 16 kHz, and there are 181,734 combinations of context information. A grapheme- to- phoneme (G2P) converter is implemented by following the Korean standard pronunciation grammar and the context information labeling program. Sixteenth-order LSFs are used for the spectral parameter and twenty third-order excitation parameters including F0 are used for excitation parameters.[11]
For the MDL-based context clustering algorithm, a penalty factor is tuned to 0.2~2.0 with an interval of 0.2. For the CV-based context clustering algorithm, the number of folds, K, is set to 5. In the CVSMAP-based context clustering algorithm, the regularization parameter for the CVSMAP is replaced to considering the ratio of occupancy counts between the current and parent nodes. K and are also applied to the proposed CLRHP-based context clustering algorithm.
. | (14) |
4.2 Analysis on the Trainability of Context Clustering Algorithms
In order to analyze the trainability of each context clustering algorithm, we investigate the trainability of the spectral and excitation features. The NMSE is defined as a normalized error between excitation parameters extracted from the original speech and those generated from the trained HMMs .
| (15) |
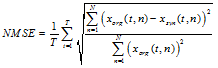 .
.Fig. 1 and 2 show the average NMSE of LSF and LF0, respectively. In Fig. 1, the NMSE value of MDL is varying depending on the scaling factor of penalty term. The NMSE values of CV, CVSMAP, and CLRHP are similar to the minimum value of NMSE of MDL. It means that the decision tree of LSF does not have a large variation depending on the type of clustering algorithm. The error reduction of spectral parameter depending on the clustering algorithm is less than one of the excitation parameter.
|
Fig. 1. NMSE of LSF for each clustering algorithm. |
|
Fig. 2. NMSE of LF0 for each clustering algorithm. |
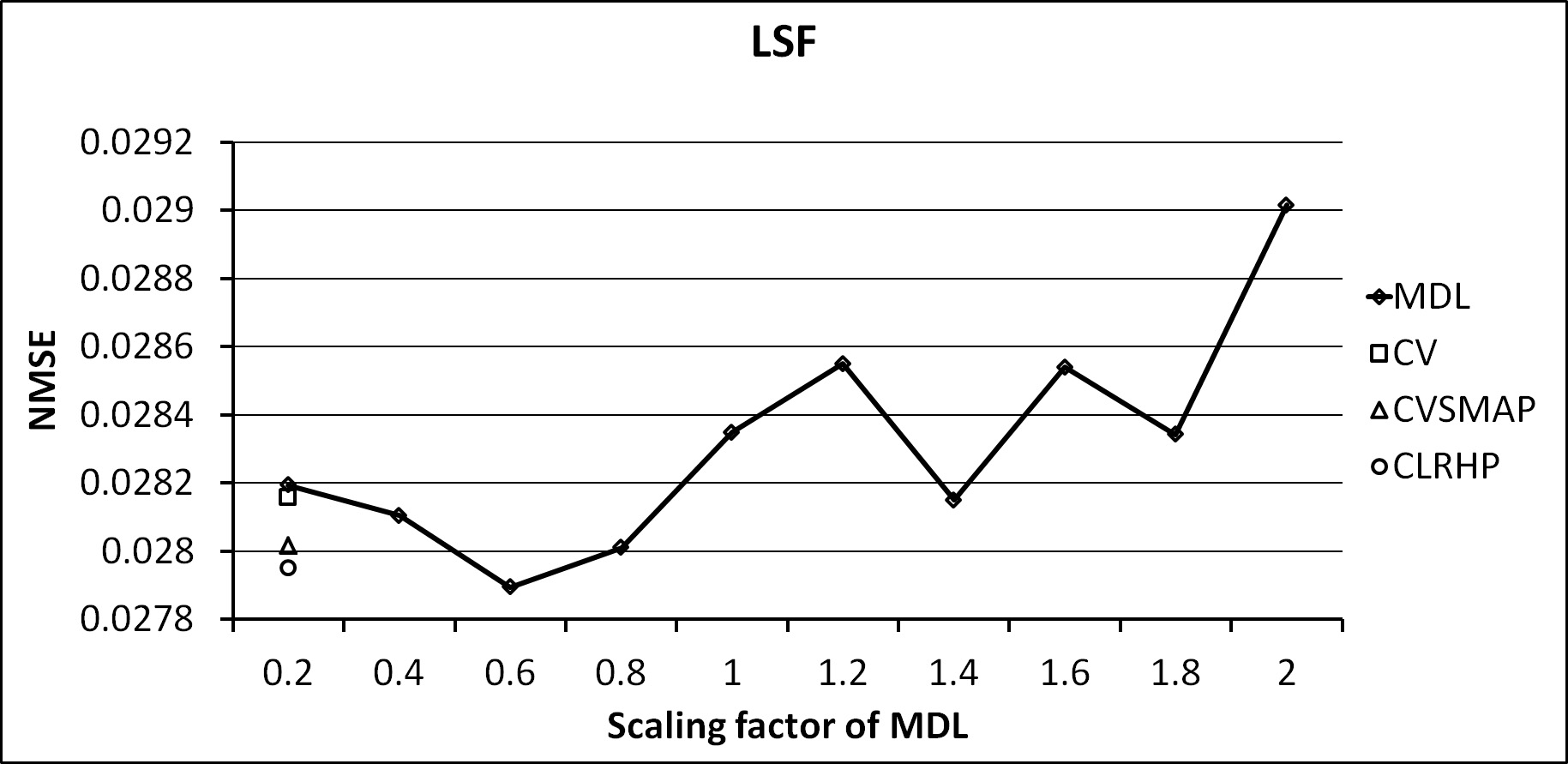
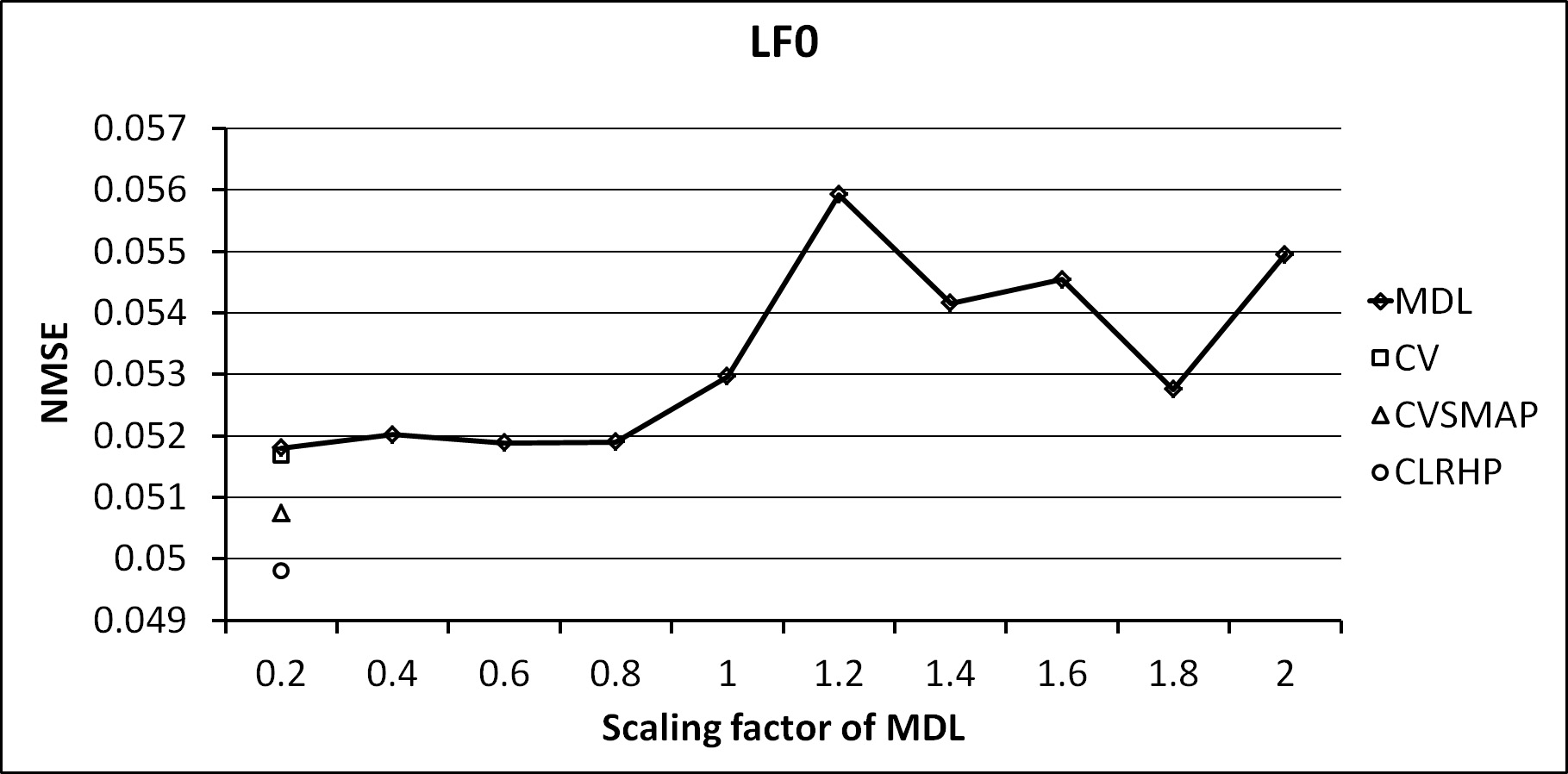
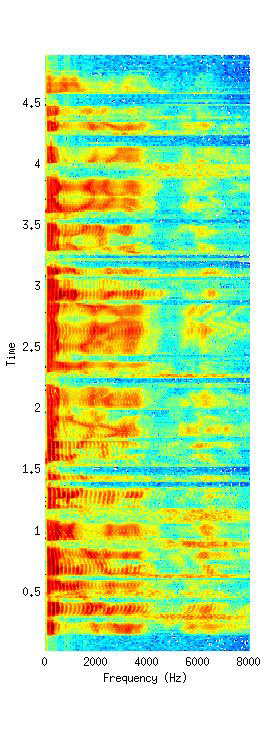
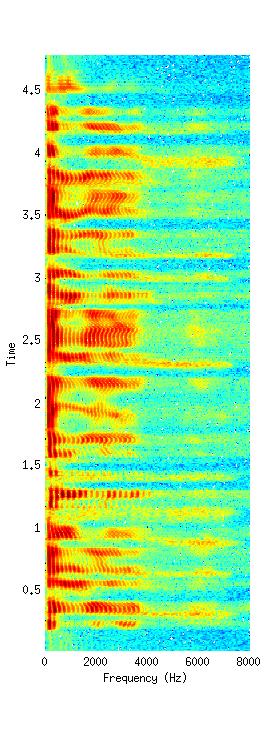
In Fig. 2, the error of excitation parameters, LF0, is reduced by the proposed CLRHP algorithm compared to the conventional algorithms. Note that the value of reduced NMSE is not large because we utilize the large amount of speech database about 4 hours for training the context-dependent HMMS. Nevertheless, the CLRHP has the smallest NMSE among all clustering algorithms. Since the excitation and spectral parameters are independently trained and clustered by each other decision tree, the results of NMSE shows that the clustering algorithm has more effect on the excitation parameters than the spectral parameters. In Fig. 3, the spectrogram synthesized by the proposed CLRHP is compard to one of the original speech.
|
Fig. 3. Original (left) and proposed CLRHP (right) speech spectra. |
4.3 Objective Test Results
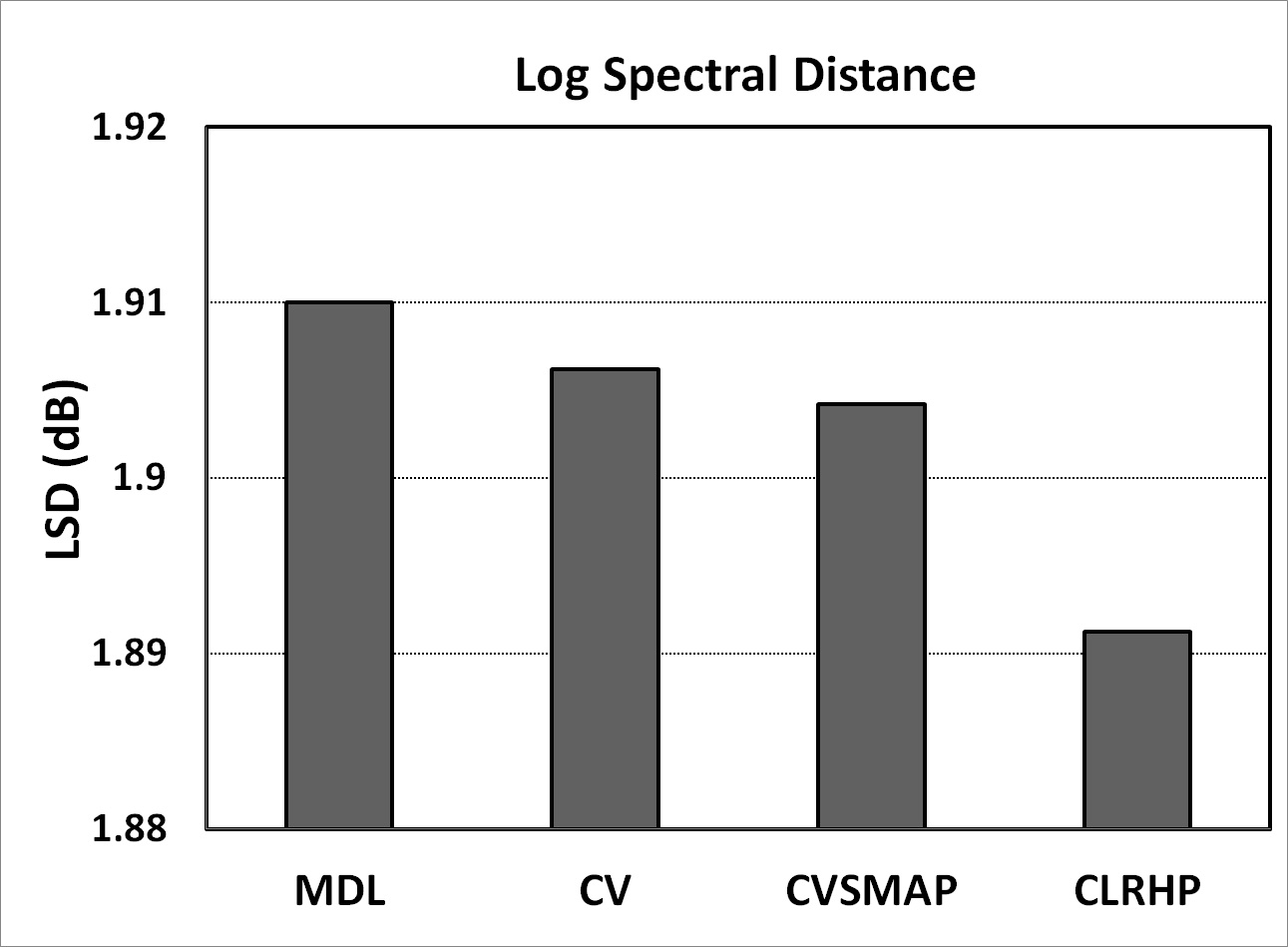
In order to evaluate the objective quality of synthesized speech by each context clustering algorithm, a log spectral distance (LSD) between the original and generated speech is measured in the speech duration. Fig. 4 represents the LSD values for each context clustering algorithm. It is clear that the spectral distortion of speech synthesized by the proposed CLRHP algorithm has lower value than the conventional context clustering algorithms, i.e. MDL, CV, and CVSMAP.
|
Fig. 4. Log spectrum distance (dB) for each context clustering algorithm. |
4.4 Subjective Test Results
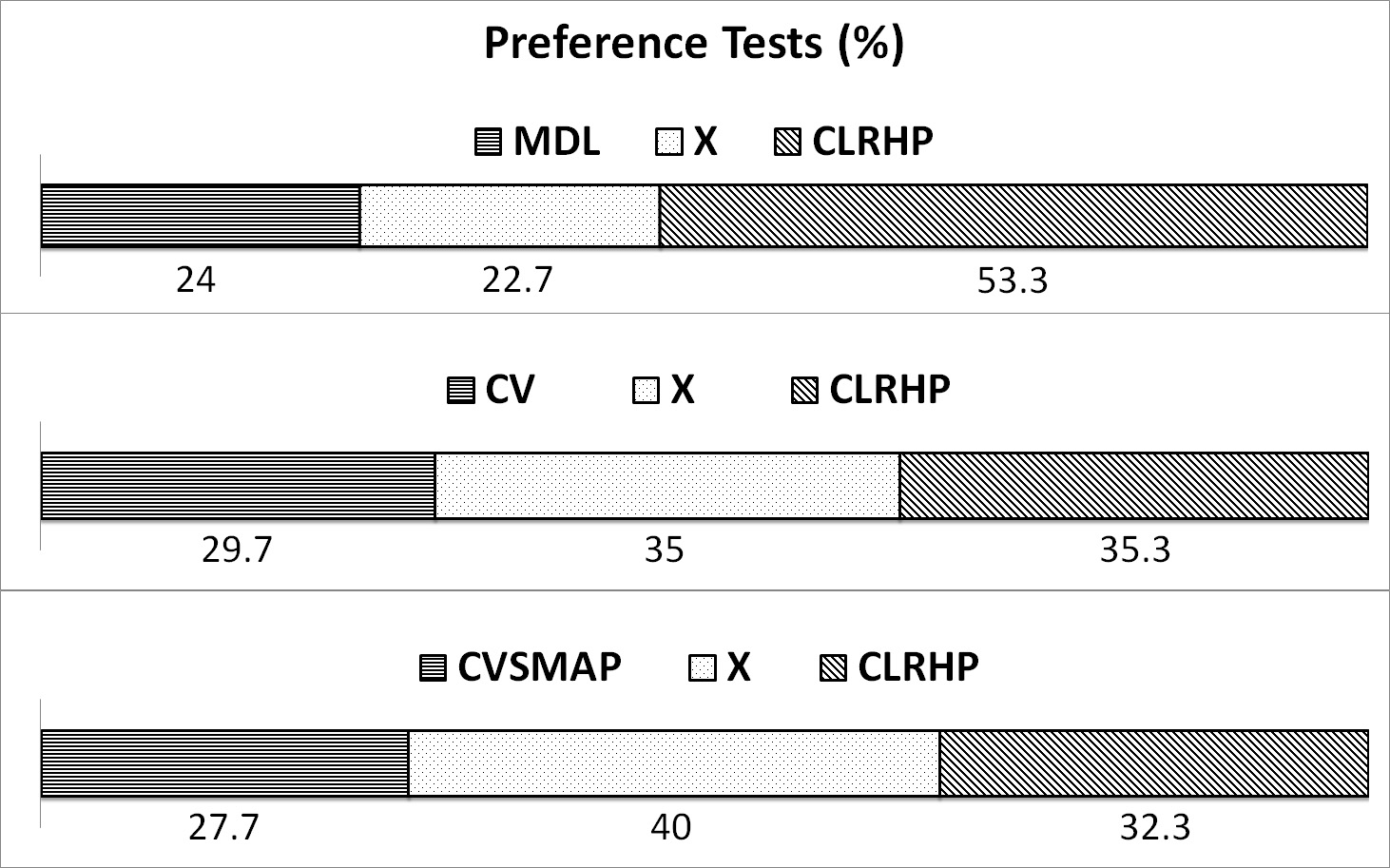
In order to measure the subjective speech quality, the A/B/X preference test is also conducted. Fifteen experts in speech signal processing field provide their preference after listening randomized utterances synthesized by four methods. In this test, the proposed CLRHP is compared to MDL, CV, and CVSMAP, respectively. In Fig. 5, the synthesized speech quality in CLRHP is much better than the MDL-based synthesized speech quality. Moreover, the listeners provide higher preference to the proposed CLRHP algorithm compared to the CV and CVSMAP algorithms.
|
Fig. 5. Scores (%) of preference tests. |
V. Conclusions
In this paper, a novel decision tree based context clustering algorithm has been proposed. Unlikely to the conventional context clustering algorithms such as CV and CVSMAP, the proposed algorithm considers the statistical characteristics of the split child nodes. Using the CLRHP, it minimizes the similarity of statistics between each other leaf nodes. The proposed algorithm shows superior performance to conventional context clustering algorithms.
