

I. 서 론
II. 베이스라인 시스템
III. 대조 중심 손실 기반 화자 분할
3.1 대조 중심 손실 함수
3.2 SL-SA-EEND with
IV. 실험 및 결과
4.1 데이터베이스
4.2 실험 설정 및 성능 평가 지표
4.3 실험 결과
4.4 임베딩 공간 시각화
V. 결 론
I. 서 론
화자 분할은 다중 발화 환경에서 “누가 언제 발화했는가”를 추론하는 작업으로, 회의록 작성, 콜센터 분석, 미디어 처리 등 다양한 음성 기반 응용 프로그램에서 중요한 역할을 수행한다. 예를 들어, 자동 회의록 작성에서 화자 분할은 화자별 발화를 분리하여 더 체계적이고 직관적인 회의록을 만들 수 있으며, 콜센터 분석에서는 상담원과 고객 간의 대화 패턴을 분리하여 상호작용 패턴을 이해하는 데 사용될 수 있다. 또한, 최근 멀티미디어 콘텐츠의 증가와 함께 대규모 음성 데이터를 효율적으로 처리하기 위한 화자 분할 기술의 필요성이 점차 증가하고 있으며, 이에 따라 사용자 경험을 개선하고자 하는 요구 또한 증가하고 있다. 이러한 배경에서 화자 분할 성능 향상은 주요 연구 주제 중 하나로, 정확한 시스템 품질을 위해 성능 향상이 요구된다.
전통적인 화자 분할 시스템은 주로 클러스터링 기반으로 작동하며, 음성 활동 감지 및 화자 임베딩 추출기와 같은 여러 모듈로 구성된다. 이러한 시스템은 먼저 음성 활동 감지를 통해 묵음 구간을 제거하고 x-vector 및 d-vector와 같은 화자 특징을 추출한다.[1,2,3] 최종적으로 화자 라벨을 얻기 위해 계층적 클러스터링(Agglomerative Hierarchical Clustering, AHC) 또는 spectral clustering을 사용하여 화자 분할을 진행한다.[4,5,6,7] 하지만 위와 같은 화자 분할 방식은 여러 화자가 발화한 중첩 구간에 대해 예측하기 어렵다는 단점과 여러 모듈을 한 번에 최적화할 수 없다는 단점이 존재한다.
이러한 문제를 해결하기 위해 심층 신경망 기반의 종단 간 화자 분할 시스템이 제안되었다.[8,9,10] 종단 간 화자 분할 시스템은 원시 오디오 데이터를 입력으로 받아 화자별 발화 구간을 직접 예측한다. 종단 간 화자 분할 모델 중 Self-Attentive End-to-End Neural Diarization(SA-EEND)[10]은 트랜스포머 인코더 구조를 통해 효과적인 화자 분할 성능 향상을 달성한 대표적인 화자 분할 모델 중 하나이다. SA-EEND 모델을 기반으로 여러 후속 연구들이 개선을 모색하고 있으며,[11,12,13] 그 중 SA-EEND의 임계값 의존성 문제를 해결하며 성능 향상을 도모하는 Single-Label(SL)-SA- EEND[13] 연구가 진행되었다. SL-SA-EEND는 단일 라벨 분류 메커니즘을 통해 SA-EEND의 임계값 의존성을 완화하면서 향상된 화자 분할 성능을 보였다.
본 논문에서는 화자 분할 성능을 더욱 향상시키기 위해 대조 중심 손실 함수[14]를 SL-SA-EEND 모델에 적용하는 방법을 제안한다. 대조 중심 손실 함수는 동일 클래스 간 거리를 최소화하고 다른 클래스 간 거리를 최대화하여 변별력 있는 임베딩 공간을 유도할 수 있게 설계된 손실 함수이다. 따라서 대조 중심 손실 함수를 SL-SA-EEND에 적용하여 더 변별력 있는 임베딩 공간을 구축하고, 모델이 견고한 표현을 학습할 수 있도록 하는 것을 목표로 한다. 학습 초기 단계에서 손실 함수를 적용하면 과적합에 의한 성능 저하가 발생할 수 있음을 발견하여, 가중치를 점진적으로 증가시키는 방법을 적용하였다.
본 연구는 다중 발화 환경에서 클래스 간의 특징을 더욱 명확하게 구별하는 접근 방식을 제안하며, SA-EEND 및 SL-SA-EEND와 같은 기존 화자 분할 시스템보다 향상된 성능을 보여준다. 또한, 본 연구의 방법은 Domain-adaptation을 통해 다른 데이터셋에서도 성능 향상을 보여 다양한 다중 발화 음성 데이터로의 일반화 가능성을 나타낸다.
II. 베이스라인 시스템
본 연구에서는 SL-SA-EEND[13]를 베이스라인 시스템으로 설정하였다. SL-SA-EEND는 다중 라벨 분류 방식의 SA-EEND[10] 모델을 단일 라벨 분류 방식으로 개선한 화자 분할 시스템이다. SA-EEND는 Eq. (1)에서 정의된 바와 같이 화자 분할을 수행한다. 은 번째 프레임에서 번째 화자 발화에 대한 확률 값으로 ≥𝜃 조건을 만족하면 1, 그렇지 않으면 0으로 두어 발화 여부를 표기한다.
하지만 이러한 다중 라벨 기반 시스템은 화자 분할 성능이 임계값(𝜃)에 의존한다는 한계를 가진다. 이 문제를 해결하기 위해 SL-SA-EEND가 제안되었으며 모델 구조는 Fig. 1과 같다.
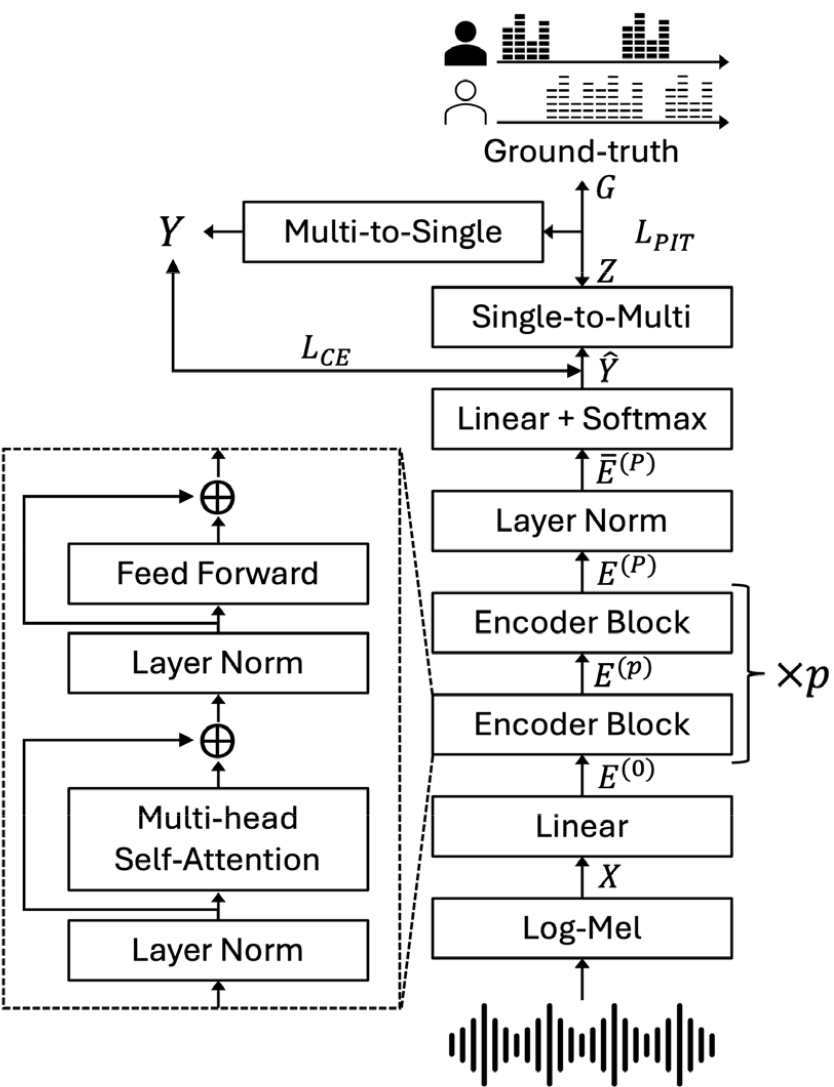
SL-SA-EEND는 시간 영역의 다중 발화 데이터를 입력으로 받아 로그-멜 스펙트럼을 통해 시간-주파수 영역의 로 변환한다. 와 는 각각 시간 축과 주파수 축에 대한 차원을 의미한다. 시간-주파수 영역으로 변환된 스펙트럼은 다음의 수식과 같이 변환되며 각 수식에 대한 설명은 Fig .1에 표기된 값과 동일하다.
Eq. (2)는 의 선형 변환을 나타내고, Eq. (3)은 번째 인코더 블록을 통한 인코딩 과정 설명하며, 여기서 는 1부터 까지의 범위를 가진다. 수식에서 는 모델의 은닉 차원을 의미하며 최종 인코더 출력은 화자 분할 추론을 위해 아래와 같이 변환된다.
Eq. (4)의 는 Eq. (3)의 마지막 인코더 블록의 최종 출력 에 LayerNorm을 적용하여 얻는다. 이어서 를 차원 공간으로 변환한다. 은 총 화자 수를 나타내며, 최종적으로 softmax 함수를 적용하여 단일 라벨 추론을 수행한다.
SL-SA-EEND의 출력은 단일 라벨 형식이며, 정답(Ground-truth)도 단일 라벨 형식이어야 한다. 하지만 SL-SA-EEND의 출력 형식과 달리 Ground-truth는 다중 라벨 형식이기에, 선행연구[13]에서는 이러한 라벨 형식을 맞추기 위해 아래와 같은 과정을 거친다.
Eqs. (6)과 (7)에서 는 화자 집합을 나타내고, 는 의 멱집합을 나타낸다. Eq. (7)에서 ∅은 침묵을 나타내고, 는 동시 발화를 나타낸다. 위와 같은 멱집합 과정을 통해 다중 라벨 형태를 단일 라벨 형태로 변환할 수 있다. 이 과정은 Fig. 1에 표시된 Single-to-Multi 및 Multi-to-Single 단계를 통해 계산된다. SL-SA-EEND의 출력인 에 Single-to-Multi를 적용하고 Ground-truth와 비교하여 를 계산한다. 는 Permutation Invariant Training(PIT)[8]을 의미하며 화자들의 모든 순열에 대해 손실 함수가 최소가 되는 올바른 순열을 제공한다. 이때 PIT를 통해 얻은 라벨에 Multi-to-Single을 적용하여 단일 라벨 형태로 변환하고, SL-SA-EEND가 예측한 과 (Cross Entropy Loss) 연산을 수행하여 단일 라벨 형태에서의 손실을 계산한다. 최종적으로 SL-SA-EEND 모델에서의 전체 손실 함수는 Eq. (8)과 같이 계산되었으며 이 과정에 대한 자세한 내용은 선행연구[13]에 제공되어 있다.
III. 대조 중심 손실 기반 화자 분할
본 논문에서는 화자 분할 성능 향상을 위해 대조 중심 손실 함수[14]와 결합된 SL-SA-EEND 모델을 제안한다. SL-SA-EEND 모델은 최적의 결정 경계를 찾아 화자 분할을 수행하며, 각 프레임에 대해 Eq. (7)의 라벨 중 하나를 예측한다. 정확한 결정 경계를 찾는 과정도 중요하지만, 모델이 변별력 있는 임베딩 표현을 학습하는 것 또한 중요하다. 이를 위해 대조 중심 손실 함수를 SL-SA-EEND 모델에 적용하여 각 클래스에 대해 더 변별력 있는 표현을 학습할 수 있도록 한다. 실험 결과를 통해 제안된 방법이 화자 분할에서 기존 모델보다 향상된 성능이 나타남을 관찰할 수 있었다.
3.1 대조 중심 손실 함수
대조 중심 손실 함수는 데이터 군집화를 강화하고 클래스 간의 변별력을 높이는 역할을 수행한다. 이 손실 함수는 동일 클래스 내 응집성을 촉진하고 서로 다른 클래스 간 분리성을 증가시켜 더 변별력 있는 임베딩 공간을 형성한다. 대조 중심 손실 함수 ()는 다음과 같이 정의한다.
Eq. (9)에서 는 프레임 인덱스를 나타낸다. 분자의 수식에서 는 Eq. (4)의 번째 프레임의 값을, 는 번째 프레임에 해당하는 라벨 의 중심 값을 의미한다. 두 명의 화자가 존재하는 다중 발화 데이터에 대해 는 Eq. (7)의 값 중 하나를 가지며, 이때 는 Eq. (10)으로부터 에 대응되는 중심 값으로 정의된다.
는 와 동일한 벡터 차원을 가지며 분자에서 두 값의 차이에 대한 L2 Norm을 계산한다. 분모의 경우, 는 클래스의 개수를 의미하며 조건을 통해 는 를 기준으로 서로 다른 클래스의 중심 값을 가지게 된다. 따라서 Eq. (9)의 분자는 동일한 클래스 간 거리, 분모는 서로 다른 클래스 간 거리 계산을 수행한다. 손실 함수가 분수 형태로 정의되는 경우, 그 값이 감소하기 위해서는 분자의 값은 감소하고 분모의 값은 증가해야 한다. 이를 통해 Eq. (9)의 손실 함수는 동일한 임베딩에 대응되는 클래스의 중심으로 당겨 클래스 내 응집성을 촉진하는 동시에, 임베딩을 서로 다른 클래스 중심으로부터 밀어내어 클래스 간 분리성을 학습하게 한다.
3.2 SL-SA-EEND with
본 논문에서 제안하는 방법의 구조는 Fig. 2와 같다. 기존 SL-SA-EEND 구조의 LayerNorm과 Linear + Softmax 사이 단계에 Eq. (10)의 클래스 별 중심 값을 두고 LayerNorm에서 출력된 와 대조 중심 손실 함수를 계산한다. 에 대조 중심 손실 함수를 적용하여 분류 단계에서 사용할 임베딩을 직접적으로 개선한다. 손실 함수는 훈련 과정에서 감소하는 방향으로 학습을 진행한다. 대조 중심 손실 함수에서 분자는 동일한 클래스의 중심 값과 L2 Norm을 계산하며, 분모는 서로 다른 클래스의 중심 값과 L2 Norm을 계산한다. 따라서 모델은 대조 중심 손실 함수를 통해 각 클래스에 대한 변별력 있는 표현을 효과적으로 학습할 수 있게 되며 Fig. 3의 와 같은 임베딩 공간을 유도할 수 있다.

Fig. 2.
(Color available online) SL-SA-EEND with . The definition of class centers in Fig. 2 is as in Eq. (10).

의 경우 MNIST 데이터셋을 사용한 실험에서 훈련 초기 단계부터 사용하는 것이 효과적이라고 알려져 있다.[14] 그러나 화자 분할에서 는 학습 초기에 불안정한 학습을 초래할 수 있다. 0-9까지의 숫자가 안정적인 패턴을 가지는 MNIST와 같이 잘 정의되고 일관된 클래스 특징을 가진 데이터셋과 달리, 화자 분할은 더 가변적이고 일관적이지 않은 특징을 포함한다. 예를 들어, 화자별 특징(성별, 억양, 발음)은 동일한 클래스(화자1, 화자2)라도 샘플에 따라 크게 달라지는 경우가 존재한다. 이러한 가변성은 불안정한 임베딩 분포로 이어지며, 이는 훈련 초기에 의 효과적인 적용을 방해하는 요인이 된다.
이 문제를 해결하기 위해, 불안정한 분류 성능의 초기 단계에서 의 가중치를 낮게 설정했다. 학습이 진행됨에 따라 분류 성능이 안정화되면서 가중치를 점진적으로 증가시켰고, 이 접근 방식을 통해 초기 불안정한 학습 문제를 해결하였고, 안정적으로 모델에 를 적용하였다. 이 문제를 반영하여 제안된 방법의 손실 함수는 아래와 같다.
훈련이 진행됨에 따라 Eq. (11)의 𝛼값은 현재 에포크와 총 에포크의 비율로 정의되며, 점진적으로 증가한다. 제안된 방법은 Eq. (11)의 𝛼를 Eq. (12)의 와 곱한다. 여기서 의 가중치는 분류 성능이 불안정한 초기 단계에서는 낮게 설정하고, 학습이 진행됨에 따라 분류 성능이 안정화되면서 점진적으로 증가시킨다. 이를 통해 화자 분할에서 발생하는 일관적이지 않은 특징 문제와 과적합 문제를 완화하여 효과적인 훈련을 가능하게 한다.
IV. 실험 및 결과
4.1 데이터베이스
2명의 화자가 존재하는 다중 발화 데이터 생성을 위해 Librispeech 데이터베이스[15]를 사용하였으며, 잡음 환경 구성을 위해 MUSAN[16] 데이터베이스를 사용하였다. Room Impulse Responses(RIR)은 선행연구[17]에서 사용된 Simulated Room Impulse Responses 데이터베이스의 10,000개 필터로 구성된다. 잡음 환경의 Signal-to-Noise Ratio(SNR) 값은 5 dB, 10 dB, 15 dB, 20 dB에서 무작위로 샘플링되었고, RIR 필터는 생성된 잡음 데이터에서 50 % 확률로 무작위로 선택되어 적용되었다. 위와 같이 두 명의 다중 발화 환경을 인위적으로 제작한 데이터베이스를 Simulated 데이터라고 부르며, 이러한 방식은 SA-EEND가 제안한 알고리즘[10]을 통해 생성되었다. 각 화자 별 발화 개수는 최소 5개에서 최대 10까지 선택 될 수 있게 선택하였으며, 발화 중첩 구간 비율이 34 %가 되도록 설정하여 생성하였다. Simulated 데이터셋은 훈련 데이터가 100,000개, 검증 및 테스트 데이터셋은 각각 500개가 되도록 생성하였다.
Simulated 환경뿐만 아니라, 실제 다중 발화 환경에서 화자 분할 성능 평가를 수행하기 위해 CALLHOME 데이터셋[18]을 사용하였다. CALLHOME은 약 13 %의 발화 중첩 비율을 가진다. CALLHOME Part 1의 155개 샘플 중 총 116개가 훈련에 사용되었고, 39개 샘플이 검증에 사용되었으며, CALLHOME Part 2의 148개의 샘플이 테스트에 사용되었다.
4.2 실험 설정 및 성능 평가 지표
Simulated 데이터셋과 CALLHOME 데이터셋 모두 8 kHz로 설정하였으며, 입력 특징으로는 25 ms 프레임 길이와 10 ms 프레임 이동 간격으로 추출한 23차원 로그-멜 필터 뱅크(log-Mel filter bank)를 사용하였다. 각 특징은 이전 7 프레임과 이후 7 프레임의 특징과 결합되었다. 결합된 특징은 신경망이 긴 오디오 시퀀스를 처리할 수 있도록 10배 간격으로 다운샘플링(subsampling) 하였다.
본 실험 설정에서 사용된 SA-EEND 기반 모델은 4개의 인코더 블록(=4)을 사용하며, 각 블록은 256개의 어텐션 유닛과 4개의 헤드로 구성된다. feed- forward 네트워크는 1,024개의 유닛으로 구성되었으며, optimizer는 25,000 warmup steps에 의해 학습률이 조정되는 Adam을 사용하였다. 배치 크기는 16으로, 학습 에포크 수는 100으로 설정하였다. 학습 종료 후 마지막 10개의 에포크에서 생성된 모델 파라미터를 평균 내어 최종 모델을 구성하였다.
Domain-adaptation을 위해, Simulated로 학습된 모델은 CALLHOME 데이터셋을 사용해 재학습을 진행하였다. Adam optimizer의 학습률은 10–5으로 설정되었으며, 이 외의 훈련 설정은 Simulated와 동일하다. 또한, 실험을 위해 중심점 값은 Simulated 데이터에서 학습된 중심점을 사용하여 초기화를 진행하였다.
화자 분할 평가 지표로 Diarization Error Rate(DER)[19]를 사용하였다. DER은 Miss(MI), False Alarm(FA), Confusion Error(CF)로 구성된다. MI는 실제 음성 구간이 비음성으로 잘못 예측될 때 발생하고, FA는 비음성 구간이 음성 구간으로 잘못 예측할 때 발생하며, CF는 화자가 잘못 할당될 때 발생한다. 이 실험에서 DER 평가를 위한 칼라 허용 오차는 0.25 s로 설정하였으며, 중앙값 필터는 적용하지 않았다.
4.3 실험 결과
기존 SA-EEND 모델을 활용하여 다중 라벨 분류 문제로 화자 분할을 수행하고, 임계값에 따른 성능 변화를 관찰하기 위해 Tables 1, 2와 같은 실험을 진행하였다. 각 Table의 𝜃는 Eq. (1)의 𝜃에 해당한다. 𝜃에 따라 Simulated 데이터셋에서 최대 1.46 % 포인트, CALLHOME 데이터셋에서 최대 3.26 % 포인트의 성능 변화가 관찰되었다. 이러한 결과는 𝜃에 따른 성능 변화를 보여주며 𝜃=0.5에서 최적의 성능이 달성됨을 확인할 수 있다.
Table 1.
The DER (%) performance of SA-EEND model on the Simulated dataset across various threshold.
| Threshold 𝜃 | MI | FA | CF | DER |
| 0.3 | 2.93 | 5.75 | 0.53 | 9.21 |
| 0.4 | 3.74 | 3.61 | 0.73 | 8.08 |
| 0.5 | 4.67 | 2.23 | 0.84 | 7.75 |
| 0.6 | 5.93 | 1.44 | 0.76 | 8.12 |
| 0.7 | 7.36 | 0.92 | 0.63 | 8.91 |
Table 2.
The DER (%) performance of SA-EEND model on the CALLHOME dataset across various threshold.
| Threshold 𝜃 | MI | FA | CF | DER |
| 0.3 | 4.93 | 11.32 | 2.21 | 18.45 |
| 0.4 | 6.35 | 6.92 | 3.00 | 16.28 |
| 0.5 | 8.15 | 4.06 | 3.49 | 15.70 |
| 0.6 | 11.04 | 2.59 | 3.21 | 16.84 |
| 0.7 | 14.68 | 1.67 | 2.62 | 18.96 |
Tables 3과 4에서는 본 논문에서 제안하는 방법(SL-SA-EEND with )의 성능 평가 결과를 다른 모델과 비교하여 나타낸다. SA-EEND는 위에서 설명한 다중 라벨 분류 문제에 기반하여 화자 분할을 수행하는 모델로, 표는 𝜃=0.5에서 최적 성능을 기준으로 작성하였다. SL-SA-EEND는 단일 라벨 분류 기법을 적용한 화자 분할 모델로, 본 논문의 베이스라인 모델로 사용된 모델이다. Table 4의 pyannote[20,21]는 오픈 소스 화자 분할 시스템을, v3.1은 모델 버전을 나타낸다. SL-SA-EEND with 는 본 논문에서 제안하는 방법을 나타낸다.
Table 3.
Evaluation results based on DER (%) for the Simulated Dataset.
| Model | MI | FA | CF | DER |
| SA-EEND (𝜃=0.5) | 4.67 | 2.23 | 0.84 | 7.75 |
| SL-SA-EEND | 2.81 | 1.79 | 0.96 | 5.56 |
| SL-SA-EEND with | 1.82 | 1.24 | 1.08 | 4.14 |
Table 4.
Evaluation results based on DER (%) for the CALLHOME Dataset.
| Model | MI | FA | CF | DER |
| pyannote (v3.1) | 10.92 | 2.47 | 5.21 | 18.60 |
| SA-EEND (𝜃=0.5) | 8.15 | 4.06 | 3.49 | 15.70 |
| SL-SA-EEND | 5.97 | 3.05 | 4.43 | 13.46 |
| SL-SA-EEND with | 5.88 | 2.83 | 3.15 | 11.86 |
Table 3의 Simulated 데이터셋 실험 결과에 따르면, 제안된 방법의 DER은 4.14 %인 반면, SA-EEND 및 SL-SA-EEND 모델의 DER은 각각 7.75 % 및 5.56 %로 나타났다. 이는 제안된 방법이 기존 화자 분할 방법 보다 성능이 향상되었음을 확인할 수 있으며 SL- SA-EEND 대비 25.53 %의 상대적인 개선을 보였다. CF의 경우 오류율이 소폭 향상된 것을 확인할 수 있으나 이는 MI, FA의 감소를 위한 트레이드 오프로 볼 수 있다. 또한, Table 4의 CALLHOME 데이터셋 실험 결과에 따르면, 제안된 방법의 DER은 11.86 %로 다른 화자 분할 모델들보다 DER 성능이 향상된 것을 확인할 수 있다. CALLHOME 데이터셋 결과의 경우 제안하는 방법이 SL-SA-EEND 대비 11.88 %의 상대적 개선을 보였다.
4.4 임베딩 공간 시각화
적용 효과를 분석하기 위해 Fig. 4과 같이 임베딩 공간을 시각화했다. 시각화를 위해 사용된 모델은 4.2절의 설정과 동일하다. 시각화 공간은 Eq. (4)의 이며, 각 번째 프레임의 256차원 임베딩은 t-SNE를 사용하여 2차원으로 축소되었다. Fig. 4에서 회색은 침묵을, 파란색은 화자1, 초록색은 화자2, 빨간색은 중첩 발화를 나타낸다. 각 색상의 “X” 표시는 에 의해 학습된 각 클래스의 중심 값을 나타내며 SL-SA-EEND는 를 적용하지 않았음으로 “X” 표시가 나타나지 않는다.

Fig. 4.
(Color available online) Visualization of embedding spaces with and without . (a) and (b) show the results on simulated dataset, (c) and (d) show the results on CALLHOME. Gray, blue, green, and red plots represent silence, speaker 1, speaker 2, and overlapping speech respectively. The “X” symbols of each color represent the center values learned by .
Fig. 4에서 를 적용한 임베딩 공간이 그렇지 않은 경우보다 클래스 간 변별력이 향상되었음을 관찰할 수 있다. Simulated 데이터셋에서 를 적용함으로써 임베딩이 각 화자 중심 주위에 클러스터링 되어 클래스 간의 명확한 분리를 확인할 수 있다. CALLHOME 데이터셋에서도 유사한 경향이 관찰되었으며, 제안된 방법을 적용했을 때 클래스 사이에 더 명확하게 분리되는 것이 관찰되었다.
V. 결 론
본 논문에서는 SL-SA-EEND 모델에 대조 중심 손실함수()를 적용하여 향상된 화자 분할 성능 시스템을 제안하였다. 는 모델이 훈련 과정에서 각 클래스에 대해 더 변별력 있는 표현을 학습할 수 있도록 하였다. 결과적으로, 제안된 방법은 베이스라인 대비 Simulated 데이터셋에서 25.53 %, CALLHOME 데이터셋에서 11.88 %로 화자 분할 성능을 개선하였다. 향후 연구에서는 더 넓은 범위의 다중 발화 시나리오를 처리하기 위해 제안된 방법을 3명 이상의 화자를 포함하는 다중 발화 환경으로 확장하는 방안에 관해 연구하고자 한다.
