

I. 서 론
II. 관련 연구
2.1 Iterative Shrinkage and Thresholding Algorithm(ISTA)
2.2 ISTA-NET
2.3 SENET
III. 제안 방법
3.1 기존모델 비교
3.2 초기화 모듈
3.3 ISTA 블록
3.4 픽셀 공간 투사 upsampling 모듈
3.5 손실 함수
IV. 실험 결과
4.1 측면 주사 소나 초 해상도 복원
4.2 측면 주사 소나 초 해상도 복원 실험 결과
V. 결 론
I. 서 론
수중영상을 통한 해양 탐사 연구는 지속적인 관심을 받고 있으며, 국방영역과 민간영역 두 분야에서 활발하게 발전되고 있다. 두 분야에서 해저면 물체 식별 및 인식을 위한 수중 시각화는 공통적인 관심 요소이다. UAV, 기뢰 식별과 같은 국방 분야와 지질 조사, 광물 탐사와 같은 민간 분야에서 연구들이 활발히 진행되고 있으며, 측면 주사 소나는 수중 영상을 획득할 수 있는 널리 알려진 능동형 원격탐사 기기로 일반적인 광학 영상 기기와 다른 특성을 가지고 있다. 측면 주사 소나 영상 시각화의 가장 큰 이슈는 운용 주파수에 따른 촬영 범위와 해상도 사이의 트레이드-오프 관계이다. 저주파 측면 주사 소나는 유전체 손실, 피층 효과 등이 작아 넓은 영역 촬영에 적합하지만, 고화질 영상을 얻을 수 없다. 반대로 고주파 측면 주사 소나는 고해상도의 영상 획득이 가능하지만, 촬영범위가 협소하여 광범위한 해저면 영상이 획득될 수 없다. 저해상도의 측면 주사 소나 영상을 고해상도 영상으로 개선하는 기술은 측면 주사 소나를 이용한 효율적 수중 탐색에 중요한 요소가 될 수 있다.
광학 영상의 초해상도 복원 연구는 최근 딥러닝 기반의 여러 기법이 제시되었으며 기존 결과들을 넘어서는 우수한 성능 결과를 보여주고 있다.[1] 하지만 수중 소나 영상의 초해상도 복원 연구는 광학 영상과는 달리 질적/양적으로 부족한 훈련 데이터 등 제약적인 요소로 인해 활발한 연구가 진행되지 못하고 있다. 압축 센싱 연구는 2006년 “IEEE Trans. on Information Theory”에 발표된 이론으로 대부분의 값이 인 성긴 신호에 대해 적은 수의 선형측정으로 원신호를 복원시킬 수 있다.[2] 수중영상의 희소성을 분석, 스파스 코딩 관점이 측면 주사 소나 영상 복원에 효과적임이 증명되었다.[3] 학습기반 영상개선은 필요한 파라미터들을 학습을 통해 자동적으로 설정하게 되는데 최근에는 딥러닝 네트워크와의 접목을 통해 우수한 성능을 획득하고 있다.[4] 2018년 “CVPR” 학회에서 발표된 “ISTA- NET”은 이러한 장점을 결합하여 제안된 학습기반 압축 센싱 네트워크로 “ISTA-NET”의 모든 파라미터는 자동화되어 학습 가능하며, 영상 복원에 탁월한 성능을 보인다.[5]
본 논문에서는 학습 기반 압축 센싱 네트워크를 수중 소나 영상의 초해상도 복원에 적용하는 방법에 대해 다룬다. 제안하는 학습 기반 압축 센싱 네트워크는 ISTA-NET의 기본 구조를 따르고 있다. 해상도 향상을 위해 본 논문에서는 초기화 부분을 개선하는 접근 방법을 제안하였으며 영상 재구성을 위한 확장 레이어를 추가하여 초해상도 복원을 위한 학습 기반 압축 센싱 네트워크를 구성하였다. 초해상도 복원 네트워크의 경량화를 위해 효과적인 특징 정보 추출을 위한 초기화는 저해상도 공간에서 추출하는 방식을 채택하였다. 다양한 측면 주사 소나 영상에 대한 모의 실험을 통해 제안된 방식의 우수성을 입증하였다.
본 논문의 구성은 다음과 같다. II장에서는 관련 연구에 대한 소개를, III장은 제안 방식들에 대한 세부 내용을 알아본다. IV장 에서는 제안 방식들의 실험 결과를 보여주며, V 장은 본 논문의 결론을 기술한다.
II. 관련 연구
2.1 Iterative Shrinkage and Thresholding Algorithm(ISTA)
압축 센싱 관점에서 관측 신호 을 토대로 원신호 를 복원하는 문제는 Eq. (1)과 같이 표현할 수 있다.
여기서 는 측정 행렬, 는 신호 x를 sparse 공간으로 변환해주는 변환 행렬,는 정규화 파라미터를 나타낸다. ISTA는 Eqs. (2), (3) 단계를 반복하면서 Eq. (1)의 최적화 해를 찾게 된다.
여기서 는 반복 단계, 는 스텝 크기 이다.
2.2 ISTA-NET
ISTA-NET은 전통적인 압축 센싱 방법인 ISTA를 학습기반 네트워크로 확장한 모델이다. 최적화 해를 찾기 위해 필요한 변환 및 문턱치 값들을 경험적으로 수동 설정해야 것을 딥러닝 네트워크를 통해 자동으로 설정할 수 있는 네트워크 형태로 구성하였다. Eq. (4)에서의 는 각각의 3x3 “filter”를 가지는 “convolutional operator”이고, F(x)는 Rectified Linear Unit(ReLU) 비선형 변환을 통한 함수이다.
2.3 SENET
Squeeze and Excitation(SE) NET은 특징 정보의 압축과 재조정을 통해 효율적인 학습을 유도한다.[6] 압축과 재조정은 각각 Eqs. (5)와 (6)를 통하여 진행된다.
여기서 ,,는 특징맵의 높이, 폭, 채널 크기를 나타낸다.는 c번째 필터의 파라미터이며, 는 입력 이미지 공간에서의 평균 연산을 나타낸다. 는 2개의 완전 연결층과() 와 는 각각 ReLU() 함수, sigmoid 함수()로 구성된다.
III. 제안 방법
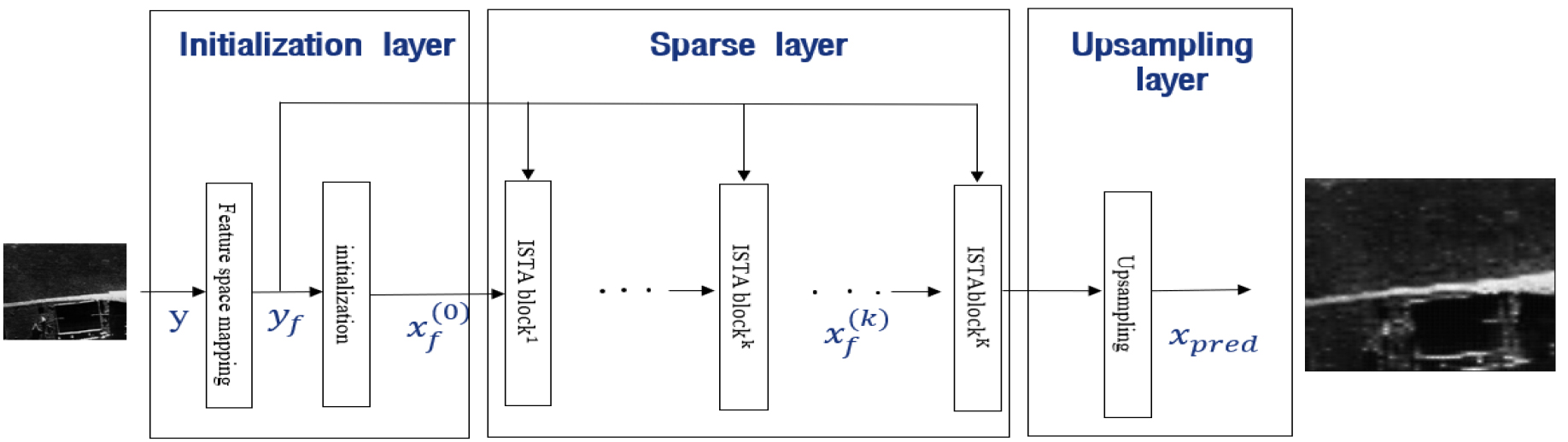
본 논문에서는 Fig. 1과 같이 ISTA 기반의 초해상도 학습형 압축 센싱 모델을 제안한다. 제안 모델은 초기화 모듈, 특징맵을 희소하게 표현해 주는 ISTA- block 모듈, 초해상도 영상 차원으로 특징을 변환해주는 업샘플링 모듈로 구성된다.
3.1 기존모델 비교
1) 기존 모델
연구에서 기초모델로 사용된 ISTA-NET은 압축센싱을 적용한 잡음제거 모델을 제안했으며, SE-NET은 전반적인 딥러닝 모델에 적용 가능한 특징 활용방식을 제안하였다. ISTA-NET에서의 초기화 모듈은 잡음제거 방식에 맞게 선형맵핑 방식을 제안하였다. ISTA-NET에서는 학습가능한 선형 Convolutional operator들로 기존 ISTA 모델안의 모듈을 대체했으며, 이는 “3x3 conv”을 기본으로 구성한다.
2) 기존 모델과의 차이점
본 연구에서는 최소 자승 방식으로 초기화를 추정해 기초적인 잡음제거를 수행하는 잡음제거 모델과는 달리, 조금 더 풍부한 특징을 추출하여 초해상도 복원에 활용하여 성능을 향상할 수 있는 다양한 초기화 방식을 제안하였으며, 추출된 정보를 활용하여 초해상도 복원을 수행하기 위한 학습 가능한 픽셀공간 투사 모듈을 제안하였다.
3.2 초기화 모듈
초기화 모듈은 Fig. 1과 같이 입력 영상을 특징 공간으로 변환해주는 “Feature space mapping” 부분과 고해상도 영상 확장을 위한 “Initialization”부분으로 구성된다. “Feature space mapping”은 2개의 “3x3conv” 연산과 “ReLU” 비선형 변환을 통해 입력 영상을 특징 공간으로 변환하고 비선형적 특징이 추출된다. “Initialization”은 고해상도 영상 복원을 위한 정보를 1차적으로 획득하는 과정이다. 일반적으로 고해상도 영상 복원을 위한 “Initialization”은 “bicubic” 보간을 통해 영상 혹은 특징을 확장해 주게 된다. 그러나 확장된 공간에서 초해상도 네트워크 모델을 학습시키는 방법은 계산량 문제와 신호 왜곡문제점들이 발생할 가능성이 있다.[7] 본 논문에서는 공간상의 확장에 필요한 정보를 채널의 확장을 통해 추정하는 방식을 제안한다. 채널 확장을 통한 고해상도 정보 추출 방식은 학습 모델 파라미터를 줄이면서도 복원 정보를 추정하는 이점을 지닌다. Fig. 2와 같이 단순 채널 확장 초기화 방식과 더불어 주요한 채널 정보에 가중치를 두어 채널 확장하는 방식을 제안한다.
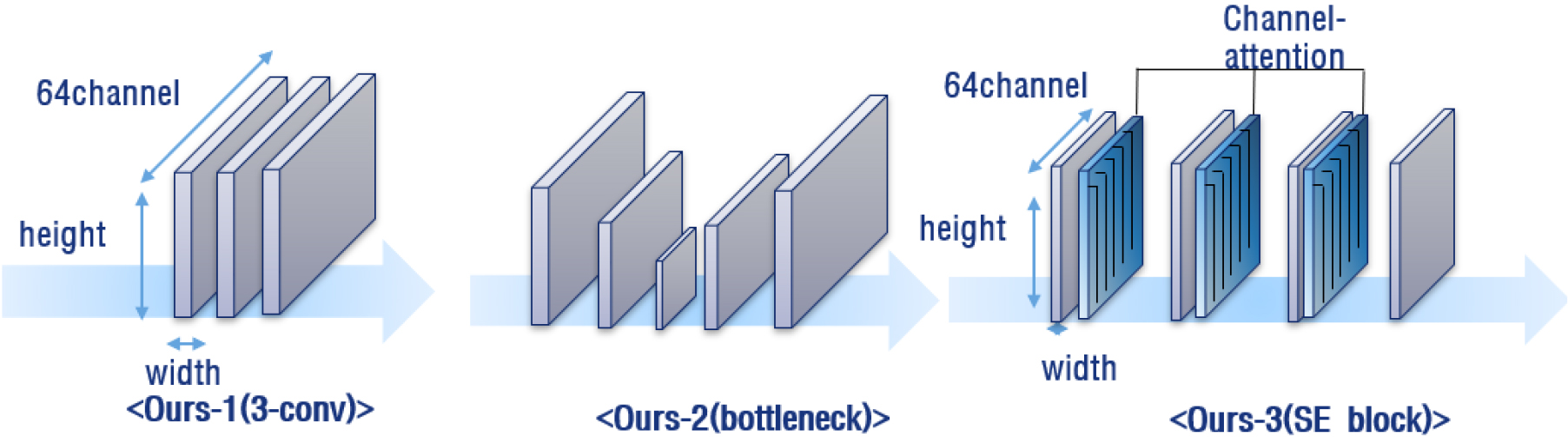
1) 기본 초기화 모듈
기본 초기화 모듈은 초기화 부분을 64 채널의 “3x3 conv” 3개로 구성해 네트워크의 기초적 초 해상도 복원 성능을 검증한다. 초 해상도 복원에 필요한 정보가 선별되지 않았을 때의 압축 센싱을 이용한 학습기반 네트워크의 기초적 성능을 알아보기 위함이다.
2) Bottleneck 초기화 모듈
병목(Bottleneck) 초기화 모듈에서는 채널이 점점 감소하다 증가하는 추세의 병목 구조를 통해 입력특징이 로 초기화된다. 채널이 확장된 특징 정보들이 초 해상도 복원에 유의미한 초기화 값을 형성하기 위해 병목 구조를 제안한다. 확장된 채널 정보 중 중요 여부에 대한 필터링 과정을 채널의 병목 구조를 통해 얻는다.
3) SE 초기화 모듈
SE 초기화 모듈에서는 채널을 통과한 정보들의 필터링 과정에서 나아가 정보의 가중치를 가하기 위해 “3x3 conv”과 SE 블록을 연결하여 설계한다. SE 블록을 “3x3 conv” 뒤에 구성해 채널의 추출된 입력 영상의 특징 중 초 해상도 복원에 도움을 주는 특징에 가중치를 더한다. 가중치로 인해 모델을 학습시킬때 고해상도 복원에 효과적인 정보들을 더욱 반영하도록 하고자 하였다.
3.3 ISTA 블록
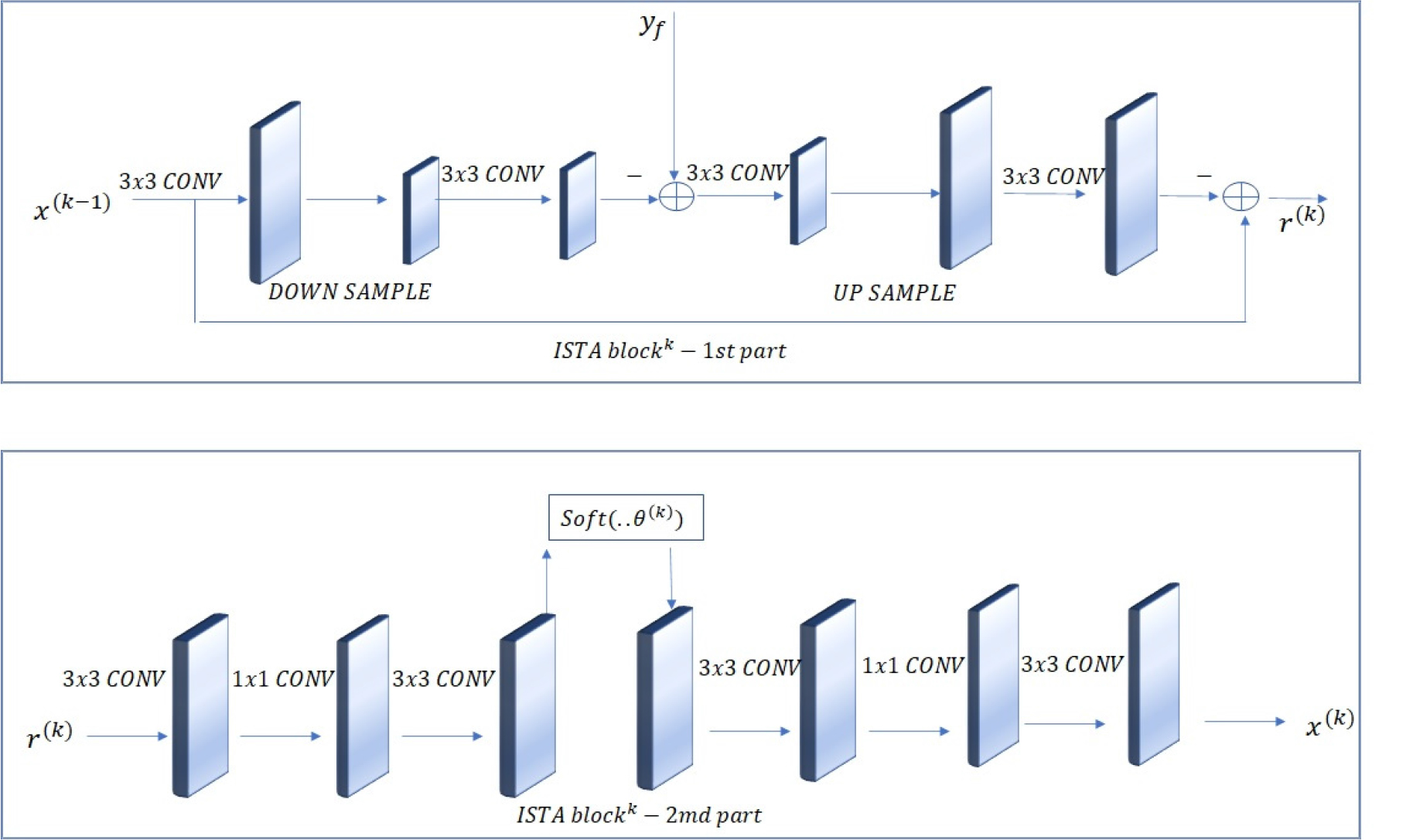
ISTA 블록의 수식은 Eqs. (7), (8)로 표현할 수 있다. 각각의 표현은 특징 표현 공간으로 매핑된 저해상도 영상의 특징 표현 , 특징 공간 내에서 추출되는 특징 표현 , 측정 행렬 , 에 대응되는 , 와 , 에 대응되면서 가 희소(sparse) 해질 수 있는 변환 공간 이다. , 와 은 서로 Restrict Isometry Property(RIP)를 만족하도록 학습하며 대칭적인 성질을 가진다.
ISTA-block은 Fig. 3과 같이 1st part와 2nd part로 구성되어 있다. Eq. (7)의 1st part는 측정 연산 와 의 계산으로 구성되며 는 “3x3conv”, “down sample”, “3x3conv”로 표현된다. 파란색 상자의 채널 크기는 두께와 비례하며, 는 의 역 구조를 가진다. Eq. (8)에 해당하는 2nd part는 1st part로부터 복원된 를 변환 공간 에서 파라미터를 가지는 “soft thresholding function” 으로 희소한 성질을 갖게 하고 로 역변환하여 희소한 성질을 갖는 특징 표현으로 복원한다. 와 는 두 개의 “3x3conv”사이에 “1x1conv”이 위치하여 비선형성을 강화하는 구조를 가지도록 설계되었다. 또한 의 마지막 “3x3conv” 채널을 두 배로 구성하여 “over- complete” 사전의 역할을 한다. K-번의 ISTA- block을 통해 비선형 공간에서의 희소해 를 얻는다.
3.4 픽셀 공간 투사 upsampling 모듈
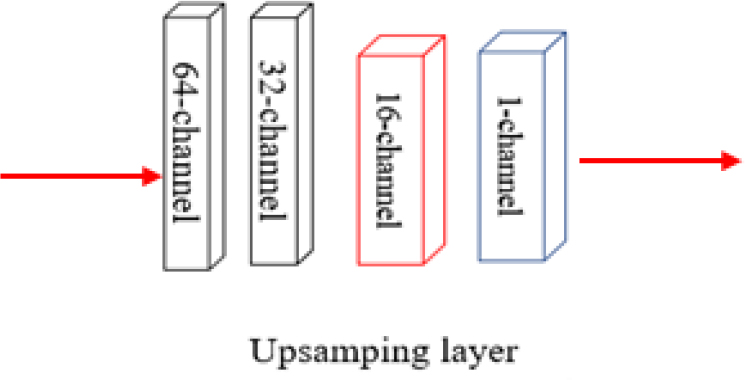
압축된 특징을 픽셀 공간으로 확장 투사를 위해 복원 영상 신호 는 Fig. 4의 “Upsampling layer”를 통과한다. 특징 표현은 저해상도 차원에서 ISTA-block을 거쳐 고해상도 공간으로 가기 위해 해상도를 늘려주는 “Upsampling layer”를 통과하게 되며, “Upsampling layer”는 연속된 두 개의 “Deconv layer”와 “3x3conv”와 “1x1conv”으로 이루어져 있다. 입력특징은 특징 공간에서 픽셀 공간으로 영상 크기를 늘려 최종 복원 결과를 얻게 된다. Fig. 4에서 64 채널과 32 채널로 표현된 검은색 “Deconv block”은 점근적으로 신호의 채널은 감소시키는 반면 공간 해상도는 확장하는 형태로 학습하게 된다. 첫 번째 “Deconv block”은 64개의 채널이 32개로 감소하게 되며, 공간 해상도는 채널 정보가 절반으로 감소하는 만큼 2배로 늘어나게 된다. 마찬가지로 두 번째 “Deconv block”에서는 32개의 채널을 16개로 개수를 차츰 줄여나가게 되며, 16채널의 특징값은 적색의 “3x3 conv”을 통하고,최종적으로 청색의 “1x1 conv”을 통해 1채널의 최종 복원 영상 값을 가진다.
3.5 손실 함수
초해상도 복원에서 제안하는 모델의 손실 함수는 총 3개로 구성되어 있으며 각각 복원 영상과 원본 영상의 차를 최소화하는 , 와 의 RIP 를 반영하는 , 의 RIP에 대응하는 ,이다. 학습 시 사용하는 최종 손실 함수는 다음과 같다.
, 은 각 손실 함수의 정규화 상수이고, ,,는 각각 영상 패치 의 크기, 미니배치 수, ISTA-block의 개수이다.
IV. 실험 결과
4.1 측면 주사 소나 초 해상도 복원
1) 측면 주사 소나 영상 분석
기존 측면 주사 소나 데이터와 새로 수집하게 된 측면 주사 소나 영상의 총 개수는 291장이며, 영상의 크기는 240x240부터 3005x5140까지 구성되어 있다. 교각, 배 등 물체를 담고 있는 영상은 총 102장으로 해저면 영상과 비율이 비슷하게 분포되어 있다. 테스트 영상은 240x240 크기의 각기 다른 물체를 포함한 20장 영상으로 구성한다. 네트워크 훈련 시 미니배치 집합은 2로 설정하였으며 정규화 상수는 모두 0.01을 사용했다. 실험 코드는 텐서플로를 사용하였으며 Intel Core i7-8700 CPU와 RTX2080Ti GPU를 이용하여 모델을 학습하였다.
4.2 측면 주사 소나 초 해상도 복원 실험 결과
1) ISTA-block 개수에 따른 성능 변화
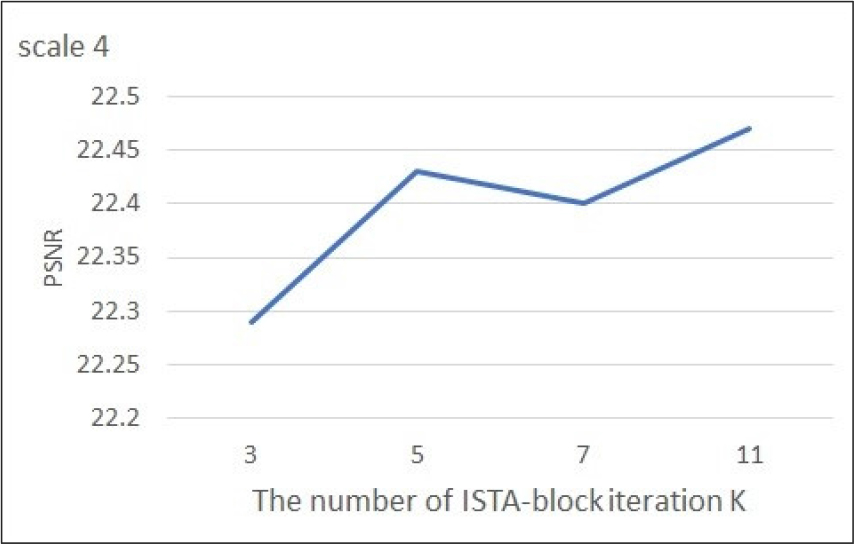
Fig. 5는 ISTA-block 개수 K에 따른 제안 모델의 4배 초 해상도 복원 테스트 결과이다. 테스트 영상은 5개의 측면 주사 소나 영상을 샘플링하여 사용했으며, ISTA-block의 개수가 증가할수록 Peak Signal-to- Noise Ratio(PSNR) 성능이 수렴한다. 성능과 모델의 메모리 사용량 사이의 트레이드-오프를 고려하여 실험에서는 K는 5로 고정하여 실험을 진행한다.
2) 모델 간 비교 검증
Table 1에서는 전통적 초 해상도 복원인 “Bicubic” 보간법, 비 학습기반 압축 센싱 초 해상도 기법(ANRSE,[8] ASDS,[9] RSSC, RSSC-NL[3])과, 학습형 압축 센싱 초 해상도 알고리즘의 테스트 영상의 해상도 별 초 해상도 복원 성능 비교이다. 알고리즘의 성능 측정은 PSNR, Structure Similarity Index Measure(SSIM)[10]실행 시간의 비교를 통해 수행한다. 제안된 방식은 Table 1에서 볼 수 있듯 영상 1개를 초해상도 복원함에 있어 스케일 별 딥러닝 학습방식으로 처리속도가 획기적으로 감소하여 실시간 영상 처리가 가능하며, 전반적으로 SSIM 수치에서 제안한 학습기반 방식이 기존 비 학습 방식보다 우수했다. 또한, 3배 초 해상도 복원에서 기존 방식보다 PSNR,SSIM,실행시간 모두 우수한 성능을 보였다.
Table 1.
A comparison of the super-resolution performance of each resolution in the test image.
3) 모델 간 비교 검증
Table 2에서는 4배 확장에 대한 초기화 방법에 따른 제안된 방법 간 초 해상도 복원 성능을 비교한다. 성능 측정은 PSNR,SSIM의 비교를 통해 수행한다. 기본모델이나 bottle-neck을 적용한 제안 모델보다 SE block을 통한 제안 모델의 성능이 대부분의 이미지에서 더 높은 정량적 결과를 보여 채널 정보가 잘 활용되는 것을 확인할 수 있다.
Table 2.
Comparison of the performance between the different proposed initialization method on scale 4.
4) 측면 주사 소나 초 해상도 복원 출력 영상
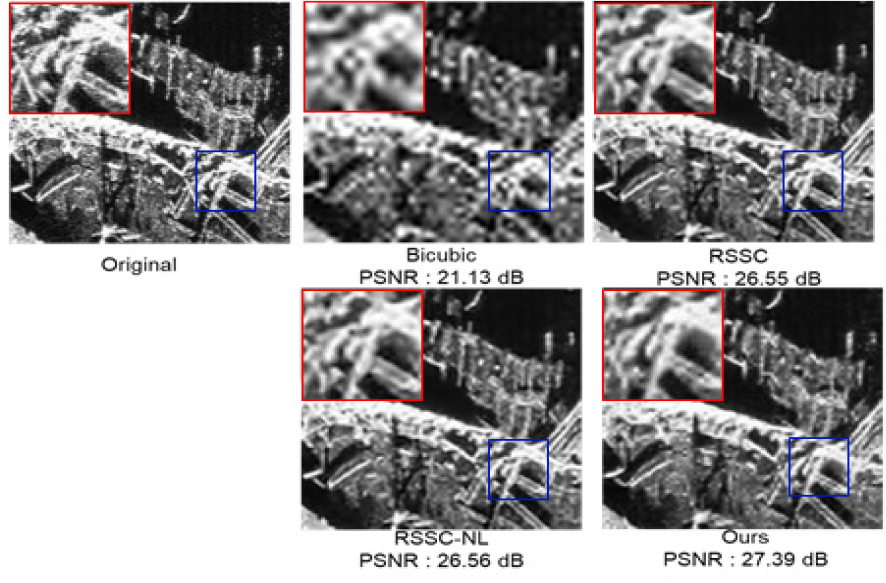
Figs. 6, 7는 3배 초 해상도 복원에 대한 “Bicubic” 보간법과, “RSSC-NL”, “RSSC”, 제안된 모델의 출력 비교 영상이다. 제시된 방법의 영상은 비 학습기반 압축 센싱 초 해상도 알고리즘 및 “Bicubic” 보다 선명하고 식별 가능한 결과를 보여주었으며, PSNR 수치도 우수한 성능을 보인다.

5) 결과 분석
제안 모델은 전통적 압축 센싱 기반 초 해상도 복원 모델과 비교하여 실시간 처리가 가능한 획기적으로 줄어든 실행시간 및 전반적 PSNR,SSIM 의 우수한 수치를 획득했다. 그러나 특정 해상도[스케일(Scale) 4, 5]의 경우는 기존 모델보다 소폭 저하되는 모습을 보인다. 채널 변화 실험에서 스케일 3에서는 PSNR과 SSIM이 채널 수가 늘어날수록 비례 관계를 보이지만, 스케일 5에서는 오히려 줄어드는 경향을 보인다. 이는 25배의 픽셀을 복원해야 하는 스케일 5에서 정보가 늘어남에 따라 학습이 원활히 이루어지지 않는 것으로 보인다. 결과 그림에서 보듯이(Figs. 6, 7) 제안한 모델은 기존 방식보다 선명한 결과 영상을 보인다. 제안 모델은 상대적으로 전반적인 영상의 선명성이 강화되고 있지만, 배경이나 바닥에 대해 스무딩 현상이 부분적으로 확인된다.
