

I. Introduction
II. Problem formulation
III. Non-causal single-channel MVDR filter
IV. Suppression of late reverberation and additive noise
4.1 Derivation of the correlation parameter
4.2 Estimation of subparameters
V. Performance evaluation
5.1 Experimental set-ups
5.2 Experimental results
VI. Conclusion
I. Introduction
In speech signal processing systems, such as voice- controlled systems, hands-free mobile telephones, and hearing aids, the received microphone signals are generally contaminated by environmental artifacts.[1] The detrimental effects, such as background noise, interfering signal, and channel distortion, degrade the overall performance of the system.[2] Many researchers are still struggling to remove the undesired com-ponents from the acquired input signal.
One critical obstacle is reverberation caused by a multi-path propagation of an acoustic sound from its source to microphone.[3-5] An acoustic channel between the source and the microphone can be described by the acoustic impulse response (AIR) and it can be divided into three segments: a direct path, early reflections, and late reverberation.[1] While the early reflections, which is the combination of the direct and the early reflections, impacts only to the color-ation of the speech, late reverberation causes the lengthening of speech phonemes. Consequently, the previous phonemes overlap following phonemes, so that it results in speech intelligibility (and also recog-nition rate) degradation.[2]
A number of techniques have been proposed to reduce the detrimental effects of the reverberation. If the AIR is known as a priori knowledge, the dereverberation can be ideally achieved by taking an inverse filtering such as multiple input/output inverse theorem (MINT).[6-8] The problem of speech derever-beration in unknown acoustic environments has also received a lot of attention. Cepstrum based decon-volution techniques utilize the idea that decon-volution in the time domain is identical to subtraction in the cepstrum domain.[9-12] Methods to enhance a residual of linear prediction (LP) filtering have been introduced.[13,14] An algorithm to employ the harmonic structure of speech, which is called har-monicity based dereverberation (HERB), has been also proposed.[15-17]
The spectral enhancement technique is known as the most famous approach for single channel derever-beration techniques.[4,18-20] The spectral enhancement based dereverberation approaches have been developed to reduce the late reverberation or in other words to estimate the early speech component from the acquired input signal. They are derived under the assumption that the early speech component and the late rever-beration are uncorrelated, and the processings are commonly performed in the frequency domain by estimating the late reverberation spectral variance (LRSV).
Several techniques have been proposed to suppress both the reverberation and the noise.[21] In Habets’ approach, the noise power spectrum is first sup-pressed, and then the LRSV is obtained from the denoised reverberant speech.[4,22] The output signal is obtained by applying a spectral enhancement. Erkelens et al. proposed a late reverberation suppression rule in noisy and reverberant environments by exploiting the longterm correlation coefficients between the current reverberant spectrum and enhanced ones in the previous frames.[23] They extended their works to design the suppression rule in noisy and non-stationary acoustical environments by assuming that the AIR has time varying characteristic.[24]
In,[25] an efficient dereverberation algorithm was introduced and verified its superiority in reverberant environment. The basic idea of the algorithm was that the reverberant signals in the following frames contain the desired speech at the current frame since the desired speech at the current frame is convolved with a relatively long time interval of the AIR in reverberant environment. The algorithm decomposed the observed reverberant signal into a component correlated to the desired speech signal and inter-ference that did not have correlation with the desired signal. The non-causal filter minimizes interference, while maintaining speech quantity by gathering the correlated component.
In this paper, the single-channel non-causal enhance-ment algorithm to suppress both reverbeartion and background noise is proposed. The dereverberation algorithm in[25] is extended to enhance the desired speech signal in noisy reverberant speech. The pro-posed algorithm utilizes a non-causal MVDR filter to exploit the correlation information that lies in sub-sequent frames. The noisy-reverberant signals are decomposed into the parts of the desired signal and the interference that does not correlated to the desired signal. The interference consists of two different components. One is a reverberant interference that is the reverberant signal and uncorrelated to the desired speech signal. The other is additive noise inter-ference that is assumed to be uncorrelated with the desired speech. Then, the filter equation is derived based on the MVDR criterion to minimize the residual interference without bringing speech distortion.
The late reverberation and additive noise are sup-pressed by estimating correlation coefficient, which is the main parameter to determine the overall per-formance of the proposed algorithm. The correlation parameter is derived by employing a statistical rever-berant model, composed of the late reverberation spectral variance and another sub-parameters. The efficient method to estimate the correlation parameter including the sub-parameters are described and prac-tically implemented.
The rest of this paper is organized as follows. The problem is formulated in section 2. Here, the observed noisy reverberant signal is decomposed into three uncorrelated components: the part correlated to the desired signal, reverberant interference, and noise interference. The non-causal single-channel MVDR filter to suppress the noise-plus-reverberant inter-ference is derived in section 3. In section 4, the complete algorithm to estimate the early speech component is described. The correlation parameter is derived using the statistical reverberation model and implemented by using estimates of sub-parameters. Section 5 demonstrates the performance evaluation and the summary follows in section 6.
II. Problem formulation
The observed noisy reverberant signal is assumed to be first convolved with the acoustic transfer function (ATF) H(k, m), and then corrupted by the uncor-related noise V(k, m), as follows
| (1) |
with
| (2) |
Where H(k, 0) = 1 and k and m mean frequency-bin and time-frame, respectively. The speech signal S(k, m) is assumed to be uncorrelated to the speech signal at different time-frame.
In reverberant environment, the desired signal S(k, m) is first delayed and attenuated by the AIR, and then accumulated into the subsequent reverberant signal Z(k, m+l), l > 0. The reverberation components in future frames, which are highly correlated with the desired signal of current frame, should be taken into account in the derivation process of dereverberation algorithms. For that purpose, a non-causal filter is employed as
| (3) |
where
| (4) |
| (5) |
are the vector of the observed signal and the vector of the filter coefficient, relatively. The filter order L is required to be determined based on reverberant level, that is the reverberation time RT60. It is obvious that the large value of L promises ideal performance. However, the limitation such as complexity in real application forces to choose appropriate value. In this paper, L is chosen to be 12 (i.e., 48 ms).
The observed signal Y(k, m+l) contains two parts; a part that has a correlation with the desired signal S(k, m) and a component that is uncorrelated to S(k, m). Precisely, the observed signal vector y(k, m) contains :
1-1)The desired signal S(k, m) itself.
1-2)The reverberant components that are correlatedwith S(k, m). H(k, 1)S(k, m) contained in Y(k, m+1) is a good example.
2-1)The reverberant components that do not have correlation with the desired signal S(k, m). This category contains undesired speech signals in subsequent frames S(k, m+l), l > 0 and the reverberant signal caused by all undesired speech signals at the earlier time-frames. For instance, the rest components of Y(k, m+1) except for H(k, 1)S(k, m), such as the speech signal S(k, m+1) and the reverberant signal from earlier time-frame H(k, 2)S(k, m-1), are included in this category.
2-2)The uncorrelated additive noise V(k, m).
The fact above inspires us to decompose the observed noisy reverberant signal into two orthogonal components corresponding to the part of the desired signal and interference.
| (6) |
where
| (7) |
is correlation coefficient between the desired signal S(k, m) and the subsequent observed signal Y(k, m+l) and SY'(k, m+l) is the interference signal.[26] Note that the desired signal and interference signal is un-correlated:
| (8) |
The interference signal SY'(k, m+l) is a super-position of both the reverberant interference SZ'(k, m+l), which is refered as (2-1) in previous page, and the noise interference SV'(k, m+l), which is (2-2), such that
| (9) |
where
| (10) |
and
| (11) |
In,[25] it was described that the observed noise-free reverberant signal was decomposed into the one correlated to the desired signal and the other referred as the interference. A dissimilarity between the decomposition in Eq. (5) and one in,[25] is that the interference SY'(k, m+l) in Eq. (5) contains not only the uncorrelated reverberant component SZ'(k, m+l) but also the additive background noise SV'(k, m+l) since the background noise is assumed to be uncorrelated to the desired speech signal.
The observed signal vector y(k, m) is given as
| (12) |
where the normalized correlation vector 款s(k, m) is
| (13) |
Sd(k, m) is the desired signal vector, and
| (14) |
denotes the reverberant-plus-noise interference signal vector.
sy'(k, m) consists of reverberant-interference signal vector sz'(k, m) and noise-interference signal vector sv'(k, m) such as
| (15) |
where
| (16) |
From Eq. (3) and (12), one can write the estimate ![]() into the following form:
into the following form:
| (17) |
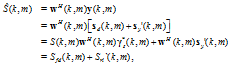
where Sfd(k, m) and Sriˋ(k, m) are the filtered desired signal and the residual (reverberation-plus-noise) interference, respectively.
By Eq. (15), the residual interference S'ri(k, m) can be rewritten as
| (18) |
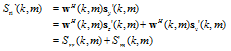
where S'rr(k, m) and S'rn(k, m) are the the residual reverberation and the residual noise, respectively. From Eq. (17) and Eq. (18), it is observed that the estimate of the desired signal is the sum of three mutually uncorrelated terms, which are the filtered desired signal, the residual reverberant signal, and the residual noise signals.
Therefore, the variance of ![]() is
is
| (19) |
where
| (20) |
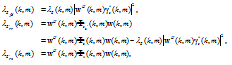
and Φa(k, m) = E[a(k, m)aH(k, m)] is the correlation matrix of a(k, m)∈sz'(k, m), z(k, m), v(k, m)}.
III. Non-causal single-channel MVDR filter
In order to derive the filter coefficients, the error signal between the estimated and desired signals is defined as
| (21) |
where
| (22) |
is the signal distortion due to the complex non-causal filter, which is difference between the filtered desired signal Sfd(k, m) in Eq. (17) and the desired signal, and
| (23) |
represents the residual (reverberation-plus-noise) interferences (See Eq. (17) and Eq. (18)).
The mean-square error (MSE) is then
| (24) |
where
| (25) |
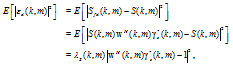
and
| (26) |
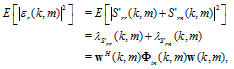
with
| (27) |
being the reverberation-plus-noise interference covar-iance matrix.
The MVDR filter can be derived by minimizing the MSE of the residual interference, E[箚졑琯r(k, m)箚졑2], with the constraint that the desired signal is not distorted.
| (28) |
for which the solution is[26,38,39]
| (29) |
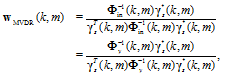
where 過y(k, m) = E[y(k, m)yH(k, m)] is the correlation matrix of y(k, m).
Note that the filter equation is actually identical to the one for the noise-free environment in,[25] except for replacement of 過z-1(k, m) by 過y-1(k, m). This is expected since the additive noise is assumed to be uncorrelated to the speech signal and thus regarded as the interference. It apparently shows that the proposed MVDR filter in Eq. (29) is primarily designed to minimize every components uncorrelated with desired speech, so that it is an algorithm robust to the noise.
IV. Suppression of late reverberation and additive noise
In this section, the correlation vector 款s(k, m) in Eq. (29) is derived using a statistical reverberation model to suppress the late reverberation. And the practical methods to obtain the subparameters which are required to construct 款s(k, m) are introduced. The subparameters include the variances and the correlation coefficients of the observed signal, the late reverberation, and the noise signal.
4.1 Derivation of the correlation parameter
The summation in Eq. (2) can be split into a contribution of the early speech component X(k, m) and the late reverberation R(k, m) as follows[4,18-20]
| (30) |
and
| (31) |
where Ne determines the start time of the AIR that may be considered as reverberation. If Ne is decided big enough, it can be assumed that the correlation between R(k, m) and S(k, m) is negligible. The time instance Ne usually ranges from 32 to 64 ms.[4] In this paper, we empirically choose Ne = 12 (i.e., 48 ms), which is identical to one in Habets’ work,[20] so that R(k, m) in the Eq. (31) consists of only late reverberation.
A new desired signal, that is, the early speech component X(k, m) is given by
| (32) |
Suppressing the late reverberation can be achieved by recovering X(k, m). From Eq. (7) and (32), the estimated correlation coefficient to estimate the early speech component is given by
| (33) |
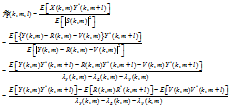
due to
| (34) |
The correlation of the reverberant component E[R(k, m)R*(k, m+l)] can be represented by the multiplication of the variance of the late rever-beration and a parameter that is exponentially decay-ing due to ![]() [25]:
[25]:
| (35) |
Then, the estimated correlation coefficient ![]() in Eq. (33) is reformulated as
in Eq. (33) is reformulated as
| (36) |
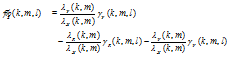
where
| (37) |
and
| (38) |
The proposed algorithm to estimate the correlation parameter in Eq. (36) requires subparameters, such as the variance of the late reverberation ![]() R(k, m), the variance of noise
R(k, m), the variance of noise ![]() V(k, m), the correlation of the late reverberation 款R(k, m, l), and the correlation of the noise signal 款V(k, m, l) at the subsequent frame. While the variance terms play a classical role in attenuating the spectral component, the correlation parameters give additional aggressiveness to the proposed algorithm, so that it dynamically suppresses the late reverberation and the noise by estimating the changes, for example speech on/off set or noise fluctuations, which may occur at the subsequent frames.
V(k, m), the correlation of the late reverberation 款R(k, m, l), and the correlation of the noise signal 款V(k, m, l) at the subsequent frame. While the variance terms play a classical role in attenuating the spectral component, the correlation parameters give additional aggressiveness to the proposed algorithm, so that it dynamically suppresses the late reverberation and the noise by estimating the changes, for example speech on/off set or noise fluctuations, which may occur at the subsequent frames.
4.2 Estimation of subparameters
The power spectrum of the early speech com-ponent in Eq. (37) can be estimated by following power spectral subtraction method
| (39) |
As shown in,[27] the spectral gain function is given by
| (40) |
where
| (41) |
and
| (42) |
denote the a priori and a posteriori SIR, respectively. The a priori SIR can be estimated by using the decision-directed method.[4,37]
From the general statisitical reverberant model in,[4,18-20] the late reverberant spectral variance 貫R(k, m) is given by
| (43) |
where
| (44) |
The estimate 貫R(k, m) can then be used to estimate the spectral variance of the early speech component 貫X(k, m) in Eq. (39-42) and to estimate the cor-relation coefficient ![]() s(k, m, l) in Eq. (36).
s(k, m, l) in Eq. (36).
For the estimation of the late reverberation spectral variance 貫X(k, m) in Eq. (39), an estimate of the power spectrum of the late reverberation 貫R(k, m) is required. The late reverberant spectral variance 貫R(k, m) can be attained by Eq. (43). For the estimation of the late reverberation spectral variance 貫R(k, m) in Eq. (43), an estimate of the power spectrum 貫Z(k, m) in Eq. (44) is required. The power spectrum of the reverberant spectral component Z(k, m) can be estimated by the power spectral subtraction method given by
| (45) |
with
| (46) |
where
| (47) |
and
| (48) |
denote the a priori and a posteriori SNR, respec-tively. The noise spectral variance 貫v(k, m) is esti-mated from the observed noisy reverberant signal Y(k, m) by using noise power spectrum estimation methods.[30-36]
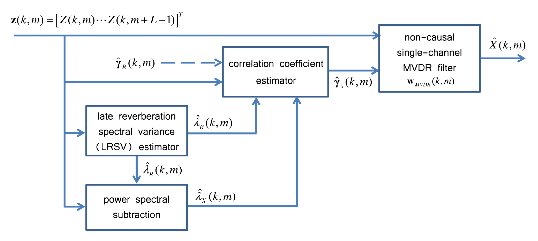
A diagram of the proposed single-channel non- causal dereverberation algorithm is depicted in Figure 1. The output signal ![]() (k, m) is made by filtering the input vector of the reverberant signal Z(k, m) with the correlation vector
(k, m) is made by filtering the input vector of the reverberant signal Z(k, m) with the correlation vector ![]() S(k, m). The correlation coefficient is estimated based on the input signal and the sub-parameters such as
S(k, m). The correlation coefficient is estimated based on the input signal and the sub-parameters such as ![]() R(k, m),
R(k, m), ![]() R(k, m), and
R(k, m), and ![]() X(k, m).
X(k, m).
|
Fig. 1. Block diagram of the proposed system. |
V. Performance evaluation
In this section, the performance of the proposed algorithm for the noisy reverberant environments is verified. We compare the proposed method with the Habet's method.[4] The evaluation is performed based on three major objective measurements - the signal to interference ratio (SIR) in time domain, the signal to interference ratio (SIR) in frequency domain, and speech distortion (SD) index. As the interference consists of both the reverberant interference and the noise interference, the SIR in frequency domain can be divided into the signal to reverberant ratio (SRR) and the signal to noise ratio (SNR). By using the SRR and the SNR measurements, the performance can be analyzed separately for each interference.
The rest of this section is organized as follows. The simulation set-ups described in section 5.1. Section 5.2 represents the evaluation of the proposed algorithm in the noisy reverberant environment.
5.1 Experimental set-ups
The clean speech signal is created by concatenating 5 different utterances, which are spoken by 5 different speakers, from AURORA2 database. The signal is sampled at 8 kHz, 15 s-long, and it is transformed into the short time Fourier transform (STFT) domain using 75% overlapping (i.e., N=32). The Kaiser window of 128 samples is used.
The speech signal is convolved with different AIRs in order to generate the reverberant signals. The AIRs are synthesized under different environments using the image method.[28] The source-microphone distance D=4.5 m, RT60={600, 800, 1000, 1200} ms, and the room size is set to 6횞8횞5 m (length 횞 width 횞 height).
The noisy reverberant signals are generated by first convolving the speech signal with the AIRs and then corrupted by the additive noise. Gaussian random noise and destroyer-engine noise (from NOISEX-92 database[40]) are added to the reverberant signal at a specified input SNR. Ten independent trials are con-ducted to examine the consistency of the evaluation.
The reverberation time RT60 is assumed to be known in the simulation, which can be estimated by using blind estimation procedures in practice.[18,29] Preliminary experiments confirm that the proposed algorithm is robust to the estimation error of RT60, although further analysis remains as future work. The forgetting factor for the variance of the late rever-beration is set to 觀 = 0.2.
The estimates of 過y(k, m) are recursively updated as follows:
| (49) |
where 關 represents the forgetting factor. The forgetting factor 關 has an important role to control the trade-off between the singular or ill-conditioned correlation matrix 過y(k, m) (with a small 關) and smoothing of the short-term variation of speech signals (for 關 close to 1). Unless we specifically mention, 關 is empirically fixed as 0.6 to guarantee relatively high output SIR and good listening quality.
To compute the inverse of 過y(k, m), the regular-ization technique is used, so that 過y-1(k, m) is replaced by
| (50) |
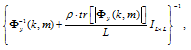
where ρ > 0, tr[・], and IL×L denote the regularization parameter, trace operation, and L by L identity matrix, respectively. We use the first 10 frames (i.e., 40 ms) to compute the initial estimates of Φy(k, m). The rest of signal frames is then used for perfor-mance evaluation.
The SIRs in both the time domain and the fre-quency domain are utilized for performance evaluation. The SIR in the time domain between the clean speech s(n) and the processed signal ![]() is defined as
is defined as
| (51) |
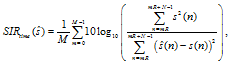
and the SIR in the time domain between the clean speech s(n) and the observed noisy reverberant signal y(n) is calculated by
| (52) |
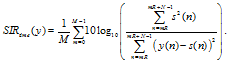
Accordingly, the improvement of the time domain SIR is defined by
| (53) |
The large ΔSIR value represents that the output signal ![]() is much more similar to the desired signal s(n) compared to the observed signal y(n).
is much more similar to the desired signal s(n) compared to the observed signal y(n).
The input SIR in the frequency domain is defined by
| (54) |
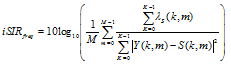
and
| (55) |
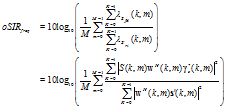
is the output SIR in the frequency domain, which is ratio between variance of the filtered desired signal 貫Sfd(k, m) and variance of the reverberation-plus-noise residual signal 貫S'ri. The improvement of the frequency domain SIR is defined by
| (56) |
The proposed algorithm suppresses both of the reverberation and the background noise at the same time. However, the performance measures described above are not able to distinguish the reverberation reduction and the noise suppression. Thus, additional measures to separately analyze the effect of the proposed method on the reverberation reduction and the noise reduction are required.
The reverberation-plus-noise residual S'ri(k, m) can be decomposed into the residual reverberation S'rr(k, m) and the residual noise S'rn(k, m) as in Eq. (18). We define the input SRR by the ratio between variance of the desired signal and variance of reverberant signal as followed
| (57) |
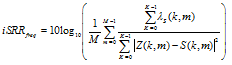
and
| (58) |
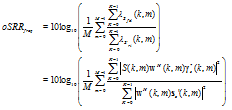
is the output SRR, which denotes the ratio between variance of the filtered desired signal 貫Sfd(k, m) and variance of the reverberation residual signal 貫S'rr. The improvement of the frequency domain SRR is defined by
| (59) |
Similarly, the improvement of the frequency domain SNR is defined by
| (60) |
where
| (61) |
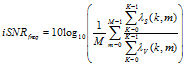
is the input SNR and
| (62) |
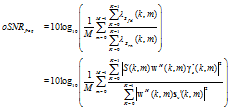
is the output SNR representing the ratio between the filtered desired signal variance and the variance of the noise residual.
Another useful performance measure is the speech distortion index defined as
| (63) |
where
| (64) |
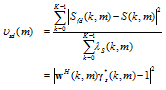
is the speech distortion at the time-frame m. The speech distortion υsd(m) is always greater than or equal to 0 and should be upper bounded by 1 for optimal filters. So the higher is its value, the more the desired signal is distorted. For the proposed filter, it is clear that υssd(m)≈, so that υsd≈-∞.
The objective measures explained above are summarized in Table 1.
Table 1. Summary of objective measures | |
Number | Objective measurement |
Eq. (53) |
|
Eq.(56) |
|
Eq.(59) |
|
Eq.(60) |
|
Eq.(63) |
|
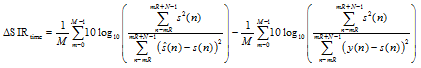
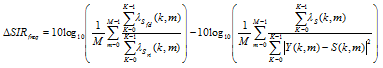
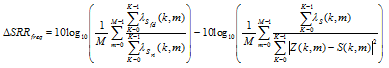
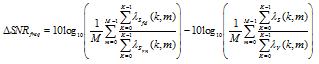
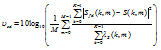
5.2 Experimental results
Figure 2 and Figure 3 show the basic simulation results. Figure 2 depicts the waveforms of the output signal processed by the conventional and the pro-posed method and the improvements of the time domain SIR by those algorithms. The same results are represented as spectrograms in Figure 3. The simulations are conducted under environment that the reverberation time RT60 is 0.9 s and 20 dB additive white noise. The proposed algorithm works with L=12.
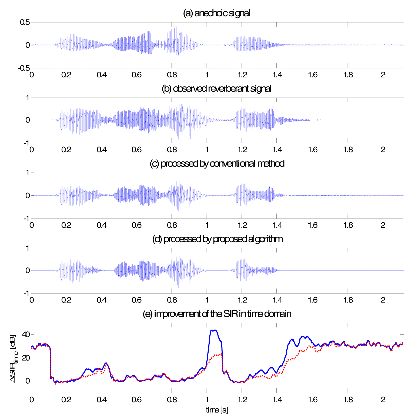
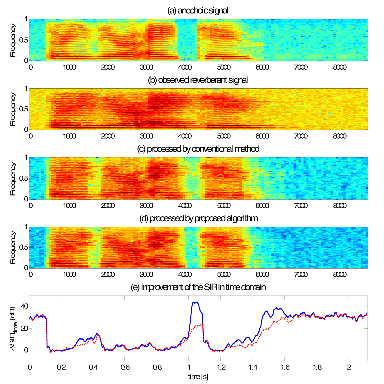
As shown in the figures, the improvements of SIRtime by both algorithms are observed mostly for non-speech region. Note that the ΔSIRtime by the proposed method tends to increasing for the region of the reverberant tail, compared to the one by the Habets' algorithm. This is one of the strong points of the proposed algorithm to dynamically suppress the reverberation by detecting the speech onset or offset, since it quantifies the variation in the subsequent frames by adopting ![]() Y(k, m) and
Y(k, m) and ![]() R(k, m) in Eq. (36).
R(k, m) in Eq. (36).
Figure 4 shows the effect of the forgetting factor 關 on the performance of the proposed algorithm. The performance of the proposed algorithms tended to monotonically increasing as the order of the FIR filter increased. Using a large 關, the temporal vari-ation of non-stationary speech signal can not be captured, so that both of SIRtime and SRRfreq gradually decrease. In contrast, the noise in the experiments is stationary such that a large 關 is more advantageous for the performance of the noise reduction, so that SRRfreq increases.
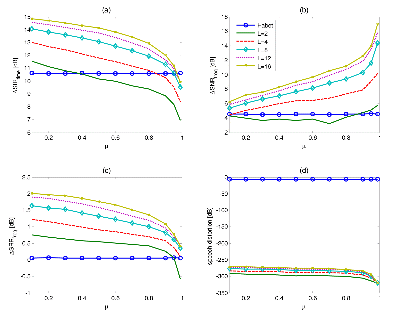
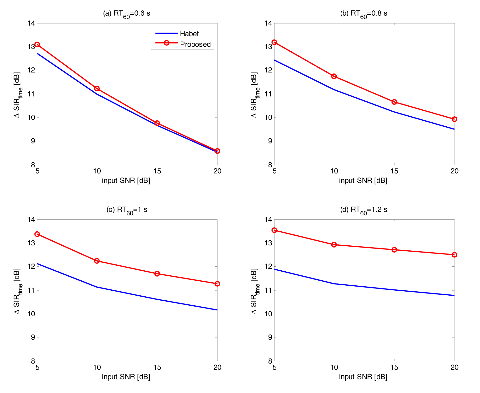
Figure 5 and Figure 6 depict the time domain SIR performances of the conventional and the proposed algorithm in noisy (white noise and destroyer-engine noise) reverberant environment as a function of the input SNR. Each sub-figure depicts results of the proposed algorithm and the Habet's method for different reverberation time RT60. The results show that the SIR improvement of both surveyed algorithms monotonically decrease as the input SNR increases. Especially, the results in relatively less-reverberant environment such as case of RT60 = 0.6 s degrades faster than the others. As shown in the figure, the proposed system outperforms the conventional one in every environments studied in this simulation. The superiority of the proposed algorithm is appeared when the environment is strongly reverberant with large RT60 value. It is interesting that the differences between the results of both algorithms remains same regardless of changes of the input SNR.
|
Fig. 5.Time domain SIR performances of the conventional and the proposed algorithm in noisy reverberant environment as a function of the input SNR (white noise case). |
|
Fig. 6.Time domain SIR performances of the conventional and the proposed algorithm in noisy reverberant environment as a function of the input SNR (destroyer-engine noise case). |
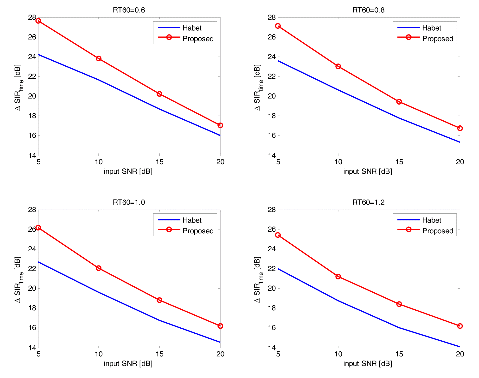
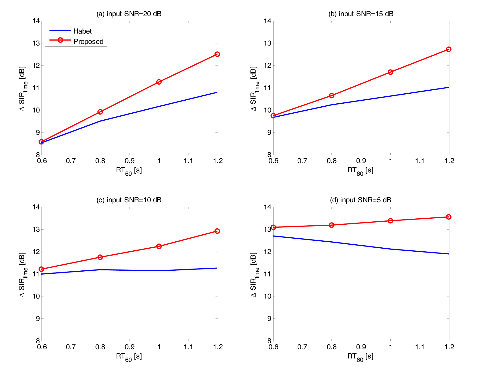
Figure 7 and Figure 8 depict the same results in Figure 5 and Figure 6, respectively, after reorganizing with different axis. It shows the time domain SIR performances of the surveyed algorithms in noisy reverberant environment as a function of the rever-beration time RT60. Each sub-figure depicts results for different input SNR. In Figure 7, we observe that ΔSIRtime values of both algorithms monotonically increase as the reverberation time increases, except for the result of the Habet's method for 5 dB input SNR. In Figure 8, ΔSIRtime values of the conventional algorithm decrease more rapidely than the proposed one as the reverberation time increases, especially for the result under 20 dB input SNR. It is clearly noticable that the proposed algorithm outperforms the con-ventional one especially when the reverberation time is large. In other words, the proposed algorithm using multiple consecutive STFT fames improves the derever-beration performances and is far better than the con-ventional algorithm under strongly reverberant environ-ments.
|
Fig. 7.Time domain SIR performances of the conventional and the proposed algorithm in noisy reverberant environment as a function of the reverberation time RT60 (white noise case). |
| ||
Fig. 8.Time domain SIR performances of the conventional and the proposed algorithm in noisy reverberant environment as a function of the reverberation time RT60 (destroyer-engine noise case). | ||
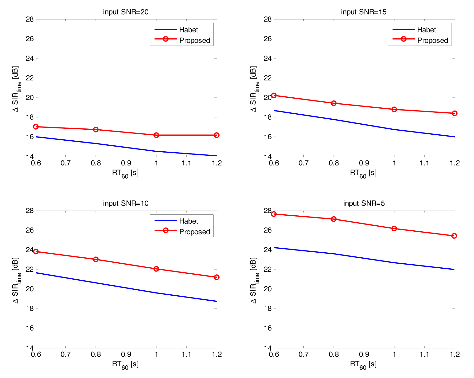
Figure 9 and Figure 10 represent the improvement of the SIR by the surveyed algorithms against the input SNR and the reverberation time. In these figures, it is shown that the results of the Habet's method always stays under the results surface of the proposed algorithm. The differences between the results under the environment with low input SNR and large rever-beration time is much larger than one with high input SNR and small reverberation time. The results illustrates that the proposed system has its superiority for the severely noisy and strongly reverberant environment.
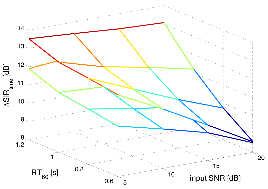
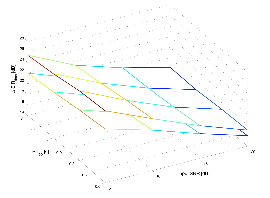
Figure 11 represents the SRR performances of the conventional and the proposed algorithms as a function of the input SNR and the reverberation time RT60. The SRR values are computed with Eq. (59). The upper surface represents the results of the proposed algorithm and the lower is ones of the conventional method. The results of both algorithms monotonically increase as the reverberation time increases, while those remain regardless to the change of the input SNR. This shows that the SRR has dependency to the RT60 and is independent to the input SNR.
|
Fig. 11.SRR performances of the conventional and the proposed algorithm in noisy reverberant environment as a function of the input SNR and the reverberation time RT60 (white noise case). |
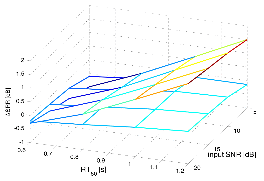
It is shown that the proposed algorithm is superior to the Habet's method, especially in the environment with strong reverberation. Because the proposed method utilizes additional information of the correlated com-ponents from the subsequent frames, it results in dynamic suppression of the late reverberation and thus, much more improvement of the SRR is attained under highly reverberant environment, such as RT60 = 1.2 s.
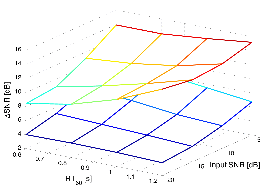
Figure 12 depicts the SNR performances of both studied algorithms against the input SNR and the reverberation time. From this figure, it is shown that the SNRs of the proposed algorithm is always bigger than those of the Habet's method. It is interesting that the SNR values of both algorithms has dependency not only to change of the input SNR but also to alteration of the reverberation time. The noise reduc-tion capacity of the proposed algorithm is improved for strongly reverberant environment, while the per-formance of the conventional one is not enhanced or rather counteracts.
|
Fig. 12.SNR performances of the conventional and the proposed algorithm in noisy reverberant environment according to the input SNR and the reverberation time RT60 (white noise case). |
We also conducted informal PESQ (Perceptual Evaluation of Speech Quality) measurement results. The results show that the proposed algorithm slightly outperforms to all the reference approaches. However, we do not include the detailed scores here because there is a clarification issue whether the PESQ score is suitable measure for measuring qualities in reverberant environment.
VI. Conclusion
In this paper, an efficient single-channel derever-beration algorithm to suppress the late reverberation from the noisy reverberant signal. The non-causal MVDR filter was proposed to attenuate the reverberant- plus-noise interference while minimizing speech distor-tion. It is interesting that the derived final filter equation is equivalent to one for noise-free environment, in spite of the additional interference (i.e. background noise). It apparently shows that the proposed MVDR filter is an algorithm robust to the noise, since it is primarily designed to minimize every components uncorrelated with desired speech.
An efficient method to estimate the correlation parameter was derived based on a statistical reverberant model and it is practically implemented. By adopting the correlation of late reverberation 款R(k, m, l) and that of noise signal 款V(k, m, l), the proposed method can control the aggressiveness of suppression of the interferences by estimating the changes which may occur at the subsequent frames.
Evaluation was conducted to verify the perfor-mance of the proposed algorithm by comparing with the conventional algorithm. The evaluation analysis was performed separately for each interference (the reverberant interference and the noise interference). The results showed that the proposed algorithm always outperformed the conventional one in various noisy reverberant environments. The performance improvement of the proposed algorithm was in-creased at the region that the speech ended, as it aggressively reduced the late reverberation at the region of the speech tail. The proposed algorithm maintained the minimal speech distortion and improved the SIR, the SNR, and the SRR perfor-mances in all studied conditions. The proposed system showed its superiority especially for the severely noisy and strongly reverberant environment.
