

I. 서 론
II. 혀 움직임 추정 센서
III. 데이터 취득 및 전처리
IV. 음성 신호 추정
V. 실험 결과
5.1 객관적 성능 평가
5.2 ASR+TTS를 사용한 합성음의 평가
VI. 결 론
I. 서 론
일반적인 음성을 통한 의사 전달은 화자(speaker) 쪽에서 전달하고자 하는 음성을 발성하고 청취자(listener) 가 이를 듣고 이해하는 방식으로 이루어진다. 정상적인 음성 발성이 어렵거나 주변 소음 등으로 원활한 음성 전달이 불가능한 경우 일반적인 음성 전달 방식과는 다른 방법이 강구되어야 한다. 무 음성 대화 기술(Silent speech interface)[1]은 음성을 이용한 의사 전달이 불가능한 상황에서도 음성을 통해 의사 전달이 가능하게 하는 기술이다. 무 음성 개화 기술에서는 화자가 직접 소리를 발성하는 대신 입 모양 만을 만드는 등, 발성의 동작만으로 의사를 전달하게 된다. 이러한 기술은 공공장소에서 주변 사람들에게 불편감을 주지 않으며 대화할 수 있고 대화 내용의 은닉 및 보안이 필요한 상황에서 활용될 수 있다. 초음파 신호를 이용한 무음성 대화 기술은 다른 방법과 비교하여 저렴한 센서 사용, 비접촉, 비침습적 취득, 주변 소음에 대한 강인성, 원거리에서도 취득 가능 등의 장점을 갖는다.[2,3,4] 예로서 초음파 도플러 변이를 검출하여 이를 60개 한국어 고립어에 대한 음성합성 및 음성인식에 적용하는 경우 주변 잡음 유무에 관계없이 주관적 청취 상 72.2 %의 인식율을, 은닉마코프 모델을 이용할 경우 90 % 이상의 인식율을 얻을 수 있는 것으로 보고되었다.[2]
입과 함께 혀는 발성에 관여된 주요한 기관으로써, 발성되는 음소와 혀의 형태 간에는 유의한 관련성을 갖는다. 기존 무음성 인터페이스 방법에서는 입 모양 또는 입술의 움직임에 관여하는 근육의 변위를 반영한 신호가 사용되고 있다. 이는 혀의 움직임과 변이에 따라 다르게 발성되는 다양한 음성의 합성에는 한계가 있음을 의미한다. 이와 같은 문제를 해결하기 위해 턱 아래에서 취득한 초음파 영상을 사용하는 방법[5]과 혀에 부착한 자석의 위치를 이용하는 방법[6]이 제안되었다. 그러나 이들 방법은 초음파 영상 장치에 따른 착용/휴대의 어려움, 혀의 이물감으로 인한 사용자의 불편감 등의 문제가 있다.
Sasaki et al.[7]은 신체의 움직임이 불가능한 중증 장애인 의사소통을 위해 혀의 특정 위치를 검출하는 방법을 제안하였다. 혀의 움직임에 관여하는 근육 일부가 턱 아래 부분에 분포한다는 사실에 착안하여, 턱 아래 피부에서 취득된 근전도 신호를 이용하여 혀의 위치를 추정하였다. 초음파 도플러 신호는 반사되는 피부면의 변이에 의존적으로 나타나며 따라서 턱 아래 부분에서 취득한 도플러 신호는 혀의 움직임과 관련이 있을 것으로 가정할 수 있다. 본 논문에서는 턱 아래에서 취득된 초음파 도플러 신호로부터 음성신호를 합성 하고, 합성음에 대한 객관적 평가 및 Automatic Speech Recognition(ASR)과 Text- To-Speech(TTS)를 이용하여 생성된 음성에 대해 주관적 평가를 수행하고자 한다.
II. 혀 움직임 추정 센서
한국어 모음은 혀의 높낮이에 따라 고모음, 중모음, 저모음으로 나뉘며(예: [i]와 [a]), 혀의 전후 위치에 따라 전설모음, 중설모음, 후설모음(예: [i]와 [u])로 나뉜다. 자음의 종류와 혀의 위치 간 에도 유의한 상관성이 존재하는 것으로 알려져 있으며, 예로서 혀끝 부분의 구강 내 위치에 따라 치조음, 경구개음, 연구개음으로 구분된다. 기존의 무음성 인터페이스에서는 신호 취득의 편이성을 고려하여 주로 입 모양을 음성 신호 추정을 위한 단서로 사용한다. 입 모양은 모음의 경우 원순모음과 비원순모음으로 구분되며 자음은 양순음 발성과 연관되어 있다. 이는 기존 무음성 인터페이스에서는 입 모양에 의존적으로 나타나는 자,모음에 대해서는 우수한 성능을 기대할 수 있지만 혀의 위치에 관여된 음소에 대해서는 제한적인 성능이 얻어질 수 있음을 의미한다.
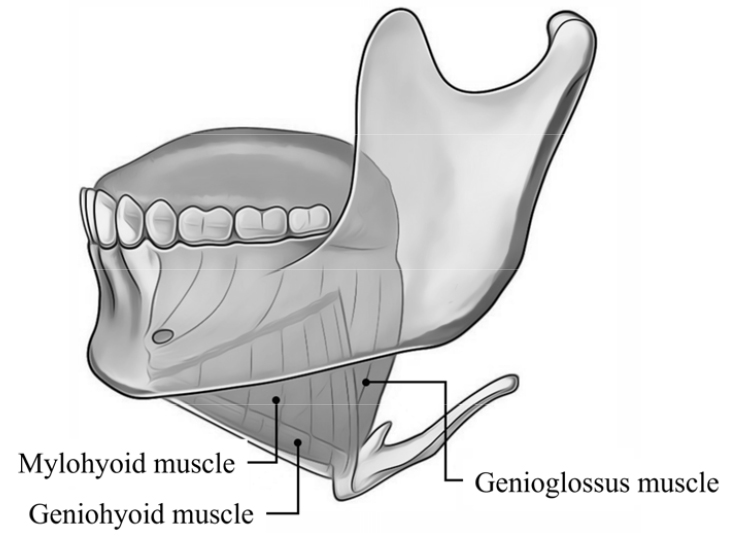
카메라 또는 초음파 센서가 얼굴 전면에 위치하는 기존의 방법에서는 입을 벌리는 순간 입 구멍을 통해 노출된 영상으로 부터 혀의 모양을 인식할 수 있다. 그러나 입술이 열리는 방사(radiation) 시간은 전체 발성 기간 중 상대적으로 짧고, 입 구멍을 통해서는 입 내부의 매우 제한된 영역만이 노출된다. 본 논문에서는 혀의 모양과 위치를 직접적으로 취득하는 방법의 대안으로 혀의 움직임에 관여하는 근육으로부터 신호를 취득하고 이로부터 혀의 변위를 간접적으로 추정하는 방법이 고려되었다. Fig. 1에 제시한 것처럼 턱 아래에는 혀의 위치를 제어하는 근육으로서, 악설골근(Mylohyoid muscle), 턱끝목뿔근(Geniohyoid muscle), 턱끝혀근(Genioglossus muscle) 의 일부가 위치하고 있다. 이중 턱끝목뿔근은 혀의 움직임 뿐이 아니라 입을 벌리는 동작에도 관여하여 입모양과 연관된 자/모음의 구분에도 유용한 정보가 제공될 수 있다. 혀의 위치와 변위를 추정하기 위해, 이들 각 근육의 수축과 이완 여부를 검출하는 것이 필요한데, 이는 해당 근육의 근전도 신호를 통해 얻을 수 있다. 비침습적 표면 근전도 측정 방법은 통증과 감염 등의 문제가 없지만 여러 근육의 수축/이완이 혼재되어 나타나는 crosstalk 및 전극의 장시간 피부 접촉에 따른 알러지 등의 단점이 있다.
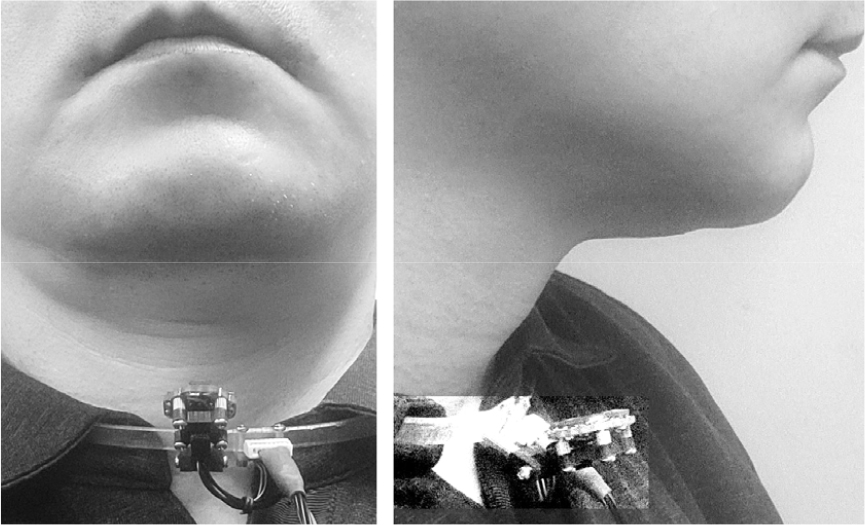
도플러 효과(Doppler effects)는 움직이고 있는 물체에 일정한 주파수를 갖는 정현파 신호를 방사했을 때, 돌아오는 반사파의 주파수는 방사 주파수와 다르게 관찰되는 현상(Doppler shift)이다. 수축 또는 이완되고 있는 피부 표면에 정현파 주파수를 방사하고 반사파를 관찰하며 근육의 변이 속도에 따른 Doppler shift가 검출된다. 따라서 반사파의 주파수와 방사 주파수의 차이를 관찰하면 해당 피부 표면 근육의 수축/이완 여부를 검출할 수 있다. 이러한 도플러 검출 방식은 근전도 방식과 비교하여 비침습적, 비접촉식 방식으로 장시간 사용하더라도 불편감이 덜 하다는 장점이 있다. 본 논문에서는 센서 구현의 비용, 사용자 착용감, 하드웨어의 간편성을 고려하여 40 kHz 초음파 신호를 방사신호로 사용하였다. Fig. 2에 제작된 prototype 센서의 사진으로 40 kHz 초음파 신호를 방사하기 위해 1개의 초음파 스피커(MA40H1S- R, Murata Electronics, Kyoto, Japan)가 사용되었고 턱 아래 각 근육의 변이를 검출하기 위해 4개의 초음파 마이크로폰(SPM0404UD5, Knowles Acoustics, Itasca, USA)이 사용되었다. 마이크로폰은 10 kH ~ 65 kHz 대역에서 –51 dB ~ –43 dB의 감도를 갖으며 초음파 스피커는 40 kHz의 중심주파수를 갖는다. 사용된 마이크로폰과 스피커는 모두 Micro Electro-Mechanical System (MEMS) 기술로 제작된 초소형 센서로서 18.2 × 18.2 mm2 크기의 prototype sensor에 모두 장착될 수 있었다.

Fig. 3은 제작된 센서를 착용한 사진으로서, 아크릴 재질의 링을 별도 제작하여 중심부에 prototype sensor를 장착하고 사용자의 카라부분에 링을 끼워넣는 형태로 센서를 고정하였다. 이와 같은 장착 방법은 머리나 몸의 움직임에 따른 취득 신호의 변동을 억제할 수 있다. 센서의 방사 및 입사 면은 턱 아래 피부면을 향하도록 장착되었고 각도 조절이 가능하여 Fig. 1에 제시된 각 근육의 변위를 가장 잘 검출할 수 있도록 조정하였다. 초음파 신호가 장시간 피부에 노출하게 되면 열손상 및 cavitation에 의한 조직 손상을 가져올 수 있다. 본 연구에서는 방사 초음파 신호의 강도를 0.1 W/cm2 이내로 조정하여 피부 손상의 문제가 발생하지 않도록 하였다.
III. 데이터 취득 및 전처리
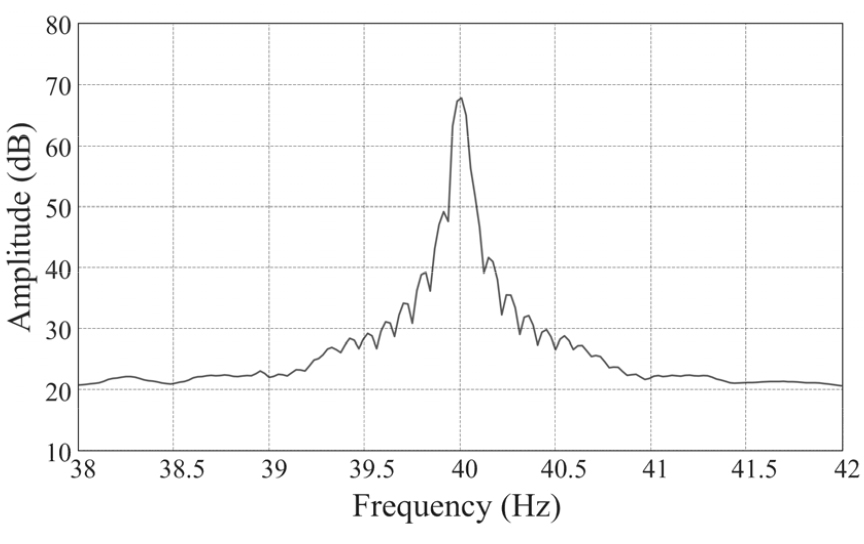
제작된 센서의 유용성을 검증하기 위해 발성 장애가 없는 1명의 피시험자로부터 음성/초음파 데이터를 취득하였다. 녹음에는 뉴스 기사 및 일상 대화에 사용되는 문장을 사용하였으며, 총 녹음 시간은 약 4시간, 2014개 문장이었다. 신호 취득은 사용자의 피로감을 줄이고 다양한 발성 스타일을 수용하기 위해 7일간에 걸쳐 이루어졌다. 제작된 prototype sensor는 음성 대역( ~ 3.5 kHz)에서 낮은 감도를 갖기 때문에 별도의 acoustic microphone(AKG-D880s, AKG Acoustics, Vienna, Austria)을 사용하여 피시험자 전면 10 cm 거리에서 음성 신호를 녹음하였다. 총 5채널 (음성1, 초음파4) 신호는 Digital audio interface(Fireface 800, RME Audio, Haimhausen, Germany)를 이용하여 96 kHz, 24 bit 디지털 신호로 변환하였다. A/D변환된 음성 신호는 16 kHz로 down sampling 하였다. 일반적으로 발성 동작과 연관된 근육의 움직임은 음성 파형의 변동과 비교하여 매우 느리게 나타나며, 따라서 도플러 변이도 좁은 주파수 대역에 국한되어 나타난다.[2] Fig. 4는 취득된 초음파 신호의 전력 스펙트럼 밀도(power spectral density)를 방사주파수인 40 kHz을 중심으로 도시한 것이다. 39 kHz ~ 41 kHz 대역 내 에서 대부분의 신호가 분포하는 것을 알 수 있으며, 이는 발성 시 입 주변에서 취득한 근전도 신호와 유사한 분포를 갖는 것임을 알 수 있다.[2] 본 논문에서는 이러한 초음파 신호의 특성을 고려하여 음성 신호 추정을 위한 특징 변수를 추출하였다. 먼저 중심 주파수 40 kHz의 좌,우 두 대역에 해당하는 성분을 추출하기 위해 39 kHz 로 복조를 수행하고, 차단 주파수 2 kHz를 갖는 저역통과필터를 통과시킨다.
여기서 은 취득된 초음파 신호, =39 kHz, , 은 저역통과필터의 충격파응답을 나타낸다. 복소 신호의 위상 𝜃는 복조 신호와 취득된 초음파 신호가 상호상관계수(cross-correlation coefficient)가 최대가 되도록 결정된다. 신호 은 =4 kHz로 down sampling된다.
초음파 도플러를 이용한 기존 음성합성 연구에서 멜-주파수 스펙트럴 계수(mel-frequency spectral coefficients)가 음성신호 추정 관점에서 가장 적합한 것으로 나타났으며,[2] 본 연구에서도 음성 추정을 위한 변수로 멜-주파수 스펙트럴 계수를 사용하였다. Eqs. (1), (2)에서와 같이, 은 중심주파수(1 kHz)를 기준으로 서로 대칭적인 분포를 갖기 때문에 멜-필터 뱅크도 1 kHz를 중심으로 서로 대칭적인 주파수 응답을 갖도록 하였다. 단측 대역에 대한 뱅크 수는 8로서, 1 프레임에 대한 특징 벡터의 차원수는 16이 되며, 4채널 신호가 사용되므로 전체적으로 64개가 된다.
IV. 음성 신호 추정
무음성 인터페이스와 관련된 이전 연구에서 초음파 도플러, 입주변 영상신호, 적외선 영상, 심도 영상을 사용한 모든 경우에서 신경망 기반 비선형 추정 방법이 선형 추정 기법에 비해 월등히 우수한 성능을 나타내었다.[4] 이는 각 비음성 modality와 음성 신호 간에는 비선형 대응관계가 존재함을 나타낸다고 볼 수 있다. 본 논문에서도 초음파 특징변수와 음성 신호간 대응 관계는 신경망으로 표현하였다.
신경망은 다층 퍼셉트론(Multi-layer perceptron ) 구조가 사용되었으며 최하위 노드에는 복조된 초음파 신호의 로그 멜-주파수 필터 뱅크 에너지 값이, 최상위 노드에서는 해당 음성의 Fourier magnitude spectrum 이 출력된다. 이는 단 구간 푸리어 크기 스펙트럼(short-time Fourier transform magnitude specturm)이 음성 합성을 위한 변수로 사용되었음을 의미한다. 단구간 푸리어 변환 계수는 음성 신호는 48 msec의 길이를 갖는 hamming window를, 33 msec 만큼 이동시켜 가면서 푸리어 변환을 수행하여 얻었다.
음성의 생성은 조음 기관이 발성하고자 하는 음소에 해당하는 형태를 먼저 취하고 폐에 저장된 공기를 후두를 거쳐 입으로 방사하는 과정을 통해 이루어진다. 이는 조음 기관의 움직임이 음성 발생에 선행함을 의미하며, 혀의 변위로 발생한 초음파 도플러 신호도 음성보다 앞서 나타남을 의미한다. 실험적인 관찰에 의하면, 초음파 도플러 신호와 음성 간 시간 불일치는 발성하고자 하는 음소, 발성자에 따라 각기 다르게 나타나는 것으로 나타났다. 본 논문에서는 초음파 특징 변수와 음성 파라메터간 시간 불일치를 고려하여 다중 입력 변수를 사용하였다. n-번째 프레임에 대응되는 신경망의 입력 특징 변수 는 아래와 같이 나타낼 수 있다.
여기서 은 -번째 프레임에 대한 멜-주파수 필터 뱅크 에너지 벡터를 나타낸다. Eq. (3)은 n-번째 프레임에 대응되는 입력 변수가 단순히 해당 프레임의 초음파 신호뿐이 아니고 인접된 몇 개 프레임에 해당하는 초음파 신호도 고려함을 의미한다. 인접 샘플 수 은 시간 불일치 기간에 따라 결정되는데, 본 논문에서는 경험적인 방법을 통해 =5로 설정하였다. 이 경우, 신경망의 입력 노드 수는 704(=멜 필터뱅크 수 × 다중 특징 변수 수 × 센서 채널 수 =16×11×4)였다.
사용된 신경망은 총 3개의 은닉 계층을 가지며, 해당 계층의 노드 수는 입력 음성 추정의 성능과 과적합을 고려하여 노드수의 1.5배(1056)로 설정하였다. 활성 함수(activation function)으로 은닉 계층에서는 Sigmoid 함수가, 출력 계층에서는 linear함수가 사용되었다. 경험적으로 learning rate는 0.001로, batch size는 85로 설정하였다. 신경망의 가중치는 역전파 알고리즘을 통해 얻어지고, 학습에 사용된 손실함수는 인간의 청각 특성을 반영한 거리 척도를 함께 고려하였다. 손실함수는 다음과 같다.
는 batch size를 나타내며 은 -번째 프레임에서 음성의 크기 스펙트럼에 대한 기준값과 추정값 간의 평균자승오차(Mean Squared Error, MSE)를 나타낸다. 과 ,는 각각 인지 거리(Perceptual disturbance)[8]와 이에 대한 가중치를 나타낸다. 실험적인 결과에 따르면, 스펙트럼간 평균자승오차와 인지 거리에 대해 동일한 가중치(=0.5)를 적용하는 경우 객관적, 주관적 평가 척도에서 가장 우수한 성능을 보이는 것으로 나타났다.
신경망을 통해 각 추정된 단구간 푸리어변환 열(sequence)로부터 음성파형을 얻기 위해서는 푸리어 역변환하여 단 구간 신호를 얻고, 이들 신호를 중첩가산(overlap and addition)하는 것이 필요하다. 본 논문에서는 크기 스펙트럼만을 추정하기 때문에 이에 대응하는 적절한 위상 스펙트럼을 생성하는 과정이 필요하다. 크기 스펙트럼으로부터 위상 스펙트럼을 추정하는 방법으로 Griffin과 Lim[9]이 제안한 최소자승오차법, 방대한 음성으로부터 학습된 신경망을 이용하여 크기 스펙트럼으로부터 음성 파형을 직접 생성하는 WaveNet 기반 방법[10]을 고려할 수 있다. 그러나 이와 같은 방법은 크기 스펙트럼이 자연스러운 음성으로부터 유래된 것이라는 가정에 기반하고 있으며, 크기 스펙트럼 자체에 왜곡이 존재하는 경우 추정된 위상 스펙트럼 또는 음성 파형에 큰 왜곡이 발생한다. 본 논문에서는 각 주파수 bin에 대해 [-𝜋~𝜋] 범위의 난수 값을 개별 위상값으로 사용하는 random phase spectrum 방법[4]을 사용하였다.
V. 실험 결과
5.1 객관적 성능 평가
제안된 초음파 취득 방법의 음성 추정 관점에서 유용성을 평가하기 위해 검증 실험을 수행하였다. 실험에는 III장에서 제시한 취득 데이터가 사용되었으며, 이 중 75 %를 학습데이터로, 25 %를 검증데이터로 사용하였다. 검증을 위한 객관적인 척도로 기준 신호와 추정된 신호의 Fourier transform magnitude spectrum 간 RMSE(Root Mean Squared Error), PMSQE (Perceptual Measurement of Speech Quality Evaluation),[8] PESQ(Perceptual Evaluation of Speech Quality)[11]를 사용하였다.
Fig. 5에 기존 초음파 취득 방법(얼굴 전면에서 초음파 방사후 반사파 취득)과 제안된 취득 방법(턱 아래 부분에서 방사 후 반사파 취득) 간 RMSE와 PMSQE값을 센서 수에 따라 도시 하였다. 두 척도 모두 턱 아래 부분에서 취득한 초음파 도플러 신호가 유의하게 낮은 값을 나타내었다. 두 방법 모두 센서의 수가 증가함에 따라 RMSE, PMSQE값이 감소하는 것을 알 수 있는데, 이는 여러 방향에서 초음파 신호를 취득하면 다양한 근육의 움직임을 음성 추정에 반영하게 되어 결과적으로 합성음의 품질이 증가되는 것으로 해석할 수 있다. 센서 수와 각 척도간 상관계수를 구하면, RMSE의 경우 기존 센싱 방법은 –0.9617, 턱 아래 센싱 방법은 –0.9388로서, 기존의 센싱 방법이 센서의 수에 따라 더 민감하게 RMSE가 감소하는 것을 알 수 있다. PMSQE의 경우도 턱 아래 센싱 방법이 전면 센싱 방법에 비해 센서 수에 덜 영향을 받는 것을 나타났다(–0.9279 vs. –0.9754). 이는 턱 아래에서 초음파 도플러를 취득하는 방법은 센서 수에 따른 성능 편차가 상대적으로 적음을 나타낸다.
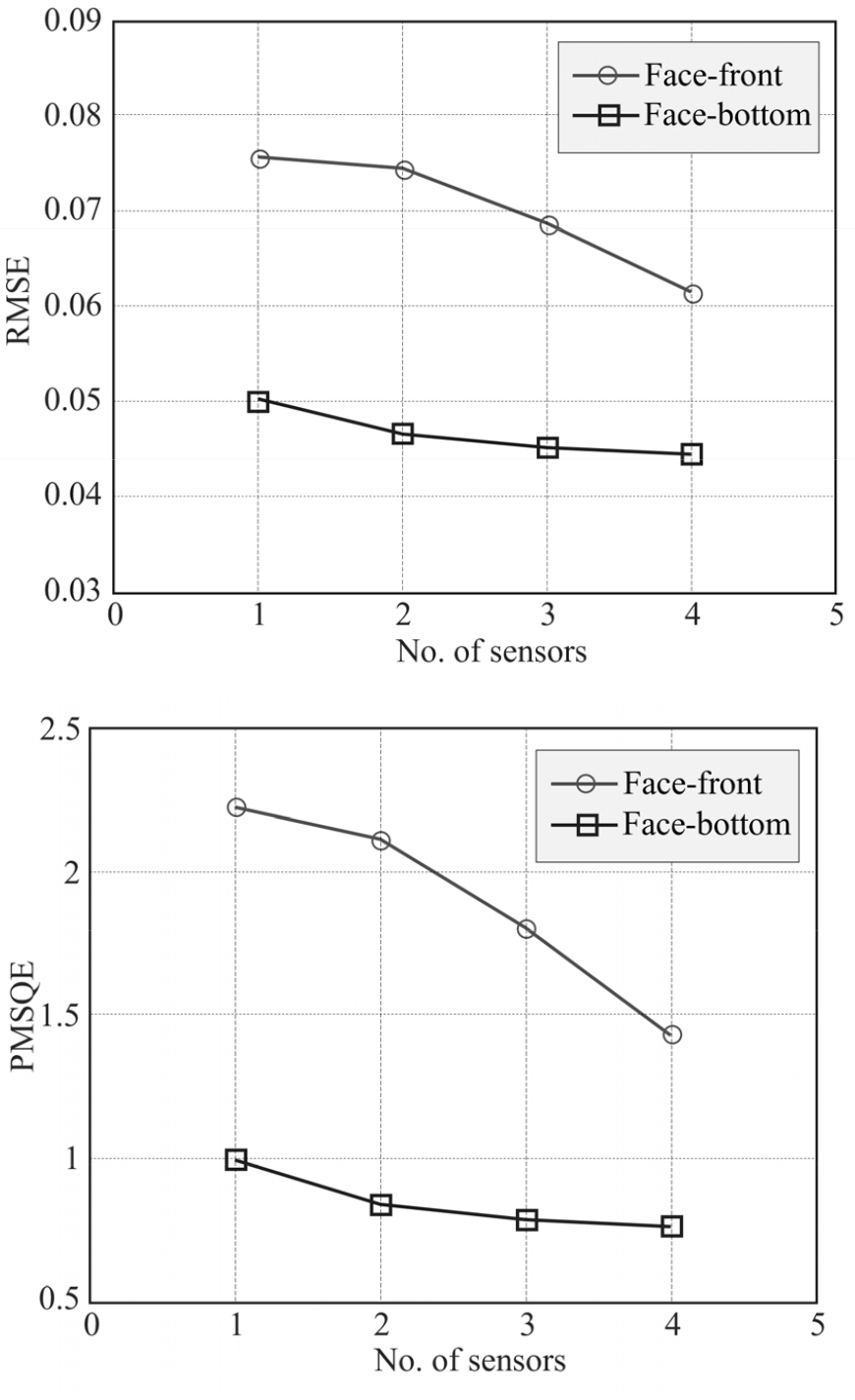
센싱 방법에 따른 RMSE, PMSQE의 최대 감소율은 각각 50.80 %, 123.77 %로서 턱 아래에서 취득한 신호가 인지 청감 거리를 더 유의하게 감소시켰다. 턱 아래 센싱 방법이 실제 음성과 청감상 더 가까운 소리를 생성한다고 볼 수 있다.
Fig. 6에서 두 센싱 방법의 평균 PESQ를 센서 수에 따라 제시하였다. RMSE, PMSQE와 마찬가지로 턱 아래면에서 취득된 초음파 도플러 신호가 유의하게 높은 PESQ를 나타내었다(=0.0001). 센서 수와 PESQ 간 상관계수는 전면 취득 방법은 0.9702, 턱 아래 취득 방법은 0.9640으로서 두 방법 모두 센서 수가 PESQ에 의미있는 영향을 끼치는 것으로 나타났다. 최대 평균 PESQ는 4개의 센서를 이용한 경우로서 2.055가 얻어졌다. 이 값은 International Telecommunication Union (ITU)에서 기술된 PESQ의 평가 기준에 따르면 인식이 어려운 bad 등급으로서, 주된 원인은 음성 합성 시 랜덤 위상을 사용한 것에 있다.
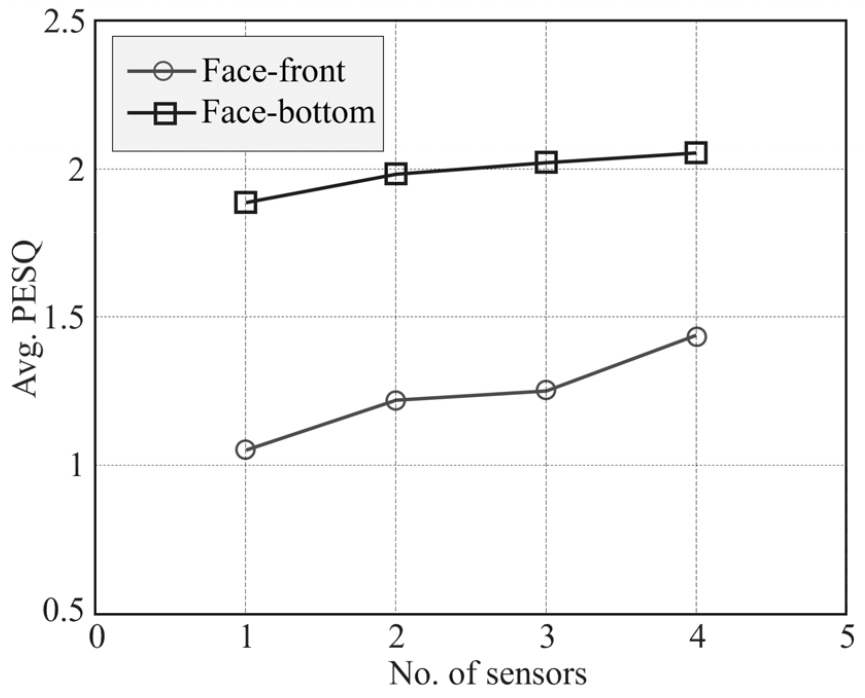
결론적으로 턱 아래 부분에서 취득한 초음파 신호는 기존의 얼굴 전면에서 취득한 신호와 비교하여 객관적 척도면에서 유의하게 우수한 성능을 나타내었으며, 이는 턱 아래에서 취득된 도플러 변이는 혀의 움직임이 일부 반영된 것이라 해석할 수 있다.
얼굴 전면에서 취득한 초음파 도플러 변이와 턱 아래에서 취득한 도플러 변이를 조합하여 사용한 경우 PESQ, RMES 값은 턱 아래서 취득한 초음파 신호만 사용한 경우와 비교하여 큰 차이가 없었다. 이는 턱 아래에서 취득된 초음파 신호에는 입 움직임에 따른 도플러 변이가 일부 포함되어 있음을 나타내는 결과라 할 수 있다.
5.2 ASR+TTS를 사용한 합성음의 평가
초음파 도플러를 이용하여 합성된 음성은 기준 음성의 크기 스펙트럼과 오차 및 인지 거리가 감소되도록 추정되었음에도 불구하고 기준 음성과의 청감 차이가 비교적 크게 나타난다. 합성음의 대표적인 특성은 harsh하고 불분명하게 들린다는 점인데, 이는 phase spectrum이 단순 랜덤값으로 대치된 것에 주된 원인이 있다. 실험적으로, 본래 음성의 phase spectrum과 초음파 도플러 정보만으로 추정된 magnitude spectrum으로 음성을 합성하는 경우 2점대 후반의 평균 PESQ 및 청감상 충분히 내용을 인지할 수 있는 음성을 얻을 수 있었다.
본 연구에서는 random phase spectrum 사용에 따른 합성음의 품질 저하를 해결하기 위한 방안으로, 음성 인식기(ASR; Automatic Speech Recognition)와 문자-음성 합성기(TTS; Text-to-Speech)을 이용하는 방법을 적용하였다. 이에 대한 과정을 Fig. 7에 제시하였다. 음성 추정 규칙을 통해 음성을 먼저 생성하고 이들 음성을 이용하여 ASR의 model을 fine-tuning 한다. 여기서 얻어지는 customized ASR model은 추정 음성이 갖는 왜곡에 대한 포용성을 갖게 된다. 온라인 음성 합성에서는 customized ASR model에 추정음성을 입력하여 음성인식을 수행하고, 여기서 얻어지는 문자열(text transcription)을 TTS에 입력하여 최종적인 합성음을 얻게 된다. 이와 같은 방법은 사용된 ASR이 음성의 크기 스펙트럼 정보를 사용하여 인식을 수행하기 때문에 phase spectrum 왜곡은 인식성능에 영향을 끼치지 않으며, 무음성 대화에서는 합성음의 화자(speaker), 운율(prosody) 정보 보다는 내용(context)이 주된 관심사라는 사실에 바탕을 두고 있다. 본 연구에서는 ASR로서 Whisper small model을 사용하였으며, TTS로서 Google TTS가 사용되었다.
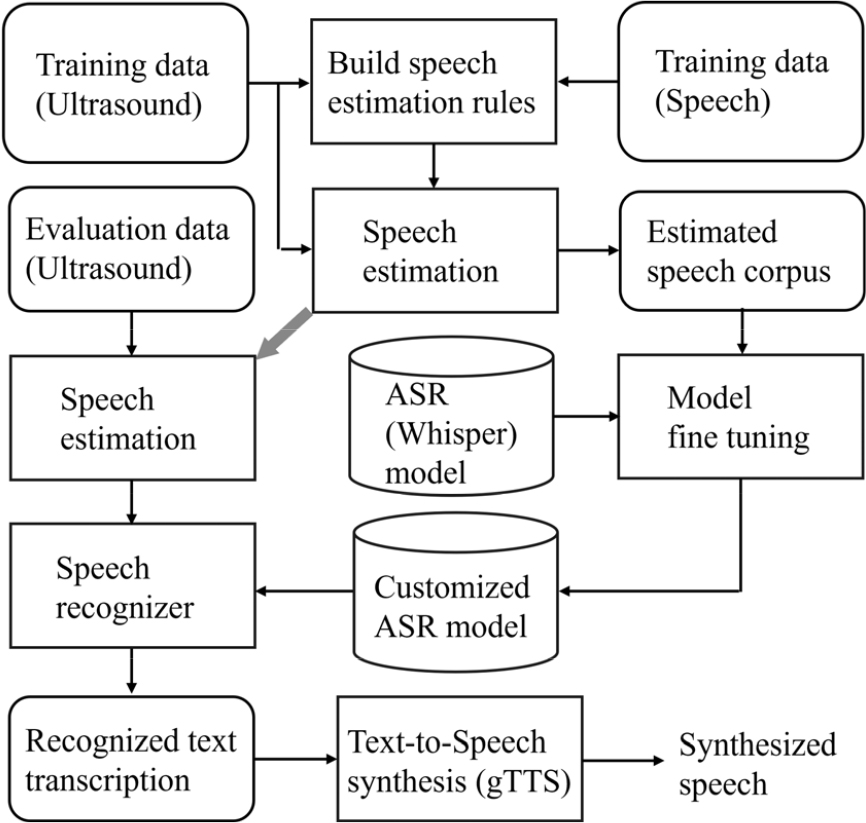
이와 같은 방법의 유용성은 일정 수준 이상의 ASR 정확도가 보장되는지 여부에 따라 결정되는데, 본 연구에서는 학습 데이터에 포함된 음성 신호, 얼굴 전면에서 취득한 초음파 도플로로부터 추정된 음성신호, 턱 아래에서 취득한 초음파 도플러로 추정된 음성신호 각각에 대해 ASR모델을 fine-tuning한 후 문자오류율(CER, Charactor Error Rate)을 살펴보았다. Table 1은 이에 대한 결과로서, 턱 아래에서 취득한 초음파 신호로 추정된 음성은 얼굴 전면에서 취득한 신호와 비교하여 유의하게 낮은 CER을 보였다. TTS로 합성된 음성의 주관적 인지도를 평가하기 위해, 합성음을 정상 청력을 지닌 18명의 피시험자에게 들려주고 이를 받아 적도록 한 후, 단어별 청감 오류율(WER, Word Error Rate)도 살펴보았다.
Table 1.
Chater Error Rate (CER) for three different input signals.
| ASR input signal | CER (%) | WER (%) |
| Raw speech | 3.5 | 0.0 |
| Estimated speech from front face | 36.6 | 20.7 |
| Estimated speech from bottom face | 20.1 | 8.8 |
초음파 추정 음성은 Raw speech와 비교하면 다소 높은 CER을 보이고 있으나, 내용어, 핵심어 부분에서는 상대적으로 낮은 오류가 발생하여 인식 문자열을 TTS로 합성하였을 때, 상대적으로 낮은 WER을 나타내었다. Table 2에 문장 “통조림보다 훨씬 더 효과적인 전투 식량은 없을지 고민했다”에 대해 각 신호에 대한 인식된 결과를 제시하였다. 얼굴 하단에서 취득된 초음파 도플러로 추정된 문장은 전면 취득 초음파 도플러와 비교하여 문장의 내용을 충분히 인지할 수 있음을 나타내고 있다.
Table 2.
Examples of recognition results from each signal.
본 연구에서는 단독 화자에 대한 실험 결과가 제시되었는데, 제안 기법이 보다 널리 이용되기 위해서는 다화자 기법으로 확장되어야 한다. 이를 위해서는 초음파 도플러 신호의 화자 간 차이 분석, 이를 이용한 화자 적응, 화자 정규화 방법이 적용되어야 할 것으로 판단된다.
