

I. 서 론
II. LSTM 모델
III. 수중 기포 소음 데이터
3.1 데이터 수집
3.2 데이터 모델 학습
IV. 수중 운동체 발사 소음 데이터
4.1 데이터 수집
4.2 데이터 모델 학습
V. 결 론
I. 서 론
수중에서는 다양한 요인에 의해 수중소음이 발생한다.[1,2]본 연구에서는 여러 수중 소음 중 기포유동소음과 수중 운동체의 발사 소음을 다루었다. 기포유동소음은 기포소음, 유동소음, 유체기인 소음[3] 이 담겨있는 데이터이며, 수중 운동체 발사 소음은 발사관에서 수중 운동체가 사출될 때 나타나는 소음이다. 이 중 기포유동소음은 저주파 기포소음이 특징적인 데이터, 고주파 기포소음이 나타나는 데이터, 저주파 유동 및 유체소음이 지배적인 데이터의 3가지로 나뉠 수 있다.
위의 두 종류의 소음의 발생 기작은 물리적으로는 결정적이지만 생성 과정 중 유체의 불규칙 특성, 발사 초기 상태의 변동 등의 우연적 요인이 포함되어 이벤트마다 랜덤한 특징도 동시에 가지고 있다. 이러한 종류의 소음은 물리 모델[4,5,6]로 모의하는 것보다는 데이터 생성 모델을 이용해 모의하는 것이 효과적일 수 있다.
본 연구에서는 초기 소음 데이터만 확보했을 때 이후의 시간 데이터를 데이터 기반 모델이 생성할 수 있는지에 대한 연구를 수행했다. 즉, 기계학습 기반 시계열 예측 모델이 위의 수중 소음 데이터의 예측에 적합한 용량을 가지고 있는지를 분석했다.
시계열 데이터를 예측하는 기법으로 대표적으로 Recurrent Neural Networks(RNN), Long Short Term Memory(LSTM), Gated Recurrent Units(GRU) 등의 기법이 존재한다.[7] RNN은 시계열 데이터가 길어질수록 역전파 이용 시 가중치의 기울기가 소실/폭발 하는 문제[8] 가 발생할 수 있어서 여러 수정 알고리즘이 나왔지만 장시간 학습에서는 일반적으로 좋은 성능을 보이지 못한다. LSTM은 기존의 RNN의 이러한 단점을 보완하고자 제안된 모델로 4개의 게이트(Gate)와 메모리셀을 추가하여 기울기 소실/폭발 문제와 장시간 학습문제를 해결하였다.[9,10] GRU는 LSTM의 계산량을 줄인 모델이다. 또한 시계열 예측 모델은 아니지만 Attention 기술[11] 을 시계열 예측 모델에 적용하면 시계열 특징벡터에 가중치를 주는 방식으로 예측을 위한 정보를 보다 폭넓게 활용할 수 있다. 본 연구에서는 위의 여러 기술 중 LSTM을 이용한 시계열 예측을 수행했다. 본 논문에서 싣지는 않았지만 RNN을 이용한 방식은 LSTM과 비슷한 성능을 보였으며 Attention 기법은 이 두 기법보다 훈련성능은 좋았으나 시험성능은 좋지 못했다.[12]
본 연구에서는 모형 수조에서 측정한 기포유동소음[13] 과 수중운동체 발사소음 데이터[14,15]를 시계열 예측 모델의 입력값으로 사용했다. LSTM 모델을 적용할 때, 데이터의 구조와 유형, 모델의 모수 값에 따라 정확도에 어떤 영향을 미치는 지에 대해 비교 연구한다.
II. LSTM 모델
LSTM은 기존의 RNN에 4개의 게이트와 메모리 셀이 추가된 순환신경망이다.[7] 전체적인 구조는 Fig. 1과 같으며, 각 게이트는 역할에 따라 입력 게이트, 망각 게이트, 출력 게이트, 갱신 게이트로 불린다.
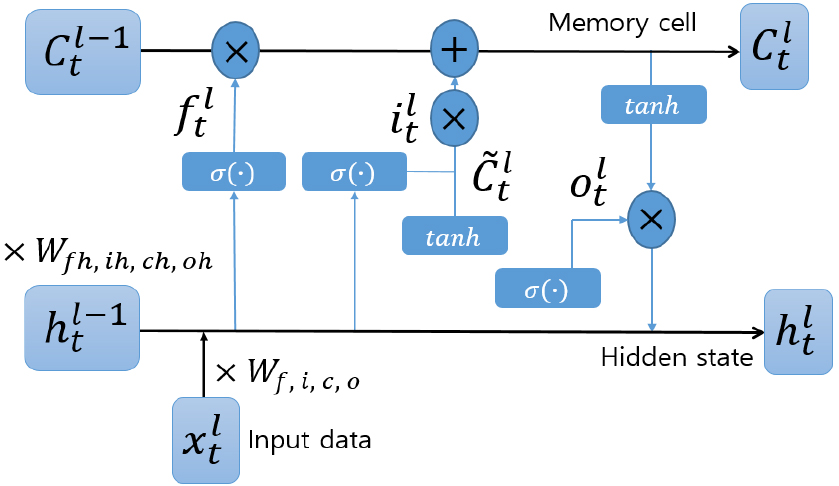
입력 게이트는 현재 메모리 셀에게 무관한 입력 데이터와 동요되지 않도록 입력 데이터를 조절해주는 역할을 한다. 망각 게이트는 이와 반대로 이전 메모리 셀에서 무관한 입력 데이터를 약하게 출력되도록 조절해준다. 출력 게이트는 현재 메모리 셀이 무관한 메모리 셀과 동요되지 않도록 메모리 셀을 조절해주는 역할을 한다. 갱신 게이트는 현재 메모리 셀과 이전 메모리 셀을 앞의 게이트들을 이용해 현재 메모리 셀을 갱신해주는 역할을 한다. 메모리 셀은 기존의 RNN과 달리 직전 데이터와 현재데이터의 관계만 전달하는 것이 아니라 더 거시적인 데이터를 연결을 하기 위해 고안된 저장소이다. 각 게이트들과 메모리 셀은 Table 1과 같이 구성되어 있다.
Table 1.
Equations in LSTM.
| LSTM cell | Equation |
| Input gate | |
| Output gate | |
| Forget gate | |
| Cell state | |
| Update gate | |
| Hidden state | |
| Fully conneted layer |
Table 1에서 는 입력 데이터, 는 입력 데이터셋, 는 데이터셋의 개수, 은 입력 시퀀스 길이, 는 가중치, 는 이전 은닉 유닛(Hidden unit), 은 편향, 은 시그모이드(Sigmoid) 함수, 은 후보 메모리 셀, 는 아다마르 곱(Hadamard product), 는 예측 값이다.
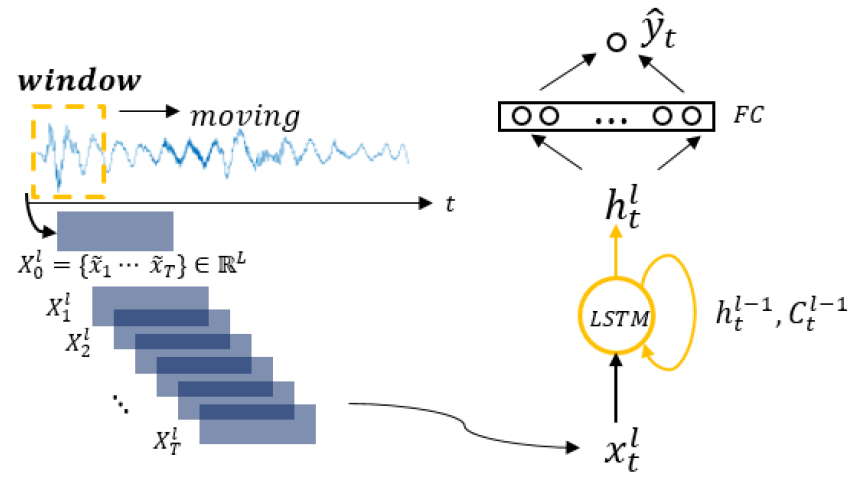
본 연구에서 사용된 LSTM 기계학습 모델은 Fig. 2와 같다. LSTM은 학습에서 셀이 입력 시퀀스 길이 단위로 입력되며, ‘Many to one’ 방식으로 학습을 진행한다. LSTM 층은 1개를 사용했다.
III. 수중 기포 소음 데이터
3.1 데이터 수집
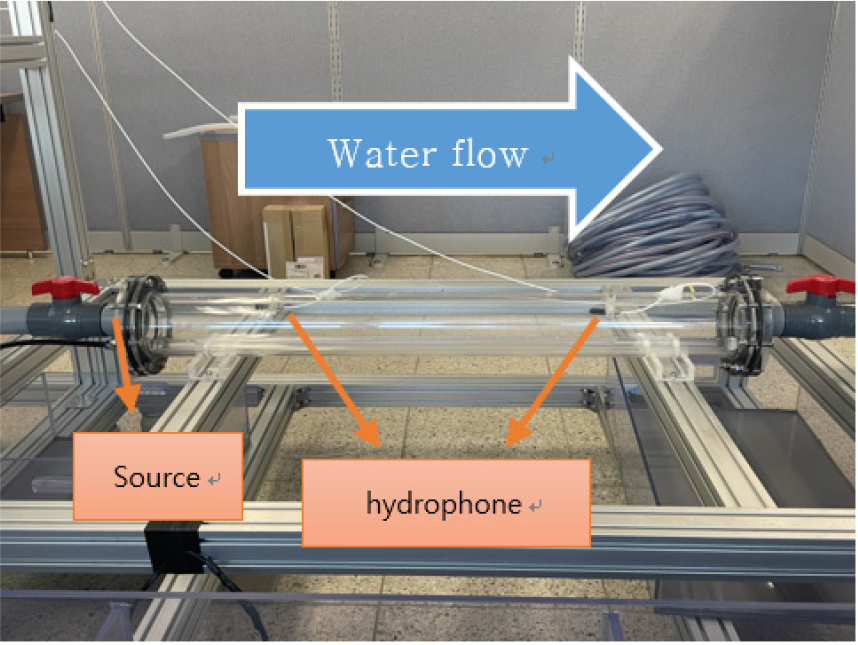
기포유동소음 데이터는 Fig. 3 과 같은 설비를 이용하여 측정했다. 물이 흐르는 배수관의 주입구에 소음원인 기포를 발생시켜 배수관의 양 끝에서 2개의 수중청음기를 설치하고 데이터를 수집했다.
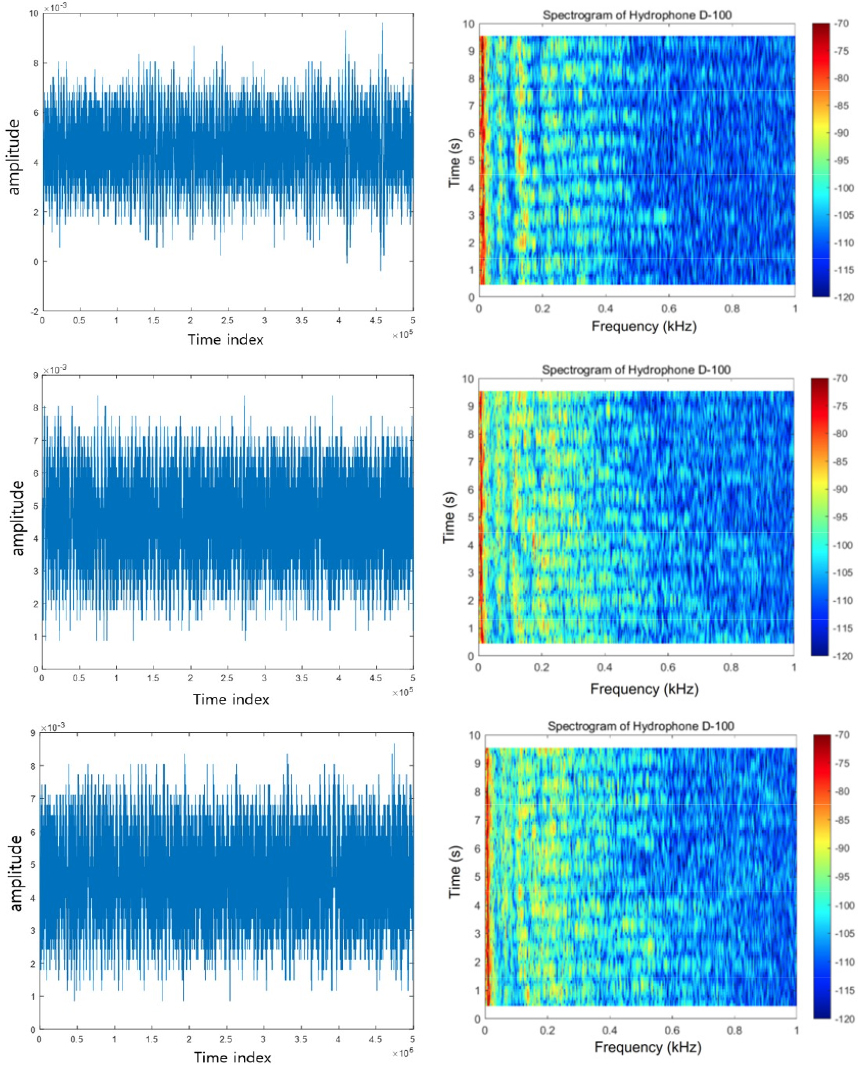
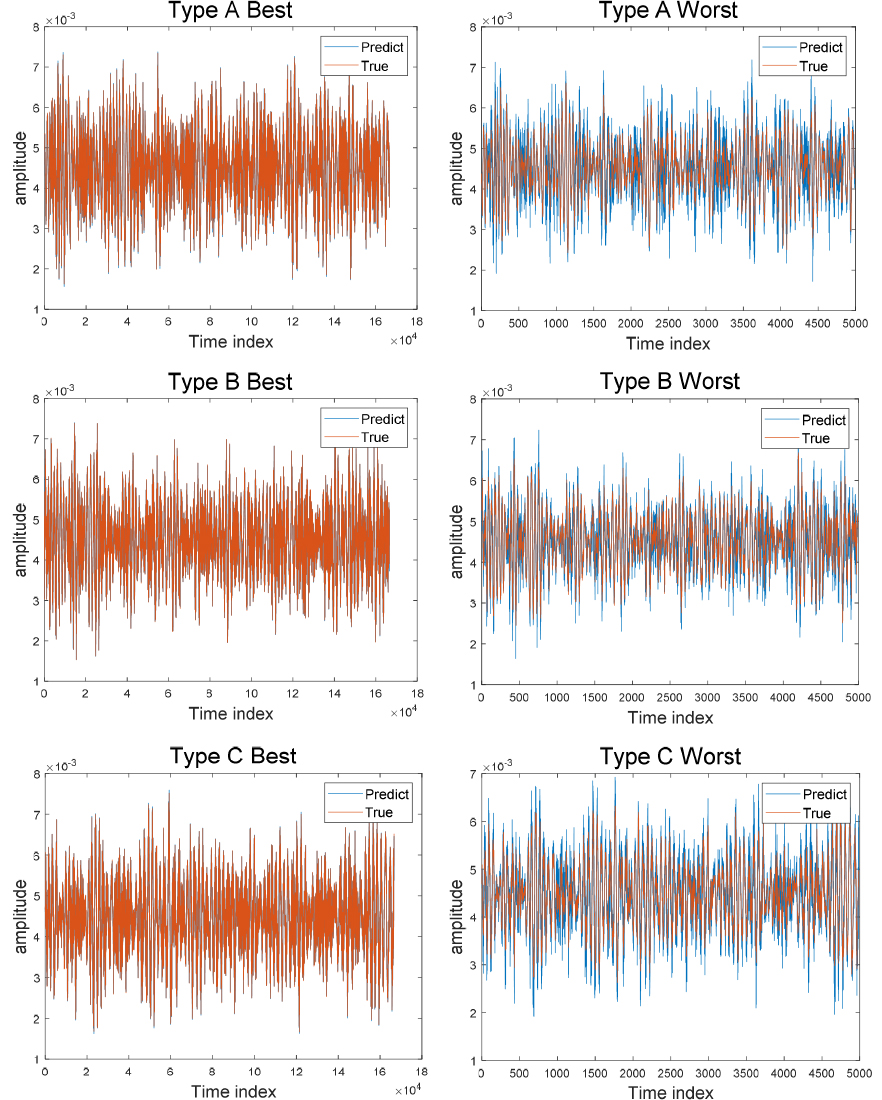
샘플링 주파수 50 kHz로 소음을 측정하였고 총 405번의 실험이 진행되었다. 측정된 데이터에는 기포 생성 및 소멸 소음만 있는 것이 아니라, 물의 배출구에서의 유체의 낙하, 구조물과의 연성, 기포가 뭉쳐서 배출구에서 주기적으로 배출되는 현상 등으로 다양한 성분의 소음이 섞여 있다. 본 연구에서는 데이터 분석을 통해 405개의 데이터는 저주파 협대역 기포소음이 지배적인 160개의 데이터(A), 유동 및 유체 소음과 고주파 기포소음이 지배적인 113개의 데이터(B), 기포 소음이 거의 발생하지 않는 132개의 데이터(C)로 분류했다. 각각의 데이터는 50,000개의 시계열 샘플로 구성되어 있으며, 초반 2,000개의 샘플을 학습에 사용했다. Fig. 4는 각 A, B, C타입의 스펙트로그램을 각각 나타낸다. A 타입은 1 kHz 근처에서 기포에 의한 협대역 소음이 관찰되며, B 타입은 저주파 대역의 유체소음이 지배적이면서 고주파 영역에서 작은 크기의 기포 소음이 랜덤하게 나타난다. C 타입은 기포소음은 거의 없고 유체 및 구조물 기인소음이 지배적이다.
3.2 데이터 모델 학습
데이터 학습을 위해 LSTM의 모수를 결정해 줘야 한다. LSTM의 주요 모수는 입력 시퀀스 개수와 은닉 유닛의 개수를 들 수 있다. 또한 원본 데이터의 데시메이션도 고려해야 한다. 본 연구에서는 Table 2의 여러 모수들에 대해서 데이터 모델을 튜닝했다.
Table 2.
Hyperparameters of LSTM model.
| Name | Hyperparameter |
| Hidden unit | 10, 30, 50, 70, 100 |
| Sequence length | 10, 30, 50, 70, 100, 150, 200 |
| Decimation factor | 3, 10, 50, 100 |
모델 학습을 위한 모수로는 은닉층 노드 수, 입력시퀀수 길이, 데시베이션 계수를 선택했다. 우선 은닉 유닛은 LSTM의 은닉층의 노드 개수이며, 일반적으로 은닉 유닛이 너무 작을때는 모델의 표현력이 작아져 언더피팅을 일으킬 수 있고 반면에 은닉 유닛이 너무 클때는 모델의 표현력이 커지지만 오버피팅을 일으킬 수 있다고 알려져 있다. 이 시뮬레이션에서는 입력시퀀스 길이는 10개, 데시메이션 계수는 적용하지 않고 은닉 유닛을 10, 30, 50, 70, 100으로 조절하여 진행했다. 은닉 유닛의 개수에 대해 훈련 손실의 변화를 관찰해보면 크게 유의미한 변화를 보이지 않았다. Tables 3과 4는 학습 및 시험손실 값을 보여준다.
Table 3.
Minimum MSE of train set (hidden unit).
Type Hidden unit | A (10-4) | B (10-4) | C (10-4) |
| 10 | 10.13 | 10.03 | 9.06 |
| 30 | 10.31 | 10.04 | 8.48 |
| 50 | 10.13 | 9.79 | 8.40 |
| 70 | 10.61 | 8.78 | 8.48 |
| 100 | 10.29 | 9.12 | 9.11 |
Table 4.
Minimum MSE of test set (hidden unit).
Type Hidden unit | A (10-4) | B (10-4) | C (10-4) |
| 10 | 13.62 | 12.58 | 12.34 |
| 30 | 13.65 | 12.53 | 12.18 |
| 50 | 13.59 | 12.55 | 12.21 |
| 70 | 13.62 | 12.44 | 12.16 |
| 100 | 13.59 | 12.43 | 12.17 |
입력 시퀀스 길이는 LSTM 모델이 예측 값을 결정할 때 예측 값 이전의 몇 개의 시계열까지 거슬러 올라갈 것인지 정해놓은 값이다. 입력 시퀀스 길이가 길어질수록 모델은 시계열 데이터의 전반적인 흐름을 잘 학습할 것이고, 입력 시퀀스 길이가 작아질수록 세밀한 변화를 잘 학습할 것이라 예상했다. 이 시뮬레이션에서는 은닉 유닛을 10으로 고정하고 앞과 마찬가지로 데시메이션 계수는 적용하지 않았으며, 입력 시퀀스 길이를 10, 30, 50, 70, 100, 150, 200으로 조절하여 진행했다. 입력 시퀀스 길이에 대해서는 A타입은 30, B타입은 10개, C타입 100개의 입력 시퀀스 길이에서 훈련 손실 값이 가장 작았지만, 입력 시퀸스 길이가 10 이상이면 훈련 손실이 매우 작기 때문에 유의미한 차이는 없었다. Tables 5와 6은 학습 및 시험손실 값을 보여준다.
Table 5.
Minimum MSE of train set (input sequence length).
Type Length | A (10-4) | B (10-4) | C (10-4) |
| 10 | 9.50 | 8.21 | 9.15 |
| 30 | 9.17 | 9.96 | 8.95 |
| 50 | 10.40 | 10.17 | 8.43 |
| 70 | 9.65 | 9.19 | 8.70 |
| 100 | 10.01 | 9.52 | 7.79 |
| 150 | 11.06 | 10.33 | 8.00 |
| 200 | 10.25 | 8.52 | 8.33 |
Table 6.
Minimum MSE of test set (input sequence length).
Type Length | A (10-4) | B (10-4) | C (10-4) |
| 10 | 13.62 | 12.61 | 12.25 |
| 30 | 13.35 | 12.50 | 12.09 |
| 50 | 13.34 | 12.54 | 12.03 |
| 70 | 13.25 | 12.61 | 12.06 |
| 100 | 13.29 | 12.37 | 11.94 |
| 150 | 13.66 | 12.49 | 12.06 |
| 200 | 13.40 | 12.36 | 12.06 |
데시메이션 계수는 신호처리 기법에서 원 신호가 에일리어싱이 발생하지 않고, 원하는 주파수 대역에 비해 과도한 데이터가 쓰이지 않도록 적당한 값을 선택하도록 권고되어 있다. 이를 기계학습의 관점에서 데시메이션 계수를 이용해 데이터의 샘플링이 예측에 있어서 어떤 영향을 미칠지 알 수 있다. 데시메이션 계수가 너무 크다면 데이터의 정보량이 적어 모델 성능에 악영향을 미치지만, 데시메이션 계수가 너무 작다면 과도한 데이터 사용으로 효율적인 학습을 할 수 없을 것이다. 은닉 유닛을 10, 입력 시퀀스 길이를 10으로 고정하고 데시메이션 계수는 3, 10, 50, 100으로 조절하여 모델 테스트를 진행했다. 모든 데이터 셋에서 데시메이션 계수가 3일 때 가장 낮은 손실 값을 보인다. 앞의 두 개의 모수와 달리 데시메이션 계수는 선택에 따라 유의미한 결과를 보인다. Tables 7과 8은 학습 및 시험손실 값을 보여준다.
Table 7.
Minimum MSE of train set (decimation factor).
Type Factor | A) | B | C |
| 3 | 0.08 | 0.07 | 0.11 |
| 10 | 8.98 | 10.33 | 9.04 |
| 50 | 32.48 | 40.72 | 31.39 |
| 100 | 53.18 | 32.02 | 53.54 |
Table 8.
Minimum MSE of test set (decimation factor).
Type Factor | A | B | C |
| 3 | 0.17 | 0.08 | 0.12 |
| 10 | 13.65 | 12.67 | 12.24 |
| 50 | 54.94 | 44.92 | 50.71 |
| 100 | 72.86 | 58.41 | 76.40 |
Fig. 5는 가장 좋은 결과를 주는 데이세이션 계수(3일 때)와 가장 나쁜 결과를 줄 때의 결과를 각각의 타입별로 보여준다.
IV. 수중 운동체 발사 소음 데이터
4.1 데이터 수집
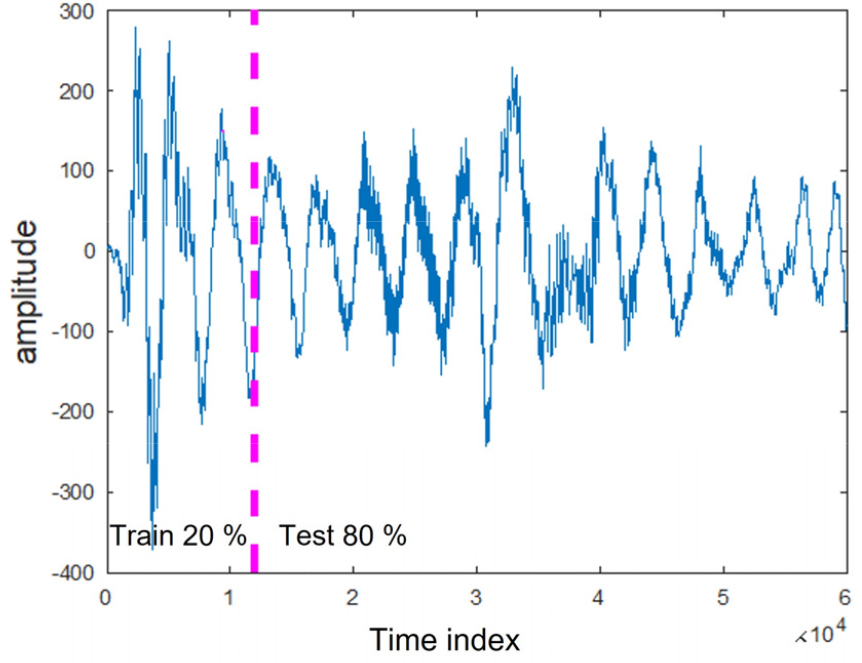
수중 운동체의 발사 소음 데이터는 동명대학교 중형수조에서 수중 운동체가 모형 발사 튜브를 이용해서 발사할 때 발생하는 소음을 수중청음기로 측정했다. 수중 운동체는 피스톤의 압력에 의해 발사 튜브로부터 사출되며 발생 소음은 피스톤 운동이 시작하면서 끝날 때까지 연속적으로 발생하며, 소음 특성은 피스톤 및 발사 튜브의 물리/운동학적인 상태와 밀접한 관련이 있다. 본 연구에서는 한 지점에서 60,000개의 샘플로 이루어진 데이터를 이용했다. Fig. 6은 해당 데이터를 보여준다. 초반 12,000개의 샘플은 훈련데이터로 사용하고, 나머지 48,000을 실험데이터로 사용했다.
4.2 데이터 모델 학습
앞의 기포 데이터와 마찬가지로 Table 9의 여러 LSTM의 모수에 대해 최적의 데이터 모델 학습을 수행했다. 나머지 조건은 기포 데이터와 동일하다.
Table 9.
Hyperparameter of simulation model.
| Name | Hyperparameter |
| Hidden unit | 10, 30, 50, 70, 100 |
| Sequence length | 10, 30, 50, 70, 100, 150, 200 |
| Decimation factor | 50, 100, 130, 150 |
우선 입력시퀀스 길이는 10개, 데시메이션 계수 1로 놓고 은닉 유닛을 10, 30, 50, 70, 100으로 조절하여 학습 성능을 분석했다. 훈련손실 값은 각각 0.008, 0.008, 0.009, 0.007, 0.009였으며, 시험손실은 0.400, 0.401, 0.398, 0.403, 0.401이었다. 앞서 마찬가지로 발사 소음 데이터에서도 은닉 유닛은 10개 이상이면 의미있는 차이가 존재하지 않았다. 입력 시퀀스 길이를 결정하기 위해 은닉 유닛을 10으로 고정하고 앞과 마찬가지로 데시메이션 계수는 적용하지 않았으며, 입력 시퀀스 길이를 10, 30, 50, 70, 100, 150, 200으로 조절하여 진행했다. 훈련손실 값은 각각 0.009, 0.008, 0.007, 0.009, 0.008, 0.008, 0.008이었으며, 시험손실은 0.408, 0.374, 0.369, 0.430, 0.371, 0.359, 0.354이었다. 훈련 데이터에서는 입력 시퀀스의 길이가 50일 때 최소 손실 값을 보이나 앞의 실험과 유사하게 입력시퀀스에 따른 유의미한 변화는 보이지 않았다. 데이메이션 계수와 관련해서는 은닉 유닛은 10개, 입력 시퀀스 길이 10으로 고정하고, 데시메이션 계수는 50, 100, 130, 150으로 조절하여 진행하였다. 훈련손실 값은 각각 0.037, 0.035, 0.057, 0.037이었으며, 시험손실은 0.079, 0.912, 1.397, 2.432이었다. 훈련 데이터셋에서 데시메이션 계수는 100일 때 가장 낮은 손실값을 보였으나, 시험손실까지 고려하면 50이 가장 좋았다. 앞의 시뮬레이션과 달리 데시메이션 계수는 실험 데이터에 적용했을 때 손실 값의 차이가 컸다.
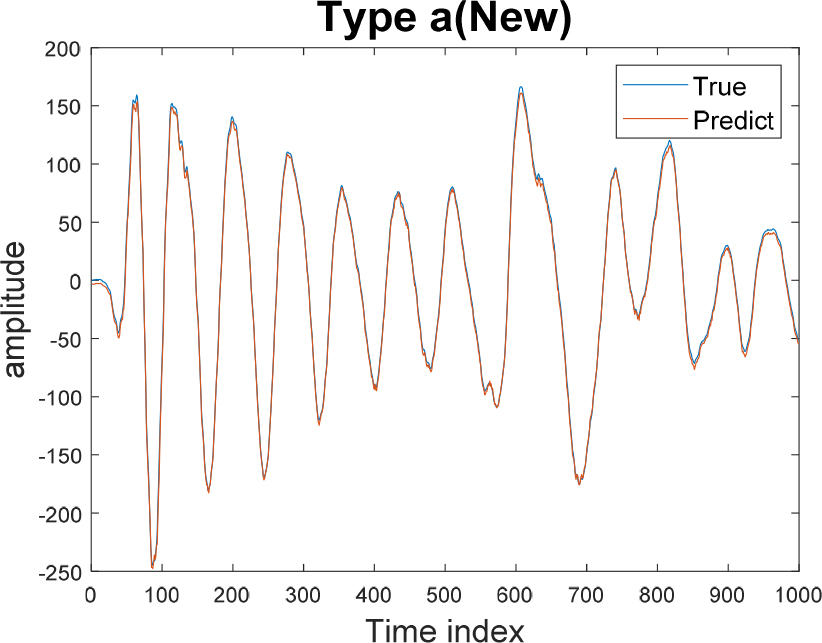
Fig. 7은 학습하지 않은 유사한 위치의 데이터에 대해 최적의 LSTM 모델(은닉유닛 10, 입력 시퀀스 길이 10, 데시메이션 계수 50)을 이용해 예측을 수행한 것이다. Fig. 7에 보이는 것처럼 LSTM 모델은 초기 시퀀스가 주어졌을 때, 학습하지 않은 데이터도 유사하게 예측하는 것을 확인할 수 있다.
V. 결 론
본 연구는 시계열 데이터 예측 분야에서 널리 사용되는 LSTM 모델을 이용해 두 종류의 수중 소음을 예측해보았다. 첫 번째 데이터는 파이프 배수관에서 측정된 기포 유동 소음 데이터를 이용해 학습 및 예측을 진행하였고, 두 번째 데이터는 수중 운동체 발사 소음으로, 모형수조에서 모형 발사 설비로부터 측정한 데이터이며, 이를 이용해 학습 및 예측을 진행했다.
본 연구에서는 두 가지 수중소음에 대해 LSTM 모델의 유용성을 확인하고 모수 선택을 하는 과정을 다루었다. 모수 최적화를 위한 여러 실험을 통해 은닉 유닛의 길이와 입력 시퀀스의 길이는 주어진 데이터에 대해서는 특정 값 이상이면 모델의 성능에 큰 영향을 미치지 않았다. 하지만 신호의 데시메이션의 영향은 유의미했다. 그 이유는 본 연구에서 사용된 소음들이 비교적 광대역 신호의 특성을 가지고 있기 때문이라고 생각한다.
시뮬레이션 결과를 통해 얻은 최적의 하이퍼파라미터로 구축한 모델을 이용해, 같은 유형의 새로운 데이터의 예측을 진행해본 바 좋은 예측 결과를 얻을 수 있었다.
