

I. 서 론
II. 문제설정: 능동소나 표적식별
III. 능동소나 데이터세트
IV. 능동소나 표적식별기 설계
4.1 능동소나 표적식별기 신경망 모델
4.2 능동소나 표적식별기 학습방법
V. 실 험
5.1 실험 환경
5.2 성능평가지표
5.3 실험 결과 및 분석
VI. 결 론
I. 서 론
능동소나 시스템(Active Sonar System)은 음파를 사용하여 펄스 신호를 수중으로 송신하고, 수신된 신호를 분석하여 표적을 탐지, 추적한다. 이때 수신된 신호에는 인공적인 물체인 표적으로부터 반사된 표적 반향음(Target Echo) 외에 해저면, 해수면, 수중생물 등과 같은 자연적인 산란체에 의해서 반사된 클러터(Clutter) 신호도 함께 수신된다. 일반적인 능동소나 시스템은 수신된 신호를 송신 신호의 복제(Replica)와 정합(Correlation)하는 정합필터(Matched Filter)를 탐지기로 사용하는데, 이러한 클러터 신호는 표적 반향음과 유사한 전파 특성을 가지기 때문에 정합률이 높아서 표적 반향음과 마찬가지로 큰 첨두치(Peaks)를 발생시킨다. 클러터로 인한 높은 첨두치는 오탐지율(False Alarm Rate)를 높이기 때문에 능동소나 시스템의 성능을 저하한다. 이를 해결하기 위해서는 탐지된 신호의 특성을 다양한 관점에서 분석하여 표적과 클러터를 구분할 수 있는 표적식별기가 필요하다.[1,2,3,4,5,6]
지난 수십 년 동안 능동소나 시스템에서 탐지된 표적을 식별하기 위해 기계학습(Machine Learning) 기반의 연구가 이루어졌다. Gorman과 Sejnowski[3]은은 사질 해저면에 위치한 금속 실린더와 실린더 형태의 바위를 구분하기 위해서 정규화된 주파수 스펙트럼의 포락선을 입력으로 하는 얕은 신경망을 설계하여 실험하였다. Murphy와 Hines[4]는 인공적인 물체를 표적으로 정의하고 데이터를 수집한 후에 이로부터 사람의 청각 시스템을 모사한 청각적인 특징 인자를 추출하고 가우시안 기반 식별기에 적용하여 표적과 클러터를 식별하는 연구를 수행하였다. Seo et al.[5]은 거리-방위 영역에서 크기에 따른 다층적인 특징 인자를 추출하고 이를 서포트벡터머신(Support Vector Machine)에 적용하여 능동소나 표적을 식별하였다. Sun et al.[6]은 Fisher Discriminant 기준과 Dictionary Learning을 결합한 능동소나 표적식별기를 제안하였다.
최근 심층신경망(Deep Neural Networks) 기반의 딥러닝(Deep Learning)이 급격히 발전하여 영상 및 음성 인식, 자율주행, 자연어 처리 등 다양한 분야에서 성공적으로 적용되고 있으며, 기존에 각 분야에서 연구된 최고 성능의 기법을 능가하는 성능을 보여주고 있다.[7,8,9,10,11] 따라서 능동소나 표적식별 문제에도 딥러닝을 적용하려는 시도가 빠르게 증가하고 있다. Magistris et al.[12]과 Lee et al.[13]은 Convolutional Neural Networks(CNN) 기반의 능동소나 표적식별기를 연구하였으며, 각각 스펙트로그램과 Power-Normalized Cepstral Coefficients을 입력으로 사용하였다.
한편 비용 등의 문제로 다양한 환경에서 능동소나 시스템을 이용하여 실험을 수행하기 어렵고, 전체 탐색 면적 내에서 표적이 차지하는 부분이 작기 때문에(대부분 표적이 아님) 능동소나 데이터세트는 데이터 샘플의 수가 소량이고 표적과 클러터 부류(Class) 간에 불균형(Imbalanced)한 특성을 가진다. 따라서 일반적으로 심층신경망을 학습하기 위해서 사용되는 지도학습(Supervised Learning)은 능동소나 데이터세트의 특성을 고려할 때 적합하지 않다. 이를 해결하기 위해서 Chen et al.[14]은 적대적생성신경망을 이용한 데이터 증강 기법을 연구하였으며, Stinco et al.[15]은 비지도학습을 이용한 능동소나 표적식별기를 연구하였다. 최근 Kim과 Choo[16]은 표적과 클러터가 내재 공간(Latent Space)에서 클러스터를 형성하는 것을 고려한 Bi-Sphere Anomaly Detection을 제안하였다.
현재까지 딥러닝 기반의 능동소나 표적식별기에 대해 다양한 관점에서 연구가 진행되고 있으나 연구의 방향성이 제각각이며, 신경망의 수용력(Capacity) 혹은 학습 방법론 등에 따른 성능 변화의 일관성을 확인하기 어렵다. 또한 소량에 불균형적인 능동소나 데이터세트의 특성 때문에 기존에 다른 연구 분야에서 성공적으로 적용된 딥러닝 구조를 능동소나 표적식별 문제에 적용하더라도 우수한 성능을 장담할 수 없다.
본 논문에서는 향후 능동소나 표적식별 연구의 방향성을 제시하기 위해서 소량의 능동표적 데이터세트에서 다양한 딥러닝 구조에 대한 광범위한 연구를 수행한다. 현재까지 이와 같은 주제로 연구된 사례는 없었으며, 최초로 시도되는 연구이다. 딥러닝은 심층신경망을 이용한다는 공통점이 있을 뿐 광범위한 분야를 다루기 때문에 딥러닝의 모든 분야에 대해서 분석하는 것은 어렵다. 따라서 본 논문에서는 시간-주파수 영역의 입력을 사용하고 표적과 클러터 두 가지 분류를 구분하는 CNN 구조로 연구 대상을 한정하였으며, 이때 학습 방법은 지도학습으로 한정하였다.
본 논문의 구성은 다음과 같다. 1장의 서론에 이어서 2장에서는 문제를 설정하고, 3장에서는 능동소나 데이터세트를 생성하는 방법과 특성을 분석한다. 4장에서는 연구에 활용할 CNN 기반의 능동소나 표적식별기와 초매개변수 최적화를 위한 베이지안 최적화를 소개한다. 5장에서는 실험 방법과 결과를 제시하고 분석한다. 6장에서는 본 연구의 의의와 향후 연구 방향을 제시하면서 본 논문을 마무리한다.
II. 문제설정: 능동소나 표적식별
Fig. 1에 능동소나 시스템의 송수신 환경에 대해서 나타내었다. 소나 플랫폼의 송신기에서 송신된 펄스 신호는 잠수함과 같은 인공적인 표적 외에도 물고기 떼(Fish School), 해수면, 해저면 등과 같은 자연적인 산란체에서 반사되어 배열센서로 수신된다. 수신되는 신호는 Fig. 2에 나타낸 것과 같이 빔형성(Beamforming)을 통해 특정 방향에 대한 빔 신호(Beam Signal)로 변환되며, 일반적으로 빔 신호에 대해서 정합필터 기반의 탐지가 수행된다. 탐지 이후 능동소나 시스템은 거리-방위에 대한 크기 기반의 정보를 획득할 수 있다.[1,17,18]
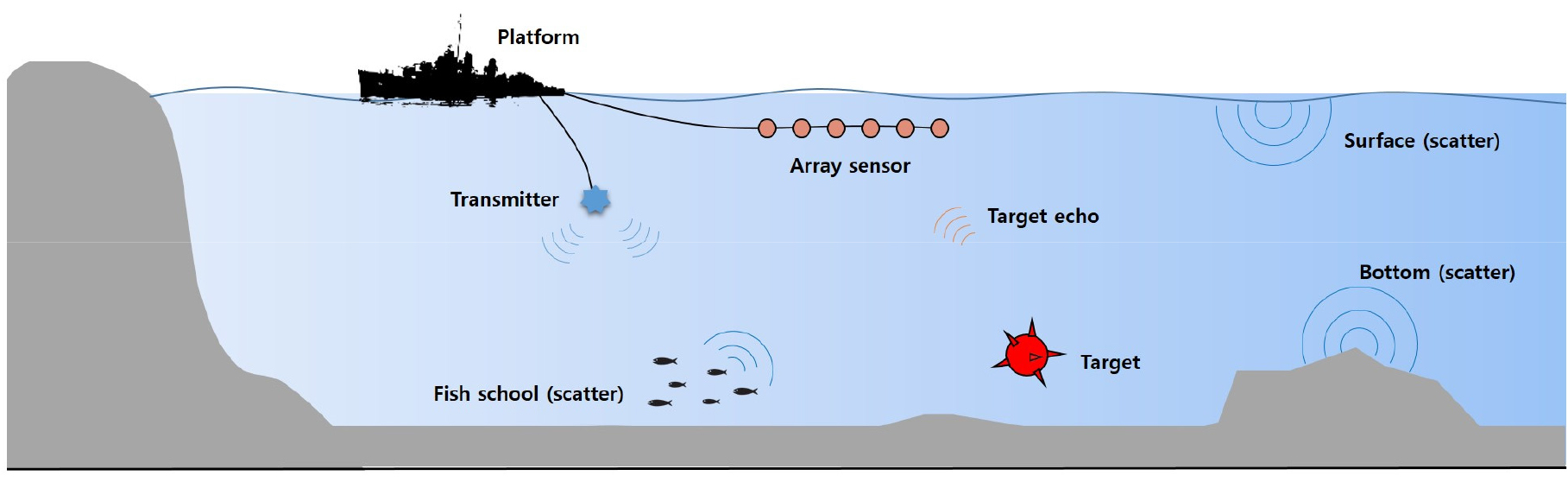
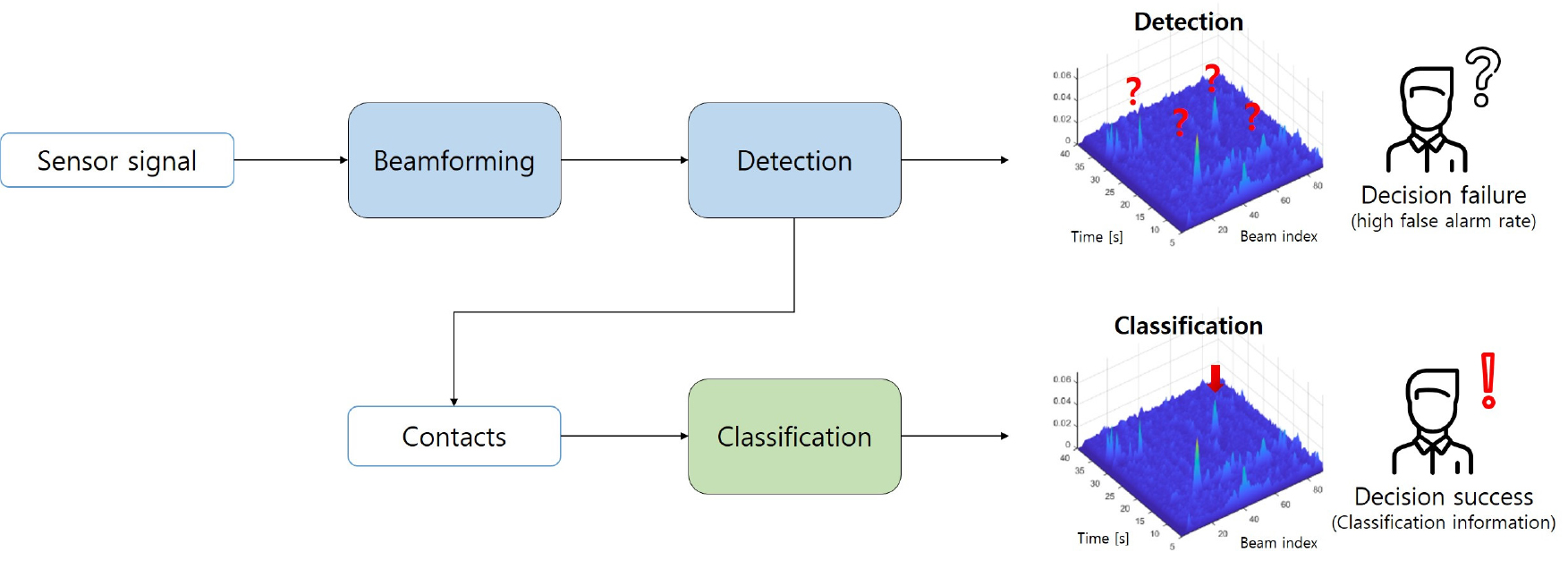
그러나 Fig. 2에 나타낸 것과 같이 표적에서 반사되어 수신되는 표적 반향음과 그 외의 물체에서 반사되어 수신되는 클러터 신호는 유사한 물리적인 전파 특성을 가지기 때문에 탐지 결과에서 이를 구분하는 것이 어렵다. 따라서 탐지 이후에 클러터로 인한 다수의 첨두치가 발생하게 되며, 이로 인해 능동소나 시스템의 성능이 저하된다.
능동소나 시스템은 이러한 문제를 해결하기 위해서 탐지 과정 이후에 표적과 클러터를 구분할 수 있는 표적식별 과정이 필수적이다. 탐지 이후 일정 문턱값(Threshold) 이상의 첨두치 결과를 표적일 가능성이 있는 접촉(Contacts) 신호로 판단할 수 있으며, 별도의 식별 알고리즘을 이용하여 접촉 신호가 표적인지 클러터인지 식별하는 것을 일반적인 능동소나 표적식별 과정으로 정의할 수 있다. 탐지기가 우수하여 높은 확률로 표적을 탐지하더라도 이를 클러터와 구분하지 못하면 능동소나 시스템이 성능을 발휘하기 어려우며, 따라서 우수한 성능의 능동소나 표적식별기를 개발하는 것이 필수적이다.
III. 능동소나 데이터세트
딥러닝 기반의 능동소나 표적식별기를 개발하기 위해서는 먼저 데이터세트를 구성해야 한다. 본 연구에서는 동일한 사양의 Linear Frequency Modulated(LFM) 펄스를 사용했지만 서로 다른 시간, 다른 해역에서 수집된 두 가지 빔 신호 데이터를 수집하였다. 첫 번째 실험은 31개의 핑(Ping)을 송신하였고, 두 번째 실험은 23개의 핑을 송신하였다. 이때 수신된 표적 반향음은 표적 반향기를 이용하여 모사된 것이다.
Fig. 3에 수신된 빔 신호를 이용하여 능동소나 데이터세트를 생성하는 과정을 나타내었다. 먼저 수신된 빔 신호는 정합필터에 적용되어 탐지를 수행한다. 수신 잡음의 준위가 변동하기 때문에 정합필터 결과에 동일한 오탐지율에 해당하는 문턱값을 적용하기 위해서 정규화를 수행한다. 일반적으로 탐지기가 적용되는 격자보다 표적의 크기가 클 수 있다. 이 경우 동일한 표적에 대해서 여러 개의 접촉 신호가 나타날 수 있기 때문에 클러스터링 알고리즘을 이용하여 하나의 접촉 신호로 통합하는 과정이 필요하다. 이후 접촉 신호의 거리-방위 색인(Index)를 추출하고, 해당하는 색인을 빔 신호에서 찾아서 오디오 신호를 생성한다.[1,16]
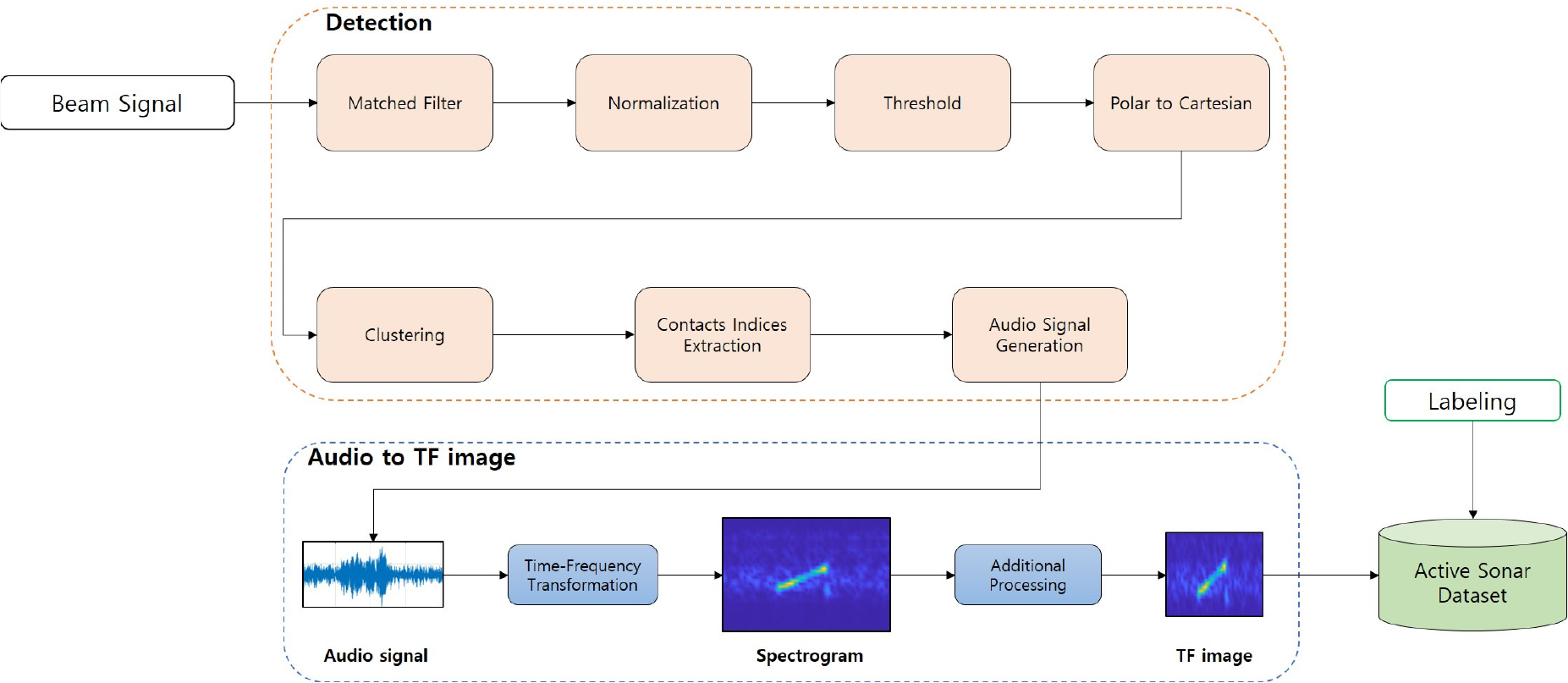
LFM 펄스와 같은 수중음향 신호는 시간에 따라서 주파수가 변화하는 특성을 가진다. 따라서 시간 영역의 신호를 그대로 처리하는 것보다 시간-주파수 영역으로 변환하여 처리하는 것이 효율적이다. 먼저 단시간퓨리에변환(Short Time Fourier Transform, STFT)을 적용하여 오디오 신호를 스펙트로그램으로 변환한다.[19] 이후에 식별기의 입력에 적합하도록 추가적인 처리를 수행한다. 본 논문에서는 세 가지 처리를 적용하였다. 첫 번째로 송신된 LFM 펄스의 길이와 대역폭의 두 배에 해당하는 영역을 스펙트로그램에서 추출하였다. 두 번째로 추출된 영역의 스펙트로그램에 로그를 취하고, Min-Max 정규화를 적용하여 최솟값과 최댓값이 각각 0과 1이 되도록 하였다.[20] 최종적으로 크기를 재조정하여 너비 64, 높이 64의 정사각형 이미지를 만든다. 본 논문에서는 이렇게 생성된 데이터 샘플을 Time-Frequency(TF) 이미지로 명명하였다.
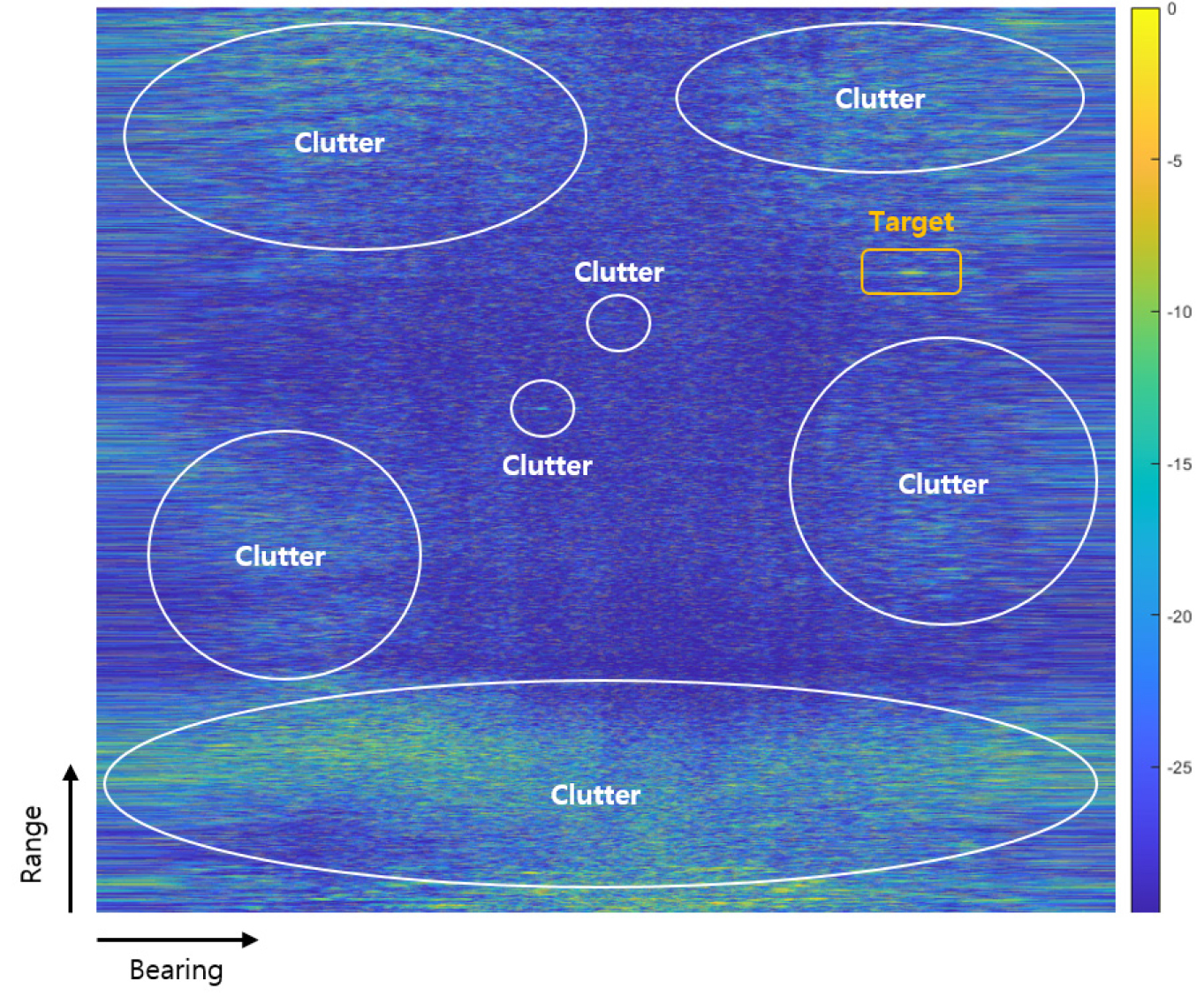
Fig. 4에 수집된 데이터 중 특정 핑에서의 정규화 결과를 나타내었다. 주황색 박스로 표시된 하나의 표적을 확인할 수 있으며, 표적 외에도 첨두치 크기가 높게 나타나는 다수의 클러터 영역을 확인할 수 있다. 클러터는 송신기 근방 해저면에서 반사된 것으로 추정되는 강한 후방산란(Backscattering) 영역 외에도 임의의 영역에서 나타날 수 있다.
수집된 데이터를 이용하여 Fig. 3에서 제시한 능동소나 데이터세트 생성 방법을 적용하였다. 수집된 데이터와 함께 주어진 정보를 활용하여 각 데이터 샘플의 부류를 정해주는 레이블링(Labeling)을 수행하였다. 시간에 따라 이동하면서 트랙을 형성하는 표적을 확인하여 해당 색인에서 추출된 데이터 샘플의 부류를 표적으로 할당하였으며, 표적 반향음 신호가 빔 패턴의 부엽으로 누출되어 나타난 데이터 샘플에 대해서도 부류를 표적으로 할당하였다. Table 1에 생성된 능동소나 데이터세트의 정보를 나타내었다. 31개의 핑을 송신한 첫 번째 실험 데이터에서 생성된 데이터세트는 Dataset A, 두 번째 실험 데이터에서 생성된 데이터세트는 Dataset B로 명명하였으며, 각각 1,645개와 1,656개의 TF 이미지로 구성된다. 일반적인 딥러닝 연구에서 수만 개에서 수십만 개 이상의 데이터 샘플로 구성되는 데이터세트를 사용하는 것에 비해서 능동소나 데이터세트는 데이터 샘플의 수가 절대적으로 적은 것을 확인할 수 있다. 또한, 데이터세트에서 표적이 차지하는 비율은 Dataset A가 4.2 %, Dataset B가 8.1 %로 불균형한 것을 확인할 수 있다. 이는 하나의 핑을 송신할 때 표적 반향음 신호는 하나만 수신되지만, 나머지 영역에서 다수의 클러터가 발생하기 때문이다.
Table 1.
Configuration of two active sonar datasets.
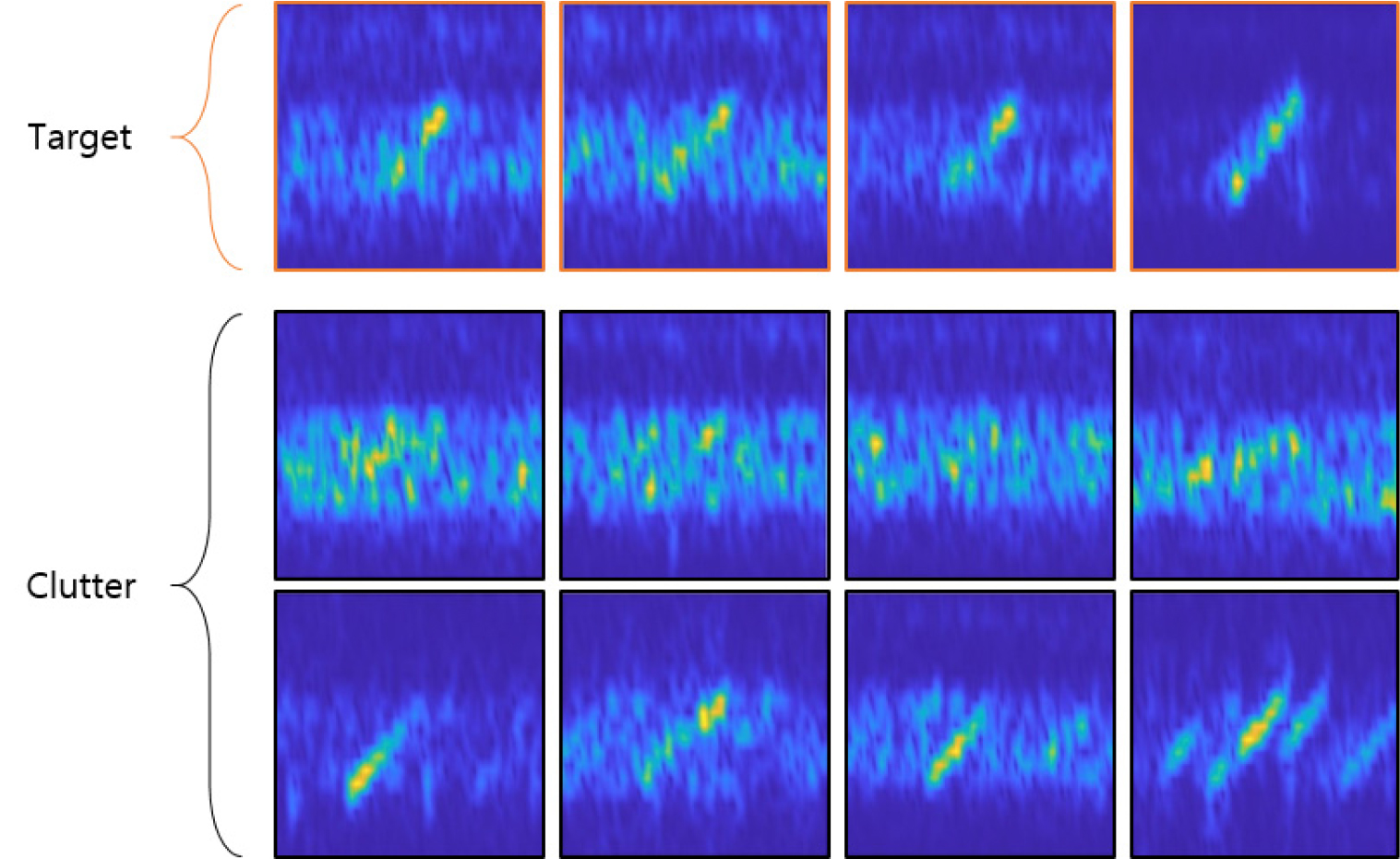
Fig. 5에 생성된 데이터세트에서 임의의 표적 샘플(표적 TF 이미지) 4개와 클러터 샘플(클러터 TF 이미지) 8개를 포함 총 12개를 예시로 제시하였다. 첫 번째 줄의 표적 TF 이미지에서 시간에 따라 선형적으로 변화하는 LFM 펄스의 특성을 확인할 수 있으며, 잡음과 함께 수신되는 것을 확인할 수 있다. 클러터 TF 이미지 중에서 두 번째 줄에 위치한 4개의 샘플은 표적과 확연히 구분되는 특성을 보이지만 세 번쨰 줄에 위치한 4개의 샘플은 표적과 유사한 특성을 보이는 것을 확인할 수 있다.
생성된 데이터세트의 특성을 자세히 분석하기 위해서 고차원의 데이터를 저차원으로 축소하는 데이터 가시화(Data Visualization) 기법 중 하나인 Uniform Manifold Approximation and Projection(UMAP)을 사용하였다.[21]Fig. 6에 두 가지 데이터세트에 포함된 3,301개의 데이터 샘플을 UMAP을 이용하여 2차원으로 축소하여 도시한 결과를 나타내었다. 그림에서 표적보다 클러터의 데이터 분포가 더 광범위하게 나타나는 것을 확인할 수 있는데, 이는 표적 반향기에서 모사되는 표적 반사 신호보다 다양한 산란체에서 반사되어 수신되는 클러터 신호가 변화의 복잡성이 크기 때문이다. 또한, 그림에서 일부 클러터 데이터 샘플이 표적 데이터 샘플과 유사한 곳에 위치한 것을 확인할 수 있는데, 이는 Fig. 5의 세 번째 줄에 위치한 것과 같이 표적과 유사한 특성을 지니는 데이터 샘플이다.
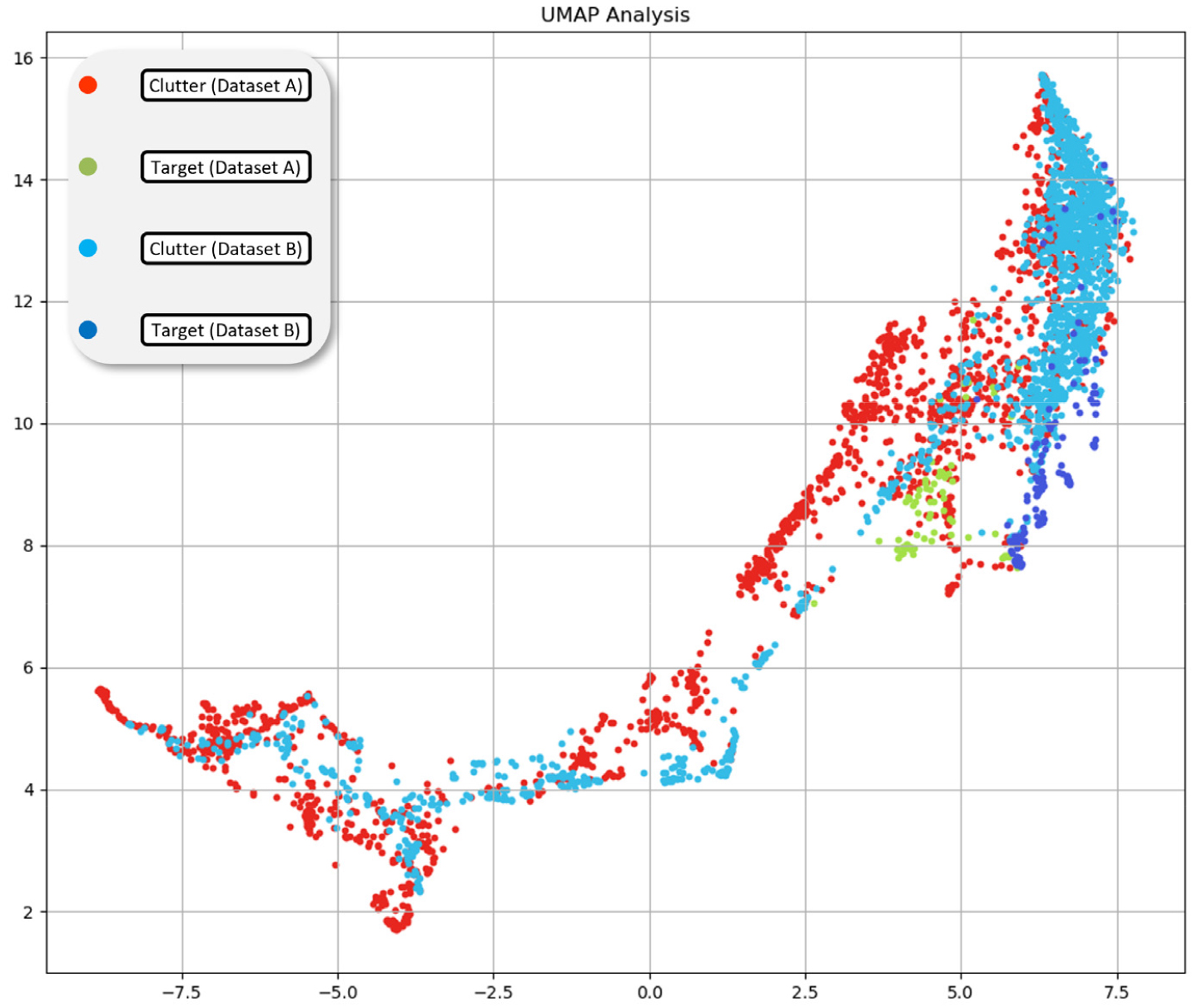
능동소나 데이터세트 분석 결과로부터 데이터 샘플의 개수가 적고 불균형한 것을 알 수 있다. 즉 데이터세트가 일반적인 딥러닝 연구에서 요구하는 풍부한 다양성을 가지는 대량의 빅데이터 조건을 충족하기 어려운 것을 알 수 있다. 더욱이 일부 클러터 데이터 샘플은 표적과 유사한 특성을 가지는 것을 확인할 수 있는데, 이는 2장에서 언급한 바와 같이 표적과 클러터가 유사한 물리적인 전파 특성을 가지기 때문이다.
이러한 능동소나 데이터세트의 특성 때문에 기존의 딥러닝 연구에서 주로 사용되는 복잡도와 수용력이 큰 깊은 층의 모델이 표적식별기에 적용되었을 때 우수한 성능을 보일 것이라고 보장하기 어렵다. 따라서 최신의 복잡한 모델 위주로 실험을 하는 것보다 다양한 딥러닝 모델에 대한 실험을 선행하여, 능동소나 표적식별 문제에서 딥러닝 모델의 성능에 대한 경향성을 분석하는 것이 필요하다.
IV. 능동소나 표적식별기 설계
4.1 능동소나 표적식별기 신경망 모델
현재 연구되는 딥러닝 연구는 Multi-Layer Perceptrons(MLP), CNN, Recurrent Neural Networks(RNN), 트랜스포머(Transformer) 등 다양한 형태의 신경망 모델을 가질 수 있으며, 인코더(Encoder)-디코더(Decoder) 구조, 어텐션 메커니즘(Attention Mechanism)과 같은 구조적인 연구, 훈련을 위한 최적화 기법, 데이터 증강 연구, 비용함수 연구 등과 같은 광범위한 분야를 포함한다.[11] 따라서 딥러닝의 모든 분야에 대해서 분석하는 것은 현실적으로 불가능하며, 연구의 범위를 한정하는 것이 필요하다.
먼저 신경망 모델은 CNN 모델로 한정하였다. 이는 CNN 모델이 2차원의 TF 이미지를 내재 공간에서 효과적으로 표현할 수 있기 때문이다.[11] 본 논문에서는 얕은 CNN 모델과 현재 시점까지 연구된 다수의 CNN 모델 중에서 최근까지 활발하게 사용되거나 최신의 연구에 주로 인용되는 22개의 모델을 사용하였다. Table 2에 본 연구에 사용된 CNN 모델의 정보를 자세히 정리하였다(모델의 깊이와 파라미터 개수는 Torchsummary 패키지를 사용하여 구한 것을 기준으로 서술하였다). Shallow CNN은 깊은 구조의 딥러닝 모델과 비교하기 위해서 본 연구에서 구성한 것이며(자세한 구조는 부록 참조), CoAtNet은 Github에 공개된 코드를 활용하였다.[22] 그 외의 모델은 Python의 Torchvision 패키지를 이용하여 구현하였다.[23]
Table 2.
Configuration of CNN models.
Shallow CNN부터 SwinViT 모델은 입력의 크기를 64 × 64으로 설정하였으며, CoAtNet과 ViT 모델의 입력의 크기는 224 × 224로 설정하였다. 이는 해당 모델의 구조가 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)[24]에 사용된 데이터에 맞춰 설계되었기 때문이며, 해당 모델에 대해서는 64 × 64 크기의 TF 이미지를 224 × 224 크기로 재조정하여 입력하였다. 출력의 크기는 2로 설정(각각 표적과 클러터를 의미)하였으며, 수정된 입출력에 알맞게 일부 층을 수정하였다.
본 논문에서는 깊고 파라미터 수가 많은 기존 딥러닝 연구의 복잡한 모델과 비교하기 위해서 얕은 Shallow CNN 모델을 설계하였다. Shallow CNN(Base) 모델의 깊이는 10이고 파라미터 수가 8,473,762개로 기존에 연구된 VGG, ResNet, EfficientNet 등의 모델과 최신의 ViT, SwinViT, CoAtNet 모델에 비해서 깊이가 얕고 파라미터 수가 적으며, Shallow CNN(Tiny) 모델과 Shallow CNN(Small) 모델은 채널의 수를 줄여서 Base 모델보다 더 적은 파라미터 수를 가지고 있다.
4.2 능동소나 표적식별기 학습방법
본 논문에서는 지도학습을 이용하여 CNN 기반 능동소나 표적식별기를 학습하였다. 3장의 레이블링된 능동소나 데이터세트를 로 표현할 수 있다. 여기서 와 는 각각 번째 데이터 샘플과 부류 정보이며, 는 데이터 샘플 개수이다. 이때 CNN 기반 능동소나 표적식별기의 지도학습 과정은 아래와 같이 표현할 수 있다.[11,16]
여기서 는 입력 데이터를 내재 공간으로 인코딩(Encoding)하는 CNN 모델을 의미하고, 는 CNN 모델의 매개변수를 의미한다. 는 활성화 함수(Activation Function)를 의미하며, 본 논문에서는 소프트맥스(Softmax) 함수를 사용하였다. 는 소프트맥스 함수의 출력으로 과 는 각각 입력 데이터 가 표적과 클러터일 확률을 의미한다. 는 비용함수를 의미하며, 본 논문에서는 교차 엔트로피(Cross Entropy)를 사용하였다.
V. 실 험
5.1 실험 환경
본 장에서는 3장에서 설명한 능동소나 데이터세트를 이용하여 4장에서 설명한 CNN 기반의 능동소나 표적식별기를 학습 및 테스트하였다. Dataset A를 학습 데이터세트로 사용하고 Dataset B를 테스트 데이터세트로 사용한 경우를 Test AB라고 명명하였고, 반대로 Dataset B를 학습 데이터세트로 사용하고 Dataset A를 테스트 데이터세트로 사용한 경우를 Test BA라고 명명하였다. 이때 학습 데이터세트로 설정되면 1:1 비율로 학습 데이터세트와 검증 데이터세트로 임의 분할 하였으며, 샘플 수가 적은 표적이 학습과 검증 데이터세트에 고르게 분포되지 않는 것을 막기 위해서 계층적샘플링(Stratified sampling) 방법으로 분할하였다.[25] 데이터 개수가 적을 때에는 데이터세트의 분할과 CNN 모델의 매개변수 초깃값 설정에 따라서 최적화된 표적식별기의 출력이 동일한 테스트 샘플에 대해서 다르게 나타날 수 있다. 이러한 변동성을 고려하여 본 논문에서는 학습/검증/테스트를 10번 반복하고, 모델 출력의 평균과 분산을 이용해서 표적식별 성능을 분석하였다.
TF 이미지 생성 시 0.1 s 길이의 Hamming 창함수를 75 % 중첩하여 단시간퓨리에변환을 수행하였으며, 최적화 기법으로는 Adam을 사용하였다.[26] 최대 에폭(Epoch) 수는 100으로 설정하였으며, 과적합을 방지하기 위해서 검증 데이터세트를 이용하여 조기 종료(Early Stopping)을 적용하였다.[11]
학습 전에 설정해야 하는 세 가지 초매개변수(Hyperparameter)로 학습률(Learning Rate), 배치 크기(Batch Size), 가중치 감쇠(Weight Decay) 초매개변수가 있으며, 표적식별 성능에 유의미한 영향을 준다. 하지만 최적의 초매개변수는 실험 환경에 따라 다르게 나타나며, 이를 무차별적으로 대입하여 찾아내는 것은 연구의 효율성을 저해한다. 본 연구에서는 초매개변수를 자동적으로 탐색하여 최적화할 수 있는 베이지안 최적화(Bayesian Optimizer) 기법을 사용하였다.[27] 이때 학습률과 가중치 감쇠 초매개변수의 탐색 범위는 10-5에서 10-2 사이로 설정하였으며, 배치 크기의 탐색 범위는 입력이 64 × 64인 경우 16에서 64 사이로 설정하였고 입력이 224 × 224인 경우 16으로 고정하였다. 이때 입력이 224 × 224인 모델의 배치 크기를 고정한 이유는 학습에 활용된 그래픽 카드(NVIDIA GeForce RTX 3080 Ti)의 메모리에 한계가 있어 그 이상의 범위를 탐색하는 것이 어렵기 때문이다.
5.2 성능평가지표
지도학습으로 학습된 CNN 기반 능동소나 표적식별기의 성능을 평가하기 위해서 세 가지 성능평가지표를 사용하였다. 첫 번째는 오차 행렬(Confusion Matrix)을 기반으로 계산되는 F1 점수(F1 Score)이다. F1 점수는 정밀도(Precision)와 재현율(Recall)의 조화 평균으로 불균형 데이터세트에 대해서 식별기의 성능을 다른 성능지표에 비해 잘 표현하는 것으로 알려져 있으며, Eq. (4)와 같이 계산할 수 있다.[25]
여기서 는 각각 테스트세트 전체에 대한 True Positive, False Negative, False Positive에 해당하는 샘플 개수를 의미한다.
일반적으로 표적식별기는 정밀도와 재현율 사이에 상충관계(Trade off)가 존재한다. 그러나 F1 점수는 표적식별기의 결정 임곗값(Decision Threshold)을 고정한 상태에서 구한 값이기 때문에 정밀도/재현율 상충관계를 분석하기 어렵다. Receiver Operating Characteristics(ROC) 곡선은 이러한 상충관계 분석에 유용한 분석 방법이다. ROC 곡선은 표적식별기의 출력에서 표적 부류에 대한 확률을 의미하는 에 대해서 결정 임곗값을 변화시키면서 계산된 False Positive Rate(FPR)과 True Positive Rate(TPR)의 그래프를 그려서 얻을 수 있다. 이때 FPR과 TPR은 각각 Eqs. (5)와(6)으로 계산할 수 있다.
ROC 곡선이 계산되면 ROC 곡선 아래 면적을 의미하는 Area Under the Curve(AUC)를 계산할 수 있으며, 이를 두 번째 성능지표로 사용하였다.[27]
딥러닝 기반의 능동소나 표적식별기는 학습 시 초깃값에 따라서 서로 다른 최적 파라미터를 가질 수 있으며, 따라서 동일 데이터 샘플에 대해서 서로 다른 결과를 낼 수 있다. 이러한 변동성을 평가하기 위해서 학습/검증/테스트를 10회 반복하여 얻어진 ROC 곡선에 대해서 10 %와 90 % 백분위수(Percentile)에 해당하는 ROC 곡선의 AUC 차이를 세 번째 성능평가지표로 정의하고 Diff로 명명하였다.
5.3 실험 결과 및 분석
Table 3에 Test AB와 Test BA에 대해서 계산된 F1 점수와 두 실험에서 얻어진 F1 점수의 평균값을 정리하였으며, Fig. 7에 결과 분석 시 편의를 위해 Test AB와 Test BA에 대한 각각의 F1 점수와 두 실험에 대한 평균 F1 점수, 그리고 두 Test에서 나타난 F1 점수의 차이를 그래프로 나타내었다. 표와 그림에 제시된 F1 점수는 베이지안 최적화를 통해 학습 초매개변수 세 가지를 최적화하여 얻어진 모델에 대해서 학습/검증/테스트를 10회 반복하고 평균값을 구한 것이다.
Table 3.
Comparison of F1 scores.
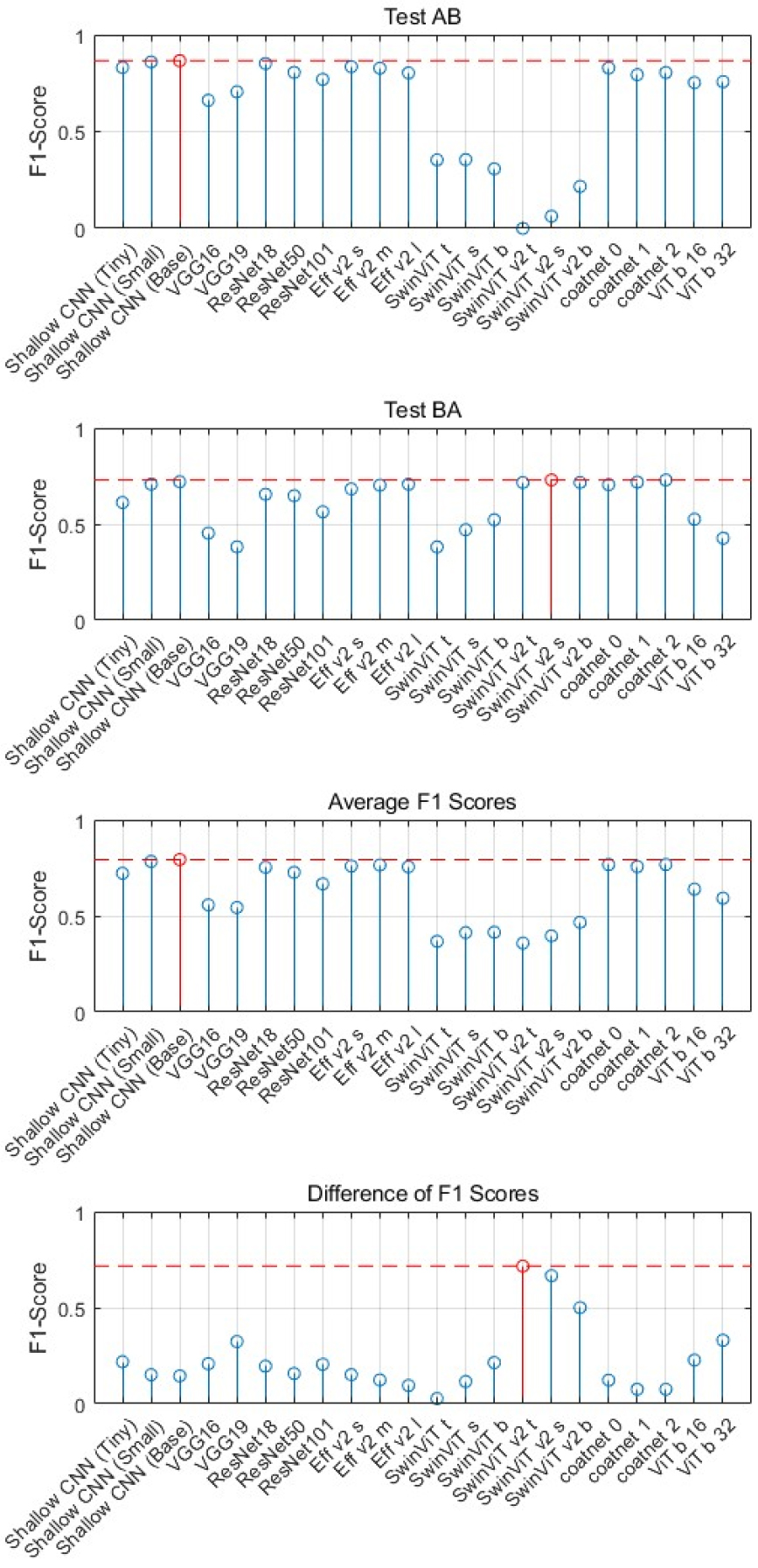
Test AB에서는 Shallow CNN(Base) 모델의 F1 점수가 0.8659로 가장 높은 F1 점수를 가지고, 그보다 파라미터 수가 적은 Shallow CNN(Small)과 Shallow CNN(Tiny) 모델도 Base 모델에 가까운 높은 F1 점수를 가진다. ResNet, EfficientNet, CoAtNet 모델들은 0.8보다 높거나 근접하는 F1 점수를 가지며, ViT b 모델들은 0.75 근처, VGG 모델들은 0.71 이하, SwinViT, SwinViT v2 모델들은 0.36보다 낮은 점수를 가진다.
Test BA에서는 Test AB에서 낮은 F1 점수를 가졌던 SwinViT v2 s 모델의 F1 점수가 0.7299로 가장 높다. Shallow CNN(Base) 모델의 F1 점수는 0.7208로 SwinViT v2 s 모델과 비슷한 높은 F1 점수를 보이며, Swin ViT v2 s 모델과 달리 실험에 따른 급격한 성능 차이가 발생하지 않는다. VGG 모델들은 Test BA에서도 낮은 성능을 보였으며, ResNet 모델들은 0.66 이하, EfficientNet, CoAtNet 모델들은 0.68 이상의 점수를 가진다. SwinViT 모델들은 0.53 이하의 상대적으로 낮은 점수를 보이지만, SwinViT v2 모델들은 0.71 이상의 높은 점수를 보인다.
두 실험에 대한 평균 F1 점수와 점수의 차이 비교 그래프에서 Shallow CNN과 CoAtNet 모델들이 양쪽 실험 모두에서 높은 F1 점수를 가지면서 실험에 따른 F1 점수의 차이가 적은 것을 확인할 수 있다. 특히 Shallow CNN 모델의 경우 CoAtNet 모델에 비해서 파라미터 수가 최소 2배에서 최대 1,425배 적지만 비슷하거나 높은 F1 점수를 가진다는 것이 주목할만한 결과이다.
표적식별기의 정밀도/재현율 상충관계를 분석하기 위해서 각 모델 범주에서 평균 F1 점수가 높은 모델을 하나씩 고르고 학습/검증/테스트 10회에 대한 ROC 곡선을 계산하여 Fig. 8에 나타내었다. 그림에서 점선은 평균 ROC 곡선을 의미하고, 위아래 선은 각각 10 %와 90 % 백분위수에 해당하는 ROC 곡선을 의미한다. 분석 시 편의를 위해서 Fig. 9에 평균 ROC 곡선을 같은 그래프 상에 나타내었다.
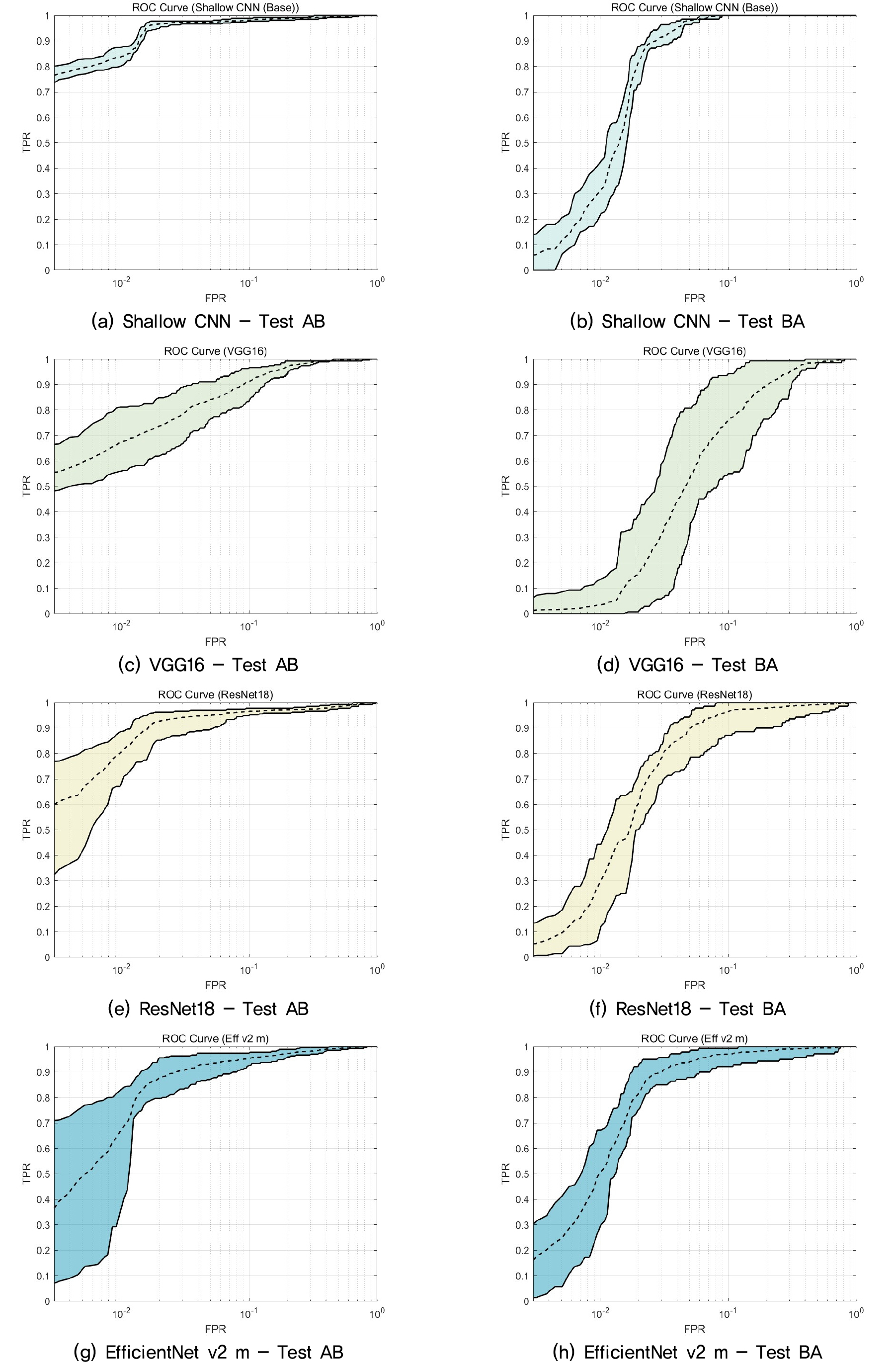
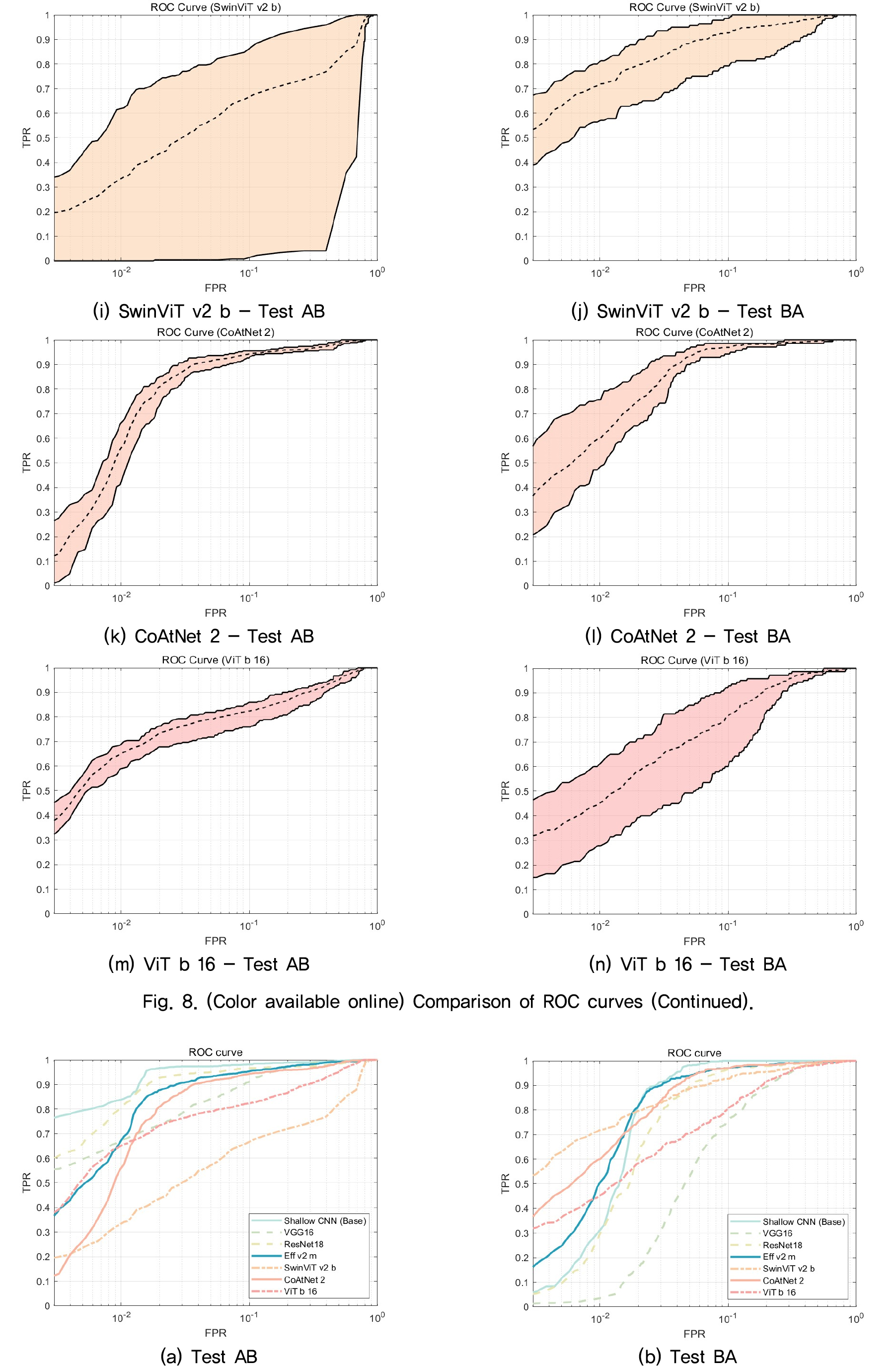
Test AB에서는 Shallow CNN(Base) 모델이 모든 FPR 구간에서 다른 모델보다 높은 TPR을 가지고, 다음으로 ResNet18 모델이 높은 TPR을 보인다. Test BA에서는 Shallow CNN(Base) 모델이 FPR이 0.02 이상인 구간에서 다른 모델보다 높은 TPR을 가지고, FPR이 0.02 보다 낮은 구간에서는 성능이 급격히 낮아진다. Test BA의 낮은 FPR 구간에서는 SwinViT v2 b 모델이 0.5 이상의 높은 TPR을 가진다. 그러나 SwinViT v2 b 모델의 경우 Test AB에서 가장 낮은 성능을 가지며 높은 변동성을 가지는 것으로 분석된다.
정량적인 분석을 위해서 Table 4에 세 가지 성능평가지표(F1 점수, AUC, Diff)를 정리하였다. Test BA의 F1 점수를 제외한 나머지 성능평가지표에서 Shallow CNN(Base) 모델이 가장 우수한 성능을 보이는 것을 확인할 수 있다. 특히 변동성을 의미하는 Diff의 값이 다른 모델과 비교해서 낮게 나타나는 것을 확인할 수 있으며, 따라서 Shallow CNN(Base) 모델의 학습이 안정적인 것을 확인할 수 있다. Fig. 8에서도 ROC 곡선을 비교하여 Shallow CNN(Base) 모델의 안정성을 확인할 수 있다. 기존 CNN 모델 중에서는 CoAtNet 2 모델이 성능과 변동성 모두 다른 모델보다 우수한 성능을 보이는 것으로 분석된다.
Table 4.
Comparison of three metrics.
능동소나 데이터세트에 대한 실험 결과 Shallow CNN(Base) 모델이 견실하면서도 우수한 일반화 성능을 나타내는 것으로 분석되었다. 기존 딥러닝 연구에서 주로 사용되는 깊은 CNN 모델의 경우 Shallow CNN(Base) 모델과 비교해서 변동성이 크게 나타났으며, 실험 환경에 따른 성능 변화도 상대적으로 크게 나타났다.
최근까지의 수행된 다수의 딥러닝 연구 결과에 따르면 일반적으로 깊이가 깊으면서 파라미터 수가 많은 모델이 우수한 성능을 보이는 것으로 알려져 있다.[7,8,9,10,11] 그러나 본 논문의 실험 결과, 데이터세트가 제한적인 능동소나 표적식별 문제에서는 깊이가 얕고 파라미터가 상대적으로 적은 Shallow CNN 모델이 기존의 깊은 모델에 비해서 성능과 변동성 모두 우수한 것을 확인할 수 있었다. 최근 본 논문의 실험보다 제한적인 실험이지만, 비슷한 사례가 보고된 바 있다.[28,29] 따라서 능동소나 데이터세트가 제한적이라면, 얕은 층의 모델을 기반으로 연구를 시작하고, 추가적으로 구조를 개선하면서 성능과 안정성을 동시에 향상하는 것이 타당할 것으로 판단된다.
본 논문에서 분석된 결과는 향후 딥러닝 기반의 능동소나 표적식별기 연구를 수행할 때 중요한 이정표로 사용될 수 있으며, 다양한 연구의 마중물 역할을 할 수 있을 것으로 기대한다.
VI. 결 론
본 논문에서는 소량 및 불균형 능동소나 데이터세트에 적용된 딥러닝 기반 표적식별기의 일반화 성능을 종합적으로 분석하였다. 서로 다른 시간과 해역에서 수집된 두 개의 능동소나 실험 데이터를 이용하였으며, 탐지된 신호의 시간-주파수 영역 이미지를 표적식별기의 입력으로 사용하였다. 표적식별기의 신경망 모델은 다양한 구조를 가지는 22개의 CNN 모델을 사용여 고안되었다. 표적식별기 출력의 변동성을 계산하기 위해서 학습/검증/테스트를 10번 반복였으며, 학습을 위한 초매개변수는 베이지안 최적화를 이용하여 도출하였다.
실험 결과 Shallow CNN(Base) 모델이 깊은 층을 가지는 기존의 CNN 모델보다 견실하면서도 우수한 일반화 성능을 가지는 것으로 분석되었다. 기존의 CNN 모델 중에서 일부 실험 환경에 대해서 우수한 성능을 보이는 모델이 있었으나 실험 환경에 따라 성능의 편차가 크게 나타났다.
본 논문은 딥러닝 기반 능동소나 표적식별 문제에 대한 종합적인 연구로 관련 연구를 수행할 때 중요한 이정표로 사용될 수 있으며, 향후 수행될 다양한 연구의 마중물 역할을 할 수 있을 것으로 기대한다.
그러나 본 논문의 결과는 제한적인 데이터세트만으로 실험이 수행되었다는 한계점이 있다. 본 논문의 결과가 능동소나 표적식별 문제에서 일반적으로 통용되는 것을 검증하기 위해서는 향후 연구에서 다양한 조건(해상환경의 시공간적 변화 및 소나 시스템의 다양성을 의미)에서 데이터를 수집하여 실험 시 학습/검증/테스트 조건을 바꿔가며 실험하는 과정이 필요할 것으로 판단된다.
VI. 결 론
본 연구에서는 깊은 CNN 모델과 비교하기 위해서 얕은 층을 가지고 파라미터 수가 적은 Shallow CNN 모델을 설계하였다. Table A1에 Shallow CNN의 3가지 구조를 정리하였다.
